블로그로 돌아가기
COCONUT잠재 추론Chain-of-ThoughtLLMMeta AI연속 잠재 공간추론 최적화
COCONUT: AI가 말하지 않고 생각하는 법을 배우다
Meta AI의 COCONUT 논문을 깊이 파헤칩니다. LLM이 토큰 대신 연속 잠재 공간에서 추론하면 어떤 일이 벌어질까요? 언어라는 병목을 넘어선 새로운 사고 패러다임의 등장입니다.
코어닷투데이2025-12-0332분
Meta AI의 COCONUT 논문을 깊이 파헤칩니다. LLM이 토큰 대신 연속 잠재 공간에서 추론하면 어떤 일이 벌어질까요? 언어라는 병목을 넘어선 새로운 사고 패러다임의 등장입니다.
2022년 카타르 월드컵 결승전. 리오넬 메시가 프랑스 수비 3명 사이에서 킬패스를 꽂는 데 걸린 시간은 0.5초였다. 이 짧은 순간에 메시의 뇌는 수비수들의 위치, 동료의 움직임, 공의 회전, 골키퍼의 무게중심을 모두 계산했다.
그런데 여기서 질문 — 메시가 이 모든 걸 말로 생각했을까?
"음, 음바페가 왼쪽에서 압박하고 있고, 바리셀라가 중앙에 있으니까, 디 마리아 쪽으로 스루패스를 넣되, 회전을 좀 먹여서…"
당연히 아니다. 0.5초 안에 이 문장을 떠올리는 건 불가능하다. 메시의 뇌는 언어를 거치지 않고 직접 추론했다. 패턴 인식, 공간 계산, 확률 평가가 언어화되기 전에 이미 근육으로 전달된 것이다.

이제 AI 이야기로 넘어가자. 현재의 LLM(대규모 언어 모델)은 메시가 아니라 칠판 앞의 교수님에 가깝다. 모든 생각을 한 글자 한 글자 "말로" 써내려가야만 추론할 수 있다. 이것이 바로 Chain-of-Thought(CoT)이라는 기법인데 — 놀랍도록 효과적이지만, 근본적인 한계가 있다.
2024년 12월, Meta AI 연구팀이 이 한계를 정면으로 돌파하는 논문을 발표했다.
"Training Large Language Models to Reason in a Continuous Latent Space" — Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, Yuandong Tian (COLM 2025 채택)
이름하여 COCONUT — Chain of CONtinuous Thought. AI가 토큰(단어)을 생성하지 않고, 연속적인 잠재 공간에서 직접 추론하는 방법이다. 메시처럼.
2022년, 구글 연구팀의 Jason Wei 등이 발표한 "Chain-of-Thought Prompting"은 AI 추론의 판도를 바꿨다. 핵심은 단순했다:
"답을 바로 말하지 말고, 중간 과정을 하나씩 적어보렴."
질문: 자동차가 시속 60km로 2시간 달리면 얼마나 갈까?
❌ 직접 답변: 120km
✅ CoT: 속도 = 60km/h, 시간 = 2h, 거리 = 속도 × 시간 = 60 × 2 = 120km
이 간단한 트릭이 가져온 변화는 극적이었다. 수학 문제, 논리 추론, 코딩 문제에서 정확도가 수십 퍼센트포인트씩 올랐다. GPT-4, Claude, Gemini — 2026년 현재 모든 주요 LLM이 CoT를 핵심 추론 전략으로 사용한다.
OpenAI의 o1, o3 모델은 아예 "생각 토큰"을 수백~수천 개 생성한 뒤 최종 답변을 내놓는 방식으로, CoT를 극한까지 밀어붙였다.
CoT의 성공에 취해 있을 때, 연구자들은 불편한 질문을 던지기 시작했다.
문제 1: 대부분의 토큰은 추론과 무관하다
CoT 추론 과정을 자세히 보면, 실제로 "추론"에 기여하는 토큰은 소수다:
"Alex는 빨간색이다. 빨간색은 둥글다. Alex는 둥근가?"
CoT 출력: True: Alex는 빨간색이다 → 빨간색은 둥글다 → 따라서 Alex는 둥글다
회색 = 구문/연결사 (추론 무관) · 노란색 = 실제 추론 · 초록색 = 답변
10개 토큰 중 추론에 핵심적인 토큰은 3개뿐. 나머지 7개는 문장을 자연스럽게 만들기 위한 "접착제"다.
