블로그로 돌아가기
PathRAGGraphRAGLightRAG지식 그래프경로 기반 검색
PathRAG: 그래프에서 '경로'만 골라내면 답변이 달라진다
GraphRAG는 너무 많이 가져오고, LightRAG는 이웃을 통째로 가져온다. PathRAG는 '질문에 답하는 데 필요한 경로만' 골라내는 흐름 기반 가지치기로, 더 적은 토큰으로 더 논리적인 답변을 만든다. 논문의 핵심 아이디어부터 실전 비교까지 풀어본다.
코어닷투데이2026-01-2437분
GraphRAG는 너무 많이 가져오고, LightRAG는 이웃을 통째로 가져온다. PathRAG는 '질문에 답하는 데 필요한 경로만' 골라내는 흐름 기반 가지치기로, 더 적은 토큰으로 더 논리적인 답변을 만든다. 논문의 핵심 아이디어부터 실전 비교까지 풀어본다.
그래프 기반 RAG를 써본 사람이라면 한 번쯤 이런 의문을 가져봤을 것이다.
GraphRAG는 커뮤니티 전체를 가져온다. 커뮤니티 안에 있는 모든 개체와 관계를 LLM에 넣는다. LightRAG는 관련 개체를 찾은 뒤 그 이웃(1-hop 이웃)을 통째로 가져온다.
두 방식 모두 "혹시 필요할지 모르니 넉넉하게 가져오자"라는 전략이다. 직관적으로는 합리적이다. 하지만 정말 그런가?
실제로 이렇게 가져온 컨텍스트를 분석해보면, LLM에 전달된 정보의 상당 부분이 질문과 무관한 노이즈다. 관련 개체 A의 이웃 중에는 질문과 전혀 상관없는 B, C, D가 있고, 커뮤니티 안에는 핵심 개체 주변의 방대한 부가 정보가 딸려온다.
이 노이즈가 일으키는 문제는 이전 글에서 다룬 "Lost in the Middle" 현상과 정확히 일치한다 — 불필요한 정보 사이에 핵심이 묻혀서, LLM이 정작 중요한 것을 놓친다.
2025년 2월, 베이징우전대학교(BUPT) GAMMA Lab의 연구팀이 이 문제에 대한 답을 내놓는다.
"검색의 문제는 정보가 부족한 것이 아니라, 너무 많은 것이다."
RAG 시스템이 지식 그래프에서 "무엇을 검색해서 가져오는가"는 세대를 거치며 정교해졌다:
각 세대가 이전 세대의 문제를 해결했다:
| 세대 | 검색 단위 | 해결한 문제 | 남긴 문제 |
|---|---|---|---|
| Naive RAG | 텍스트 청크 | — | 관계 정보 없음 |
| GraphRAG | 커뮤니티 | 전체 조망 가능 | 과도한 정보량, 높은 비용 |
| LightRAG | 이웃 네트워크 | 비용 절감 | 이웃 전체를 가져와 노이즈 포함 |
| PathRAG | 관계 경로 | 노이즈 제거, 논리적 추론 구조 | 커뮤니티 수준 조망 불가 |
핵심을 짚자면: GraphRAG는 "지역 전체"를 가져오고, LightRAG는 "건물과 인접 건물"을 가져오고, PathRAG는 "건물 사이를 잇는 도로만" 가져온다. 도로(경로)만으로도 건물 간의 관계는 충분히 파악되며, 인접 건물의 내부 정보(노이즈)는 불필요하다.

