들어가며: "GraphRAG가 좋은 건 알겠는데, 비용이..."
GraphRAG의 가치는 이미 증명되었다. 문서를 지식 그래프로 변환하면 개별 청크 검색으로는 보이지 않던 문서 간 관계와 전체 패턴을 파악할 수 있다. 포괄성 72~83% 승률, 멀티홉 추론에서의 압도적 성능 — 결과는 인상적이다.
하지만 현실적인 장벽이 있다. 100만 단어를 GraphRAG로 인덱싱하는 데 $11~76. 글로벌 검색 한 번에 ~15만 토큰, 610번의 API 호출. 새로운 문서가 추가되면? 커뮤니티 전체를 재구축해야 한다.
스타트업 개발자가 사내 문서 검색 시스템을 만들려 할 때, 이 비용은 현실적이지 않다. "그래프 기반 검색의 장점은 원하지만, GraphRAG의 무게는 감당할 수 없다"는 요구가 자연스럽게 등장했다.
2024년 10월, 홍콩대학교와 베이징우전대학교의 연구팀이 이 문제에 정면으로 답하는 논문을 발표한다.
1. RAG 발전의 흐름 속에서 LightRAG의 위치
벡터에서 그래프로, 그리고 다시 가벼운 그래프로
RAG의 역사를 돌아보면, 정보를 어떻게 표현하느냐의 진화 과정이 보인다.
Naive RAG
→
Advanced RAG
→
GraphRAG
→
LightRAG
| 세대 | 정보 표현 | 강점 | 약점 |
|---|
| Naive RAG (2020) | 평면적 텍스트 청크 | 단순, 빠름 | 관계 파악 불가 |
| Advanced RAG (2022~) | 청크 + 리랭킹/하이브리드 | 검색 품질 향상 | 여전히 청크 단위 |
| GraphRAG (2024.4) | 지식 그래프 + 커뮤니티 계층 | 전체 조망, 멀티홉 | 비용 높음, 업데이트 어려움 |
| LightRAG (2024.10) | 지식 그래프 + 듀얼 레벨 검색 | 빠르고 저렴, 증분 업데이트 | 커뮤니티 수준 추론 불가 |
LightRAG는 GraphRAG의 "지식 그래프를 활용한다"는 핵심 통찰은 유지하면서, "커뮤니티 계층"이라는 가장 비용이 큰 구성 요소를 제거한 것이다. 마치 풀사이즈 SUV의 엔진 성능은 유지하면서 차체를 경량화한 크로스오버 차량과 같다.
왜 이 시점에 등장했는가
2024년 4월 GraphRAG 발표 이후 6개월간, 실무자들의 피드백이 명확한 방향을 가리켰다:
- 인덱싱 비용이 너무 높다: 100만 단어에 $76(GPT-4-Turbo). 엔터프라이즈 규모에서는 감당 불가
- 업데이트가 불가능에 가깝다: 문서 하나 추가할 때마다 Leiden 클러스터링 + 커뮤니티 요약 전체 재실행
- 글로벌 검색이 느리다: 610개 커뮤니티를 순회하며 각각 LLM 호출 — 지연 시간과 비용 모두 문제
- 모든 질문에 글로벌 수준이 필요하지 않다: 대부분의 질문은 특정 개체와 그 주변만 보면 답할 수 있다
이 피드백들이 LightRAG의 설계 철학을 직접적으로 형성했다.
2. 논문 소개
"LightRAG: Simple and Fast Retrieval-Augmented Generation"
- 저자: Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, Chao Huang (홍콩대학교, 베이징우전대학교)
- 발표: arXiv:2410.05779 (2024년 10월)
- 학회: EMNLP 2025 Findings (Suzhou, China)
- GitHub: 29,600+ 스타
논문의 핵심 주장:
"LightRAG는 그래프 구조를 텍스트 인덱싱과 검색에 통합하되, 듀얼 레벨 검색(dual-level retrieval)으로 세밀한 개체 정보와 넓은 주제 정보를 동시에 제공한다. GraphRAG 대비 쿼리당 토큰 사용량을 ~6,000배 줄이면서 유사한 답변 품질을 달성한다."
