블로그로 돌아가기
LangChainLangGraphGraphRAGNeo4jRAG에이전트
LangChain 완전 가이드: AI 앱의 레고 블록부터 GraphRAG 구축까지
LLM 애플리케이션 개발의 사실상 표준이 된 LangChain — 800줄짜리 사이드 프로젝트에서 유니콘 기업까지의 여정과 핵심 개념을 정리하고, LangChain으로 GraphRAG를 구축하는 실전 패턴을 단계별로 풀어본다.
코어닷투데이2026-03-1030분
LLM 애플리케이션 개발의 사실상 표준이 된 LangChain — 800줄짜리 사이드 프로젝트에서 유니콘 기업까지의 여정과 핵심 개념을 정리하고, LangChain으로 GraphRAG를 구축하는 실전 패턴을 단계별로 풀어본다.

2022년 10월, 해리슨 체이스(Harrison Chase)라는 ML 엔지니어가 퇴근 후 사이드 프로젝트로 800줄짜리 Python 패키지를 만들었다. LLM 개발자 밋업에서 반복적으로 보이는 패턴들 — 프롬프트 관리, LLM 체이닝, 외부 도구 연결 — 을 표준화한 것이었다.
한 달 뒤 ChatGPT가 출시되었다. 전 세계가 LLM에 열광하기 시작했고, 이 800줄짜리 패키지는 LLM 개발자들의 첫 번째 도구가 되었다.
3년이 지난 2025년 10월, 그 패키지는:
이것이 LangChain의 이야기다.
이 글에서는 LangChain이 무엇이고 왜 이렇게 급성장했는지, 핵심 개념은 무엇인지를 먼저 정리한 뒤, LangChain으로 GraphRAG를 구축하는 실전 방법을 다룬다.
LangChain 이전에 LLM 애플리케이션을 만들려면 이런 코드를 매번 처음부터 작성해야 했다:
모든 프로젝트에서 같은 보일러플레이트를 반복하는 것이 문제였다. LangChain은 이 반복되는 패턴을 모듈화하고 표준화하여, 레고 블록처럼 조합할 수 있게 만들었다.
해리슨 체이스의 표현:
"LLM은 위대한 기술이다. 하지만 외부 데이터와 API에 연결될 때 더욱 강력해진다."
LangChain은 이 "연결"을 쉽게 만드는 프레임워크다.
LangChain을 이해하는 데 필요한 핵심 개념을 하나씩 짚어보자.
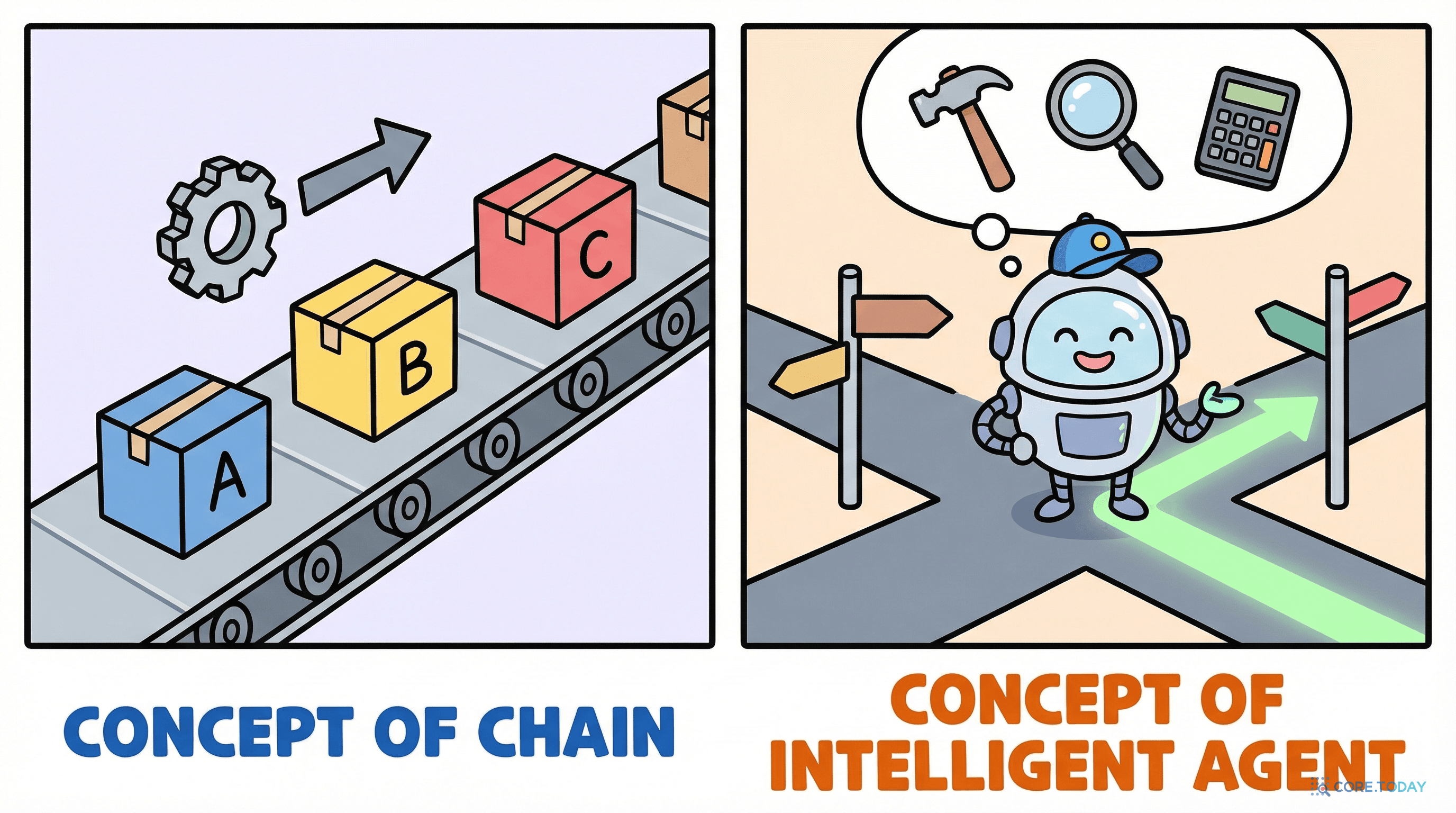
비유하자면:
Chain과 Agent의 차이가 핵심이다. Chain은 미리 정해진 순서대로 실행한다. Agent는 LLM이 실행 중에 다음 행동을 결정한다. 단순한 작업에는 Chain, 복잡하고 동적인 작업에는 Agent를 쓴다.
