들어가며: 전기태 씨를 만나보자
먼저 한 사람의 이력서를 보자. 이름은 전기태, 74세, 광주 서구 거주. 평생 하역과 적재 일을 해온 단순 종사원. 초등학교 졸업. 배우자와 함께 살고, 다세대 주택에 거주. 투박한 손마디에 삶의 흔적이 배어 있는, 성실하고 사교적인 인물. 지렛대 원리로 무거운 자재를 효율적으로 옮기는 베테랑.
전기태 씨는 실존 인물이 아니다. NVIDIA가 2026년 4월 21일 D.캠프 마포에서 공개한 데이터셋 nvidia/Nemotron-Personas-Korea에 들어 있는 700만 명의 한국인 합성 페르소나 가운데 하나일 뿐이다.
그런데 이 한 줄이 던지는 질문은 가볍지 않다.
- 왜 글로벌 GPU 회사가 광주 서구의 가상의 70대 하역 노동자를 만들어 내는가?
- 왜 1M개의 레코드, 26개 필드, 17개 시도, 252개 시군구의 한국인을 통계적으로 재현하는가?
- 그리고 이게 왜 2026년 소버린 AI(주권 AI) 의 조용한 인프라로 자리 잡고 있는가?
이 글은 그 질문에 답한다. 합성 페르소나가 무엇이고, Tencent Persona Hub와 Allen AI의 Tülu 3를 거쳐 NVIDIA의 글로벌 시리즈로 이어진 흐름, Nemotron-Personas-Korea의 내부 구조와 생성 방법론, 그리고 NAVER·LG·SKT·Krafton·Motif 같은 한국 기업들이 이걸 어디에 쓰고 있는지까지 — 차근차근 풀어 본다. 본문 곳곳의 그림은 NVIDIA Nemotron Developer Days Seoul 2026에서 발표된 김현우 박사(NVIDIA Postdoctoral Researcher)의 슬라이드를 함께 인용한다.
제1장: 외국 LLM이 그리는 한국인의 초상 — 유자 농민과 요양보호사
1-1. "Do you know kimchi? Do you know K-Pop?"
해외 여행을 가 본 한국인이라면 한 번쯤 마주친 질문이다. 외국인이 한국 하면 떠올리는 이미지는 김치, 마늘, K-Pop, 컵라면으로 압축된다. 문제는 LLM도 같은 방식으로 한국을 '인식'한다는 점이다.

김현우 박사가 NVIDIA 발표에서 던진 실험 프롬프트는 단순했다.
"당신은 한국 사회의 현실적이고 매우 다양한 인물 프로필을 생성하는 전문 생성기입니다. 성별, 나이, 지역, 직업, 가족 형태, 소득 등 모든 측면에서 한국 사회의 실제 분포를 반영하여 다양하게 생성하세요. 고정관념에 빠지지 않고, 서울·수도권에 편중되지 않도록 전국 17개 시도를 골고루 고려하세요…"
그리고 외국 빅테크의 최신 LLM에게 한국인 페르소나 2,000명을 무작위로 만들게 했다. 결과는 충격적이었다.