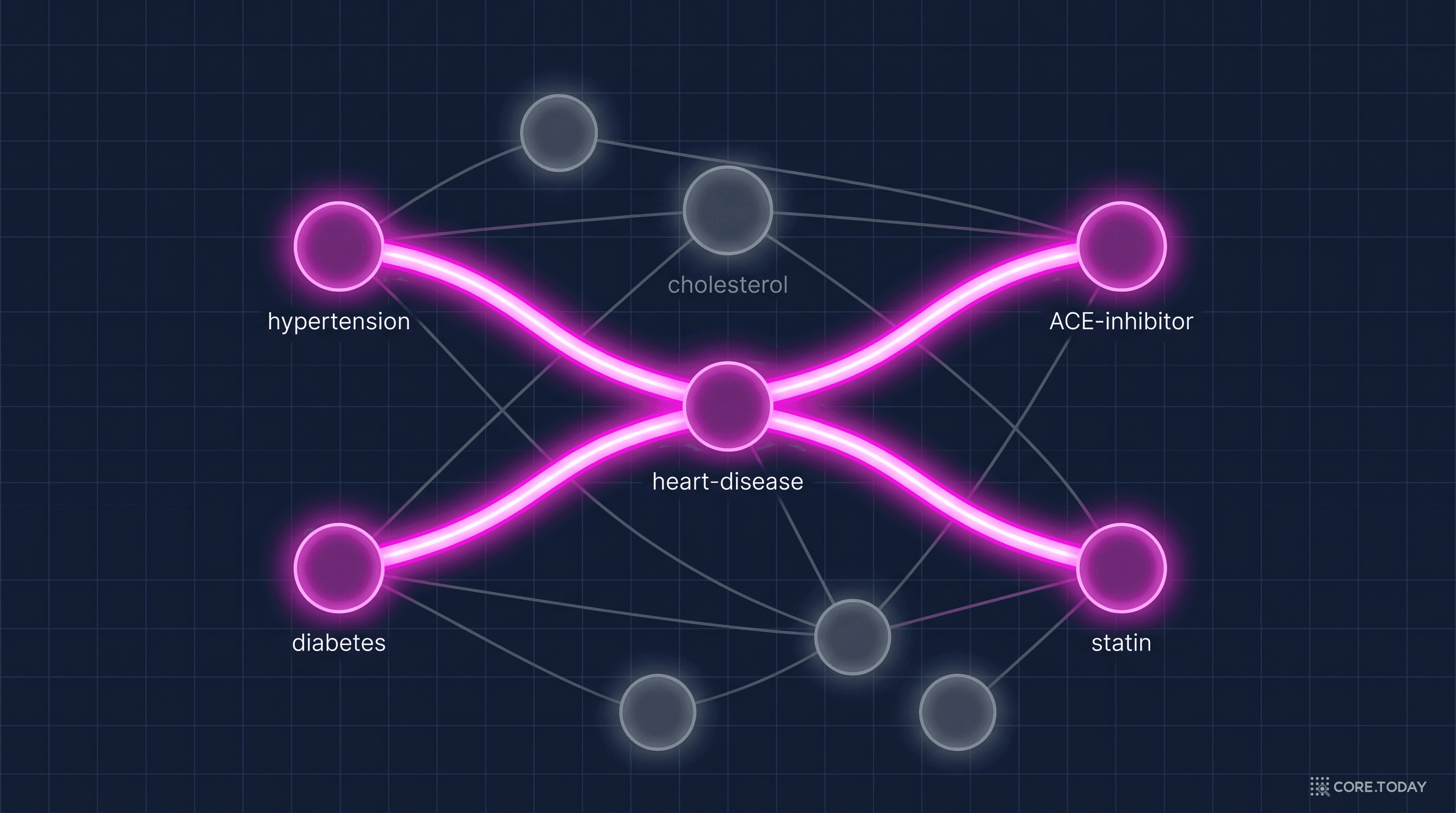
"심장 질환의 위험 인자와 치료법의 관계"를 설명해달라는 질문을 생각해보자.
인간 전문가는 이렇게 답한다:
"고혈압은 심장 질환의 주요 위험 인자다. ACE 억제제가 고혈압을 치료한다. 따라서 ACE 억제제는 심장 질환 예방에 간접적으로 기여한다."
이것은 경로다: 고혈압 → (위험 인자) → 심장 질환 ← (예방) ← ACE 억제제. 전문가는 수천 개의 의학적 사실 중에서 이 특정 경로만 선택하여 답변을 구성한다. 관련 없는 사실("심장은 분당 72회 박동한다")은 자연스럽게 배제한다.
PathRAG는 이 과정을 알고리즘으로 구현한다.
"PathRAG: Pruning Graph-based Retrieval Augmented Generation with Relational Paths"
논문의 핵심 주장:
"기존 그래프 기반 RAG 방법들의 병목은 정보 부족이 아니라 정보 과잉(redundancy)이다. 관계 경로(relational path)를 검색 단위로 사용하고, 흐름 기반 가지치기(flow-based pruning)로 노이즈를 제거하면, 더 적은 토큰으로 더 높은 품질의 답변을 생성할 수 있다."
주목할 점: 공동 저자 중 Zirui Guo는 LightRAG의 1저자이기도 하다. LightRAG의 한계를 직접 경험한 연구자가 그 다음 단계를 제안한 것이다.
