GPT급 거대 모델을 실시간으로, 저비용으로, 심지어 스마트폰에서도 돌리려면? 양자화, 프루닝, 지식 증류, 컴파일러 최적화까지 — AI 추론 최적화의 핵심 기법들을 실전 사례와 함께 총정리한다.
코어닷투데이2026-02-1558분
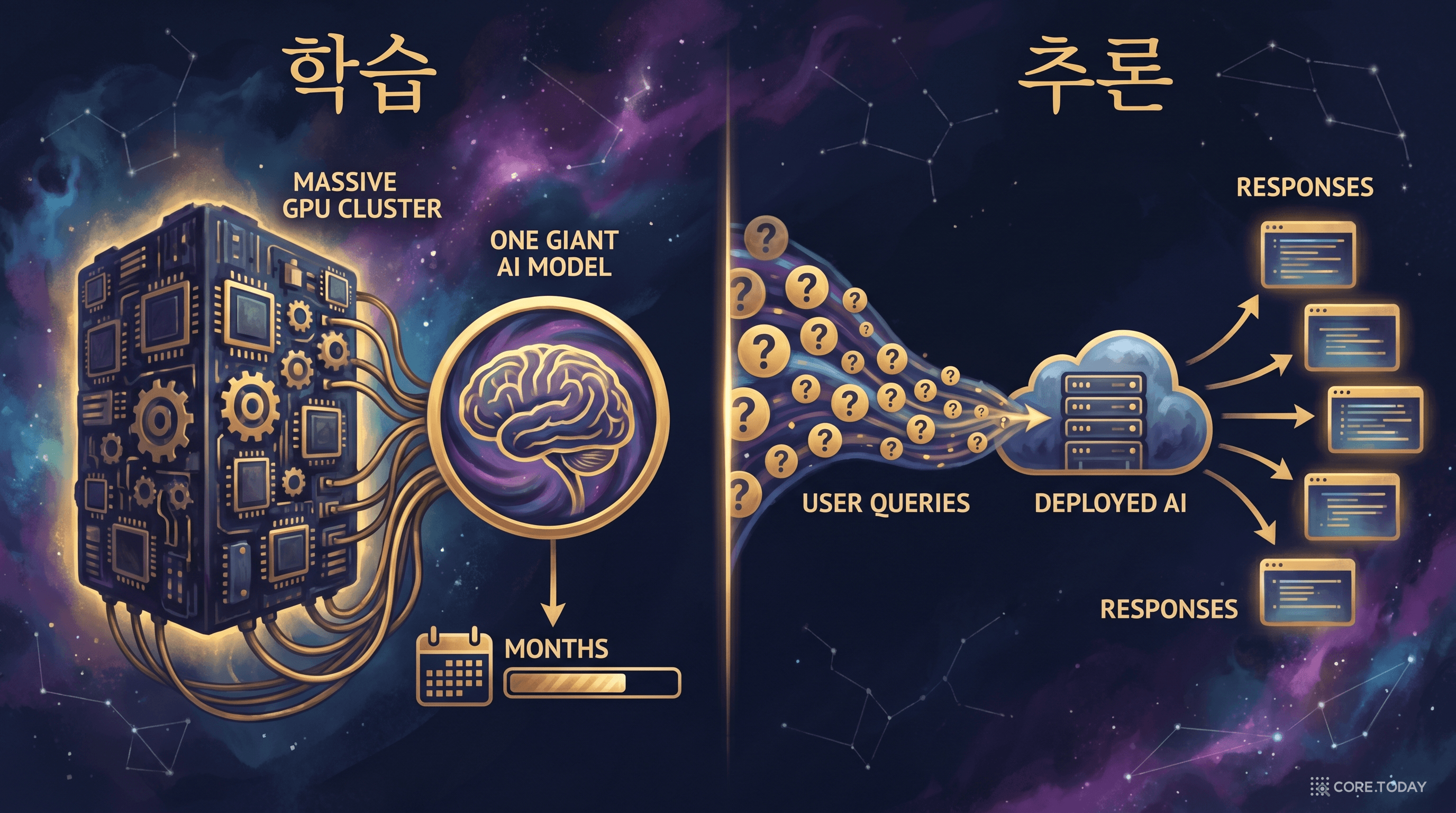
들어가며: 70만 달러가 매일 증발한다
OpenAI는 ChatGPT 운영에 하루 70만 달러 이상의 추론 비용을 지출하는 것으로 알려져 있다. 사용자 한 명이 질문 하나를 던질 때마다 약 $0.01의 컴퓨팅 비용이 발생한다. 별것 아닌 것 같지만, 주간 활성 사용자가 9억 명을 넘어서고 하루 수십억 건의 쿼리가 쏟아지는 상황에서 이 비용은 연간 수십억 달러 규모로 불어난다.
