FlowPlan-G2P특허 자동 생성LLM논문-특허 변환Concept GraphNLPAI 법률자동화
논문을 특허로 바꾸는 AI — FlowPlan-G2P 논문 완전 해부
매년 350만 건의 특허가 출원되지만, 한 건당 수천만 원의 변리사 비용이 든다. FlowPlan-G2P는 논문을 특허 명세서로 변환하는 3단계 구조적 프레임워크로, Llama-4급 오픈 모델이 Claude-4.5를 2배 이상 압도하는 성과를 냈다. 핵심 아이디어부터 '메트릭 패러독스'까지, 이 논문이 왜 중요한지 완전히 해부한다.
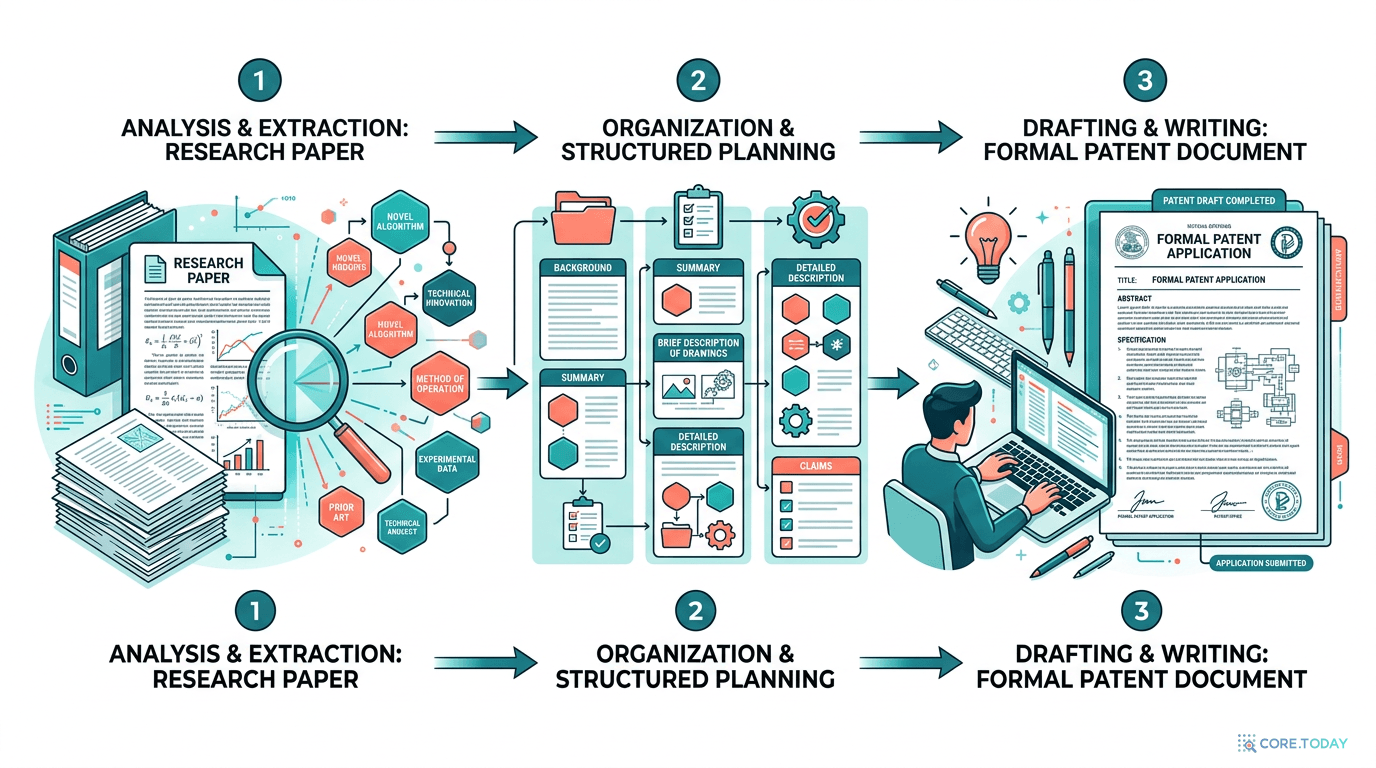
숙련된 변리사가 특허를 작성할 때의 사고 과정을 관찰해 보면, 바로 글을 쓰지 않는다. 먼저 논문을 읽고, 머릿속에 "발명의 구조"를 그린다. 어떤 문제가 있고, 어떤 해결책이 있으며, 각 구성 요소가 어떻게 연결되는지 — 이런 개념적 지도를 먼저 만든 다음에 글을 쓴다.
FlowPlan-G2P는 이 인지적 과정을 3단계로 명시적으로 모델링한다:
Stage 1 개념 그래프 유도 논문 → 구조화된 개념 맵
Stage 2 단락/섹션 계획 개념 맵 → 특허 구조 설계
Stage 3 그래프 조건부 생성 구조 설계 → 특허 명세서
각 단계를 자세히 살펴보자.
Stage 1: 구조화된 추론 기반 개념 그래프 유도
첫 번째 단계는 논문을 읽고 "발명의 뼈대"를 추출하는 것이다.
9가지 정규 드래프팅 카테고리
논문의 내용을 다음 9가지 카테고리로 분해한다:
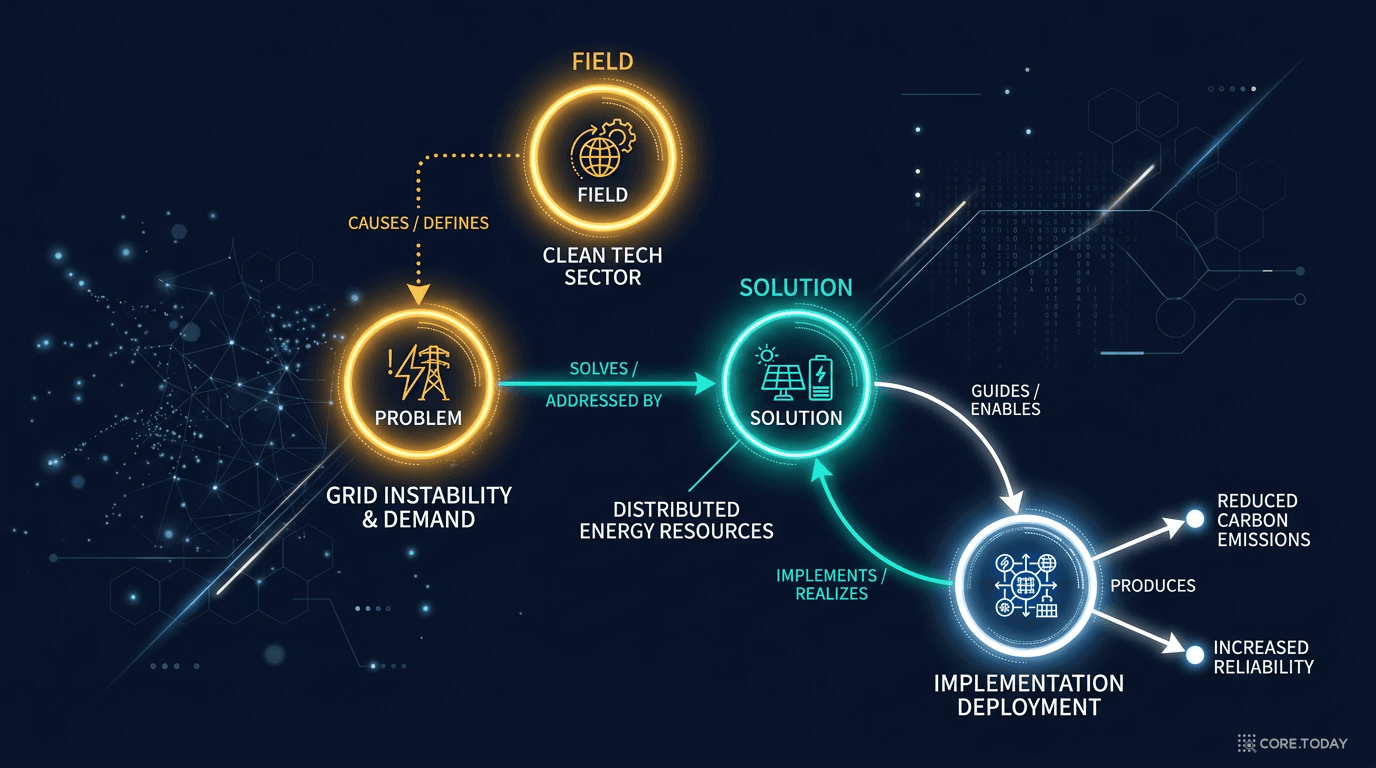
Field 기술 분야
TechProblem 기술적 문제
PriorArt 선행 기술
Novelty 신규성
Solution 해결책
Implementation 구현
Effects 효과
Embodiment 실시예
Figure 도면
LLM이 논문을 읽으며 각 카테고리에 대한 구조화된 텍스트를 순차적으로 생성한다. 여기서 중요한 건 이전 단계의 출력을 다음 단계의 입력에 포함시킨다는 점이다. "기술 분야"를 먼저 정의하고, 그 위에 "기술적 문제"를 정의하고, 그 위에 "해결책"을 정의하는 식이다. 이렇게 하면 인과적 연속성이 자연스럽게 유지된다.