LangChain의 현대적 작성법은 LCEL(LangChain Expression Language)이다. Python의 파이프 연산자(|)를 활용해 컴포넌트를 연결한다.
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 프롬프트 → LLM → 출력 파서를 파이프로 연결
chain = (
ChatPromptTemplate.from_template(
"다음 주제에 대해 설명해줘: {topic}"
)
| ChatOpenAI(model="gpt-4o")
| StrOutputParser()
)
# 실행
result = chain.invoke({"topic": "GraphRAG"})
RAG 파이프라인도 같은 패턴이다:
from langchain_core.runnables import RunnableParallel
from langchain_core.runnables import RunnablePassthrough
# 검색 + 원래 질문을 병렬로 준비
retrieval = RunnableParallel({
"context": retriever, # 관련 문서 검색
"question": RunnablePassthrough() # 원래 질문 유지
})
# 검색 → 프롬프트 → LLM → 파싱
rag_chain = retrieval | prompt | model | StrOutputParser()
RunnableParallel이 검색과 질문 유지를 동시에 처리하고, 결과를 프롬프트에 주입하여 LLM이 답변을 생성한다. RAG의 전체 파이프라인이 4줄이다.
LangChain은 이제 단일 라이브러리가 아니라 생태계다.
| 제품 | 역할 | 설명 |
|---|---|---|
| LangChain | 고수준 API | 에이전트·체인 구축의 핵심 프레임워크. v1.0 (2025.10) |
| LangGraph | 저수준 오케스트레이션 | 그래프 기반 상태 머신으로 복잡한 에이전트 워크플로 구성. v1.0 |
| LangSmith | 관측·평가 플랫폼 | 트레이싱, 디버깅, 품질 모니터링. 핵심 수익원 |
| Deep Agents | 장시간 에이전트 | 계획 수립, 서브에이전트, 파일시스템 접근. v0.4 (2026.3) |
LangGraph가 특히 중요하다. LangChain의 Chain이 "직선 파이프라인"이라면, LangGraph는 "분기·루프·조건이 있는 그래프"다.
