"게임은 일련의 흥미로운 선택이다." — 시드 마이어 (Sid Meier), 문명(Civilization) 시리즈 창시자
여러분은 Flappy Bird를 해본 적 있나요? 화면을 탭 한 번 할 때마다 새가 날개짓을 하고, 파이프 사이를 빠져나가는 단순한 게임입니다. 인간은 몇 번 죽은 후 금세 타이밍 감각을 익히죠. 그런데 세계 최고의 AI 모델에게 이 게임을 시키면 어떻게 될까요?
수십 조 파라미터를 가진 AI가, 탭 하나의 타이밍도 못 맞춥니다.

2026년 4월, 싱가포르 국립대학교(NUS)와 옥스포드 대학교의 연구진이 발표한 GameWorld 논문(arXiv:2604.07429)은 이 질문에 체계적인 답을 제시합니다. 34개의 브라우저 게임과 170개의 태스크로 구성된 이 벤치마크는 현재 AI 에이전트의 게임 플레이 능력을 가장 포괄적으로 측정한 연구입니다.
결론부터 말하면: 최고의 AI도 게임 초보자에게 크게 진다. 이게 왜 중요한지, 차근차근 이야기해 봅시다.
1. AI와 게임: 30년의 역사
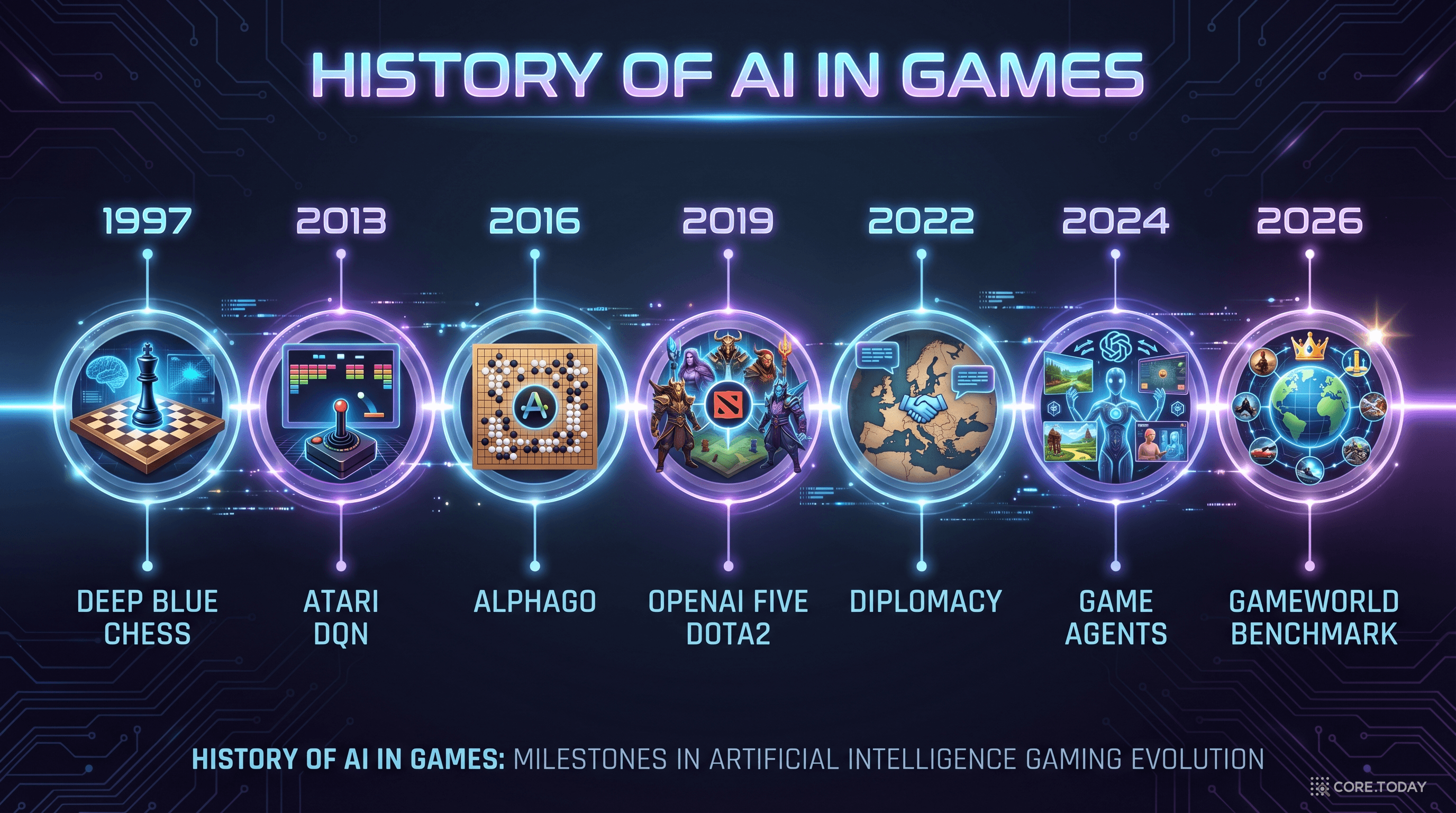
비디오 게임은 AI 연구의 '시금석(試金石)'이었습니다. 체스, 바둑, 스타크래프트 — 각 시대의 가장 어려운 게임을 정복하는 것이 곧 AI 발전의 이정표가 되어 왔죠.