문제 2: 한 번 선택하면 되돌릴 수 없다
CoT는 본질적으로 깊이 우선 탐색(DFS)이다. 첫 번째 추론 단계에서 하나의 경로를 선택하면, 그 이후로는 그 경로를 따라갈 수밖에 없다. 잘못된 길을 택했다면? 돌아갈 수 없다.
CoT: Alex → 빨간색이다 → 빨간색은 차갑다 (잘못된 규칙!) → ???
↑ 이미 여기서 잘못됨, 하지만 되돌릴 수 없음
문제 3: 속도와 비용
CoT는 토큰을 많이 생성할수록 추론이 정확해지지만, 그만큼 시간과 비용이 든다. o1 모델이 하나의 답을 내놓기 위해 수천 개의 "생각 토큰"을 생성하는 것은, 말하자면 메시에게 모든 판단을 칠판에 써가며 하라고 요구하는 것과 같다.
인지과학의 오랜 논쟁 중 하나가 있다. "사고는 언어로 이루어지는가?" 현대 신경과학의 답은 명확하다: 아니오.
MIT의 Evelina Fedorenko 교수팀은 2024년 Nature에 발표한 연구에서, 인간의 언어 네트워크는 추론이 아니라 의사소통에 최적화되어 있음을 보여줬다. 수학 문제를 풀 때, 체스를 둘 때, 공간을 탐색할 때 — 뇌의 언어 영역은 거의 활성화되지 않는다.
"Language is optimized for communication, not for thinking." — Fedorenko et al., Nature (2024)
Transformer 모델 내부에서는 각 토큰이 고차원 벡터(예: 4096차원)로 표현된다. 이 벡터에는 의미, 문맥, 관계에 대한 풍부한 정보가 담겨 있다.
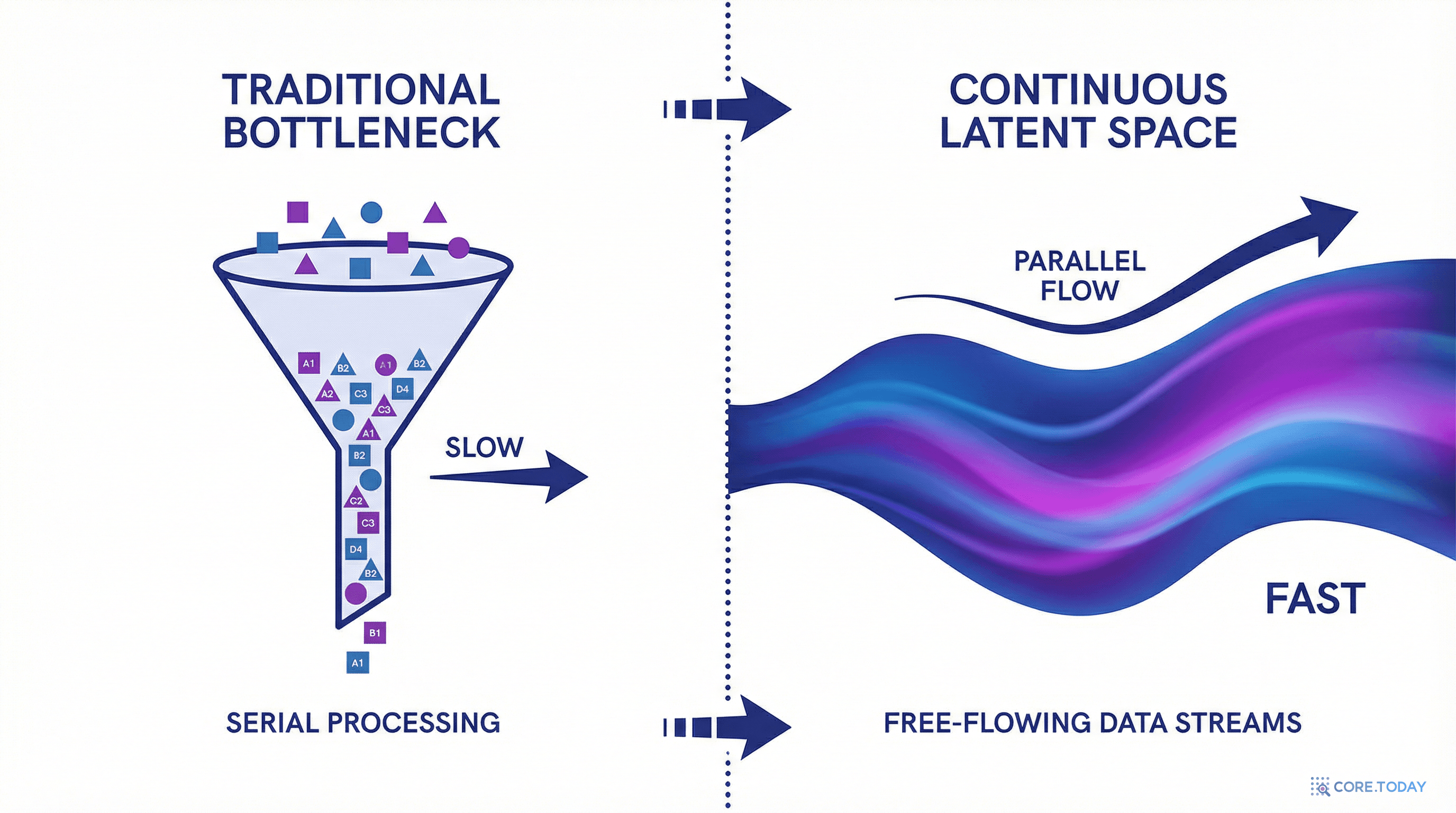
그런데 CoT는 이 풍부한 벡터를 어휘 공간의 이산적 토큰 하나로 압축하라고 강제한다. 수만 개 단어 중 하나를 골라야 한다. 이것은 마치 고해상도 사진을 1비트 흑백으로 변환하는 것과 같다.
이 과정에서 정보 병목(information bottleneck)이 발생한다. 히든 스테이트가 품고 있던 미묘한 확률 분포, 여러 가능성에 대한 동시적 고려, 불확실성 정보가 모두 사라진다.
CoT의 또 다른 문제는 모든 토큰에 동일한 연산량을 할당한다는 점이다.