에이전트가 "검색 결과가 충분한가?" → 불충분하면 다시 검색 → 충분하면 답변 생성 — 이런 자기 수정 루프를 LangGraph로 구현한다. Agentic RAG의 핵심 기반이다.
주요 기업 사용: Uber, LinkedIn, Klarna, J.P. Morgan, BlackRock, Cisco, Workday, Snowflake
주요 수치: 110K+ GitHub 스타, 월 9,000만 다운로드, 4,000+ 오픈소스 기여자, 750+ 통합
시리즈 B (2025년 10월): IVP 주도로 $125M 투자, 기업 가치 $1.25B (유니콘 달성)
LangChain이 완벽한 것은 아니다. 커뮤니티에서 반복되는 비판이 있다:
"과도한 추상화" — 가장 흔한 비판. 레이어가 너무 많아서 내부에서 무슨 일이 벌어지는지 파악하기 어렵다는 것. AI 테스트 스타트업 Octomind는 2024년에 LangChain을 제거하고 "그냥 코딩"했더니 생산성이 크게 올랐다고 보고했다.
"단순한 일에는 과잉" — 2025~2026년, 많은 개발자들이 단순 RAG 앱에는 OpenAI/Anthropic SDK를 직접 쓰는 것을 선호한다.
"잦은 API 변경" — v0.1 → v0.2 → v0.3 → v1.0 각각에서 상당한 deprecation이 있어 프로덕션 코드 유지가 어려웠다.
LangChain의 대응 — v1.0에서 "잘 작동하는 것은 보존하고, 그렇지 않은 것을 고쳤다"고 공식 발표. 미들웨어 시스템 도입, API 간소화, langchain-classic 패키지로 레거시 분리.
2026년의 현실적 판단: 단순한 RAG 앱이라면 직접 코딩이 더 효율적일 수 있다. 하지만 에이전트, 복잡한 워크플로, 프로덕션 모니터링이 필요한 프로젝트에서는 LangChain + LangGraph + LangSmith 조합이 여전히 가장 성숙한 선택이다.
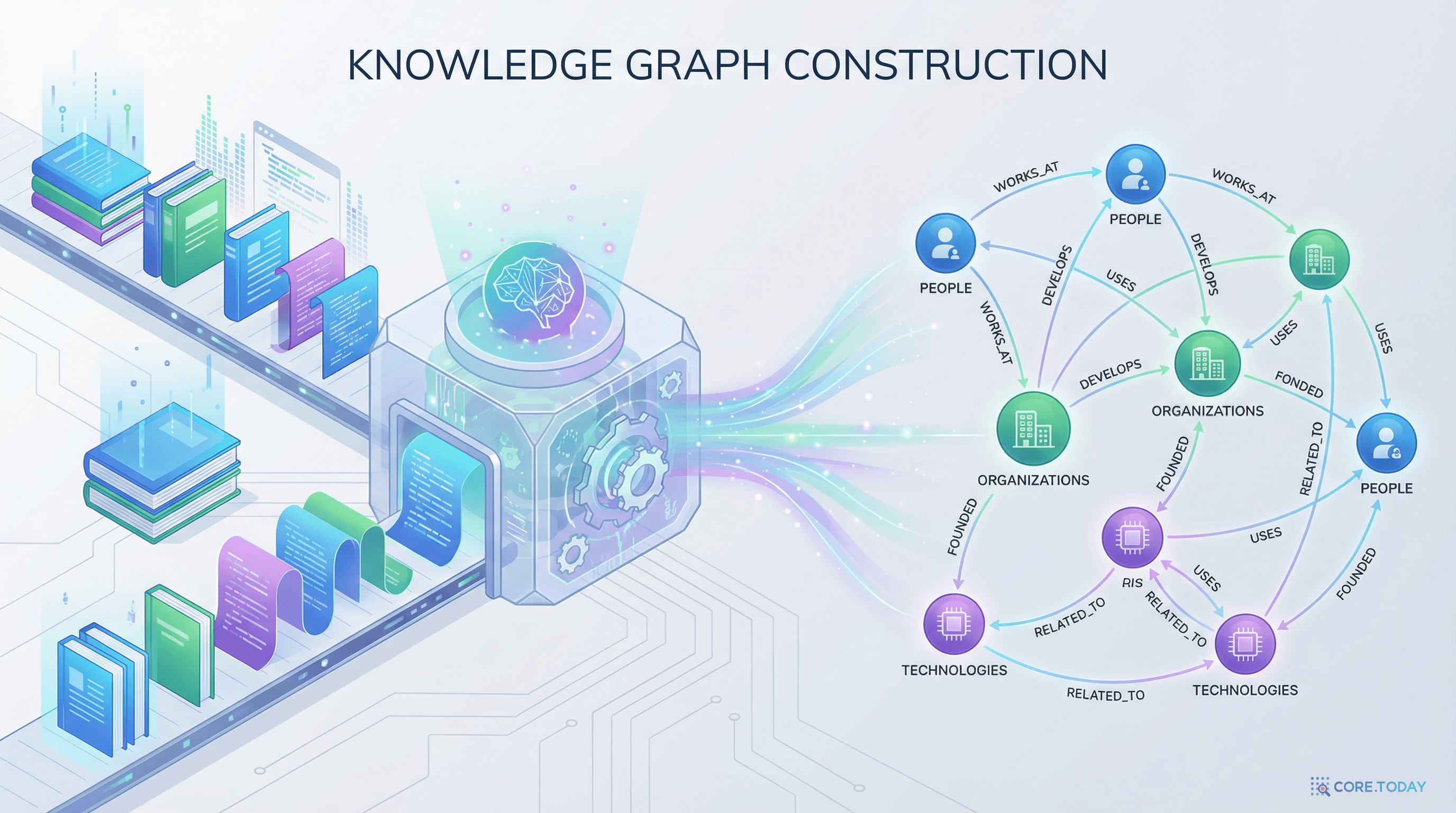
LangChain은 지식 그래프 기반 RAG를 위해 여러 통합을 제공한다. 핵심은 Neo4j 통합(langchain-neo4j v0.8.0)이다.
from langchain_experimental.graph_transformers import (
LLMGraphTransformer
)
from langchain_neo4j import Neo4jGraph
from langchain_openai import ChatOpenAI
# LLM으로 개체·관계 추출기 설정
llm = ChatOpenAI(model="gpt-4o", temperature=0)
transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=[
"Person", "Organization", "Technology"
],
allowed_relationships=[
