뮌헨공대 연구팀이 제안한 Adaptive Noise Schedule이 디퓨전 모델의 PDE 에뮬레이션 정확도를 수 자릿수 개선한 원리를 쉽고 깊이 있게 파헤칩니다.
CORE.TODAY2026-04-1349분
들어가며: 500년 된 문제에 AI가 도전하다
레오나르도 다빈치는 1508년 노트에 물의 소용돌이를 스케치하며 이렇게 적었습니다.
"물의 움직임을 관찰하라. 그것은 머리카락과 닮았다. 일부는 거대한 흐름에 속하고, 일부는 작은 소용돌이 속에 빙빙 돈다."
500년이 지난 지금, 우리는 유체의 움직임을 편미분방정식(PDE)으로 정밀하게 기술할 수 있게 되었습니다. 나비에-스토크스 방정식(Navier-Stokes equations)은 유체역학의 핵심으로, 기상 예측부터 항공기 설계, 반도체 냉각 시스템까지 현대 공학의 근간을 이룹니다.
하지만 문제가 있습니다. 나비에-스토크스 방정식을 정확히 푸는 것은 수학에서 가장 어려운 문제 중 하나입니다. 실제로 이 방정식의 해의 존재성과 매끄러움을 증명하는 것은 클레이 수학연구소의 밀레니엄 7대 문제 중 하나로, 100만 달러의 상금이 걸려 있죠.
수치 시뮬레이션의 딜레마
현실적으로 우리는 수치적 방법(CFD: Computational Fluid Dynamics)으로 이 방정식을 근사합니다. 격자를 아주 촘촘하게 나누고, 시간을 아주 잘게 쪼개서, 각 점에서의 유체 상태를 반복적으로 계산합니다. 이 방법은 정확하지만:
시간이 엄청나게 오래 걸립니다. 3D 난류 시뮬레이션 하나에 수천 CPU 코어로 수 주가 필요합니다.
비용이 막대합니다. 2024년 기준 대형 기상 예측 모델 하나의 연간 슈퍼컴퓨터 비용이 수백억 원에 달합니다.
실시간 예측이 불가능합니다. 항공기 설계에서 100가지 변형을 테스트하려면 몇 달이 걸립니다.
P
전통 수치 시뮬레이션의 한계
고해상도 3D 난류 시뮬레이션 하나에 수천 CPU 코어 × 수 주의 계산 시간이 필요
S
AI 뉴럴 에뮬레이터의 등장
학습된 뉴럴 네트워크가 PDE 솔버를 대체하여 수천 배 빠른 예측을 제공
R
남은 과제: 정확도와 안정성
빠르지만 장기 예측에서 오차가 축적되고, 물리적으로 비현실적인 아티팩트가 발생
이러한 한계를 극복하기 위해, AI 기반 뉴럴 에뮬레이터가 등장했습니다. 수치 시뮬레이션 데이터로 학습한 뉴럴 네트워크가, 같은 PDE를 수천 배 빠르게 근사할 수 있다는 아이디어입니다.
디퓨전 모델: 이미지 생성에서 물리 시뮬레이션까지
디퓨전 모델이란?
2020년 Ho et al.의 DDPM(Denoising Diffusion Probabilistic Models) 논문 이후, 디퓨전 모델은 이미지 생성 분야를 혁신했습니다. Stable Diffusion, DALL-E, Midjourney 등 우리가 매일 사용하는 이미지 생성 AI의 핵심 기술이죠.
원리는 놀랍도록 단순합니다:
Forward
깨끗한 데이터에 점진적으로 가우시안 노이즈를 추가하여 순수한 노이즈로 만든다
학습
뉴럴 네트워크가 각 노이즈 레벨에서 추가된 노이즈를 예측하도록 학습한다
Reverse
순수한 노이즈에서 시작하여 학습된 모델로 단계적으로 노이즈를 제거하며 깨끗한 데이터를 복원한다
수학적으로, 노이즈 추가 과정(forward process)은 다음과 같습니다:
y~t=αˉt⋅y+σt⋅ϵ,ϵ∼N(0,I)
여기서 αˉt는 신호 보존 계수, σt=1−αˉt는 노이즈 레벨, y는 원본 데이터입니다. 시간 t가 증가할수록 노이즈가 많아지고 원본 신호는 사라집니다.