"따라서" → 연산: Transformer 전체 레이어 통과 (불필요)
"둥글다" → 연산: Transformer 전체 레이어 통과 (핵심 추론)
접속사 "따라서"를 생성하는 데도, 핵심 결론 "둥글다"를 도출하는 데도 동일한 양의 계산이 필요하다. 이것은 엄청난 낭비다.
COCONUT의 아이디어는 놀랍도록 단순하다:
히든 스테이트를 토큰으로 변환하지 말고, 그대로 다음 입력으로 넣자.
일반적인 LLM 추론에서는 이런 일이 벌어진다:
COCONUT은 이 흐름을 바꾼다:
이 "연속적 사고(continuous thought)"는 토큰이 아니다. 어떤 단어에도 대응하지 않는 연속적인 벡터다. 인간으로 치면, 아직 말로 만들어지지 않은 "직감"이나 "감" 같은 것이다.
COCONUT 모델은 두 가지 모드를 오간다:
1. 언어 모드(Language Mode): 평소 LLM처럼 토큰을 입력받고 토큰을 출력한다. 질문을 읽거나 최종 답변을 생성할 때 사용.
2. 잠재 모드(Latent Mode): 토큰 생성 없이 히든 스테이트를 그대로 다음 입력으로 재활용한다. <bot> 토큰이 잠재 모드 시작을, <eot> 토큰이 종료를 알린다.
입력 (언어 모드): "Alex는 빨간색이다. 빨간색은 둥글다. Alex는 둥근가?"
<bot> → 잠재 모드 진입
⟨thought₁⟩ → 히든 스테이트가 다음 입력으로 직접 전달
⟨thought₂⟩ → 여러 경로를 동시에 탐색
⟨thought₃⟩ → 확신도 수렴
<eot> → 언어 모드 복귀
출력: "둥글다"
중요한 점: 잠재 모드에서는 단 하나의 토큰도 생성하지 않는다. 모든 "사고"가 벡터 공간 안에서 완결된다.
아래 인터랙티브 컴포넌트에서 CoT와 COCONUT의 차이를 직접 비교하고, BFS 탐색 패턴을 단계별로 확인할 수 있습니다:
COCONUT의 훈련은 직관적으로 이해하기 어렵다. 평생 말로 생각해온 AI에게 갑자기 "말하지 말고 생각해"라고 하면 어떻게 될까?
답은 망한다. 논문의 ablation 실험이 이를 확인한다. 커리큘럼 없이 바로 잠재 추론을 훈련하면 성능이 14.4%까지 추락한다.