3. LightRAG의 핵심 아이디어: 무엇을 버리고, 무엇을 남겼나
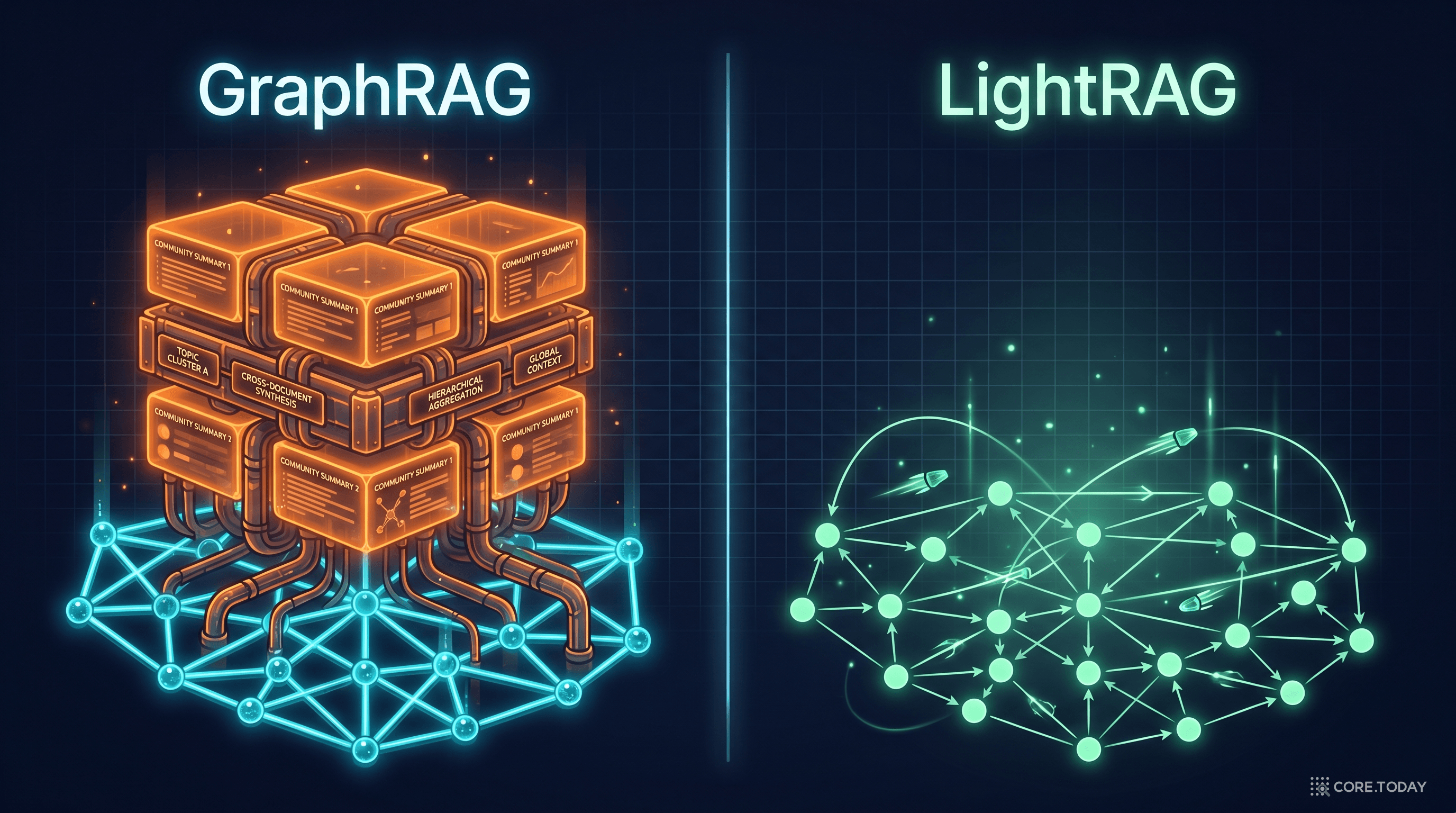
GraphRAG에서 가장 비싼 것: 커뮤니티 계층
GraphRAG의 비용 구조를 다시 보자:
개체 추출(75%)은 두 시스템 모두에서 필수적이다. 하지만 커뮤니티 요약(25%)은 Leiden 알고리즘으로 그래프를 계층적으로 클러스터링하고, 각 커뮤니티에 대해 LLM으로 요약 보고서를 생성하는 과정이다. 이것이 인덱싱 비용의 1/4, 쿼리 비용의 대부분을 차지한다.