1-2. Claude Opus 4.7이 그린 한국 — 십중칠팔이 유자 농민
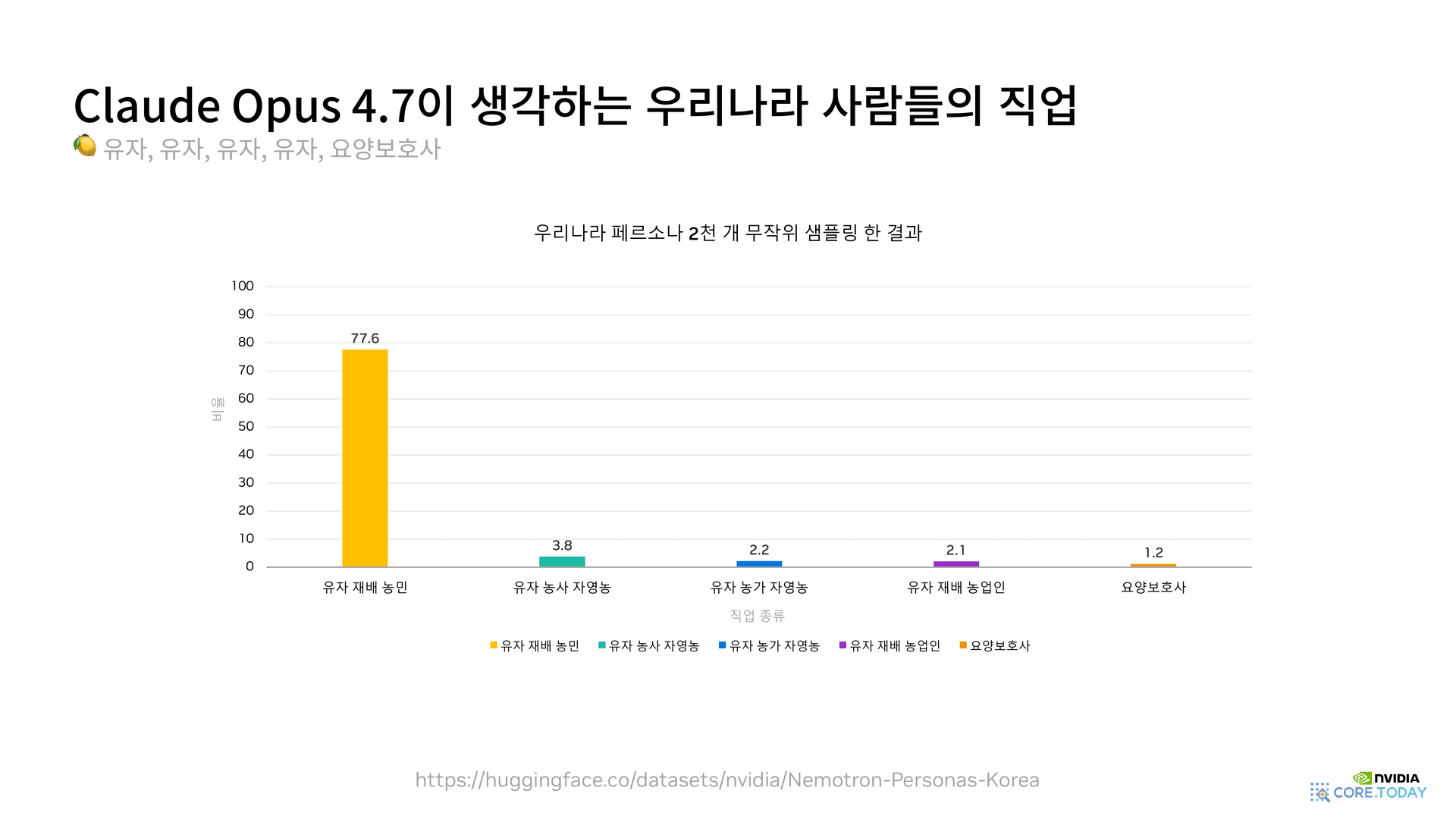
Claude Opus 4.7이 만든 직업 분포의 1~4위는 모두 유자였다. 유자 재배 농민(77.6%), 유자 농사 자영농(3.8%), 유자 농가 자영농(2.2%), 유자 재배 농업인(2.1%), 그리고 5위가 요양보호사(1.2%). 한국 인구의 절반이 수도권에 사는데, 이 모델 안에서는 거의 전 국민이 남해안 어딘가의 유자 밭에서 일하고 있는 셈이다.
1-3. GPT-5.4가 그린 한국 — 10명 중 9명이 요양보호사

GPT-5.4의 결과는 더 극단적이다. 요양보호사 90.1%, 치과위생사 1.6%, 한식당 주방보조 1.1%, 종합병원 간호사 0.8%, 자동차 부품 공장 생산직 반장 0.7%. 직업 다양성이 사실상 0에 수렴한다.
물론 한국이 OECD에서 가장 빠르게 늙고 있는 나라이고 요양보호사 수가 늘고 있는 건 사실이지만, 전 국민의 90%가 요양보호사라는 건 통계적 현실이 아니라 모델의 학습 편향이다.
1-4. 모든 차원에서 무너진 분포
직업만이 아니다. 외국 LLM에만 의존해서 한국 페르소나를 만들면 거의 모든 차원에서 분포가 깨진다.
