블로그로 돌아가기
온톨로지지식 그래프Palantir시맨틱 웹데이터 모델링
온톨로지의 모든 것: 아리스토텔레스에서 Palantir까지
2,400년 전 아리스토텔레스가 '존재의 범주'를 정리한 이래, 온톨로지는 철학에서 컴퓨터 과학으로, 다시 엔터프라이즈 AI의 핵심으로 진화해 왔다. Palantir 특집과 함께 그 역사를 추적한다.
코어닷투데이2026-01-0239분
2,400년 전 아리스토텔레스가 '존재의 범주'를 정리한 이래, 온톨로지는 철학에서 컴퓨터 과학으로, 다시 엔터프라이즈 AI의 핵심으로 진화해 왔다. Palantir 특집과 함께 그 역사를 추적한다.
ChatGPT 이후 AI 업계의 관심은 온통 LLM에 쏠려 있다. 그런데 2024~2025년, 의외의 키워드가 엔터프라이즈 AI의 중심으로 부상했다. 바로 온톨로지(Ontology) 다.
Microsoft가 GraphRAG를 오픈소스로 공개하고, Palantir가 "온톨로지 위의 AI"를 내세워 시가총액 760억 달러를 돌파하고, 미국 국방부가 공식 온톨로지 표준을 채택하면서 — 이 2,400년 된 개념이 갑자기 가장 뜨거운 기술 화두가 되었다.
온톨로지란 무엇이고, 어떻게 철학의 서재에서 실리콘밸리의 서버실까지 왔을까? 그리고 Palantir는 이 개념을 어떻게 1,300억 달러짜리 플랫폼의 핵심으로 만들었을까?

온톨로지의 역사는 고대 그리스의 파르메니데스에서 시작된다. 그는 서양 철학사에서 최초로 "존재(being)"와 "비존재(non-being)"를 명시적으로 논한 인물이다. 그의 핵심 주장은 과감했다 — 존재는 영원하고 불변하며, 감각 세계의 모든 변화는 환상이라는 것.
이 주장은 후대에 두 가지 방향으로 갈라진다. 플라톤은 "이데아의 세계"로, 아리스토텔레스는 "범주론"으로.
아리스토텔레스는 형이상학 제4권에서 온톨로지를 "제1철학(first philosophy)"이라 불렀다. 그리고 범주론(Categories)에서 존재를 10가지 범주로 분류했다:
| 범주 | 그리스어 | 현대적 예시 |
|---|---|---|
| 실체(Substance) | οὐσία | "사람", "말" |
| 양(Quantity) | ποσόν | "2미터", "3킬로그램" |
| 질(Quality) | ποιόν | "하얀", "문법적인" |
| 관계(Relation) | πρός τι | "두 배의", "절반의" |
| 장소(Place) | ποῦ | "아고라에서" |
| 시간(Time) | πότε | "어제" |
| 자세(Position) | κεῖσθαι | "앉아 있는" |
| 상태(State) | ἔχειν | "무장한" |
| 능동(Action) | ποιεῖν | "자르다" |
| 수동(Passion) | πάσχειν | "잘리다" |
이 체계에서 실체(Substance) 가 가장 근본적인 범주다. 나머지 9개 범주는 모두 실체에 의존한다. "하얗다"는 속성은 "하얀 무엇"이 있어야 성립하기 때문이다.
2,300년이 지난 오늘날, 데이터베이스의 Entity-Attribute 모델이나 객체지향 프로그래밍의 Class-Property 구조가 이 범주론과 놀랍도록 닮아 있다는 점은 우연이 아니다.
포르피리오스는 아리스토텔레스의 범주론에 대한 입문서 이사고게(Isagoge)를 저술하며, 서양 지성사 최초의 계층적 분류 체계를 만들었다 — "포르피리오스의 나무(Arbor Porphyriana)"다.
이것은 본질적으로 트리 구조의 분류 체계다. 속(Genus) → 종(Species) → 종차(Differentia)로 내려가는 이 구조는, 보에티우스가 6세기에 라틴어로 번역한 뒤 중세 내내 표준 논리학 교과서로 사용되었다. 현대 컴퓨터 과학의 클래스 상속(class inheritance) 개념의 직접적 조상이라 할 수 있다.