룰 기반에서 학습 기반으로
1997
Deep Blue vs 카스파로프 — IBM의 체스 AI가 세계 챔피언을 꺾다. 하드코딩된 평가 함수와 무차별 탐색의 승리.
2013
Atari DQN — DeepMind가 화면 픽셀만 보고 Atari 게임을 학습. 강화학습(RL) 혁명의 시작.
2016
AlphaGo vs 이세돌 — 바둑의 탐색 공간(
10170)을 딥러닝으로 정복. "AI가 직관을 가졌다"는 논의 촉발.
2019
OpenAI Five — Dota 2에서 세계 챔피언을 꺾다. 실시간 팀 전략과 불완전 정보를 다룸.
2022
Cicero — Meta의 AI가 외교 게임 Diplomacy에서 인간 수준 달성. 언어 + 전략 + 협상.
2026
GameWorld — 34개 게임 × 18개 MLLM 모델. "범용 게임 에이전트"를 처음으로 체계적으로 평가.
과거 AI와 지금의 차이점
과거의 게임 AI(AlphaGo, OpenAI Five 등)에는 공통점이 있습니다: 한 게임에 특화되어 있었다는 겁니다. AlphaGo는 바둑만 둘 수 있고, OpenAI Five는 Dota 2만 할 수 있었죠. 각각의 게임을 수백만 판 이상 학습시켜야 했습니다.
2026년 지금, 질문이 달라졌습니다:
"하나의 AI가 아무 게임이나 할 수 있을까?"
GPT-5.2, Claude Sonnet 4.6, Gemini 3 같은 멀티모달 대규모 언어 모델(MLLM)은 텍스트, 이미지, 코드를 모두 이해합니다. 이론적으로는 게임 화면을 보고, 규칙을 읽고, 적절한 행동을 취할 수 있어야 합니다. GameWorld는 바로 이 가설을 검증합니다.
2. 기존 벤치마크의 한계: 왜 GameWorld가 필요한가?
GameWorld 이전에도 게임 에이전트를 평가하려는 시도는 있었습니다. 하지만 각각 심각한 한계를 가지고 있었죠.
🔴
문제 1: 이종 액션 인터페이스
각 벤치마크가 서로 다른 방식으로 에이전트를 조작합니다. 어떤 건 키보드 입력, 어떤 건 API 호출, 어떤 건 텍스트 명령. 모델 간 공정한 비교가 불가능했습니다.
🔴
문제 2: 휴리스틱 평가
대부분의 벤치마크가 OCR이나 "VLM을 심판으로 사용"하는 방식에 의존했습니다. AI가 AI를 평가하는 셈이라 결과가 불안정하고 재현이 어려웠습니다.
🟢
GameWorld의 해결책
표준화된 두 가지 에이전트 인터페이스(CUA / Generalist)와 게임 내부 상태를 직접 읽는 결정론적(State-Verifiable) 평가 시스템을 도입했습니다.
