블로그로 돌아가기
PROV-O데이터 프로비넌스W3C시맨틱 웹데이터 리니지AI 거버넌스온톨로지
데이터의 족보를 추적하라: W3C PROV-O 완전 정복
당신이 보는 데이터, 정말 믿을 수 있나요? 2013년 W3C가 발표한 PROV-O는 '데이터의 족보'를 추적하는 국제 표준이다. AI 딥페이크와 가짜뉴스의 시대, 이 13년 된 표준이 왜 지금 가장 뜨거운 기술이 되었는지 추적한다.
코어닷투데이2026-04-0757분
당신이 보는 데이터, 정말 믿을 수 있나요? 2013년 W3C가 발표한 PROV-O는 '데이터의 족보'를 추적하는 국제 표준이다. AI 딥페이크와 가짜뉴스의 시대, 이 13년 된 표준이 왜 지금 가장 뜨거운 기술이 되었는지 추적한다.
2023년 5월, 미국 뉴욕의 한 법정에서 희극적인 사건이 벌어졌다. 변호사 스티븐 슈워츠가 제출한 준비서면에 인용된 판례 6건이 모두 ChatGPT가 만들어낸 가짜였던 것이다. "Varghese v. China Southern Airlines"이라는 그럴듯한 판례명, 정확해 보이는 인용 번호 — 하지만 실제로는 존재하지 않는 판결이었다.