GPT-4를 한 번 학습시키는 데 약 $6,300만이 들었다고 한다. 비싸다. 하지만 학습은 한 번이다. 반면 추론은 서비스가 살아있는 한 영원히 계속된다. AI 기업의 진짜 전쟁터는 학습이 아니라 추론이다.
SmoothQuantXiao et al., ICML 2023양자화 난이도를 활성화에서 가중치로 이전. W8A8 실현. 서버 추론에 적합
llama.cpp는 특별히 언급할 가치가 있다. 불가리아 개발자 게오르기 게르가노프가 2023년 3월에 공개한 이 프로젝트는 순수 C/C++로 LLaMA를 실행하며, 어떤 의존성도 필요 없다. 이것이 "노트북에서 LLM 돌리기" 혁명의 시작이었다. 2023년 8월 도입된 GGUF 포맷은 양자화 모델 배포의 사실상 표준이 되었다.
극한의 양자화: BitNet b1.58 (1.58비트)
2024년, Ma et al.이 발표한 "The Era of 1-bit LLMs"는 AI 커뮤니티에 충격을 주었다. 가중치를 {−1,0,+1} 세 가지 값으로만 제한하는 것이다. log23≈1.58비트이므로 "1.58비트 양자화"라 불린다.
Wij∈{−1,0,+1}
이론적으로 행렬 곱셈이 덧셈과 뺄셈만으로 대체된다. 곱셈 연산이 필요 없으니 에너지 소비가 극적으로 줄어든다. 3B 규모에서 FP16 대비 메모리 10배 절감, 에너지 71배 절감이라는 결과가 보고되었다. 아직 대규모 모델에서의 검증이 필요하지만, 미래 양자화의 방향을 제시하는 연구다.
2부: 프루닝(Pruning) — 불필요한 가지를 잘라내다
핵심 원리
신경망의 가중치 중 상당수는 0에 가깝거나 중복적이다. 나무의 가지치기처럼, 이런 가중치를 제거해도 모델의 성능은 거의 변하지 않는다.
비구조적 프루닝 (Unstructured)개별 가중치 제거높은 압축률 가능 (90%+). 하지만 희소 행렬 연산이 필요하여 실제 속도 향상이 제한적
구조적 프루닝 (Structured)뉴런/헤드/레이어 단위 제거압축률은 낮지만, 표준 하드웨어에서 실제 속도 향상. 별도의 희소 연산 불필요
비구조적 프루닝은 가중치 행렬에서 개별 원소를 0으로 만든다. 이론적으로 90% 이상 제거해도 성능이 유지될 수 있지만, GPU는 밀집 행렬 연산에 최적화되어 있어 실제 속도 이점이 적다. 반면 구조적 프루닝은 어텐션 헤드, 뉴런, 심지어 레이어 전체를 제거하므로 표준 GPU에서 즉시 속도가 빨라진다.
복권 가설 (The Lottery Ticket Hypothesis)
2019년, Frankle과 Carlin이 ICLR에서 발표한 이 논문은 Best Paper를 수상하며 프루닝 연구에 새로운 방향을 제시했다.
"무작위로 초기화된 밀집 신경망 안에는, 독립적으로 학습시켜도 원본과 동일한 성능에 도달하는 희소 부분 네트워크('당첨 복권')가 존재한다."
직관적으로 말하면, 거대한 네트워크는 수많은 복권을 한꺼번에 산 것과 같다. 그중 "당첨 복권"에 해당하는 소수의 연결만 있으면 원본과 같은 성능을 낼 수 있다. 문제는 어떤 것이 당첨 복권인지 사전에 알 수 없다는 점이다.