그리고 검색할 때의 차이가 더 극적이다:
| GraphRAG 글로벌 검색 | LightRAG |
|---|
| API 호출 수 | ~610회 (커뮤니티당 1회) | 1회 |
| 검색 토큰 사용 | ~610,000 | <100 |
| 비율 | 1x | ~6,000x 절감 |
LightRAG의 선택: 커뮤니티 없이도 "전체"를 볼 수 있다
LightRAG의 핵심 통찰은 이것이다: 커뮤니티 계층 없이도, 그래프 자체의 구조(노드 + 엣지 + 이웃)와 듀얼 레벨 키워드 검색을 조합하면 충분히 넓은 시야를 확보할 수 있다.
비유하자면, GraphRAG가 "도시 전체의 행정 구역도를 먼저 그리고, 구역별로 요약한 뒤, 질문에 맞는 구역을 찾아가는 것"이라면, LightRAG는 "도시의 도로망(그래프)만 가지고, 관련된 건물(개체)을 찾은 뒤 바로 인접 도로를 따라가보는 것"이다. 행정 구역도를 만드는 비용을 아끼면서도, 도로망 자체가 충분한 연결 정보를 제공한다.
4. LightRAG는 어떻게 작동하는가
4.1 인덱싱: R-P-D 파이프라인
LightRAG의 인덱싱은 세 단계로 이루어진다: 인식(Recognition), 프로파일링(Profiling), 중복 제거(Deduplication).
문서 청킹
→
R: 개체·관계 추출
→
P: 키-값 프로파일
→
D: 중복 제거·병합
→
그래프 + 벡터 DB
① Recognition (인식): 각 문서 청크에서 LLM이 개체(노드)와 관계(엣지)를 추출한다.
입력 텍스트
"심장내과 전문의는 심장 질환을 진단한다. 심장 질환의 주요 위험 인자에는 고혈압과 당뇨가 있다."
추출된 개체
심장내과 전문의 (직업), 심장 질환 (질병), 고혈압 (위험인자), 당뇨 (위험인자)
추출된 관계
심장내과 전문의 —진단→ 심장 질환
고혈압 —위험인자→ 심장 질환
당뇨 —위험인자→ 심장 질환
이 과정은 GraphRAG와 동일하다. 차이는 여기서 끝난다는 것이다. GraphRAG는 이후 Leiden 클러스터링 → 커뮤니티 요약이 이어지지만, LightRAG는 그래프를 그대로 사용한다.
