들어가며: "강아지"를 검색했는데 "puppy"도 나온다?
기존 검색의 한계를 생각해 보자:
- SQL:
WHERE name LIKE '%강아지%' → "강아지"라는 글자가 정확히 포함된 것만
- OpenSearch: 풀텍스트 검색으로 토큰 매칭 → "강아지"와 관련 키워드는 찾지만, "puppy"나 "귀여운 댕댕이"는 못 찾음
둘 다 키워드 매칭이다. "강아지"라는 단어가 문서에 있어야 찾는다.
하지만 인간은 다르게 검색한다. "강아지"를 검색하면 "puppy", "댕댕이", "반려견", "골든 리트리버 사진" — 단어는 다르지만 의미가 같은 결과를 기대한다.
"키워드가 아니라 '의미'로 검색할 수는 없을까?"
이것이 벡터 검색(Vector Search) 의 핵심이고, 이를 위한 전문 저장소가 벡터 데이터베이스(Vector Database) 다.
1. 벡터(임베딩)란 무엇인가
텍스트를 숫자로 바꾸기
컴퓨터는 "강아지"라는 단어의 의미를 이해하지 못한다. 하지만 이 단어를 숫자 배열(벡터) 로 변환하면 "의미"를 수학적으로 다룰 수 있다.
이 변환을 임베딩(Embedding) 이라 부른다.
hljs language-python
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
model="text-embedding-3-small",
input="강아지는 귀엽다"
)
vector = response.data[0].embedding
"강아지는 귀엽다"라는 문장이 1,536개의 소수점 숫자 배열로 변환된다. 이 벡터가 문장의 "의미"를 수학적으로 인코딩한 것이다.