역과정(reverse process)에서 모델은 각 스텝에서 노이즈를 예측하고 제거합니다:
y^t−1=αˉt−1⋅y^est(y^t,x,σt)+σt−1⋅ϵt
PDE 에뮬레이션에 디퓨전을 적용하면?
유체역학 시뮬레이션에서 디퓨전 모델은 이렇게 작동합니다:
조건(condition): 현재 시점의 유체 상태 xk (속도장, 압력 등)
타겟(target): 다음 시점의 유체 상태 xk+1
생성: 노이즈에서 시작하여 조건부 디노이징으로 다음 상태를 예측
자기회귀(autoregressive): 예측된 상태를 다시 조건으로 사용하여 연쇄적으로 시뮬레이션
x⁰ (초기 조건)
→
M_θ(x⁰)
→
x̂¹ (예측)
→
M_θ(x̂¹)
→
x̂² ...
이 접근법은 결정론적(deterministic) 모델에 비해 여러 장점이 있습니다:
불확실성 추정: 같은 조건에서 여러 샘플을 생성하여 예측의 신뢰도를 측정
장기 안정성: 확률적 특성이 오차 축적을 어느 정도 완화
유연성: 초해상도, 예측, 데이터 동화 등 다양한 태스크에 활용 가능
2023년 GenCast(Price et al.)는 디퓨전 기반 날씨 예측 모델이 기존 수치 모델의 정확도를 능가할 수 있음을 보여주었고, Kohl et al.(2023)은 자기회귀 디퓨전이 난류 시뮬레이션에서 뛰어난 장기 안정성을 달성함을 입증했습니다.
그런데 결정적인 문제가 하나 있습니다.
핵심 문제: 디퓨전 모델은 왜 정확하지 않은가?
디퓨전 모델이 아름다운 이미지를 만들어내는 것과, 특정 물리 시스템의 정확한 궤적을 재현하는 것은 전혀 다른 문제입니다.
"비슷한" 것과 "정확한" 것의 차이
이미지 생성에서는 FID(Frechet Inception Distance)처럼 분포적 유사성을 측정합니다. "이 고양이 사진이 진짜 고양이 사진의 통계적 분포와 비슷한가?"가 핵심이죠. 어떤 특정 고양이를 정확히 재현할 필요는 없습니다.
하지만 PDE 에뮬레이션에서는 상황이 다릅니다. 항공기 날개 주변의 충격파 위치가 1mm만 달라져도 설계 판단이 완전히 달라집니다. 기상 예측에서 태풍의 경로가 조금만 어긋나도 대피 계획이 바뀝니다.
기준
이미지 생성
PDE 에뮬레이션
목표
분포적 유사성 (FID)
궤적 정확도 (MSE)
허용 오차
높음 (다양성이 미덕)
매우 낮음
자기회귀
보통 단일 생성
수백 스텝 연쇄 예측
오차 축적
해당 없음
치명적 (아티팩트 발생)
노이즈 스케줄 최적화
지각적 품질 중심
재구성 정확도 중심
Exposure Bias: 학습과 추론의 괴리
여기서 이 논문의 핵심 개념이 등장합니다: Exposure Bias(노출 편향).
NLP에서 자기회귀 언어 모델을 학습할 때 발생하는 문제와 본질적으로 같습니다:
학습(Training) 시: 모델은 항상 정답 데이터에 노이즈를 추가한 깨끗한 입력(y~t)을 봅니다.
추론(Inference) 시: 모델은 자기 자신의 이전 예측에서 생성된 입력(y^t)을 봅니다.
이 두 입력의 분포가 다릅니다. 학습 때 본 적 없는 오차 패턴이 추론 입력에 포함되어 있기 때문에, 모델의 예측이 점점 정답에서 벗어나게 됩니다.
논문에서는 이 현상을 정량화하기 위해 Reconstruction Exposure-Bias(REB)를 정의합니다:
REB(t)=Eclean(t)Einf(t)
Eclean(t): 정답에 노이즈를 추가한 입력으로부터의 복원 오차
Einf(t): 추론 과정에서 모델이 실제로 보는 입력으로부터의 복원 오차
REB가 1이면 편향이 없고, 1보다 크면 추론 시 오차가 더 크다는 뜻입니다.
두 가지 Exposure Bias의 연결
이 논문의 빛나는 통찰은 PDE 디퓨전 모델에는 두 가지 서로 다른 exposure bias가 존재하고, 이 둘이 깊이 연결되어 있다는 발견입니다.
