들어가며: "분명히 말했는데, 왜 또 물어보는 거야?"
당신은 AI 챗봇과 영화에 대해 이야기하고 있다.
당신: "저는 스릴러 영화를 별로 안 좋아해요. SF 영화를 좋아합니다."
AI: "알겠습니다! 앞으로 SF 영화를 추천해드리겠습니다."
일주일 뒤, 같은 AI에게 다시 묻는다.
당신: "오늘 밤에 영화 볼 건데, 뭐 추천해줘?"
AI: "스릴러 영화는 어떠세요? 몰입감이 좋답니다."
…분명히 싫다고 했는데.

이것이 현재 LLM의 근본적인 한계다. 대화가 끝나면, 모든 것을 잊는다. 컨텍스트 윈도우 안에서는 완벽하게 기억하지만, 세션이 바뀌면 백지 상태로 돌아간다. 마치 금붕어처럼.
"AI가 나의 취향, 습관, 선호도를 기억하게 할 수는 없을까?"
Mem0는 바로 이 문제를 해결하기 위해 탄생한 AI 메모리 레이어다. 그리고 Kuzu는 그 기억을 관계 그래프로 저장하는 임베디드 그래프 데이터베이스다.
이 글에서는 Mem0의 공식 예제 노트북을 기반으로, AI에게 기억을 주는 기술의 원리부터 실전 구현, 그리고 2026년 개인화 AI의 미래까지 종합적으로 다룬다.
📎 이 글은 Mem0 공식 리포지토리의 kuzu-example.ipynb를 기반으로 작성되었다.
1. LLM은 왜 기억하지 못하는가
스테이트리스(Stateless)의 저주
LLM은 본질적으로 무상태(stateless) 시스템이다. 각 API 호출은 독립적이며, 이전 호출의 정보를 보존하지 않는다.
| 인간의 대화 | LLM의 대화 |
|---|
| 단기 기억 | 현재 대화 내용 기억 | ✅ 컨텍스트 윈도우 내에서 가능 |
| 장기 기억 | 지난주 대화 내용 기억 | ❌ 세션 종료 시 소멸 |
| 선호도 학습 | "이 사람은 매운 걸 좋아해" | ❌ 매번 처음부터 시작 |
| 관계 파악 | "이 사람의 아내 이름은 수진" | ❌ 알려줘도 다음에 잊음 |
기존 해결 시도와 한계
이 문제를 해결하기 위한 시도들이 있었다:
1. 대화 이력 전체를 프롬프트에 넣기
hljs language-python
messages = [
previous_conversation_1,
previous_conversation_2,
current_message
]
문제: 대화가 쌓이면 토큰 한도를 초과하고, 비용이 급증한다. 100번의 대화 이력을 매번 보내는 것은 비현실적이다.
2. 대화 요약을 저장하기
각 대화를 요약하여 저장하고, 다음 대화에 요약만 포함. 하지만 요약 과정에서 세부 정보가 손실된다. "SF 영화를 좋아한다"는 기억될 수 있지만, "인터스텔라가 인생 영화"라는 디테일은 사라진다.
3. 벡터 DB에 대화를 저장하기 (RAG)
대화 청크를 벡터화하여 저장하고, 유사한 대화를 검색. 하지만 이전 글에서 살펴봤듯이, 벡터 검색은 관계를 추적하지 못한다. "이 사용자가 SF를 좋아한다"는 사실과 "이 사용자가 스릴러를 싫어한다"는 사실이 서로 다른 청크에 있으면 연결되지 않는다.
❓
핵심 문제
AI에게 필요한 것은 단순한 "저장"이 아니라 "이해하고 구조화된 기억"이다. "사용자 A는 SF를 좋아하고, 스릴러를 싫어하며, 인터스텔라가 인생 영화"라는 관계를 가진 지식이 필요하다.
2. Mem0: AI를 위한 메모리 레이어

Mem0란 무엇인가
Mem0(메모제로, 구 EmbedChain)는 AI 에이전트를 위한 메모리 레이어 오픈소스 프레임워크다. GitHub 스타 25,000개 이상을 달성하며 AI 메모리 분야에서 가장 활발한 프로젝트 중 하나로 자리잡았다.