이 사건은 전 세계에 충격을 주었지만, 사실 더 근본적인 질문을 던진다:
"우리가 매일 사용하는 데이터는 어디서 왔고, 누가 만들었고, 어떤 과정을 거쳤는가?"
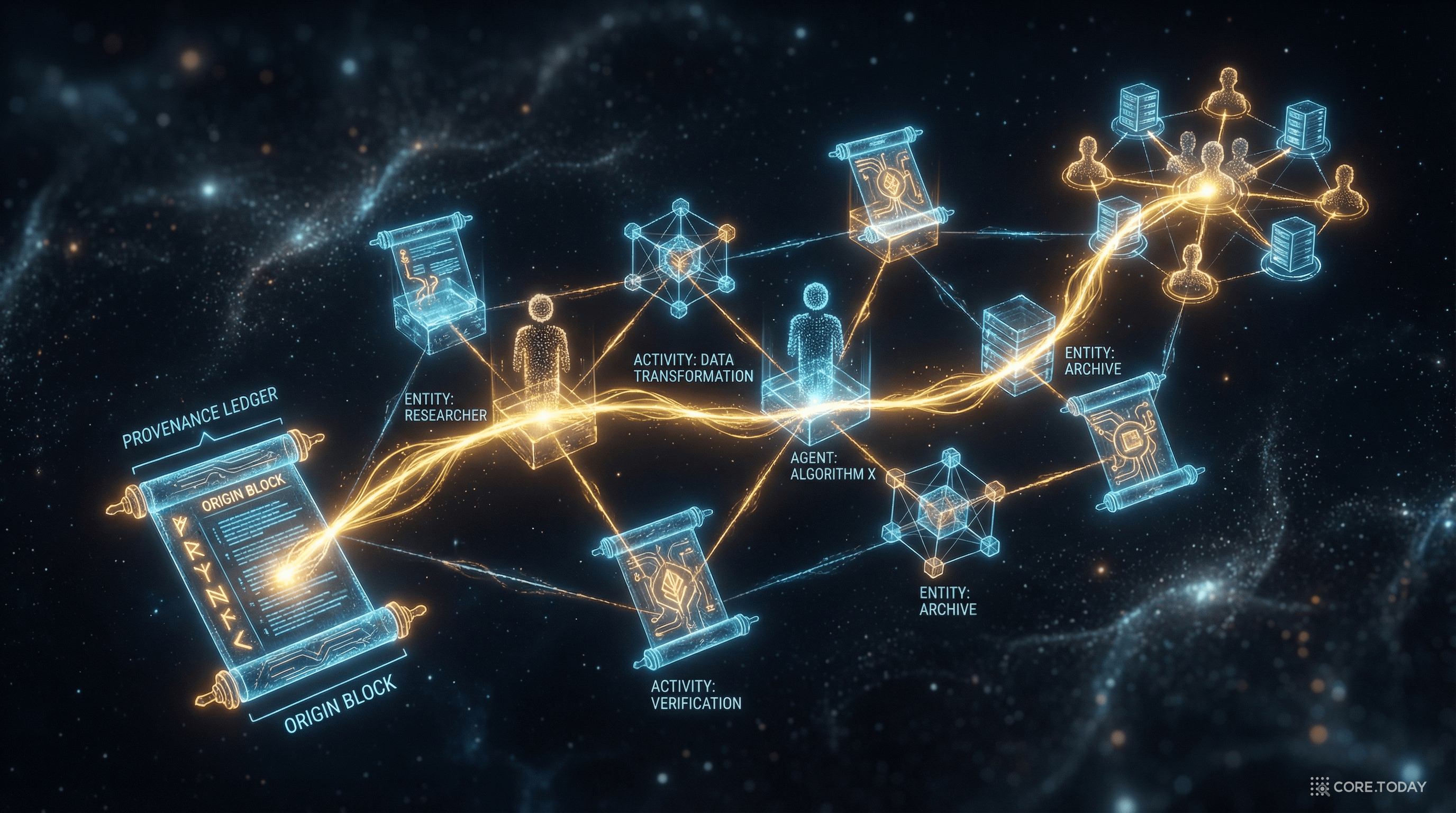
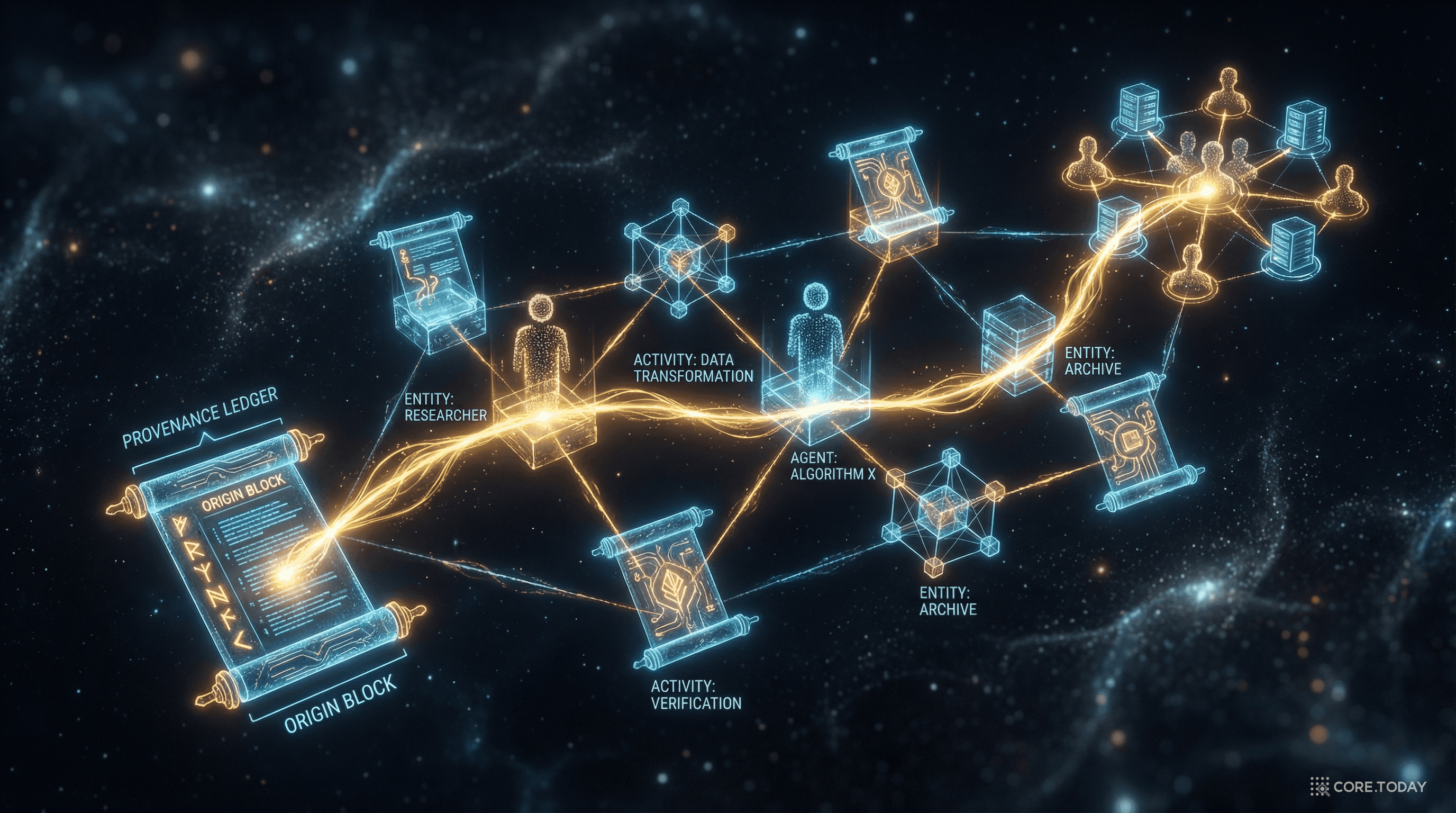
이 질문에 체계적으로 답하려는 시도가 바로 프로비넌스(Provenance) 다. 그리고 W3C가 2013년에 발표한 PROV-O(The PROV Ontology) 는 이 프로비넌스를 웹 전체에서 표현하고 교환하기 위한 국제 표준이다.
2026년 현재, EU AI Act의 데이터 출처 공개 의무화, 딥페이크 범람, AI 학습 데이터 저작권 논쟁이 격화되면서 — 이 13년 된 표준이 갑자기 가장 시의적절한 기술이 되었다. 데이터의 족보를 추적하는 여정을 함께 시작해 보자.
프로비넌스(Provenance) 는 원래 미술사 용어다. 프랑스어 provenir(~에서 오다)에서 유래했으며, 미술품의 소유 이력 — 누가 언제 소유했고, 어떤 경로로 현재 위치에 이르렀는지를 뜻한다.
왜 이것이 중요할까? 한 가지 사례를 보자.
2006년, 잭슨 폴록의 작품으로 추정되는 회화 한 점이 경매에 나왔다. 감정가 1억 4천만 달러. 하지만 소유 이력(프로비넌스)에 공백이 있었다. 1950년대부터 1990년대까지 이 작품이 어디에 있었는지 아무도 증명하지 못했다. 결국 거래는 무산되었다. 작품 자체가 아니라 "이 작품이 진짜라는 증거의 연쇄" 가 끊어졌기 때문이다.
데이터 프로비넌스도 동일한 원리다:
프로비넌스가 데이터 과학에서 핵심 화두가 된 배경에는 재현성 위기(Reproducibility Crisis) 가 있다.
2016년 학술지 Nature의 설문조사에 따르면, 1,576명의 과학자 중 70% 이상이 다른 연구자의 실험을 재현하는 데 실패한 경험이 있었고, 절반 이상이 자신의 실험조차 재현하지 못했다고 답했다. 데이터가 어디서 왔는지, 어떤 전처리를 거쳤는지, 어떤 버전의 코드를 사용했는지 — 이런 프로비넌스 정보의 부재가 핵심 원인 중 하나였다.