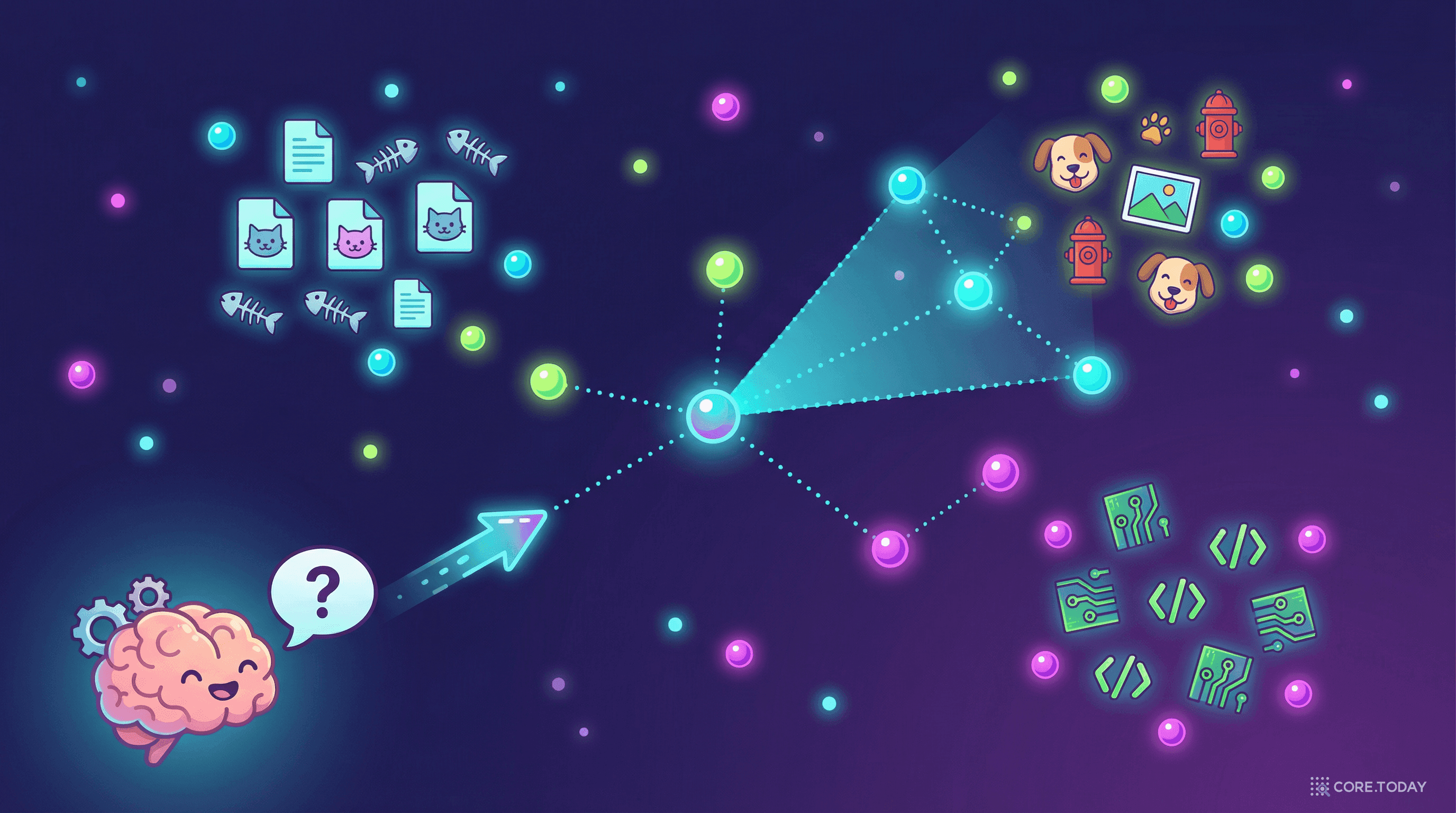
의미가 가까우면 벡터도 가깝다
임베딩의 마법: 의미가 비슷한 텍스트는 벡터 공간에서 가까이 위치한다.
벡터 공간에서의 의미적 거리 (단순화)
"강아지"
← 가까움 →
"puppy"
← 가까움 →
"댕댕이"
↕ 멀다
"자동차"
← 가까움 →
"car"
← 가까움 →
"automobile"
"강아지"의 벡터와 "puppy"의 벡터는 수학적으로 가깝고, "강아지"와 "자동차"의 벡터는 멀다. 이 거리(유사도)를 측정하여 "의미적으로 비슷한 것"을 찾는 것이 벡터 검색이다.
💡
임베딩은 텍스트만이 아니다: 이미지, 오디오, 코드, 분자 구조 — 거의 모든 데이터를 벡터로 변환할 수 있다. 이미지를 벡터로 변환하면 "비슷한 이미지" 검색이 가능하고, 코드를 벡터로 변환하면 "비슷한 기능의 코드" 검색이 가능하다.
2. 벡터 검색의 역사: 최근접 이웃 문제에서 AI 검색으로
ANN: 근사 최근접 이웃 (Approximate Nearest Neighbor)
벡터 검색의 핵심 문제: 수백만~수십억 개의 벡터 중에서 쿼리 벡터와 가장 가까운 K개를 빠르게 찾는 것. 이것을 K-Nearest Neighbor(KNN) 검색이라 한다.
완벽하게 가장 가까운 것을 찾으려면(정확한 KNN) 모든 벡터와의 거리를 계산해야 한다. 10억 개의 1,536차원 벡터면? 계산이 수 분~수 시간.
해결: 100% 정확하지는 않지만 99%+ 정확도로 수 밀리초에 찾는 근사 알고리즘 — ANN(Approximate Nearest Neighbor).