핵심 아이디어: 대화에서 중요한 사실(fact)과 관계(relation)를 자동으로 추출하여 저장하고, 다음 대화에서 관련 기억을 검색하여 LLM에 제공한다.
대화 메시지
→
Mem0 추출
→
벡터 + 그래프 저장
↕ 다음 대화 시
새 질문
→
Mem0 검색
→
개인화된 답변
Mem0의 역사
| 시점 | 사건 |
|---|
| 2023 | EmbedChain으로 시작 — RAG 파이프라인 자동화 도구 |
| 2024 초 | Mem0로 리브랜딩 — AI 메모리 레이어로 방향 전환 |
| 2024 중 | 그래프 메모리(Graph Memory) 기능 추가 — 관계형 기억 지원 |
| 2024 | 투자 유치, 커뮤니티 급성장 |
| 2025~현재 | Kuzu, Neo4j 등 다양한 그래프 DB 백엔드 지원 |
Mem0의 핵심 원리: 이중 기억 시스템
Mem0가 다른 메모리 솔루션과 근본적으로 다른 점은 두 가지 형태의 기억을 동시에 관리한다는 것이다.
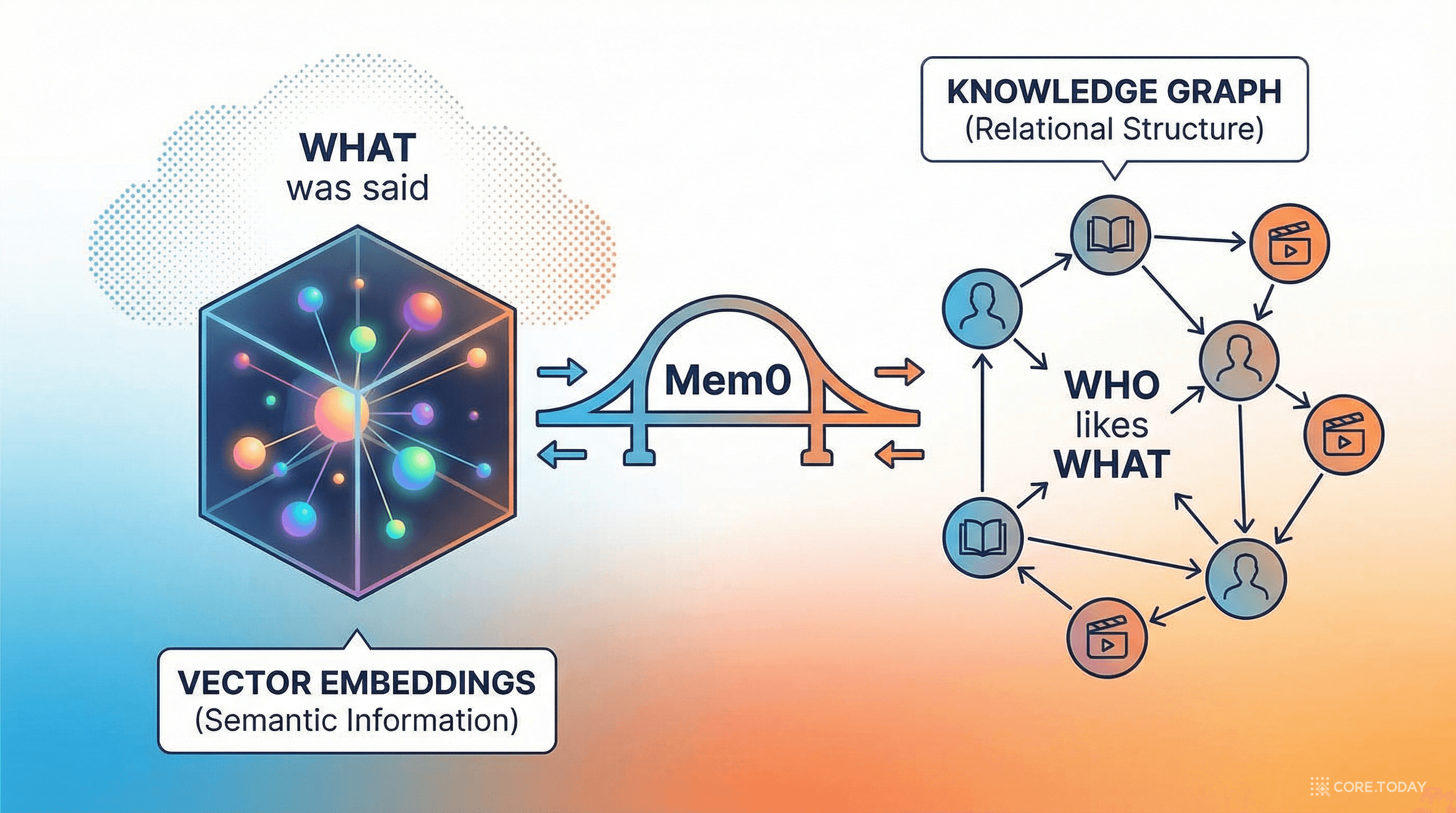
Mem0 이중 기억 시스템
대화에서 두 종류의 기억을 동시 추출
📐 벡터 메모리 (Embeddings)
"무엇을 말했는가"
대화 내용의 의미적 임베딩
유사도 기반 검색
🔗 그래프 메모리 (Relations)
"누가 무엇을 좋아하는가"
엔티티 간 관계 트리플렛
관계 추적 + 멀티홉 추론
벡터 메모리 (Embeddings)
대화 내용을 임베딩 벡터로 변환하여 저장한다. "사용자가 영화에 대해 이야기했다"는 의미적 맥락을 포착한다. 나중에 비슷한 주제의 질문이 들어오면, 유사도 검색으로 관련 기억을 꺼낸다.
그래프 메모리 (Relations)
대화에서 엔티티 간의 관계를 추출하여 그래프로 저장한다:
사용자(myuser) — 좋아한다 → SF 영화
사용자(myuser) — 싫어한다 → 스릴러 영화
사용자(myuser) — 계획 중 → 오늘 밤 영화 관람