"WORKS_AT", "DEVELOPS", "COMPETES_WITH"
],
node_properties=["description"],
)
# 문서에서 그래프 문서 생성
graph_documents = transformer.convert_to_graph_documents(
documents
)
# Neo4j에 저장
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True, # 모든 노드에 __Entity__ 라벨
include_source=True # 원본 문서 링크 보존
)
allowed_nodes와 allowed_relationships로 도메인에 맞는 스키마를 지정하면 추출 품질이 크게 향상된다. 이전 글에서 다룬 GraphRAG의 자동 튜닝과 같은 원리다.
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings
# 벡터 검색 인덱스 생성
vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
search_type="hybrid", # 벡터 + 키워드
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding"
)
# 그래프 기반 Cypher 검색
from langchain_neo4j import GraphCypherQAChain
cypher_chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True,
allow_dangerous_requests=True
)
하이브리드 검색의 핵심: Neo4jVector의 벡터 검색은 의미적 유사성을, GraphCypherQAChain의 Cypher 검색은 구조적 관계를 잡아낸다. 2026년 기준 Cypher 생성 정확도는 벤치마크에서 92%에 달한다.

실전에서 가장 효과적인 패턴은 세 가지 검색을 결합하는 것이다:
from langchain_core.runnables import RunnableParallel
# 세 가지 검색을 병렬 실행
hybrid_retriever = RunnableParallel({
"vector_context": vector_store.as_retriever(
search_kwargs={"k": 5}
),
"graph_context": graph_entity_retriever,
"cypher_context": cypher_chain,
"question": RunnablePassthrough()
})
# 결합된 컨텍스트로 답변 생성
graphrag_chain = (
hybrid_retriever
| combine_contexts_prompt
| llm
| StrOutputParser()
)

단순 체인을 넘어, 에이전트가 검색 전략을 동적으로 결정하는 시스템을 LangGraph로 구축할 수 있다.