핵심 ANN 알고리즘
| 알고리즘 | 원리 | 대표 구현 | 사용처 |
|---|
| HNSW | 계층적 그래프 탐색. 멀리서 대략 찾고, 가까이서 정밀 탐색 | hnswlib, FAISS | 가장 많이 사용 |
| IVF | 벡터를 클러스터로 나누고, 쿼리와 가까운 클러스터만 검색 | FAISS | 대규모 데이터셋 |
| PQ | 벡터를 압축하여 메모리 절약 + IVF와 결합 | FAISS | 메모리 제한 환경 |
| Annoy | 랜덤 투영 트리. 빌드 빠르지만 정확도 중간 | Annoy (Spotify) | 정적 데이터셋 |
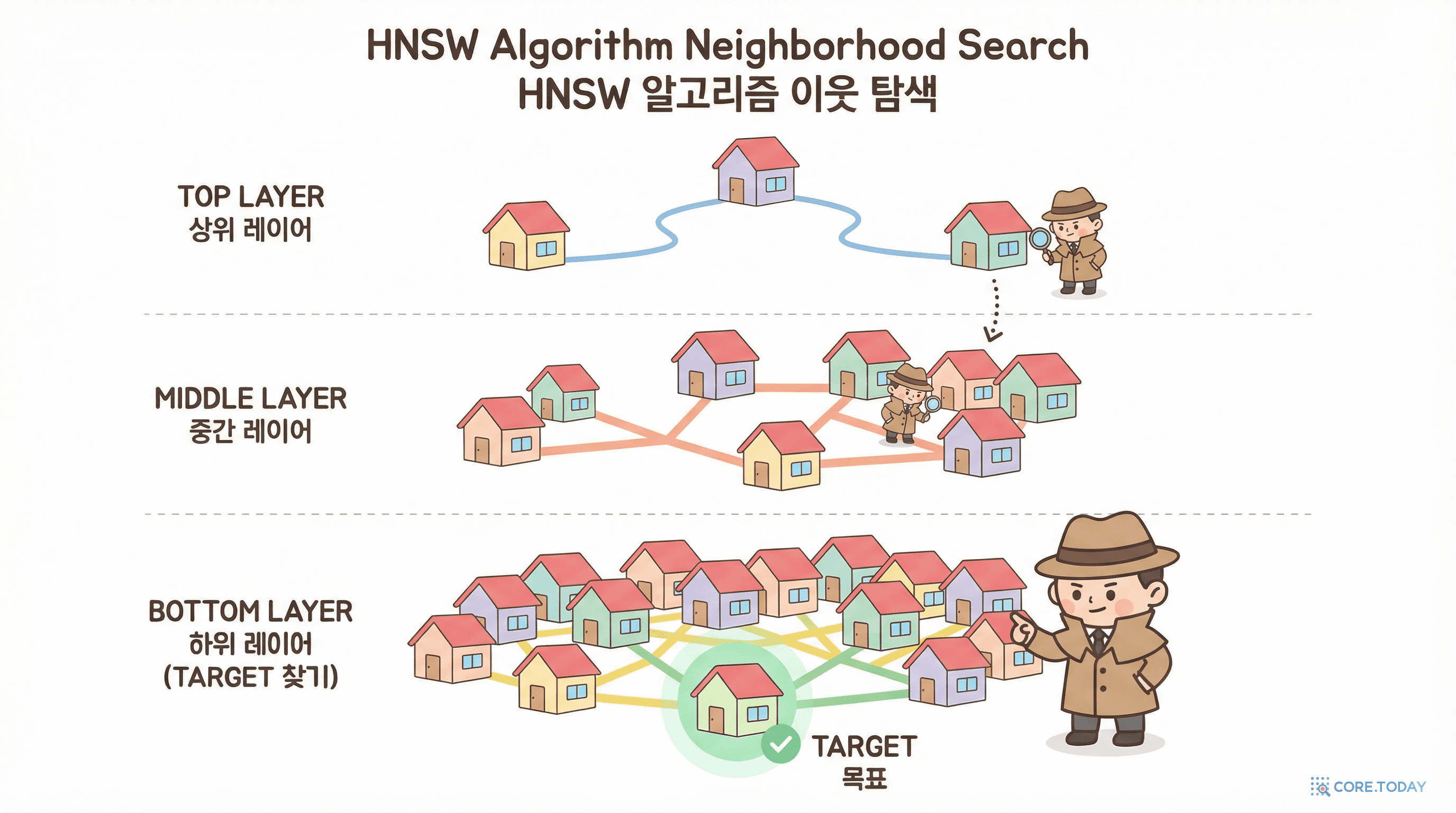
HNSW(Hierarchical Navigable Small World) 가 2026년 현재 가장 많이 사용되는 알고리즘이다. 2016년 Malkov와 Yashunin의 논문 "Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs"에서 제안됐다.
