들어가며: 카카오 판교 화재 — 4,700만 명이 멈춘 10시간
2022년 10월 15일 오후 3시 32분, 경기도 성남시 판교 SK C&C 데이터센터 지하 3층에서 UPS(무정전 전원장치) 배터리가 발화했다. 리튬 배터리에서 시작된 불은 급속히 번졌고, 이 데이터센터에 전적으로 의존하고 있던 카카오톡이 멈췄다.
4,700만 명의 한국인이 사용하는 국민 메신저가 10시간 이상 먹통이 되었다. 카카오톡뿐 아니라 카카오맵, 카카오택시, 카카오페이, 카카오뱅크 — 카카오 생태계 전체가 마비됐다. 택시를 잡을 수 없었고, 송금이 안 됐고, 지도가 작동하지 않았다. 국민 생활 인프라가 단일 데이터센터 의존이라는 아키텍처적 결함으로 무너진 것이다.
사태의 여파는 거셌다. 카카오 공동대표가 사임했고, 카카오는 이중화 인프라 구축에 4,600억 원의 긴급 투자를 발표했다.
P
문제
카카오 핵심 서비스가 단일 데이터센터(SPOF)에 의존. 재해 복구 아키텍처 부재.
S
대응
4,600억 원 투입, 멀티 리전 이중화 아키텍처 재설계. Active-Active DR 체계 도입.
R
교훈
아키텍처는 추상적 도면이 아니다. 국민 생활과 기업의 존망을 결정하는 설계 행위다.
이 사건이 증명한 것: 시스템 아키텍처는 기술자의 취미가 아니라, 사업의 생존 조건이다. 이 글은 DX 전문가 로드맵 10편 시리즈의 다섯 번째 편으로, "그림으로 설계하는 능력" — 시스템 아키텍처의 역사, 원리, 실전을 총정리한다.
이전 글에서 우리는 데이터 구조를 이해하는 것이 DX의 기반이라고 했다. 데이터를 저장하고 흐르게 하는 구조물 — 그것이 시스템 아키텍처다.
제1장: 시스템 아키텍처의 계보 — 폰 노이만에서 서버리스까지
1945년: 모든 컴퓨터의 원형
1945년 6월 30일, 수학자 존 폰 노이만(John von Neumann)은 "First Draft of a Report on the EDVAC"를 발표했다. 이 39페이지짜리 문서에 담긴 아이디어 — 저장 프로그램 개념(stored-program concept) — 는 이후 만들어질 모든 컴퓨터의 원형이 되었다. CPU, 메모리, 입출력, 버스 — 오늘날 우리가 사용하는 모든 컴퓨터는 여전히 이 구조 위에 있다.
81년이 지난 지금, 시스템 아키텍처는 단일 기계의 내부 구조에서 수만 대의 서버가 협력하는 분산 시스템으로 진화했다. 그 계보를 추적한다.
폰 노이만 1945
→
메인프레임 1960s
→
Client-Server 1980s
↓
3-Tier 1990s
→
SOA 2000s
→
Microservices 2014
↓
Serverless 2014~
→
Edge + AI 2024~
Client-Server (1980s): 역할의 분리
1980년대, 제록스 PARC(Xerox Palo Alto Research Center)에서 시작된 클라이언트-서버 아키텍처는 컴퓨팅의 첫 번째 대분리를 만들었다. "요청하는 쪽(Client)"과 "처리하는 쪽(Server)"을 나눈 것이다. 단순한 아이디어지만, 이 분리가 이후 모든 네트워크 아키텍처의 기본 문법이 되었다.