기존 벤치마크와의 비교
| 벤치마크 | 게임 수 | 태스크 | 비전 중심 | 검증 가능 평가 |
|---|
| VideoGameBench | 23 | 23 | O | X (휴리스틱) |
| FlashAdventure | 34 | 34 | O | X (CUA-as-Judge) |
| BALROG | 6 | 48 | X | O |
| V-MAGE | 5 | 30 | O | X |
| GameWorld | 34 | 170 | O | O (State-Verifiable) |
GameWorld만이 대규모 게임 수(34개), 다수 태스크(170개), 비전 중심 평가, 결정론적 검증을 모두 갖추고 있습니다.
3. GameWorld 아키텍처: 어떻게 작동하나?
GameWorld는 네 가지 핵심 모듈로 구성됩니다.
① MLLM 게임 에이전트
스크린샷 관찰 → 추론 → 액션 생성
② 브라우저 샌드박스
Chromium 격리 환경
추론 중 게임 일시정지
③ 게임 & 태스크 라이브러리
34게임 × 170태스크
5개 장르 분류
④ 상태 검증 평가기
gameAPI에서 직렬화된 상태 읽기
결정론적 SR / PG 계산
핵심 설계: 추론 속도 ≠ 게임 실력
가장 혁신적인 설계 결정은 일시정지(Pause) 메커니즘입니다. 에이전트가 "다음에 뭘 할까?" 고민하는 동안 게임 시계가 멈춥니다. 이게 왜 중요할까요?
GPT-5.2는 한 스텝에 약 3.9초가 걸리고, Grok-4.1은 2.5초가 걸립니다. 만약 게임이 멈추지 않으면, 느린 모델은 빠른 게임에서 타이밍을 놓치게 됩니다. 이러면 "모델의 판단력"이 아니라 "모델의 속도"를 평가하게 되죠.
GameWorld는 이를 분리합니다:
- 기본 모드 (Paused): 의사결정 품질만 평가
- GameWorld-RT (Real-Time): 속도까지 포함한 실시간 평가
상태 검증 평가: AI 심판 없이
기존 벤치마크: "스크린샷을 찍어서 다른 AI에게 '이거 성공한 거야?' 물어봄"
GameWorld: "게임 내부 JavaScript API에서 점수, 좌표, 레벨, 생명 수를 직접 읽어옴"
34개 게임에 걸쳐 총 233개의 상태 변수를 추적합니다. 예를 들어 마리오 게임에서는:
hljs language-json
{
"score": 1200,
"level": 2,
"player_x": 342.5,
"player_y": 128.0,
"lives": 2,
"coins": 8,