1. Diffusion Exposure Bias (디퓨전 노출 편향)
디노이징 과정 내부에서 발생합니다. 모델이 T 스텝에 걸쳐 노이즈를 점진적으로 제거하는 과정에서, 각 스텝의 예측 오차가 다음 스텝의 입력에 영향을 미칩니다.
2. Simulation Exposure Bias (시뮬레이션 노출 편향)
자기회귀 예측 과정에서 발생합니다. 이전 시간 스텝의 예측값을 다음 스텝의 조건으로 사용할 때, 오차가 시간에 따라 축적됩니다. 이것이 장기 시뮬레이션에서 아티팩트가 발생하는 원인입니다.
Diffusion Exposure Bias
디노이징 스텝 내부 노이즈 스케줄에 의해 제어 REB = Einf/Eclean
⟷
Simulation Exposure Bias
자기회귀 스텝 간 Unrolled Training으로 완화 아티팩트의 주요 원인
논문의 핵심 발견
Diffusion Bias를 줄이면 Simulation Bias를 효율적으로 해결할 수 있는 프록시가 생긴다
핵심 연결고리: 디퓨전 exposure bias가 충분히 작으면, 전체 디노이징 체인을 실행하지 않고도 마지막 몇 스텝만으로 모델의 실제 출력을 근사할 수 있습니다. 이 근사를 프록시(proxy)로 사용하면, 기존에는 계산 비용 때문에 불가능했던 unrolled training을 디퓨전 모델에도 적용할 수 있게 됩니다.
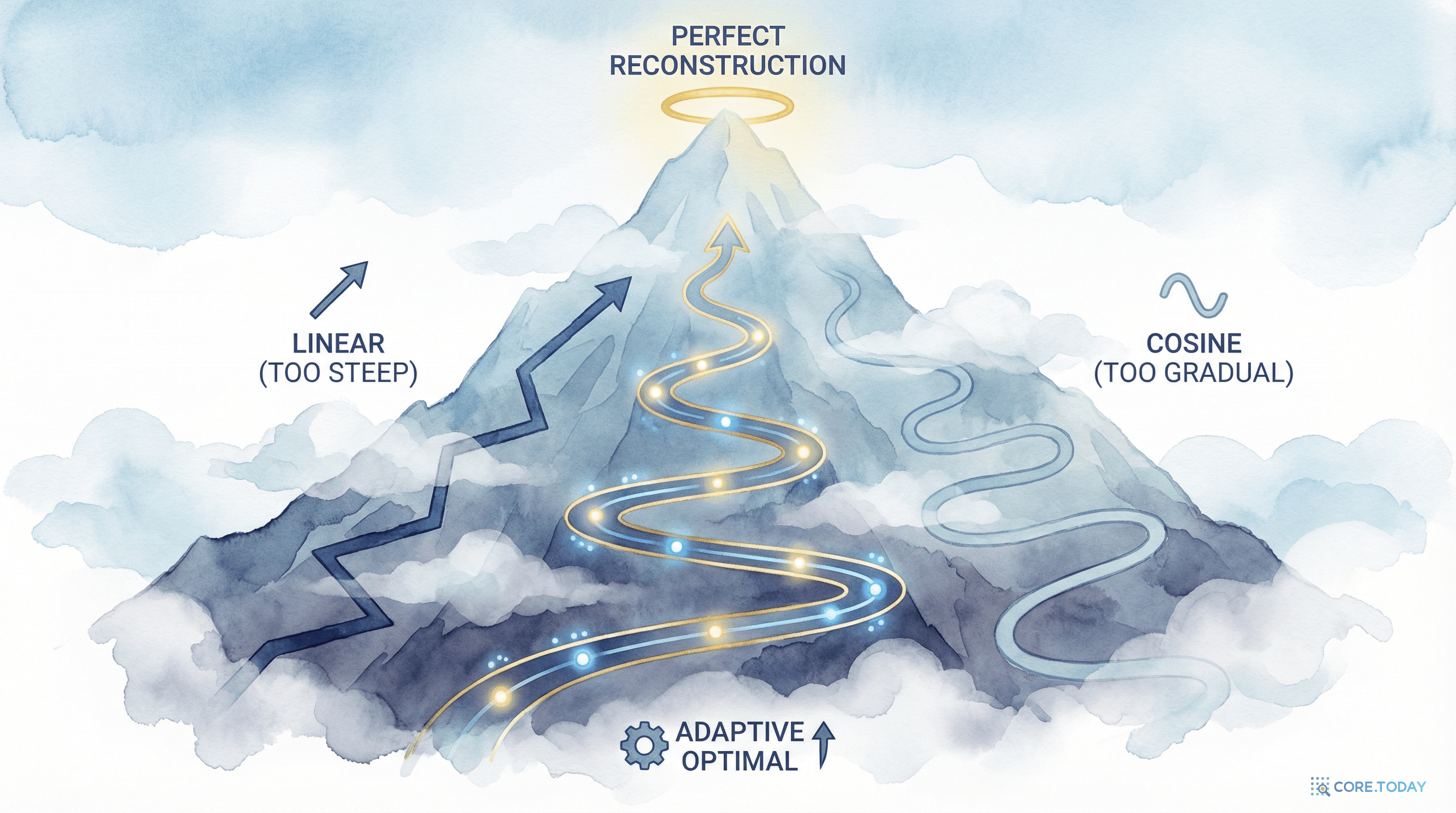
왜 노이즈 스케줄이 중요한가?