Frantar와 Alistarh가 2023년 ICML에서 발표한 SparseGPT는 대규모 언어 모델에 프루닝을 성공적으로 적용한 첫 사례다:
OPT-175B와 BLOOM-176B를 50% 희소화 — 재학습 없이, 단일 GPU에서 4.5시간
60% 비구조적 희소화에서도 퍼플렉시티 손실이 미미
NVIDIA 2:4 구조적 희소성과 결합하면 하드웨어 가속까지 가능
NVIDIA A100/H100의 Sparse Tensor Core는 4개 연속 값 중 2개가 0인 2:4 희소 패턴을 하드웨어에서 직접 가속한다. 이론적 2배 처리량, 실측 30%+ 성능/와트 개선.
SparseGPT — 희소화율별 퍼플렉시티 변화 (OPT-175B, WikiText-2)
원본 (0%)
8.34
기준
50% 희소
8.72
+4.6%
60% 희소
9.58
+14.9%
2:4 구조적
9.13
HW 가속 가능
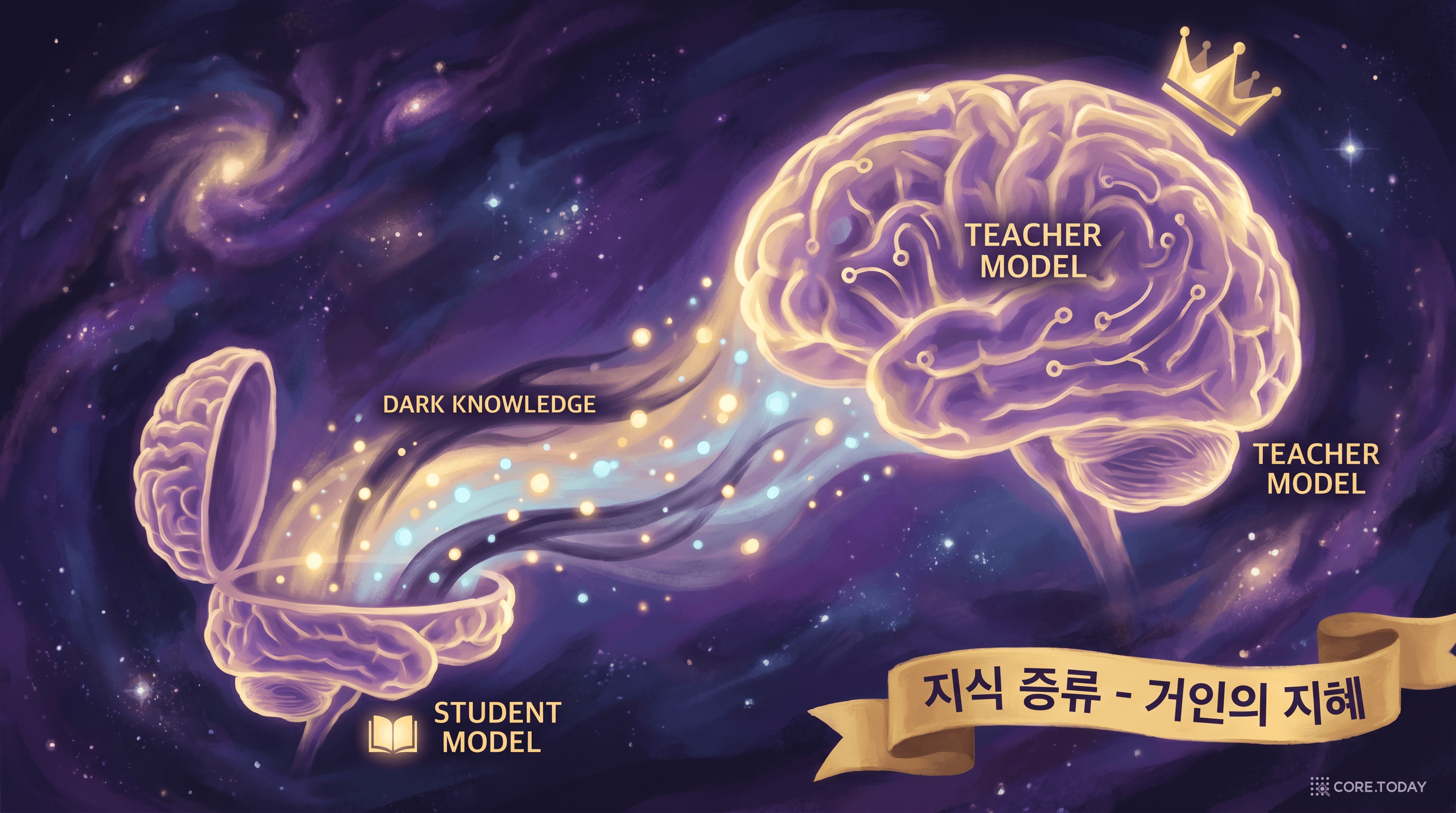
3부: 지식 증류(Knowledge Distillation) — 거인의 지혜를 난쟁이에게
Hinton의 "어둠의 지식" (2015)
2015년, Geoffrey Hinton, Oriol Vinyals, Jeff Dean이 발표한 "Distilling the Knowledge in a Neural Network"는 지식 증류의 기초를 세웠다.