"enemies_defeated": 3,
"checkpoint_reached": true
}
이 데이터로 Progress(진행률)을 계산합니다:
progressi=clip[0,1](τi−biqimax−bi)
여기서 qimax는 런에서 달성한 최고 점수, bi는 시작 점수, τi는 목표 점수입니다. 부분 진행도 인정되므로, "완전 실패 vs 완전 성공"의 이분법을 피할 수 있습니다.
4. 두 가지 에이전트 인터페이스: CUA vs Generalist
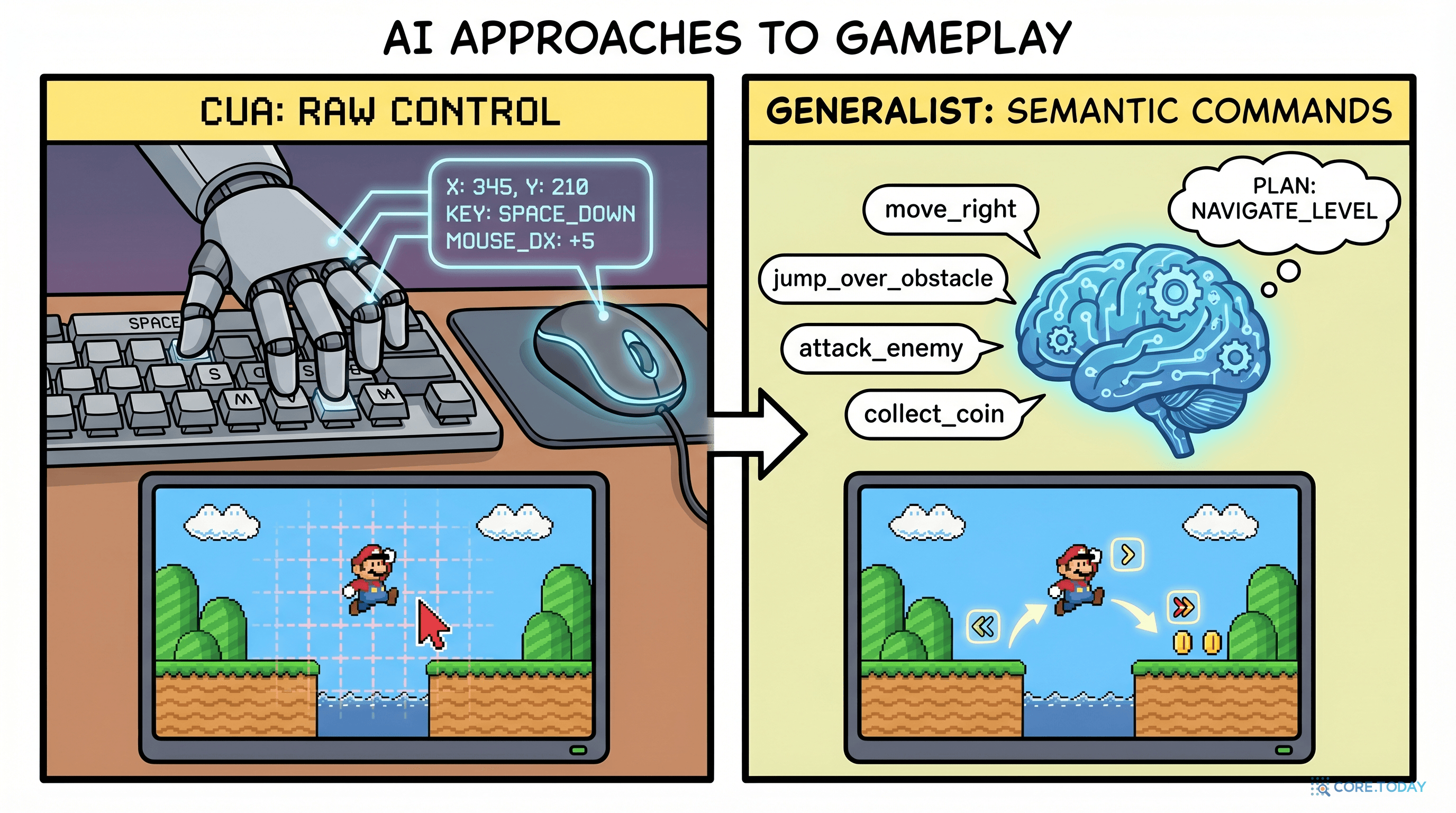
GameWorld의 또 다른 혁신은 두 가지 제어 방식을 동시에 평가한다는 점입니다.
CUA (Computer-Use Agent): "키보드와 마우스를 직접 조작"
CUA는 화면의 스크린샷을 보고 실제 키보드/마우스 입력을 생성합니다. 마치 사람이 컴퓨터 앞에 앉아 플레이하는 것처럼요.
mouse_move(342, 256) // 마우스를 특정 좌표로 이동
left_click(342, 256) // 해당 좌표 클릭
press_key(ArrowRight) // 오른쪽 화살표 키 누르기
press_key(Space) // 스페이스바로 점프
장점: 어떤 게임이든 적용 가능. 게임별 별도 설정 불필요.
단점: 정밀한 좌표 지정이 어렵고, 타이밍 제어가 부정확.
Generalist Agent: "의미 기반 명령어 사용"
Generalist는 게임마다 정의된 의미적 액션(semantic action)을 사용합니다. move_forward(), action_jump() 같은 고수준 명령어죠.
move_right() // 오른쪽으로 이동
action_jump() // 점프
move_left() // 왼쪽으로 이동
no_op() // 아무것도 안 함 (대기)
장점: 전략적 사고에 집중 가능. 정밀 좌표 걱정 없음.
단점: 게임마다 액션 정의 필요. 자유도 제한.
핵심 발견: 두 인터페이스의 성능이 비슷하다
놀랍게도, 같은 모델이 CUA와 Generalist로 플레이했을 때 전체 성능이 크게 다르지 않습니다. 하지만 성격이 다릅니다:
CUA 강점
러너 게임에서 약간 우위 — 단순 반복 키 입력에 유리
Generalist 강점
퍼즐/시뮬레이션에서 약간 우위 — 전략적 사고에 집중 가능
공통 약점
정밀 타이밍, 공간 탐색, 장기적 계획 수행 모두 취약
5. 34개 게임, 5개 장르: 어떤 게임을 테스트하나?

GameWorld는 5개 장르에 걸쳐 총 34개의 브라우저 게임을 포함합니다. 각 장르는 서로 다른 인지 능력을 테스트합니다.

장르별 핵심 특성
| 장르 | 게임 수 | 핵심 능력 | 대표 게임 |
|---|
| 러너 | 8 | 고빈도 반사 제어, 타이밍 | Chrome Dino, Flappy Bird, Temple Run 2 |
| 아케이드 | 7 | 빠른 폐루프 제어, 동적 추적 | Pac-Man, Breakout, Google Snake |
| 플랫포머 | 8 | 시공간 탐색, 물리 기반 이동 | Mario Game, Doodle Jump, Vex 3 |
| 퍼즐 | 7 | 전략적 계획, 논리적 추론 | 2048, Tetris, Minesweeper, Wordle |
| 시뮬레이션 | 4 | 오픈월드 탐색, 자원 관리 | Minecraft Clone, Wolfenstein 3D |
왜 브라우저 게임인가?
연구진이 AAA 타이틀 대신 브라우저 게임을 선택한 이유가 있습니다:
- 가볍다: 별도 설치 없이 Chromium에서 실행
- 다양하다: 단순 러너부터 복잡한 3D 시뮬레이션까지
- 리셋이 쉽다: 한 판이 끝나면 즉시 재시작
- JavaScript 접근: 게임 내부 상태를 JS API로 직접 읽을 수 있음
6. 실험 결과: 최고의 AI도 초보 게이머에게 진다
18개 모델-인터페이스 조합을 170개 태스크에서 평가한 결과입니다. 아래 인터랙티브 탐색기에서 직접 확인해 보세요.
핵심 발견들
발견 1: 최고 AI의 Progress는 41.9%, 초보 인간은 64.1%
가장 잘하는 AI(Gemini-3-Flash, 41.9%)조차 초보 플레이어(64.1%)에 22% 포인트나 뒤처집니다. 숙련 플레이어(82.6%)와는 거의 두 배 가까운 차이입니다.
발견 2: 장르별 성능 편차가 크다
모든 모델이 러너 게임에서 가장 높은 Progress(49~56%)를 보이고, 시뮬레이션에서 가장 낮습니다(1.7~21.1%). 이는 러너가 단순 반복에 가깝고, 시뮬레이션은 장기적 계획이 필요하기 때문입니다.
상위 모델(Gemini-3-Flash, Generalist) 기준 장르별 Progress
발견 3: Success Rate는 더 참혹하다
Progress(부분 진행도)는 41.9%까지 올라가지만, Success Rate(완전 성공률)은 최고 21.2%에 불과합니다. 즉, 에이전트가 "어느 정도는 진행"하지만, 목표를 달성까지 완수하는 경우는 매우 드뭅니다.
이는 게임에서 치명적인 문제입니다. "80%까지 진행했다가 죽는 것"은 결국 실패니까요.
7. 5단계 능력 커리큘럼: AI의 강점과 약점
논문의 가장 통찰력 있는 분석 중 하나는 5단계 능력 커리큘럼입니다. 34개 게임을 요구하는 핵심 능력에 따라 5개 레벨로 분류했습니다.