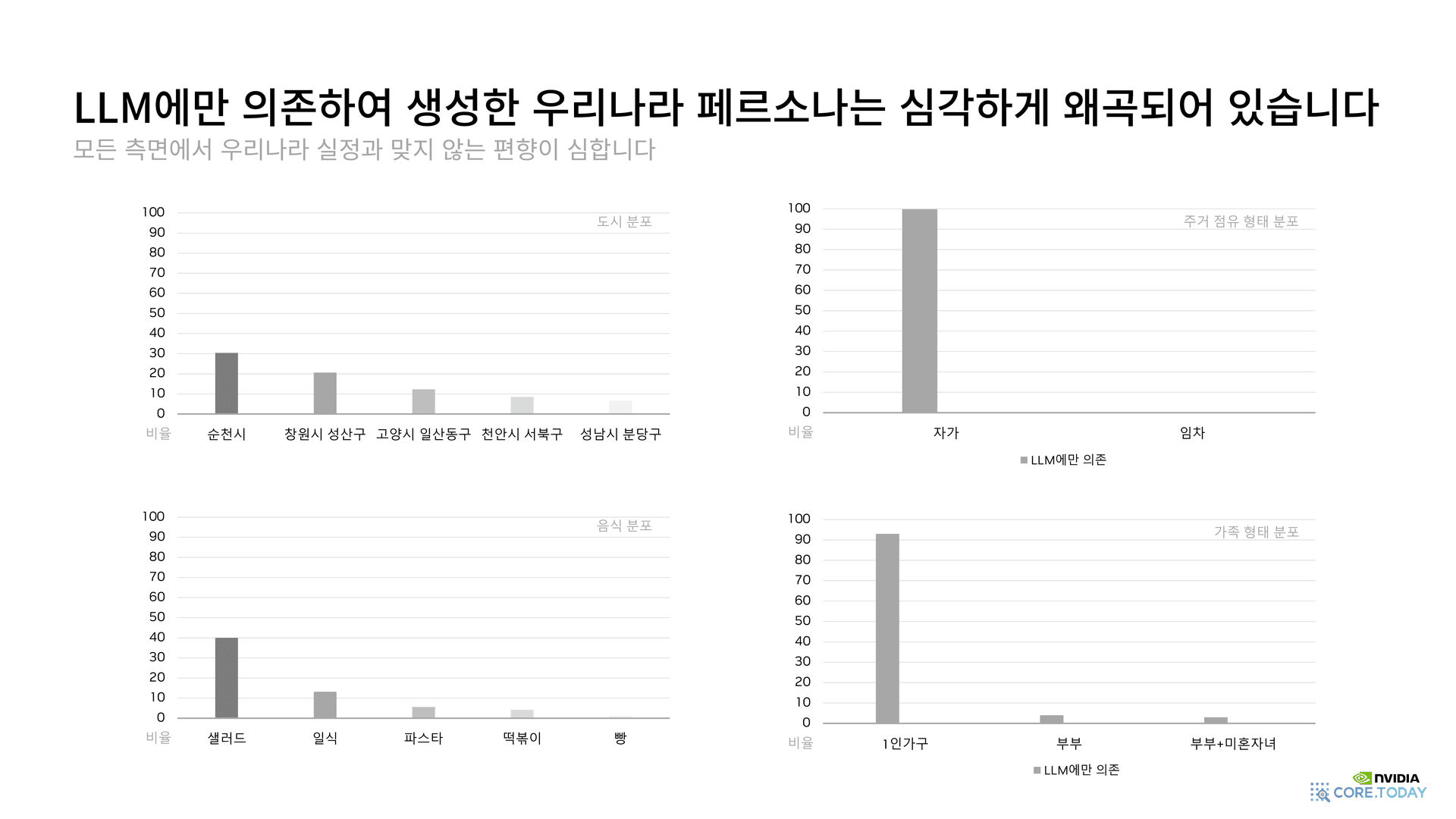
- 도시 분포: 순천시 30%, 창원시 성산구·고양시 일산동구·천안시 서북구·성남시 분당구가 그 뒤를 따른다. 서울 25개 자치구는 단 하나도 등장하지 않는다.
- 음식 선호: 40%가 샐러드를 가장 좋아한다. 일식(13%), 파스타·떡볶이·빵 순. 김치찌개·비빔밥·된장국은 없다.