연구팀은 점진적 내면화(gradual internalization) 전략을 사용했다:
각 단계에서:
이 과정은 마치 자전거 보조 바퀴를 하나씩 떼는 것과 같다. 처음에는 언어의 보조를 받다가, 점점 혼자 잠재 공간에서 "달리는" 법을 배운다.
| 학습 방법 | GSM8k 정확도 | ProsQA 정확도 |
|---|---|---|
| 커리큘럼 없이 직접 학습 | 14.4% | — |
| 커리큘럼 적용 (COCONUT) | 34.1% | 97.0% |
직접 학습이 실패하는 이유는 명확하다. 잠재 추론은 관찰 불가능한 과정이다. 모델은 입력과 출력만 보고 중간의 잠재 표현이 어떻게 흘러야 하는지를 추측해야 한다. CoT 데이터가 제공하는 "이 문제는 이런 단계로 풀어야 해"라는 가이드 없이는, 모델이 올바른 잠재 표현을 학습할 실마리가 없다.
연구팀은 세 가지 벤치마크에서 COCONUT을 평가했다:
ProntoQA에서 COCONUT은 CoT보다 1% 더 정확하면서 토큰을 10분의 1만 사용했다.
하지만 진짜 인상적인 건 ProsQA다. ProsQA는 그래프 구조에서 경로를 찾는 복잡한 계획 문제로, 백트래킹(되돌아가기)이 필수적인 태스크다:
여기서 주목할 점: CoT는 No-CoT와 거의 차이가 없다(77.5% vs 76.7%). 백트래킹이 필요한 문제에서 언어 기반 CoT는 사실상 무력하다. 한 번 잘못된 길로 들어서면 되돌아올 수 없기 때문이다.
반면 COCONUT은 97.0%를 달성했다. 토큰도 3분의 1만 사용하면서.
| 방법 | 정확도 | 토큰 수 |
|---|---|---|
| No-CoT | 16.5% | — |
| CoT | 42.9% | 25.0 |
| COCONUT (c=2) | 34.1% | 8.2 |
수학 추론에서는 CoT가 여전히 우세했다. 이는 예상된 결과인데, 수학은 본질적으로 순차적이고 언어적인 추론이 강점인 영역이기 때문이다. 2+3=5를 계산하는 과정은 잠재 공간에서 병렬로 탐색할 성격이 아니다.
이 결과는 COCONUT의 강점과 한계를 명확히 보여준다:
| 방법 | ProntoQA (초/문제) | ProsQA (초/문제) |
|---|---|---|
| CoT | 0.85 | 0.26 |