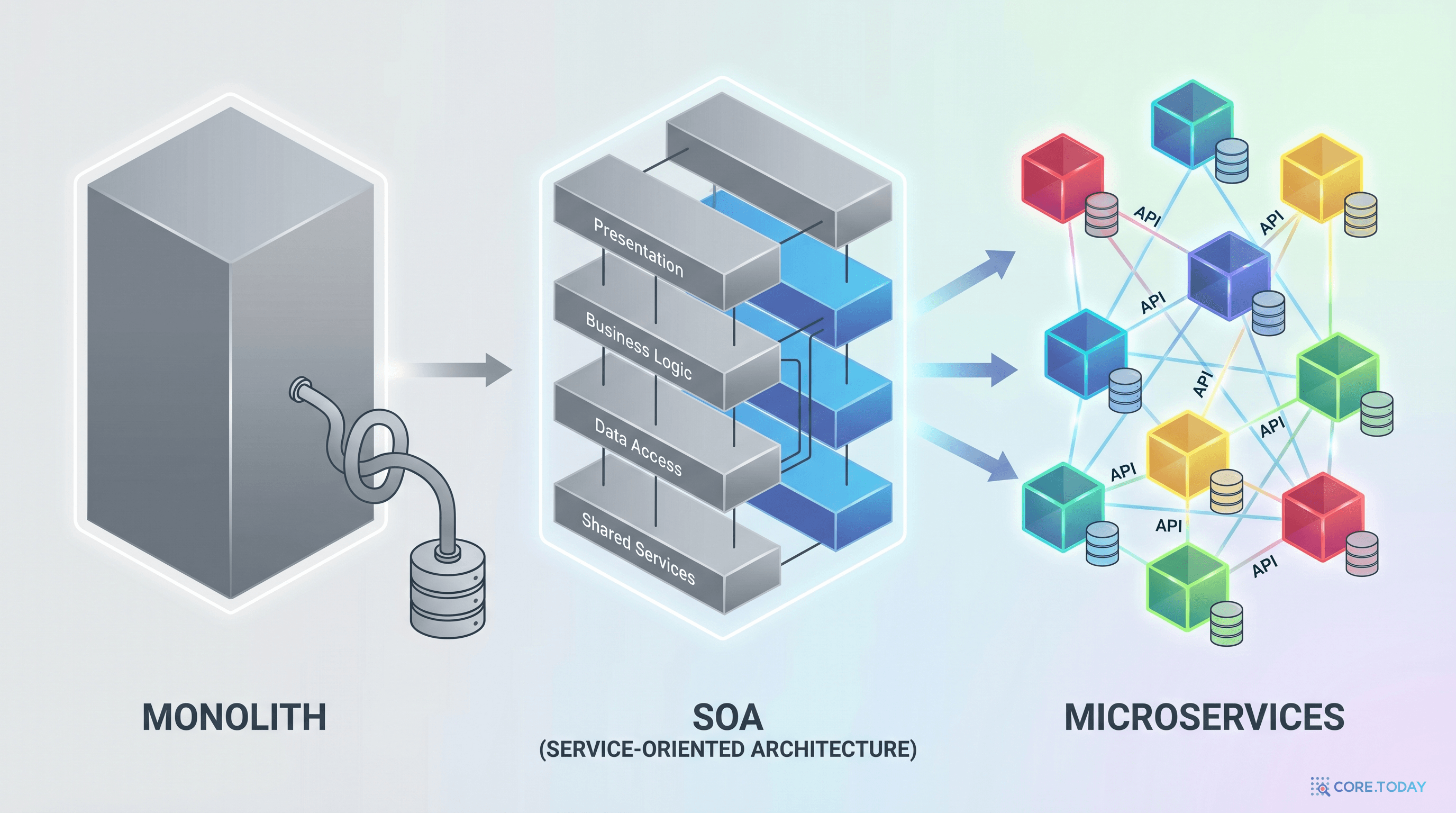
SOA (2000s): 서비스의 발견
2000년대, SOA(Service-Oriented Architecture)가 등장했다. SOAP 1.1(2000년), WSDL(2001년)이 표준화되었고, OASIS SOA Reference Model(2006년)이 공식 프레임워크로 자리잡았다. 핵심 아이디어: 비즈니스 기능을 독립적인 "서비스"로 캡슐화하고, 표준 프로토콜로 연결한다.
SOA는 올바른 방향이었지만, 실행이 무거웠다. XML 기반의 SOAP 메시지, ESB(Enterprise Service Bus)의 복잡성 — "서비스 지향"이라는 이름 아래 오히려 더 복잡한 모놀리스가 탄생하기도 했다.
Microservices (2014): 작게, 독립적으로, 빠르게
2014년 3월 25일, 제임스 루이스(James Lewis)와 마틴 파울러(Martin Fowler)가 "Microservices" 아티클을 발표했다. SOA의 정신을 계승하되, 실행을 근본적으로 바꿨다.
| 항목 | SOA (2000s) | Microservices (2014~) |
|---|
| 통신 프로토콜 | SOAP/XML (무겁다) | REST/gRPC (가볍다) |
| 통합 방식 | ESB (중앙 집중) | API Gateway (분산) |
| 배포 단위 | 서비스 그룹 단위 | 서비스별 독립 배포 |
| 데이터 저장 | 공유 DB | 서비스별 독립 DB |
| 팀 구조 | 기능별 사일로 | 서비스별 cross-functional 팀 |
Serverless (2014~): 인프라의 소멸
2014년 11월 13일, AWS Lambda가 출시되었다. 서버를 관리하지 않고 코드만 올리면 실행되는 모델 — 서버리스(Serverless)의 시작이다. "서버가 없다"는 뜻이 아니라 "서버를 생각하지 않아도 된다"는 뜻이다.
아키텍처 진화의 핵심 방향
모놀리스
1 서비스 = 1 배포 단위
단순하지만 확장 어려움
마이크로서비스
N 서비스 = N 배포 단위
독립적 확장, 복잡성 증가
서버리스
함수 단위 실행
인프라 추상화, 이벤트 드리븐
이 진화의 일관된 방향: 추상화 수준의 상승. 하드웨어 → 운영체제 → 가상머신 → 컨테이너 → 함수 — 개발자가 "관리해야 할 것"이 점점 줄어들고, "비즈니스 로직에 집중할 수 있는 것"이 점점 늘어난다.