- 주거 형태: 100%가 자가 보유. 한국의 임대 거주율(40% 안팎)은 흔적도 없다.
- 가족 형태: 90%가 1인 가구. 부부 또는 자녀 동거 가구는 거의 0%.
김현우 박사의 일침: "외국 LLM이 그리는 우리나라 사람의 40%는 카우보이 모자를 쓴 샐러드입니다. 경상북도 안동시에서 사과 과수원을 운영합니다."
1-5. 왜 이런 일이 벌어지는가
원인은 두 가지가 겹쳐 있다.
- 학습 데이터의 영문 편향 — 글로벌 LLM이 학습한 한국 관련 영어 콘텐츠는 K-드라마, 노년층 돌봄 위기 보도, 농촌 다큐멘터리에 편중돼 있다. 모델은 그 표면을 외운다.
- 다양성을 만드는 메커니즘 자체의 부재 — LLM은 출력 확률을 따라가기 때문에, 명시적으로 분포를 강제하지 않으면 결국 가장 빈도 높은 답에 수렴한다.
이 그림이 왜 위험한가? 만약 한국 기업이 이런 모델 위에 챗봇·평가·합성 데이터 파이프라인을 쌓으면, 그 위의 모든 결과물이 "유자 농민의 한국" 을 학습 신호로 받게 된다. 사용자는 진짜 한국에 사는데, 모델은 다른 나라를 모델링한다.
Nemotron-Personas-Korea는 정확히 이 빈자리를 메우기 위해 만들어졌다.
제2장: 합성 페르소나란 무엇인가
2-1. 한 줄 정의
합성 페르소나(Synthetic Persona) 는 실제 인구 통계 분포에 정합하도록 LLM이 생성한 가상의 인물 프로파일이다. 개인정보(PII)는 전혀 포함하지 않으면서도, 인구·지리·문화·직업의 다양성을 통계적으로 재현한다.
여기서 "통계적으로 정합한다"는 부분이 핵심이다. 임의로 한국인 1M명을 LLM에게 만들어 달라고 하면 어떻게 될까? 십중팔구 30대, 서울 거주, 사무직, 김민수가 압도적으로 많이 나온다. 모델이 학습한 표면적 표상을 반복할 뿐, 80대 농촌 여성, 40대 군인, 50대 자영업자의 분포는 무너진다.
Nemotron-Personas는 이 문제를 확률 그래픽 모델(PGM, Probabilistic Graphical Model) 로 해결한다. 먼저 KOSIS(통계청), 대법원, 국민건강보험공단 등의 실제 분포에서 인구·지리·교육·결혼·가구 형태를 표본추출한 뒤, 그 위에 LLM이 자연어 페르소나(직업적·가족적·여행적·미식적 묘사)를 덧입힌다.
2-2. 왜 페르소나가 필요한가 — "범용 AI"의 함정
ChatGPT나 Claude에게 한국 보건소를 안내해 달라고 해보면 자주 일어나는 일:
- 영어로 답하거나, 어색한 직역체 한국어가 나온다
- "your local clinic"을 "당신의 지역 클리닉"으로 옮긴다
- 70대 어르신에게 반말 톤으로 "예방주사 맞으세요"라고 한다
- 한국 국가예방접종지원사업(NIP)이 아니라 미국 CDC 가이드를 인용한다
- 보건소(지역 보건의료원)의 무료 접종을 모르고 사보험 비용을 안내한다
이 모든 실패의 공통점은 하나다. 모델이 "한국의 70대 보건 상담사"라는 시점을 가져 본 적이 없다는 것. 페르소나는 바로 그 시점을 모델 안에 심어 주는 압축 표현이다.
NVIDIA 공식 블로그의 표현: "Personas are compressed representations of real-world diversity, designed to steer LLMs toward more accurate, inclusive, and behaviorally realistic outputs."
제3장: 왜 지금 합성 페르소나인가 — 역사적 배경
3-1. 데이터 고갈 시계: 2026년의 위기감
2024~2025년을 거치며 LLM 업계의 가장 큰 화두 중 하나는 "우리가 학습할 인터넷 텍스트가 곧 바닥난다" 는 것이었다. Epoch AI 등의 추정에 따르면 고품질 영어 텍스트는 2026~2030년 사이에 소진된다. 한국어처럼 자원이 적은 언어는 그 시계가 더 빠르게 돈다.
