들어가며 — "작은 ViT는 왜 못 하는 걸까?"
2026년, 컴퓨터 비전의 풍경은 이렇다.
큰 ViT(Vision Transformer)는 경이적이다. DINOv3, SAM2, CLIP — 수억 파라미터의 거대 모델들은 객체 검출, 분할, 포즈 추정 등 거의 모든 밀집 예측(dense prediction) 과제에서 압도적 성능을 보여준다. 하지만 이 모델들은 서버급 GPU가 필수다. 자율주행차의 임베디드 보드, 드론의 엣지 칩, 스마트 카메라의 NPU에는 올릴 수 없다.
한편 엣지 디바이스에서의 밀집 예측은 여전히 CNN의 세계다. YOLO, MobileNet, EfficientNet — CNN 기반 경량 모델들이 엣지를 지배하고 있다. ViT가 엣지에 진입하지 못하는 이유는 명확해 보인다. "ViT는 무거우니까."
하지만 정말 그럴까? ViT를 작게 만들면 안 되는 걸까?
Intellindust AI Lab의 연구팀은 놀라운 실험을 했다. ViT-Tiny(5M 파라미터)를 ImageNet-21K로 지도 학습(supervised pretraining)한 뒤 COCO 검출에 적용했더니, 42.2% AP에 그쳤다. 같은 크기의 CNN 기반 모델보다 못한 수치다. 그런데 같은 ViT-Tiny를 아예 랜덤 초기화해서 검출 학습을 하면? 46.6% AP — 사전학습한 것보다 4.4%나 높다.
범용 사전학습이 소형 ViT에게는 오히려 독이 된 것이다.
그렇다면 질문은 이것이다. 소형 ViT에게 필요한 것은 "범용 지식"이 아니라 "태스크에 특화된 지식"이 아닐까?
이 질문의 답이 EdgeCrafter다. DINOv3를 검출 태스크에 먼저 적응시켜 "태스크 특화 교사"를 만들고, 이 교사로부터 소형 ViT에 지식을 증류한다. 결과: ECDet-S는 10M 파라미터로 51.7% AP — DEIMv2-S(50.9%)와 RT-DETRv4-S(49.7%)를 모두 넘어서며, COCO 주석만으로 학습했다. 그리고 이 검출용 백본이 인스턴스 분할과 포즈 추정에도 그대로 전이된다. 하나의 백본, 세 가지 태스크.
1장: 범용 사전학습의 역설 — 작을수록 더 해롭다
ImageNet 사전학습이 소형 ViT에게 독인 이유
이 논문의 가장 충격적인 발견은 Figure 1b에 요약된다.
| 초기화/증류 전략 | COCO AP (%) | 비고 |
|---|
| ViT-T + ImageNet-21K 사전학습 | 42.2 | 범용 사전학습 → 오히려 낮음 |
| ECViT-T + 랜덤 초기화 | 46.6 | 사전학습 없이 더 높음! |
| ECViT-T + DINOv3 증류 (범용) | 50.7 | VFM 증류는 효과적 |
| ECViT-T + 태스크 특화 증류 | 51.7 | 검출에 특화된 교사가 최고 |
왜 이런 일이 벌어질까?
범용 사전학습의 함정. ImageNet-21K 분류 학습은 "이미지 전체를 하나의 라벨로 분류"하는 과제다. 이 과정에서 모델은 전역적 의미론(global semantics)을 학습한다. 하지만 밀집 예측(검출, 분할, 포즈)은 공간적 정밀도(spatial precision)가 핵심이다. 객체의 경계, 키포인트의 정확한 위치, 픽셀 단위의 마스크 — 이 모든 것이 세밀한 공간 정보를 요구한다.
큰 ViT는 용량이 충분하여, 범용 사전학습으로 얻은 전역 지식 위에 공간 정보를 추가 학습할 수 있다. 하지만 소형 ViT는 용량이 제한적이다. 범용 분류에 맞춰진 표현이 이미 모델을 채우고 있으면, 검출에 필요한 공간 표현을 새로 학습할 여지가 줄어든다. 결과적으로, 사전학습이 오히려 학습을 방해한다.