PathRAG의 파이프라인은 세 단계로 구성된다.
질문에서 LLM이 키워드를 추출하고, 벡터 임베딩으로 지식 그래프의 개체 노드와 매칭한다. 상위 N개(기본값 40)를 선택한다. 이 단계는 LightRAG와 유사하다.
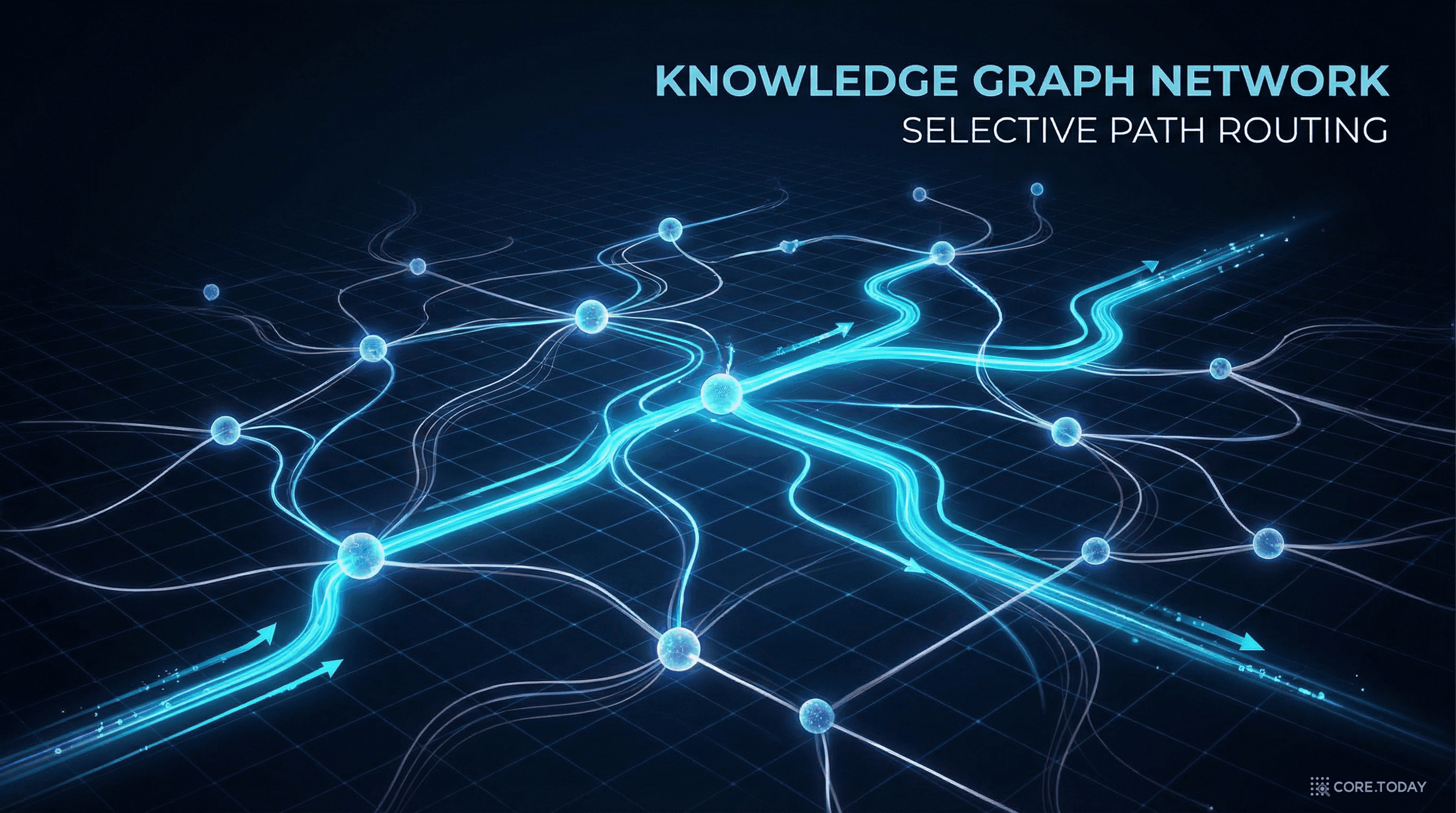
여기가 PathRAG의 핵심 혁신이다.
