역사적 사건부터 해적 공격까지 — 세상의 모든 '일어난 일'을 컴퓨터가 이해할 수 있게 표현하려면 어떻게 해야 할까? 2011년 탄생한 Simple Event Model(SEM)이 그 해답이다. 왜 이 개념이 필요했고, 2026년 AI 시대에 어떤 의미를 갖는지 깊이 파헤친다.
코어닷투데이2026-04-0748분
들어가며: "무슨 일이 있었는데요"
우리는 매일 사건(Event) 속에서 산다.
"오늘 오전 10시, 서울 코엑스에서 AI 컨퍼런스가 열렸다. 발표자는 김철수 교수였고, 주제는 LLM 안전성이었다."
이 한 문장 안에는 놀라울 정도로 많은 정보가 담겨 있다. 언제(오전 10시), 어디서(코엑스), 누가(김철수 교수), 무엇을(AI 컨퍼런스 발표) 했는지. 인간은 이걸 자연스럽게 이해하지만, 컴퓨터에게는 전혀 다른 이야기다.
구글 캘린더에 저장된 일정은 "장소"와 "시간"은 알지만 "누가 어떤 역할로 참여했는지"는 모른다. 뉴스 기사는 사건을 서술하지만, 같은 사건에 대한 다른 관점을 연결하지 못한다. 위키피디아는 역사적 사건을 설명하지만, 그 사건들 사이의 인과관계를 기계가 추론할 수 있는 형태로 제공하지 않는다.
💡
핵심 질문: 세상에서 일어나는 모든 종류의 사건을 — 역사적 전투부터 해양 해적 공격, 음악 페스티벌부터 자율주행차 사고까지 — 하나의 통일된 방식으로 표현할 수 있을까? 그것도 서로 다른 출처의 데이터가 자유롭게 연결되고 질의될 수 있도록?
바로 이 질문에 답하기 위해 2011년, 네덜란드 암스테르담 자유대학교의 연구진이 Simple Event Model(SEM) 을 만들었다.
1부: 왜 이벤트 모델이 필요해졌을까
웹이 만든 데이터의 바벨탑
2000년대 중반, 웹은 폭발적으로 성장하고 있었다. 하지만 데이터의 양이 늘어날수록 "같은 것을 다르게 말하는" 문제가 심각해졌다.
🔴
문제: 데이터 사일로
역사학자, 뉴스 기자, 해양 안전 기관이 각각 "사건"을 다른 형식으로 기록한다. 서로의 데이터를 연결할 방법이 없다.
🔵
시도: 이벤트 온톨로지들
Event Ontology, LODE, CIDOC-CRM 등 다양한 모델이 등장했지만, 각각 특정 도메인에 치우쳐 있거나 너무 복잡했다.
🟢
해결: SEM
최소한의 의미적 제약으로 최대한의 상호운용성을 달성하는 "심플한" 이벤트 모델이 탄생한다.
시맨틱 웹의 꿈
SEM을 이해하려면 먼저 시맨틱 웹(Semantic Web) 을 알아야 한다. 웹의 아버지 팀 버너스리가 2001년에 제안한 비전이다.
현재 웹은 사람이 읽기 위한 것이다. HTML 문서에 "이순신 장군이 1592년 한산도에서 해전을 벌였다"라고 쓰여 있어도, 컴퓨터는 이것이 사람에 대한 것인지, 장소에 대한 것인지, 사건에 대한 것인지 구분하지 못한다.
시맨틱 웹은 이걸 바꾸려 했다. 데이터에 의미(semantics) 를 부여하여 기계가 추론할 수 있게 만드는 것이다.
1단계
RDF (Resource Description Framework) — 모든 정보를 "주어-술어-목적어" 트리플로 표현한다. 예: (이순신, 참여함, 한산도대첩)
2단계
OWL (Web Ontology Language) — 개념 간의 관계를 정의하는 온톨로지를 만든다. 예: "해전은 군사 행동의 하위 유형이다"
3단계
SPARQL — 이렇게 구조화된 데이터를 질의한다. 예: "16세기에 동아시아에서 일어난 모든 해전을 찾아줘"
목표
Linked Data — 전 세계의 데이터가 하나의 거대한 그래프로 연결된다. DBpedia(위키피디아), GeoNames(지명), WordNet(어휘) 등이 서로 링크된다.
