들어가며
2023년 6월, Microsoft Research에서 한 편의 논문이 공개됐다. 제목은 "Textbooks Are All You Need". 직역하면 "교과서만 있으면 된다." AI 커뮤니티에서는 두 가지 반응이 동시에 터져 나왔다. 하나는 "역대 최악의 논문 제목"이라는 조롱이었고, 다른 하나는 논문이 보여준 숫자에 대한 경악이었다.
숫자는 이랬다. 13억(1.3B) 파라미터짜리 모델 phi-1이, 1,750억(175B) 파라미터의 GPT-3.5를 코딩 벤치마크에서 이겼다.
HumanEval 벤치마크에서 phi-1은 50.6%, GPT-3.5는 47%. 모델 크기는 100배 이상 차이가 났다. 학습에 사용한 데이터는 phi-1이 70억 토큰, GPT-3.5는 수조 토큰. 학습에 들어간 컴퓨팅도 비교가 안 됐다. phi-1은 A100 GPU 8장으로 4일이면 충분했다.
비결이 뭐였을까? 논문의 저자들은 답을 논문 제목에 이미 써놓았다. 교과서. 정확히 말하면, "교과서처럼 잘 정리된 데이터."
인터넷에서 긁어모은 수조 개의 토큰 대신, 명확하고 체계적이며 교육적 가치가 높은 데이터만 골라 학습시켰더니, 100분의 1 크기의 모델이 거인을 이긴 것이다. 이것은 단순한 벤치마크 해킹이 아니었다. 2020년부터 AI 산업을 지배해온 "크게 만들면 된다"는 상식에 정면으로 도전하는 결과였다.

이 글은 그 도전의 이야기를 추적한다. "크게 만들면 된다"가 왜 상식이 되었는지(제1장), 교과서 품질 데이터가 어떻게 그 상식을 뒤집었는지(제2장), phi-1 이후 3년간 무슨 일이 있었는지(제3장), 소형 모델이 왜 중요한지(제4장), 그리고 2026년 현재 이 논문을 어떻게 읽어야 하는지(제5장)를 다룬다.
제1장: "크게 만들면 된다"의 시대 — Scaling Laws의 지배 (2020–2022)
카플란의 법칙: 크기가 곧 성능이다
2020년 1월, OpenAI의 Jared Kaplan 등이 발표한 논문 "Scaling Laws for Neural Language Models"는 AI 산업의 방향을 결정지은 논문 중 하나다. 핵심 발견은 놀라울 정도로 단순했다.
모델을 키우면, 성능이 예측 가능하게 올라간다.
로그 스케일에서 모델 크기와 성능의 관계는 거의 직선이었다. 10배의 컴퓨팅 예산이 주어지면, 최적 전략은 모델을 약 5.5배 키우고 데이터를 약 1.8배 늘리는 것이었다. 즉, 추가 자원의 대부분을 모델 크기에 투입하는 것이 정답이라는 뜻이다.
이것은 AI 연구자들에게 매우 매력적인 메시지였다. 복잡한 아키텍처 혁신 없이도, 돈과 GPU만 있으면 성능을 예측하고 달성할 수 있다는 이야기니까. "모델을 키워라"가 산업의 기본 전략이 되었다.

GPT-3: 거대함의 시대를 열다 (2020)
Kaplan Scaling Laws가 발표된 같은 해, OpenAI는 그 법칙의 극단적 실현인 GPT-3를 공개했다. 1,750억 파라미터, 3,000억 토큰으로 학습. 당시 기준으로 역대 최대 규모의 언어 모델이었다.
GPT-3는 few-shot learning이라는 능력을 보여주며 세상을 놀라게 했다. 몇 개의 예시만 보여주면 번역, 요약, 코딩, 심지어 시 쓰기까지 할 수 있었다. 하지만 GPT-3의 학습 데이터를 들여다보면, 흥미로운 사실이 드러난다.
학습 데이터의 대부분은 인터넷 크롤링 데이터였다. Common Crawl에서 필터링한 텍스트가 전체의 60%를 차지했다. 나머지는 WebText2, Books1, Books2, Wikipedia 등이었다. 필터링을 거쳤다고는 하지만, 그 안에는 Reddit 댓글, 광고 문구, 스팸, 의미 없는 텍스트, 중복된 코드 스니펫이 대량으로 포함되어 있었다.
GPT-3는 인터넷의 쓰레기까지 통째로 삼킨 셈이었다. 하지만 모델이 워낙 거대했기 때문에, 쓰레기 속에서도 패턴을 찾아내는 힘이 있었다. 모델 크기가 데이터 품질의 부족을 보상한 것이다.

친칠라의 반격: "데이터도 키워라" (2022)
2022년, DeepMind의 Jordan Hoffmann 등이 발표한 "Chinchilla" 논문은 Kaplan Scaling Laws에 중요한 수정을 가했다. Kaplan은 "모델을 키워라"고 했지만, Chinchilla의 결론은 달랐다.
"데이터도 모델만큼 키워라."