FAISS(Facebook AI Similarity Search) 는 2017년 Meta AI가 공개한 벡터 검색 라이브러리다. 논문 "Billion-scale similarity search with GPUs" (Johnson 등, 2017)에서 GPU를 활용한 대규모 벡터 검색을 제시했다.
2003
LSH (Locality-Sensitive Hashing)
ANN의 초기 알고리즘. 해시 함수로 비슷한 벡터를 같은 버킷에
2013
Word2Vec (Google)
단어를 벡터로 변환하는 혁신적 모델. "king - man + woman = queen" 유명한 예시
2016
HNSW 논문
현재 가장 많이 사용되는 ANN 알고리즘. 계층적 그래프 기반
2017
FAISS (Meta AI)
GPU 기반 대규모 벡터 검색 라이브러리. 오픈소스
2019~2021
벡터 DB 스타트업 등장
Pinecone(2019), Weaviate(2019), Milvus(2019), Qdrant(2021), Chroma(2022)
2023~2026
LLM + RAG 혁명
ChatGPT 이후 RAG가 필수 패턴으로. 벡터 DB 수요 폭발. 기존 DB들도 벡터 검색 추가
3. 벡터 데이터베이스가 왜 필요한가: RAG
RAG(Retrieval-Augmented Generation)이란
LLM(GPT, Claude)은 학습 데이터까지만 알고 있다. 당신 회사의 내부 문서, 최신 데이터, 도메인 지식은 모른다.
"우리 회사의 재택근무 정책이 뭐야?"라고 물으면 → LLM은 모른다 (학습 데이터에 없으니까).
RAG는 이 문제를 해결한다:
사용자 질문: "재택근무 정책이 뭐야?"
↓ 질문을 벡터로 변환 (임베딩)
벡터 DB에서 질문과 의미적으로 가장 가까운 문서 검색
↓ "인사규정 3.4절: 재택근무는 주 2회..." 발견
검색된 문서 + 질문을 LLM에게 전달
↓
LLM: "당사 인사규정에 따르면, 재택근무는 주 2회까지... (출처: 인사규정 3.4절)"
벡터 DB의 역할: 질문과 의미적으로 가장 관련 있는 문서를 빠르게 찾아주는 것. 이것이 없으면 LLM은 "모른다"고 답하거나, 있는 것처럼 지어낸다(환각).

💡
RAG = 오픈북 시험: LLM 단독은 "기억에만 의존하는 시험". RAG는 "교과서를 보면서 치는 오픈북 시험". 벡터 DB가 "가장 관련 있는 교과서 페이지를 찾아주는 역할"을 한다. 답의 정확도가 극적으로 올라간다.