출처: Baker, M. "1,500 scientists lift the lid on reproducibility." Nature 533, 452–454 (2016)
2006년 5월, 시카고에서 열린 제1회 IPAW(International Provenance and Annotation Workshop) 에 약 50명의 연구자가 모였다. 이들은 서로 다른 과학 워크플로우 시스템(Taverna, Kepler, VisTrails 등)을 사용하고 있었는데, 공통된 문제에 직면해 있었다:
"우리 시스템의 프로비넌스를 서로 교환할 수 없다."
각 시스템이 저마다 다른 방식으로 프로비넌스를 기록하고 있었기 때문이다. 이 자리에서 탄생한 것이 프로비넌스 챌린지(Provenance Challenge) — 서로 다른 시스템 간 프로비넌스를 교환할 수 있는 공통 모델을 만들자는 도전이었다.
2007년 8월, 솔트레이크시티에서 열린 워크숍에서 OPM(Open Provenance Model) 의 초안이 만들어졌다. 주도한 인물은 사우샘프턴 대학의 Luc Moreau 교수. OPM은 세 가지 핵심 개념을 정의했다:
변하지 않는 데이터 조각
어떤 동작이나 변환
프로세스의 촉매자
OPM은 세 차례의 프로비넌스 챌린지를 거치며 발전했고, v1.1까지 진화했다. 하지만 한계가 있었다 — 웹 환경에서의 상호운용성이 부족했고, 시맨틱 웹 기술과의 통합이 미흡했다.
OPM의 성과를 바탕으로, W3C는 2009년 프로비넌스 인큐베이터 그룹을 결성했다. Yolanda Gil(USC/ISI)이 이끈 이 그룹은 다양한 도메인에서 유스케이스를 수집하고, 기존 프로비넌스 시스템의 현황을 조사했다. 이 조사 결과를 토대로 2011년, W3C 프로비넌스 워킹 그룹이 공식 출범했다.
워킹 그룹의 의장은 Luc Moreau(사우샘프턴 대학)와 Paul Groth(암스테르담 자유대학)가 맡았다. 2013년 4월 30일, PROV 패밀리 문서가 W3C 정식 권고안(Recommendation) 으로 발표되었다. OPM의 Artifact/Process/Agent가 PROV에서는 Entity/Activity/Agent로 재정의되었고, 웹 표준 기술(RDF, OWL)과 완전히 통합되었다.
W3C PROV의 핵심 통찰은 놀라울 정도로 단순하다:
세상의 모든 프로비넌스는 Entity(무엇), Activity(어떻게), Agent(누가)로 설명할 수 있다.
물리적, 디지털, 개념적 — 고정된 측면을 가진 어떤 것
📄 문서, 📊 데이터셋, 🖼️ 이미지, 💊 약물, 🌍 장소
일정 시간 동안 발생하는 행위로, 엔티티를 사용·생성·변환
📝 문서 작성, 🔬 실험 수행, 🖥️ 데이터 분석, 🏭 제조
액티비티의 발생이나 엔티티의 존재에 책임을 지는 주체
👤 사람, 🏢 조직, 🤖 소프트웨어, 🏛️ 기관
PROV-O 스펙에 등장하는 예제를 현실적인 시나리오로 재구성해 보자. 데릭이라는 데이터 분석가가 범죄 통계 기사를 작성하는 과정이다:
이것을 PROV-O의 RDF(Turtle 문법)로 표현하면 이렇게 된다:
@prefix prov: <http://www.w3.org/ns/prov#> .
@prefix ex: <http://example.org/> .
# 엔티티 정의
ex:govCrimeData a prov:Entity .
ex:crimeChart a prov:Entity .
ex:article-v1 a prov:Entity .
# 액티비티 정의
ex:dataAnalysis a prov:Activity ;
prov:used ex:govCrimeData ;
prov:startedAtTime "2026-03-01T09:00:00"^^xsd:dateTime ;
prov:endedAtTime "2026-03-01T17:00:00"^^xsd:dateTime .
# 생성 관계
ex:crimeChart prov:wasGeneratedBy ex:dataAnalysis .
ex:article-v1 prov:wasDerivedFrom ex:crimeChart .