700억(70B) 파라미터의 Chinchilla가 2,800억(280B) 파라미터의 Gopher를 이겼다. 비결은 학습 데이터를 1.4조 토큰으로 대폭 늘린 것이었다. Chinchilla 법칙이 제시한 최적 비율은 토큰 대 파라미터 약 20:1. 즉 10B 파라미터 모델이면 200B 토큰, 100B 파라미터 모델이면 2T 토큰이 필요하다는 것이다.
Scaling Laws 시대의 학습 전략 비교
GPT-3는 거대한 모델에 상대적으로 적은 데이터를, Chinchilla는 적절한 모델에 대량의 데이터를 투입하는 전략이었다. Chinchilla가 이겼다.
핵심 맹점: "모든 토큰은 동등하다"
하지만 Kaplan도, Chinchilla도 하나의 중요한 가정을 공유하고 있었다. "모든 토큰은 동등하다." 데이터의 양이 중요한 것이지, 각 토큰의 품질은 고려 대상이 아니었다. Reddit 댓글 1토큰이나 교과서 설명 1토큰이나 동등한 가치를 가진다고 본 것이다.
수능 공부에 비유하면 이렇다. Kaplan의 전략은 "두꺼운 문제집을 사라"이고, Chinchilla의 전략은 "문제집을 많이 풀어라"다. 둘 다 일리 있는 조언이다. 하지만 어느 쪽도 이런 질문을 하지 않았다.
"문제집의 질은 따지지 않아도 되는 건가?"
문제집 100권을 대충 풀기 vs 정평 있는 교재 1권을 정독하기. 우리는 직관적으로 후자가 효율적이라는 것을 안다. 하지만 2020년부터 2022년까지, AI 산업은 전자의 논리로 움직이고 있었다. 더 많은 데이터, 더 큰 모델. 데이터 품질은 Scaling Laws의 사각지대였다.
그리고 2023년 6월, 누군가 그 질문을 던졌다.
제2장: "교과서가 답이다" — phi-1의 등장 (2023)
세바스티앙 부벡의 질문
Microsoft Research의 세바스티앙 부벡(Sébastien Bubeck)은 수학자 출신의 ML 연구자다. 그는 동료 수리야 구나세카르(Suriya Gunasekar) 등과 함께 단순하지만 근본적인 질문을 던졌다.
"Instead of training on just raw web data, why don't you look for data which is of extremely high quality?"
— 인터넷 쓰레기 대신, 정말 극도로 높은 품질의 데이터로 학습하면 어떨까?

이 질문의 답이 2023년 6월 발표된 논문 "Textbooks Are All You Need"(Gunasekar et al.)다. 저자들은 "교과서 품질(textbook-quality)"이라는 개념을 정의하고, 그 기준에 맞는 데이터만으로 모델을 학습시켰다.
"교과서 품질"이란 무엇인가
논문이 정의한 교과서 품질 데이터의 네 가지 특성:
- Clear (명확함) — 모호하지 않고, 읽는 사람이 즉시 이해할 수 있다
- Self-contained (자기완결적) — 외부 맥락 없이도 그 자체로 완결된다
- Instructive (교육적) — 개념을 가르치는 목적으로 구성되어 있다
- Balanced (균형잡힌) — 주제와 난이도가 적절히 분포되어 있다
이것을 코드 데이터로 보면 차이가 극명하다.
GitHub에서 긁어온 일반 코드 데이터는 이런 식이다:
hljs language-python
def f(x, y, z):
if z:
return [i for i in x if i not in y]
return x
변수명이 x, y, z이고, 함수명이 f이며, 이 코드가 무엇을 하는지 맥락이 전혀 없다. 작동은 하지만, 이것을 읽고 프로그래밍 개념을 배울 수 있는 사람은 없다.
교과서 품질 데이터는 이렇게 다르다:
hljs language-python
def find_common_elements(list_a, list_b):
"""두 리스트에서 공통 원소를 찾아 반환합니다.
이진 탐색 대신 집합(set)을 활용하면
O(n*m)을 O(n+m)으로 줄일 수 있습니다.
"""
set_b = set(list_b)
return [item for item in list_a if item in set_b]
같은 기능이지만, 함수명이 의도를 설명하고, 독스트링이 알고리즘 선택의 이유를 설명하며, 변수명이 맥락을 제공한다. 이것을 읽는 것만으로도 배울 수 있다. 그래서 "교과서"인 것이다.
phi-1의 세 가지 데이터 소스
phi-1은 총 약 70억 토큰의 데이터로 학습되었다. 이 데이터는 세 가지 소스에서 왔다.
phi-1의 학습 데이터 구조
phi-1 학습 데이터 (~7B 토큰)
교과서 품질 기준으로 구성된 3가지 소스
필터링된 웹 코드
~6B 토큰 | The Stack + StackOverflow에서 "교육적 가치" 기준 필터링
합성 교과서
<1B 토큰 | GPT-3.5로 생성한 교과서 스타일 코드 설명
합성 연습문제
~180M 토큰 | GPT-3.5로 생성한 코딩 연습문제 (파인튜닝용)
첫 번째 소스: 필터링된 웹 코드 (~6B 토큰). The Stack과 StackOverflow에서 코드를 수집한 뒤, "교육적 가치"가 높은 코드만 남겼다. 필터링 방법이 흥미롭다. GPT-4를 사용해 약 10만 개의 코드 샘플에 "이 코드의 교육적 가치"를 주석으로 달게 한 뒤, 그 주석을 학습 데이터로 Random Forest 분류기를 훈련시켰다. 이 분류기가 수십억 줄의 코드를 빠르게 평가하고, 교과서 품질에 해당하는 코드만 걸러냈다.