② Profiling (프로파일링): 각 노드와 엣지에 대해 키-값 쌍을 생성한다. 개체 이름이 검색 인덱스 키가 되고, 관계 엣지에는 LLM이 생성한 글로벌 테마 키워드가 추가된다. 예를 들어 "고혈압 → 심장 질환" 관계에 "심혈관 위험 요인"이라는 테마 키워드가 붙는다.
③ Deduplication (중복 제거): 여러 청크에서 같은 개체가 추출되면 하나로 병합하고, 설명을 누적한다.
GraphRAG vs LightRAG 인덱싱 비교
인덱싱 파이프라인 비교
GraphRAG
추출 → 그래프 구축 → Leiden 클러스터링 → 커뮤니티 요약
LightRAG
추출 → 그래프 구축 → 끝. 커뮤니티 없음
4.2 검색: 듀얼 레벨 키워드 매칭
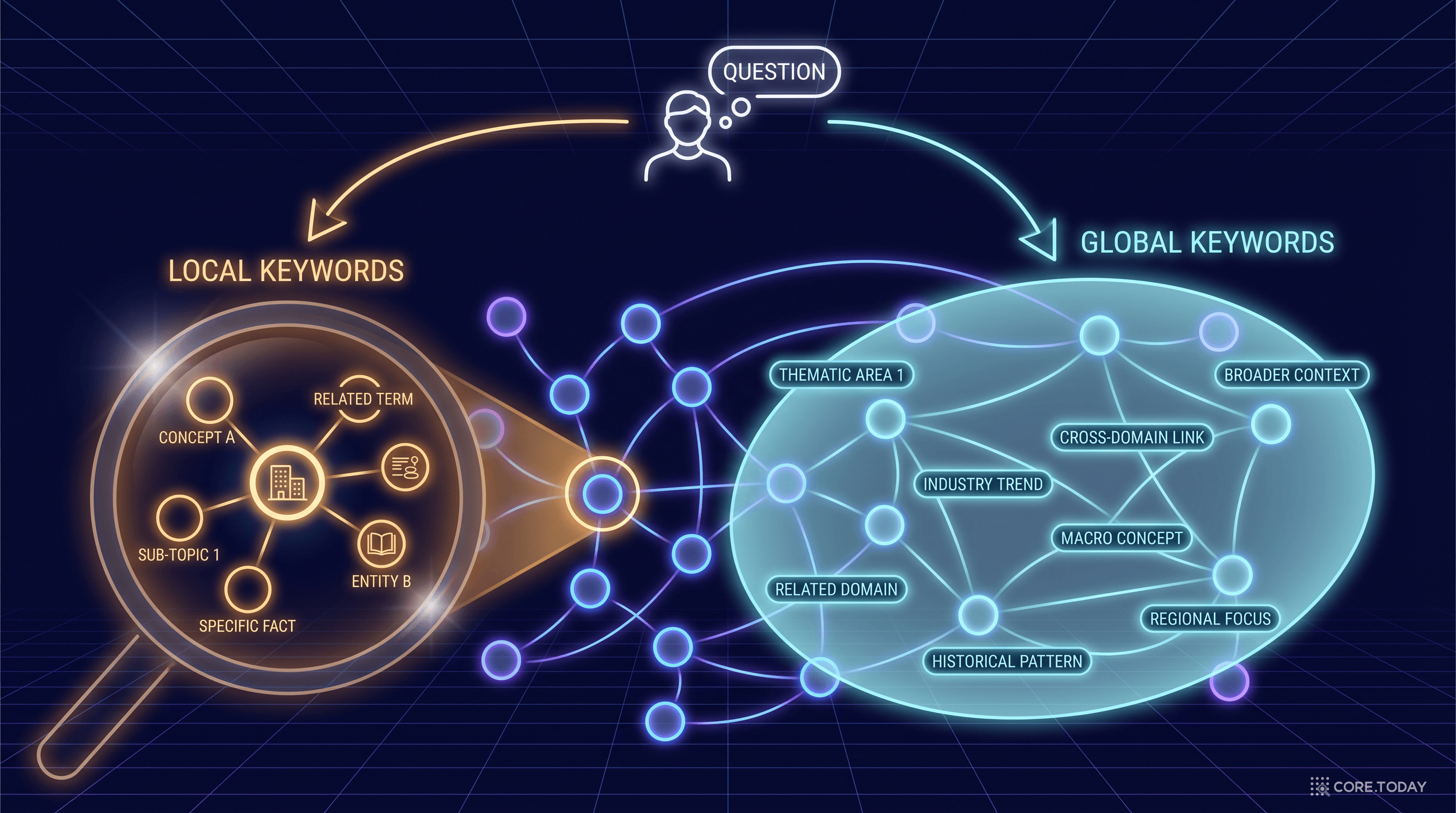
LightRAG의 핵심 혁신은 검색 단계에 있다. 질문이 들어오면 LLM이 두 종류의 키워드를 추출한다:
사용자 질문
"심장 질환의 위험 인자와 예방법은?"
로컬 키워드 (Low-Level)
심장 질환, 고혈압, 당뇨 → 특정 개체와 그 속성을 검색
글로벌 키워드 (High-Level)
심혈관 위험 요인, 예방 의학 → 여러 개체를 아우르는 주제 검색
로컬 키워드는 그래프의 개체 노드와 직접 매칭되어, 해당 개체와 1-hop 이웃(직접 연결된 개체들)을 가져온다. 글로벌 키워드는 관계 엣지의 테마 키워드와 매칭되어, 더 넓은 범위의 정보를 가져온다.
EXTRACTLLM이 질문에서 로컬 키워드 + 글로벌 키워드 추출 (단일 호출, <100 토큰)
LOW-LEVEL로컬 키워드 → 개체 노드 임베딩 매칭 → 해당 개체 + 1-hop 이웃 수집
HIGH-LEVEL글로벌 키워드 → 관계 엣지 임베딩 매칭 → 연결된 개체 쌍 + 주제 정보 수집
GENERATE수집된 컨텍스트 + 원래 질문 → LLM이 최종 답변 생성
기본 모드는 하이브리드(hybrid) — 로컬과 글로벌 결과를 모두 결합한다. 이것이 GraphRAG의 "글로벌 검색"이 610회 API 호출로 하는 일을, 1회 API 호출로 달성하는 방법이다.