이것은 Ghiasi et al. (2021)과 Zoph et al. (2020)의 관찰과도 일치한다. 작은 모델에서는 사전학습이 반드시 이득이 아니다.
태스크 특화 증류가 답이다
그렇다면 해법은 명확하다. 소형 ViT에게 처음부터 검출에 특화된 표현을 가르치면 된다. 하지만 소형 ViT가 직접 검출을 잘 학습하기는 어렵다 — 용량이 부족하니까. 그래서 거대한 VFM을 검출 교사로 변환한 뒤, 그 교사로부터 증류하는 것이다.
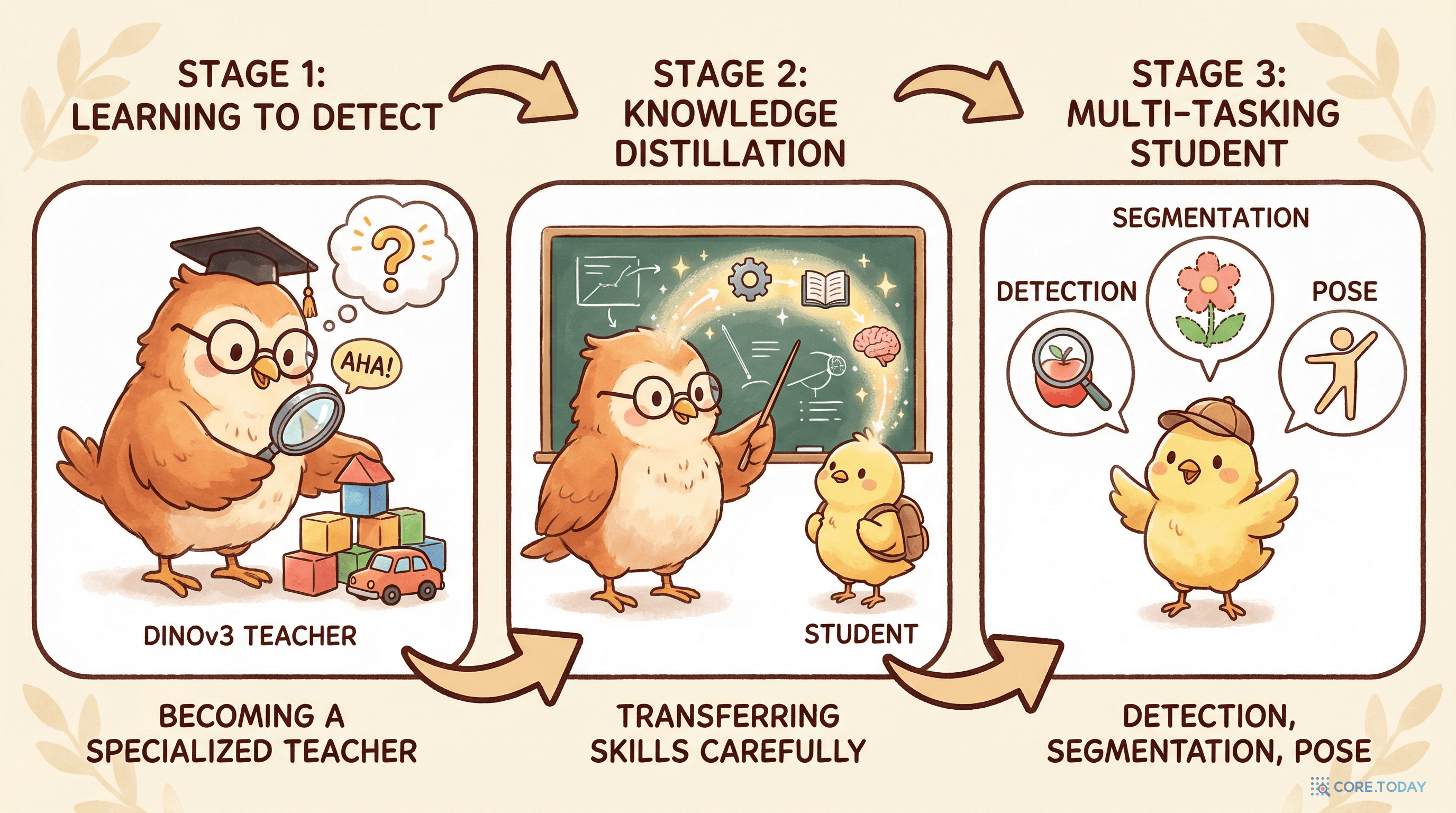
2장: 3단계 파이프라인 — 교사 준비, 증류, 태스크 전이
Stage 1: 교사 준비 — DINOv3를 검출 전문가로
EdgeCrafter의 첫 단계는 범용 VFM인 DINOv3를 검출 전문 교사(ECTeacher)로 변환하는 것이다.