두 번째 소스: 합성 교과서 (<1B 토큰). GPT-3.5에게 "Python 교과서를 써달라"고 요청해서 생성한 합성 데이터다. 단순히 "교과서를 써라"가 아니라, 주제(알고리즘, 데이터 구조, 웹 개발 등)와 대상 청중(초보자, 중급자 등)을 다양하게 제약 조건으로 주어 다양성을 확보했다.
세 번째 소스: 합성 연습문제 (~180M 토큰). 역시 GPT-3.5로 생성한 코딩 연습문제와 풀이. 이것은 사전학습이 아니라 파인튜닝 단계에서 사용되었다. 모델이 실제 코딩 과제를 수행하는 능력을 기르는 데 초점을 맞춘 데이터였다.
다윗이 골리앗을 이기다: 벤치마크 결과
결과는 충격적이었다.
1.3B 파라미터의 phi-1이 175B의 GPT-3.5를 넘어섰다. MBPP 벤치마크에서도 phi-1은 55.5%를 기록했다. 15.5B 파라미터에 1조 토큰으로 학습한 StarCoder(33.6%)와 비교하면 차이가 더 극적이다. 파라미터는 12분의 1, 학습 데이터는 140분의 1인데, 성능은 17%포인트 높았다.
WizardCoder(57.3%)가 phi-1보다 높은 점수를 기록하긴 했지만, WizardCoder는 16B 파라미터에 1T 토큰으로 학습된 모델이다. phi-1 대비 12배 크고 140배 많은 데이터를 사용하고도, 격차는 7%포인트에 불과했다.
학습 비용도 파격적이었다. phi-1은 A100 GPU 8장으로 4일이면 학습이 끝났다. GPT-3의 학습에 들어간 비용이 수백만 달러 단위였던 것과 비교하면, 차원이 다른 효율성이었다.

"오염 아닌가?" — 논란과 검증
이렇게 좋은 결과가 나오면 의심이 따른다. AI 커뮤니티에서 가장 먼저 제기된 의문은 벤치마크 오염(benchmark contamination)이었다. "GPT-3.5로 생성한 합성 데이터 안에 HumanEval 문제의 답이 포함되어 있는 것 아닌가?"
저자들은 이 의심에 대해 다중 검증을 수행했다.
- N-gram 분석: 학습 데이터와 벤치마크 문제 사이의 N-gram 중복률을 측정. 유의미한 오염을 발견하지 못함
- AST 기반 유사도: 코드의 추상 구문 트리(Abstract Syntax Tree) 수준에서 구조적 유사도를 분석. 표면적 텍스트가 달라도 구조가 같은 경우를 잡아내기 위한 것
- 데이터 삭제 후 재학습: 학습 데이터의 40%를 무작위로 삭제한 뒤 다시 학습해도 StarCoder를 추월
- 신규 문제 테스트: 연구진이 새로 만든 50개의 코딩 문제에서 phi-1은 52%, StarCoder는 34%
오염 가능성을 완전히 배제할 수는 없었지만, 이 정도의 검증이면 "핵심 성능이 오염 때문이 아니다"는 주장을 뒷받침하기에 충분했다.
또 다른 비판: "이건 그냥 지식 증류 아닌가?"
더 근본적인 비판도 있었다. "GPT-3.5가 생성한 데이터로 학습한 것이면, 결국 GPT-3.5의 지식을 작은 모델에 옮긴 것(지식 증류) 아닌가? 교과서 품질이 중요한 게 아니라, 강한 모델의 지식을 전달한 것이 핵심 아닌가?"
이것은 일리 있는 비판이었다. 하지만 저자들은 두 가지 반론을 제시했다. 첫째, 필터링된 웹 코드(첫 번째 소스)는 합성 데이터가 아니라 인간이 작성한 실제 코드다. 이 데이터만으로도 상당한 성능 향상이 있었다. 둘째, 합성 데이터의 역할은 "GPT-3.5의 지식을 전달하는 것"이 아니라 "교과서처럼 잘 정리된 형식으로 개념을 제시하는 것"이었다. 같은 개념이라도 제시 방식이 학습 효율에 결정적 영향을 미친다는 것이 논문의 핵심 주장이었다.
비유하자면 이렇다. 수영을 가르치는 방법은 두 가지가 있다. 하나는 바다에 던져 넣는 것이다. 파도와 싸우면서 어떻게든 수영을 배울 수 있다. 인터넷 크롤링 데이터로 학습하는 것이 이것과 같다. 다른 하나는 전문 강사가 체계적으로 가르치는 것이다. 물에 뜨는 법부터, 팔 젓기, 발차기, 호흡법을 순서대로 배운다. 교과서 품질 데이터가 이것이다. 바다에서도 수영을 배울 수 있지만, 체계적 교습이 훨씬 효율적이다. phi-1은 그 효율성의 차이가 100배의 크기 차이를 뒤집을 수 있다는 것을 증명했다.