노이즈 스케줄의 역할
디퓨전 모델에서 노이즈 스케줄은 디노이징 과정의 각 스텝에서 노이즈가 얼마나 줄어드는지를 결정합니다. 이것은 마치 산을 내려오는 등산로를 설계하는 것과 같습니다:
Linear 스케줄: 일정한 간격으로 내려옵니다. 단순하지만, 어려운 구간과 쉬운 구간을 구분하지 못합니다.
Cosine 스케줄: 중간 노이즈 레벨에 더 많은 스텝을 할당합니다. 이미지 생성에서는 효과적이지만, PDE에서는 낮은 노이즈 레벨이 더 중요합니다.
Sigmoid 스케줄: 양 끝(높은 노이즈와 낮은 노이즈)에 집중합니다.
이미지 생성에서 이 스케줄들은 잘 작동합니다. 왜냐하면 이미지에서 지각적으로 중요한 특징은 중간 노이즈 레벨에서 나타나기 때문입니다. 얼굴의 윤곽은 노이즈가 꽤 높을 때도 보이지만, 피부 결 같은 세부사항은 낮은 노이즈에서야 드러납니다.
하지만 PDE 에뮬레이션에서는 최종 재구성 정확도가 핵심입니다. 유체의 작은 소용돌이 하나가 나비효과처럼 전체 흐름을 바꿀 수 있으므로, 노이즈가 거의 제거된 마지막 단계에서의 정확도가 결정적으로 중요합니다.
논문의 핵심 발견: "느린 오차 감소 원리"
논문은 Figure 2(아래 재구성)에서 매우 흥미로운 실험 결과를 보여줍니다.
스케줄별 최종 재구성 오차 (낮을수록 좋음)
Low-Level Focus
높은 Clean 오차 + REB 폭발
Linear
중간 수준의 REB
Cubic (고노이즈 집중)
REB 시작, 정확도 한계
Adaptive (본 논문)
최적
낮은 노이즈 레벨에 많은 스텝을 할당하면 직관적으로는 최종 정확도가 좋아야 합니다. 하지만 실제로는:
낮은 노이즈에 집중하면 clean-input 오차는 낮아지지만, 높은 노이즈 레벨에서의 큰 스텝 크기가 REB를 폭발시킵니다.
높은 노이즈에 집중하면 REB는 작지만, 낮은 노이즈에서 오차를 충분히 줄이지 못합니다.
이 딜레마를 해결하는 것이 바로 느린 오차 감소 원리(Slow Error Decrease Principle)입니다:
각 디노이징 스텝에서 모델이 안정적으로 처리할 수 있는 만큼만 노이즈를 줄여야 한다. 불필요하게 큰 점프는 exposure bias를 증폭시키고, 불필요하게 작은 점프는 모델 용량을 낭비한다.
Adaptive Scheduling Algorithm: 핵심 기술
논문의 첫 번째 핵심 기여는 안정성 제약 기반 적응적 스케줄링 알고리즘입니다. 이 알고리즘은 두 단계로 구성됩니다.
Phase 1: 탐색 (Exploration)
먼저, 로그 균등 분포의 촘촘한 노이즈 레벨 격자에서 모델을 학습시키며, 각 레벨에서의 안정성 임계값을 발견합니다.
