들어가며 — 4,300만 편의 논문 앞에서
2026년 5월, 한 편의 논문이 학계 X(트위터)와 한국 AI 연구자 슬랙을 달궜다. 제목은 짧고 야심 차다.
SciAtlas: A Large-Scale Knowledge Graph for Automated Scientific Research (arXiv:2605.22878)
저자는 중국 저장대학교(Zhejiang University) ZJUNLP 연구실 — 우리에게는 KnowLM, OpenAGI, OneKE 같은 지식 그래프·LLM 결합 작업으로 친숙한 그룹이다. 그들이 이번에 들고 나온 숫자는 학술계 그 자체의 규모처럼 압도적이다.
SciAtlas, 한눈에 보는 스케일
총 관계 (Triplets)
3,000M (3B)
26개 학문 분야에 걸친 4,300만 편의 논문, 그리고 그것을 잇는 30억 개의 관계 — 이것이 SciAtlas가 Neo4j 위에 펼쳐 놓은 "과학의 지도(Atlas of Science)"다.
하지만 진짜 흥미로운 부분은 숫자가 아니다. SciAtlas가 학계의 시선을 끄는 건, 이 거대한 그래프 위에서 LLM이 마치 사람이 도서관을 거니는 것처럼 "추론하며 걸을 수 있게" 만든 알고리즘 때문이다.
이 글은 그 알고리즘을 천천히 풀어보는 특집이다. 정보 폭발의 시대가 왜 새로운 인프라를 요구했는지, 마이크로소프트 학술 그래프(MAG)부터 OpenAlex까지 이어지는 계보 위에 SciAtlas가 어떻게 올라섰는지, 그리고 2026년 — AI 에이전트가 스스로 연구를 시작하는 이 시점에서 이 기술이 무엇을 바꾸는지를 살핀다.
제1장: 왜 지금, "과학의 지도"인가
정보 폭발 — 학자의 익사

2024년 STM(국제학술출판협회) 보고에 따르면, 전 세계에서 매년 약 500만 편의 동료 평가 논문이 출판된다. 분당 약 10편, 1초에 1편 가까이 새 논문이 세상에 나오는 셈이다.
생물의학 분야 하나만 봐도 PubMed에는 매일 평균 4,000편 이상의 신규 논문이 색인된다. 어느 의대 교수의 말처럼,
"내가 잠든 8시간 동안 우리 분야에 1,300편의 새 논문이 나온다.
일어나면 어떤 논문이 새로 나왔는지 따라잡는 것조차 불가능하다."
이걸 두고 정보 과학자 데렉 솔라(Derek Solla)는 1963년 이미 "과학의 빅 사이언스(Big Science of Science)"라는 개념을 만들었고, 1980년대 미국 NSF는 "Information Overload"라는 용어를 정책 문서에 처음 도입했다. 솔라의 예측대로 학술 출판량은 약 15년마다 두 배씩 늘어 왔다.
검색 도구의 진화 — 그리고 그 한계
연구자들은 이 홍수에 맞서 도구를 끊임없이 갈아 끼웠다.
1960s
MEDLINE — 의학 문헌의 색인. 종이 카드 → 자기 테이프.
1997
Google 등장. 학술계는 곧 Google Scholar(2004)로 합류.
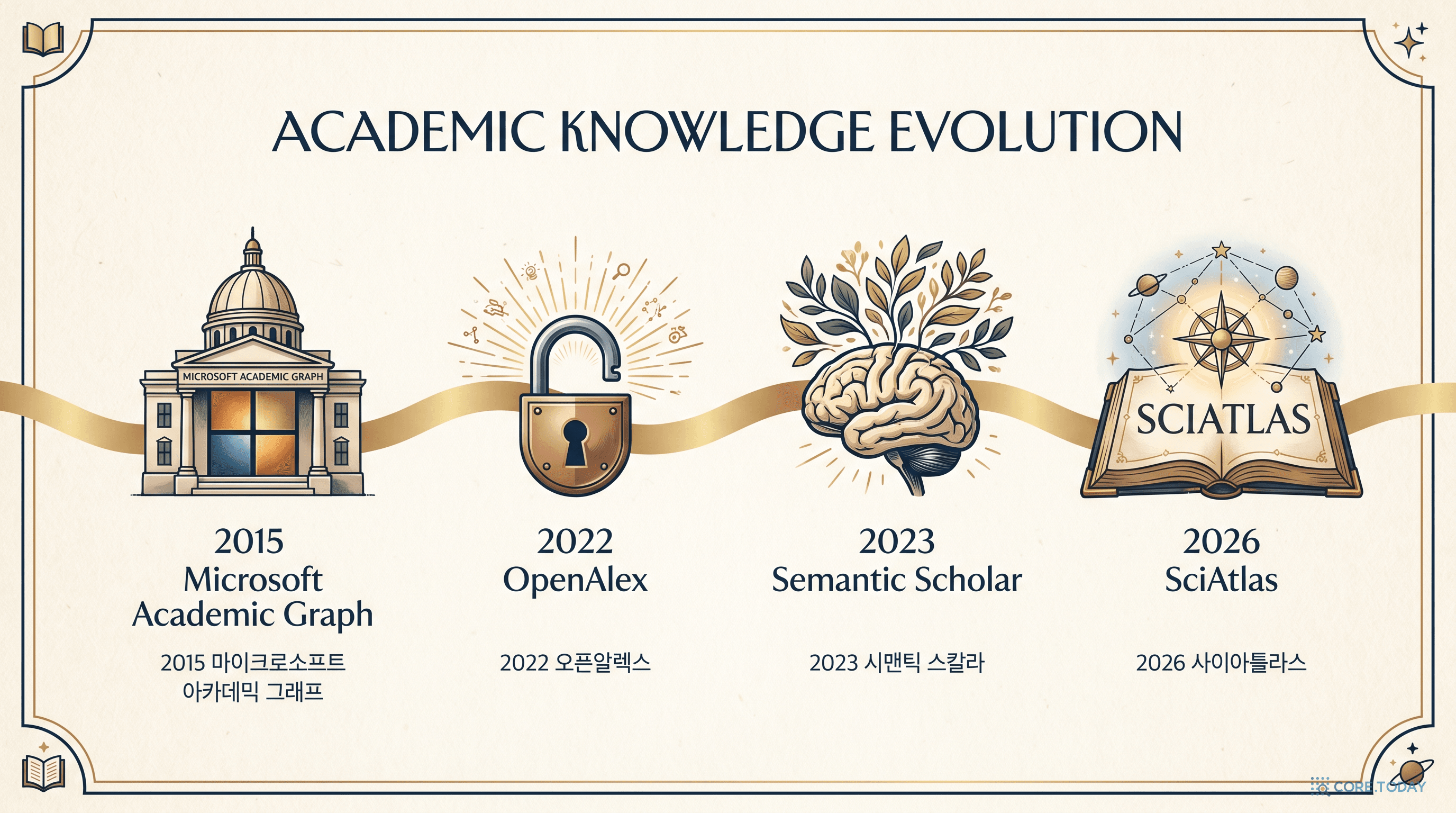
2015
Microsoft Academic Graph(MAG). "지식 그래프"라는 단어가 과학에 도착.