3중 후보 그래프 생성
다음으로, 추출한 개념들을 방향 그래프(Directed Concept Graph)로 변환한다.
노드: 특허의 개별 구성 요소 (특정 알고리즘, 기능 모듈 등)
엣지: 구성 요소 간 관계 — solves, implements, causes, improves, validates
여기서 독특한 점은 3개의 후보 그래프를 동시에 생성한다는 것이다:
G1
규칙 기반 그래프
미리 정의된 엣지 템플릿 사용 (예: TechProblem → solves → Solution)
G2
LLM 기반 그래프 #1
LLM이 암묵적 의존 관계를 추론하여 그래프 생성
G3
LLM 기반 그래프 #2
다른 시드로 LLM이 추론 — 다양성 확보
이 3개의 그래프를 다수결 투표(majority voting)와 합집합(union semantics)으로 병합하여 최종 그래프 G*를 만든다. 갈등하는 엣지 타입은 다수결로 해결하고, 고립된 노드는 제거하며, 필수 노드(Field, TechProblem, Solution)가 빠져있으면 플레이스홀더를 자동 주입한다.
왜 3개나? 하나의 방법으로는 모든 관계를 포착하기 어렵기 때문이다. 규칙 기반은 명시적 관계를 놓치지 않지만 암묵적 관계를 놓치고, LLM 기반은 그 반대다. 세 가지를 합치면 구조적 리콜(structural recall)이 극대화된다.
이 논문의 가장 충격적인 발견은 성능 자체가 아니다. 기존 평가 지표가 완전히 틀렸다는 것이다.
ROUGE가 높으면 특허 품질도 좋을까?
모델
ROUGE-L
BERTScore
전문가 법적 평가
Zero-Shot
0.178
0.870
1.5 / 5
Few-Shot
0.138
0.834
2.1 / 5
FlowPlan-G2P
0.169
0.830
4.7 / 5
놀랍게도 Zero-Shot이 가장 높은 ROUGE-L(0.178)과 BERTScore(0.870)를 기록했다. 하지만 전문가 평가에서는 1.5점 — 법적으로 무효 수준이었다.
반면 FlowPlan-G2P는 ROUGE-L과 BERTScore가 오히려 낮지만, 전문가 평가에서 4.7점 — 거의 완벽한 결과를 받았다.
왜 이런 역전이 일어나는가?
!
ROUGE/BERTScore의 한계
이 지표들은 표면적 어휘 유사도를 측정한다. 원본 특허와 비슷한 단어를 많이 쓸수록 점수가 높다. 하지만 특허의 품질은 단어 유사도가 아니라 법적 논리 구조에 있다.
→
Zero-Shot이 높은 이유
Zero-Shot은 논문의 표현을 거의 그대로 재활용한다. 원문과 어휘 겹침이 크니 ROUGE가 높지만, 특허로서의 법적 구조는 갖추지 못한다.
★
FlowPlan-G2P가 낮은 이유
FlowPlan-G2P는 논문의 표현을 특허 전문 용어로 완전히 재구성한다. 어휘 겹침은 줄지만, 법적 유효성은 극적으로 높아진다.
저자들은 이를 "메트릭 패러독스(Metric Paradox)"라고 명명했다. 특허 도메인에서 기존 NLG 지표를 신뢰하면 법적으로 무효한 텍스트에 가장 높은 점수를 주게 된다.
이를 해결하기 위해 논문은 Pat-DEVAL이라는 특허 전문 평가 프레임워크를 사용했다. Chain-of-Legal-Thought(CoLT) 메커니즘으로 통상의 기술자(PHOSITA)의 사고를 시뮬레이션하며, 인간 전문가와의 상관계수(Kendall's tau)가 0.67~0.76으로 높은 일치도를 보였다.
제6장: 방법론이 모델 크기를 이긴다
이 논문에서 두 번째로 중요한 발견:
FlowPlan-G2P를 장착한 Llama-4-scout가 아무것도 없는 Claude-4.5를 2배 가까이 이긴다.