이 두 가지를 합치면: 벡터 메모리가 "어떤 맥락의 대화였는지"를 기억하고, 그래프 메모리가 "구체적으로 어떤 관계가 있는지"를 기억한다. 마치 인간이 감각적 기억(분위기, 맥락)과 명시적 기억(사실, 관계)을 동시에 가지는 것과 같다.
3. Kuzu: 설치 없는 그래프 데이터베이스
왜 Kuzu인가
이전 글에서도 언급했듯, Kuzu는 워털루 대학교 Semih Salihoglu 교수 연구실에서 만든 임베디드 그래프 데이터베이스다. SQLite가 관계형 DB의 임베디드 버전이라면, Kuzu는 그래프 DB의 SQLite다.
Mem0 + Kuzu 조합의 핵심 이점:
1
설치 제로
pip install "mem0ai[graph]" 한 줄이면 Kuzu가 함께 설치된다. Neo4j처럼 별도 서버를 띄울 필요가 없다.
2
인메모리 모드
"db": ":memory:"로 설정하면 메모리에서 실행된다. 프로토타이핑에 최적. 디스크 경로를 주면 영구 저장도 가능하다.
3
Cypher 호환
Neo4j의 Cypher 쿼리 언어를 지원하므로, 나중에 프로덕션으로 전환할 때 Neo4j로 쉽게 마이그레이션할 수 있다.
Mem0에서의 설정
hljs language-python
config = {
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-3-large",
"embedding_dims": 1536
},
},
"graph_store": {
"provider": "kuzu",
"config": {
"db": ":memory:",
},
},
}
embedder는 벡터 메모리를 위한 임베딩 모델, graph_store는 그래프 메모리를 위한 그래프 DB를 설정한다. 이 두 줄의 설정이 Mem0의 이중 기억 시스템을 정의한다.
4. 실전 구현: 영화 추천 챗봇

노트북의 데모를 단계별로 살펴보자.