제2장: 클라우드 아키텍처의 6가지 기둥 — AWS Well-Architected Framework
2015년, AWS는 Well-Architected Framework을 공개했다. 수십만 고객의 아키텍처 리뷰 경험을 체계화한 것이다. 원래 5개 기둥이었으나, 2021년에 지속 가능성(Sustainability) 기둥이 추가되어 현재 6개다.
AWS Well-Architected 6 Pillars
운영 우수성
Operational Excellence
IaC, 모니터링, 자동화된 운영
보안
Security
최소 권한, 암호화, 감사 추적
안정성
Reliability
자동 복구, 멀티 AZ, DR 전략
성능 효율성
Performance Efficiency
적정 리소스, 캐싱, CDN
비용 최적화
Cost Optimization
사용량 기반 과금, RI, Spot
지속 가능성
Sustainability (2021~)
에너지 효율, 탄소 발자국 최소화
이 6가지 기둥은 "좋은 아키텍처란 무엇인가?"에 대한 가장 체계적인 답이다. DX 전문가가 시스템을 설계할 때, 이 6가지를 체크리스트로 사용해야 한다. 하나의 기둥을 극대화하면 다른 기둥이 약해지는 트레이드오프 관계에 있다는 점이 핵심이다.
클라우드 시장의 현재
2026년 1분기 기준, 글로벌 클라우드 인프라 시장은 분기당 1,190억 달러(약 159조 원) 규모에 도달했다. GenAI 워크로드의 클라우드 지출 성장률은 전년 대비 140~180%에 달한다.
글로벌 클라우드 인프라 시장 점유율 (2026 Q1)
AWS가 선두를 유지하고 있지만, Azure의 추격이 빠르다. 특히 Microsoft의 OpenAI 파트너십이 Azure의 AI 워크로드 점유율을 끌어올리고 있다. GCP는 12%로 3위이나, TPU 기반의 AI 학습 인프라에서 강세를 보인다. 핵심 시사점: 클라우드 선택은 이제 "가격"이 아니라 "AI 워크로드와의 적합성"이 기준이 되고 있다.
제3장: 확장성의 설계 — "트래픽이 10배가 되면?"
DX 전문가에게 가장 자주 던져지는 질문이 있다: "이 시스템, 트래픽이 10배가 되면 괜찮나요?" 이 질문에 답하려면 확장성(Scalability)의 두 가지 축을 이해해야 한다.
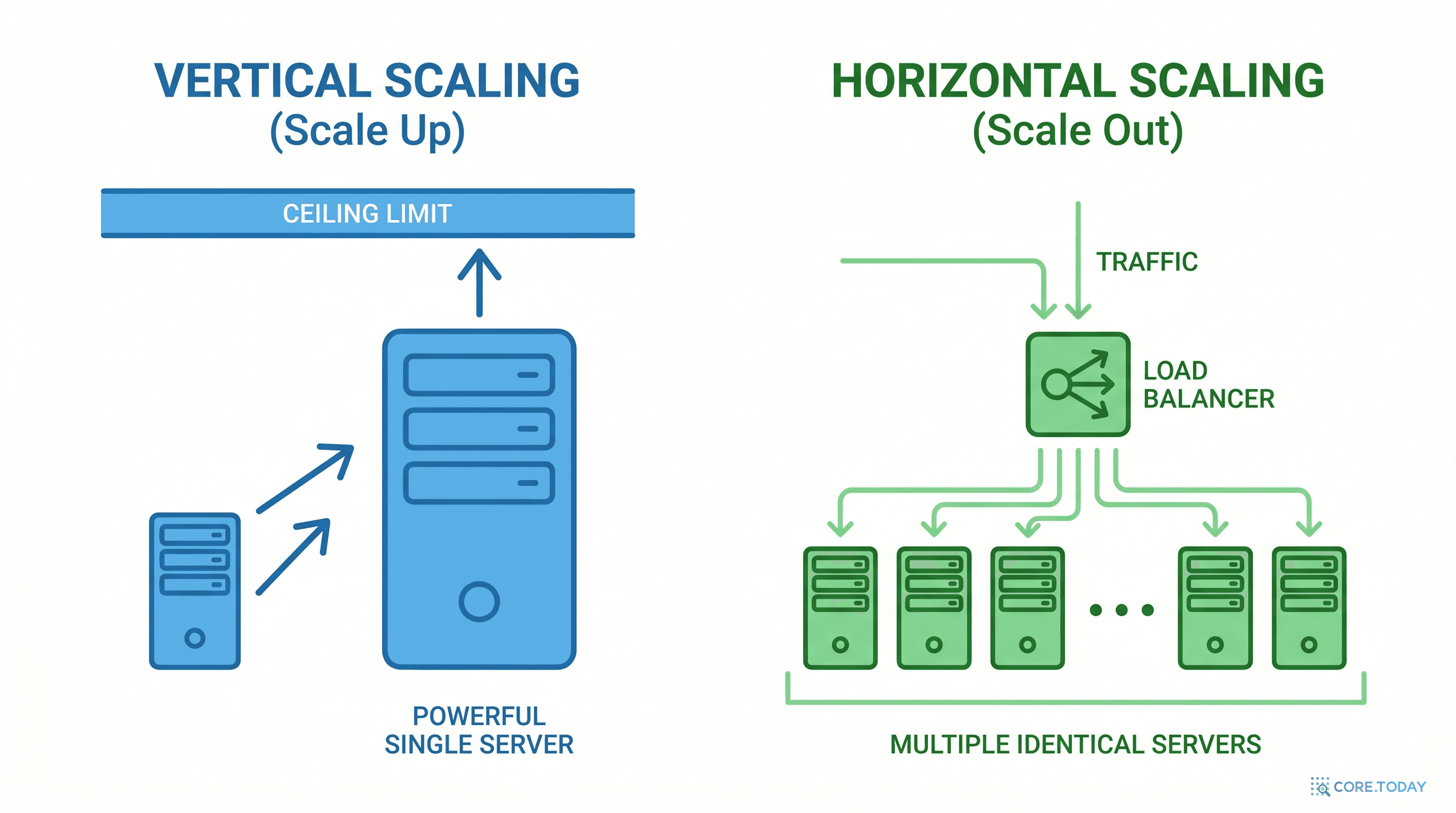
수직 확장 vs 수평 확장
| 구분 | 수직 확장 (Scale Up) | 수평 확장 (Scale Out) |
|---|
| 방법 | 더 강한 서버 1대 | 보통 서버 N대 |
| 비용 곡선 | 지수적 증가 (2배 성능 = 4배 비용) | 선형적 증가 (2배 성능 ≈ 2배 비용) |
| 한계 | 물리적 한계 존재 | 이론적으로 무한 확장 |
| 복잡성 | 낮음 (코드 변경 불필요) | 높음 (분산 시스템 설계 필요) |