4.3 증분 업데이트: 그래프에 노드를 추가하면 끝
GraphRAG에서 새 문서를 추가하면 벌어지는 일:
- 새 문서에서 개체/관계 추출
- 기존 그래프에 병합
- Leiden 알고리즘으로 전체 그래프를 다시 클러스터링
- 변경된 모든 커뮤니티의 요약을 다시 생성
3~4번이 전체 비용의 상당 부분을 차지한다.
LightRAG에서 새 문서를 추가하면:
- 새 문서에서 개체/관계 추출 (R-P-D)
- 기존 그래프에 합집합(union) 연산으로 병합
- 끝
커뮤니티가 없으니 재구축할 것도 없다. 기존 그래프 구조는 그대로 보존되고, 새 노드와 엣지만 추가된다. 논문에 따르면 이 방식으로 업데이트 처리 시간이 50~70% 감소한다.
이것은 실무에서 결정적인 차이를 만든다. 매일 새로운 문서가 추가되는 사내 지식 베이스, 실시간으로 업데이트되는 뉴스 데이터, 지속적으로 변경되는 기술 문서 — 이런 시나리오에서 "업데이트할 때마다 전체 재구축"은 현실적이지 않다.
5. 성능: 실제로 GraphRAG와 어떻게 비교되는가
공식 벤치마크 (UltraDomain 데이터셋)
논문은 428개 대학 교과서 기반의 4개 도메인(농업, CS, 법률, 혼합)에서 LLM-as-judge 방식으로 평가했다.
LightRAG vs Naive RAG — 대부분 압도적 승리:
LightRAG vs Naive RAG 승률 (%)
높을수록 LightRAG 우세
특히 법률 도메인에서 84.8% 승률 — 개체 간 관계(조항, 판례, 당사자)가 복잡한 영역에서 그래프 기반 검색의 강점이 극대화된 것이다.
LightRAG vs GraphRAG — 박빙이지만 다양성에서 우세:
| 지표 | 농업 | CS | 법률 | 혼합 |
|---|
| 포괄성 | 54.4% | 51.6% | 51.6% | 49.6% |
| 다양성 | 77.2% | 59.2% | 73.6% | 64.0% |
| 전체 | 54.8% | 52.0% | 52.8% | 49.6% |
포괄성에서는 거의 대등하지만(50% 내외), 다양성(Diversity)에서 LightRAG가 일관되게 우세하다. 이것은 GraphRAG의 커뮤니티 요약이 정보를 압축하는 과정에서 일부 관점을 소실하는 반면, LightRAG는 그래프의 원본 구조를 직접 탐색하여 더 다양한 관점의 정보를 수집하기 때문으로 해석된다.
비용 효율성: 숫자로 보는 차이

| 지표 | GraphRAG | LightRAG | 비율 |
|---|
| 쿼리당 토큰 | ~610,000 | <100 | ~6,000x |
| 쿼리당 API 호출 | ~610 | 1 | ~610x |
| 같은 데이터셋 인덱싱 비용 | ~$4 | ~$0.10~0.15 | ~27~40x |
| 평균 응답 시간 | 수 초 | ~200ms | — |
주의: 평가 방법론의 한계
2025년 발표된 논문 "How Significant Are the Real Performance Gains?"(arXiv:2506.06331)은 LightRAG를 포함한 GraphRAG 계열 논문들의 평가 방법론에 중요한 문제를 제기했다:
- 위치 편향: 답변 A/B 순서를 바꾸면 승률이 30% 이상 변동
- 길이 편향: 25토큰 차이만으로 승률이 50% 이상 변동 — LLM은 더 긴 답변을 선호
- 시행 편향: 동일 평가를 반복하면 결과가 모순적
이 편향을 제거한 평가에서는 순위가 역전되었다: FastGraphRAG > GraphRAG > NaiveRAG > LightRAG. 이는 LightRAG의 절대적 품질 우위를 확신하기 어렵다는 것을 의미한다.
하지만 이것이 LightRAG의 가치를 부정하는 것은 아니다. 비용 효율성과 증분 업데이트 능력은 평가 방법론과 무관한 구조적 장점이다. "비슷한 품질을 1/100 비용으로"라는 가치 제안은 여전히 유효하다.