# 에이전트와 책임
ex:derek a prov:Person .
ex:dataAnalysis prov:wasAssociatedWith ex:derek .
ex:article-v1 prov:wasAttributedTo ex:derek .
Entity, Activity, Agent를 연결하는 관계(property)는 총 7가지다. PROV-O는 이것을 Starting Point Terms(출발점 용어) 라 부른다:
| 관계 | 방향 | 의미 | 예시 |
|---|---|---|---|
wasGeneratedBy | Entity → Activity | ~에 의해 생성됨 | 보고서가 분석 작업으로 생성됨 |
used | Activity → Entity | ~을 사용함 | 분석 작업이 원본 데이터를 사용함 |
wasDerivedFrom | Entity → Entity | ~에서 파생됨 | 차트가 원본 데이터에서 파생됨 |
wasAttributedTo | Entity → Agent | ~에 귀속됨 | 보고서가 데릭에게 귀속됨 |
wasAssociatedWith | Activity → Agent | ~와 연관됨 | 분석 작업이 데릭과 연관됨 |
actedOnBehalfOf | Agent → Agent | ~를 대신하여 행동 | 데릭이 신문사를 대신하여 행동 |
wasInformedBy | Activity → Activity | ~로부터 정보를 받음 | 편집 작업이 분석 작업의 정보를 받음 |
이 7가지 관계만으로도 대부분의 프로비넌스를 표현할 수 있다. PROV-O 스펙이 이것을 "Starting Point"라 부르는 이유다 — 여기서 시작하면 80%는 해결된다.
아래 인터랙티브 도구로 Entity, Activity, Agent를 추가하고 관계를 연결해 보자. 프리셋 예제로 시작하거나 직접 처음부터 만들 수 있다:
PROV-O의 가장 영리한 설계 결정 중 하나는 3단계 점진적 학습 구조다. 마치 게임의 난이도 선택처럼, 필요한 만큼만 깊이 들어갈 수 있다:
Level 2에서는 세 주인공의 하위 유형과 파생의 세부 구분이 추가된다:
Agent의 하위 유형:
👤 사람
🏢 조직
🤖 소프트웨어
Entity의 하위 유형:
📦 엔티티들의 구조화된 모음
📋 프로비넌스 기술의 이름 붙은 집합
(프로비넌스의 프로비넌스!)
📐 목표 달성을 위한 행동 집합
파생(Derivation)의 세부 유형:
| 관계 | 의미 | 예시 |
|---|---|---|
wasQuotedFrom | 인용 — 원본의 일부를 가져옴 | 블로그 글이 논문의 한 문단을 인용 |
wasRevisionOf | 개정 — 실질적 내용을 이어받은 새 버전 | 기사 v2가 기사 v1의 오타를 수정한 개정판 |
hadPrimarySource | 원본 출처 — 직접 경험/지식에서 나온 소스 | 기사가 정부 공식 통계를 원본 출처로 함 |
특히 prov:Bundle 은 독특한 개념이다. 프로비넌스 정보 자체도 하나의 엔티티이므로, 프로비넌스의 프로비넌스를 기록할 수 있다. "이 출처 기록은 누가, 언제 작성했는가?"까지 추적할 수 있다는 뜻이다.
Level 1에서 "분석 작업이 원본 데이터를 사용했다(used)"고 했다. 그런데 현실에서는 더 많은 정보가 필요하다:
이때 등장하는 것이 Qualification Pattern(한정 패턴) 이다. 단순한 2자(binary) 관계 사이에 중간 클래스를 끼워 넣어 추가 정보를 달 수 있게 한다:
Turtle로 표현하면:
ex:dataAnalysis a prov:Activity ;
prov:qualifiedUsage [
a prov:Usage ;
prov:entity ex:govCrimeData ;
prov:atTime "2026-03-01T09:15:00"^^xsd:dateTime ;
prov:hadRole ex:primaryInput
] .