| 장애 영향 | SPOF (전체 장애) | 부분 장애에 그침 |
| 대표 사례 | 메인프레임, 고성능 DB | Netflix, Google, Coupang |
현대 대규모 시스템의 정답은 명확하다: 수평 확장. 그러나 수평 확장은 공짜가 아니다. 데이터의 정합성, 네트워크 지연, 분산 트랜잭션 — 이 모든 복잡성을 관리해야 한다. 그 복잡성의 이론적 기반이 CAP 정리다.
CAP 정리: 분산 시스템의 불가능 삼각형
2000년 7월 19일, 버클리 대학의 에릭 브루어(Eric Brewer) 교수가 ACM PODC 키노트에서 혁명적인 추측을 발표했다. 2002년, MIT의 길버트(Gilbert)와 린치(Lynch)가 이를 수학적으로 증명했다.
CAP 정리: 분산 시스템은 일관성(Consistency), 가용성(Availability), 분할 내성(Partition Tolerance) 세 가지를 동시에 보장할 수 없다. 최대 두 가지만 선택 가능하다.
CAP 정리 — 세 가지 속성
일관성 (C)
Consistency
모든 노드가 항상 같은 데이터를 본다
가용성 (A)
Availability
모든 요청에 항상 응답한다
분할 내성 (P)
Partition Tolerance
네트워크 단절에도 동작한다
인터넷 기반 분산 시스템에서 네트워크 분할(P)은 피할 수 없는 현실이다. 따라서 실질적 선택지는 CP(일관성 우선) vs AP(가용성 우선)다.
| 전략 | CP (일관성 우선) | AP (가용성 우선) |
|---|
| 특성 | 네트워크 문제 시 응답 거부 가능 | 항상 응답하되 데이터 불일치 허용 |
| 적합 도메인 | 금융, 결제, 재고 | SNS, 검색, 추천 |
| 대표 시스템 | Google Spanner, CockroachDB | Cassandra, DynamoDB, Riak |
실무에서 중요한 것: 하나의 시스템 안에서도 기능별로 다른 전략을 적용한다는 점이다. 예를 들어 이커머스에서 결제 시스템은 CP, 상품 추천 시스템은 AP로 설계한다. "시스템 전체가 CP냐 AP냐"가 아니라, "어떤 데이터에 어떤 보장이 필요한가"를 기능 단위로 판단하는 것이 아키텍트의 역할이다.
캐싱: 확장성의 숨은 무기
확장성을 논할 때 빼놓을 수 없는 것이 캐싱이다. 세계에서 가장 널리 쓰이는 캐시 시스템 Redis는 초당 100만 건 이상의 연산을 1ms 미만의 지연으로 처리한다. 2026년 1월 기준 ARR(연간 반복 매출)은 3억 달러를 돌파했다.
CDN(Content Delivery Network) 시장에서는 Cloudflare가 CDN을 사용하는 웹사이트의 79.9%, 전체 CDN 시장의 40.56%를 점유하며 압도적 1위다. 전 세계 수백 개 데이터센터에서 콘텐츠를 캐싱하여, 사용자와 가장 가까운 엣지에서 응답한다.