Stage 1
DINOv3를 ECDet 프레임워크 안에서 COCO 검출 데이터로 적응 → ECTeacher 생성. 범용 VFM이 검출 전문가로 변환된다.
Stage 2
ECTeacher의 표현을 소형 ECViT 학생에게 특징 정렬(feature alignment) 증류. ImageNet-1K + COCO 이미지 사용.
Stage 3
증류된 ECViT 백본으로 ECDet(검출), ECInsSeg(분할), ECPose(포즈) 학습. 백본+인코더 공유, 태스크별 헤드만 교체.
핵심: 교사가 범용 DINOv3가 아니라, 검출에 적응된 DINOv3라는 점이다. RT-DETRv4는 범용 DINOv3를 교사로 사용했지만, EdgeCrafter는 한 단계 더 나아가 교사 자체를 태스크에 맞춘다.
Stage 2: 특징 정렬 증류 — 단순하지만 강력한
증류의 핵심은 특징 정렬(feature alignment)이다. 학생의 마지막 트랜스포머 블록 출력을 교사의 마지막 두 블록 출력에 정렬한다.
Ldistill = Σl∈{L-1,L} || φ(XLS) − XlT ||2
· XLS: 학생의 마지막 블록 출력
· XlT: 교사의 l번째 블록 출력 (L-1, L)
· φ: 선형 어댑터 (차원 맞춤)
일대다(one-to-many) 정렬: 학생의 단일 특징이 교사의 여러 특징과 정렬된다. 무거운 프로젝션 헤드 없이 최소한의 어댑터로, 학생 백본에 표현 부담을 집중시킨다.
Stage 3: 하나의 백본, 세 가지 태스크
가장 우아한 설계는 Stage 3다. 검출(ECDet)을 위해 증류된 백본과 인코더가 인스턴스 분할(ECInsSeg)과 포즈 추정(ECPose)에 그대로 재사용된다.
ECViT 백본 + 인코더
(검출 증류로 학습, 모든 태스크에서 공유)
↓ ↓ ↓
ECDet
검출 디코더
ECInsSeg
+ 마스크 헤드
ECPose
+ 포즈 헤드
각 태스크에서 백본과 인코더는 고정되고, 태스크별 경량 헤드만 교체된다. 이것이 의미하는 바:
- 엣지 디바이스에 하나의 백본만 올리면, 세 가지 태스크를 모두 수행 가능
- 백본 메모리/연산을 공유하므로 멀티태스크 배포가 효율적
3장: ECDet 아키텍처 — 엣지 친화적 ViT 설계
합성곱 스템: 패치 임베딩의 대체
표준 ViT는 16×16 패치 임베딩을 사용한다. 하나의 큰 스트라이드로 토큰화하는 것인데, 이 과정에서 세밀한 공간 디테일이 손실된다. 분류에는 문제없지만, 검출처럼 정밀한 위치가 중요한 태스크에서는 치명적이다.