2022
OpenAlex. MAG가 종료되자 비영리 OurResearch가 오픈으로 부활.
2023~25
Semantic Scholar + LLM 시대. AI Assistant들이 논문 요약을 자동화.
2026
SciAtlas. 4,300만 논문을 LLM이 "걸어 다닐" 수 있는 그래프로.
문제는 이 모든 도구가 같은 두 가지 한계를 안고 있었다는 점이다.
!
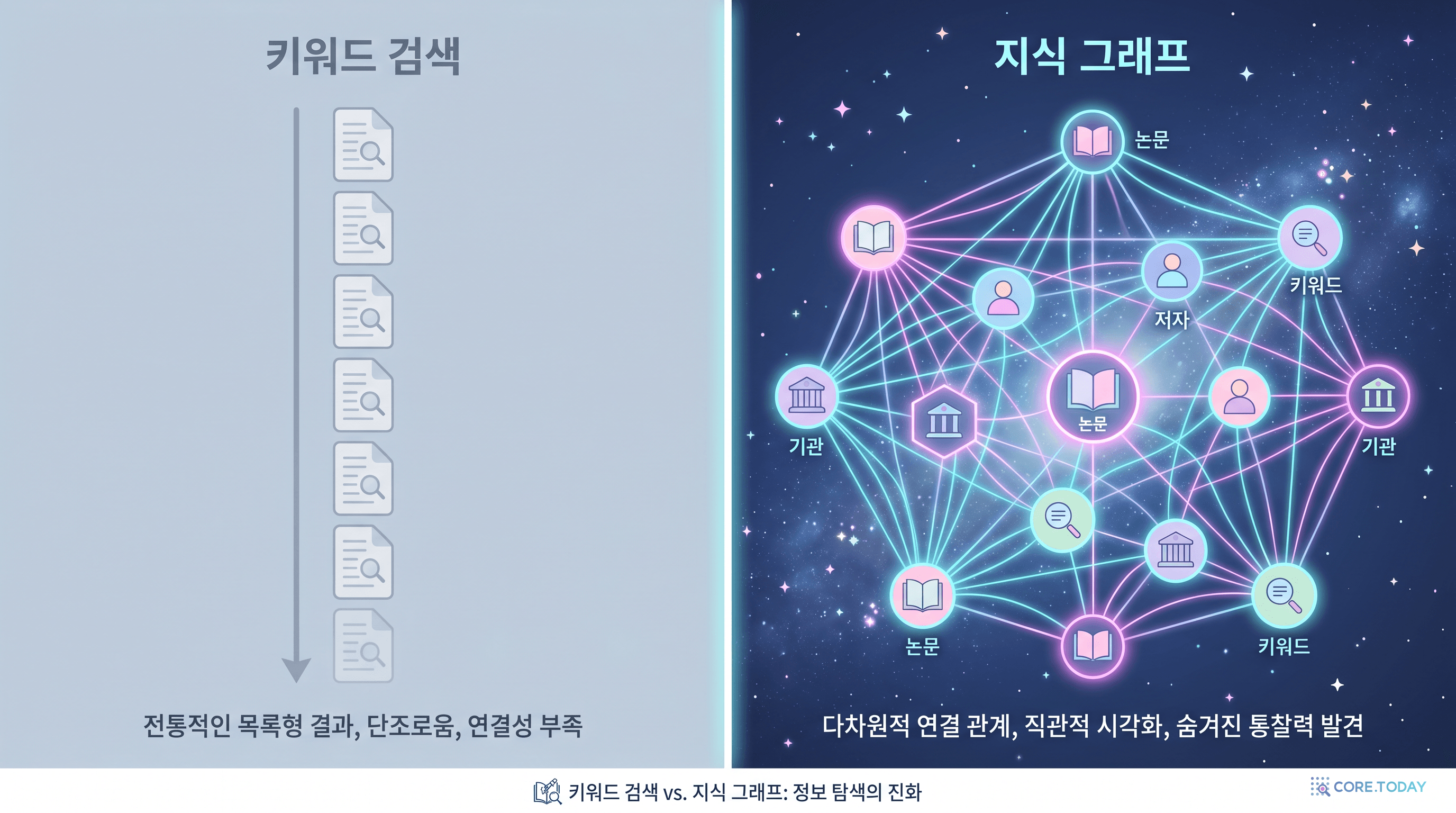
문제 1 — 키워드 매칭의 평면성
"open world agent"로 검색하면 그 단어가 들어간 논문만 나온다. 같은 개념을 "lifelong agent"나 "open-ended exploration"으로 부른 논문은 보이지 않는다.
!
문제 2 — 벡터 검색의 환각
임베딩 유사도만으로 "관련된 듯한" 논문을 묶으면, 실제 인용·저자·기관처럼 실증된 구조적 관계는 모두 사라진다. LLM은 "그럴듯하지만 존재하지 않는" 논문을 인용한다.
→
필요했던 것
키워드 + 의미 + 구조(인용·저자·소속·키워드 공출현)를 하나의 그래프에서 동시에 다루는 인프라. 그게 SciAtlas가 풀려는 문제다.
제2장: 학술 지식 그래프의 짧은 역사
SciAtlas를 이해하려면, 그 앞에 무엇이 있었는지 알아야 한다. "과학을 그래프로 그리려는" 시도는 사실 60년 가까이 된다.
1955 — 가필드의 한 줄짜리 혁명
미국 정보학자 유진 가필드(Eugene Garfield)는 1955년 지에 짧은 글을 한 편 실었다. "Citation Indexes for Science."