그런데 문제가 있었다. 시맨틱 웹 기술 스택(RDF, OWL, RDFS)은 존재했지만, "사건을 어떻게 표현할 것인가" 에 대한 표준은 여전히 혼란스러운 상태였다.
SEM 이전의 이벤트 모델들
SEM이 등장하기 전에도 여러 이벤트 모델이 있었다. 각각 장단점이 뚜렷했다.
모델
Event Ontology (EO)
LODE
CIDOC-CRM
SEM
탄생 연도
2007
2009
2006 (v5.0)
2011
원래 목적
음악 이벤트
역사/뉴스
박물관 유물
범용
클래스 수
4개
1개
140개
10개
속성 수
17개
6개
144개
~15개
도메인 독립성
✓
✓
△ (박물관 중심)
✓
관점(View) 지원
✗
✗
✗
✓
역할(Role) 지원
✗
✗
✓
✓
시간 제약(Temporal)
✗
✗
✓
✓
OWL 제약 수준
최소
중간
최소
최소
Event Ontology(EO) 는 BBC Music에서 음악 공연을 기록하기 위해 만들어졌다. 심플하지만 역할(Role)이나 관점(View) 개념이 없어서, "같은 사건에 대한 다른 해석"을 담을 수 없었다.
LODE(Linking Open Descriptions of Events) 는 클래스가 Event 단 하나인 극단적 미니멀리즘을 택했다. 가볍지만, 사건의 복잡한 맥락을 표현하기엔 역부족이었다.
CIDOC-CRM 은 정반대로 갔다. 국제 박물관 위원회가 만든 이 모델은 140개 클래스, 144개 속성의 거대한 온톨로지다. 표현력은 뛰어났지만, 학습 곡선이 높고 범용성이 떨어졌다.
SEM은 이 세 모델의 교훈을 종합하여, "충분히 단순하면서도 복잡한 현실을 담을 수 있는" 균형점을 찾았다.
2부: SEM의 핵심 구조 — "누가, 무엇을, 어디서, 언제"
SEM의 설계 철학: 관대한 모델
SEM의 가장 큰 특징은 "최소한의 의미적 약속(minimal semantic commitment)" 이다. 논문의 핵심 문장을 직접 인용하면:
📄 van Hage et al., 2011
"The primary consideration for designing SEM is that it should on the one hand be forgiving for the inherent messiness of the (Semantic) Web, while on the other hand still allowing a user to derive useful facts."
"SEM 설계의 첫 번째 원칙은, 한편으로는 시맨틱 웹의 본질적인 지저분함을 용인하면서도, 다른 한편으로는 사용자가 유용한 사실을 도출할 수 있게 하는 것이다."
이 철학이 왜 혁신적이었을까? 당시 시맨틱 웹 커뮤니티에서는 "더 엄격한 온톨로지가 더 좋은 온톨로지" 라는 믿음이 지배적이었다. 하지만 현실의 웹 데이터는 지저분하고, 불완전하고, 모순적이다. SEM은 이 현실을 인정한 최초의 이벤트 모델 중 하나였다.
SEM의 핵심 설계 원칙들:
이벤트의 정의를 고정하지 않는다 — 아서 왕의 탐험, 로즈웰 UFO 착륙, 조지 W. 부시의 선거 모두 SEM에서 유효한 이벤트다.
disjointness를 최소화한다 — 장소와 행위자를 분리하지 않는다. 지리적 지역이 동시에 통치 기관일 수 있기 때문이다.
카디널리티를 강제하지 않는다 — 한 사람의 생년월일이 여러 개 기록되어도 시스템이 깨지지 않는다.
SKOS 매핑을 사용한다 — 다른 온톨로지와의 연결에 owl:sameAs 대신 느슨한 SKOS 매핑을 쓴다.