이 패턴은 모든 관계에 적용된다. 각 관계에 대응하는 Qualified 클래스가 있다:
| 단순 관계 | Qualified 클래스 | 추가 가능한 정보 |
|---|---|---|
used | Usage | 시점, 역할 |
wasGeneratedBy | Generation | 시점, 위치 |
wasDerivedFrom | Derivation | 사용된 Usage, Generation, Activity |
wasAssociatedWith | Association | 역할(hadRole), 계획(hadPlan) |
wasAttributedTo | Attribution | 에이전트의 역할 |
actedOnBehalfOf | Delegation | 위임의 맥락, 관련 Activity |
wasInformedBy | Communication | 정보 전달의 세부사항 |
이 3단계 설계의 핵심 철학은 "단순함에서 시작하되, 필요할 때 깊이 들어갈 수 있다" 는 것이다. Level 1만 써도 대부분의 프로비넌스를 기록할 수 있고, 정밀한 추적이 필요한 도메인에서는 Level 3까지 활용하면 된다.
PROV-O는 혼자 존재하지 않는다. PROV 패밀리라 불리는 11개 문서 세트의 일부다:
핵심 데이터 모델
모든 직렬화의 기반
OWL2 온톨로지
→ RDF/링크드 데이터
XML 스키마
→ XML 환경
사람이 읽을 수 있는 표기법
→ 예제/문서화
유효성 검증 규칙
형식 의미론 (1차 논리)
프로비넌스 접근/검색
핵심 포인트: PROV-O가 특별한 이유는 시맨틱 웹(RDF/OWL) 기술을 기반으로 하기 때문에, 프로비넌스를 웹 전체에서 링크하고 질의할 수 있는 표준이라는 것이다. 지식 그래프, SPARQL 질의, 링크드 데이터 생태계와 자연스럽게 통합된다.
2026년 현재 가장 뜨거운 이슈 — AI 모델의 학습 데이터 출처 문제를 PROV-O로 모델링해 보자.
이 모델이 있으면 "이 LLM의 학습 데이터에 저작권 침해 콘텐츠가 포함되었는가?" 같은 질문에 체계적으로 답할 수 있다.
@prefix prov: <http://www.w3.org/ns/prov#> .
@prefix food: <http://example.org/food/> .
# 농장에서 식탁까지
food:organicTomatoes a prov:Entity ;
prov:wasGeneratedBy food:harvesting ;
prov:wasAttributedTo food:farmJeju ;
prov:generatedAtTime "2026-03-15"^^xsd:date .
food:harvesting a prov:Activity ;
prov:wasAssociatedWith food:farmerKim ;
prov:atLocation food:jejuFarm .
food:tomatoSauce a prov:Entity ;
prov:wasDerivedFrom food:organicTomatoes ;
prov:wasGeneratedBy food:sauceProduction .
food:sauceProduction a prov:Activity ;
prov:used food:organicTomatoes ;
prov:wasAssociatedWith food:factorySeoul .
월마트는 IBM과 협력하여 블록체인 기반 식품 추적 시스템을 구축했다. 망고의 농장-소비자 이동 경로를 추적하는 데 기존 7일이 걸리던 것이 2.2초로 단축되었다. 이것이 바로 프로비넌스의 힘이다.
가짜뉴스 확산 경로도 PROV-O로 모델링할 수 있다:
hadPrimarySource로 원본까지 거슬러 올라가 대조할 수 있다. 정보의 변형 과정 자체가 투명해지는 것이다.