실전: Shopify BFCM 2024
확장성 설계의 실전 교과서는 Shopify의 블랙 프라이데이/사이버 먼데이(BFCM) 2024다.
엣지 요청: 분당 28.4억 건 (peak)
DB 읽기: 초당 3,000만 건
DB 쓰기: 초당 300만 건
캐시 연산: 초당 1.45억 건
가용성: 99.999%+ 업타임
BFCM = Black Friday / Cyber Monday, 연중 최대 트래픽 이벤트
분당 28.4억 건의 엣지 요청. 이것은 초당 4,733만 건이다. 이 트래픽을 단일 서버로 처리하는 것은 물리적으로 불가능하다. Shopify가 이를 가능하게 한 것은 수평 확장된 엣지 네트워크, 다계층 캐싱, 그리고 읽기/쓰기 분리 아키텍처다.

제4장: 회복탄력성 — "장애는 반드시 온다"
확장성이 "얼마나 커질 수 있는가"의 문제라면, 회복탄력성(Resilience)은 "장애가 났을 때 어떻게 살아남는가"의 문제다. 시스템 아키텍처에서 가장 비관적이면서 동시에 가장 현실적인 전제: 장애는 반드시 온다.
Netflix Chaos Monkey — 장애를 의도적으로 만들다
2010년, Netflix는 자체 데이터센터에서 AWS로 전면 이전하면서 기묘한 도구를 만들었다. Chaos Monkey — 프로덕션 환경에서 무작위로 서버를 종료하는 프로그램이다. 2011년 기술 블로그에서 공개했고, 2012년에 오픈소스로 배포했다.
미친 짓처럼 보이지만, 논리는 명확했다:
전제
AWS에서 개별 서버는 언제든 죽을 수 있다. 이것은 확률이 아니라 확정이다.
논리
장애가 예고 없이 올 때 당하는 것보다, 일부러 만들어서 대비하는 것이 낫다.
실행
업무 시간 중 프로덕션에서 무작위 서버를 종료. 팀이 깨어 있을 때 장애를 경험.
결과
모든 서비스가 단일 서버 장애에 자동 복구되도록 설계됨. 회복탄력성이 문화가 됨.
Netflix는 이후 Simian Army로 확장했다. Chaos Gorilla(가용 영역 전체 장애 시뮬레이션), Chaos Kong(리전 전체 장애) 등 — 장애의 규모를 점점 키우면서 시스템의 내성을 테스트했다.
Circuit Breaker 패턴
2007년, 마이클 나이가드(Michael Nygard)가 저서 "Release It!"에서 서킷 브레이커(Circuit Breaker) 패턴을 소개했다. 전기 회로의 차단기에서 영감을 받은 이 패턴은, 장애가 전파(cascade)되는 것을 막는 핵심 메커니즘이다.
Closed 정상 운영
→ 실패 누적
Open 요청 차단
↓ 타임아웃 후
Half-Open 시험 요청
→ 성공 시
Closed 복구
원리: 특정 서비스 호출의 실패가 임계치를 넘으면 자동으로 회로를 끊어(Open) 더 이상 요청을 보내지 않는다. 일정 시간 후 시험 요청(Half-Open)을 보내 복구 여부를 확인하고, 성공하면 정상(Closed)으로 돌아간다. 이 패턴이 없으면, 하나의 서비스 장애가 호출 체인을 따라 전체 시스템을 마비시킨다 — 이것이 바로 카스케이드 장애다.
RPO/RTO: 재해 복구의 언어
아키텍트가 경영진에게 재해 복구(DR)를 설명할 때 사용하는 두 가지 핵심 지표:
재해 복구 핵심 지표
RPO
Recovery Point Objective
"얼마나 많은 데이터를 잃을 수 있는가?" (시간 단위)
RTO
Recovery Time Objective
"얼마나 빨리 복구해야 하는가?" (시간 단위)
RPO가 0에 가까울수록 "데이터 손실 없음"을 의미하고, RTO가 0에 가까울수록 "즉시 복구"를 의미한다. 당연히 두 값이 0에 가까울수록 비용은 기하급수적으로 증가한다.