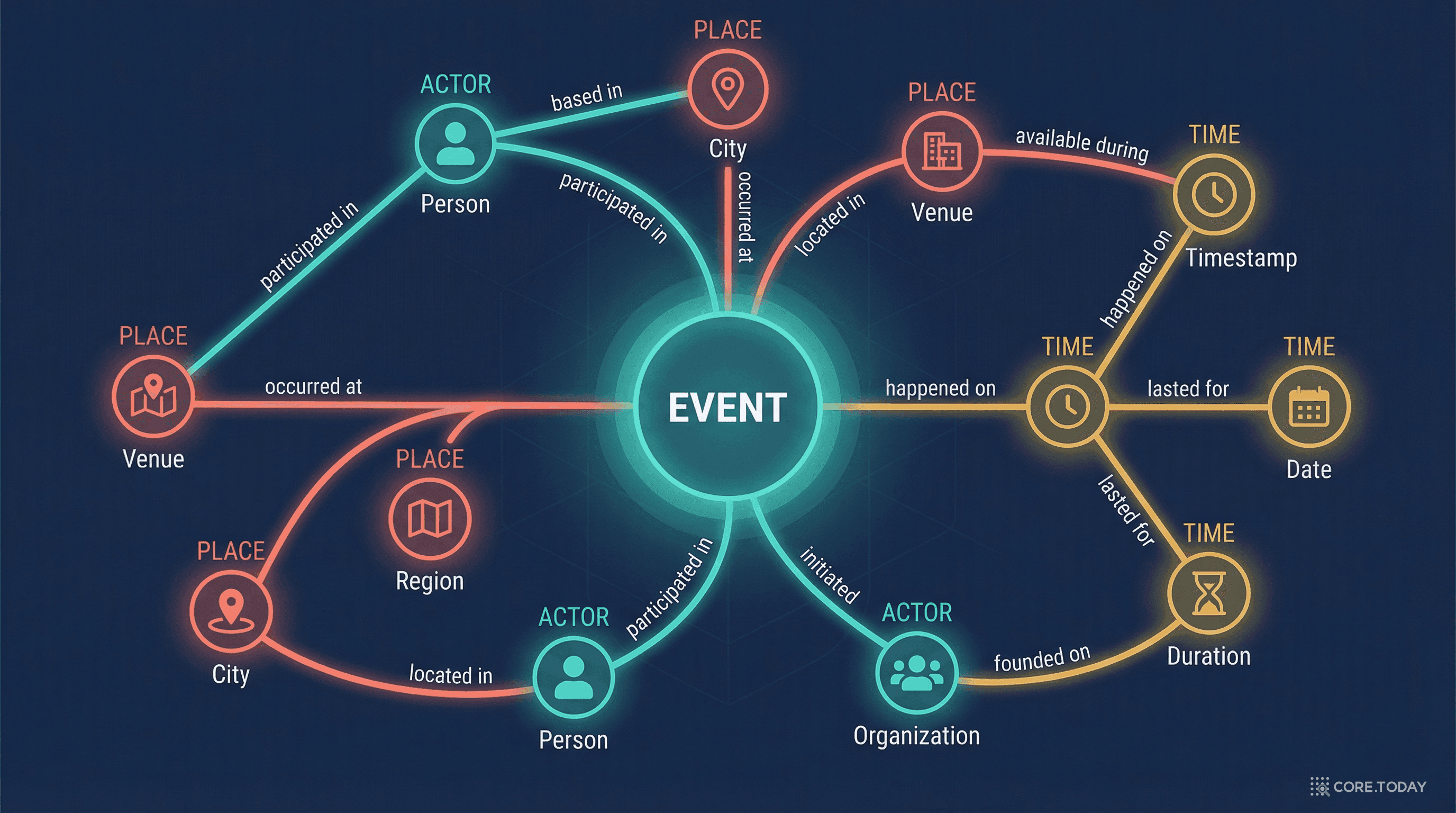
4개의 핵심 클래스
SEM의 구조는 놀라울 정도로 단순하다. 4개의 핵심(Core) 클래스가 전부다.