Level 1
기본 제어 & 타이밍 그라운딩 — 시각 정보를 올바른 원자적 상호작용으로 매핑. Breakout, Core Ball, Stack
Level 2
시스템-1 반사 제어 — 고빈도 반사 행동. 빠르게 변하는 장면에서 즉각 반응. Chrome Dino, Flappy Bird, Temple Run 2, Run 3 등 12개 게임
Level 3
시스템-2 공간 탐색 — 2D/3D 기하학적 세계 모델링과 의도적 경로 탐색. Mario, Pac-Man, Wolfenstein 3D, World's Hardest Game 등 11개 게임
Level 4
상징적 추론 & 전략 — 규칙 집약적 환경에서 전략적 계획. 2048, Tetris, Minesweeper, Wordle 등 5개 게임
Level 5
오픈월드 조정 & 관리 — 탐색, 상호작용, 하위 목표 관리가 결합된 개방형 환경. Fireboy & Watergirl, Minecraft Clone, Monkey Mart
레이더 차트가 보여주는 것
논문의 Figure 5에서, 레이더 차트의 형태가 모든 모델에서 비슷합니다:
- Level 2 (반사 제어): 상대적으로 강함 — MLLM이 "패턴 인식 → 즉시 반응"에 괜찮음
- Level 4 (상징적 추론): 가장 강함 — MLLM의 언어적 추론 능력이 직접 활용됨
- Level 1 (타이밍 그라운딩): 급격히 하락 — "언제 정확히" 행동해야 하는지 모름
- Level 5 (오픈월드): 급격히 하락 — 장기적 계획을 유지하지 못함
💡
핵심 인사이트
AI 에이전트의 강점은 기반 모델(Foundation Model)의 강점을 그대로 상속합니다. MLLM은 본질적으로 "언어적 추론"에 강하고 "물리적 타이밍"에 약합니다. 게임 능력도 이 패턴을 정확히 따릅니다.
시스템-1 vs 시스템-2 사고로 이해하면 더 명확합니다:
- 시스템-1 (빠른 직관적 반응): 인간은 반복 훈련으로 무의식적 반응을 형성합니다. MLLM은 매 프레임 "생각"을 해야 합니다.
- 시스템-2 (느린 분석적 사고): MLLM이 원래 잘하는 영역. Wordle의 단어 추론, 2048의 전략 수립.
8. 사례 연구: 구체적으로 어떻게 실패하는가?

사례 1: Flappy Bird — 타이밍의 잔혹함
논문의 Figure 8은 연속된 Flappy Bird 프레임을 보여줍니다. 사람 눈에는 거의 같아 보이는 두 프레임이지만, 하나에서는 기다려야 하고 다른 하나에서는 탭해야 합니다. 약간의 타이밍 차이가 생사를 가릅니다.
MLLM은 이 문제에서 구조적으로 불리합니다:
- 스크린샷 한 장만 보고 판단 (속도/가속도 추론 불가)
- "지금 탭"과 "0.1초 후 탭"의 차이를 표현할 방법이 없음
- 이전 프레임의 새 위치를 기억해도, 물리 시뮬레이션이 불가능
사례 2: Mario — CUA vs Generalist의 차이
같은 모델(Claude-Sonnet-4.6)이 마리오를 플레이할 때:
| CUA | Generalist |
|---|
| "press_key(ArrowRight)를 200ms 실행" | "move_right()를 호출" |
| 점프 높이를 키 누르기 시간으로 조절해야 함 | action_jump()이 일정한 점프 높이를 보장 |
| 좌표 착오로 엉뚱한 곳을 클릭하는 경우 발생 | 전략적 판단에 집중 가능 |
CUA는 "어떤 키를 얼마나 눌러야 하는가"까지 판단해야 하므로 부담이 더 큽니다. 반면 Generalist는 "오른쪽으로 갈까 점프할까"라는 전략적 판단에만 집중합니다.
사례 3: Minecraft — 90%까지 갔지만 실패
논문의 Figure 7은 Minecraft Clone에서 자원 수집 태스크를 보여줍니다. 에이전트는 locally plausible한(국소적으로 합리적인) 행동을 계속합니다 — 나무를 찾고, 캐고, 다른 자원으로 이동하고... Progress가 90%까지 올라갑니다.
하지만 100스텝 제한 내에 목표량을 달성하지 못합니다. 문제는 "방향 감각"의 부재입니다. 이미 캔 나무가 있는 곳으로 되돌아가거나, 가까운 자원을 무시하고 먼 곳으로 가는 등 전체적인 계획이 없었습니다.
9. 추가 실험: 더 깊은 분석들
실시간 평가 (GameWorld-RT)
게임을 일시정지하지 않으면 어떻게 될까요?
| 모델 | 응답 시간 | Paused PG | RT PG |
|---|
| Qwen3-VL-30B (빠름) | 2.4초/스텝 | 30.8% | 33.0% |
| Qwen3-VL-235B (느림) | 6.2초/스텝 | 31.4% | 33.2% |
흥미롭게도, 실시간 모드에서 성능이 오히려 비슷하거나 약간 높습니다. 이유는: 일시정지 모드에서는 정확히 100개의 의사결정을 하지만, 실시간 모드에서는 게임이 계속 진행되므로 일부 구간을 "자동으로" 넘기기도 합니다. 그러나 Success Rate은 여전히 매우 낮아서, 빠른 반응만으로 문제가 해결되지 않음을 보여줍니다.