LLM 백본
Vanilla (Few-Shot)
+ FlowPlan-G2P
향상률
Llama-4-scout
2.0
4.3
+115%
DeepSeek-v3.1
2.2
4.6
+109%
Claude-4.5
2.3
4.8
+109%
Pat-DEVAL 종합 점수 (5점 만점) 시각화:
Llama-4 Vanilla2.0
DeepSeek Vanilla2.2
Claude-4.5 Vanilla2.3
Llama-4 + G2P4.3
DeepSeek + G2P4.6
Claude-4.5 + G2P4.8SOTA
이 결과가 의미하는 바는 크다:
방법론 > 모델 크기: 구조화된 프레임워크가 원시 모델 능력보다 중요하다
오픈소스의 가능성: Llama-4-scout 같은 오픈 모델에 FlowPlan-G2P를 적용하면 상용 모델 수준의 특허 생성이 가능하다
양의 스케일링: 더 강한 모델일수록 계획을 더 잘 활용한다 (Claude-4.5가 가장 높은 점수)
이는 단순히 특허 분야에만 해당하는 통찰이 아니다. 복잡한 전문 문서 생성에서 "구조적 중간 표현"의 힘을 보여주는 사례다.
제7장: 사례로 이해하는 FlowPlan-G2P
실제로 어떻게 작동하는지, 가상의 예시로 살펴보자.
입력: 어텐션 메커니즘 논문
가상의 논문 "EfficientAttention: A Lightweight Self-Attention for Mobile Vision"이 있다고 하자.
논문 핵심 내용
- 기존 Self-Attention은 O(n²) 복잡도로 모바일 기기에 부적합
- 입력 시퀀스를 청크로 분할하여 지역 어텐션 계산 후 병합
- ImageNet Top-1 정확도 78.3%, FLOPs 2.1G (MobileNetV3 대비 1.5% 높고 FLOPs 동일)
- 청크 크기 하이퍼파라미터에 따른 정확도-속도 트레이드오프 분석
Stage 1에서 추출된 개념 그래프 (간소화)
모바일 비전 [Field]
→
O(n²) 복잡도 [TechProblem]
→ solves
청크 분할 어텐션 [Solution]
청크 분할 어텐션 [Solution]
→ implements
지역 어텐션 모듈 [Implementation]
→ causes
78.3% 정확도 [Effects]
Stage 3에서 생성된 특허 명세서 (일부)
생성된 특허 명세서 — 기술 분야
본 발명은 모바일 디바이스 환경에서의 이미지 인식 장치 및 방법에 관한 것으로, 보다 상세하게는 제한된 연산 자원 하에서 효율적인 셀프 어텐션 연산을 수행하는 경량 어텐션 모듈에 관한 것이다.
생성된 특허 명세서 — 배경 기술
종래의 셀프 어텐션 메커니즘은 입력 시퀀스의 길이 n에 대해 O(n²)의 연산 복잡도를 갖는다. 이는 서버 환경에서는 허용 가능하나, 모바일 디바이스와 같이 연산 자원이 제한된 환경에서는 실시간 처리가 불가능하다는 문제가 있었다. 따라서, 어텐션의 표현력을 유지하면서도 연산 복잡도를 줄이는 기술이 요구되고 있다.
논문의 "우리가 이겼다" 식 서술이 "~의 문제가 있었다" → "따라서 ~가 요구된다"라는 특허 특유의 인과적 서술로 완전히 재구성된 것을 볼 수 있다.
제8장: 2026년, 이 기술은 왜 중요한가
1. 특허 민주화
특허 출원의 가장 큰 장벽은 비용이다. 한 건당 수백만 원의 변리사 비용은 대학 연구실, 1인 창업가, 개발도상국 발명가에게 사실상 접근 불가능한 벽이다. FlowPlan-G2P 같은 기술이 상용화되면, 초안 생성 비용이 90% 이상 절감될 수 있다. 물론 최종 검토는 변리사가 해야 하지만, "백지에서 시작"하는 것과 "80% 완성된 초안을 다듬는 것"은 천지 차이다.
2. 과학-산업 간 기술 이전 가속
매년 수백만 편의 학술 논문이 발표되지만, 특허로 이어지는 비율은 극히 낮다. 이유 중 하나가 "논문은 쓸 줄 알지만 특허는 어떻게 써야 할지 모르겠다"는 것이다. 논문→특허 변환이 자동화되면, 실험실의 연구 성과가 산업적 보호를 받는 속도가 빨라진다.