2026년 8월 시행 예정인 EU AI Act는 고위험 AI 시스템에 대해 다음을 의무화한다:
| 요구사항 | PROV-O 대응 |
|---|---|
| 학습 데이터의 출처·범위·특성 문서화 | Entity(데이터셋) + wasGeneratedBy + hadPrimarySource |
| 데이터 획득·선별 방법 기록 | Activity(수집·정제) + used + wasAssociatedWith |
| 학습 데이터 출처 공개 요약본 발행 | Bundle(프로비넌스 기술의 집합) + wasAttributedTo(발행자) |
| AI 생성 콘텐츠의 기계 판독 가능한 출처 표시 | Entity + wasGeneratedBy(AI Activity) + wasAssociatedWith(SoftwareAgent) |
C2PA(Coalition for Content Provenance and Authenticity) 는 Adobe, Microsoft, Google, OpenAI 등이 참여하는 디지털 콘텐츠 출처 인증 표준이다. 2025~2026년 주요 진전:
C2PA는 PROV 모델과 직접적으로 연결되지는 않지만, 같은 철학을 공유한다: "이 콘텐츠가 어디서 왔고, 어떤 과정을 거쳤는가를 기록하자."
2026년의 AI는 단순한 질의응답을 넘어 에이전트(Agent) 로 진화하고 있다. AI 에이전트는 여러 단계의 의사결정을 자율적으로 수행한다. 이때 전통적 데이터 리니지는 "이 소스에 접근했다"만 기록하지만, 에이전트 리니지는 "에이전트가 소스 Z에서 Y를 발견했기 때문에 소스 X에 접근하기로 결정했다"까지 추적한다.
PROV-O의 Entity-Activity-Agent 모델은 이 에이전트 의사결정 체인을 표현하기에 적합하다:
PROV-O는 OWL2 기반 온톨로지이기 때문에, 지식 그래프(Knowledge Graph) 와 자연스럽게 결합한다. 이것이 PROV-O가 JSON이나 XML 기반 프로비넌스 표현보다 강력한 이유다.
PROV-O 데이터를 트리플스토어에 저장하면 SPARQL로 강력한 질의가 가능하다:
# "이 데이터셋의 원본 출처가 무엇인가?"
SELECT ?source ?sourceTime
WHERE {
ex:myDataset prov:wasDerivedFrom+ ?source .
?source prov:generatedAtTime ?sourceTime .
FILTER NOT EXISTS { ?source prov:wasDerivedFrom ?deeper }
}
# "김철수가 관여한 모든 데이터의 파생물은?"
SELECT ?entity ?derived
WHERE {
?activity prov:wasAssociatedWith ex:kimCS .
?entity prov:wasGeneratedBy ?activity .
?derived prov:wasDerivedFrom+ ?entity .
}
PROV-O는 확장을 위해 설계되었다. 어떤 도메인이든 PROV-O 클래스를 상속받아 특화할 수 있다:
# 생명과학 도메인 확장 예시
bio:Experiment rdfs:subClassOf prov:Activity .
bio:Sample rdfs:subClassOf prov:Entity .
bio:Researcher rdfs:subClassOf prov:Person .
bio:Laboratory rdfs:subClassOf prov:Organization .
bio:experiment001 a bio:Experiment ;
prov:used bio:bloodSample42 ;
prov:wasAssociatedWith bio:drPark ;
bio:protocol bio:pcr-v3 ;
bio:temperature "37.0"^^xsd:decimal .
이미 바이오메디컬, 지구과학, 디지털 인문학 등 다양한 분야에서 PROV-O 기반 확장 온톨로지가 활발히 사용되고 있다.
프로비넌스의 가장 큰 약점은 "프로비넌스 기록 자체를 위변조할 수 있다" 는 점이다. 아무리 정밀하게 출처를 기록해도, 그 기록이 조작되면 의미가 없다.
여기서 블록체인이 등장한다. W3C PROV 모델을 블록체인에 통합하여 변조 불가능한 프로비넌스를 구현하는 연구가 활발히 진행되고 있다.
실제 적용 사례:
지금까지 배운 개념을 직접 적용해 보자. 이 블로그 글 자체의 프로비넌스를 PROV-O로 기록해 본다:
@prefix prov: <http://www.w3.org/ns/prov#> .