| COCONUT | 0.12 | 0.09 |
| 속도 향상 | 7.1× | 2.9× |
토큰을 적게 생성하니 당연히 빠르다. 그것도 3~7배 빠르다.
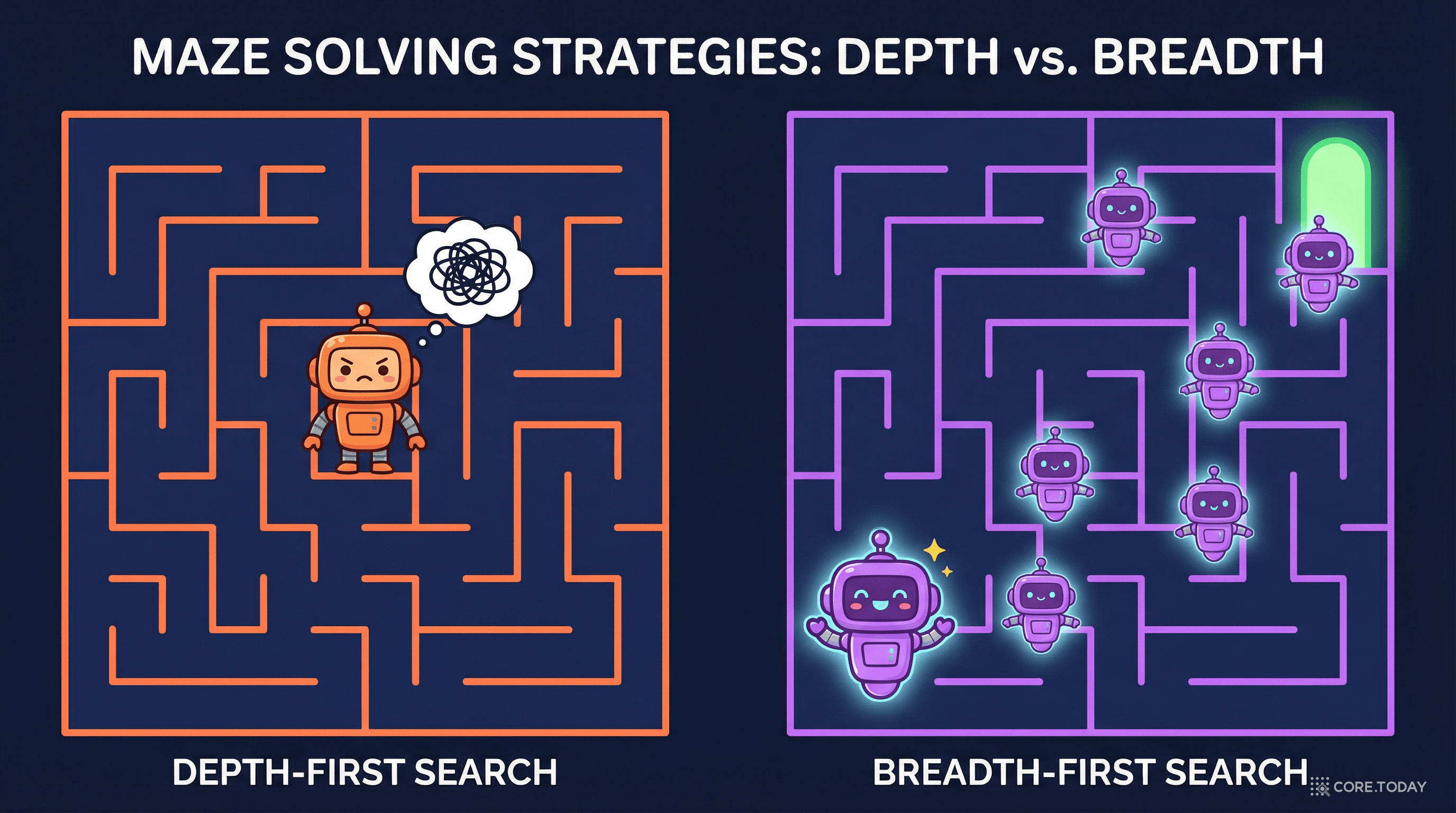
COCONUT의 실험 결과 중 가장 흥미로운 발견은 학습 목표에 없던 행동이 자발적으로 출현했다는 것이다.
기존 CoT는 깊이 우선 탐색(DFS)이다:
한 경로를 끝까지 탐색한 뒤에야 잘못됨을 깨닫는다. 그리고 되돌아갈 수 없다.
COCONUT은 다르다. 연구팀이 잠재 표현을 분석한 결과, 모델이 여러 가능한 다음 단계를 동시에 유지하고 있었다:
Thought 1에서의 확률 분포:
Thought 2에서의 확률 분포:
→ 여러 후보를 병렬로 유지하다가 점진적으로 수렴!
이것이 바로 너비 우선 탐색(BFS)이다. 한 경로에 올인하지 않고, 여러 가능성을 열어둔 채 가장 유망한 경로로 수렴해 간다.
비밀은 연속 벡터의 표현력에 있다. 이산적인 토큰은 "빨간색" 또는 "파란색" 중 하나만 선택할 수 있다. 하지만 연속 벡터는 "45% 빨간색 + 30% 파란색 + 25% 크다"를 하나의 벡터로 동시에 인코딩할 수 있다.
이것은 양자역학의 중첩(superposition) 개념과 유사하다. 관측(토큰 생성)하기 전까지 여러 상태가 공존하는 것이다.
연구팀은 이 패턴이 명시적으로 훈련되지 않았음에도 자발적으로 출현했다고 보고했다. 모델은 단순히 "정답을 맞춰라"는 목표만 받았는데, 스스로 BFS 전략을 발견한 것이다.
"This reasoning pattern surpasses traditional CoT, even though the model is not explicitly trained or instructed to operate in this manner."
COCONUT은 혁신적이지만, 완벽하지 않다. 논문이 솔직하게 인정하는 한계들:
COCONUT은 처음부터 잠재 추론을 발견하지 못한다. 반드시 언어 CoT 데이터로 먼저 학습한 뒤, 그것을 잠재 공간으로 이전해야 한다. 즉, CoT를 대체하는 것이 아니라 CoT 위에 세워진 것이다.
GSM8k에서 CoT 대비 ~9%p 낮은 정확도를 보였다. 모든 유형의 추론에 만능은 아니다.