3. "구조적 중간 표현" 패러다임의 확산
FlowPlan-G2P의 진짜 기여는 특허 분야에만 있지 않다. "복잡한 문서는 바로 쓰지 말고, 먼저 구조를 설계하라"는 원칙은 다음에도 적용 가능하다:
법률 문서 계약서, 소장
규제 보고서 FDA 제출 문서
기술 사양서 RFC, API 문서
의료 기록 임상 시험 보고서
금융 문서 투자설명서, 감사보고서
교육 자료 교과서, 커리큘럼
어떤 분야든 엄격한 구조와 전문 용어, 법적/규제적 요건이 있는 문서 생성에서 "개념 그래프 → 계획 → 생성" 패러다임은 게임 체인저가 될 수 있다.
4. 평가 방법론의 전환
메트릭 패러독스의 발견은 NLP 커뮤니티 전체에 중요한 경고다. 도메인 전문 지식이 필요한 텍스트를 ROUGE/BERTScore로 평가하면 완전히 잘못된 결론에 도달할 수 있다. 법률, 의료, 금융 등 전문 도메인의 텍스트 생성 연구에서 도메인 특화 평가 프레임워크(Pat-DEVAL 같은)의 필요성이 부각된다.
제9장: 한계와 미래 방향
저자들이 인정한 한계
1
청구항과의 법적 일관성
현재 FlowPlan-G2P는 "상세 설명" 생성에 초점을 맞추고 있다. 실제 특허에서는 상세 설명이 청구항(Claims)을 명시적으로 뒷받침해야 하는데, 이 둘 간의 실시간 정합성 검증 메커니즘이 아직 없다. 향후 청구항과 명세서를 동시에 생성하는 연구가 필요하다.
2
변화하는 법적 판례 대응
특허법 해석은 새로운 판례와 법률 개정에 따라 변한다. FlowPlan-G2P는 학습 시점의 법적 지식에 의존하므로, 실시간 법률 데이터베이스 연동(RAG 방식)이 필요하다.
추가적 고려 사항
146쌍이라는 데이터셋 규모는 통계적으로 충분하지 않을 수 있다
영어 특허에 집중했으므로, 한국어/일본어/중국어 특허로의 확장 검증이 필요하다
이 프레임워크는 보조 도구이지 변리사를 대체하는 것이 아니다 — Human-in-the-Loop가 반드시 필요하다
맺으며: AI가 발명을 보호하는 시대
FlowPlan-G2P 논문이 던지는 메시지는 명확하다:
LLM에게 "글 써줘"라고 하는 것과 "먼저 설계하고 그 다음에 써"라고 하는 것은 전혀 다른 결과를 낳는다.
이 원칙은 특허뿐 아니라, 복잡한 구조를 가진 모든 전문 문서에 적용된다. 그리고 이 논문이 보여준 것처럼, 올바른 방법론은 올바른 모델보다 강하다. Llama-4에 구조적 프레임워크를 얹으면 Claude-4.5를 단독으로 사용하는 것보다 2배 나은 결과를 낸다.
2026년은 AI가 단순히 "글을 쓰는 도구"에서 "전문가의 사고 과정을 모방하는 시스템"으로 진화하는 전환점이다. FlowPlan-G2P는 그 전환의 좋은 사례다 — 표면적 패턴 매칭에서 구조적 추론으로, 벤치마크 최적화에서 실세계 유효성으로.
다음에 "이 논문으로 특허 써줘"라고 ChatGPT에 부탁하고 싶어질 때, 이 논문을 떠올려 보자. "먼저 개념 그래프를 그려"라고 한마디 더하는 것만으로, 결과물의 품질이 완전히 달라질 수 있다.
참고 문헌
• Pan, K. W. & Yoo, Y. (2026). FlowPlan-G2P: A Structured Generation Framework for Transforming Scientific Papers into Patent Descriptions. arXiv:2601.02589.
• Knappich, M. et al. (2025). Pap2Pat: Paper-to-Patent Generation. EMNLP 2025.
• Bai, J. et al. (2024). PatentGPT: A Large Language Model for Intellectual Property. arXiv:2404.18011.
• Wang, S. et al. (2024). AutoPatent: A Multi-Agent Framework for Automatic Patent Generation. arXiv:2412.09796.
• 35 U.S.C. §112 — Specification Requirements.