중세 철학에서 온톨로지의 핵심 논쟁은 "존재의 의미는 하나인가, 여럿인가"였다.
이 논쟁이 현대 데이터 모델링에 시사하는 바가 있다. "하나의 통합 스키마로 모든 도메인을 표현할 수 있는가(일의성)" vs. "도메인마다 별도의 스키마가 필요한가(유비성)" — 이것은 오늘날 상위 온톨로지(upper ontology) 와 도메인 온톨로지(domain ontology) 간의 관계를 설계할 때 여전히 핵심적인 문제다.
야코프 로르하르트(Jacob Lorhard) 가 1606년 저서 Ogdoas Scholastica에서 "ontologia"라는 단어를 최초로 사용했다 — "존재 일반에 대한 학문(scientia entis in genere)"이라는 뜻이다. 이후 크리스티안 볼프(Christian Wolff) 가 1730년 Philosophia Prima sive Ontologia를 출간하며 이 용어를 학문적으로 정착시켰다.
임마누엘 칸트 (1724~1804) 는 순수이성비판(1781)에서 볼프식 합리론적 온톨로지에 치명적 일격을 가했다. 인과성, 실체 같은 범주는 경험의 조건이지, 경험 너머의 "물자체(Ding an sich)"에 대한 지식을 줄 수 없다는 것이다.
이후 온톨로지는 한동안 철학의 주류에서 밀려났다가, 마르틴 하이데거 (1889~1976) 가 1927년 존재와 시간(Sein und Zeit)에서 부활시켰다. 하이데거는 "현존재(Dasein)" — 세계-내-존재로서의 인간 — 에 대한 분석을 통해 근본적 온톨로지를 제시했다.
철학적 온톨로지가 컴퓨터 과학에 진입한 계기는 의외로 AI의 한계에서 비롯되었다. 1980년대 전문가 시스템(expert system)은 특정 도메인에서는 뛰어났지만, 시스템 간에 지식을 공유하거나 재사용하는 것이 불가능했다.
1983년 스탠퍼드에서 열린 모임에서 마빈 민스키, 앨런 뉴얼, 에드워드 파이겐바움, 존 매카시 등 AI 거장들이 모여 논의한 결론은 하나였다 — AI의 근본적 한계는 상식(common sense) 의 부재다.
더그 레넷(Douglas Lenat) 은 이 문제를 정면 돌파하기로 했다. 1984년 7월, 그는 MCC에서 Cyc 프로젝트를 시작했다. 목표: 인간이 당연하게 여기는 상식 지식을 포괄하는 온톨로지와 지식 베이스를 구축하는 것.
Cyc는 상업적으로는 제한적 성공에 그쳤지만, 온톨로지 엔지니어링이라는 분야 자체를 탄생시켰다.
1993년, 톰 그루버(Tom Gruber) 가 발표한 논문은 컴퓨터 과학에서의 온톨로지 개념을 결정적으로 확립했다:
"An ontology is an explicit specification of a conceptualization." 온톨로지란 개념화의 명시적 명세다.
이 정의는 Google Scholar 기준 21,000회 이상 인용되었으며, DARPA의 지식 공유 이니셔티브에서 출발했다. 그루버는 Ontolingua라는 번역 시스템도 개발해, 술어 논리로 작성된 온톨로지 정의를 다양한 표현 형식으로 변환할 수 있게 했다.
이 정의가 혁명적이었던 이유는, 온톨로지를 철학적 사변에서 공학적 산출물로 전환시켰기 때문이다. 온톨로지는 더 이상 "존재란 무엇인가"에 대한 답이 아니라, "우리 시스템이 세계를 어떻게 모델링할 것인가"에 대한 합의된 설계도가 되었다.
2001년 5월, 월드와이드웹의 창시자 팀 버너스리는 제임스 핸들러, 오라 라실라와 함께 Scientific American에 역사적인 논문을 발표했다:
"I have a dream for the Web in which computers become capable of analyzing all the data on the Web."