@prefix blog: <https://coredot.today/blog/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
# 이 블로그 글의 프로비넌스
blog:prov-o-article a prov:Entity ;
prov:wasGeneratedBy blog:articleWriting ;
prov:wasAttributedTo blog:coredotToday ;
prov:generatedAtTime "2026-04-07"^^xsd:date ;
prov:wasDerivedFrom blog:w3cProvSpec ;
prov:wasDerivedFrom blog:provChallengePapers ;
prov:wasDerivedFrom blog:euAiActDocs .
# 원본 출처들
blog:w3cProvSpec a prov:Entity ;
prov:wasAttributedTo blog:w3cProvWG ;
prov:generatedAtTime "2013-04-30"^^xsd:date .
blog:provChallengePapers a prov:Entity ;
prov:wasAttributedTo blog:lucMoreau .
# 작성 활동
blog:articleWriting a prov:Activity ;
prov:used blog:w3cProvSpec ;
prov:used blog:provChallengePapers ;
prov:used blog:euAiActDocs ;
prov:wasAssociatedWith blog:coredotToday ;
prov:startedAtTime "2026-04-07T21:00:00"^^xsd:dateTime .
# 에이전트들
blog:coredotToday a prov:Organization .
blog:w3cProvWG a prov:Organization .
blog:lucMoreau a prov:Person .
직접 실습할 수 있는 오픈소스 도구들:
| 도구 | 언어 | 특징 |
|---|---|---|
| prov (Python) | Python | PROV-DM 구현, 그래프 시각화, PROV-N/JSON/RDF 변환 |
| ProvToolbox | Java | PROV-O/PROV-N/PROV-XML 간 변환, 검증 |
| PROV Translator | 웹 서비스 | PROV 직렬화 형식 간 변환 (온라인) |
| ProvStore | 웹 서비스 | 프로비넌스 문서 저장·공유·시각화 |
Python으로 프로비넌스 그래프를 만드는 예제:
from prov.model import ProvDocument
from prov.dot import prov_to_dot
# 프로비넌스 문서 생성
doc = ProvDocument()
doc.set_default_namespace('http://example.org/')
# 엔티티, 액티비티, 에이전트 정의
report = doc.entity('report:v1', {'prov:type': 'Report'})
analysis = doc.activity('act:analysis',
'2026-03-01T09:00:00',
'2026-03-01T17:00:00')
derek = doc.agent('agent:derek', {'prov:type': 'prov:Person'})
# 관계 설정
doc.wasGeneratedBy('report:v1', 'act:analysis')
doc.wasAssociatedWith('act:analysis', 'agent:derek')
doc.wasAttributedTo('report:v1', 'agent:derek')
# 시각화
dot = prov_to_dot(doc)
dot.write_png('provenance_graph.png')
W3C PROV-O가 제시하는 비전은 명확하다:
데이터를 신뢰하려면, 데이터의 이력을 알아야 한다.
2013년에 발표된 이 표준은 단순히 "데이터의 족보를 기록하자"는 제안이 아니었다. 그것은 웹 전체에서 통용되는 신뢰의 언어를 만들자는 야심 찬 프로젝트였다. Entity-Activity-Agent라는 놀라울 정도로 단순한 세 가지 개념으로, 미술품의 소유 이력부터 AI 학습 데이터의 출처까지 — 세상의 모든 프로비넌스를 설명할 수 있다.
2026년, 우리는 역사상 가장 많은 데이터와 콘텐츠가 생산되는 시대에 살고 있다. AI가 텍스트, 이미지, 비디오를 쏟아내고, 그중 진짜와 가짜를 구분하기 어려운 시대. EU AI Act가 데이터 출처 공개를 법제화하고, C2PA가 콘텐츠 인증을 표준화하는 이유가 여기 있다.
프로비넌스는 선택이 아니다. 신뢰의 필수 인프라다.
지금까지 배운 내용을 점검해 보자! 8개의 질문으로 PROV-O 핵심 개념을 테스트할 수 있다: