Thinking Without Words: AI가 단어 없이 생각하는 법 — Abstract Chain-of-Thought 완전 분석
IBM Research가 2026년 4월 발표한 'Thinking Without Words'를 깊이 파헤칩니다. 64개의 정체불명 토큰만으로 추론 토큰을 최대 11.6배 줄이고도 동등한 성능을 내는 비밀, 그리고 그 안에서 자연 언어와 똑같이 떠오른 Zipf의 법칙까지 — 'AI가 말 없이 생각한다'는 명제가 현실이 된 순간을 해부합니다.
코어닷투데이2026-04-2953분
들어가며: 만약 AI가 외계어로 생각한다면
머릿속에 이런 장면을 그려봅시다.
당신이 GPT-5나 Claude 4에게 어려운 수학 문제를 던집니다. 모델은 잠시 멈추더니 답을 내놓습니다. 그런데 답을 내기 전에 모델 내부에서 이런 일이 벌어집니다.
여기서 잠시 — 저 <TOKEN_R>, <TOKEN_C>, <TOKEN_M>은 무슨 단어일까요?
정답은 아무 단어도 아닙니다. 영어도 아니고, 한국어도 아니고, 라틴어도 아닙니다. 그냥 모델이 사후 학습 단계에서 새로 만들어낸, 인간이 읽을 수 없는 추상 토큰입니다.
그런데 이 외계어 같은 토큰 96개로, 모델은 평소에 1,500개의 영어 토큰을 동원해 풀던 문제를 똑같이 풀어냅니다. 추론 토큰이 최대 11.6배 줄었는데, 정확도는 그대로거나 오히려 더 올라갑니다.
2026년 4월 27일 arXiv에 올라온 IBM Research의 논문 "Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought" (Keshav Ramji, Tahira Naseem, Ramón Fernandez Astudillo)는 정확히 이 일을 해냈습니다.
이 글에서는 이 논문이 왜 중요한지, 어떻게 동작하는지, 그리고 2026년의 AI 산업에 어떤 의미인지 깊이 파헤칩니다. 미리 결론부터 말하면 — 이건 단순한 효율화 기법이 아니라, "사고와 언어는 같은가?"라는 70년 묵은 질문에 대한 새로운 답이기도 합니다.
1장. Chain-of-Thought 혁명 — AI에게 "생각의 과정"을 가르친 순간
2022년, 모든 것을 바꾼 한 줄의 프롬프트
시간을 4년 전으로 돌려봅시다. 2022년 1월, 구글 브레인의 Jason Wei 등이 발표한 논문이 AI 추론의 판도를 갈아엎습니다.
"Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"
— Wei et al., NeurIPS 2022
핵심은 우스울 만큼 단순했습니다.
"답을 바로 말하지 말고, 풀이 과정을 한 단계씩 적어보렴."
이 한 마디가 LLM의 수학 풀이 정확도를 PaLM 540B 기준 18%에서 57%로 올렸습니다. 거의 3배. 모델 구조도, 파라미터도, 데이터도 바꾸지 않고 단지 "생각하는 방식"만 바꿨을 뿐입니다.
같은 해 5월, 도쿄대 Kojima 연구팀이 더 충격적인 발견을 합니다 — "Let's think step by step"(차근차근 생각해 보자)이라는 단 한 문장만 프롬프트 끝에 붙여도 같은 효과가 난다는 것이었죠. Zero-shot CoT의 탄생입니다.
CoT가 만든 새로운 시대
그 이후로 CoT는 폭발적으로 진화했습니다:
2022
Chain-of-Thought 등장 — 단계별 추론 프롬프팅, PaLM 540B 수학 정확도 3배
2023
Self-Consistency, Tree-of-Thoughts — 여러 경로를 동시에 탐색하는 방식으로 진화
2024
OpenAI o1 — 답하기 전 수천~수만 개의 "생각 토큰"을 생성하는 추론 모델 시대 개막
2026년 현재, 거의 모든 프론티어 모델은 어떤 형태로든 CoT를 내장하고 있습니다. GPT-5, Claude 4, Gemini 3, Qwen3, Granite 4 — 모두 마찬가지입니다.
그런데 이 화려한 성공의 그림자에서, 연구자들은 점점 불편한 질문을 던지기 시작합니다.