SEM 핵심 클래스 구조
sem:Event
무엇이 일어났는가
모든 것의 중심. 전쟁, 회의, 해적 공격, 콘서트 등 어떤 종류의 사건이든 표현한다.
sem:Actor
누가 참여했는가
사람, 조직, 국가, 심지어 자연 현상(허리케인)까지. 사건에 참여한 모든 주체.
sem:Place
어디서 일어났는가
상징적 장소(서울, 인도네시아)와 좌표(위도/경도) 모두 표현 가능.
sem:Time
언제 일어났는가
정확한 날짜, 기간, 불확실한 시간 구간(~1945년 이후) 모두 지원.
각 핵심 클래스에는 대응하는 타입 클래스(Type Class) 가 있다:
sem:Event
→
sem:EventType
sem:Actor
→
sem:ActorType
sem:Place
→
sem:PlaceType
sem:Time
→
sem:TimeType
타입 클래스가 별도로 존재하는 이유가 재밌다. 웹에는 수천 가지 어휘(vocabulary)가 존재하고, 각각 "타입"을 다르게 정의한다. SEM은 어떤 어휘의 타입이든 빌려 쓸 수 있도록 유연한 타입 시스템을 제공한다. DBpedia에서 "Police_action"이라는 이벤트 타입을 가져오고, Getty TGN에서 "republic"이라는 장소 타입을 가져와서 조합할 수 있는 것이다.
3부: SEM의 진짜 힘 — 관점(View)과 역할(Role)
SEM이 다른 이벤트 모델과 결정적으로 차별화되는 것은 속성 제약(Property Constraints) 시스템이다. 세 가지 제약이 있다: 역할(Role), 시간 제약(Temporary), 관점(View).
역사 속 논쟁으로 이해하는 SEM
이 개념들을 설명하기 위해, 논문이 사용하는 역사적 예시를 함께 살펴보자.
📜 네덜란드 식민지 역사 — 1947년
"네덜란드는 1947년 네덜란드령 동인도에서 첫 번째 경찰 행동(politionele actie)을 개시했다. 네덜란드는 스스로를 해방자라고 칭했지만, 인도네시아인들에게는 점령자로 여겨졌다."
이 한 문장이 왜 이벤트 모델에게 도전적인지 분석해 보자.
⚔️
도전 1: 역할의 이중성
네덜란드는 "해방자"인가, "점령자"인가? 같은 행위자가 같은 사건에서 정반대의 역할을 가질 수 있다.
🗺️
도전 2: 장소의 정체성
사건이 일어난 곳은 "네덜란드령 동인도"인가, "인도네시아 공화국"인가? 같은 장소의 유형이 관점에 따라 달라진다.
📋
도전 3: 권위의 출처
"해방자"라는 역할은 누구의 주장인가? 네덜란드 정부인가, 인도네시아 국민인가? 출처에 따라 사실이 달라진다.
대부분의 이벤트 모델은 이런 복잡성을 처리할 수 없다. "네덜란드 = 행위자"로 저장하면, 그 역할이 해방자인지 점령자인지 구분할 방법이 없다.
sem:Role — 맥락 속의 역할
sem:Role은 행위자가 특정 사건의 맥락에서 어떤 역할을 하는지를 정의한다.
SEM Role 모델링
1이벤트ex:FirstPoliceAction — 1947년 네덜란드 제1차 경찰 행동
2행위자dbpedia:Netherlands — 네덜란드
3역할 Awordnet:liberator-1 (해방자) — 네덜란드 관점
4역할 Bwordnet:occupier-2 (점령자) — 인도네시아 관점
핵심은 역할이 사건에 묶여 있다는 점이다. 네덜란드라는 국가가 영구적으로 "해방자"나 "점령자"인 것이 아니라, "이 사건의 맥락에서" 그 역할을 가지는 것이다. 다른 사건에서는 완전히 다른 역할을 가질 수 있다.
sem:View — 누구의 이야기인가
sem:View는 SEM에서 가장 독창적인 개념이다. 같은 사실에 대한 서로 다른 관점을 명시적으로 모델링한다.