핵심 아이디어는 단순했다. 논문 A가 논문 B를 인용했다는 사실 자체를 데이터로 다루자는 것. 이 한 줄짜리 아이디어가 Web of Science(1964~)를 낳았고, "인용 그래프(citation graph)"라는 개념을 학문의 뼈대로 만들었다.
2015 — Microsoft Academic Graph
검색엔진 빙(Bing)의 학술 검색 기능에서 출발한 MAG는 단순한 인용 그래프를 넘어, 논문·저자·소속·필드·콘퍼런스를 모두 노드로 묶은 첫 이종(heterogeneous) 학술 그래프였다. 약 2억 편의 문헌, 10억 개 이상의 인용 관계를 담았고, "field of study"라는 6단계 위계 분류가 인상적이었다.
하지만 2021년 12월 31일, MS는 이 그래프를 종료한다. 학계는 패닉.
2022 — OpenAlex의 부활
비영리 단체 OurResearch가 "MAG가 닫혀도 학문은 닫을 수 없다"며 2022년 1월 OpenAlex를 발표한다. CC0 라이선스, 완전 무료, REST API. SciAtlas가 메타데이터의 1차 출처로 사용하는 바로 그 시스템이다.
2026년 현재 OpenAlex는 4억 8천만 편 이상의 문헌과 2억 5천만 명의 저자, 6만 5천 종의 학술지를 포괄한다 — 사실상 인류 학술 출판의 거의 전부.
2015~ — Semantic Scholar의 AI 노선
같은 시기 시애틀의 Allen Institute for AI가 시작한 Semantic Scholar는 다른 방향을 택했다. "그래프"보다 "논문을 이해하는 AI"에 집중. TLDR(자동 1~2문장 요약), Specter(논문 임베딩), SPECTRE2, Citation Intent 분류 등이 모두 여기서 나왔다.
2024~25 — Deep Research / Idea Agent의 시대
OpenAI의 Deep Research, Google의 NotebookLM/Co-Scientist, 그리고 Sakana AI의 "AI Scientist" 같은 자동 연구 에이전트들이 등장한다. 이들은 LLM이 직접 웹과 학술 DB를 돌아다니며 논문을 읽고 가설을 세운다.
하지만 이 에이전트들에게는 공통의 약점이 있었다. 그들이 의존하는 정보 인프라가 여전히 "검색 결과 리스트"라는 점이다. LLM은 한 번에 20~50편의 문헌 스니펫을 받아 들고, 그 사이의 관계는 LLM의 머릿속에서 환각으로 메꿔야 한다.
SciAtlas의 출발점은 바로 여기다.
"LLM에게 평면 텍스트가 아니라, 이미 잘 짜인 과학의 지도(map)를 건네자."
제3장: SciAtlas 시스템 한눈에 보기
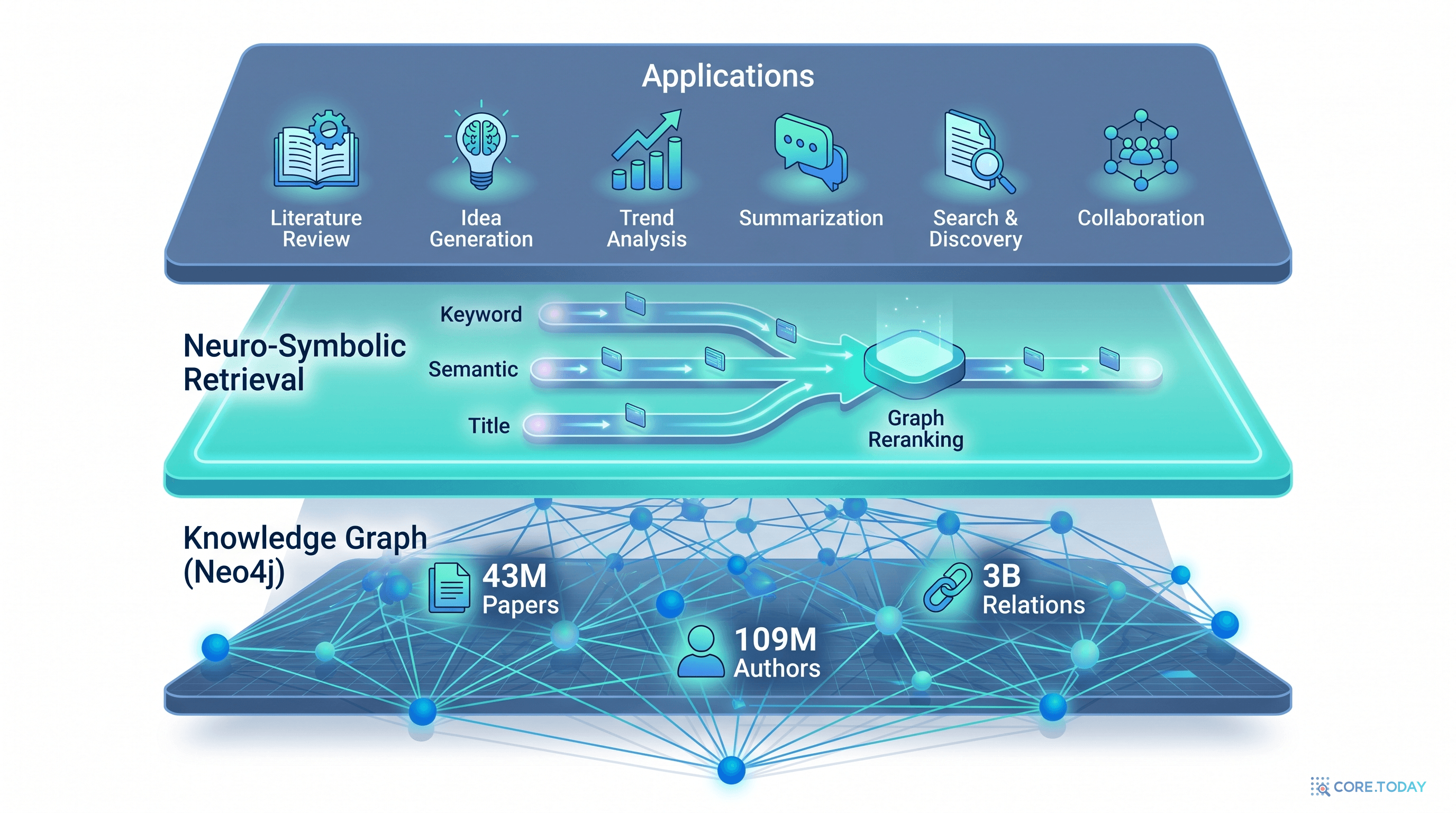
논문 Figure 2는 시스템을 세 층으로 나눈다. 이름은 어렵지만 구조는 의외로 깔끔하다.