검색된 N개 노드 사이에는 수많은 경로가 존재한다. 이 중 질문에 가장 관련 있는 경로만 선택해야 한다. PathRAG는 이를 위해 네트워크 흐름(network flow)에서 영감을 받은 자원 전파 알고리즘(resource propagation)을 사용한다.
비유하자면 이렇다. 각 시작 노드에 1단위의 물을 붓는다고 상상하자. 물은 그래프의 엣지(도로)를 따라 흘러가되, 갈래길에서는 균등하게 나뉘고, 멀리 갈수록 증발한다(감쇠율 α). 도착 노드에 물이 많이 도달하는 경로가 "잘 연결된 경로"다.
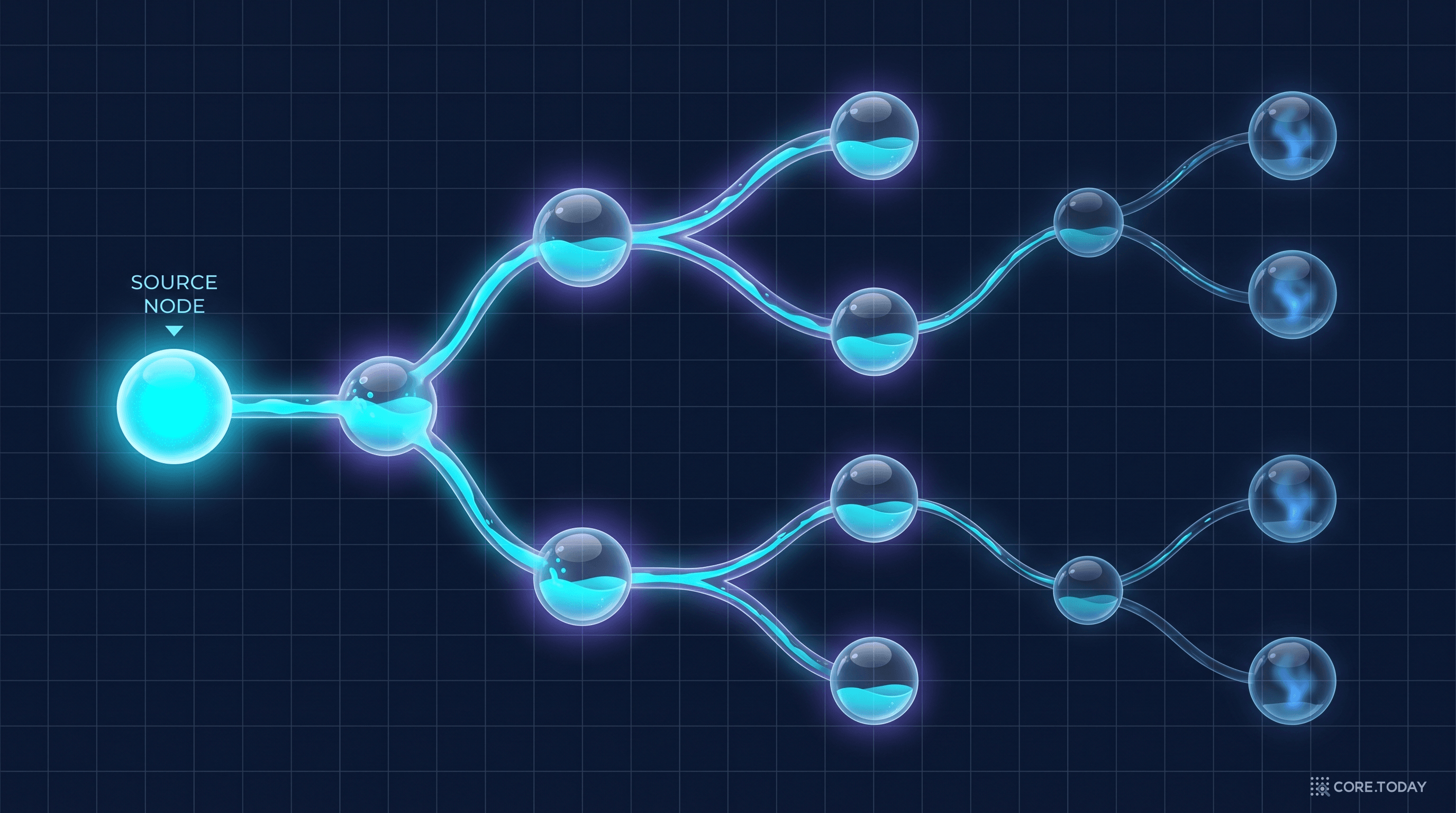
이 알고리즘의 핵심 속성은 거리 인식(distance-aware)이라는 점이다. α(감쇠율, 기본값 0.8)가 매 홉마다 곱해지므로, 먼 노드까지의 경로는 자연스럽게 낮은 점수를 받는다. 2-hop 경로는 0.8² = 0.64, 3-hop은 0.8³ = 0.512... 이런 식으로 먼 경로일수록 점수가 기하급수적으로 감소한다.