제3장: 코드를 넘어 — Phi 시리즈의 진화 (2023–2025)
phi-1의 성공은 시작에 불과했다. Microsoft Research 팀은 하나의 질문을 계속 밀어붙였다. "교과서 품질 데이터의 힘이 코딩에만 한정되는 것인가, 아니면 범용적인 원리인가?"

phi-1.5: 코드에서 자연어로 (2023년 9월)
phi-1 발표 3개월 뒤, Yuanzhi Li 등이 phi-1.5를 발표했다. 같은 1.3B 파라미터 크기에, 코딩 능력을 유지하면서 자연어 이해와 상식 추론 능력을 추가한 모델이었다.
비결은 역시 합성 데이터였다. 200억 토큰 규모의 "합성 교과서"를 생성했는데, 이번에는 프로그래밍이 아니라 과학, 일상 생활, 상식 추론 등 다양한 주제의 교과서 스타일 텍스트였다.
결과는 놀라웠다. 1.3B 파라미터의 phi-1.5가 5B~7B 모델급의 성능을 보여준 것이다. 그런데 더 흥미로운 발견이 있었다. phi-1.5에서 chain-of-thought 추론이 창발적으로 나타난 것이다. 1.3B라는 작은 모델에서 이런 능력이 나타나는 것은 기존 상식에 어긋났다. 일반적으로 이런 능력은 수십 B 이상의 모델에서만 관찰되었으니까.
phi-1.5 논문에는 예언적인 문장이 하나 있다.
"creation of synthetic datasets will become a crucial technical skill"
— 합성 데이터셋의 생성이 핵심 기술이 될 것이다
2026년 현재, 이 예언은 현실이 되었다.
Phi-2: 절반 크기로 두 배 크기를 이기다 (2023년 12월)
2023년 12월, Phi-2가 발표되었다. 2.7B 파라미터, 1.4T 토큰으로 학습. phi-1.5 대비 파라미터는 2배, 데이터는 70배로 늘었지만 여전히 "소형 모델"의 범주에 있었다.
Phi-2의 성적표: Llama-2 13B를 추월. 파라미터가 5분의 1도 안 되는 모델이 5배 큰 모델을 이긴 것이다. Phi-2에는 또 다른 혁신이 있었다. "지식 전이(knowledge transfer)"라는 기법으로, phi-1.5에서 학습된 지식을 Phi-2의 학습 초기 단계에 이식했다. 작은 모델에서 검증된 교과서 품질 학습의 성과를 다음 모델에 넘겨주는 방식이었다.
사트야 나델라 Microsoft CEO가 Ignite 컨퍼런스에서 Phi-2를 직접 발표했다. "소형 언어 모델"이라는 개념이 실험실을 넘어 산업 전략의 한 축으로 자리잡는 순간이었다.
Phi-3: "어린이의 학습"에서 영감을 얻다 (2024년 4월)
Phi-3는 소형 모델의 가능성을 한 단계 더 끌어올렸다. 3.8B 파라미터의 Phi-3-mini가 Mixtral 8x7B(총 45B 파라미터)를 MMLU 벤치마크에서 추월한 것이다. 68.8% vs 68.4%. 파라미터 수 기준 12배 작은 모델이 이겼다.
Phi-3의 데이터 전략에는 새로운 착안이 추가되었다. "어린이가 언어를 배우는 방식"에서 영감을 받은 것이다. 어린이는 제한된 양의 텍스트(부모의 대화, 그림책, 교과서)만으로도 놀라운 언어 능력을 갖추게 된다. 이것은 Microsoft Research의 이전 연구인 TinyStories 접근법의 진화였다. TinyStories는 3~4세 수준의 단순한 이야기로도 일관된 문법과 서사를 학습할 수 있음을 보여준 연구다.
세바스티앙 부벡은 이렇게 설명했다.
"Because it's reading from textbook-like material, from quality documents that explain things very, very well, you make the task of the language model to read and understand this material much easier."
— 교과서 같은 고품질 자료를 읽으면, 언어 모델이 이해하는 과제가 훨씬 쉬워진다.

Phi-4: 학생이 교사를 넘어서다 (2024년 12월)
Phi-4는 Phi 시리즈의 결정판이었다. 14B 파라미터, 10T 토큰으로 학습. 여기서 주목할 숫자는 합성 데이터 비율 40%다. 전체 10T 토큰 중 4T가 합성 데이터였다.
Phi-4의 결과는 기존 Phi 시리즈보다 더 극적이었다.
Phi-4 vs GPT-4o 벤치마크 비교
Phi-4 (14B) HumanEval
82.6%
14B 파라미터 모델이 GPT-4o를 MATH 벤치마크에서 이겼다. 80.4% vs 74.6%. 이것은 "교사 모델을 능가하는 학생"이라는 현상을 보여준 것이다. Phi-4의 합성 데이터는 GPT-4 계열 모델을 사용해 생성되었지만, 최종 모델의 수학 성능은 GPT-4o를 넘어섰다. 단순한 지식 증류가 아니라는 증거였다.
Phi-4에는 Pivotal Token Search (PTS)라는 혁신적 기법도 도입되었다. 수학 풀이에서 정답과 오답을 가르는 "결정적 토큰"을 식별하는 방법이다. 예를 들어, 수학 문제를 풀 때 10단계의 풀이 과정 중 3번째 단계에서 부호를 잘못 넣으면 나머지가 전부 틀어진다. PTS는 이런 "성패를 가르는 순간"을 찾아내어 모델이 그 지점에서 집중적으로 학습하도록 했다. Phi-4 기술 보고서는 이렇게 밝혔다.
"performing more iterations on the synthetic data is more beneficial than supplying more web tokens"
— 합성 데이터에 더 많은 반복 학습을 하는 것이, 더 많은 웹 토큰을 공급하는 것보다 유익하다
Phi-4-reasoning: 수학 올림피아드에 도전하다 (2025년 4월)
2025년 4월, Phi 시리즈의 최신작인 Phi-4-reasoning-plus가 발표되었다. 여전히 14B 파라미터. 이 모델이 AIME 2025(미국 수학 올림피아드 예선)에서 기록한 점수는 82.5%.
이 점수가 어떤 의미인지 맥락을 보자. AIME에서 비슷한 수준의 성능을 낸 모델은 DeepSeek-R1이다. DeepSeek-R1의 파라미터 수는 671B. Phi-4-reasoning의 48배다.
Phi 시리즈 연대기: 파라미터 수 vs "이긴 상대"
phi-1 (1.3B)
→ GPT-3.5 (175B)
Phi-2 (2.7B)
→ Llama-2 (13B)
Phi-3-mini (3.8B)
→ Mixtral 8x7B (45B)
Phi-4-reasoning (14B)
→ DeepSeek-R1 (671B)
3년간의 흐름을 정리하면 이렇다. phi-1에서 Phi-4-reasoning까지, 모델 크기는 1.3B에서 14B로 약 10배 커졌다. 하지만 이기는 상대의 크기는 175B에서 671B로, 거의 4배가 올라갔다. "작은 모델의 한계"가 아니라 "작은 모델의 가능성"이 계속 확장되고 있다.
phi-1
→
phi-1.5
→
Phi-2
→
Phi-3
→
Phi-4
→
Phi-4-reasoning
각 세대에서 핵심 전략은 동일했다. 교과서 품질 데이터, 합성 데이터의 전략적 활용, 그리고 작은 모델의 효율성 극대화. "Textbooks Are All You Need"의 핵심 통찰이 3년간 일관되게 유효했다는 뜻이다.
제4장: 왜 이것이 중요한가 — 소형 모델이 바꾸는 세상
phi-1이 GPT-3.5를 이긴 것이 벤치마크 위의 숫자 놀음일 뿐이라면, 이 글은 여기서 끝나도 된다. 하지만 소형 언어 모델(SLM)의 등장은 단순한 학술적 성과가 아니다. AI가 배포되는 방식 자체를 바꾸고 있다.
LLM의 현실적 한계
2026년 현재, 최고 성능의 LLM을 사용하려면 이런 현실과 마주해야 한다.
- 비용: 입력 1M 토큰당 $0.50~$2.00. 매일 수백만 건의 요청을 처리하는 서비스라면, 토큰 비용만으로 월 수억 원이 나간다
- 지연: API 호출 한 번에 500~2,000ms. 실시간 응답이 필요한 서비스에서는 치명적
- 프라이버시: 사용자의 데이터가 클라우드 서버로 전송된다. 의료 기록, 금융 데이터, 기업 기밀을 외부 API에 보내는 것은 많은 조직에서 허용되지 않는다
- 연결 필수: 인터넷이 없으면 AI도 없다. 비행기 안에서, 지하철에서, 통신이 불안정한 환경에서는 사용 불가
- 모델 크기: 140~350GB. 개인 디바이스에서 실행하는 것은 불가능
SLM이 여는 다른 세상
소형 언어 모델은 이 모든 한계를 뒤집는다.
LLM (대형 언어 모델)
비용: $0.50–2.00 / 1M 토큰
지연: 500–2,000ms
프라이버시: 클라우드 전송 필수
배포: 데이터센터 전용
크기: 140–350GB
연결: 인터넷 필수
SLM (소형 언어 모델)
비용: $0.01–0.05 / 1M 토큰 (10–30배 저렴)
지연: 50–100ms (10–20배 빠름)
프라이버시: 온디바이스, 데이터 유출 없음
배포: 스마트폰, 노트북, 엣지 디바이스
크기: 14–26GB (양자화 시 더 작음)
연결: 오프라인 가능
10~30배 저렴한 비용, 10~20배 빠른 응답, 완벽한 프라이버시, 오프라인 작동. 이것은 "같은 일을 싸게 하는 것"이 아니라, 완전히 다른 종류의 AI 서비스를 가능하게 하는 것이다.
현실이 된 온디바이스 AI
이론이 아니다. 2025년 현재, 세계 최대 기술 기업들이 SLM을 핵심 전략으로 채택했다.
Apple Intelligence (2025). Apple은 약 3B 파라미터의 온디바이스 모델을 iPhone, iPad, Mac에 탑재했다. 2비트 양자화로 모델 크기를 극단적으로 줄이고, KV-cache 공유 기법으로 메모리 효율을 높였다. 16개 언어를 지원하며, 내부 벤치마크에서 Phi-3-mini, Mistral-7B, Llama-3-8B를 추월했다. 사용자의 이메일, 메시지, 사진이 기기 밖으로 나가지 않으면서도 요약, 편집, 검색 기능을 제공한다.
Google Gemini Nano. Pixel 9 시리즈에 탑재된 Gemini Nano는 Tensor G5 칩의 NPU에서 실행된다. 4비트 양자화를 적용하여, 스팸 감지, 메시지 요약, 오프라인 스마트 답장 등을 인터넷 연결 없이 처리한다. 사용자가 비행기 모드에서도 AI 기능을 사용할 수 있다.
Microsoft Phi Silica. Microsoft의 Copilot+ PC에 탑재된 Phi Silica는 NPU에 최적화된 Phi 시리즈 파생 모델이다. Windows의 기본 기능(검색, 요약, 번역 등)에 통합되어, 사용자가 별도의 API 호출이나 클라우드 연결 없이도 AI 기능을 사용할 수 있다.
Apple Intelligence
Gemini Nano
Phi Silica
↓
iPhone / iPad / Mac
Pixel / Android
Copilot+ PC
↓
온디바이스 AI: 빠르고, 저렴하고, 프라이빗하고, 오프라인

Apple, Google, Microsoft — 세 기업은 서로 다른 길을 걸어왔지만, 2025년에 같은 결론에 도달했다. 작지만 잘 훈련된 모델이, 사용자 디바이스에서 직접 실행되는 AI의 열쇠다.
NVIDIA도 같은 방향을 가리키고 있다. 2025년 포지션 페이퍼에서 NVIDIA는 "SLM이 에이전트 AI의 미래"라고 선언했다. AI 에이전트가 실시간으로 판단하고 행동하려면, API 호출을 기다릴 시간이 없다. 엣지에서 빠르게 추론하는 SLM이 필수라는 논리다.
시장 규모도 이 방향성을 반영한다. SLM 시장은 2023년 $7.76B에서 2030년 $20.7B로, 연평균 15.1%의 성장률이 전망된다.
💡
핵심 통찰: SLM은 LLM의 "저가형"이 아니다. 엣지, 온디바이스, 실시간이라는 완전히 다른 배포 패러다임을 가능하게 하는 기술이다. LLM이 할 수 없는 일을 SLM이 한다.
제5장: 2026년 관점 — "교과서가 답이다"를 어떻게 읽을 것인가
"Textbooks Are All You Need"가 발표된 지 3년이 지났다. 이 논문의 핵심 주장은 검증되었는가? 반론은 해소되었는가? 그리고 2026년의 AI 개발자에게 어떤 교훈을 남겼는가?
검증된 것
데이터 품질 > 데이터 양. Phi 시리즈가 3년간 일관되게 증명한 원리다. phi-1에서 Phi-4-reasoning까지, 세대가 바뀔 때마다 모델 크기와 데이터 양은 늘어났지만, 핵심 전략은 변하지 않았다. 교과서 품질의 데이터를 만들고, 합성 데이터를 전략적으로 활용하고, 그 효율성으로 작은 모델이 큰 모델을 이기는 것. 이 원리가 한 번만 성공했다면 우연일 수 있다. 6세대에 걸쳐 반복되었다면, 그것은 원리다.
독립적 검증. Microsoft만의 주장이 아니다. Apple, Google, NVIDIA가 독립적으로 같은 결론에 도달했다. Apple Intelligence의 온디바이스 모델은 "적은 파라미터, 높은 품질 데이터"라는 정확히 같은 전략을 따른다. NVIDIA의 데이터 플라이휠 아키텍처도 "더 많은 데이터"가 아니라 "더 좋은 데이터"의 순환을 핵심으로 한다.
합성 데이터가 주류가 되었다. 2023년에는 "합성 데이터로 학습? 그게 되나?"라는 의문이 일반적이었다. 2026년에는 주요 모델 학습에 합성 데이터가 포함되지 않는 경우를 찾기가 더 어렵다. Phi-4는 전체 학습 데이터의 40%가 합성 데이터였고, NVIDIA Nemotron-4의 정렬 데이터는 98% 이상이 합성이었다. phi-1.5 논문의 예언대로, 합성 데이터 생성은 AI 개발의 핵심 기술이 되었다.
뉘앙스와 한계
3년간의 검증이 모든 것을 해결하지는 않았다. 중요한 뉘앙스가 있다.
"양이 무의미하다"가 아니다. phi-1은 7B 토큰으로 학습했지만, Phi-4는 10T 토큰을 사용한다. 1,400배 증가다. "Textbooks Are All You Need"의 메시지는 "데이터를 줄여라"가 아니라 "데이터의 질을 높여라"다. 양을 줄인 것이 아니라, 양을 유지하면서 질을 올린 것이다. 이 구분은 중요하다.
합성 데이터 패러독스. 좋은 합성 데이터를 만들려면 GPT-4 같은 강한 교사 모델이 필요하다. 그 교사 모델은 어디서 왔는가? 대규모 데이터와 대규모 컴퓨팅으로 학습된 것이다. 결국 합성 데이터 전략은 "대규모 모델이 먼저 존재해야" 가능하다. 이것은 순환 의존이다. 닭이 먼저냐 달걀이 먼저냐의 문제. phi-1의 성공이 GPT-3.5 없이는 불가능했다는 사실은 부정하기 어렵다.
잘 작동하는 영역과 아직 어려운 영역. Phi 시리즈가 인상적인 성과를 보여준 영역은 주로 코드, 수학, 논리적 추론이다. 이 영역들의 공통점은 정답이 명확하다는 것이다. 코드는 실행되거나 실행되지 않고, 수학 문제는 답이 맞거나 틀리다. 반면, 넓은 세계 지식(역사적 맥락, 문화적 뉘앙스), 개방형 대화(공감, 유머, 창의적 글쓰기), 다국어 이해 같은 영역에서 SLM은 여전히 LLM에 크게 뒤진다. 교과서 품질 데이터의 힘이 모든 영역에 동등하게 적용되는 것은 아니다.
Model Collapse 우려. 합성 데이터로 학습한 모델이 다시 합성 데이터를 생성하고, 그 데이터로 다음 세대 모델을 학습시키면 어떻게 될까? 2024년 Nature에 발표된 Shumailov et al.의 연구는 이런 순환이 반복되면 모델이 붕괴한다는 것을 보여줬다. 원래 데이터 분포의 다양성이 세대를 거듭하며 소실되는 것이다. Phi 시리즈가 지금까지 이 문제를 피한 것은 매 세대마다 "신선한" 교사 모델(GPT-3.5, GPT-4)과 실제 웹 데이터를 함께 사용했기 때문이다. 하지만 합성 데이터의 비중이 계속 늘어난다면, 이 문제는 언젠가 정면으로 다뤄야 할 과제가 된다.
LLM vs SLM이 아니라, LLM + SLM
"소형 모델이 대형 모델을 이겼다"는 서사는 매력적이지만, 현실은 더 미묘하다. 2026년의 실무에서 정답은 이 둘을 함께 사용하는 것이다.
LLM + SLM 이종 에이전트 시스템
오케스트레이터
작업 복잡도에 따라 SLM 또는 LLM에 라우팅
SLM (온디바이스 / 엣지)
간단한 분류, 요약, 포맷 변환, 실시간 응답 | 전체 요청의 70–80%
LLM (클라우드)
복잡한 추론, 긴 문서 분석, 창의적 생성, 멀티모달 | 전체 요청의 20–30%
회사에서 모든 결정을 CEO가 하지 않는다. 일상적인 업무 결정은 담당자가 하고, 전략적 판단만 경영진이 한다. AI 시스템도 마찬가지다. 간단한 분류, 요약, 포맷 변환 같은 작업은 SLM이 온디바이스에서 즉시 처리한다. 복잡한 추론, 긴 문서 분석, 창의적 생성 같은 작업만 LLM에게 넘긴다. 대부분의 실제 서비스에서 "간단한 작업"은 전체의 70~80%를 차지한다. 이 부분을 SLM이 처리하면, 비용은 급감하고 속도는 급증한다.
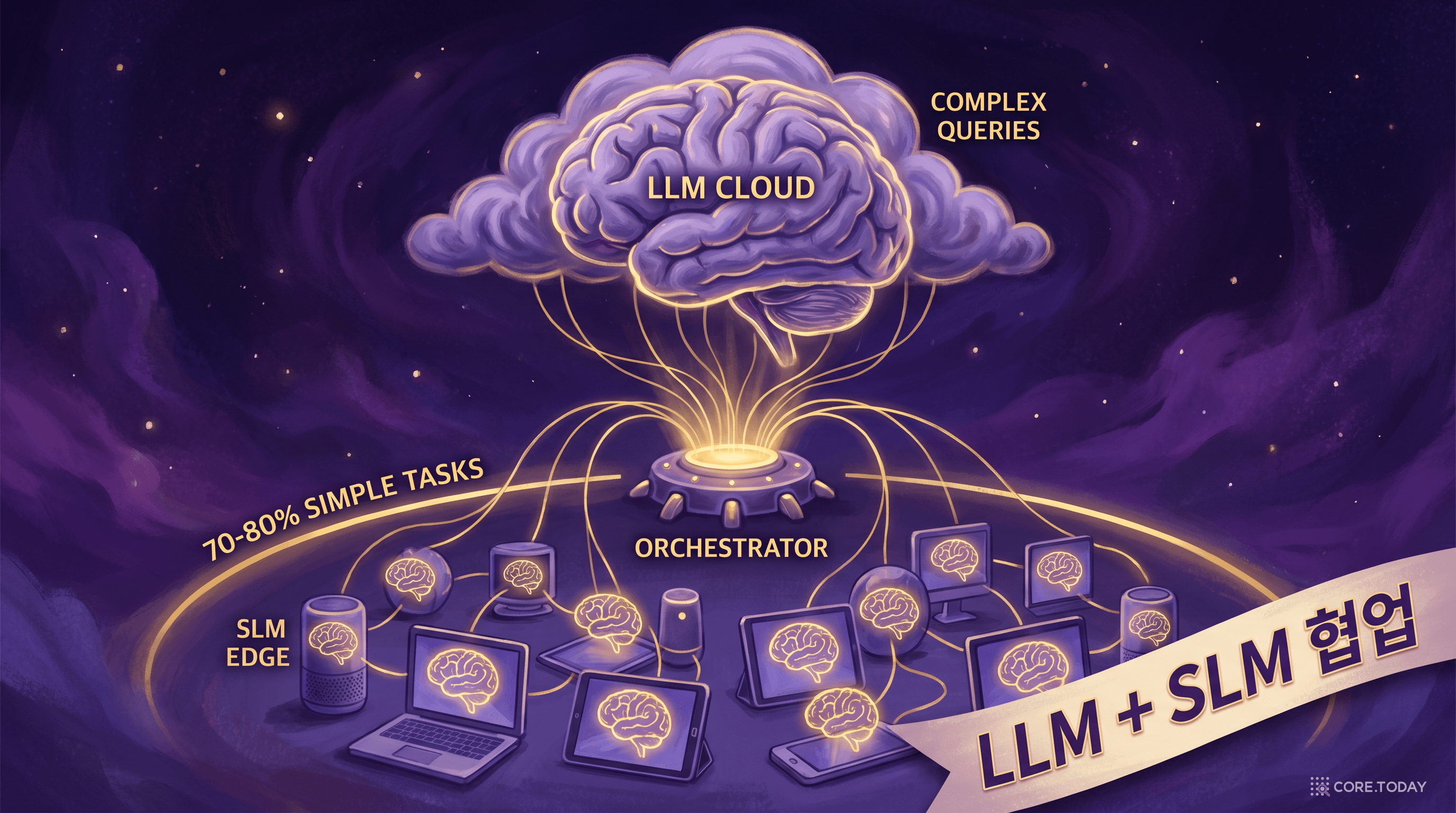