6. 사례로 보는 LightRAG의 활용
사례 1: 스타트업의 사내 지식 베이스
50명 규모의 SaaS 스타트업을 상상해보자. 사내 위키, API 문서, 미팅 노트, 고객 피드백이 매일 쌓인다. 팀은 "우리 제품의 X 기능과 관련된 고객 불만은?"이나 "지난달 의사결정 맥락이 뭐였지?" 같은 질문에 답하는 챗봇을 원한다.
GraphRAG를 선택하면: 초기 인덱싱에 수십~수백 달러. 매일 새 문서가 추가될 때마다 재인덱싱 비용 발생. 스타트업 예산에 부담.
LightRAG를 선택하면: 초기 인덱싱 비용 1/40. 새 문서는 그래프에 노드만 추가하면 되어 증분 업데이트 비용 최소. 응답 시간 ~200ms로 챗봇 UX에 적합.
사례 2: 법률 문서 분석
로펌에서 계약서, 판례, 규정 간의 관계를 추적하는 시스템을 구축한다. "이 계약 조항과 상충하는 규정이 있는가?"라는 질문에 답해야 한다.
이 시나리오에서 LightRAG의 법률 도메인 승률 84.8%(vs Naive RAG)는 의미가 크다. 계약-조항-규정-판례 간의 관계가 그래프로 자연스럽게 표현되고, 로컬 검색(특정 조항)과 글로벌 검색(전체 규정 체계)을 하이브리드로 결합할 수 있다.
사례 3: 기술 문서 + 코드베이스 검색
개발팀이 API 문서, README, 코드 주석, Jira 티켓을 통합 검색하려 한다. "이 API의 인증 방식은?"(로컬 질문)부터 "우리 인증 시스템의 전체 아키텍처는?"(글로벌 질문)까지 다양한 수준의 질문이 들어온다.
LightRAG의 듀얼 레벨 검색은 이 시나리오에 자연스럽게 맞는다. 로컬 키워드로 특정 API 개체를 찾고, 글로벌 키워드로 인증 아키텍처 전체를 조망한다. 코드가 업데이트될 때 증분 인덱싱으로 실시간에 가까운 반영이 가능하다.
사례 4: 의료 문헌 리서치
연구자가 수천 편의 논문에서 약물-유전자-질병 간 관계를 추적한다. 새 논문이 매주 출판되므로 증분 업데이트가 필수적이다.
LightRAG는 "Drug A → targets → Gene B → associated with → Disease C" 같은 멀티홉 경로를 그래프에서 직접 추적한다. GraphRAG처럼 커뮤니티 수준의 전체 요약이 필요 없다면 — 즉, "이 분야의 전반적 트렌드는?"보다 "Drug A와 관련된 유전자 경로는?"이 주요 질문이라면 — LightRAG가 더 효율적인 선택이다.
사례 5: Edge AI / 온디바이스 배포
IoT 환경에서 장비 매뉴얼과 고장 이력을 기반으로 현장 기사에게 진단 가이드를 제공하는 시스템. 클라우드 연결이 불안정하여 로컬 실행이 필요하다.
LightRAG의 가벼운 구조는 Ollama 같은 로컬 LLM과 결합하여 완전한 온디바이스 배포가 가능하다. GraphRAG의 글로벌 검색(610회 API 호출)은 로컬에서 현실적이지 않지만, LightRAG의 1회 호출 검색은 에지 디바이스에서도 실행 가능하다.
7. 경량 대안들과의 비교
LightRAG만이 "가벼운 GraphRAG"는 아니다. 비슷한 문제를 다른 방식으로 해결하는 대안들이 있다.
| 시스템 | 핵심 차별점 | GitHub 스타 | 인덱싱 비용 |
|---|
| LightRAG | 듀얼 레벨 검색, 증분 업데이트 | 29.6K | GraphRAG의 ~1/40 |
| nano-graphrag | 1,100줄 Python, 극도로 단순 | 3.7K | 중간 |
| FastGraphRAG | PageRank 기반 개체 순위 | — | GraphRAG의 ~1/75 |
| LazyGraphRAG | 쿼리 시점까지 LLM 호출 지연 | — (MS 내부) | GraphRAG의 0.1% |
nano-graphrag
LightRAG의 "상위 프로젝트"에 해당한다. LightRAG는 nano-graphrag를 기반으로 만들어졌다. 약 1,100줄의 Python으로 구현된 극도로 단순한 GraphRAG 구현체로, 해킹과 커스터마이징이 쉽다. 하지만 LightRAG의 듀얼 레벨 검색 같은 고급 기능은 없다.