애플리케이션 계층
literature review · idea grounding · trend · etc.
Keyword Recall
Semantic Recall
Title Recall
Graph Reranking
Random Walk with Restart
Papers
Authors
Keywords
Topics · Fields · Sources
위에서 아래로:
- 애플리케이션 계층 — 사용자(또는 AI 에이전트)가 던지는 질문. "RAG 분야 최신 동향 정리해 줘", "이 아이디어가 이미 누가 했는가?" 같은 6종 다운스트림 태스크.
- 뉴로-심볼릭 검색 계층 — 키워드·의미·제목 3개 경로로 동시에 그래프를 찌르고, 결과를 Random Walk with Restart로 재정렬.
- 지식 그래프 계층 — 9종 노드, 12종 관계, 30억 트리플로 짜인 Neo4j 그래프.
이제 위에서부터 한 층씩 자세히 들여다보자. 가장 아래 그래프부터.
제4장: 스키마 — "과학"이라는 우주의 지도책
SciAtlas의 스키마(논문 Figure 2)는 단순하지만 영리하다. 모든 학문 분야를 다음 네 단계의 위계로 나눈다.
Domain (4)
→
Field (26)
→
Subfield (252)
→
Topic (4,520)
가장 큰 도메인(Physical Sciences, Life Sciences, Health Sciences, Social Sciences)이 4개, 그 아래 26개의 "필드(Computer Science, Medicine, …)", 그 아래 252개의 "서브필드", 마지막에 4,520개의 "토픽". 이건 OpenAlex의 분류 체계를 그대로 채택한 것이다.
그 위에 다음 9종의 노드와 12종의 관계가 얹힌다.
9종 노드의 역할
| 노드 타입 | 개수 | 역할 |
|---|
| Paper | 43.30M | 핵심. 모든 검색이 결국 도달해야 하는 목표. |
| Author | 109.70M | 저자. 공동연구·전공 분석의 출발점. |
| Keyword | 3.76M | LLM이 추출한 3~8개 "핵심 키워드"가 노드로 승격. |
| Institution | 0.12M | 대학·연구소·기업. 연구 지형의 지정학. |
| Source | 0.28M | 저널·콘퍼런스. NeurIPS, Nature, ACL, ... |
| Topic | 4,520 | 가장 세밀한 주제 분류. |
| Subfield | 252 | 중간 분류. |
| Field | 26 | 대분류. Computer Science, Medicine, ... |
| Domain | 4 | 최상위. Physical / Life / Health / Social. |
이 중 흥미로운 건 Keyword를 노드로 승격시킨 설계다. 보통 학술 그래프에서는 키워드가 노드가 아니라 단순 속성(attribute)인 경우가 많다. SciAtlas는 LLM(Qwen3-30B)에게 모든 논문 초록을 읽혀 "이 논문을 대표하는 핵심 키워드 3~8개"를 뽑아낸 뒤, 그것을 노드로 만들었다.
그래서 "RLHF"라는 키워드 노드를 클릭하면, 그것을 핵심으로 다룬 모든 논문이 한 가족으로 묶인다 — 마치 책의 색인 페이지처럼.
12종 관계 — 그래프의 진짜 살
| 관계 | 개수 | 의미 |
|---|
| COAUTHOR | 2.06B | 두 저자가 같은 논문을 함께 썼다. |
| CITES | 213.88M | 논문 A가 논문 B를 인용했다. |
| AUTHORED | 149M | 저자가 논문을 썼다. |
| HAS_TOPIC | 105.89M | 논문이 어떤 토픽에 속한다. |
| HAS_KEYWORD | 101.38M | 논문의 핵심 키워드(가중치 포함). |
| AFFILIATED_WITH | — | 저자가 기관에 소속. |
| PUBLISHED_IN | — | 논문이 특정 저널·콘퍼런스에 실림. |
| RELATED_TO | — | 토픽↔서브필드↔필드의 위계 연결. |
| COOCCUR | — | 두 키워드가 같은 논문에서 함께 등장. |
20억 개에 달하는 공동저자(COAUTHOR) 관계와 2억 개를 넘는 인용(CITES) 관계가 그래프 전체의 뼈대를 이룬다. 사람의 사회적 관계가 학문의 지형을 만든다는 것이, 숫자만 봐도 명백해진다.
분야별 분포 — 4,300만 편은 어디서 왔는가
SciAtlas 분야별 논문 비중 (Top 10, 단위 %)
Biochem./Genetics/MB
6.44%
Physics & Astronomy
≈ 4.6%
상위 5개 분야(의학·사회과학·공학·생화학·전산학)가 전체의 51.4%. 출판량으로 보면 학문의 지형은 의학에 크게 기울어 있다. SciAtlas는 이걸 26개 분야 모두에서 일정 균형이 잡힌 코퍼스로 사용한다 — 분야 간 아이디어 이전(cross-disciplinary transfer)을 적극 노린 설계다.
제5장: 핵심 알고리즘 ① — Tri-Path Collaborative Recall
자, 이제 SciAtlas의 가장 흥미로운 부분이다. 사용자가 질문을 던지면 어떤 일이 벌어지는가?
기존 학술 검색은 보통 단 하나의 채널만 쓴다. Elasticsearch라면 키워드 매칭, BGE/E5라면 임베딩 유사도. 둘 중 하나에 모든 걸 건다. 그러다 보니 한쪽의 약점이 그대로 결과의 약점이 된다.