Context Memory: 많이 기억하면 잘할까?
Qwen3-VL-235B 기준, Context Memory 라운드별 Progress (%)
결과가 극명합니다:
- Generalist: 과거 의미적 행동 기억이 도움이 됨 → 소폭 상승
- CUA: 과거 저수준 좌표/키 입력 기억이 방해가 됨 → 오히려 하락
이유는 간단합니다. move_right()라는 의미적 히스토리는 "아, 이전에 오른쪽으로 갔구나"라는 맥락을 제공합니다. 하지만 press_key(ArrowRight) + mouse_move(342, 256)이라는 저수준 히스토리는 의미 있는 맥락을 주지 못하면서 토큰만 낭비합니다.
액션 유효성: 명령을 제대로 내리기는 하나?
대부분의 최신 모델(Claude, Gemini, GPT, Seed)은 0%의 무효 액션 비율(IAR)을 보입니다. 함수 호출 형식을 완벽히 따르죠. 하지만 일부 모델은 문제가 있습니다:
| 모델 | 무효 액션 비율 | 주요 원인 |
|---|
| Claude-Sonnet-4.6 | 0.0% | - |
| GPT-5.2 | 0.0% | - |
| Gemini-3-Flash | 0.0% | - |
| Qwen3-VL-30B | 2.7% | No-Tool-Call (도구 미호출) |
| GLM-4.6V | 8.3% | No-Tool-Call (7.6%) + OOS (0.7%) |
GLM-4.6V는 8.3%의 시간 동안 실행 가능한 액션 대신 자유형 텍스트를 출력합니다. 이는 게임에서 "가만히 서 있다가 죽는" 것과 같습니다.
10. 벤치마크의 신뢰성: 10번 반복해도 결과가 같을까?
벤치마크가 유용하려면 재현 가능해야 합니다. 같은 모델을 10번 돌렸을 때 결과가 들쭉날쭉하면, 그 벤치마크 점수는 의미가 없죠.
GameWorld는 4개의 Qwen 모델-인터페이스 조합을 각각 10번 전체 벤치마크를 재실행했습니다:
| 모델 | 인터페이스 | PG 평균 ± 표준편차 |
|---|
| Qwen3-VL-30B | CUA | 30.9 ± 1.1 |
| Qwen3-VL-30B | Generalist | 30.7 ± 1.1 |
| Qwen3-VL-235B | CUA | 30.4 ± 0.7 |
| Qwen3-VL-235B | Generalist | 30.1 ± 0.5 |
표준편차가 0.5~1.4%로 매우 작습니다. 이는 GameWorld의 상태 검증 평가 방식이 매우 안정적이라는 것을 증명합니다. "AI 심판"을 쓰는 벤치마크에서는 이런 수준의 재현성을 기대하기 어렵습니다.
11. 비용: 이 실험에 얼마가 들었나?
AI 연구의 현실적 측면도 살펴봅시다. 18개 모델을 170개 태스크에서 각각 100스텝씩 실행하는 데 드는 API 비용:
모델별 170태스크 × 100스텝 실행 비용 (USD)
총 비용: 815.</strong> 흥미로운 점은, 1위 모델인 Gemini-3-Flash(\29)가 Claude-Sonnet-4.6($244)의 8분의 1 비용으로 더 높은 성능을 달성했다는 것입니다. 비용 효율성과 성능이 반드시 비례하지 않습니다.
12. 실패 유형 분류: AI는 어디서 무너지나?
논문은 에이전트의 실패를 네 가지 범주로 분류합니다:
👁️ 지각 실패
시각 상태를 잘못 읽음. 물체 위치, UI 요소, 공간 배치를 오인
🎯 정밀 행동 실패
올바른 의도지만 잘못된 실행. 점프 타이밍, 키 콤보 지속 시간 오류
📋 지시 따르기 실패
선언된 컨트롤, 출력 스키마, 태스크 제약 위반. 목표에서 이탈
🧠 장기 기억 실패
이전 맥락 상실, 비효과적 루프 반복, 다단계 계획 실패
이 네 가지는 서로 독립적이지 않습니다. 예를 들어, 지각 실패가 정밀 행동 실패로 이어지고, 이것이 장기 기억 실패(같은 실수 반복)로 연결되기도 합니다.