EdgeCrafter는 패치 임베딩을 4개의 3×3 합성곱 스트라이드 2 스택으로 대체한다. 수용야(receptive field)를 점진적으로 확장하면서 지역 구조를 보존한다. 중심부에 집중된 효과적 수용야(effective receptive field)가 유지되어, 검출에 중요한 세밀한 위치 정보가 살아남는다.
경량 멀티스케일 특징 피라미드
ViT는 단일 스케일(1/16) 출력만 생성한다. 검출에는 멀티스케일이 필수다. EdgeCrafter는 비용이 큰 Feature Pyramid 대신 극도로 단순한 방법을 사용한다.
1. 마지막 두 블록 평균:
F(16) = ½ (XL-1 + XL)
2. 양선형 보간 + 1×1 투영:
F(s) = Θs(Bs(F(16))), s ∈ {8, 16, 32}
→ 파라미터 프리 보간 + 최소한의 투영으로 3스케일 피라미드 완성
DEIMv2의 STA는 여러 ViT 블록에서 특징을 추출하고 Bi-Fusion으로 합성했지만, EdgeCrafter는 마지막 두 블록의 평균 하나만 사용한다. 더 단순하고 더 적은 연산.
인코더와 디코더
인코더는 RT-DETR의 AIFI + CCFF를 따르고, 디코더는 4개 레이어, 300 쿼리로 모든 스케일에서 고정된다. 변하는 것은 백본의 너비(embedding dimension)와 인코더/디코더의 히든 차원뿐이다.
| 모델 | ECViT 변형 | Embed Dim | Heads | 교사 |
|---|
| ECDet-S | ECViT-T | 192 | 3 | ECTeacher-S |
| ECDet-M | ECViT-T+ | 256 | 4 | ECTeacher-B |
| ECDet-L | ECViT-S | 384 | 6 | ECTeacher-B |
| ECDet-X | ECViT-S+ | 384 | 6 | ECTeacher-B |
4장: 실험 결과 — 세 가지 태스크에서 모두 SOTA
아래 탐색기에서 EdgeCrafter의 세 가지 태스크 성능을 직접 비교해보자.
객체 검출: ECDet
| S 모델 | 에폭 | 파라미터 | GFLOPs | AP (%) |
|---|
| YOLOv12-S-turbo | 600 | 9M | 19 | 47.6 |
| D-FINE-S | 124 | 10M | 25 | 48.5 |
| DEIM-S | 132 | 10M | 25 | 49.0 |
| RT-DETRv4-S | 132 | 10M | 25 | 49.7 |
| DEIMv2-S | 132 | 10M | 26 | 50.9 |
| ECDet-S | 74 | 10M | 26 | 51.7 |
ECDet-S: 51.7% AP, 10M 파라미터, COCO 주석만 사용. DEIMv2-S(50.9%)를 +0.8%, RT-DETRv4-S(49.7%)를 +2.0% 앞서며, Objects365 사전학습에 의존하는 경쟁자들과도 비교할 만하다.
| X 모델 | 에폭 | 파라미터 | GFLOPs | AP (%) |
|---|
| D-FINE-X | 72 | 62M | 202 | 55.8 |
| DEIM-X | 58 | 62M | 202 | 56.5 |
| RT-DETRv4-X | 58 | 62M | 202 | 57.0 |
| DEIMv2-X | 58 | 50M | 152 | 57.8 |
| ECDet-X | 50 | 49M | 151 | 57.9 |
ECDet-X: 57.9% AP — DEIMv2-X(57.8%)와 거의 동일하면서, Objects365 사전학습 없이 달성. 가장 적은 에폭(50)으로 최고 수준 성능.