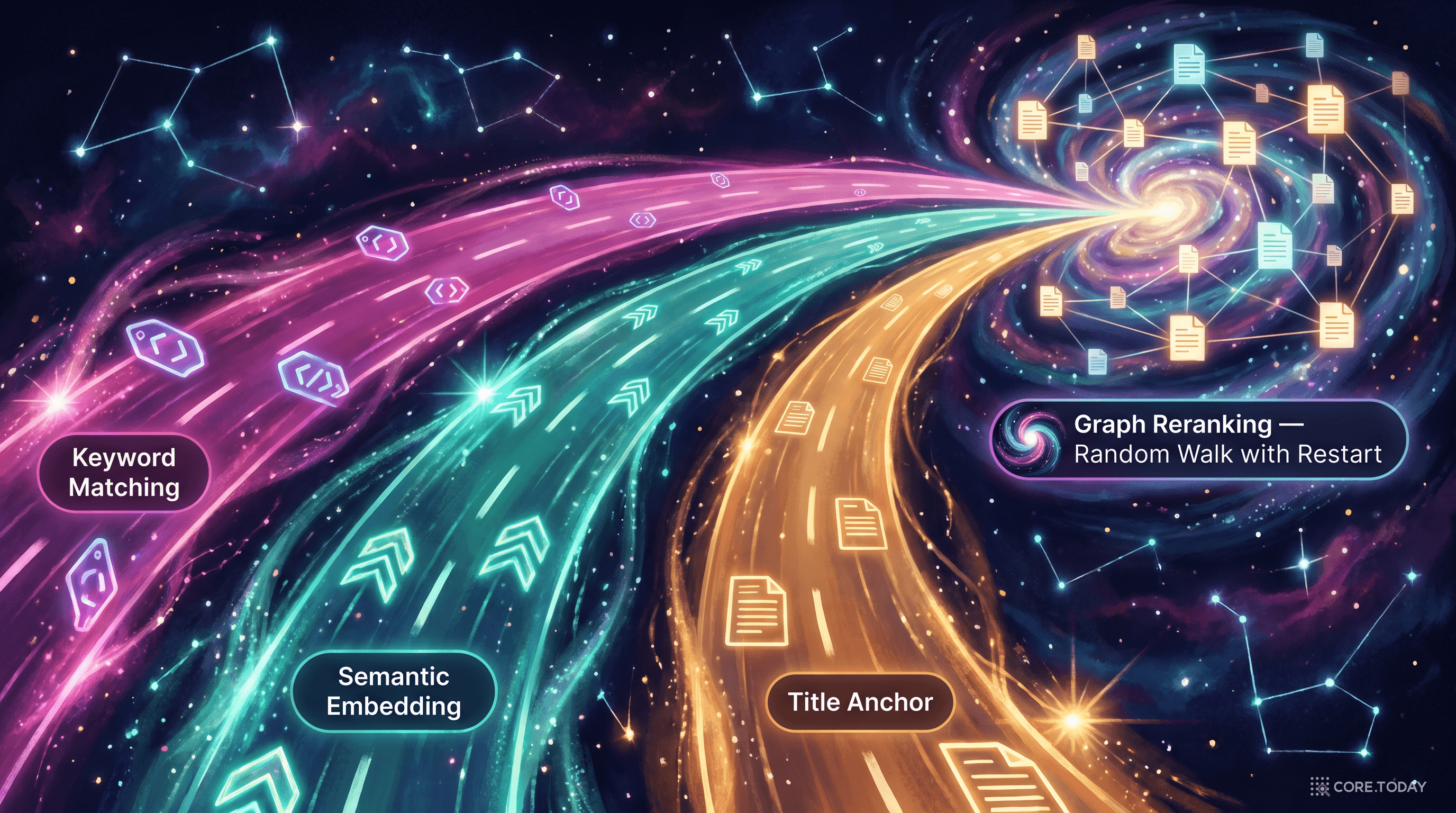
SciAtlas는 처음부터 세 갈래 길을 동시에 달려가서 모은다(tri-path collaborative recall). 비유하자면 같은 사람을 찾을 때 얼굴 인식, 이름 검색, 옷차림 묘사를 동시에 돌리는 것과 비슷하다.
User Query
"open-world agent의 최신 동향"
Path 1
Keyword
LLM이 핵심 키워드 3~8개 추출
exact match + vector sim ≥ 0.7
Path 2
Semantic
BGE-large 임베딩
title + abstract 위에서 cosine
Path 3
Title
GROBID로 인용 제목 추출
LCS 65% + token 35% 퍼지
↓ 각 경로 top-60 → 통합 후보 풀 ↓
각 경로를 천천히 풀어보자.
Path 1 — Keyword Matching: "당신이 던진 단어"
먼저 LLM이 사용자의 자연어 질의를 읽고 핵심 키워드 3~8개를 뽑아낸다. 각 키워드에는 1~10점의 중요도 점수(s_i^llm)가 매겨진다.
그 다음 그래프의 Keyword 노드와 두 방식으로 매칭한다.
Keyword 매칭 두 단계
① exact text match — 정확히 같은 문자열의 Keyword 노드
② vector similarity — 임베딩 cosine ≥ 0.7인 Keyword 노드
각 후보의 점수: score_vec(k_i, g) = s_i^llm × sim(k_i, g)
→ 매칭된 키워드에 연결된 논문들을 후보로 회수
요점은 LLM이 매긴 중요도가 그대로 그래프 워크의 가중치로 전달된다는 점이다. "high:open world agent"라고 강조하면, 그 키워드 노드가 그래프에서 더 굵은 다리(edge)를 갖게 된다.
Path 2 — Semantic Matching: "당신이 의미하는 것"
질의 전체를 BGE-large-en-v1.5(1024차원)로 임베딩한 뒤, 모든 논문의 title·abstract 임베딩과 cosine 유사도를 계산한다. 상위 60편을 가져온 뒤 리랭킹으로 15편까지 압축.
이 경로는 키워드가 일치하지 않아도 "비슷한 이야기를 하는" 논문을 잡는 역할을 한다. "RLHF" 대신 "preference optimization"이라고 쓴 논문도 여기서 살아남는다.
Path 3 — Title Matching: "당신이 손에 들고 있는 그 논문"
흥미로운 세 번째 경로다. 사용자가 질의 안에 특정 논문 제목을 언급하거나, 자기 PDF를 업로드한 경우 동작한다. PDF에서는 GROBID가 참고문헌 섹션을 파싱해 모든 인용 제목을 뽑아낸다.
그러고는 그래프의 Paper 노드 제목과 다음 점수로 퍼지 매칭한다.
제목 유사도 = 0.65 × LCS + 0.35 × Token Overlap
LCS(Longest Common Subsequence) — 두 제목이 공유하는 가장 긴 부분 문자열 길이.
Token Overlap — 토큰 집합의 자카드 유사도.
"lcs를 더 신뢰하는" 가중치 0.65/0.35는, 단어 순서가 어느 정도 유지되는 학술 인용 패턴에 맞춘 선택.
이렇게 세 경로에서 각각 후보를 얻고 나면, 사실 이미 100~200편의 "꽤 관련 있는" 논문 풀이 만들어진다. 하지만 진짜 마법은 그 풀을 그래프 구조로 다시 정렬하는 다음 단계에서 일어난다.