4.1 메모리 저장 (memory.add)
사용자와 AI 사이의 대화를 Mem0에 저장한다:
hljs language-python
from mem0 import Memory
memory = Memory.from_config(config_dict=config)
messages = [
{"role": "user", "content": "I'm planning to watch a movie tonight. Any recommendations?"},
{"role": "assistant", "content": "How about a thriller movie? They can be quite engaging."},
{"role": "user", "content": "I'm not a big fan of thriller movies but I love sci-fi movies."},
{"role": "assistant", "content": "Got it! I'll avoid thriller recommendations and suggest sci-fi movies in the future."}
]
results = memory.add(messages, user_id="myuser", metadata={"category": "movie_recommendations"})
memory.add()를 호출하면, Mem0는 내부적으로 LLM을 사용하여 대화에서 두 가지를 동시에 추출한다:
입력
대화 메시지 4개 (사용자 2개 + 어시스턴트 2개)
추출 1
벡터 메모리(embeddings): "사용자가 SF 영화를 좋아하고 스릴러를 싫어한다"는 사실을 임베딩 벡터로 저장
추출 2
그래프 관계(relations): (myuser) → [좋아한다] → (SF 영화), (myuser) → [싫어한다] → (스릴러 영화) 관계를 Kuzu 그래프에 저장
결과
results 딕셔너리에 results(임베딩)와 relations(그래프 엣지) 모두 포함
결과를 출력하는 헬퍼 함수:
hljs language-python
def print_added_memories(results):
print("::: Saved the following memories:")
print(" embeddings:")
for r in results['results']:
print(" ", r)
print(" relations:")
for k, v in results['relations'].items():
print(" ", k)
for e in v:
print(" ", e)
출력 예시:
embeddings:
• "Plans to watch a movie tonight"
• "Loves sci-fi movies"
• "Dislikes thriller movies"
relations:
added:
• myuser → loves → sci-fi movies
• myuser → dislikes → thriller movies
• myuser → plans_to_watch → movie tonight
핵심: 개발자가 어떤 정보를 추출할지 정의하지 않았다. Mem0가 LLM을 사용하여 대화에서 중요한 사실과 관계를 자동으로 판단하고 추출한 것이다.
4.2 메모리 검색 (memory.search)
저장된 기억 중에서 관련 있는 것을 검색한다:
hljs language-python
results = memory.search("what does the user love?", user_id="myuser")
for result in results["results"]:
print(result["memory"], result["score"])
"사용자가 무엇을 좋아하나요?"라는 질문에, Mem0는 벡터 유사도와 그래프 관계를 모두 활용하여 "Loves sci-fi movies"를 높은 점수로 반환한다.
score는 유사도 점수다. 점수가 낮을수록 더 관련성이 높다 (거리 기반).
4.3 메모리 활용 챗봇
이제 핵심 — 이 기억을 활용하여 개인화된 대화를 하는 챗봇을 만든다:
hljs language-python
def chat_with_memories(message: str, user_id: str = "myuser") -> str:
relevant_memories = memory.search(query=message, user_id=user_id, limit=3)
memories_str = "\n".join(
f"- {entry['memory']}" for entry in relevant_memories["results"]
)
system_prompt = f"""You are a helpful AI. Answer the question based on query and memories.
User Memories:
{memories_str}"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": message}
]
response = openai_client.chat.completions.create(
model="gpt-4.1-nano-2025-04-14",
messages=messages
)
assistant_response = response.choices[0].message.content
messages.append({"role": "assistant", "content": assistant_response})
results = memory.add(messages, user_id=user_id)
return assistant_response
이 코드의 흐름을 시각화하면:
사용자 입력
"오늘 밤에 뭐 볼까?"
기억 검색
- Loves sci-fi movies
- Dislikes thriller movies
- Plans to watch a movie tonight
개인화된 응답
"SF 영화를 좋아하신다고 기억하고 있어요! '인셉션'이나 '어라이벌' 어떠세요? 스릴러는 피할게요."
새 기억 저장
이 대화에서 새로운 사실이 있으면 기억에 추가
핵심 패턴: 검색(Retrieve) → 증강(Augment) → 생성(Generate) → 저장(Store). RAG에 저장(Store) 단계가 추가된 것이다. 대화할수록 기억이 축적되며, 시간이 지날수록 AI는 사용자를 더 잘 이해하게 된다.