2장. CoT의 그림자 — 토큰의 무게
문제 1: 추론 토큰이 곧 돈이고 시간이다
OpenAI o1이 어려운 수학 문제 하나를 풀 때, 백그라운드에서 평균 수천~수만 개의 "생각 토큰"을 생성합니다. 사용자에게는 보이지 않지만, 요금은 똑같이 청구됩니다.
논문이 보여주는 숫자가 충격적입니다. Qwen3-8B 모델로 MATH-500을 풀 때:
Baseline (CoT 없이): 평균 1,205 토큰
SFT + RL (verbal CoT): 1,671 토큰 (정확도 92.6%)
AIME'25 (더 어려운 문제): 9,343 토큰 (한 문제당!)
AIME 같은 경시대회 수준 문제는 한 문제 풀이에 9,000 토큰 이상을 씁니다. 소설 한 챕터 분량입니다. 100명이 동시에 질문을 던지면 90만 토큰. GPU 1대로는 감당이 안 되는 수준이죠.
문제 2: CoT는 "거짓말"을 한다
더 본질적인 문제가 있습니다. CoT가 모델의 진짜 추론 과정을 보여주지 않는다는 것이죠.
Anthropic의 Tamera Lanham 등이 2023년 발표한 "Measuring Faithfulness in Chain-of-Thought Reasoning"은 충격적인 결과를 내놓았습니다. 모델은 종종:
답을 먼저 결정하고, 나중에 그럴듯한 추론을 만들어냅니다 (post-hoc rationalization)
프롬프트에 살짝 힌트를 주면 답이 바뀌는데, CoT는 그 힌트를 언급하지 않습니다
추론 과정 자체가 답에 대한 신뢰할 만한 설명이 아닐 수 있습니다
"Verbalized CoT can be unfaithful, while leveraging a different latent reasoning process that is not communicated."
— Lanham et al., 2023
다시 말해, 모델은 이미 머릿속(잠재 공간)에서 다른 방식으로 추론하고 있고, 텍스트로 보여주는 CoT는 일종의 "대본"에 가까울 수 있다는 것입니다.
문제 3: 자연어는 추론에 최적화되어 있지 않다
체스 그랜드마스터를 떠올려 봅시다.
매그너스 칼슨이 5초 안에 다음 수를 결정할 때, 그의 머릿속에서 "음, 룩을 e5로 옮기면 비숍이 c4를 노릴 텐데..."라는 문장이 흐르지 않습니다. 그는 패턴으로 생각합니다. 수십만 판의 경험이 추상화된 시각적 직감으로 즉시 떠오르죠.
MIT의 Evelina Fedorenko 교수팀이 2024년 Nature에 발표한 연구 결과도 일치합니다 — 인간의 언어 네트워크는 의사소통에 최적화되어 있지, 추론에 최적화되어 있지 않습니다. 수학 문제를 풀 때, 공간을 추론할 때, 뇌의 언어 영역은 거의 활성화되지 않습니다.
LLM도 마찬가지입니다. Transformer 내부에서는 모든 토큰이 4096차원 (혹은 그 이상)의 풍부한 벡터로 표현됩니다. 그런데 CoT는 매 단계마다 이 벡터를 수만 개 단어 중 하나로 압축하라고 강제합니다. 마치 고해상도 영상의 매 프레임을 1비트 흑백으로 변환하는 것과 같은 정보 손실이 일어나죠.
3장. 잠재 추론으로 가는 여정 — 선구자들
이 문제를 해결하려는 시도는 ACoT가 처음이 아닙니다. "AI가 말이 아닌 다른 방식으로 생각할 수 있을까?"라는 질문은 2024년 무렵부터 본격적으로 연구되기 시작했습니다.
길 1: Pause Tokens — "잠깐 생각할 시간을 주자"
2024년 ICLR에서 Sachin Goyal 등이 발표한 "Think Before You Speak"는 가장 단순한 아이디어를 제시했습니다.
답하기 전에 의미 없는 <pause> 토큰을 N개 끼워넣자. Transformer가 그 토큰들을 처리하는 동안 추가 연산이 일어난다.
발상은 흥미로웠지만 한계가 명확했습니다. Pause 토큰은 의미가 없기에 새 정보를 추가하지 못합니다. 본 논문에서도 ACoT의 비교군으로 등장하는데, 거의 모든 벤치마크에서 baseline보다 떨어지는 결과를 보입니다.
길 2: COCONUT — 연속 잠재 공간에서 생각하기
2024년 12월, Meta AI의 Shibo Hao 등이 발표한 COCONUT (Chain of CONtinuous Thought)이 두 번째 길을 열었습니다. 핵심 아이디어:
히든 스테이트를 토큰으로 변환하지 말고, 그대로 다음 입력으로 재투입하자.
이렇게 하면 모델이 토큰화 병목 없이 연속적인 벡터 공간에서 "잠재 사고"를 이어갈 수 있습니다. 효율적이지만, 연속 공간은 이산 토큰처럼 다루기 어렵고, 강화학습 적용도 까다롭습니다.
길 3: 코드북과 양자화 — 이산화된 잠재 토큰
DiJia Su 등의 "Token Assorted" (2025), Zhenyi Shen 등의 CODI (2025), Shannon Shen 등의 HybridCoT (2026) 같은 연구들은 자연어 토큰과 잠재 토큰을 섞는 하이브리드 방식을 시도했습니다. 효과는 있었지만, 여전히 교사 모델의 추론 경로에 묶여 있다는 한계가 있었습니다.
그리고 — Abstract Chain-of-Thought의 등장
이 모든 흐름의 끝에서 IBM Research가 던진 질문은 신선합니다.
"교사를 따라하지 말고, 모델이 처음부터 자기만의 '추론 언어'를 만들게 하면 어떨까?"
그 결과가 바로 Abstract-CoT입니다. 자연어와도, 연속 잠재 공간과도, 양자화된 코드북과도 다른 — 완전히 새로운 종류의 추론 매체입니다.
4장. Abstract Chain-of-Thought — 완전히 새로운 "추론 언어"
핵심 아이디어 한 줄 요약
논문의 핵심 아이디어는 다음과 같이 요약됩니다.
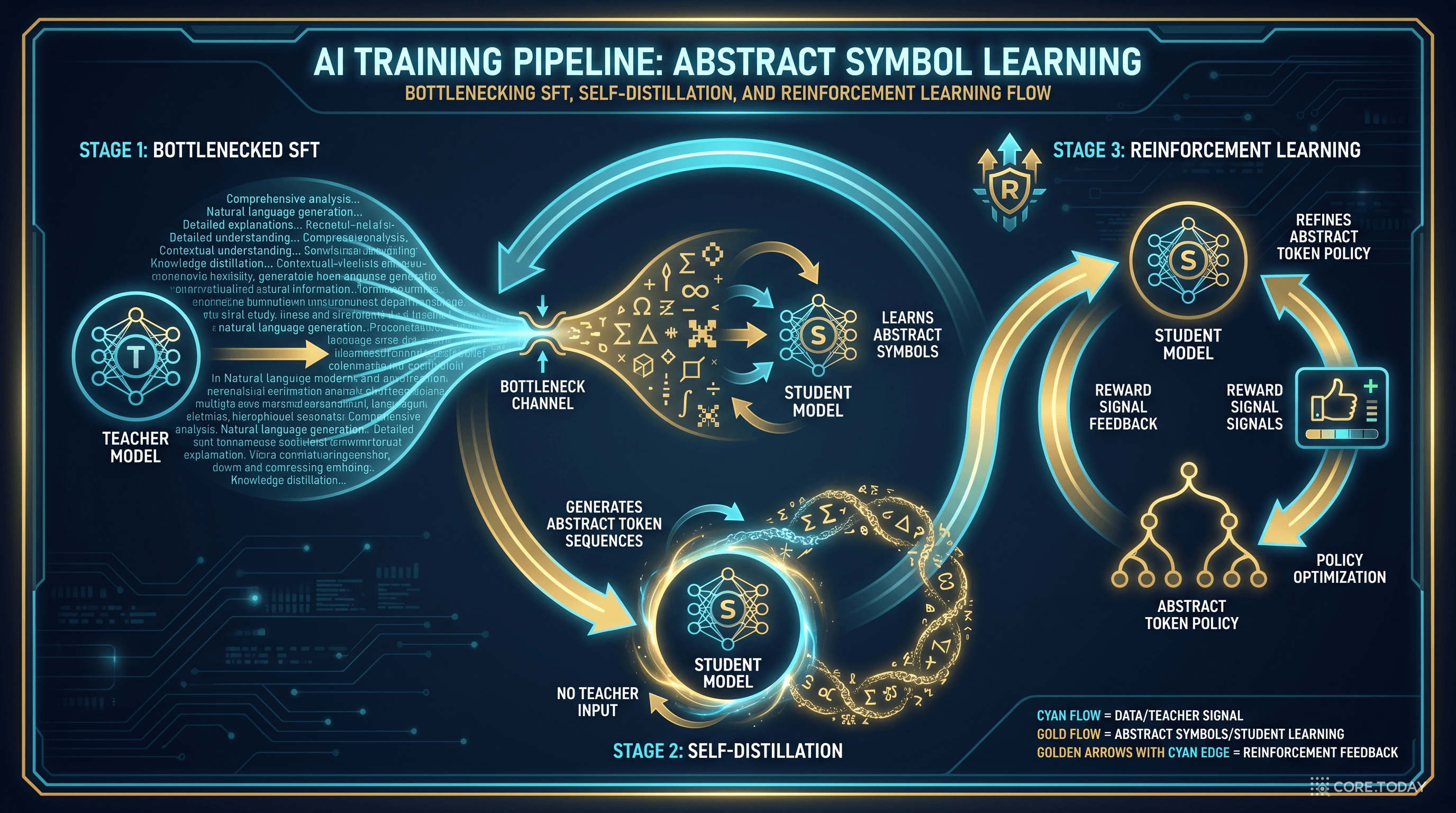