4. 벡터 DB 제품 비교
전문 벡터 DB vs 기존 DB의 벡터 확장
전문 벡터 DB
벡터 검색에 특화된 새로운 DB
최고의 벡터 검색 성능
별도 인프라 필요
데이터가 두 곳에 분산 (원본 DB + 벡터 DB)
Pinecone, Weaviate, Milvus, Qdrant, Chroma
기존 DB의 벡터 확장
기존 DB에 벡터 검색 기능 추가
벡터 성능은 전문 DB보다 낮을 수 있음
기존 인프라 활용, 추가 DB 불필요
메타데이터 + 벡터가 한 곳에
pgvector(PostgreSQL), OpenSearch k-NN, MongoDB Atlas Vector
주요 제품 비교
| 제품 | 유형 | 강점 | 적합한 경우 |
|---|
| pgvector | PostgreSQL 확장 | 기존 PG에 추가만, SQL 통합, 무료 | PG 사용 중, 소~중규모 |
| Pinecone | 전문 벡터 DB (관리형) | 완전 관리형, 간단, 빠른 시작 | 빠른 프로토타이핑, 운영 부담 최소화 |
| Weaviate | 전문 벡터 DB (오픈소스) | 멀티모달, GraphQL API | 이미지+텍스트 통합 검색 |
| Milvus | 전문 벡터 DB (오픈소스) | 대규모 특화, GPU 지원 | 10억+ 벡터, 고성능 |
| Qdrant | 전문 벡터 DB (오픈소스) | Rust 구현, 고성능, 필터링 강력 | 고성능 + 복잡한 필터 |
| Chroma | 전문 벡터 DB (임베디드) | 경량, Python 네이티브 | 프로토타이핑, 로컬 개발 |
| OpenSearch k-NN | OpenSearch 확장 | 풀텍스트 + 벡터 하이브리드 | 키워드+의미 통합 검색 |
| MongoDB Atlas Vector | MongoDB 확장 | 문서 DB + 벡터 통합 | MongoDB 사용 중 |
| Aurora pgvector | Aurora PG 확장 | Aurora + 벡터, 관리형 | AWS Aurora 사용 중 |
✅
선택 가이드 핵심: 이미 PostgreSQL(Aurora)을 쓰고 있다면 → pgvector로 시작하라. 별도의 벡터 DB를 추가하지 않고, 같은 DB에서 SQL과 벡터 검색을 모두 할 수 있다. 벡터가 1억 개를 넘거나 전문 DB의 고급 기능(멀티모달, GPU 가속)이 필요할 때 전문 벡터 DB로 전환.