5. Mem0의 내부 동작 원리
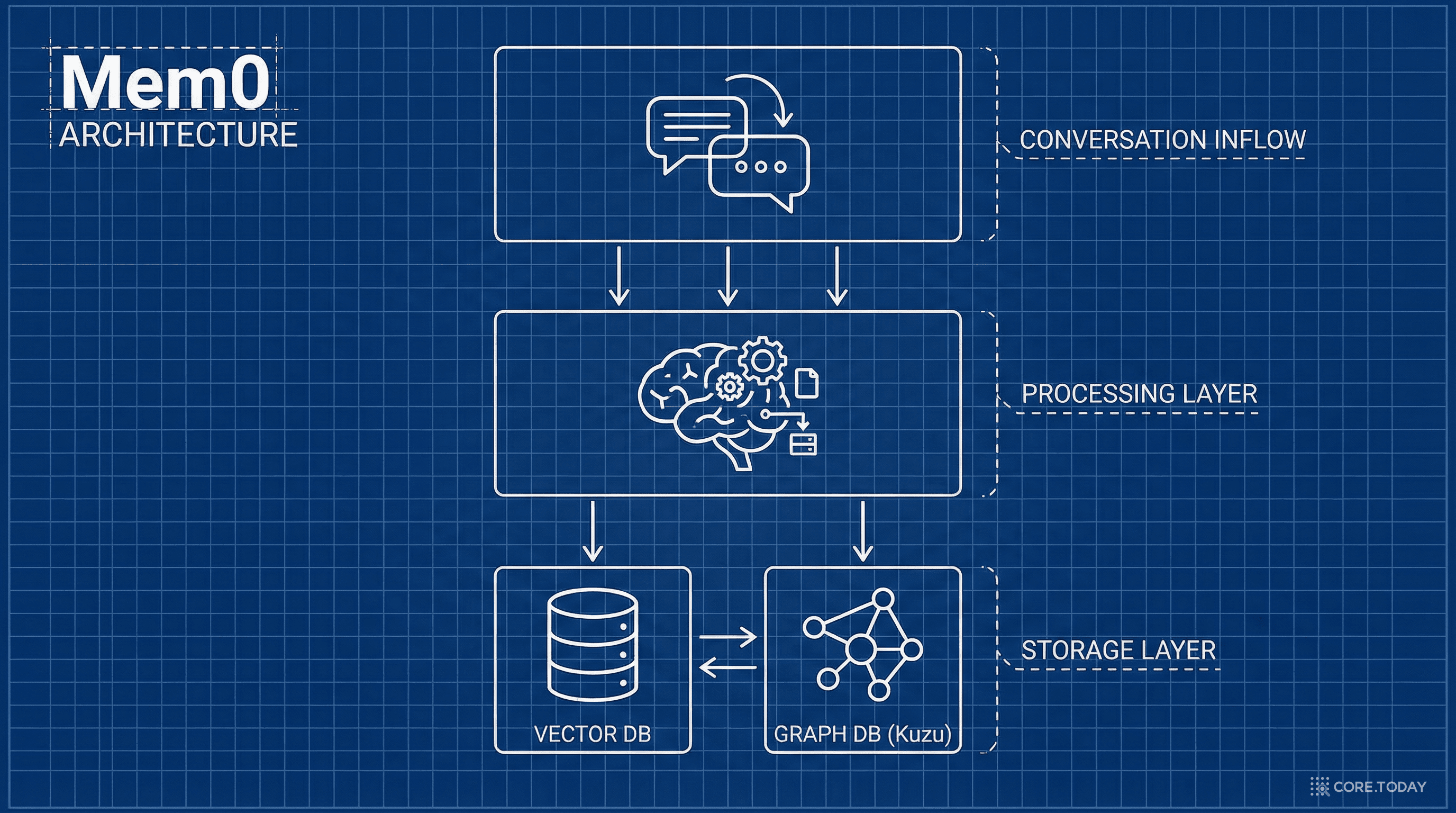
메모리 추출 파이프라인
memory.add()가 호출되면 내부에서 일어나는 일:
Step 1
메시지 분석: LLM이 대화 메시지를 분석하여 "기억할 만한 사실"을 추출. "사용자가 SF를 좋아한다"는 기억할 가치가 있지만, "안녕하세요"는 아니다.
Step 2
임베딩 생성: 추출된 사실을 text-embedding-3-large 모델로 벡터화하여 벡터 DB에 저장 (1,536차원).
Step 3
관계 추출: LLM이 대화에서 (주어, 술어, 목적어) 트리플렛을 추출. "myuser → loves → sci-fi movies".