이 비전은 시맨틱 웹(Semantic Web) — 컴퓨터가 의미를 이해할 수 있는 웹 — 이었다. 핵심 기술 스택은 이렇다:
OWL(Web Ontology Language) 은 2004년 2월 10일 W3C 표준이 되었다. OWL Lite, OWL DL, OWL Full의 세 가지 방언을 정의하며, 클래스 간의 관계, 속성의 제약 조건, 추론 규칙을 형식적으로 표현할 수 있게 했다.
시맨틱 웹의 비전 자체는 완전히 실현되지 않았다. 하지만 그 기술적 유산 — RDF, OWL, SPARQL, 지식 그래프 — 은 오늘날 AI 시스템의 핵심 인프라가 되었다. 버너스리의 2001년 논문은 30,000회 이상 인용되었다.
2012년 5월 16일, 구글의 엔지니어 아밋 싱할(Amit Singhal) 은 이 한마디로 Knowledge Graph를 소개했다:
"Things, not strings."
출시 당시 5억 개의 엔티티와 35억 개의 팩트를 보유했던 이 시스템은, 7개월 만에 5억 7천만 엔티티, 180억 팩트로 성장했다. 2016년 중반에는 700억 팩트에 달하며 구글 검색의 약 1/3을 처리하게 되었다.
Knowledge Graph의 성공 이후, Microsoft(Satori, 2013), Facebook, LinkedIn, Amazon, IBM이 모두 자체 지식 그래프를 구축했다. 온톨로지는 더 이상 학술적 개념이 아니라 빅테크의 핵심 경쟁력이 되었다.

2003년, 피터 틸(Peter Thiel) 은 PayPal에서의 경험에서 착안한 아이디어로 회사를 설립했다. PayPal에서 사기 거래를 탐지하던 패턴 인식 기술이 9/11 이후의 대테러 작전에도 적용될 수 있다는 것이었다. 틸은 개인 자금 3,000만 달러를 투자하고, 스탠퍼드 법학대학원 동문인 알렉스 카프(Alex Karp) — 프랑크푸르트 괴테대학교에서 철학 박사학위를 받은 인물 — 를 CEO로 영입했다.
회사 이름은 톨킨의 반지의 제왕에 등장하는 "팔란티르(palantír)" — 멀리 보는 수정구 — 에서 따왔다.