5. pgvector: 가장 실용적인 선택
"새 DB 없이 벡터 검색을"
pgvector는 PostgreSQL의 확장(Extension)으로, Aurora PostgreSQL에서도 사용 가능하다.
hljs language-sql
CREATE EXTENSION vector;
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT,
embedding VECTOR(1536)
);
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
SELECT title, content,
1 - (embedding <=> '[0.012, -0.034, ...]') AS similarity
FROM documents
ORDER BY embedding <=> '[0.012, -0.034, ...]'
LIMIT 5;
SQL로 벡터 검색을 할 수 있다. 기존 PostgreSQL 도구(pg_dump, pgAdmin, ORM)가 모두 작동한다. 새로운 도구, 새로운 인프라가 불필요.
pgvector의 장단점
pgvector 장점
기존 PostgreSQL에 추가만 하면 됨
SQL과 벡터 검색을 하나의 쿼리에서
메타데이터 필터 + 벡터 검색 결합 쉬움
Aurora PostgreSQL에서도 사용 가능
ACID 트랜잭션 안에서 벡터 업데이트
무료 (오픈소스)
pgvector 한계
전문 벡터 DB보다 대규모에서 느릴 수 있음
10억+ 벡터에서는 성능 한계
GPU 가속 미지원
멀티모달(이미지+텍스트) 전용 기능 없음
인덱스 빌드가 대규모에서 느림
6. 벡터 DB 보안: 임베딩도 데이터다
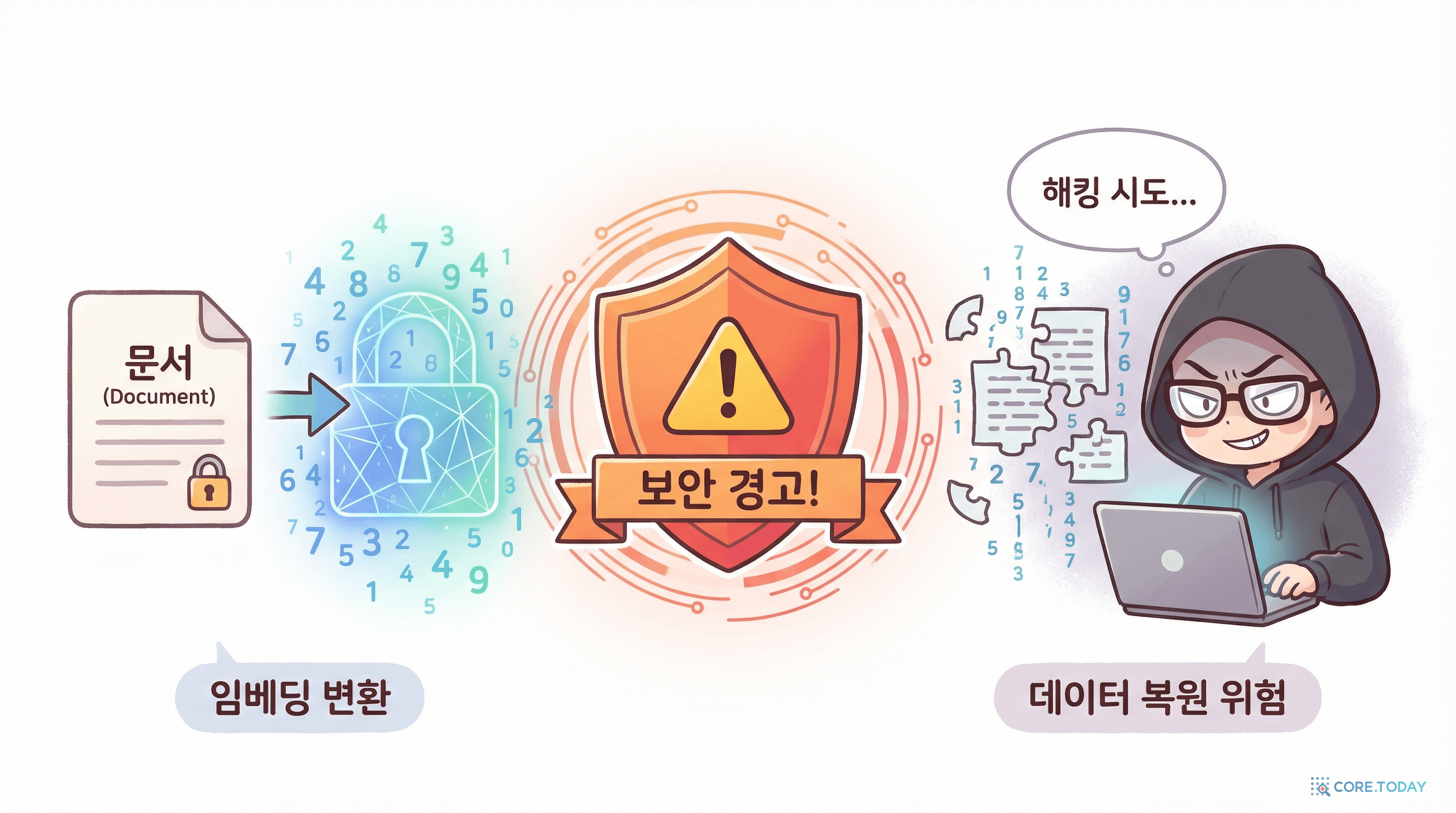
임베딩에서 원본 복원이 가능한가?
연구에 따르면, 임베딩 벡터에서 원본 텍스트를 부분적으로 복원하는 것이 가능하다. 2023년 논문 "Text Embeddings Reveal (Almost) As Much As Text" (Morris 등)에서 텍스트 임베딩으로부터 원본 텍스트를 상당 부분 재구성할 수 있음을 증명했다.