관점 1
네덜란드 관점 (sem:Authority: dbpedia:Netherlands) 인도네시아의 장소 유형 = "통제 지역(controlled region)" 네덜란드의 역할 = "해방자(liberator)"
관점 2
인도네시아 관점 (sem:Authority: dbpedia:Indonesia) 인도네시아의 장소 유형 = "공화국(republic)" 네덜란드의 역할 = "점령자(occupier)"
sem:Authority는 특정 주장의 출처를 나타낸다. 반드시 행위자일 필요는 없다 — 데이터 소스 자체가 권위(authority)가 될 수도 있다. 이것은 출처 추적(provenance) 과 신뢰 추론(trust reasoning) 의 기반이 된다.
sem:Temporary — 시간이 바꾸는 진실
sem:Temporary는 속성의 시간적 유효 범위를 정의한다.
예를 들어, "인도네시아"라는 장소의 타입은 시간에 따라 달라진다:
1945년 이전
네덜란드령 동인도
PlaceType: "식민지(colony)" — 네덜란드의 통치 하에 있던 지역
1945년
인도네시아 독립 선언
PlaceType이 "공화국(republic)"으로 바뀐다 — 적어도 인도네시아인들의 관점에서는
1949년
국제적 독립 승인
네덜란드도 최종적으로 독립을 인정. 모든 관점에서 PlaceType = "독립 국가"
이것이 바로 sem:Temporary가 해결하는 문제다. 사실은 영원하지 않다. 장소의 성격도, 사람의 직함도, 조직의 상태도 시간에 따라 변한다. SEM은 이런 시간 한정적 진실(time-bounded validity) 을 일급 시민(first-class citizen)으로 다룬다.
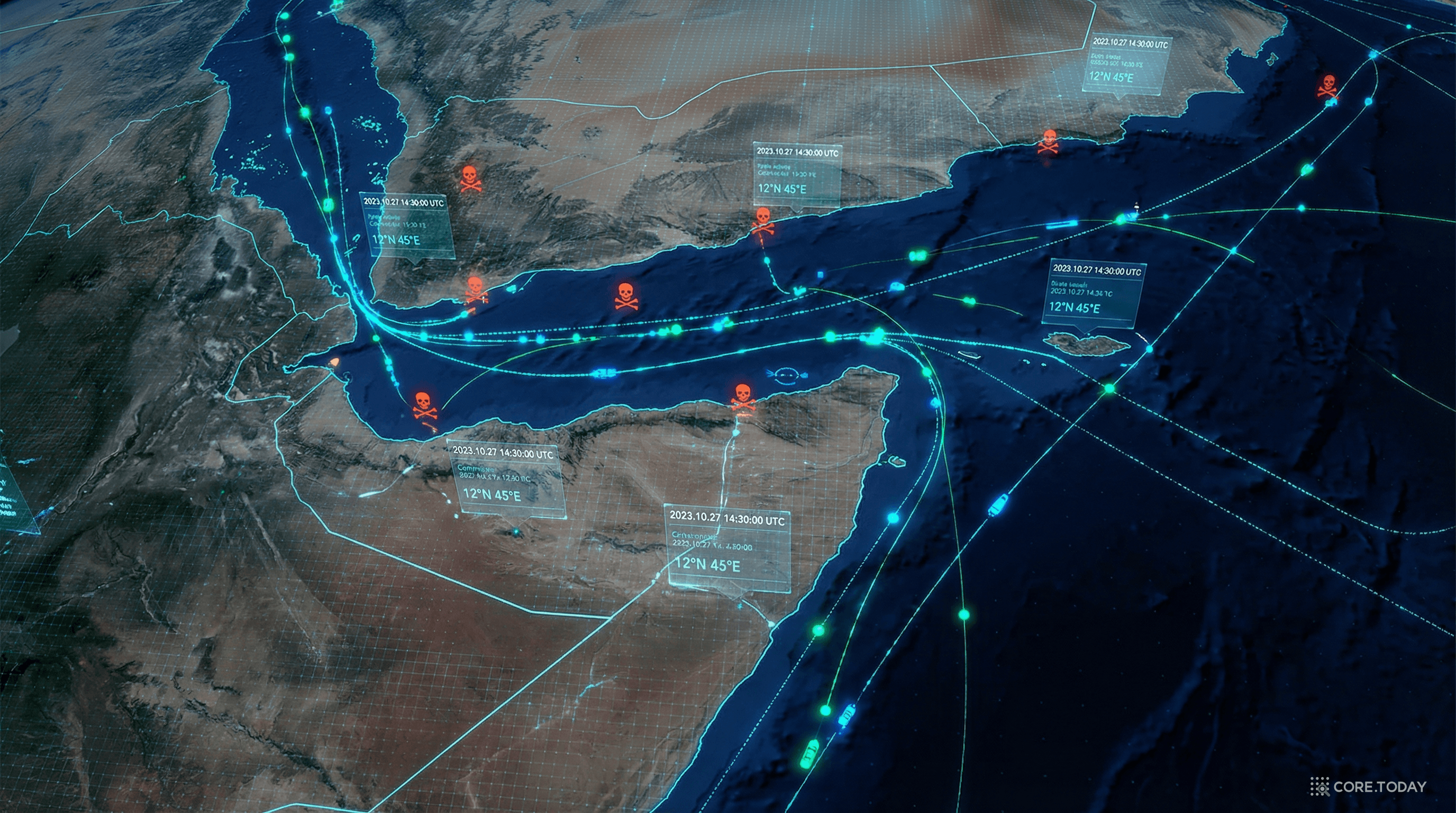
4부: 실전 사례 — 아덴만 해적 추적
SEM의 진가는 실전 적용에서 드러난다. 논문은 두 번째 사례로 소말리아 해적 사건 모델링을 소개한다.
배경: 아덴만의 위기
2006~2009년, 소말리아 해안의 아덴만(Gulf of Aden) 은 세계에서 가장 위험한 해역이었다. 국제상업회의소(ICC-CCS)는 피해 선박이 보고한 모든 해적 공격을 기록하고 있었다.
연구진은 ICC-CCS의 2006~2009년 해적 보고서를 크롤링하고, SEM API를 사용해 RDF로 변환했다. 각 해적 사건은 다음과 같이 구조화되었다:
SEM의 Prolog API는 사용이 놀라울 정도로 간단하다. 위의 해적 사건을 생성하는 코드:
hljs language-prolog
% 이벤트 타입 설정: 납치
assert_event(ex:event_2008_164, ex:hijacked),
% 행위자: 요트형 익명 선박
assert_event_actor(ex:event_2008_164, -, ex:yacht),
% 장소: 좌표와 해상 타입
assert_event_location(ex:event_2008_164,
-, ex:out_at_sea, point(9.5899, 51.635)),
% 시간: ISO 8601 형식
assert_event_time(ex:event_2008_164,
literal(type(xsd:dateTime,
'2008-08-04T03:00+0400Z'))).
이 몇 줄의 코드만으로 완전한 SEM RDF 그래프가 자동 생성된다. API가 모델의 구조를 알아서 처리하기 때문에, 사용자는 SEM의 클래스나 속성 이름을 외울 필요가 없다.
놀라운 발견: 안전 회랑의 역설
이렇게 구조화된 데이터를 SPARQL + 공간 추론으로 분석하자 흥미로운 패턴이 드러났다.
연구진은 Google Earth로 아덴만의 안전 통항 회랑(safety transit corridor) 좌표를 KML 형식으로 만들고, 이것을 SEM 데이터와 결합했다. 그 결과:
기간
MSPA 구역
IRTC 서쪽
IRTC 동쪽
전체 걸프
순찰 회랑
2008.05~08
0
0
0
9 (2)
없음
2008.11~2009.02
19 (3)
1 (0)
0
40 (9)
MSPA
2009.02~04
1 (0)
8 (2)
12 (2)
36 (7)
IRTC
* 괄호 안 숫자는 실제 납치 성공 건수. 출처: van Hage et al., 2011, Table 1
⚠️
역설적 발견: 안전 회랑이 도입된 후, 해적 공격은 오히려 안전 회랑 주변에 집중되었다! 가능한 이유: (1) 해적들이 선박이 회랑을 따라 이동하는 것을 알고 공격을 집중했다. (2) 회랑을 이용하는 선박이 사건을 더 적극적으로 신고했다.
이 발견은 SEM의 공간-시간 통합 추론 능력을 보여주는 강력한 사례다. 이벤트의 좌표, 시간, 유형을 하나의 프레임워크에서 다룰 수 있기 때문에 가능한 분석이었다.