자연어 CoT를 길게 생성하는 대신, 사후 학습으로 새로 만든 64개의 추상 토큰 어휘에서 짧은 시퀀스를 뽑아 "잠재 스크래치패드"로 사용하자.
논문이 가장 강조하는 발견 중 하나는 워밍업 없이 바로 RL을 돌리면 모든 게 무너진다는 것입니다.
방법
MATH-500
AlpacaEval
HotpotQA
Baseline (CoT 없음)
82.4%
52.4%
51.1
Abstract-CoT (RL-only, cold-start)
82.0%
50.4%
49.0
Abstract-CoT (Warm-up only)
88.0%
55.9%
53.7
Abstract-CoT (Warm-up + RL)
90.8%
60.8%
58.8
Cold-start RL은 baseline보다도 못합니다. 워밍업만 해도 baseline을 넘지만, RL과 결합해야 진짜 성능이 나옵니다. 두 단계가 모두 필요합니다.
이게 왜 중요할까요? 강화학습은 보상 신호로 학습하는데, 새로 만든 추상 토큰들은 처음에는 의미가 전혀 없습니다. 보상 신호가 의미 있는 학습 신호로 변환되려면, 사전에 토큰들의 임베딩이 어느 정도 자리 잡혀 있어야 합니다. 워밍업이 그 역할을 합니다.
7장. Power Law의 신비 — AI가 만들어낸 새로운 "언어"
이 논문에서 가장 매혹적인 발견은 따로 있습니다.
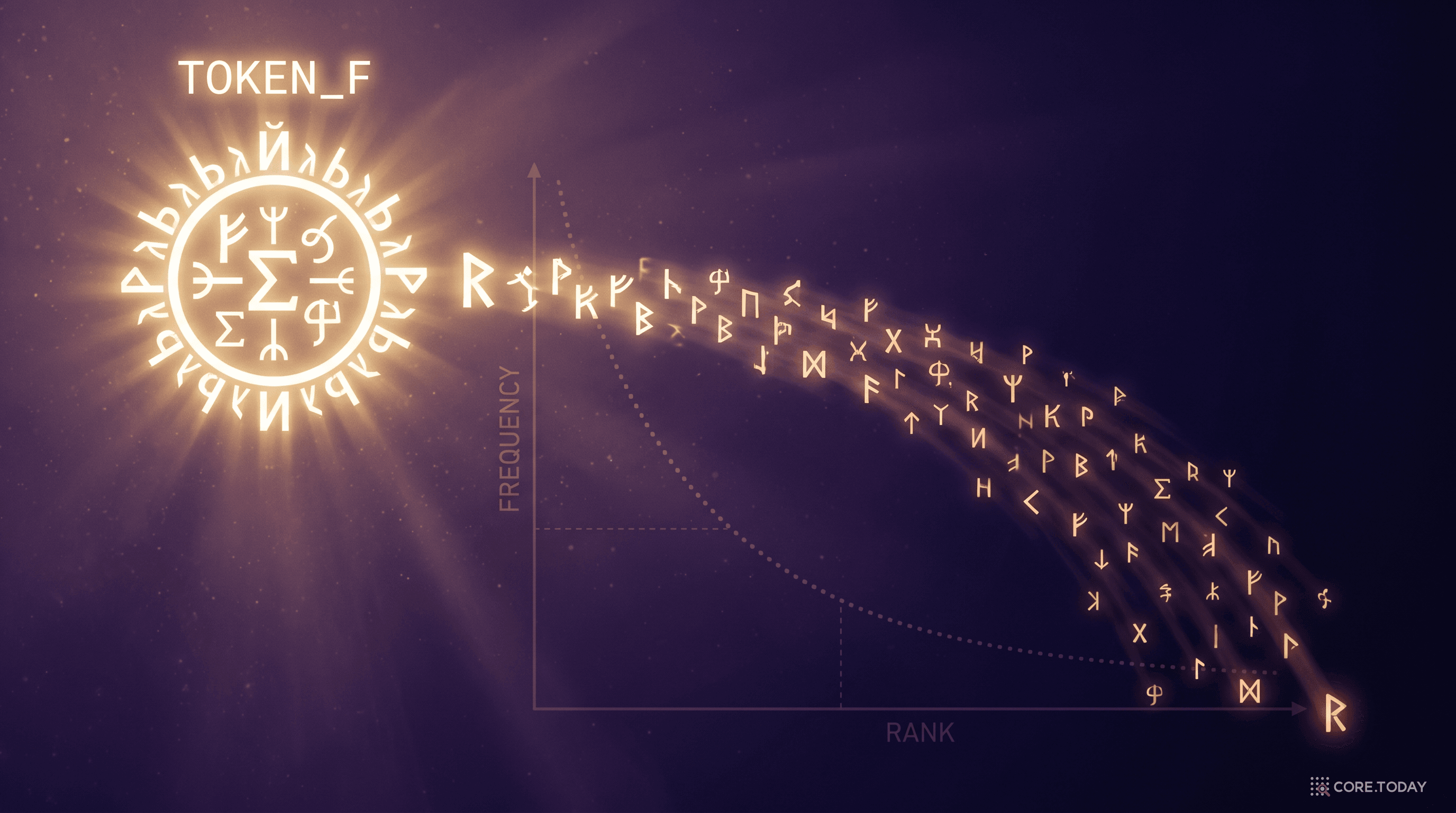
Zipf의 법칙이 외계어에서도 떠오르다
언어학자라면 누구나 아는 법칙이 있습니다 — Zipf의 법칙(Zipf's Law).
자연 언어에서 단어의 출현 빈도는 순위의 역수에 비례한다.
즉, 1순위 단어는 2순위 단어의 2배, 3순위의 3배 ... 이런 식으로 출현한다.