초기 3년간 매출이 전무한 상태에서 엔지니어들은 이라크, 아프가니스탄, 대테러 작전 현장에 직접 파견되어 기술을 개발했다. 이 현장 경험이 Palantir 온톨로지의 DNA를 형성했다.
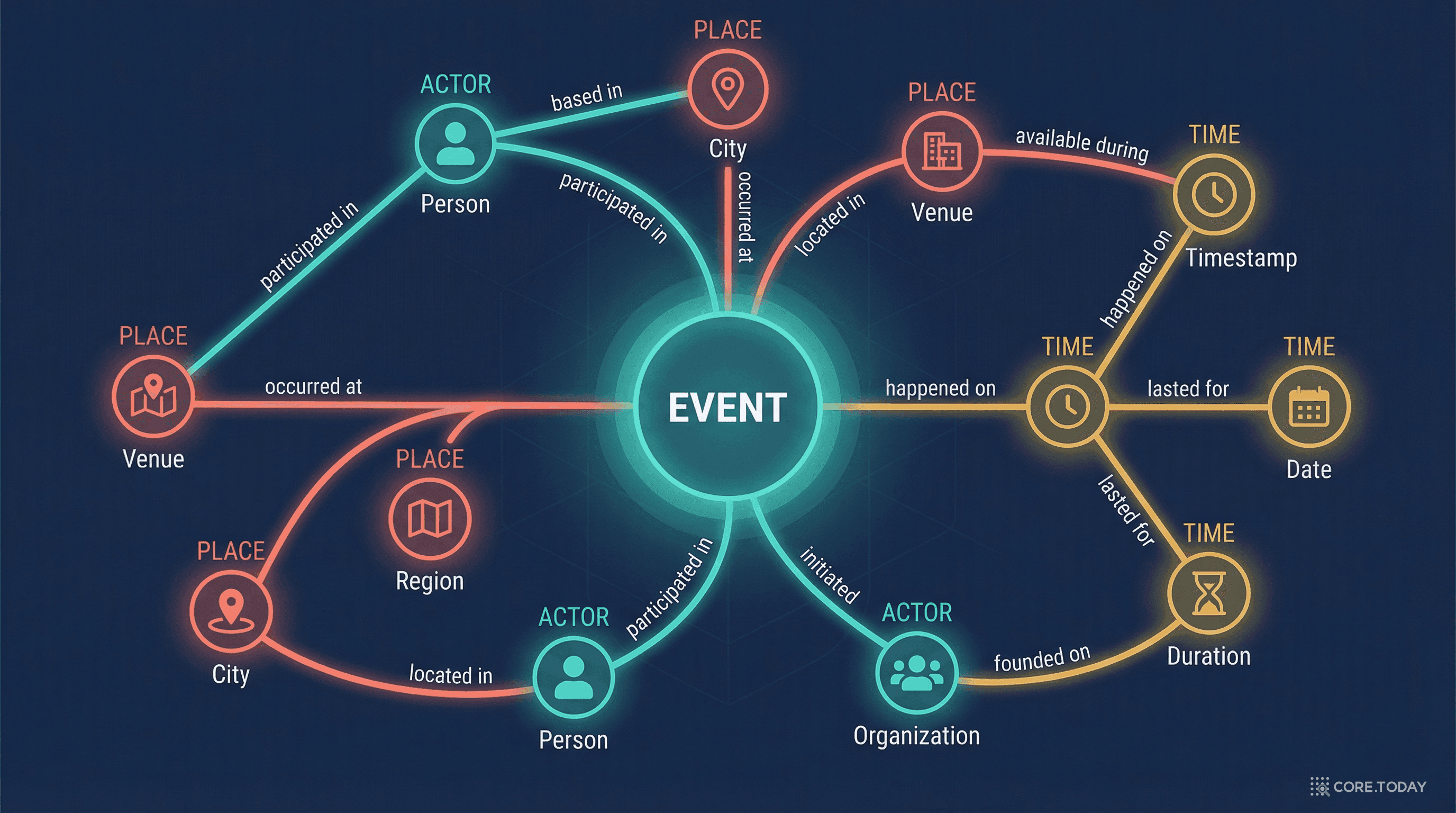
Palantir의 온톨로지는 학술적 OWL/RDF 온톨로지와는 결이 다르다. 그것은 단순한 데이터 모델이 아니라, 조직 전체의 디지털 트윈 — 데이터를 통합하고, 의미를 부여하고, 그 위에서 행동(Action)까지 가능하게 하는 운영 계층(operational layer) 이다.
핵심은 세 개의 레이어로 구성된다:
전통적 데이터베이스 개념과 Palantir 온톨로지의 대응 관계:
| 전통 데이터베이스 | Palantir 온톨로지 | 현실 세계 |
|---|---|---|
| 테이블(Table) | 오브젝트 타입(Object Type) | 직원, 항공기, 주문 |
| 행(Row) | 오브젝트(Object) | "김철수", "A350-941 #1234" |
| 열(Column) | 속성(Property) | 이름, 제조일, 상태 |
| 조인(Join) | 링크 타입(Link Type) | "소속", "담당", "공급" |
| — | 인터페이스(Interface) | 다형적 상호작용 패턴 |
예를 들어, "직원" 오브젝트 타입에는 이름, 직급, 부서 등의 속성이 있고, "부서" 오브젝트 타입과 "소속" 링크로 연결된다. 이것은 관계형 데이터베이스의 JOIN과 비슷해 보이지만, 결정적 차이가 있다 — 비즈니스 의미가 스키마 자체에 내장되어 있다는 점이다.
여기서 Palantir 온톨로지가 다른 모든 온톨로지와 차별화된다.
이것은 1980년대 지식공학의 3요소 — 시맨틱, 키네틱, 다이나믹 — 를 현대적으로 구현한 것이지만, 실시간 운영 시스템에 대한 쓰기(write-back) 가 가능하다는 점에서 학술적 온톨로지와 근본적으로 다르다.