5부: SEM의 건축학 — 세 가지 속성 제약 표현
SEM의 기술적 핵심 중 하나는 속성 제약을 세 가지 방식으로 표현할 수 있다는 점이다. 같은 의미를 다른 기술적 방식으로 표현하되, API가 이들 사이를 투명하게 번역해 준다.
SEM 속성 제약의 3가지 표현 방식
① rdf:value 패턴
기본(Default)
속성에 빈 노드를 넣고, rdf:value로 실제 값을 연결. 측정 단위 표현에 자주 사용.
② rdf:Statement
구문 재현
RDF 트리플 자체를 객체화(reification). 메타데이터를 트리플에 부착할 수 있다.
③ Named Graph
그래프 단위
관련 트리플을 하나의 이름 있는 그래프로 묶어서 메타데이터 부착. 가장 현대적.
이 세 가지 방식은 서로 다른 RDF 스토어와 도구에서 선호되는 패턴이 다르기 때문에 모두 지원된다. SEM API는 어떤 방식이든 통일된 인터페이스로 질의할 수 있게 해준다.
6부: 2026년, SEM이 우리에게 말하는 것
2011년에 발표된 SEM이 2026년인 지금 왜 중요할까?
Knowledge Graph의 르네상스
2023년부터 시작된 AI 붐은 역설적으로 구조화된 지식의 가치를 재확인시켰다. LLM은 놀라운 언어 능력을 보여주지만, 사실의 정확성(factual accuracy) 과 추론의 일관성(reasoning consistency) 에서 한계가 있다.
2024~2026 주요 Knowledge Graph 동향
Microsoft GraphRAG
2024 오픈소스 공개
Palantir 온톨로지
시총 $130B+ 돌파
Google Knowledge Graph
Gemini에 통합
Wikidata + LLM 연동
학계 활발 연구
SEM 기반 이벤트 KG
디지털 인문학·안보에 적용
SEM의 설계 원칙이 AI 시대에 더 빛나는 이유
SEM이 15년 전에 채택한 설계 원칙들은 2026년의 AI 과제와 정확히 맞물린다.
SEM 설계 원칙 (2011)
2026년 AI 과제
왜 관련이 있는가
최소 의미적 약속
멀티모달 데이터 통합
텍스트, 이미지, 센서 데이터를 하나의 프레임워크에 담으려면 유연한 모델이 필수
관점(View) 모델링
AI 환각 검증
LLM의 답변과 출처를 비교 검증하려면, "누구의 주장인가"를 추적할 수 있어야
시간 한정 진실
실시간 지식 업데이트
RAG 시스템에서 "언제까지 유효한 정보인가"를 표현해야 최신성을 보장
Linked Data 연동
에이전트 간 지식 공유
AI 에이전트들이 공통 지식 그래프를 기반으로 협업하려면 표준화된 이벤트 표현 필요
역할(Role) 모델링
복잡한 시나리오 분석
디지털 트윈, 시뮬레이션에서 동일 개체의 맥락별 역할을 구분해야
현대적 적용: 이벤트 중심 지식 그래프
SEM의 정신을 이어받은 현대적 접근들이 여러 분야에서 활약하고 있다.
1. 디지털 인문학 (Digital Humanities)
역사적 사건을 SEM으로 모델링하면, "1945~1950년 동남아시아에서 일어난 모든 독립 운동을 찾아서, 각 운동에 대한 식민 본국의 관점과 독립 운동가의 관점을 비교해 줘"라는 복잡한 질의가 가능해진다.
2. 해양 안보 (Maritime Security)
논문에서 시연한 해적 추적 사례는 지금도 유효하다. 아덴만뿐 아니라, 말라카 해협, 기니만 등 전 세계 해적 위험 지역의 사건을 통합적으로 분석할 수 있다.
3. 뉴스 팩트체크
같은 뉴스 사건에 대한 다양한 보도를 SEM으로 구조화하면, 관점(View) 과 권위(Authority) 시스템으로 "이 주장은 어떤 출처에서 나왔는가"를 체계적으로 추적할 수 있다. LLM + SEM 조합은 자동화된 팩트체크의 유력한 후보다.