제6장: 핵심 알고리즘 ② — Graph Reranking (RWR)
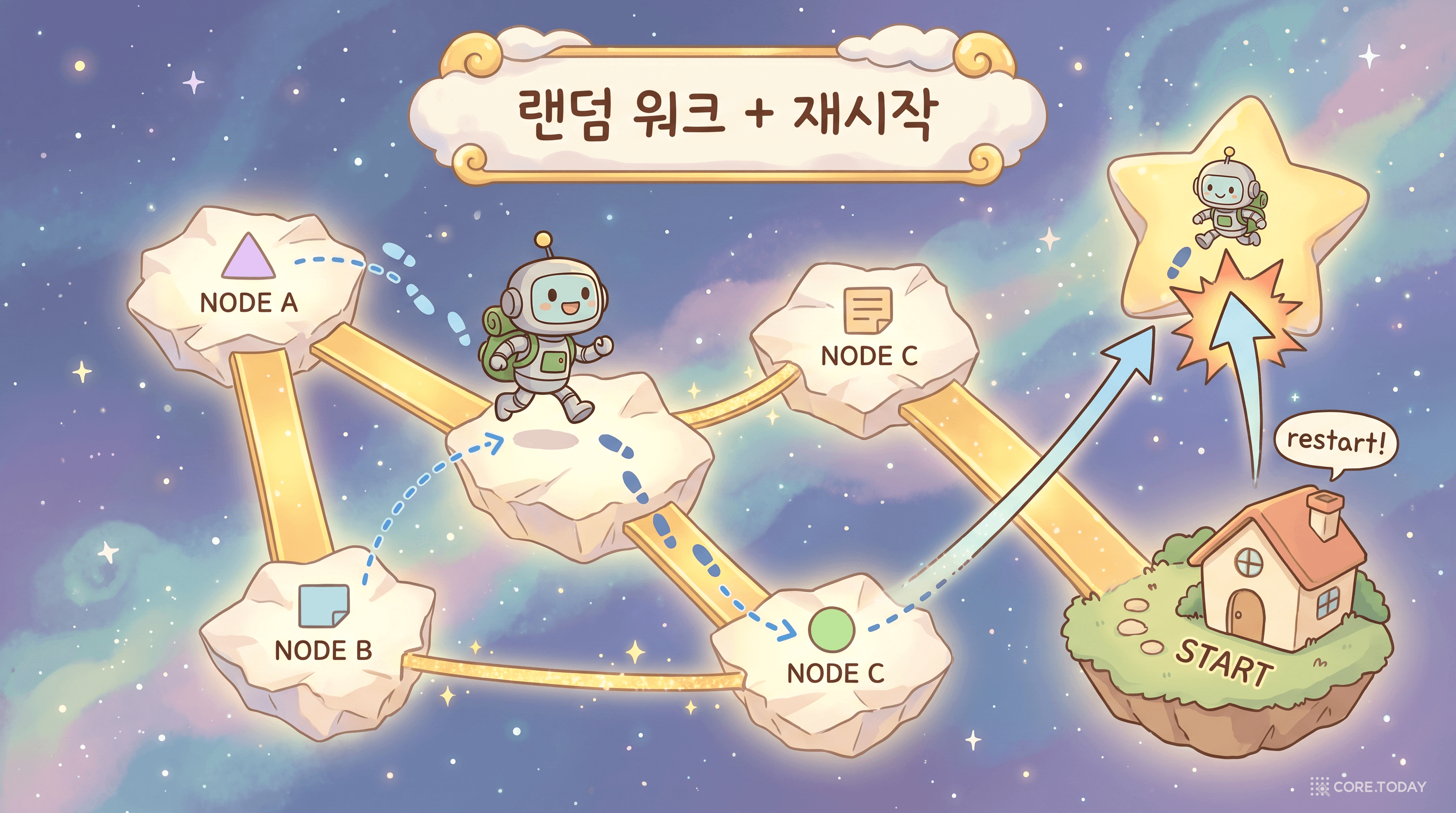
세 경로가 모아 놓은 후보 풀을, 이번엔 그래프 구조 자체로 다시 채점한다. 사용하는 알고리즘이 Random Walk with Restart(RWR) — 우리말로 "재시작 있는 랜덤 워크".
RWR이 뭐냐, 한 문단으로
작은 로봇 한 마리가 시드 노드(앞에서 찾은 후보 논문)에서 출발한다. 매 스텝마다 다음 둘 중 하나를 한다.
- 확률 (1−α): 현재 노드에 연결된 이웃 중 하나로 간선 가중치에 비례해 이동.
- 확률 α: 시드 노드로 순간이동(restart).
이걸 수억 번 반복하면, 각 노드가 "방문된 빈도"를 갖게 된다. 시드와 그래프적으로 가까운(잘 연결된, 자주 같이 등장하는, 같은 저자에 묶이는…) 노드일수록 자주 방문된다. 이 방문 빈도가 그대로 위상학적 관련도 점수가 된다.
비유: 페이지랭크가 "온 웹을 떠도는 서퍼"라면, RWR는 "내가 출발한 동네 주변을 집요하게 맴도는 산책자". 시드 근처를 떠나지 않으므로, 질의 맥락에서 벗어나지 않는다.
간선 가중치 — 어떤 길이 "굵게" 보이는가
여기서 SciAtlas의 디테일이 빛난다. 모든 관계의 가중치를 동일하게 두지 않고, 관계의 의미에 따라 다른 공식을 쓴다.
| 관계 | 기본 가중치 | 스케일링 방식 |
|---|
| HAS_KEYWORD | 1.20 | LLM 점수와 임베딩 유사도 곱셈 |
| CITES | 1.00 | 고정 (인용은 인용) |
| COAUTHOR | 가변 | log(1 + 공저 횟수) 로그 스케일 |
| HAS_TOPIC | 가변 | 토픽 위계 거리 기반 감쇠 |
| AUTHORED | 가변 | 저자 가중 (downstream 태스크가 조절) |
| COOCCUR | 가변 | 키워드 공출현 빈도 + smoothing |
가장 인상적인 건 HAS_KEYWORD 가중치를 가장 굵게(1.20) 둔 선택이다. "사용자가 강조한 핵심 키워드와 연결된 논문일수록, 랜덤 워크의 로봇이 더 자주 들른다." 라는 직관을 직접 그래프에 새긴 것.