| DR 전략 | RTO | RPO | 비용 | 적합 시나리오 |
|---|
| Backup & Restore | 수 시간 | 수 시간 | 최저 | 비핵심 시스템 |
| Pilot Light | 수십 분 | 수 분 | 낮음 | 중요 시스템 |
| Warm Standby | 수 분 | 수 초 | 중간 | 핵심 비즈니스 |
| Multi-Site Active-Active | 거의 0 | 0 (동기 복제) | 최고 | 미션 크리티컬 |
3대 장애 사례 비교
| 항목 | 카카오 (2022.10.15) | Facebook (2021.10.4) | AWS us-east-1 (2021.12.7) |
|---|
| 원인 | UPS 배터리 화재 | BGP 설정 오류 (백본 유지보수) | Kinesis 카스케이드 장애 |
| 장애 시간 | 10시간+ | 6~7시간 | 수 시간 (서비스별 상이) |
| 영향 범위 | 4,700만 사용자, 카카오 전 서비스 | 35억 사용자, FB/IG/WA | 수십 개 AWS 서비스 |
| 근본 원인 | 단일 DC 의존 (DR 부재) | 자동 복구 시스템도 BGP에 의존 | 내부 서비스 간 과도한 결합 |
| 아키텍처 교훈 | 멀티 사이트 DR 필수 | OOB(Out-of-Band) 관리 경로 | 서비스 간 의존성 격리 |
세 사건의 공통점: 장애 자체는 사소했다. 배터리 하나의 발화, 라우팅 설정 하나의 오류, 하나의 서비스의 과부하. 문제는 그 사소한 장애가 전파(propagation)되는 경로를 아키텍처가 차단하지 못했다는 것이다.
P
공통 패턴
사소한 단일 장애점(SPOF) → 카스케이드 전파 → 전체 시스템 마비
S
설계 원칙
Blast Radius 최소화: 장애의 폭발 반경을 격리하여, 하나가 죽어도 전체가 살아남게 한다.
R
실행 도구
Circuit Breaker, Bulkhead, Timeout, Retry with Backoff, Chaos Engineering
제5장: 실전 사례 — 아키텍처가 조직을 만든다
"아키텍처는 조직 구조를 반영한다." — 콘웨이의 법칙 (Melvin Conway, 1967)
Spotify 스쿼드 모델 — 아키텍처와 조직의 일치
2012년, Spotify는 급성장하는 조직(1,600명 이상 엔지니어)을 관리하기 위해 독특한 모델을 도입했다. 약 150개의 스쿼드(Squad)가 각각 하나의 마이크로서비스를 소유한다.
Spotify Engineering Culture
Squad
~8명, 자율적 미니 스타트업
하나의 기능을 End-to-End로 소유
Tribe
관련 Squad들의 집합
같은 비즈니스 영역, ~100명 이하
Chapter
같은 직군 (예: BE 개발자)
기술 역량 공유, 매니저 소속
Guild
관심사 커뮤니티
Tribe 횡단, 자발적 참여
콘웨이의 법칙이 말하는 것: 마이크로서비스 아키텍처를 원한다면, 먼저 조직을 마이크로서비스처럼 구조화해야 한다. 모놀리식 조직에서 마이크로서비스를 만들면, 결국 "분산된 모놀리스"라는 최악의 결과가 나온다.
네이버 각 세종 데이터센터 — 한국 최대 규모
네이버의 각 세종(GAK Sejong) 데이터센터는 한국 AI 인프라의 상징이다.
총 면적: 290,000m² (축구장 약 40개)
전력 용량: 270MW
수용 서버: 60만 대
저장 용량: 65 엑사바이트(EB)
HyperCLOVA X 학습을 위한 GPU 클러스터 포함. 한국 최대 규모.
290,000m²에 60만 대 서버. 이 규모의 인프라를 운영하려면 단순한 서버 관리가 아니라, 건물 자체가 하나의 시스템 아키텍처여야 한다. 전력 이중화, 냉각 시스템, 네트워크 토폴로지, 물리적 보안 — 소프트웨어 아키텍처만큼이나 물리적 아키텍처가 중요하다.
한국 금융권의 코어뱅킹 현대화
한국 금융 산업은 아키텍처 전환의 최전선에 있다.
| 은행 | 전략 | 현황 | 목표 |
|---|
| KB국민은행 | 코어뱅킹 이원화 | 메인프레임 + 클라우드 MSA 병행 | 2030년 완전 전환 목표 |
| 신한은행 | THE NEXT 프로젝트 | 2024년 5월 완료 | 5대 은행 중 최초 차세대 시스템 |
신한은행의 THE NEXT 프로젝트는 주목할 만하다. 5대 시중은행 중 최초로 차세대 시스템을 2024년 5월에 완료했다. 금융 시스템은 "절대 멈추면 안 되는" 시스템이기 때문에, 운영 중인 메인프레임을 MSA로 전환하는 것은 "날아가는 비행기의 엔진을 교체하는 것"에 비유된다.
KB국민은행은 다른 접근법을 택했다. 기존 메인프레임과 새로운 클라우드 MSA를 이원화(bifurcation)하여 병행 운영하면서, 2030년까지 점진적으로 전환한다. "빅뱅 전환"의 리스크를 피하고, "스트랭글러 패턴(Strangler Pattern)"으로 점진적 이전을 추구하는 것이다.
레거시 메인프레임
→
Anti-Corruption Layer
→
신규 클라우드 MSA
↓
Strangler Pattern: 기능 단위 점진적 이전
쿠팡: 한국의 확장성 교과서
쿠팡은 한국에서 가장 극단적인 트래픽 변동을 경험하는 기업이다. 로켓배송의 주문 폭주, 쿠팡 플레이의 스포츠 중계, 멤버십 데이 이벤트 — 평소 대비 수십 배의 트래픽 스파이크가 예고 없이 발생한다.