13. 2026년 시점의 의의: 왜 게임 AI 평가가 중요한가?
GameWorld가 단순히 "AI가 게임 못한다"는 사실을 확인하는 데 그치지 않는 이유가 있습니다.
게임은 현실 세계의 축소판
비디오 게임에서 요구되는 능력은 현실 세계 AI 에이전트에게도 필수적입니다:
| 게임 능력 | 현실 세계 응용 |
|---|
| 시각 인식 + 즉각 반응 | 자율주행, 로봇 조작 |
| 장기적 계획 수립 | 프로젝트 관리, 연구 에이전트 |
| 불확실성 하의 의사결정 | 금융 거래, 재난 대응 |
| 다중 목표 동시 추구 | 복합 업무 자동화 |
| 실패 후 전략 수정 | 디버깅, 문제 해결 |
AI가 Flappy Bird에서 타이밍을 못 맞추는 문제와, 자율주행차가 끼어드는 차량에 즉시 반응하지 못하는 문제는 같은 능력의 부재에서 비롯됩니다.
"범용 에이전트"로 가는 길의 이정표
2026년은 AI 에이전트의 전환기입니다. Computer-Use 에이전트(Claude, GPT, Gemini의 컴퓨터 사용 기능)가 상용화되면서, "AI가 사람처럼 컴퓨터를 조작할 수 있다"는 기대가 높아졌습니다.
GameWorld는 이 기대에 차가운 물을 끼얹습니다:
"네, AI가 컴퓨터를 조작할 수 있습니다. 하지만 아직 서툽니다. 특히 빠른 반응, 정밀한 타이밍, 장기적 계획이 필요한 상황에서요."
이는 비관적 메시지가 아니라, 정확한 현실 진단입니다. 어떤 능력이 부족한지 알아야 개선할 수 있으니까요.
14. 핵심 요약
🎮
34개 게임, 170개 태스크, 18개 모델
GameWorld는 가장 포괄적인 멀티모달 게임 에이전트 벤치마크입니다. 브라우저 기반 샌드박스로 공정한 비교를 보장하고, 게임 내부 상태를 직접 읽는 결정론적 평가를 수행합니다.
📊
최고 AI 41.9% vs 초보 인간 64.1%
현재 최고 성능의 모델도 게임 초보자에게 크게 뒤처집니다. 부분적 진행은 가능하지만, 목표를 완수하는 경우(SR 21.2%)는 매우 드뭅니다.
🧩
전략 추론은 강하고, 타이밍/장기 계획은 약하다
AI 에이전트의 게임 능력 프로파일은 기반 모델의 강점을 그대로 반영합니다. 언어적 추론(Wordle, 2048)은 잘하지만, 물리적 타이밍(Flappy Bird)과 오픈월드 조정(Minecraft)에서 무너집니다.
15. 마치며: 게임은 AI의 거울이다
시드 마이어의 말처럼, 게임은 "일련의 흥미로운 선택"입니다. GameWorld가 보여주는 것은, 현재의 AI가 이 선택들을 만들어내는 데 아직 서투르다는 것입니다.
하지만 비관할 필요는 없습니다. 불과 3년 전만 해도 AI가 게임 화면을 보고 직접 플레이한다는 개념 자체가 주류 연구가 아니었습니다. GameWorld 같은 체계적인 벤치마크가 등장했다는 것은, 이 분야가 "재미있는 실험"에서 "측정 가능한 과학"으로 발전하고 있다는 뜻입니다.
다음 세대의 AI 모델이 이 벤치마크에서 초보 게이머를 넘어서는 날이 올까요? 그때가 바로 "범용 AI 에이전트"가 현실이 되는 순간일지도 모릅니다.
논문: Ouyang, M., Hu, S., Lin, K.Q., Ng, H.T., & Shou, M.Z. (2026). GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents. arXiv:2604.07429
프로젝트 페이지: gameworld-bench.github.io
아래 퀴즈로 이 논문에 대한 이해도를 테스트해 보세요!