Llama 3.2-3B, 3-8B 같은 큰 모델에서는 개선 폭이 줄어든다. 연구팀의 분석:
"더 큰 모델은 이미 광범위한 언어 중심 사전학습을 거쳐, 잠재 추론으로의 전환이 더 어렵다."
이미 "말로 생각하는" 습관이 깊이 박힌 모델일수록, "말 없이 생각하는" 법을 배우기가 더 어렵다는 뜻이다.
잠재 사고는 사람이 읽을 수 없다. CoT의 큰 장점 중 하나가 추론 과정의 투명성인데, COCONUT은 이를 포기한다. AI 안전성 관점에서 이는 심각한 우려 사항이다.
COCONUT이 2024년 12월에 발표된 이후, 잠재 추론(latent reasoning) 분야는 폭발적으로 성장했다.
2025년 5월, 대규모 서베이 논문 "Reasoning Beyond Language"가 발표되며 잠재 CoT 연구의 전체 지형도를 정리했다. 이 서베이에 따르면, COCONUT 이후 등장한 주요 접근법은 세 갈래로 나뉜다:
2025년 하반기부터는 강화학습(RL)으로 잠재 추론을 훈련하는 연구가 급부상했다. CoLaR, FR-Ponder 같은 방법들은 COCONUT의 커리큘럼 의존성을 벗어나, 모델이 스스로 잠재 추론 전략을 발견하도록 유도한다.
2026년 현재, AI 추론의 핵심 화두는 효율성이다.
o1, o3 같은 "더 많이 생각하는" 모델은 정확도를 높였지만, 비용도 함께 치솟았다. COCONUT이 제시하는 방향 — 더 적은 토큰으로, 더 정확한 추론 — 은 이 비용 문제의 근본적 해결책이 될 수 있다.
특히 Edge AI와 에이전트 AI 환경에서 잠재 추론의 가치는 더욱 빛난다:
일반 CoT에서의 "사고"는 토큰이다. 단어, 숫자, 기호.
COCONUT에서의 "사고"는 벡터다. 수천 차원의 실수값으로 이루어진, 인간이 읽을 수 없는 표현.
| Chain-of-Thought | COCONUT | |
|---|---|---|
| 사고의 단위 | 토큰 (이산적) | 벡터 (연속적) |
| 사고의 표현력 | 단일 선택 | 확률 분포 인코딩 |
| 탐색 전략 | DFS (깊이 우선) | BFS (너비 우선) |
| 정보 병목 | 있음 (토큰화) | 없음 (직접 전달) |
| 해석 가능성 | 높음 | 낮음 |
| 토큰 효율성 | 낮음 | 높음 |
Continuous Co-chain of thought에서 따온 이름이다. 하지만 이 이름에는 더 깊은 의미가 있다고 생각한다 — 코코넛처럼 겉은 딱딱한 껍질(언어)로 보호되고, 속은 부드러운 과육(잠재 표현)으로 채워진 구조. 외부와 소통할 때만 껍질(언어 모드)을 사용하고, 내부의 추론은 부드러운 연속 공간에서 이루어진다.
비슷한 시도로 Pause Token 방법이 있다. 빈 토큰 <pause>를 삽입해 모델에게 "더 생각할 시간"을 주는 것이다.
COCONUT과의 핵심 차이: Pause Token은 여전히 이산적 토큰 공간에서 동작한다. 반면 COCONUT은 토큰 공간을 완전히 벗어나 연속 벡터 공간에서 추론한다.
실험에서도 차이가 드러난다. ProsQA에서 Pause Token은 96.6%, COCONUT은 97.0%를 달성했다. 작은 차이지만, 복잡한 계획 문제일수록 연속 표현의 이점이 커진다.
COCONUT은 "AI가 반드시 언어로 추론해야 하는가?"라는 근본적 질문에 "아니오"라고 답한 최초의 실증적 연구 중 하나다.
물론 한계는 있다. 수학 추론에서의 열세, 해석 불가능성, 큰 모델에서의 어려움. 하지만 이 논문이 열어젖힌 방향 — 언어를 넘어선 추론 — 은 2026년 AI 연구의 가장 뜨거운 분야가 되었다.
어쩌면 미래의 AI는 우리에게 이렇게 말할지도 모른다:
"결과는 알려드리겠습니다. 하지만 어떻게 생각했는지는 — 말로는 설명이 안 돼요."
메시가 그 킬패스를 어떻게 생각해냈는지 말로 설명할 수 없는 것처럼.
RELATED