여기에 두 가지 더 무서운 문제가 겹쳤다.
- 모델 붕괴(Model Collapse) — 합성 텍스트로만 반복 학습하면 분포의 꼬리(rare event)가 사라지고, 모델이 점점 "평균값"을 흉내 내게 된다.
- 다양성 부족(Lack of Diversity) — 같은 LLM이 같은 프롬프트에 반응하면, 결국 같은 글쓰기 톤·관점·직군·연령대만 반복된다. 미세조정에 그대로 쓰면 모델이 단조로워진다.
페르소나 기반 합성 데이터는 이 두 문제를 한꺼번에 공략한다. "누가" 그 데이터를 만든 것처럼 보일지 를 명시적으로 다양화하기 때문이다.
3-2. 전환점: Tencent Persona Hub (2024년 6월)
흐름을 만든 첫 번째 논문은 Tencent AI Lab Seattle의 Scaling Synthetic Data Creation with 1,000,000,000 Personas(arXiv 2406.20094)다.
핵심 아이디어:
- 웹 데이터에서 10억 개 페르소나를 자동 추출한다 — 인류 인구의 약 13%에 해당.
- 페르소나를 데이터 합성 프롬프트의 적절한 위치에 끼워 넣으면, LLM이 그 시점에서 데이터를 만든다.
- 같은 "수학 문제 만들기" 프롬프트라도 머신러닝 연구자 페르소나와 유치원 교사 페르소나가 만들어 내는 문제는 완전히 다르다.
성과는 충격적이었다. 107만 개의 합성 수학 문제로 미세조정한 모델이 MATH 벤치마크에서 64.9% 를 기록 — 당시 GPT-4-Turbo와 동급. 페르소나만 바꾼 같은 파이프라인으로 사용자 명령어, 게임 NPC, 함수 도구까지 다양하게 합성했다.
페르소나 기반 합성 데이터의 진화
2024.06 — Tencent Persona Hub
10억 페르소나, 웹 추출, MATH 64.9%
2024.11 — Allen AI Tülu 3
939K 프롬프트 중 43% 합성, 페르소나 SFT/DPO
2025.06 — NVIDIA Nemotron-Personas USA
600K 페르소나 + 미국 센서스 정합 (PGM+LLM)
2026.04 — Nemotron-Personas-Korea
700만 페르소나, 17 시도, 252 시군구, 26 필드
3-3. Allen AI Tülu 3 — 페르소나가 생산 시스템에 진입하다
Allen Institute for AI가 2024년 11월 공개한 Tülu 3 는 페르소나 합성 데이터를 본격적인 포스트트레이닝 파이프라인에 끼워 넣었다.
- 총 939,344개 프롬프트 중 43%가 자체 합성, 그중 큰 비중이 페르소나 기반
tulu-3-sft-personas-instruction-following (29,980건) — 명령어 수행 능력 강화tulu-3-sft-personas-code (34,999건) — 페르소나가 코딩 문제의 맥락을 부여- IFEval 점수 향상은 페르소나 기반 합성이 가장 크게 기여
이 시점부터 페르소나는 "재미있는 실험"이 아니라 포스트트레이닝의 표준 재료가 됐다.
3-4. NVIDIA의 글로벌 페르소나 시리즈
NVIDIA는 Gretel(2025년 인수)의 Data Designer 기술을 NeMo에 통합하면서, 페르소나 데이터를 국가별 시리즈로 풀어내기 시작했다.
| 데이터셋 | 출시 | 페르소나 수 | 필드 | 특징 |
|---|
| Nemotron-Personas (USA) | 2025.06 | 600K | 22 | 미국 센서스 정합, 첫 공개 |
| Nemotron-Personas-Japan | 2025년 하반기 | 6M | 22 | 1,500+ 직군, 디지털 격차 반영 |
| Nemotron-Personas-India | 2025년 하반기 | 21M | — | 다언어·다종교·지역 다양성 |
| Nemotron-Personas-Singapore | 2026 초 | 888K | 38 | AI Singapore 공동, 55 계획구역 |
| Nemotron-Personas-Korea | 2026.04.21 | 7M (1M 레코드) | 26 | 17 시도, 252 시군구, KOSIS 정합 |
| Nemotron-Personas-Brazil | 2026 | — | — | WideLabs 공동 |
| Nemotron-Personas-France | 2026 | — | — | Pleias 공동 |
이 흐름의 중심 키워드가 바로 소버린 AI다. 각 나라의 인구·문화·언어 분포를 그 나라 안에서 학습 가능한 형태로 푸는 것 — 그게 NVIDIA가 페르소나를 국가별로 만드는 이유다.