초기화
촘촘한 로그 균등 탐색 스케줄 σexp = {σ(1), ..., σ(N)} 설정
학습
모든 활성 노이즈 레벨에서 모델 학습. 주기적으로 B(own)(t) 평가
판정
B(own) ≤ τ이면 "해결됨" → 체크포인트 저장 후 활성 스케줄에서 제거
반복
활성 스케줄이 점점 축소되므로 후반 에폭이 더 빠름. 새로 해결되는 레벨이 없으면 종료
여기서 Own-Prediction BiasB(own)(t)는 모델이 자신의 예측을 입력으로 받았을 때 오차가 얼마나 증폭되는지를 측정합니다:
B(own)(t)=Eclean(t)Eϵ∥yest(y^t(own))−y∥
B(own)≈1이면 모델이 해당 노이즈 레벨에서 안정적이라는 뜻이고, B(own)≫1이면 불안정하다는 뜻입니다.
Proposition 3.4에 따르면, 안정성 임계값은 노이즈 레벨이 높을수록 더 관대하고, clean-input 오차가 작을수록 더 안정적입니다. 직관적으로, 노이즈가 많은 상태에서는 약간의 추가 오차가 상대적으로 미미하지만, 노이즈가 거의 제거된 상태에서는 작은 오차도 치명적이라는 뜻입니다.
Phase 2: 탐욕적 스케줄 구축 (Greedy Construction)
탐색 단계에서 얻은 체크포인트들을 이용하여, 가장 큰 안정적 점프를 반복적으로 선택합니다:
스텝 수 T가 자동으로 결정됩니다. 태스크의 난이도에 따라 필요한 스텝 수가 다르고, 알고리즘이 이를 자동으로 찾습니다.
모든 중간 노이즈 레벨이 필수적입니다. 불필요한 스텝이 없으므로, 모델 용량이 낭비되지 않습니다.
Phase 2는 forward pass만 필요합니다. 그래디언트 계산이 없으므로 계산 비용이 무시할 수 있을 정도입니다.
알고리즘 의사코드
Algorithm 1: Phase 1 — 안정성 탐색
입력: bias 허용치 τ, 탐색 격자 σexp, 모델 θ 반복:
1. 활성 스케줄에서 모델 학습 (1 에폭)
2. 각 활성 레벨 σ에 대해 B(own)(σ) 계산
3. B(own) ≤ τ인 레벨: 체크포인트 저장, 활성에서 제거
4. 새로 해결된 레벨이 없으면 종료 출력: {θ*(σ)}σ ∈ σˢᵒˡᵛᵉᵈ
Algorithm 2: Phase 2 — 탐욕적 스케줄 구축
입력: 체크포인트들, bias 허용치 τ
σ₀ ← min σˢᵒˡᵛᵉᵈ
t ← 0 반복:
σt+1 ← max{σ' ∈ σˢᵒˡᵛᵉᵈ : B(2S)(σt, σ') ≤ τ}
σt+1 = σT이면 종료
t ← t + 1 출력: S* = {σ₀, σ₁, ..., σT}
Proxy Unrolled Training: 효율적 안정화
디퓨전 모델의 두 번째 큰 문제는 simulation exposure bias입니다. 결정론적 모델에서는 이 문제를 unrolled training으로 해결합니다 — 학습 시 여러 자기회귀 스텝을 펼쳐서 모델이 자신의 오차에 적응하도록 학습시키는 것이죠.
하지만 디퓨전 모델에서 이것은 계산적 악몽입니다:
항목
결정론적 모델
디퓨전 모델 (나이브)
Proxy UT (본 논문)
한 스텝 비용
1 forward pass
T forward passes (~20)
n forward passes (~1)
U=2 unrolled 비용
2 forward + backprop
2T forward + backprop
2+n forward + backprop
실용성
가능
불가능
가능
프록시 추정의 원리
논문의 핵심 아이디어: 디퓨전 exposure bias가 충분히 작으면, 마지막 n 스텝만으로 전체 디노이징 과정을 근사할 수 있다.
첫 번째 항은 일반적인 디퓨전 손실이고, 두 번째 항이 프록시 unrolled 손실입니다. 모델은 자신의 (근사된) 예측을 조건으로 받아 다음 스텝을 예측하는 법을 배우게 됩니다.