핵심 아이디어: 어둠의 지식 (Dark Knowledge)
고양이 사진에 대해 교사 모델이 "고양이 99%, 개 0.5%, 호랑이 0.3%"라고 출력했다면,
"개보다 호랑이와 더 비슷하다"는 정보가 이 부드러운 확률 분포 안에 숨어 있다.
정답 라벨("고양이 100%")만으로는 절대 알 수 없는 정보 — 이것이 "어둠의 지식"이다.
DeepSeek-R1 증류 (2025)DeepSeek671B 교사 → 7B 학생이 32B 경쟁 모델 능가. 80만 추론 샘플 활용
DeepSeek-R1의 사례는 특히 주목할 만하다. 671B MoE 교사 모델이 생성한 80만 개의 추론 중심 샘플로 7B~70B 학생 모델을 학습시켰는데, 7B 증류 모델이 AIME 2024 수학 벤치마크에서 55.5%를 기록하며 32B 모델을 능가했다. 학생이 스승보다 효율적이 된 것이다.
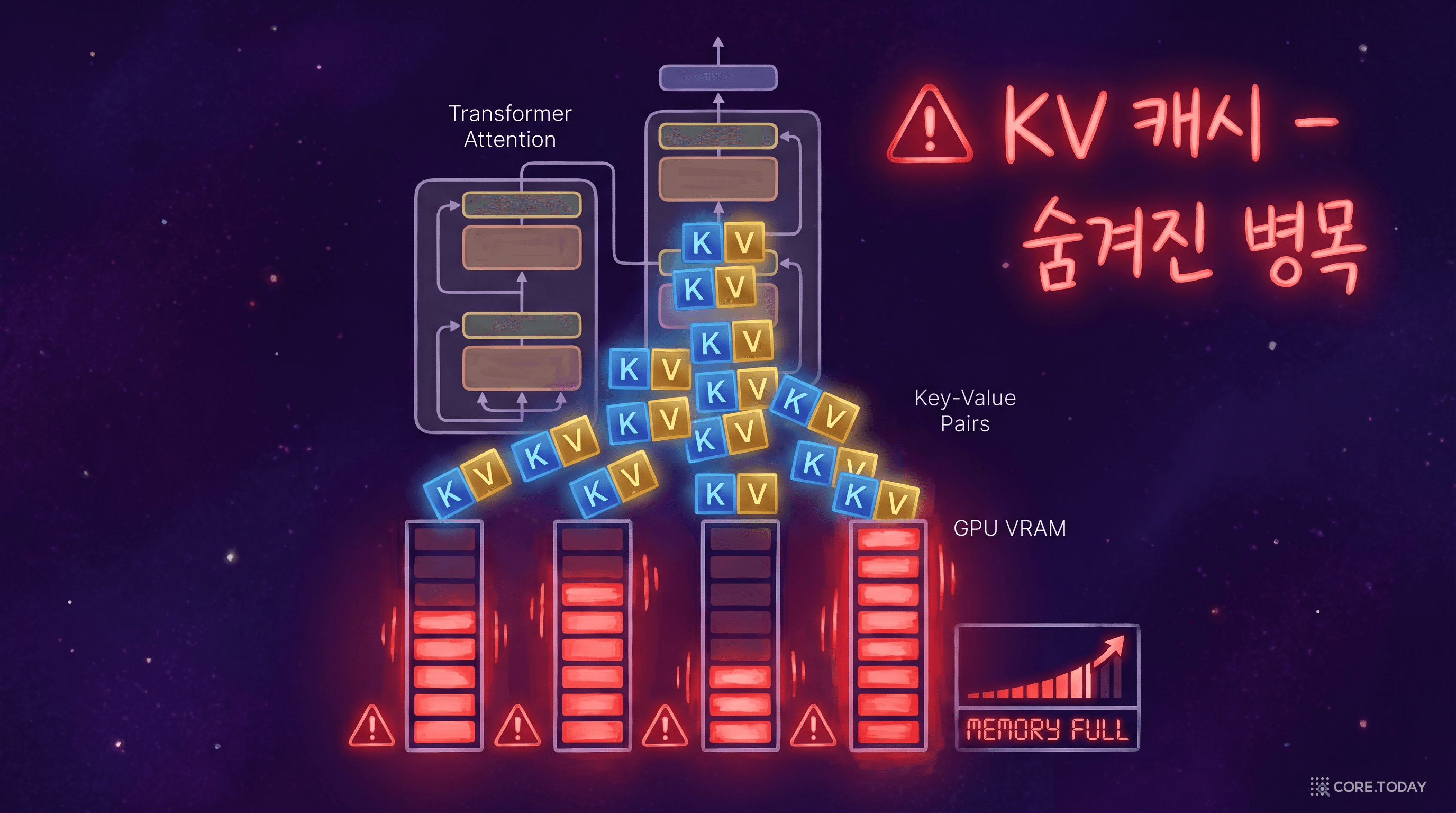
4부: KV Cache 최적화 — LLM 추론의 숨겨진 병목
KV Cache란 무엇인가
Transformer는 매 토큰 생성 시 이전 모든 토큰의 Key와 Value를 참조해야 한다. 이를 매번 다시 계산하면 낭비이므로, 계산 결과를 KV Cache에 저장한다. 문제는 시퀀스가 길어질수록 이 캐시가 급격히 커진다는 것이다.
70B 모델이 4096 토큰 시퀀스를 처리할 때 KV Cache만 수십 GB를 차지할 수 있다. 배치 크기를 늘릴수록 문제는 더 심각해진다. 모델 가중치보다 KV Cache가 더 큰 메모리를 잡아먹는 상황이 발생한다.
torch.compilePyTorch 2.0+, 2023~한 줄 추가로 평균 30~50% 속도 향상. Triton 백엔드. 점진적 도입 가능
핵심 최적화 기법들