영어, 한국어, 중국어, 라틴어 — 어떤 언어를 분석해도 이 패턴이 나타납니다. "the", "a", "of" 같은 단어가 압도적으로 많이 쓰이고, 나머지는 긴 꼬리(long tail)를 이룹니다.
논문의 Figure 4가 보여준 것은 무엇일까요?
무작위로 초기화된 64개의 추상 토큰이 RL을 거치면서, 자연 언어와 똑같은 power law 분포를 만들어낸다.
구체적으로:
처음에는 64개 토큰이 거의 균등하게 분포 (warm-up이 uniform random initialization으로 시작)
RL 1M 에피소드를 거치면서 한 토큰(<TOKEN_F>)이 압도적으로 많이 사용되기 시작
점차 자연 언어의 Zipf 분포와 닮은 모습으로 수렴
이게 무슨 의미일까요? 모델이 그냥 우연히 <TOKEN_F>를 많이 쓴 게 아닙니다. 이 토큰이 다양한 추론 상황에서 보편적으로 유용한 "기능어" 역할을 한다는 뜻입니다. 자연 언어의 "the"나 "of"처럼요.
논문은 이를 다음과 같이 표현합니다:
"This serves as an indication of the value in the embedding learning stage, promoting token usage across the vocabulary, ... indicating re-use over a learned 'reasoning language'."
모델이 사후 학습만으로 자기만의 "추론 언어(reasoning language)"를 만들어냈다는 것입니다. 영어도 아니고 라틴어도 아닌, 64개 단어로 된 미니 언어. 그리고 그 언어는 자연 언어의 통계적 법칙을 그대로 따르죠.