실험 결과: 세 가지 벤치마크에서의 검증
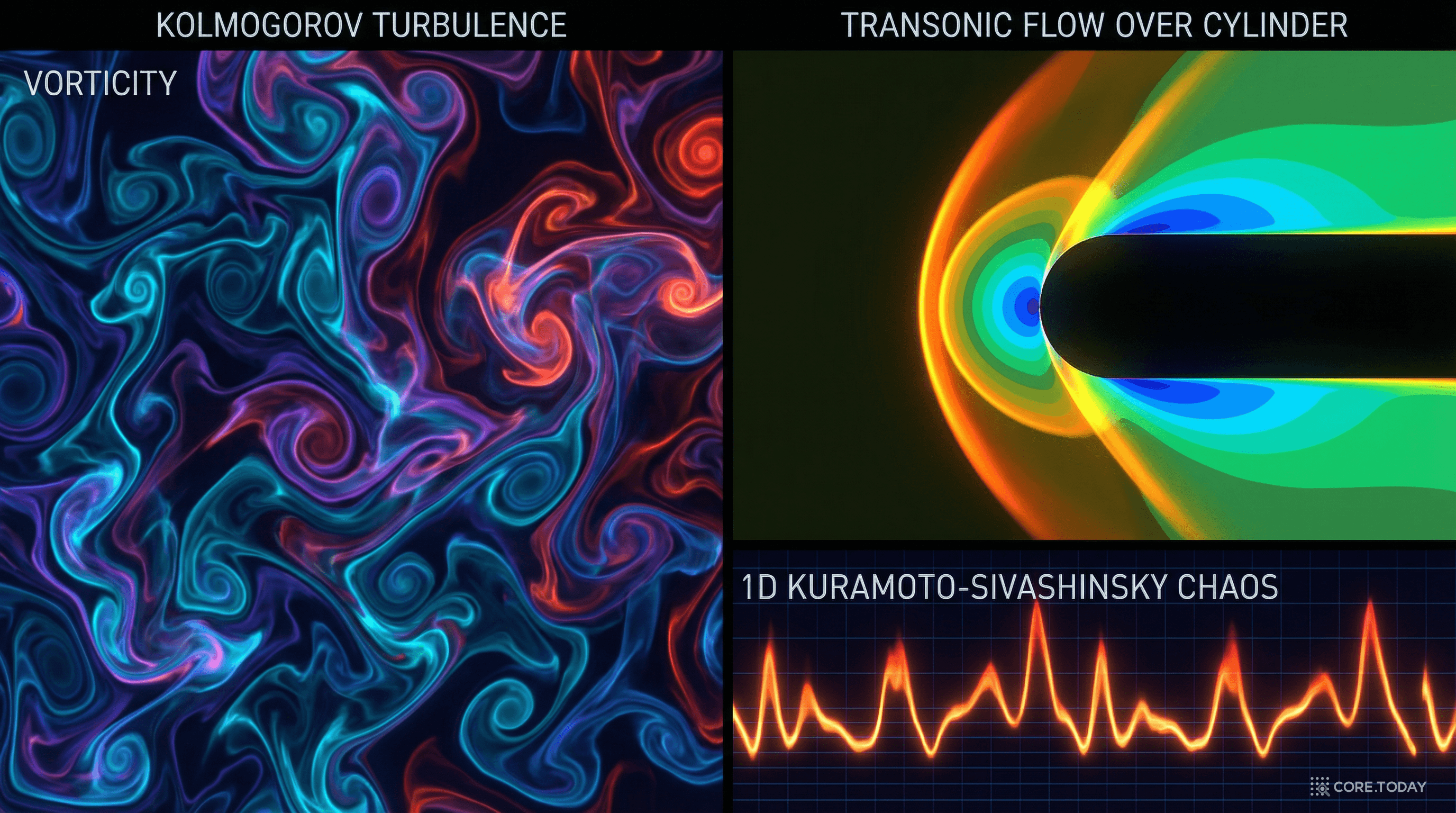
논문은 세 가지 서로 다른 유체역학 벤치마크에서 방법을 검증합니다.