이것이 NVIDIA가 말한 "SLM이 에이전트 AI의 미래"의 의미다. 에이전트가 10개의 도구를 호출하고, 3단계의 추론을 거쳐 작업을 완료하는 과정에서, 매번 클라우드 LLM을 호출할 수는 없다. 각 단계가 50ms면 전체가 1.5초, 각 단계가 1,500ms면 전체가 45초다. 에이전트의 실시간성은 SLM에 달려 있다.
이 논문이 남긴 교훈
"Textbooks Are All You Need"가 AI 개발자에게 남긴 가장 중요한 메시지는 이것이다.
데이터 큐레이션은 모델 아키텍처만큼 중요한 기술이 되었다.
2020년까지 AI 연구의 영웅은 새로운 아키텍처를 설계하는 사람이었다. Transformer를 만든 사람, ResNet을 만든 사람. 2026년에는 다른 종류의 영웅이 추가되었다. 좋은 데이터를 만들고, 고르고, 정제하는 사람. "무엇으로 학습시킬 것인가"라는 질문이 "어떤 구조로 학습시킬 것인가"만큼 중요해진 것이다.
Phi-4가 GPT-4o를 수학에서 이긴 것은 아키텍처의 승리가 아니다. 둘 다 Transformer 기반이다. 차이를 만든 것은 데이터를 다루는 방식이었다. 어떤 데이터를 선별하고, 어떤 합성 데이터를 생성하고, 어떤 순서로 학습시키는가. 이것이 14B 모델과 수백 B 모델의 격차를 메운 것이다.
마치며
돌이켜보면, "Textbooks Are All You Need"의 통찰은 직관적이다. 너무 직관적이어서, 왜 2023년이 되어서야 누군가 그 질문을 던졌는지가 오히려 의아할 정도다.
인간도 무작위 정보의 홍수 속에서 학습하는 것보다, 잘 정리된 교과서로 학습할 때 더 효율적이다. 인터넷을 하루 종일 서핑하는 것보다 교과서를 한 시간 읽는 것이, 그 과목에 대한 이해를 더 깊게 만들어준다. 우리는 이것을 경험적으로 알고 있다. 기계에게도 같은 원리가 적용된다는 것이 이 논문의 핵심이었고, 3년간의 후속 연구가 그것을 확인해주었다.
세바스티앙 부벡의 질문 "정말 좋은 데이터로 학습하면 어떨까?"는 3년 만에 답을 얻었다. 그 답은 지금 여러분의 주머니 속에 있다. 스마트폰 안에서 돌아가는 AI, 노트북 위에서 오프라인으로 작동하는 AI, 인터넷 없이도 사용자의 질문에 답하는 AI. 이 모든 것이 가능해진 이유는, 누군가 "크게 만들면 된다"는 상식에 의문을 제기하고, "교과서처럼 잘 가르치면 작아도 된다"는 것을 증명했기 때문이다.
"Attention Is All You Need"가 아키텍처 혁명이었다면, "Textbooks Are All You Need"는 데이터 혁명이다. 전자가 "기계가 어떻게 배우는가"를 바꿨다면, 후자는 "기계가 무엇으로 배우는가"를 바꿨다. 그리고 두 혁명이 합쳐진 결과가, 2026년 우리가 매일 사용하는 AI의 현재다.