4. GraphRAG와의 결합
Microsoft의 GraphRAG가 텍스트에서 지식 그래프를 자동 추출하지만, 추출된 사건들의 구조를 표현하는 데는 아직 표준이 없다. SEM의 이벤트 모델을 GraphRAG 파이프라인에 통합하면, 더 풍부하고 질의 가능한 지식 그래프를 구축할 수 있다.
7부: SEM을 직접 만져보기 — 실습 가이드
SEM을 실제로 사용하려면 어떻게 할까? 논문에서 제공하는 Prolog API의 핵심 패턴을 현대적 관점에서 정리한다.
이벤트 생성 — assert 패턴
hljs language-prolog
% 이벤트 + 행위자 + 행위자 타입을 한 번에 선언
assert_event_actor(
ex:'FirstPoliceAction', % 이벤트
dbpedia:'Netherlands', % 행위자
wordnet:'government-1'). % 행위자 타입
이 한 줄의 Prolog 코드가 실행되면, API가 자동으로:
ex:FirstPoliceAction이 rdf:type sem:Event임을 선언
dbpedia:Netherlands가 rdf:type sem:Actor임을 선언
wordnet:government-1이 rdf:type sem:ActorType임을 선언
sem:hasActor 관계를 생성
sem:actorType 관계를 생성
6개의 RDF 트리플이 자동 생성된다.
이벤트 질의 — query 패턴
hljs language-prolog
% 요트가 관련된 모든 이벤트 찾기
event_actor(Event, Actor, ex:yacht).
% 결과: Event = ex:event_2008_164, Actor = _:anonymous_ship, ...
변수에 값을 넣으면 결과가 제한된다. -로 표시하면 "아무 값이나", _로 시작하면 "관심 없음"을 의미한다.
공간 추론 — space 패턴
hljs language-prolog
% 특정 좌표에서 100km 이내의 모든 이벤트 찾기
event_location(Event, Place, _PlaceType),
space_nearest(Place, point(12.0, 45.0), 100).
% 특정 다각형(안전 회랑) 내부의 이벤트 찾기
event_location(Event, Place, _PlaceType),
space_within_range(Place, polygon(...)).
SEM API는 SWI-Prolog의 space 패키지와 통합되어, 공간 근접성 검색, 범위 내 포함 여부 검사 등의 지리 공간 추론을 지원한다.
맺으며: 단순함의 지혜
SEM의 이름에 "Simple"이 들어간 것은 겸손함이 아니라 의도적 설계다.
💡 SEM의 교훈
"Since it is easier to add statements than to remove them from an ontology, we choose to specify less, rather than more."
"온톨로지에서 문장을 제거하는 것보다 추가하는 것이 쉬우므로, 우리는 더 많이 명시하기보다 더 적게 명시하는 것을 선택한다."
— van Hage et al., 2011
이 원칙은 소프트웨어 엔지니어링의 YAGNI(You Aren't Gonna Need It) 원칙과 놀라울 정도로 닮았다. 그리고 15년이 지난 지금, 이 선택은 옳았음이 증명되고 있다.
지식 그래프가 AI의 핵심 인프라로 부상하는 2026년, SEM이 2011년에 제시한 교훈은 여전히 유효하다:
4
핵심 클래스
Event, Actor, Place, Time
3
속성 제약
Role, Temporary, View
∞
표현 가능한 사건
어떤 도메인이든
0
강제되는 제약
최소 약속 원칙
세상의 모든 사건을 담을 수 있는 그릇은, 역설적으로 가장 단순한 그릇이었다.
📚
원문 논문: Willem Robert van Hage, Véronique Malaisé, Roxane Segers, Laura Hollink, Guus Schreiber. "Design and use of the Simple Event Model (SEM)." Web Semantics: Science, Services and Agents on the World Wide Web, 2011. Vrije Universiteit Amsterdam & Technical University Delft.
SEM RDF 코드:http://semanticweb.cs.vu.nl/2009/11/sem/ SEM API Git:http://eculture.cs.vu.nl/git/poseidon/sem.git