FastGraphRAG
개체 추출 후 PageRank 알고리즘으로 개체의 중요도를 매기고, 중요한 개체를 우선적으로 검색에 활용한다. 앞서 언급한 편향 제거 평가에서 LightRAG보다 높은 성능을 보였다. 다만 LightRAG만큼 폭넓은 생태계(벡터 DB, 그래프 DB 통합)를 갖추지는 않았다.
LazyGraphRAG (Microsoft)
가장 급진적인 접근법. 인덱싱 시점에 LLM을 전혀 호출하지 않고, NLP 기반으로 그래프만 구축한다. LLM 호출은 쿼리 시점까지 미룬다(lazy evaluation). 인덱싱 비용이 GraphRAG의 0.1%, 쿼리 비용이 700배 낮다고 주장한다. 하지만 독립 코드로 공개되지 않아 Microsoft GraphRAG 프로젝트의 일부로만 사용 가능하다.
선택 기준
빠른 프로토타입nano-graphrag → 1,100줄, 즉시 해킹 가능
프로덕션 배포LightRAG → 넓은 인프라 지원, 증분 업데이트, 활발한 커뮤니티
최대 비용 절감LazyGraphRAG → 인덱싱 비용 거의 0, MS 생태계 내에서 사용
품질 최우선FastGraphRAG → 편향 제거 평가에서 최고 성능
8. LightRAG의 한계: 언제 쓰지 말아야 하는가
커뮤니티 수준 추론이 필요한 경우
"이 데이터셋의 핵심 주제 5가지를 정리해줘" — 이런 질문에는 GraphRAG의 커뮤니티 요약이 더 적합하다. LightRAG는 1-hop 이웃만 탐색하므로, 전체를 관통하는 추상적 패턴을 파악하는 데 한계가 있다. 듀얼 레벨의 글로벌 키워드가 이를 일부 보완하지만, GraphRAG의 계층적 커뮤니티 요약에는 미치지 못한다.
대규모 모델이 필요한 점
논문의 최적 성능은 32B+ 파라미터 모델, 32K+ 컨텍스트 윈도우에서 달성되었다. 7B~13B급 소규모 모델에서는 개체 추출 품질이 떨어지고, 키워드 추출 정확도도 낮아진다. 리소스가 제한된 환경에서는 같은 팀이 개발한 MiniRAG(소규모 모델 특화)가 더 적합할 수 있다.
단순 FAQ에는 과잉
"반품 정책이 뭐야?" 같은 단순 질문만 처리하는 시스템에 지식 그래프는 불필요하다. 개체 간 관계가 중요하지 않다면 Advanced RAG(하이브리드 검색 + 리랭킹)가 더 효율적이다.
9. LightRAG 생태계의 진화
HKUDS 팀의 RAG 제품군
LightRAG를 만든 홍콩대학교 Data Science Lab(HKUDS)은 이후 관련 도구들을 연속 발표했다:
| 프로젝트 | 발표 | 특징 |
|---|
| LightRAG | 2024.10 | 경량 그래프 RAG의 기본 |
| MiniRAG | 2025.01 | 소규모/오픈소스 모델에 최적화 |
| VideoRAG | 2025.02 | 긴 비디오 컨텍스트 RAG (KDD 2026) |
| RAG-Anything | 2025.06 | LightRAG 기반 멀티모달 RAG (PDF, 이미지, 표, 수식) |
특히 RAG-Anything은 LightRAG 위에 구축되어, PDF의 표와 수식, 이미지까지 통합 처리하는 올인원 멀티모달 RAG를 제공한다.