주문
사용자 주문 → 이벤트 큐(Kafka)로 비동기 처리. 주문 서비스와 결제 서비스 분리.
물류
주문 이벤트 → 물류 최적화 엔진 → 자동 배차. 실시간 재고 동기화.
배송
자체 물류 네트워크(쿠팡 풀필먼트) → 실시간 위치 추적 → 고객 알림.
피드백
배송 완료 이벤트 → 리뷰 시스템 → 추천 알고리즘 학습 데이터로 순환.
쿠팡이 뉴욕 증권거래소에 상장할 수 있었던 기술적 기반: 주문-결제-물류-배송-피드백 각 단계를 독립적 마이크로서비스로 분리하고, 이벤트 드리븐 아키텍처로 연결한 것이다.

제6장: 2026년 아키텍처 트렌드 — 무엇이 변하고 있는가
1. FinOps: "클라우드 비용도 아키텍처다"
클라우드의 가장 큰 함정: "쓴 만큼 낸다"가 아니라 "모르는 사이에 쓴다." 2026년 현재, 98%의 조직이 AI 관련 클라우드 지출을 별도로 관리하고 있으며, 78%가 CTO 또는 CIO에게 직접 보고한다.
P
문제
GenAI 워크로드의 클라우드 비용이 전년 대비 140~180% 증가. GPU 인스턴스 비용은 CPU 대비 10~50배.
S
FinOps 접근
비용 가시성(Visibility) → 최적화(Optimization) → 운영(Operation). 팀별 비용 할당, 태깅, 예산 알림.
R
핵심 변화
아키텍처 결정에 비용이 1급 시민(first-class citizen)으로 포함. "기술적으로 최선"이 아니라 "비용 대비 최선"이 기준.
FinOps의 핵심 통찰: 아키텍처 결정은 곧 비용 결정이다. 서버리스 vs 컨테이너, 리전 선택, 인스턴스 타입, 스토리지 계층 — 모든 아키텍처 선택에는 비용 곡선이 붙어 있다. 이것을 모르고 설계하면, 기술적으로 완벽한데 회사가 파산하는 일이 벌어진다.
2. Platform Engineering: "개발자를 위한 내부 플랫폼"
Gartner는 2026년까지 대기업의 80%가 내부 플랫폼 엔지니어링 팀을 운영할 것으로 예측한다. Platform Engineering은 인프라, CI/CD, 모니터링, 보안을 "셀프서비스 플랫폼"으로 추상화하여, 제품 개발자가 인프라를 직접 관리하지 않아도 되게 하는 것이다.
제품 개발팀
→ 셀프서비스 →
내부 개발자 플랫폼 (IDP)
↓
"당신이 DevOps를 해야 합니다"가 아니라 "당신을 위해 DevOps가 되어 있습니다". 이것이 Platform Engineering의 약속이다.
3. AI 인프라: GPU가 아키텍처를 바꾼다
2026년 AI 인프라의 핵심 하드웨어는 NVIDIA H200이다.
HBM3e 메모리: 141GB
메모리 대역폭: 4.8TB/s
H100 대비 성능: 30~50% 향상 (추론 기준)
LLM의 핵심 병목인 메모리 대역폭을 대폭 확장. 대형 모델의 실시간 서빙에 최적화.
GPU 클러스터 아키텍처는 전통적 웹 서비스 아키텍처와 근본적으로 다르다. GPU 간 통신(NVLink, InfiniBand), 모델 병렬화(Tensor Parallelism, Pipeline Parallelism), 메모리 최적화(KV Cache, Paged Attention) — 이 모든 것이 새로운 아키텍처 어휘다.
4. Zero Trust Architecture: "신뢰하지 말고, 항상 검증하라"
전통적 보안 모델은 "성 안은 안전하다(castle-and-moat)"는 전제에 기반했다. 방화벽 안쪽은 신뢰하고, 바깥만 막으면 된다는 것이다. Zero Trust는 이 전제를 뒤집는다: 아무도 신뢰하지 않는다. 내부든 외부든, 모든 접근을 매번 검증한다.
2020년 8월, NIST(미국 표준기술연구소)는 SP 800-207 "Zero Trust Architecture"를 발표하여 공식 프레임워크를 정의했다. 그 원조는 Google의 BeyondCorp(2011년 시작)으로, 구글 직원들이 VPN 없이 어디서든 사내 시스템에 접근하되, 매 요청마다 사용자, 디바이스, 컨텍스트를 검증하는 구조다.
원칙 1
Never Trust, Always Verify — 네트워크 위치가 아니라 ID와 컨텍스트로 접근 제어
원칙 2
Least Privilege — 최소 권한만 부여, 필요한 시간 동안만 유효
원칙 3
Assume Breach — 이미 침해당했다고 가정하고, Blast Radius 최소화
원칙 4
Continuous Monitoring — 모든 트래픽을 실시간 분석, 이상 행위 즉시 탐지
5. Edge Computing: 데이터가 생성되는 곳에서 처리하라
엣지 컴퓨팅 시장은 2025년 5,544억 달러에서 2026년 7,100억 달러로, CAGR 27%의 폭발적 성장을 보이고 있다.