최종 스코어 — 3개 신호의 가중 평균
랜덤 워크가 끝나면, 각 후보 논문은 다음 3가지 신호를 갖는다.
SciAtlas 최종 랭킹 공식
Score = 0.35 · S_pre + 0.45 · S_graph + 0.20 · S_imp
S_pre — tri-path가 매긴 초기 관련도 (정규화)
S_graph — RWR로 얻은 위상학적 지지도 (가장 큰 가중치 0.45)
S_imp — 인용 수 기반 영향력 (정규화)
가장 큰 가중치 0.45를 그래프 구조에 둔다는 게 핵심이다. 키워드·임베딩이 가져오는 "표면적 관련도"보다, 그래프가 보여주는 "이 분야의 진짜 중심"을 더 믿겠다는 선언.
상위 20편이 점수와 함께, "왜 이 논문이 위에 올라왔는가"를 보여주는 경로 기반 설명(path explanation)과 함께 반환된다.
{`{
"paper": "Voyager: An Open-Ended Embodied Agent...",
"score": 0.872,
"breakdown": { "S_pre": 0.71, "S_graph": 0.94, "S_imp": 0.85 },
"why": [
"seed 'AutoGPT' → CITES → Voyager (인용)",
"Voyager → HAS_KEYWORD → 'open-world agent' (1.20)",
"Voyager → COAUTHOR → 'AutoGen' 저자 (log scale)"
]
}`}
LLM이 환각으로 메우던 "이 논문이 왜 관련 있냐"는 빈칸이, 실제 그래프 경로의 형태로 채워진다. 이것이 SciAtlas가 자신을 "neuro-symbolic retrieval"이라 부르는 이유다 — 신경망(임베딩)과 기호 구조(그래프 경로)가 같은 답을 함께 만든다.
제7장: 데이터 파이프라인 — 30억 관계는 어떻게 만들어지는가
이 거대한 그래프는 어떻게 만들어졌을까? 논문은 세 단계로 정리한다.
Step 1
데이터 재구조화
OpenAlex의 4.8억+ 메타데이터를 가져와 영문 논문만 선별, 핵심 속성(제목·초록·DOI·인용)이 결손된 엔트리 제거. 저자명·기관명 정규화.
Step 2
키워드 추출
Qwen3-30B-A3B가 모든 논문 초록을 읽고 핵심 키워드 3~8개를 추출. 시스템 이름·마케팅 문구·일반 명사는 제외 — "이 논문이 학문적으로 무엇에 기여하는가"에 집중.
Step 3
의미 임베딩
BGE-large-en-v1.5로 제목·초록·키워드를 각각 1,024차원 벡터로 임베딩. Neo4j의 벡터 인덱스에 적재.
특히 2단계에 LLM을 쓴 점이 흥미롭다. 4,300만 편 × Qwen3-30B 추론은 결코 가벼운 비용이 아니다. 하지만 SciAtlas 팀은 이걸 한 번 지불해서 "키워드 노드 3.76M개"라는 영구 자산으로 만들었다.
사람이 책 색인을 만드는 일을 LLM이 한 셈이다 — 다만 4,300만 권에 대해서.
제8장: 6가지 다운스트림 활용 사례
SciAtlas는 검색만을 위한 인프라가 아니다. 이 그래프 위에 6가지 "연구 워크플로"를 미리 깔아 두었다.
① Literature Review
② Idea Grounding
③ Idea Generation
④ Trend Forecast
⑤ Related Authors
⑥ Researcher Profile
① Literature Review — 문헌 리뷰 자동화
"RAG의 최근 5년 흐름을 정리해 줘"라고 던지면, 시스템이 tri-path로 후보를 모으고, RWR로 정렬한 뒤, 각 논문의 핵심 기여·인용 관계·발표 venue를 정리한 표를 만들어 준다.
특이한 건 사용자가 venue·author·institution에 가중치를 직접 부여할 수 있다는 점. "NeurIPS·ICLR·ACL에서 나온 것만 50% 가중", "DeepMind·OpenAI 저자에 +30%" 같은 식으로.
② Idea Grounding — "내 아이디어, 이미 누가 했나?"
가장 박사 과정생이 좋아할 기능이다. 자기 아이디어를 한 문장으로 넣으면, 시스템이 그 아이디어와 선행 연구의 거리를 측정한다.
아이디어
"LLM 기반 다관점 평가로 과학 아이디어를 자동 검증한다"
탐색
tri-path로 가까운 50편 회수 → 그래프에서 인용 클러스터링
분석
"InnoEval(2025)이 80% 겹침. 차별 포인트는 다관점이 아니라 LLM 판단의 신뢰도 보정에 있어야 함."
③ Idea Generation — 분야 간 아이디어 합성
"내가 RAG를 하는데, 신경과학 분야의 어떤 개념을 결합하면 새로운 길이 열릴까?" SciAtlas는 두 토픽 노드 사이의 그래프 경로를 찾아, 둘을 잇는 중간 키워드들을 제안한다. "spike-based attention", "synaptic plasticity for memory routing" 같은 식.
④ Trend Forecast — 시간 축으로 본 분야 지형
연도별 키워드·인용·저자 분포를 그래프에서 잘라 와, 어느 토픽이 가속하는지/감속하는지를 시각화한다. 논문에서는 "biologically plausible spiking neural networks"가 2023~25에 인용 가속 3배라는 분석을 예시로 든다.
⑤ Related Authors — 협업자 찾기
내 연구와 가장 가까운 저자 Top-N을 찾아 준다. AUTHORED 가중치를 사용자가 조정해 "지난 3년에 활발한 저자만", "한국·일본 기관 소속만" 같은 필터가 가능.
⑥ Researcher Profile — 한 연구자의 학문 궤적
특정 저자의 모든 논문을 가져와 토픽별·시간별로 군집화한 뒤 한 문장 요약을 만든다. 박사 지원 시 지도교수 분석, 채용 시 후보자 검토에 즉시 쓸 수 있다.