어휘 크기는 얼마가 적당한가?
논문 부록 A.1은 추상 어휘 크기 M에 대한 ablation을 합니다. M=1,2,4,8,...,512까지 테스트하고:
M = 2 (너무 작음)
M = 8
M = 32
M = 64 (최적)
M = 128
M = 512 (수확체감)
M = 64가 가장 좋고, 그 이상은 오히려 감소합니다. 흥미로운 점은 M=128,256,512로 가면 긴 꼬리(rarely-used tokens)가 점점 길어진다는 것입니다. 모델이 "이 정도 어휘만 있으면 충분하다"고 자율적으로 결정하는 셈이죠.
순열 검사 (Permutation Test)
추상 토큰이 진짜 "언어"라면, 순서를 바꾸면 의미가 달라져야 합니다. "철수가 영희를 봤다"와 "영희가 철수를 봤다"가 다르듯이요.
논문은 추상 시퀀스의 토큰 순서를 랜덤하게 섞은 뒤 답변을 생성시켜 봤습니다:
방법
원본
순열 후
변화량
Verbal CoT (SFT+RL)
92.6%
81.6%
-11.0
Abstract-CoT (PI-3+RL)
90.6%
82.8%
-7.8
두 방법 모두 성능이 크게 떨어집니다. 그런데 Abstract-CoT의 하락폭(-7.8)이 verbal CoT(-11.0)보다 작습니다. 이는 추상 토큰이 자연어보다 약간 더 permutation-invariant하다는 뜻이지만, 동시에 순서가 의미를 만든다는 사실은 명확합니다. 추상 토큰들이 단순한 "더미 패딩"이 아니라 구조적, 합성적 의미를 갖는다는 강력한 증거입니다.
Truncation Test (잘라보기)
만약 추상 시퀀스를 32개로 강제 잘라낸다면? 일반적인 verbal CoT를 32 토큰에서 잘라내면 어떤 일이 벌어질까요?
방법
전체
32 토큰만
하락폭
Verbal CoT (SFT+RL)
92.6%
80.9%
-11.7
Abstract-CoT (PI-3+RL, M=64)
90.8%
84.6%
-6.2
Verbal CoT는 무참히 무너집니다(-11.7). 하지만 Abstract-CoT는 상대적으로 우아하게 열화합니다(-6.2). 이미 짧은 trace로 추론하도록 훈련됐기 때문이죠. 이건 inference-time budget control 측면에서도 큰 장점입니다 — "오늘은 토큰을 적게 쓰라"고 시스템에 명령했을 때, ACoT가 더 잘 적응합니다.
96개의 추상 토큰. 사람이 읽을 수는 없지만, 모델은 이 시퀀스로 정확히 같은 답에 도달합니다.
예시 2: 기하 문제 (헤론의 공식)
예시: 기하 (논문 Appendix C.1.2)
문제: 변의 길이가 13, 14, 15인 삼각형 ABC의 넓이와 변 b로의 수선 길이를 구하시오.
Verbal CoT 풀이 (요약):
반둘레 s=21
헤론 공식: A=21⋅8⋅7⋅6=7056=84
수선: h=2×84/14=12
(대략 500자 + 여러 수식)
Abstract CoT (실제 출력): 약 70개의 추상 토큰
모델 답변: "헤론 공식과 반둘레 s=21로 넓이는 84, 변 BC로의 수선은 h=142×84=12"
흥미로운 점이 보입니다. 두 예시에서 추상 시퀀스에 공통적으로 등장하는 토큰들이 있습니다 — <TOKEN_C>, <TOKEN_M>, <TOKEN_R>, <TOKEN_AD>. 이들은 수학 추론 전반에서 보편적으로 쓰이는 "기능어"인 것이죠. 마치 자연어의 "if", "then", "therefore" 같은 역할을 하는 것으로 추측됩니다.
논문은 명시적으로 해석하지 않지만, 그 자체가 흥미로운 미래 연구 방향입니다 — 이 추상 토큰들의 의미를 역공학(reverse engineer)할 수 있을까?
예시 3: 일반 지시 따르기 (Lifestyle Advice)
논문 Appendix C.2.1에는 수학이 아닌 일반 대화 예시도 있습니다. 이런 식의 프롬프트:
"바쁜 직장인이 더 건강한 식습관을 만들기 위한 5가지 실용적 팁을 제안해주세요."