Gotham (2008~)은 국방·정보기관을 위해 설계되었다. 감시 데이터, 위성 영상, 신호정보 등 다양한 출처의 원시 데이터를 자동으로 인제스트하고, 엔티티 해소(entity resolution)를 통해 중복을 제거하고, 사람·장소·사물·사건 간의 관계를 그래프로 매핑한다. 분석관이 여러 데이터베이스를 동시에 질의할 수 있게 하여, 정보 사일로를 해체했다.
Foundry (2016~)는 이 기술을 상업 영역으로 확장한 것이다. 500개 이상의 데이터 소스 커넥터를 제공하며, Apache Spark과 Apache Flink를 컴퓨트 엔진으로 활용한다. 데이터가 인제스트되면 변환 파이프라인을 거쳐 온톨로지 오브젝트로 매핑되고, 그 위에서 애플리케이션이 구축된다.
2023년 4월 출시된 AIP(Artificial Intelligence Platform) 는 Palantir의 가장 중요한 전략적 이동이다. LLM을 온톨로지와 통합하여, AI가 단순한 텍스트 검색(RAG)을 넘어 구조화된 데이터, 로직, 액션과 직접 상호작용할 수 있게 했다.
핵심은 온톨로지가 AI의 가드레일 역할을 한다는 것이다. LLM이 환각(hallucination)을 일으키더라도, 온톨로지에 정의된 오브젝트, 속성, 링크, 액션의 구조가 AI의 행동 범위를 제한한다. 역할·분류·목적 기반 접근 제어가 AI 에이전트에도 동일하게 적용되며, 모든 AI 활동은 감사 추적된다.
AIP 부트캠프는 5일 집중 워크숍으로, 고객을 제로에서 실제 유스케이스까지 안내한다. 2024년 Q4 기준 1,300회 이상 진행되었으며, 약 75%의 전환율을 보인다. 기존에 거의 1년 걸리던 영업 주기를 며칠로 압축한 것이다.
2015년 말, 에어버스는 A350 생산에서 위기에 직면했다. 500만 개의 부품, 4개국, 8개 공장의 데이터가 분산되어 있었다. Palantir Foundry는 생산 일정, 교대 근무, 부품 납품, 작업 지시, 품질 데이터를 하나의 온톨로지로 통합했다.
결과: A350 생산 속도 33% 향상. 이 성공을 바탕으로 2017년 Skywise 항공 데이터 플랫폼이 탄생했다. 2025년 현재 10,500대 이상의 항공기 (에어버스 전체 기단의 49%)가 연결되어 있으며, 월간 고유 사용자 수는 25,000명에 달한다.
2020년 3월, 미국 CDC/HHS/NIH는 Palantir Foundry를 도입해 코로나 확산을 추적했다. 병원, 주, 기타 기관에서 올라오는 파편화된 데이터를 정제·통합하여, 인공호흡기 분배, 마스크 할당, 지역사회 수요 예측에 활용했다.
영국 NHS도 Foundry 기반으로 COVID-19 데이터를 분석했다. 이후 2023년 11월, 영국 정부는 NHS Federated Data Platform(FDP) 구축을 위해 Palantir와 7년간 3억 3천만 파운드 계약을 체결했다.
이 시스템은 위성 영상, 위치 정보 등 다양한 소스를 인제스트하여 잠재적 표적을 자동 탐지한다. 참고로, 구글은 직원 수천 명의 항의로 2018년에 Project Maven에서 철수했다.
2024년 3월, 미 육군은 Palantir에 1억 7,840만 달러를 투자하여 TITAN(Tactical Intelligence Targeting Access Node) 프로토타입 10기를 개발·생산하도록 했다. TITAN은 지상국으로서 육군 부대를 고고도·우주 센서에 연결하며, AI/ML을 활용해 다중 도메인 센서 데이터를 신속히 처리한다. 2025년 3월, 첫 두 대의 프로토타입이 예산과 일정 내에 납품되었다.
Palantir의 온톨로지 기술은 동시에 가장 논란이 많은 기술이기도 하다.