🔒
임베딩도 민감 데이터다: "원본 텍스트 대신 벡터만 저장하면 안전하다"는 잘못된 가정이다. 임베딩 벡터에도 원본의 의미 정보가 인코딩되어 있으므로, 임베딩을 원본 데이터와 동일한 보안 수준으로 보호해야 한다. 암호화, 접근 제어, 감사 로깅이 필요하다.
벡터 DB 관련 보안 사고
2023
RAG 시스템 프롬프트 인젝션
벡터 DB에 저장된 문서에 악의적 프롬프트를 삽입. RAG가 이 문서를 검색하면 LLM의 행동이 조작됨. "간접 프롬프트 인젝션"의 새로운 공격 벡터
2024
벡터 DB 접근 제어 미흡
여러 기업에서 벡터 DB에 저장된 내부 문서 임베딩이 적절한 접근 제어 없이 노출. 검색 API를 통해 내부 기밀 문서 내용 유추 가능
7. 실전 아키텍처: RAG 파이프라인
전형적인 RAG 아키텍처
RAG 파이프라인 아키텍처
1. 문서 수집 (S3, Confluence, Notion)
3. 임베딩 생성 (OpenAI, Cohere, Bedrock)
4. 벡터 DB에 저장 (pgvector, Pinecone, OpenSearch)
5. 사용자 질문 → 벡터 검색 → 관련 문서 → LLM 답변
AWS에서의 RAG 구현 방법
| 방법 | 복잡도 | 벡터 저장소 | 적합한 경우 |
|---|
| Bedrock Knowledge Bases | 가장 간단 | OpenSearch Serverless (자동) | 빠른 시작, 관리 최소화 |
| Aurora pgvector | 중간 | Aurora PostgreSQL | 이미 Aurora 사용 중 |
| OpenSearch k-NN | 중간 | OpenSearch | 키워드+벡터 하이브리드 |
| 직접 구축 | 높음 | Pinecone/Milvus 등 | 완전한 커스터마이징 |
✅
AWS에서 가장 쉬운 RAG: Bedrock Knowledge Bases를 사용하면 S3에 문서를 올리기만 하면 된다. 청킹, 임베딩 생성, 벡터 저장, 검색 — 모든 것을 Bedrock이 자동으로 처리한다. 이전 Bedrock 글에서 다룬 패턴 그대로.
8. 하이브리드 검색: 키워드 + 의미를 함께
벡터 검색만으로는 부족하다
벡터 검색은 "의미"를 잡지만, 정확한 키워드 매칭에서는 전통적 검색보다 약할 수 있다. 예: 제품 코드 "A-1234"를 검색하면 벡터 검색은 의미적으로 비슷한 다른 제품을 반환할 수 있다.
하이브리드 검색: 키워드 검색(BM25)과 벡터 검색을 결합하여 둘의 장점을 모두 취한다.

| 키워드 검색 | 벡터 검색 | 하이브리드 |
|---|
| "A-1234" | ✓ 정확히 찾음 | △ 비슷한 것을 찾을 수 있음 | ✓ 정확 + 관련 |
| "따뜻한 느낌의 케이스" | ✗ 키워드 없으면 못 찾음 | ✓ 의미적으로 찾음 | ✓ 의미적으로 찾음 |
| "MongoDB vs PostgreSQL" | △ 키워드 매칭 | ✓ 비교 문서 찾음 | ✓ 최적 |
OpenSearch와 MongoDB Atlas는 하이브리드 검색을 네이티브로 지원한다.
9. 실제 사례
Notion AI: 지식 검색
Notion AI는 사용자의 워크스페이스에 있는 모든 문서를 벡터화하여, "우리 팀의 Q3 목표는?"같은 질문에 관련 문서를 찾아 답변한다. 이것이 RAG다.
Spotify: 음악 추천
Spotify는 노래를 벡터로 변환하여, "이 곡과 비슷한 곡"을 벡터 유사도로 추천한다. 장르, 템포, 무드가 비슷한 곡이 벡터 공간에서 가까이 위치한다.