커널 융합(Kernel Fusion): GPU에서 연산 하나를 실행할 때마다 커널 실행 오버헤드가 발생한다. 여러 연산을 하나의 커널로 병합하면 이 오버헤드를 없앨 수 있다. 예를 들어 LayerNorm + Linear + GELU를 하나의 커널로 합치면, 중간 결과를 GPU 메모리에 썼다 읽는 비용이 사라진다.
연산자 최적화(Operator Optimization): FlashAttention이 대표적이다. Tri Dao가 2022년에 발표한 FlashAttention은 어텐션 계산을 타일 단위로 쪼개어 GPU의 SRAM에서 처리함으로써, 메모리 접근을 최소화한다. 표준 어텐션 대비 2~4배 빠르고, 시퀀스 길이에 대해 메모리를 O(N2)에서 O(N)으로 줄인다.
FlashAttention:O(N2) memory→O(N) memory
7부: 하드웨어 전쟁 — 추론의 왕좌를 두고
2026년 추론 하드웨어 지형도
2026년 주요 추론 하드웨어
NVIDIA B200192GB HBM3e, 8 TB/sH100 대비 LLM 추론 최대 15배 향상. FP4 지원. 데이터센터 왕좌
NVIDIA H200141GB HBM3e, 4.8 TB/sH100 대비 추론 37% 향상. 현재 가장 널리 배포된 최신 GPU
Google TPU Ironwood192GB HBM3e, 7.4 TB/s최초의 추론 전용 TPU. 칩당 4.6 PFLOPS. Google 내부 서비스 최적화
AMD MI300X192GB HBM3, 5.3 TB/sH100 대비 메모리 대역폭 60% 우위. 가격 경쟁력. NVIDIA 대안으로 부상
Groq LPUSRAM 기반, 결정론적 실행LLaMA 3 70B: 280~300 tok/s. GPU 대비 10배 에너지 효율. 배치 1 추론 특화