인프라 통합 현황
LightRAG는 2025~2026년에 걸쳐 프로덕션급 인프라 통합을 빠르게 확장했다:
벡터 DB: Milvus, Chroma, Faiss, Qdrant, PGVector, MongoDB, OpenSearch
그래프 DB: Neo4j, PostgreSQL(AGE), NetworkX, OpenSearch
LLM: OpenAI, Ollama, Vertex AI(Gemini), Azure OpenAI, Amazon Bedrock, DeepSeek
배포: Docker Compose, PyPI(lightrag-hku), uv 소스 빌드
최근 주요 기능 추가 (2025)
- 출처 인용(Citation): 답변에 근거 문서를 자동 링크
- 문서 삭제: 삭제 시 지식 그래프 자동 재생성
- 리랭커 지원: 검색 결과에 리랭킹 단계 추가 가능
- WebUI 대시보드: 지식 그래프를 시각적으로 탐색
- RAGAS 평가 통합: 검색 품질을 자동으로 측정
- 다국어 지원: 한국어, 일본어, 독일어, 베트남어, 러시아어 등
10. 실전 도입 가이드
단계별 도입 경로
Phase 1: 빠른 검증 (1~2일)
hljs language-bash
pip install lightrag-hku
소규모 데이터셋(10~50개 문서)으로 기본 설정 테스트. NetworkX + NanoVectorDB로 의존성 최소화. 핵심 질문 유형에 대한 답변 품질 확인.
Phase 2: 도메인 튜닝 (1주)
개체 유형 커스터마이징. 로컬/글로벌/하이브리드 모드 중 최적 조합 탐색. 청크 크기 실험 (512~1024토큰). RAGAS로 품질 자동 측정.
Phase 3: 프로덕션 준비 (2~3주)
벡터 DB를 Milvus/Qdrant/PGVector로 교체. Neo4j 또는 PostgreSQL(AGE)로 그래프 영속화. Docker Compose로 배포. 증분 업데이트 파이프라인 구축. 리랭커 추가.
핵심 설정 팁
모드 선택:
- hybrid (기본): 대부분의 시나리오에 적합. 로컬 + 글로벌 결합
- local: 특정 개체에 대한 상세 질문이 대부분일 때
- global: 넓은 주제나 트렌드 파악이 주요 목적일 때
모델 선택:
- 프로덕션: GPT-4o-mini 또는 GPT-4o (비용 대비 품질 최적)
- 로컬 배포: Ollama + Llama 3.1 70B 이상
- 최소 요구: 32B+ 파라미터, 32K+ 컨텍스트 윈도우
마치며: "충분히 좋은" 그래프가 만드는 실질적 차이
LightRAG의 핵심 가치를 한 문장으로 정리하면:
"완벽한 지식 그래프보다, 저렴하고 빠르게 업데이트되는 '충분히 좋은' 그래프가 실전에서는 더 큰 가치를 만든다."
GraphRAG는 학술적으로 우수하고, 커뮤니티 수준의 전체 조망이 필요한 분석에서 대체 불가능하다. 하지만 대부분의 실전 시나리오에서 — 사내 문서 검색, 기술 문서 Q&A, 고객 지원 — 필요한 것은 "문서 간 관계를 활용하되, 비용과 업데이트 부담이 적은 시스템"이다.
LightRAG는 정확히 이 지점을 공략한다. 커뮤니티 계층이라는 가장 비용이 큰 구성 요소를 제거하고, 듀얼 레벨 검색으로 빈자리를 메우며, 증분 업데이트로 실시간 데이터 반영을 가능하게 한다.
물론 한계도 명확하다. 전체 조망 질문에서의 약점, 평가 방법론의 논란, 대규모 모델 요구사항. 이런 한계를 인지한 위에서 — "내 상황에서 이 트레이드오프가 합리적인가?"를 판단하는 것이 올바른 접근이다.
참고 논문 및 자료
- Guo, Z., et al. (2024). "LightRAG: Simple and Fast Retrieval-Augmented Generation." EMNLP 2025 Findings. arXiv:2410.05779.
- Edge, D., et al. (2024). "From Local to Global: A Graph RAG Approach to Query-Focused Summarization." arXiv:2404.16130.
- Feng, J., et al. (2025). "GraphRAG vs. RAG: A Systematic Evaluation." arXiv:2502.11371.
- Wu, L., et al. (2025). "How Significant Are the Real Performance Gains? Unbiased Evaluation of GraphRAG." arXiv:2506.06331.
- Gao, Y., et al. (2024). "Retrieval-Augmented Generation for Large Language Models: A Survey." arXiv:2312.10997.
- Microsoft Research. (2024). "LazyGraphRAG: Setting a New Standard for Quality and Cost."
- LightRAG GitHub Repository. github.com/HKUDS/LightRAG
- LightRAG Official Site. lightrag.github.io