ICE(이민세관단속국) 계약: 2013년부터 ICE에 FALCON, ICM 등의 시스템을 제공해 왔다. 직장 급습, 대규모 단속, 망명 신청자 관련 수사에 활용되었다. 2019년 8월에는 연간 1,600만 달러 규모의 새 계약이 체결되었고, 2025년에는 ImmigrationOS라는 3,000만 달러 규모의 새 플랫폼 개발이 시작되었다.
사내 반발: 2019년, 200명 이상의 Palantir 직원이 카프 CEO에게 ICE 소프트웨어 사용에 대한 항의 서한을 보냈다. 60명 이상이 서명한 별도의 청원서는 ICE 계약 수익을 자선단체에 기부할 것을 요청했다.
프라이버시 우려: Amnesty International은 알고리즘 편향, 표현의 자유 침해, 인간 감독 부재를 우려했다. 비판자들은 Palantir의 기술이 "대중 감시(mass surveillance)"를 가능하게 하며, 개인을 "기본적으로 의심스러운 존재"로 취급한다고 주장한다.
이 논쟁은 온톨로지 기술 자체의 본질적 문제를 드러낸다. 세계를 정밀하게 모델링하고, 엔티티 간의 관계를 파악하고, 그 위에서 행동을 자동화하는 능력은 — 그것이 공급망 최적화에 쓰이든 이민자 추적에 쓰이든 — 기술적으로 동일하다. 차이는 거버넌스와 윤리에 있다.
헬스케어: SNOMED CT는 1965년 SNOP에서 시작되어, 현재 80개국 이상에서 사용되는 포괄적 의학 용어 온톨로지다. Gene Ontology(2000년 Nature Genetics 발표)는 생물정보학의 표준 도구가 되었다.
금융: FIBO(Financial Industry Business Ontology)는 2008년 금융위기 이후 EDM Council과 OMG가 개발한 금융 산업 온톨로지다. OWL로 작성되어 금융 계약, 상품, 기관에 대한 표준 어휘를 제공한다.