인스턴스 분할: ECInsSeg
| 모델 | 파라미터 | GFLOPs | 지연 (ms) | Mask AP (%) |
|---|
| ECInsSeg-S | 10M | 33 | 6.96 | 43.0 |
| ECInsSeg-M | 20M | 64 | 9.85 | 45.2 |
| ECInsSeg-L | 34M | 111 | 12.56 | 47.1 |
| ECInsSeg-X | 50M | 168 | 14.96 | 48.4 |
ECInsSeg는 RF-DETR-Seg와 비교할 만한 성능을 훨씬 적은 파라미터로 달성한다. 백본과 인코더가 ECDet에서 그대로 전이되므로, 분할 전용 학습 비용이 최소다.
포즈 추정: ECPose
| 모델 | 파라미터 | GFLOPs | 지연 (ms) | Keypoint AP (%) |
|---|
| ECPose-S | 10M | 30 | 5.54 | 68.9 |
| ECPose-M | 20M | 63 | 9.25 | 72.4 |
| ECPose-L | 34M | 112 | 11.83 | 73.5 |
| ECPose-X | 51M | 172 | 14.31 | 74.8 |
| YOLO26Pose-X (참고) | — | — | — | 71.6 |
ECPose-X: 74.8% AP — YOLO26Pose-X(71.6%)를 3.2% AP 능가한다. 검출을 위해 증류된 ViT 표현이 포즈 추정에서도 강력하다는 놀라운 결과다.
EdgeCrafter 멀티태스크 성능 (X 스케일)
5장: 왜 태스크 특화 증류가 범용 증류보다 나은가
교사의 질이 학생의 질을 결정한다
논문의 어블레이션에서 중요한 관찰이 있다.
범용 DINOv3에서 직접 증류하면 50.7% AP를 달성한다. 하지만 DINOv3를 먼저 검출에 적응시킨 뒤 증류하면 51.7% AP — +1.0% 추가 향상이다.
1%가 작아 보일 수 있지만, 이 규모(50% AP 이상)에서 1%는 수개월의 아키텍처 연구에 해당하는 향상이다. 그리고 이 향상은 추가 파라미터나 연산 비용 없이 달성된다 — 교사가 더 좋을 뿐이다.
직관적으로: 수학을 배우려는 학생에게 "모든 과목을 잘하는 범용 교사"보다 "수학 전문 교사"가 더 효과적인 것과 같다.
RT-DETRv4, DEIMv2와의 차이
| 접근법 | 교사 | 증류 대상 | 추론 시 백본 |
|---|
| RT-DETRv4 | 범용 DINOv3 | AIFI 특징 F̃5만 | CNN (HGNetv2) |
| DEIMv2 | DINOv3 자체가 백본 | 직접 사용 | ViT (DINOv3) |
| EdgeCrafter | 검출 적응 DINOv3 | 소형 ViT 전체 | 소형 ViT (ECViT) |
EdgeCrafter의 독특한 위치:
- RT-DETRv4처럼 증류를 사용하지만, 교사가 태스크 특화됨
- DEIMv2처럼 ViT 백본을 사용하지만, 소형(compact) ViT
- 결과적으로 소형 ViT + 태스크 특화 증류라는 새로운 조합
6장: 엣지 배포의 실제
파라미터와 메모리
EdgeCrafter의 실무적 가치는 파라미터 효율성에 있다.
| 모델 | AP (%) | 파라미터 | GFLOPs |
|---|
| ECDet-S | 51.7 | 10M | 26 |
| RT-DETRv2-S | 48.1 | 20M | 60 |
| RF-DETR-S | 52.9 | 32M | 60 |
ECDet-S는 RT-DETRv2-S의 절반 파라미터, 절반 이하 GFLOPs로 3.6% 높은 AP를 달성한다. RF-DETR-S는 AP에서 앞서지만, 파라미터가 3.2배, GFLOPs가 2.3배 많다.
엣지 디바이스에서 10M 파라미터는 FP16으로 약 20MB, INT8 양자화하면 10MB — 대부분의 엣지 칩에 올릴 수 있는 크기다. 그러면서 51.7% AP라는 높은 정확도를 제공한다.