벤치마크 데이터셋
Kuramoto-Sivashinsky (1D)
화염 전파면의 카오스적 동역학 256 공간점, Δt = 0.2 4차 비선형 PDE
Kolmogorov Flow (2D)
사인파 외력의 비압축성 유체 64×64 격자, Navier-Stokes 와도(vorticity) 기반 평가
Transonic Flow (2D)
실린더 주위 천음속 유동 128×64 격자 속도·압력·밀도 4채널
결과 테이블
논문의 Table 1을 재구성합니다. 가장 중요한 결과를 강조합니다:
Kolmogorov Flow (난류 — 가장 까다로운 벤치마크)
1-step MSE (×10⁻⁷, 낮을수록 좋음)
Linear TF
13.0
Sigmoid TF
12.5
PDE-Refiner
11.2
U-Net UT
9.53
Adaptive (Ours)
8.12
Adaptive + Proxy UT
8.07 ★
하지만 진정한 차이는 장기 롤아웃 품질(FSD)에서 드러납니다:
Frechet Spectral Distance (낮을수록 좋음, 로그 스케일)
Sigmoid TF
2.4×10⁶
Linear TF
2.1×10⁵
Adaptive TF
3.7×10⁵
PDE-Refiner
1.05×10¹
U-Net UT
9.1×10⁻¹
Adaptive + Proxy UT
3.8×10⁻¹ ★
Adaptive + Proxy UT는 기존 디퓨전 베이스라인 대비 FSD를 최대 600만 배 개선했습니다. 이것은 장기 시뮬레이션에서 아티팩트가 사실상 제거되었음을 의미합니다.
전체 벤치마크 종합
데이터셋
메트릭
최고 베이스라인
Adaptive + Proxy UT
개선율
Kolmo
1-step MSE
9.53×10⁻⁷
8.07×10⁻⁷
15% ↓
Kolmo
FSD
9.1×10⁻¹
3.8×10⁻¹
58% ↓
Tra
1-step MSE
4.90×10⁻⁵
3.87×10⁻⁵
21% ↓
KS
1-step MSE
8.99×10⁻⁸
8.83×10⁻⁸
2% ↓
KS
High-Corr Time
88.0s
86.1s
유사
스케줄 시각화에서 드러나는 인사이트
논문의 Figure 4는 각 벤치마크에서 얻어진 적응적 스케줄의 모습을 보여줍니다. 매우 흥미로운 패턴이 관찰됩니다:
Kolmogorov Flow: 작은 와도 구조가 많아 고주파 성분이 풍부 → 최적 σ0이 매우 작음 (더 정밀한 마무리 필요)
Transonic Flow: 충격파 같은 선명한 경계가 있지만 고주파가 상대적으로 적음 → 중간 크기의 σ0
KS: 1D이고 카오스적이지만 공간 해상도가 높지 않음 → 가장 작은 σ0 (가장 정밀)
이것은 PDE-Refiner(Lippe et al., 2023)의 관찰과도 일치합니다 — 고주파 성분이 많은 데이터일수록 낮은 노이즈 레벨에서의 정밀 제어가 중요합니다. 하지만 본 논문은 이것을 자동으로 발견하는 반면, PDE-Refiner는 이를 수동으로 설정해야 한다는 차이가 있습니다.
이론적 기반: 수학적 엄밀성
이 논문의 강점 중 하나는 실험적 성공을 이론적으로 뒷받침한다는 것입니다. 핵심 정리들을 살펴봅시다.
Proposition 3.3: 재노이징 감쇄 (Re-noising Attenuation)
REB가 재귀적으로 분해될 수 있음을 보여줍니다:
REB(t)≤B(2S)(t)+λt⋅REB(t+1)
여기서 λt<1이면 이전 스텝의 편향이 감쇄되고, λt>1이면 증폭됩니다. 이것은 스케줄 설계의 핵심 제약 조건을 제공합니다.
Proposition 3.4: 안정성 임계값 (Stability Threshold)
Wiener 디노이저 구조와 신경망의 스펙트럼 편향을 가정하면, B(own)는 Eclean의 증가 함수입니다. 즉:
Clean-input 오차가 충분히 작으면, 모델은 자신의 예측을 입력으로 받아도 안정적입니다.
이것이 적응적 스케줄의 이론적 토대입니다.
Proposition 3.5: 느린 오차 감소 원리의 최적성
안정성 제약 하에서, 탐욕적 구성(greedy construction)이 최적임을 증명합니다. 매 스텝에서 가능한 가장 큰 점프를 선택하는 것이, 최소 스텝 수로 최저 최종 오차를 달성하는 유일한 방법입니다.