이것은 직관과도 맞는다. "심장 질환 → 고혈압 → ACE 억제제" (2-hop)는 관련성이 높지만, "심장 질환 → 고혈압 → 소금 섭취 → 한식 조리법 → 김치" (4-hop)는 갈수록 관련성이 떨어진다.
같은 질문에 대해 LightRAG와 PathRAG가 가져오는 정보를 비교해보자.
LightRAG는 "심장 질환"의 모든 이웃을 가져온다. 진단 방법(심전도, 심초음파)이나 합병증(부정맥, 심부전) 같은, 질문과 직접 관련 없는 정보까지 포함된다.
PathRAG는 "위험 인자"와 "치료법"을 잇는 경로만 가져온다. 질문이 요구하는 추론 구조에 정확히 맞는 정보만 선택된 것이다.
검색된 경로를 LLM에 전달할 때, PathRAG는 신뢰도가 낮은 경로부터 높은 경로 순서로 배치한다. 가장 신뢰도 높은 경로가 프롬프트의 맨 끝에 온다.
왜 이렇게 할까? Liu et al. (2024)의 "Lost in the Middle" 연구에서 밝혀진 것처럼, LLM은 컨텍스트의 시작과 끝에 있는 정보에 가장 주의를 기울인다. 특히 끝 부분이 답변 생성에 가장 큰 영향을 미친다. PathRAG는 이 "황금 기억 영역(golden memory region)"에 가장 중요한 경로를 배치한다.

또한 경로 형태 자체가 LLM에게 추론 구조를 제공한다. "A → B → C"라는 경로는 "A가 B를 통해 C와 연결된다"라는 논리적 흐름을 명시적으로 보여주므로, LLM이 더 논리적인 답변을 생성할 수 있다.
논문은 UltraDomain 벤치마크(428개 대학 교과서)의 6개 도메인에서 평가했다. GPT-4o-mini를 평가자로 사용하여 5가지 차원(포괄성, 다양성, 논리성, 관련성, 일관성)에서 승률을 측정했다.
도메인별 분석 — 복잡한 도메인에서 더 강하다:
| 도메인 | 문서 수 | 토큰 수 | vs LightRAG 승률 |
|---|---|---|---|
| 법률 | 94 | 4.7M | 65.5% |
| 역사 | 26 | 5.1M | 60.1% |
| 생물학 | 27 | 3.2M | 59.5% |
| 농업 | 12 | 1.9M | 57.8% |
| CS | 10 | 2.0M | 55.2% |
| 혼합 | 61 | 0.6M | 52.7% |
법률(65.5%)과 역사(60.1%)에서 가장 큰 차이를 보인다. 이 도메인들은 개체 간 관계가 복잡하고 멀티홉 추론이 빈번하다 — 정확한 경로 추출이 답변 품질에 직결되는 영역이다.
반면 혼합 도메인(52.7%)에서는 차이가 거의 없다. 문학, 전기, 철학 등 관계 밀도가 낮은 콘텐츠에서는 경로 기반 검색의 이점이 줄어든다.
주목할 점: PathRAG-lightweight(N=20, K=5)는 LightRAG 대비 44% 적은 토큰을 사용하면서도 50.69% 승률 — 실질적으로 동등한 품질을 유지한다. 적게 가져오는 것이 오히려 노이즈를 줄여 성능을 유지시키는 것이다.
| 변형 | 평균 점수 |
|---|---|
| PathRAG (흐름 기반 가지치기) | 기준 |
| 랜덤 경로 선택 | -3.25% |
| 홉 수 기반 선택 (짧은 경로 우선) | -1.67% |
| 경로 형식 제거 (평면 텍스트로 전달) | -1.86% |
흐름 기반 가지치기가 랜덤 대비 3.25%, 단순 최단경로 우선 대비 1.67% 우수. 경로 형식으로 전달하는 것도 평면 텍스트 대비 1.86% 더 효과적이다.