Step 4
그래프 저장: 추출된 관계를 Kuzu 그래프 DB에 노드와 엣지로 저장.
Step 5
중복 처리: 이미 존재하는 사실은 업데이트하고, 모순되는 정보는 최신으로 갱신.
메모리 검색 파이프라인
memory.search()가 호출되면:
- 쿼리를 벡터로 변환
- 벡터 DB에서 유사한 기억 검색 (코사인 유사도)
- 그래프 DB에서 관련 관계 검색 (엔티티 매칭 + 그래프 탐색)
- 두 결과를 병합하고 점수 기준으로 정렬하여 반환
이 하이브리드 검색이 Mem0의 핵심 강점이다. 벡터 검색은 의미적으로 관련된 기억을, 그래프 검색은 구조적으로 연결된 기억을 가져온다. 둘을 합치면 단일 방식보다 훨씬 정확한 기억 검색이 가능하다.
user_id: 사용자별 기억 격리
hljs language-python
memory.add(messages, user_id="alice")
memory.add(messages, user_id="bob")
memory.search("영화 추천", user_id="alice")
user_id를 통해 사용자별 기억이 완전히 격리된다. 이것은 멀티테넌트 환경에서 필수적이다 — Alice의 취향이 Bob의 검색 결과에 나타나서는 안 된다.
6. 그래프 메모리가 벡터 메모리보다 나은 순간
벡터 메모리만으로 충분한 경우도 있다. 하지만 관계가 중요한 순간에는 그래프 메모리가 빛난다.
| 시나리오 | 벡터 메모리만 | 벡터 + 그래프 메모리 |
|---|
| "사용자가 좋아하는 장르는?" | ✅ 유사도로 찾을 수 있음 | ✅ 관계로 정확히 찾음 |
| "사용자가 싫어하는 것은?" | ⚠️ "좋아한다" 기억과 혼동 가능 | ✅ "싫어한다" 관계를 명확히 구분 |
| "사용자 A와 B의 공통 취향은?" | ❌ 두 사용자 기억을 교차 검색 어려움 | ✅ 그래프에서 공통 노드 탐색 |
| "이 사용자의 아내 이름은?" | ⚠️ 맥락 따라 불안정 | ✅ (사용자) → [배우자] → (수진) |
| "인터스텔라를 좋아하는 사용자는 누구?" | ⚠️ 모든 사용자 기억 전수 검색 | ✅ (인터스텔라) ← [좋아한다] 역방향 탐색 |
특히 부정(negation)의 처리에서 차이가 크다:
📐
벡터 메모리의 한계
"스릴러를 좋아한다"와 "스릴러를 싫어한다"의 임베딩 벡터는 매우 유사하다 — 둘 다 "스릴러"와 "선호도"라는 의미를 공유하기 때문이다. 벡터 유사도만으로는 긍정/부정을 정확히 구분하기 어렵다.
🔗
그래프 메모리의 강점
그래프에서는 (사용자) → [좋아한다] → (SF)와 (사용자) → [싫어한다] → (스릴러)가 완전히 다른 엣지다. 관계 유형이 명시적으로 구분되므로 모호함이 없다.
7. 실전 적용 시나리오
개인화된 AI 비서
가장 직접적인 적용. 사용자의 선호도, 습관, 일정을 기억하여:
- 일정 관리: "지난번에 화요일마다 요가 간다고 했잖아. 이번 화요일도 알림 드릴까요?"
- 업무 보조: "지난 회의에서 김 대리가 데이터 분석 담당이라고 했었어. 이번 보고서도 김 대리에게 요청할까?"
- 건강 관리: "카페인에 민감하다고 하셨죠. 오후 3시 이후 커피 대신 허브티를 추천합니다."
고객 서비스 챗봇
첫 번째 문의
고객: "주문한 노트북이 아직 안 왔어요" → AI: 주문번호 확인, 배송 상태 조회 → 기억 저장: (고객A) → [주문] → (노트북), (주문) → [상태] → (배송 지연)
두 번째 문의
고객: "그거 어떻게 됐어요?" → AI: 기억 검색 → "노트북 배송 건 말씀이시죠? 확인해보니 내일 도착 예정입니다." (맥락을 기억하고 있어 다시 설명할 필요 없음)
세 번째 문의
고객: "추가로 마우스도 하나 사려고요" → AI: 기억 활용 → "노트북과 호환되는 무선 마우스를 추천드릴게요." (이전 구매 기록 기반 추천)
교육 AI 튜터
학생의 학습 이력과 약점을 기억:
- "지난번에 이차방정식에서 판별식 개념을 어려워했었지. 오늘은 판별식을 좀 더 쉽게 설명해볼게."