2026년 시점의 의의와 전망
AI 기반 과학 시뮬레이션의 현재
2026년 현재, AI 기반 물리 시뮬레이션은 폭발적으로 성장하고 있습니다:
기상 예측: Google DeepMind의 GenCast, Nvidia의 FourCastNet 등이 전통적 수치 모델의 정확도를 능가
신약 개발: AlphaFold 이후, 분자동역학 시뮬레이션의 가속화가 핵심 과제
항공/자동차 설계: 풍동 실험 대체를 위한 실시간 유동 시뮬레이션 수요 급증
기후 모델링: 고해상도 기후 시뮬레이션의 민주화
이 논문의 기여는 이 생태계에서 매우 시의적절합니다:
1
정확도-다양성 트레이드오프 해결
기존 디퓨전 모델은 다양한 샘플을 생성할 수 있지만, 특정 궤적의 정확한 재현에서는 결정론적 모델에 뒤졌습니다. 이 논문은 두 가지 장점을 동시에 달성할 수 있는 길을 열었습니다.
2
확장 가능한 프레임워크
Adaptive Scheduling은 데이터 통계에 자동으로 적응하므로, 새로운 PDE 시스템에 대해 수동 하이퍼파라미터 튜닝 없이 적용할 수 있습니다. 이것은 대규모 다물리 시뮬레이션에서 특히 중요합니다.
3
효율적 학습 전략
Proxy Unrolled Training은 디퓨전 모델의 unrolled training 비용을 단 1 추가 forward pass로 줄임으로써, 이전에는 불가능했던 학습 전략을 실용화했습니다.
미래 연구 방향
논문은 여러 흥미로운 미래 연구 방향을 제시합니다:
역문제(Inverse Problems)와 데이터 동화: 관측 데이터로부터 물리 시스템의 초기/경계 조건을 추정하는 문제에도 동일한 프레임워크를 적용할 수 있습니다.
초해상도(Super-Resolution): 저해상도 시뮬레이션을 고해상도로 업스케일링하는 데도 재구성 정확도가 핵심이므로, 적응적 스케줄이 효과적일 수 있습니다.
예측 파라미터화의 영향:ϵ-prediction 대신 x0-prediction이나 v-prediction을 사용했을 때 오차 경관이 어떻게 달라지는지는 열린 질문입니다.
비조건부 디퓨전으로의 확장: 이 논문이 밝힌 "모델 용량 할당"이라는 관점의 exposure bias가 이미지 생성 등 비조건부 디퓨전에서도 존재하는지 확인하는 것이 중요합니다.
핵심 개념 정리
개념 1
Reconstruction Exposure-Bias (REB) — 학습 시(clean input)와 추론 시(inference input)의 복원 오차 비율. 디퓨전 모델의 근본적인 정확도 한계를 정량화하는 새로운 지표
개념 2
느린 오차 감소 원리 — 각 디노이징 스텝에서 모델이 안정적으로 처리할 수 있는 만큼만 노이즈를 줄여야 한다는 최적 설계 원리. 탐욕적 구성이 최적임을 수학적으로 증명
개념 3
Adaptive Scheduling — 2단계(탐색 + 구축) 알고리즘으로, 데이터 특성에 맞는 bias-constrained 노이즈 스케줄을 자동으로 발견. 태스크별 최적 스텝 수가 자동 결정
개념 4
Proxy Unrolled Training — Diffusion bias 감소가 가능하게 하는, 단 1-step 프록시를 이용한 효율적 unrolled training. 디퓨전 모델에서 처음으로 실용적인 UT를 구현
마무리: 디퓨전 모델의 새로운 지평
이 논문은 단순히 "더 나은 스케줄을 찾았다"는 수준을 넘어, 디퓨전 모델의 정확도를 제어하는 근본적인 메커니즘을 밝혔다는 점에서 의의가 큽니다.
노이즈 스케줄이라는 겉보기에 단순한 하이퍼파라미터가 실은 모델 용량의 할당, exposure bias의 크기, 장기 안정성을 모두 결정한다는 통찰은, 앞으로 디퓨전 모델을 과학적 시뮬레이션에 적용하는 모든 연구에 영향을 미칠 것입니다.
레오나르도 다빈치가 물의 소용돌이를 스케치한 지 500년이 지난 지금, 우리는 AI가 그 소용돌이를 실시간으로 예측하는 시대에 살고 있습니다. 이 논문은 그 예측을 더 정확하고, 더 안정적이고, 더 효율적으로 만드는 중요한 한 걸음입니다.
논문 정보
제목: Bias-Constrained Diffusion Schedules for PDE Emulations: Reconstruction Error Minimization and Efficient Unrolled Training
저자: Constantin Le Clei, Nils Thuerey, Xiaoxiang Zhu (Technical University of Munich)