제9장: OpenAlex·Semantic Scholar와 무엇이 다른가
SciAtlas의 등장이 흥미로운 건, 그것이 기존 학술 인프라를 대체하지 않는다는 점이다. 오히려 그 위에 새로운 층을 올린다.
| 시스템 | 강점 | 한계 | SciAtlas와의 관계 |
|---|
| OpenAlex | 4.8억 편, 완전 오픈, REST API | 키워드/필터 검색 위주, 추론 X | SciAtlas의 메타데이터 1차 출처 |
| Semantic Scholar | TLDR 요약, Specter 임베딩 | 그래프 위 다중 경로 추론 부재 | 임베딩 검색 측면에서 보완 관계 |
| Google Scholar | 커버리지·인용 추적 최강 | API 없음, 구조화 데이터 X | SciAtlas는 API/SDK 제공 |
| OmniScientist | 연구 에이전트 통합 UX | 핵심 키워드·벡터 통합 부재 | SciAtlas가 우위로 인용 |
| Connected Papers | 인용·동시인용 시각화 | 분야 좁고 추론 깊이 얕음 | SciAtlas는 26개 분야 전 영역 |
핵심 차별점을 한 문장으로 줄이면:
"오픈된 학술 메타데이터(OpenAlex) 위에 LLM이 추출한 키워드와 임베딩을 얹고, 그 위에서 LLM이 실제로 추론하며 걸을 수 있는 그래프 알고리즘(RWR + tri-path)을 제공한다."
이건 단순한 검색 엔진의 진화가 아니다. "AI 에이전트를 위한 학술 인프라"의 첫 진지한 후보다.
제10장: 2026년, 자동화된 과학의 시대에서 SciAtlas의 자리

2026년 봄, 우리는 이미 자동화된 과학 연구(Automated Scientific Research)가 SF가 아닌 시점에 도달했다.
- Sakana AI의 "AI Scientist v3" — 2025년 8월, ICLR Workshop 통과 논문을 LLM이 단독 저자로 게재.
- Google DeepMind의 "Co-Scientist" — 2025년 2월, 노벨상급 가설을 생성·검증하는 멀티에이전트 시스템 발표.
- OpenAI Deep Research — 일반 사용자도 30분 만에 박사급 리뷰 페이퍼 초안 생성.
- Stanford "Virtual Lab" — LLM 에이전트들이 가상 실험실에서 실험 설계·해석·반박을 자동 수행.
이 모든 시스템이 마주한 공통의 병목이 바로 "문헌" 이다. 아무리 좋은 추론 엔진이 있어도, 인류가 쌓아 온 4억 편 이상의 논문 사이의 관계를 정확히 모르면 환각으로 떨어진다.
SciAtlas는 그 병목의 가장 직접적인 해결책 중 하나다.
LLM이 30억 개의 검증된 관계 위에서 추론을 시작할 수 있게 만든 인프라.
여기서 한국 연구 생태계에 던지는 함의가 또렷해진다.
!
한국의 현실
학술 정보 인프라는 KISTI의 ScienceON, KCI, RISS에 분산. LLM이 추론할 수 있는 그래프 형태로는 거의 없다.
→
기회
SciAtlas의 코드(zjunlp/SciAtlas)는 오픈소스. OpenAlex+한국 학술 데이터를 입력으로 한 "K-SciAtlas"는 한국어 LLM의 가장 강력한 학술 백엔드가 될 수 있다.
✓
기대 효과
박사과정 문헌 리뷰 자동화, IRB·연구비 신청 시 선행연구 매핑, 산업 R&D 부서의 기술 동향 모니터링, 정부 R&D 정책 입안의 근거 데이터 — 모두 그래프 한 장 위에서.
제11장: 직접 써보기 — pip install sciatlas
논문은 단순히 페이퍼로 끝나지 않는다. zjunlp/SciAtlas에 CLI·Python SDK·호스팅 API가 모두 공개돼 있다. 설치는 한 줄.
hljs language-bash
pip install "git+https://github.com/zjunlp/SciAtlas.git#subdirectory=sciatlas"
호스팅 API(http://scinet.openkg.cn)에 가입하면 SDK가 자동으로 토큰을 들고 동작한다. 가장 단순한 예제는 다음과 같다.
hljs language-python
from sciatlas import SciAtlasClient
client = SciAtlasClient()
result = client.search_papers(
query="retrieval augmented generation for korean legal QA",
keywords=[
{"text": "retrieval augmented generation", "score": 10},
{"text": "legal", "score": 7},
{"text": "korean", "score": 6},
],
domain="artificial intelligence",
time_range=(2022, 2026),
top_k=10,
)
for paper in result.papers:
print(paper.title, "—", paper.score, paper.why)
paper.why에 위에서 설명한 그래프 경로 설명이 그대로 담겨 온다. RAG 시스템에 이 경로 정보를 그대로 컨텍스트로 넣으면, LLM의 환각률이 눈에 띄게 떨어진다.
좀 더 강력한 워크플로는 CLI 한 줄이면 된다.
hljs language-bash
sciatlas literature-review \
--query "retrieval augmented generation" \
--domain "artificial intelligence" \
--time-range 2020-2026 \
--keyword "high:retrieval augmented generation" \
--top-k 10
sciatlas idea-evaluate \
--idea "LLM-based multi-perspective evaluation for scientific ideas" \
--domain "artificial intelligence" \
--keyword "high:idea evaluation"
결과물은 request.json, response.json, plan.json, 그리고 사람이 읽기 좋은 마크다운 요약. 자동화 에이전트와 사람 사이의 인터페이스를 모두 갖춘 구조다.
마무리 — 지도가 바뀌면 항해가 바뀐다
15세기, 포르투갈의 항해사들이 처음으로 정확한 해도를 손에 쥐었을 때 일어난 일을 우리는 안다. 그 전까지 "바다 끝에는 절벽이 있다"고 믿었던 인류가, 정확한 지도 한 장으로 지구를 한 바퀴 돌게 됐다.
4,300만 편의 논문, 1억 5,700만 개체, 30억 개의 관계.
SciAtlas는 그 학문의 지도책이다.
그리고 이번에는 사람이 아니라 AI 에이전트가 그 지도를 들고 항해한다. 환각으로 메우던 빈칸이 그래프 경로로 채워지고, "그럴듯한 인용"이 "실재하는 관계"로 바뀐다. 자동화된 과학이 약속만이 아니라 도구가 되는 순간이다.
코어닷투데이는 한국어 학술·법률·산업 데이터를 같은 방식으로 그래프로 묶고, 그 위에서 LLM이 안전하게 추론하는 시스템을 만들고 있다. SciAtlas는 그 길에서 마주친 가장 정직하고 야심 찬 동료 작업이다. 우리는 이 지도책을 책장에 꽂고, 우리 분야의 지도를 우리 손으로 그릴 차례다.
더 읽어 볼 자료