- "너는 시각적 예시로 설명할 때 더 잘 이해하더라. 그래프를 그려서 보여줄게."
- "지난 3번의 테스트에서 확률 파트 점수가 계속 올라가고 있어! 잘하고 있어."
멀티에이전트 시스템의 공유 메모리
여러 AI 에이전트가 하나의 Mem0 인스턴스를 공유 메모리로 사용:
🎬 영화 추천 에이전트
사용자의 장르 취향 활용
🍕 음식 추천 에이전트
사용자의 음식 취향 활용
📅 일정 관리 에이전트
사용자의 습관 활용
Mem0 공유 메모리
벡터 DB + Kuzu 그래프 DB
사용자의 모든 선호도와 관계를 통합 관리
영화 에이전트가 알아낸 "이 사용자는 SF를 좋아한다"는 정보가, 음식 추천 에이전트에서 "SF 영화관 근처 맛집"을 추천하는 데 활용될 수 있다.
8. Mem0 vs 다른 AI 메모리 솔루션
2026년 AI 메모리 생태계
| | Mem0 | | MemGPT/Letta | | Zep | | Cognee |
|---|
| 핵심 메타포 | 메모리 레이어 | OS 가상 메모리 | 대화 기억 서버 | 인지 엔진 |
| 메모리 형태 | 벡터 + 그래프 | 컨텍스트 계층 | 시간적 기억 | 지식 그래프 |
| 입력 소스 | 대화 메시지 | 대화 메시지 | 대화 메시지 | 문서, 텍스트 |
| 그래프 지원 | ✅ Kuzu, Neo4j | ❌ | ⚠️ 내부적 | ✅ Kuzu, Neo4j |
| 사용자별 격리 | ✅ user_id | ✅ agent별 | ✅ user/session | ⚠️ dataset별 |
| 시간 인식 | ⚠️ 제한적 | ❌ | ✅ 강력 | ❌ |
| 설치 난이도 | 낮음 | 중간 | 중간 (서버) | 낮음 |
| 최적 사용처 | 대화형 개인화 AI | 장기 에이전트 | 시간 순서 중요한 대화 | 문서 지식 구조화 |
선택 가이드
💬
Mem0 — 대화에서 취향을 기억
"사용자가 챗봇과 대화하면서 밝힌 선호도, 습관, 관계를 기억하고 싶다." → Mem0. 가장 빠르게 시작할 수 있고, 그래프 메모리까지 지원한다.
📄
Cognee — 문서를 지식으로 변환
"이력서, 계약서, 보고서 같은
문서에서 지식을 추출하고 싶다." →
Cognee. 문서 중심의 지식 그래프 자동 구축에 최적화.
🤖
MemGPT/Letta — 장기 실행 에이전트
"에이전트가 며칠에 걸쳐 자율적으로 작업하면서 컨텍스트를 유지해야 한다." → Letta. OS 수준의 메모리 관리에 최적화.
9. 시작하기: 5분 만에 기억하는 AI 만들기
설치
hljs language-bash
pip install "mem0ai[graph]"
이 한 줄로 Mem0, Kuzu, 그리고 필요한 모든 의존성이 설치된다.