이 경우에도 모델은 30~50개의 추상 토큰을 만든 뒤 답변을 생성합니다. 그 답변은 verbal CoT 버전과 비교해 거의 차이가 없거나 오히려 더 정돈된 모습을 보입니다. 일반 대화에서도 "잠재 추론 → 답변"의 패러다임이 작동한다는 증거입니다.
9장. 인터랙티브 비교 — 직접 봐야 와닿는다
지금까지의 내용을 한눈에 비교해 봅시다.
😩
기존 Verbal CoT의 문제
"step 1, step 2, step 3..." — 인간이 읽기 좋게 풀이하느라 토큰을 1500~9000개씩 소모. 비싸고, 느리고, 심지어 "거짓말"일 수 있음 (CoT unfaithfulness)
💡
Abstract CoT의 해법
새로운 64개의 추상 토큰 어휘를 사후 학습으로 추가. 3단계 파이프라인(Bottlenecking → Self-Distillation → GRPO)으로 토큰들에 의미를 부여. 추론 시점에는 자연어 CoT 없이 짧은 추상 시퀀스만 생성
🚀
결과
최대 11.6배 적은 토큰, 같거나 더 좋은 성능. 자연어와 동일한 Zipf 법칙이 외계어에서도 떠오름. AlpacaEval과 HotpotQA에서는 verbal CoT를 능가
10장. 한계와 열린 질문들
논문은 자신의 한계를 솔직하게 인정합니다.
한계 1: 인간이 읽을 수 없다 (Black-box)
가장 명백한 단점입니다. <TOKEN_F>가 정확히 무엇을 의미하는지 우리는 모릅니다. 디버깅, 안전성 검증, 감사(audit)에는 불리합니다.
다만 논문은 이를 "chain-of-thought monitorability에 대한 새로운 인터페이스"로 재해석합니다. 자연어 CoT가 unfaithful할 수 있다는 점을 고려하면, 차라리 명시적으로 "이건 잠재 표현이고 인간이 못 읽음"이라고 선언하는 게 더 정직할 수 있습니다.
한계 2: AIME 같은 극한 추론에서는 압축 효과가 작다
AIME'25에서 압축 비율은 2.7배로, MATH-500의 11.6배에 비하면 작습니다. 올림피아드 수학처럼 정말 긴 추론이 필요한 영역에서는 64 토큰이 부족할 수 있습니다.
논문은 미래 방향으로 "budget-adaptive Abstract-CoT"를 제시합니다 — 문제 난이도에 따라 추상 시퀀스 길이를 동적으로 조절하는 방식입니다.
한계 3: 사후 학습 비용
ACoT 학습 자체가 비싸지는 않지만(8x H100 GPU), policy iteration 3라운드 + RL 1M 에피소드는 무시할 수 없는 컴퓨팅을 요구합니다. 이 비용을 한 번 치르면 추론 단계에서 영구적으로 토큰을 절약하는 셈이지만, 진입 장벽은 있습니다.
한계 4: 코드북의 작업 전이성
현재 학습된 64개 토큰은 한 번에 하나의 작업 분포에 대해 최적화됩니다. 수학용 코드북, 코딩용 코드북, 일반 대화용 코드북이 다를 수 있죠. 논문은 계층적 코드북(hierarchical codebook)으로 재사용 가능한 서브루틴을 만드는 방향을 제안합니다.
11장. 2026년의 의미 — 추론 효율 전쟁의 새 라운드
추론 모델 시대의 핵심 모순
2026년 AI 산업의 핵심 모순 중 하나는 이렇습니다:
추론 능력 향상
→
더 긴 CoT 필요
→
토큰 비용 폭증
→
서비스 단가 상승
OpenAI o3, DeepSeek-R2, Anthropic의 추론 모델 — 모두 길어지는 CoT의 비용 부담을 안고 있습니다. 한 번의 어려운 질문에 수만 토큰이 소모되는 건 일상이 됐습니다.
ACoT가 보여주는 것은 다음과 같습니다:
"추론 능력과 토큰 길이 사이의 트레이드오프는 본질적인 것이 아니다. 우리는 다른 매체로 같은 추론을 할 수 있다."