멀티태스크 배포의 효율
엣지 디바이스에서 검출, 분할, 포즈를 모두 수행해야 한다면?
기존 방식: 세 가지 별도 모델을 각각 로드 → 메모리 3배, 관리 복잡
EdgeCrafter: 하나의 ECViT 백본 + 세 개의 경량 태스크 헤드 → 백본 메모리 공유, 단일 프레임워크
7장: 2026년의 EdgeCrafter — ViT의 엣지 시대를 열다
"CNN만 가능하다"는 편견의 종말
EdgeCrafter가 증명한 것은 이것이다.
"소형 ViT가 엣지에서 약한 것은 아키텍처의 한계가 아니라, 태스크 특화 표현의 부족 때문이다."
올바른 증류 전략(태스크 특화 교사)과 올바른 설계(합성곱 스템, 경량 피라미드)를 갖추면, 10M 파라미터의 ViT가 CNN 기반 경쟁자를 능가할 수 있다.
객체 검출 시리즈의 완성
이 글은 YOLO에서 시작된 객체 검출 시리즈의 마지막 글이다. 11년의 여정을 돌아보자.
2015
YOLO — 검출을 회귀로. 실시간의 탄생.
2024
RT-DETR — NMS 제거. 트랜스포머의 실시간.
2024
D-FINE — 좌표 대신 분포 정제.
2025
RT-DETRv4 — VFM 증류, 추론비용 0.
2026
DEIMv2 — DINOv3 직접 통합, 8스케일.
2026
EdgeCrafter — 태스크 특화 증류로 소형 ViT가 엣지에서 멀티태스크.
각 세대가 이전 세대의 한계를 돌파해왔고, EdgeCrafter는 그 최전선에서 "엣지에서의 밀집 예측"이라는 가장 실용적인 문제를 해결한다.
마치며 — 작은 것이 아름답다, 다시 한 번
EdgeCrafter의 메시지는 명확하다.
크기가 작다고 능력이 없는 것이 아니다. 올바른 교육을 받지 못했을 뿐이다.
ViT-Tiny에 ImageNet-21K를 주입하면 42.2% AP에 그친다. 하지만 검출에 특화된 교사로부터 정교하게 증류하면 51.7% AP — 9.5%나 향상된다. 같은 학생에게 같은 시간을 투자해도, 교사의 질과 교육 방법이 결과를 좌우한다.
그리고 이 교육의 성과는 검출을 넘어 분할과 포즈까지 전이된다. 하나의 교육이 세 가지 능력을 낳는다.
57.9% AP의 검출, 48.4% AP의 분할, 74.8% AP의 포즈. 모두 하나의 소형 ViT 백본에서. 모두 엣지에서 실시간으로.
작은 것이 아름답다. 단, 올바르게 가르쳤을 때.
참고 자료
- Liu, L., Hou, Y., Li, Y., Wang, Q., Sha, Y., Yu, Y., Wang, Y., Ru, P., Yu, X., & Shen, X. (2026). "EdgeCrafter: Compact ViTs for Edge Dense Prediction via Task-Specialized Distillation." arXiv:2603.18739
- Siméoni, O. et al. (2025). "DINOv3." arXiv 2025.
- Huang, S. et al. (2026). "DEIMv2: Real-Time Object Detection Meets DINOv3." arXiv 2026.
- Liao, Z. et al. (2025). "RT-DETRv4: Painlessly Furthering Real-Time Object Detection with Vision Foundation Models."
- Peng, Y. et al. (2024). "D-FINE: Redefine Regression Task in DETRs." ICLR 2024.
- Zhao, Y. et al. (2024). "DETRs Beat YOLOs on Real-time Object Detection." CVPR 2024.
- 프로젝트: https://intellindust-ai-lab.github.io/projects/EdgeCrafter/
- 코드: https://github.com/Intellindust-AI-Lab/EdgeCrafter