Edge Computing 아키텍처 계층
디바이스 엣지
On-Device AI
스마트폰, IoT 센서, 카메라
네트워크 엣지
MEC / CDN PoP
기지국, ISP 엣지 서버
클라우드 엣지
Cloud Region
AWS, Azure, GCP 리전
왜 엣지인가? 자율주행 차량은 1초당 수 GB의 데이터를 생성한다. 이 데이터를 클라우드까지 보내서 처리하고 다시 받으면 수십~수백 ms의 지연이 발생한다. 시속 100km로 달리는 차에서 100ms는 2.78미터다. 장애물 앞에서 2.78미터의 차이는 생사의 차이다. 데이터가 생성되는 곳에서 즉시 처리해야 하는 이유다.
마무리: 그림으로 설계 못하면 구현 못한다
이 글의 제목이기도 한 명제: "그림으로 설계 못하면 구현 못한다."
시스템 아키텍처의 본질은 코드가 아니다. 화이트보드에 박스와 화살표를 그리는 능력 — 복잡한 시스템을 추상화하고, 구성 요소 사이의 관계를 시각화하고, 트레이드오프를 명확히 표현하는 능력이다. 이 능력이 없으면, 아무리 코딩 실력이 뛰어나도 대규모 시스템을 설계할 수 없다.
그리고 한 가지 더: 왜 그렇게 설계했는지를 기록하라.
ADR: 아키텍처 결정 기록
2011년 11월 15일, 마이클 나이가드(Michael Nygard) — Circuit Breaker 패턴을 소개한 바로 그 사람 — 가 ADR(Architecture Decision Records)을 제안했다. 아키텍처 결정을 구조화된 문서로 기록하는 것이다.
# ADR-0042: 결제 서비스를 이벤트 소싱으로 전환
상태: 승인됨 (2026-04-10)
맥락: 현재 결제 시스템은 상태 변경 이력 추적이 불가. 감사 요구사항 증가.
결정: 결제 서비스에 이벤트 소싱 패턴 적용. CQRS와 결합.
근거: 모든 상태 변경이 이벤트로 기록되어 완전한 감사 추적 가능.
결과: 초기 복잡도 증가, 이벤트 스토어 운영 비용 발생. 장기적으로 감사/컴플라이언스 비용 감소.
대안 검토: (1) CDC(Change Data Capture) — 기존 DB 유지 가능하나 이력 불완전 (2) 감사 테이블 추가 — 단순하나 스키마 변경에 취약
Michael Nygard, "Documenting Architecture Decisions" (Nov 15, 2011)
ADR이 중요한 이유: 아키텍처에서 가장 비싼 실수는 "왜 이렇게 설계했는지 아무도 모르는 상태"에서 발생한다. 6개월 후 새로운 팀원이 합류했을 때, "이 결정은 이런 맥락에서 이런 이유로 내려졌다"는 기록이 없으면, 같은 논의를 처음부터 반복하거나 — 더 나쁜 경우 — 중요한 설계 의도를 모르고 변경하다 시스템을 망가뜨린다.
DX 전문가의 다섯 번째 근육은 "그림으로 설계하는 힘"이다.
시스템 아키텍처는 화이트보드에서 시작된다. 박스와 화살표로 시작되는 이 그림이 — 4,700만 명의 서비스를 지탱하기도, 10시간 동안 멈추게 하기도 한다. 카카오의 10시간 장애, Facebook의 6시간 정전, Netflix의 Chaos Monkey — 이 모든 이야기가 말하는 것은 같다:
아키텍처는 추상적 학문이 아니다. 비즈니스의 생존 조건이다.
다음 편에서는 이 아키텍처 위에서 실제로 시스템을 운영하는 기반 — "클라우드 & 인프라"를 다룬다.
참고 자료
- John von Neumann, "First Draft of a Report on the EDVAC" (June 30, 1945)
- Eric Brewer, "Towards Robust Distributed Systems," ACM PODC Keynote (July 19, 2000)
- Seth Gilbert & Nancy Lynch, "Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services," ACM SIGACT News (2002)
- James Lewis & Martin Fowler, "Microservices" (March 25, 2014)
- Michael Nygard, Release It! Design and Deploy Production-Ready Software (Pragmatic Bookshelf, 2007)
- Michael Nygard, "Documenting Architecture Decisions" (November 15, 2011)
- AWS, Well-Architected Framework (2015~2026)
- NIST, SP 800-207: Zero Trust Architecture (August 2020)
- Netflix Technology Blog, "The Netflix Simian Army" (2011)
- Spotify Engineering, "Spotify Engineering Culture" (2014)
- Gartner, "Top Strategic Technology Trends 2026: Platform Engineering"
- Synergy Research Group, "Cloud Infrastructure Market Q1 2026"