코어닷투데이의 관점에서
저희가 다양한 LLM 기반 서비스를 만들면서 가장 자주 마주치는 문제 중 하나가 바로 추론 토큰 비용입니다. 고객이 어려운 질문 하나에 5초~30초씩 기다리고, 그 사이 서버는 수천 토큰을 생성하며, 결국 청구서가 늘어납니다.
ACoT 같은 기술이 상용화되면 어떤 변화가 있을까요?
Abstract CoT가 가져올 산업 변화
💰 추론 단가 90% 절감
11.6× 압축 시 토큰 비용 동등
⚡ 응답 속도 개선
생성 토큰 수가 곧 latency
📱 온디바이스 추론
짧은 trace로 모바일/엣지 가능
🔒 IP 보호
추론 과정이 가독 불가 → 모방 어려움
🧠 새 추론 패러다임
언어 ≠ 사고의 증거
🔬 해석 가능성 연구
학습된 토큰의 의미 역공학
안전성과의 미묘한 긴장
한 가지 주의할 점이 있습니다. AI 안전 연구자들은 CoT의 가독성을 안전성의 중요한 도구로 봅니다. 모델이 무슨 생각을 하는지 들여다볼 수 있어야 위험한 추론(예: 사용자 속이기, 자기 보존)을 잡아낼 수 있다는 것이죠.
ACoT는 이 가독성을 포기합니다. 논문도 이를 인정하면서, "abstract token monitoring"이라는 새로운 형태의 감사 도구가 필요할 것이라고 제안합니다. 이건 향후 몇 년의 큰 연구 방향이 될 것 같습니다.
"AI가 단어 없이 생각한다"는 명제
마지막으로 — 이 논문의 가장 큰 의미는 어쩌면 기술적인 것이 아닐지도 모릅니다.
수십 년간 우리는 "생각은 곧 언어"라는 무언의 가정 위에서 AI를 만들어왔습니다. ChatGPT가 단어 단위로 "타이핑"하면서 답하는 모습은 바로 그 가정의 시각화죠.
ACoT는 이 가정에 균열을 냅니다. 모델은 사후 학습 단계에서 자기만의 언어를 만들고, 그 언어로 인간의 언어보다 더 효율적으로 추론할 수 있다. 그리고 그 과정에서 자연 언어의 통계적 특성(Zipf의 법칙)이 자발적으로 떠오르죠.
체스 그랜드마스터가 말없이 패턴으로 생각하듯, 메시가 0.5초 안에 패스를 결정하듯 — AI도 그럴 수 있다는 증명입니다.
"Our findings highlight the potential for post-training latent reasoning mechanisms that enable efficient inference through a learned abstract reasoning language."
— Ramji et al., 2026
마치며: 다음 5년의 풍경
ACoT 같은 기술이 주류가 되기까지는 시간이 걸릴 것입니다. 학습 파이프라인이 복잡하고, 안전성 검증 프레임워크도 새로 만들어야 합니다.
하지만 방향은 명확합니다. 2030년의 LLM은 지금처럼 단어로 "타이핑하며" 생각하지 않을 가능성이 큽니다. 추상 토큰일 수도, 연속 잠재 공간일 수도, 우리가 아직 상상하지 못한 다른 매체일 수도 있습니다.
그리고 그 모델들은 더 빠르고, 더 싸고, 더 강력할 것입니다.
이 논문이 던지는 가장 흥미로운 질문은 이것입니다:
만약 AI가 인간이 이해할 수 없는 언어로 더 잘 생각할 수 있다면, 우리는 그 언어를 받아들일 준비가 되어 있는가?
답은 시간이 알려줄 것입니다.
참고 문헌
Ramji, K., Naseem, T., Astudillo, R. F. (2026). Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought. IBM Research AI. arXiv:2604.22709
Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022
Hao, S. et al. (2025). Training Large Language Models to Reason in a Continuous Latent Space (COCONUT). COLM 2025
Goyal, S. et al. (2024). Think Before You Speak: Training Language Models with Pause Tokens. ICLR 2024
Lanham, T. et al. (2023). Measuring Faithfulness in Chain-of-Thought Reasoning. arXiv:2307.13702
Guo, D. et al. (2025). DeepSeek-R1 Incentivizes Reasoning in LLMs through Reinforcement Learning. Nature 645(8081)
Shao, Z. et al. (2024). DeepSeekMath (GRPO algorithm). arXiv:2402.03300
Korbak, T. et al. (2025). Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety. arXiv:2507.11473