국방·정보: 2024년 2월, 미 국방부와 국가정보국장실(ODNI)은 BFO(Basic Formal Ontology) 와 CCO(Common Core Ontology) 를 공식 온톨로지 표준으로 채택했다. BFO는 뉴욕주립대 버펄로의 배리 스미스(Barry Smith) 가 개발했으며, 2021년에 ISO/IEC 21838-2 국제표준이 되었다.
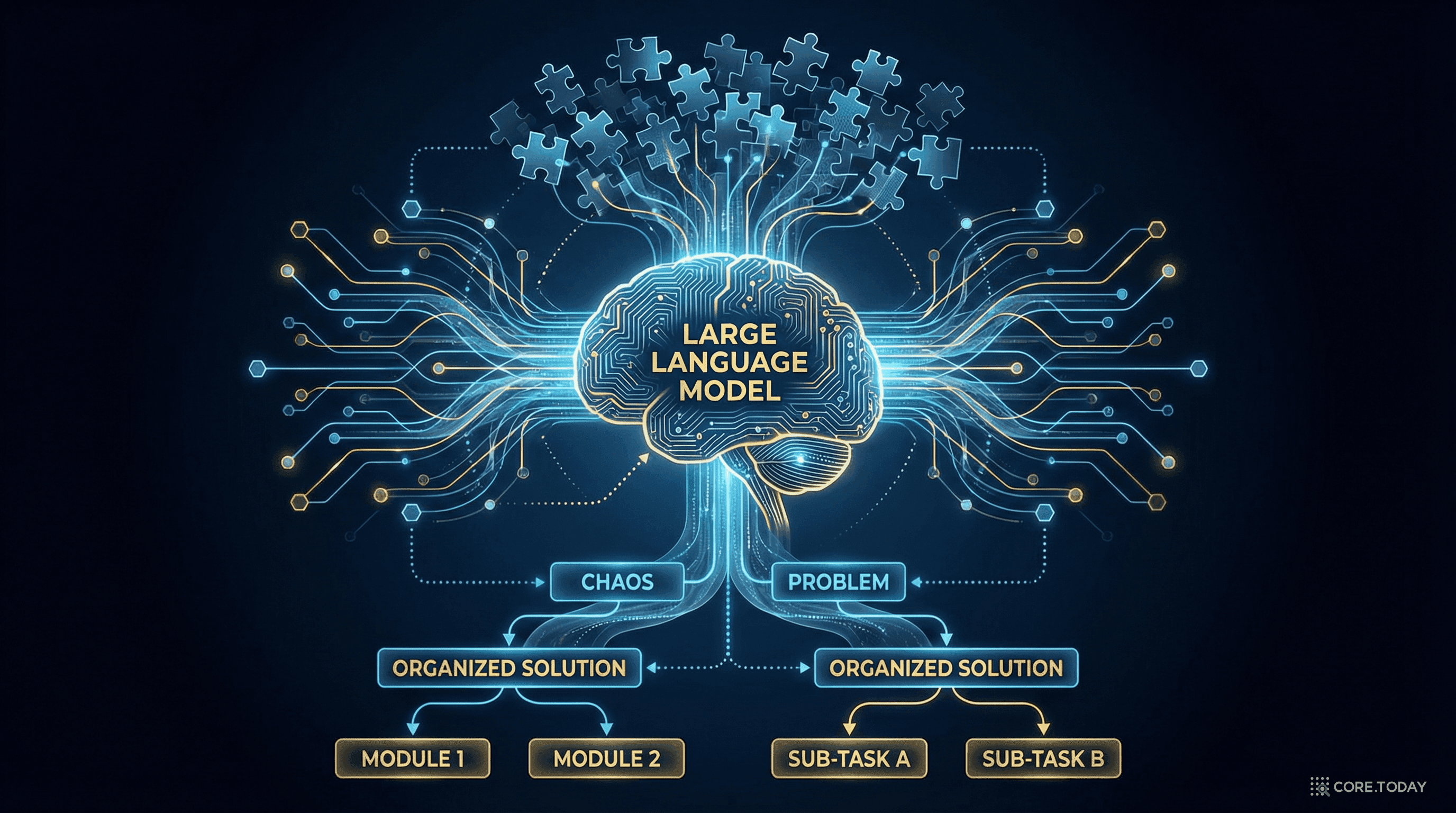
2024년, Microsoft가 GraphRAG를 오픈소스로 공개하며 온톨로지와 LLM의 결합이 본격화되었다. 기존 RAG(Retrieval-Augmented Generation)가 비구조화된 텍스트 청크를 검색하는 데 그친다면, GraphRAG는 지식 그래프의 구조화된 관계를 활용해 더 정확하고 맥락 있는 답변을 생성한다.
이것은 온톨로지의 역사에서 결정적 전환점이다. 2,400년간 온톨로지의 핵심 가치는 "세계를 구조적으로 이해하는 것"이었다. LLM은 자연어를 놀랍도록 잘 처리하지만, 구조적 추론에서는 한계가 있다. 온톨로지는 LLM이 가장 취약한 지점을 정확히 보완한다.
아리스토텔레스가 Palantir Foundry의 온톨로지 화면을 봤다면 무슨 생각을 했을까? 아마 놀랍도록 친숙하다고 느꼈을 것이다.
2,400년의 시간을 두고, "존재란 무엇인가"라는 철학적 질문이 "데이터를 어떻게 의미 있게 조직하고 그 위에서 행동할 것인가"라는 공학적 질문으로 변환되었다. 그러나 근본적 구조는 놀랍도록 유사하다.
온톨로지의 역사가 가르쳐 주는 것은 이것이다: 세계를 이해하려면, 먼저 세계를 분류해야 한다. 파르메니데스가 "존재"를 정의한 이래, 포르피리오스가 나무를 그리고, 그루버가 명세를 작성하고, Palantir가 운영 계층을 구축하기까지 — 그 본질은 변하지 않았다.
LLM이 자연어의 혁명을 가져왔다면, 온톨로지는 구조의 혁명을 가져올 것이다. 그리고 그 두 혁명이 만나는 지점이 바로 지금, 우리가 서 있는 곳이다.