Airbnb: 숙소 검색
"바다가 보이는 조용한 숙소"라고 검색하면, 키워드 매칭이 아닌 의미적으로 비슷한 숙소 리스팅을 벡터 검색으로 찾는다. 숙소 설명, 리뷰, 이미지를 모두 벡터화.
한국 기업 사례
- 네이버: 쇼핑 검색에서 상품 이미지+텍스트를 벡터화하여 의미 검색 적용
- 카카오: 카카오톡 채널의 AI 고객 상담에 RAG + 벡터 검색 활용
- 토스: 내부 지식 검색 시스템에 RAG 파이프라인 구축. 사내 문서를 벡터화하여 직원이 자연어로 검색
- 코어닷투데이: AI 서비스의 도메인 지식 검색에 벡터 DB 활용. Bedrock Knowledge Bases + Aurora pgvector
10. 벡터 DB의 미래
임베딩 모델의 진화
2026년의 임베딩 모델은 2023년 대비 훨씬 강력하다:
- 다국어 지원: 한국어 ↔ 영어 의미 매칭이 자연스러움
- 멀티모달: 텍스트, 이미지, 코드를 같은 벡터 공간에 매핑
- 긴 컨텍스트: 전체 문서를 하나의 벡터로 (수만 토큰)
모든 DB가 벡터를 지원하게 된다
PostgreSQL(pgvector), MongoDB(Atlas Vector), OpenSearch(k-NN), Redis(Vector), DynamoDB(곧 지원 예상) — 전문 벡터 DB 없이도 벡터 검색이 가능한 시대가 오고 있다.
장기적으로 전문 벡터 DB는 초대규모(10억+ 벡터)이거나 특수 기능(GPU 가속, 멀티모달)이 필요한 경우에 사용되고, 대부분의 서비스는 기존 DB의 벡터 확장으로 충분해질 것이다.
마치며: "의미"를 저장하는 시대
이 시리즈에서 다룬 데이터 저장소의 최종 완성판:
| 저장하는 것 | DB 유형 | 대표 제품 | 검색 방식 |
|---|
| 구조화된 관계 | 행 저장 RDBMS | Aurora, RDS | SQL (정확한 값) |
| 유연한 문서 | 문서 DB | MongoDB | 쿼리 언어 (필드 매칭) |
| 키-값 | 키-값 DB | DynamoDB | 키로 직접 조회 |
| 텍스트 | 검색 엔진 | OpenSearch | 역색인 (키워드 매칭) |
| 집계 분석 | 컬럼나 DW | Redshift | SQL (범위 집계) |
| 시간 순서 | 시계열 DB | Prometheus, Timestream | 시간 범위 쿼리 |
| 의미 | 벡터 DB | pgvector, Pinecone | 벡터 유사도 (의미 검색) |
| 파일 | 오브젝트 스토리지 | S3 | 키로 직접 접근 |
벡터 DB는 이 지도의 마지막 조각이다. 기존 DB들이 "정확한 값"을 검색했다면, 벡터 DB는 "의미"를 검색한다. 이것이 AI 시대의 데이터 저장소에서 가장 큰 변화다.
"강아지"를 검색하면 "puppy"도 찾아주는 것 — 이 간단해 보이는 기능 뒤에 임베딩 모델, ANN 알고리즘, 벡터 인덱스라는 기술의 탑이 쌓여 있다. 그리고 이 탑 위에서 RAG가 작동하고, AI 어시스턴트가 당신 회사의 내부 문서를 이해하고, 추천 시스템이 당신의 취향을 파악한다.
코어닷투데이의 AI 서비스에서 벡터 DB는 핵심 인프라다. 도메인 지식을 벡터로 저장하고, 사용자의 질문에 가장 관련 있는 정보를 밀리초 만에 검색하여, AI가 정확하고 신뢰할 수 있는 답변을 제공한다. 키워드가 아닌 의미로 검색하는 시대 — 벡터 DB가 그 시대의 기반이다.