"관련 개체 사이의 최단경로를 찾으면 되지 않나?"라고 생각할 수 있다. 하지만 최단경로에는 문제가 있다.
예를 들어, "고혈압"과 "심장 질환"을 잇는 최단경로가 "고혈압 → 심장 질환" (1-hop)이라고 하자. 이 경로는 짧지만, "고혈압 → 동맥경화 → 관상동맥질환 → 심장 질환"이라는 3-hop 경로가 훨씬 풍부한 추론 맥락을 제공한다.
반대로, 최단경로만 쓰면 중요하지만 약간 먼 경로를 놓친다. 그렇다고 모든 경로를 쓰면 너무 많다.
PathRAG의 자원 전파 알고리즘은 경로의 길이뿐 아니라 연결 구조의 "밀도"를 반영한다.
이 접근은 Personalized PageRank(개인화된 페이지랭크)와 구조적으로 유사하지만, 특정 노드 쌍 사이에서 결정론적으로 전파한다는 점이 다르다.
| 파라미터 | 기본값 | 역할 |
|---|---|---|
| N (검색 노드 수) | 40 | 1단계에서 가져올 관련 개체 수. 너무 적으면 핵심 개체 누락, 너무 많으면 노이즈 |
| K (선택 경로 수) | 15 | 최종 프롬프트에 포함할 경로 수. 논문에서 15가 최적 |
| α (감쇠율) | 0.8 | 홉당 자원 감쇠. 0.6이면 가까운 경로만 보고, 1.0이면 감쇠 없음 |
| θ (조기 종료 임계값) | — | 자원이 이 값 이하면 더 이상 전파하지 않음 |
논문의 실험에서 α = 0.8이 최적이었다. α = 0.6(공격적 감쇠)은 먼 경로를 너무 빨리 포기하고, α = 1.0(감쇠 없음)은 거리 정보를 무시해 멀고 관련 없는 경로까지 포함한다.
질문: "이 고용 계약의 비경쟁 조항이 최근 FTC 규정과 상충하는가?"
Naive RAG: "비경쟁 조항"이 포함된 텍스트 청크를 가져온다. FTC 규정이 별도 문서에 있으면 연결하지 못한다.
LightRAG: "비경쟁 조항" 노드의 이웃 전체를 가져온다 — 이 조항을 포함하는 수십 개의 계약, 관련 법률 용어, 과거 판례 등이 모두 포함되어 컨텍스트가 비대해진다.
PathRAG: "비경쟁 조항 → (규제 대상) → FTC 규정 2024" 경로와 "비경쟁 조항 → (유효성 조건) → 지역적 범위 제한" 경로만 선택한다. 질문이 요구하는 논리적 연결만 남기고 나머지는 가지치기된다.
법률 도메인에서 PathRAG의 65.5% 승률은 이런 맥락에서 이해된다. 법률 추론은 본질적으로 "A는 B에 근거하고, B는 C와 상충하므로, A는 C에 의해 제한된다"와 같은 경로 기반 논리다.
질문: "와파린을 복용 중인 환자에게 아스피린을 동시 처방할 때의 위험은?"
PathRAG가 추출하는 경로:
이 세 경로만으로 LLM은 "두 약물의 출혈 위험이 상승적으로 증가한다"는 정확한 답변을 생성할 수 있다. LightRAG가 가져오는 "와파린의 모든 이웃"(반감기, 대사 경로, 식이 상호작용, 모니터링 프로토콜 등)의 대부분은 이 특정 질문에 불필요하다.
질문: "제1차 세계대전의 발발에 비스마르크의 외교 정책이 어떻게 기여했는가?"
이것은 전형적인 멀티홉 역사 추론이다. PathRAG는 이런 경로를 추출한다:
경로 구조 자체가 인과관계의 사슬을 명시적으로 보여주므로, LLM이 "A가 B를 야기하고, B가 C로 이어졌다"는 형태의 논리적 답변을 생성하기 쉽다. 역사 도메인 승률 60.1%는 이 강점을 반영한다.
질문: "이 마이크로서비스의 인증 실패가 결제 시스템에 영향을 미칠 수 있는가?"
기술 아키텍처 문서에서:
PathRAG는 이 의존성 체인을 경로로 추출하여, "인증 실패 → API 게이트웨이 차단 → 주문 서비스 불능 → 결제 서비스 영향"이라는 연쇄 효과를 명확히 보여줄 수 있다.