from langgraph.graph import StateGraph, END
# 에이전트 상태 정의
class GraphRAGState(TypedDict):
question: str
search_mode: str # "vector", "graph", "cypher"
context: list[str]
answer: str
# 워크플로 그래프 구성
workflow = StateGraph(GraphRAGState)
workflow.add_node("classify", classify_question)
workflow.add_node("vector_search", do_vector_search)
workflow.add_node("graph_search", do_graph_search)
workflow.add_node("generate", generate_answer)
workflow.add_node("evaluate", evaluate_quality)
# 조건부 라우팅
workflow.add_conditional_edges(
"classify",
route_by_question_type,
{
"simple": "vector_search",
"relational": "graph_search",
}
)
# 품질 평가 후 재시도 루프
workflow.add_conditional_edges(
"evaluate",
check_quality,
{"sufficient": END, "retry": "graph_search"}
)
이 구조에서 에이전트는:
이것이 이전 글에서 다룬 Agentic RAG의 LangChain 구현이다.
Microsoft의 GraphRAG(microsoft/graphrag)는 독립적인 라이브러리로, LangChain과의 공식 통합은 없다. 하지만 두 가지 접근이 가능하다:
접근 1: 커뮤니티 통합 사용
langchain-graphrag는 GraphRAG 논문의 패턴을 LangChain 컴포넌트로 재구현한 커뮤니티 프로젝트다. Azure OpenAI 외의 LLM도 지원한다.
접근 2: LangChain 네이티브로 구현 (추천)
Microsoft의 라이브러리를 쓰지 않고, LangChain의 컴포넌트로 GraphRAG 패턴을 직접 구축하는 것이 더 유연하다:
LLMGraphTransformer로 개체·관계 추출Neo4jGraph로 지식 그래프 저장GraphCypherQAChain 또는 커스텀 리트리버로 검색| 차원 | LangChain | LlamaIndex |
|---|---|---|
| 빌트인 GraphRAG | 수동 조립 필요 | PropertyGraphIndex로 원클릭 |
| 커뮤니티 탐지 | 외부 라이브러리 (Neo4j GDS) | 빌트인 Leiden 알고리즘 |
| 그래프 DB 지원 | Neo4j, FalkorDB, Memgraph, Spanner | Neo4j, Nebula, Kuzu |
| 에이전트 워크플로 | LangGraph (강력) | Workflows (성장 중) |
| 프로덕션 모니터링 | LangSmith (성숙) | 서드파티 |
| 프레임워크 오버헤드 | ~10ms | ~6ms |
결론: 순수 GraphRAG만 빠르게 구축하려면 LlamaIndex의 PropertyGraphIndex가 더 편리하다. 하지만 GraphRAG를 에이전트 시스템의 일부로 구축하거나, 프로덕션 모니터링까지 필요하다면 LangChain + LangGraph + LangSmith 조합이 더 적합하다.
벡터 검색 기반 RAG 챗봇. LCEL로 파이프라인을 구성하고 LangSmith로 모니터링.
LLMGraphTransformer로 지식 그래프 구축 → Neo4jVector + GraphCypherQAChain으로 하이브리드 검색.
LangGraph로 검색 품질 평가 → 불충분 시 다른 소스 검색 → 충분하면 답변 생성하는 자기 수정 루프 구축.
KET-RAG이나 LightRAG로 비용 효율적 인덱싱 수행, LangChain은 검색·생성 단계의 오케스트레이션에 활용.
LangChain의 핵심 가치는 한 문장으로 요약된다:
LLM을 외부 세계(데이터, 도구, API, 그래프)와 연결하는 표준화된 방법을 제공한다.
GraphRAG 맥락에서 이것은 특히 중요하다. 지식 그래프를 만들고, 벡터 검색과 그래프 탐색을 결합하고, 에이전트가 검색 전략을 동적으로 결정하는 — 이 모든 것을 하나의 일관된 프레임워크 안에서 구축할 수 있다.
물론 모든 프로젝트에 LangChain이 필요한 것은 아니다. 단순한 RAG라면 직접 코딩이 더 빠를 수 있다. 하지만 복잡한 워크플로, 여러 검색 전략의 조합, 프로덕션 모니터링이 필요한 순간 — 그때 LangChain은 가장 성숙하고 넓은 생태계를 가진 선택지다.
참고 자료