최소 코드
hljs language-python
import os
from mem0 import Memory
os.environ["OPENAI_API_KEY"] = "your-api-key"
config = {
"embedder": {
"provider": "openai",
"config": {"model": "text-embedding-3-large", "embedding_dims": 1536},
},
"graph_store": {
"provider": "kuzu",
"config": {"db": ":memory:"},
},
}
memory = Memory.from_config(config_dict=config)
memory.add(
[{"role": "user", "content": "나는 SF 영화를 좋아하고 스릴러는 싫어해"}],
user_id="user_1"
)
results = memory.search("영화 추천해줘", user_id="user_1")
for r in results["results"]:
print(r["memory"], r["score"])
from openai import OpenAI
client = OpenAI()
memories = "\n".join(f"- {r['memory']}" for r in results["results"])
response = client.chat.completions.create(
model="gpt-4.1-nano-2025-04-14",
messages=[
{"role": "system", "content": f"사용자 기억:\n{memories}"},
{"role": "user", "content": "오늘 밤 영화 추천해줘"}
]
)
print(response.choices[0].message.content)
프로덕션 전환
프로토타입에서 프로덕션으로 전환할 때는 Kuzu의 인메모리 모드 대신 디스크 경로를 지정하거나, Neo4j로 교체하면 된다:
hljs language-python
config["graph_store"]["config"]["db"] = "./production_memory"
config["graph_store"] = {
"provider": "neo4j",
"config": {
"url": "bolt://localhost:7687",
"username": "neo4j",
"password": "password"
}
}
10. 2026년의 방향: 개인화 AI의 미래
기억이 바꾸는 AI 경험
2026년, AI의 가장 큰 변화는 개인화다. 모든 사용자에게 같은 응답을 하는 범용 AI에서, 각 사용자를 기억하고 이해하는 개인 AI로의 전환.
프라이버시와 데이터 주권
AI가 사용자를 기억한다는 것은 개인정보 보호의 문제이기도 하다. Mem0 + Kuzu의 조합이 특히 주목받는 이유 중 하나:
- 로컬 실행: Kuzu는 임베디드 DB이므로 데이터가 사용자의 기기에 머문다
- 사용자별 격리:
user_id로 기억이 완전히 분리된다
- 삭제 용이: 특정 사용자의 기억만 선택적으로 삭제 가능
클라우드 기반 메모리와 달리, Kuzu를 사용하면 기억이 사용자의 디바이스에서 벗어나지 않는 구조를 만들 수 있다. 이것은 GDPR이나 개인정보보호법 관점에서 큰 장점이다.
AI 에이전트의 장기 기억
2026년 AI 에이전트 시대에, 메모리는 에이전트의 핵심 인프라가 된다:
- 작업 맥락 유지: "어제 시작한 데이터 분석 작업을 이어서 해줘"
- 사용자 선호 학습: "이 사용자는 간결한 보고서를 선호하더라"
- 실패로부터 학습: "지난번에 이 API는 타임아웃이 자주 났어. 재시도 로직을 넣자"
Mem0는 이러한 에이전트 메모리를 위한 표준적인 인프라 레이어로 자리잡아가고 있다.
마무리: 기억하는 AI, 이해하는 AI
📌
핵심 3줄 요약
1. Mem0는 대화에서 사실과 관계를 자동 추출하여 벡터 메모리(의미) + 그래프 메모리(관계)로 이중 저장하는 AI 메모리 프레임워크다.
2. Kuzu 임베디드 그래프 DB와 결합하면 설치 없이 관계 기반 기억 시스템을 구축할 수 있으며, "좋아한다/싫어한다" 같은 부정 관계도 정확히 구분한다.
3. 대화형 개인화 AI, 고객 서비스, 교육 AI 등에서 사용자를 기억하고 이해하는 AI를 만드는 핵심 인프라로 자리잡고 있다.
"분명히 말했는데, 왜 또 물어보는 거야?" — 이 불만은 AI 사용자의 가장 흔한 불편함이다. Mem0 + Kuzu는 이 문제에 대한 가장 실용적인 답을 제공한다.
기억하지 못하는 AI는 도구에 불과하다. 기억하는 AI는 파트너가 된다.
참고 자료
- Kuzu Example — Mem0 GitHub — 이 글의 기반이 된 공식 노트북
- Mem0 GitHub — 오픈소스 리포지토리
- Kuzu — 임베디드 그래프 데이터베이스
- Packer et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560.
- Lewis et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
- Liu et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172.
관련 글
- Cognee 완전 가이드 — 비정형 데이터를 자동으로 지식 그래프로
- Graph RAG with Milvus — 벡터 DB에 지식 그래프를 더하는 실전 구현
- GraphRAG 완전 가이드 — Microsoft GraphRAG의 이론과 실전
- 벡터 데이터베이스 완전 정복 — 벡터 검색의 기초
- AI 에이전트 완전 가이드 — 에이전트 시대의 AI 아키텍처