1. 커뮤니티 수준 조망 불가 "이 데이터셋의 핵심 주제 5가지"처럼 전체를 관통하는 추상적 패턴은 경로만으로 파악하기 어렵다. GraphRAG의 커뮤니티 요약이 이런 질문에는 더 적합하다.
2. 1단계 노드 검색의 오류 전파 초기 노드 검색이 핵심 개체를 놓치면, 이후 경로 검색 전체에 영향을 미친다. 경로는 검색된 노드 사이에서만 탐색되므로, 빠진 노드를 포함하는 경로는 절대 발견되지 않는다.
3. 공격적 가지치기의 부작용 α와 θ 설정에 따라 중요하지만 약간 먼 경로가 잘려나갈 수 있다. 미묘한 멀티홉 관계가 필요한 경우 주의가 필요하다.
PathRAG의 벤치마크도 LLM-as-judge 방식(GPT-4o-mini)을 사용한다. LightRAG 글에서 언급한 것처럼, 이 방식에는 위치/길이/시행 편향이 있다. 보고된 승률을 절대적 수치로 받아들이기보다, 상대적 경향으로 해석하는 것이 바람직하다.
| 상황 | 더 나은 대안 |
|---|---|
| 단순 사실 검색 ("API 엔드포인트 URL은?") | Advanced RAG |
| 전체 조망 질문 ("핵심 주제 정리해줘") | GraphRAG |
| 최소 비용이 최우선 | LightRAG-lightweight 또는 LazyGraphRAG |
| 소규모 단순 문서셋 | Naive RAG |
| 관계 밀도가 낮은 콘텐츠 (FAQ, 독립 매뉴얼) | Advanced RAG |
세 가지 그래프 기반 RAG를 나란히 놓으면:
| 차원 | GraphRAG | LightRAG | PathRAG |
|---|---|---|---|
| 검색 단위 | 커뮤니티 전체 | 개체 + 이웃 | 개체 간 경로 |
| 쿼리 토큰 | ~610,000 | ~100 (검색) + 15,837 (생성) | ~100 (검색) + 13,318 (생성) |
| 인덱싱 비용 | 높음 ($11~76/1M단어) | 중간 (~1/40) | 중간 (LightRAG와 동일) |
| 글로벌 질문 | ✓ 최강 | △ 듀얼 레벨로 부분 지원 | ✗ 경로 수준만 |
| 멀티홉 추론 | ✓ 커뮤니티 내 | △ 1-hop 이웃 | ✓ 경로 자체가 멀티홉 |
| 논리적 구조 | △ 커뮤니티 요약 | △ 평면적 컨텍스트 | ✓ 경로가 추론 구조 제공 |
| 증분 업데이트 | ✗ 재구축 필요 | ✓ 그래프 union | ✓ 그래프 union |
| 노이즈 수준 | 높음 | 중간 | 낮음 |
PathRAG의 공식 구현체(BUPT-GAMMA/PathRAG)는 풀스택 애플리케이션을 포함한다:
논문의 실험 결과를 바탕으로:
두 시스템의 인덱싱 그래프 구조가 동일하므로, 그래프를 재구축할 필요 없이 검색 모듈만 교체할 수 있다. 이것은 이미 LightRAG를 사용 중인 팀에게 큰 장점이다.
PathRAG가 증명한 것은 단순하지만 강력한 원리다:
검색의 문제는 정보 부족이 아니라 정보 과잉이다. 필요한 경로만 정확히 골라내면, 더 적은 토큰으로 더 논리적인 답변을 만들 수 있다.
이것은 RAG에만 국한되지 않는 보편적 통찰이다. 인간 전문가도 수천 개의 사실 중에서 질문에 답하는 데 필요한 몇 개의 추론 경로만 선택한다. PathRAG는 이 인간의 추론 방식을 알고리즘으로 구현한 것이다.
물론 모든 질문이 경로 기반 추론에 적합한 것은 아니다. 전체 조망, 주제 요약, 관계 밀도가 낮은 콘텐츠에서는 다른 접근법이 더 나을 수 있다. 하지만 "A와 B의 관계는?", "X가 Y에 미친 영향의 경로는?", "이 의존성 체인에서 실패 지점은?" 같은 관계 추론 질문에서 PathRAG는 현재 가장 정밀한 도구다.
참고 논문 및 자료