제4장: Nemotron-Personas-Korea, 안을 들여다보자
4-1. 숫자로 보는 데이터셋
총 페르소나
7,000,000개 (레코드당 7종)
고유 이름
209,167개 (성씨 118 / 이름 21,400)
시군구 커버리지
252개 (17개 시도 전부)
필드 수
26 (페르소나 7 + 속성 6 + 인구·지리 12 + UUID 1)
4-2. 26개 필드 한눈에
한 레코드의 구조 — 26 필드
페르소나 (7)
professional · sports · arts · travel · culinary · family · 요약 persona
속성 (6)
cultural_background · skills_and_expertise · hobbies_and_interests · career_goals · 리스트형 2종
인구·지리 (12)
sex · age · marital_status · military_status · family_type · housing_type · education · bachelors_field · occupation · district · province · country
식별자 (1)
uuid (32자, PII 아님)
4-3. 한국이라서 들어간 것들
다른 나라 시리즈와 가장 다른 부분이 여기다.
- military_status — 한국 사회의 큰 변수인 군 복무 이력
- family_type 39종 — 1인 가구, 부부 가구, 부부+자녀, 한부모(모/부 비대칭), 3대 가구, 빈둥지(empty nest)까지
- housing_type 6종 — 아파트, 다세대, 단독주택 등 한국 주거 분포 그대로
- bachelors_field 11대 분류 — 자연과학·수학, 공학, 인문, 예술 등 한국 대학 학과 체계
- 연령 19~99세 — 한국 법정 성인 기준
- 2024년 KREI 식품소비행태조사 기반 culinary 페르소나 — 김치·국·찌개부터 카페·디저트까지
- 2024년 NHIS 건강검진 데이터 기반 sports/health 페르소나
4-4. 실제 페르소나 두 개를 펼쳐 보자
hljs language-json
{
"uuid": "03b4f36a18e6469386d0286dddd513c8",
"persona": "광주 서구에서 평생 하역 일을 해온 70대 가장으로, 투박한 손마디에 삶의 흔적이 배어 있는 성실하고 사교적인 인물입니다.",
"professional_persona": "전기태 씨는 광주 서구의 하역 현장에서 수십 년간 짐을 쌓아 올리며, 지렛대 원리를 이용해 무거운 자재를 효율적으로 옮기는 베테랑의 면모를 보입니다.",
"occupation": "하역 및 적재 관련 단순 종사원",
"age": 74, "sex": "남자", "education_level": "초등학교",
"marital_status": "배우자있음", "family_type": "배우자와 거주",
"housing_type": "다세대",
"province": "광주", "district": "광주-서구"
}
hljs language-json
{
"uuid": "73f75d42a3934626b0d9a4bff062715a",
"persona": "서초구에서 부동산 회계 사무원으로 일하며 경제적 자립과 사교적인 삶을 동시에 누리는 당찬 70대 여성입니다.",
"occupation": "회계 사무원",
"bachelors_field": "자연과학·수학",
"age": 71, "education_level": "4년제 대학교",
"marital_status": "배우자있음",
"province": "서울", "district": "서울-서초구"
}
이 두 페르소나가 같은 "예방접종 안내"라는 작업을 받았을 때 만들어 내는 답은 완전히 다르다 — 언어 톤, 추천 채널, 비용 정보, 동반자 안내까지. 그래서 페르소나가 데이터다.
4-5. 한 페르소나의 7가지 결 — 33세 정훈 씨 카드
레코드 한 줄은 단순 표가 아니다. 한 사람을 바라보는 7개의 시점(persona) 이 함께 들어 있다. 발표자료에 등장한 사례 — 퇴근길 동료들과 삼겹살에 소주를 곁들이며 하루의 피로를 푸는 33세 행거루족 정훈 씨 — 의 카드를 보면 이해가 쉽다.
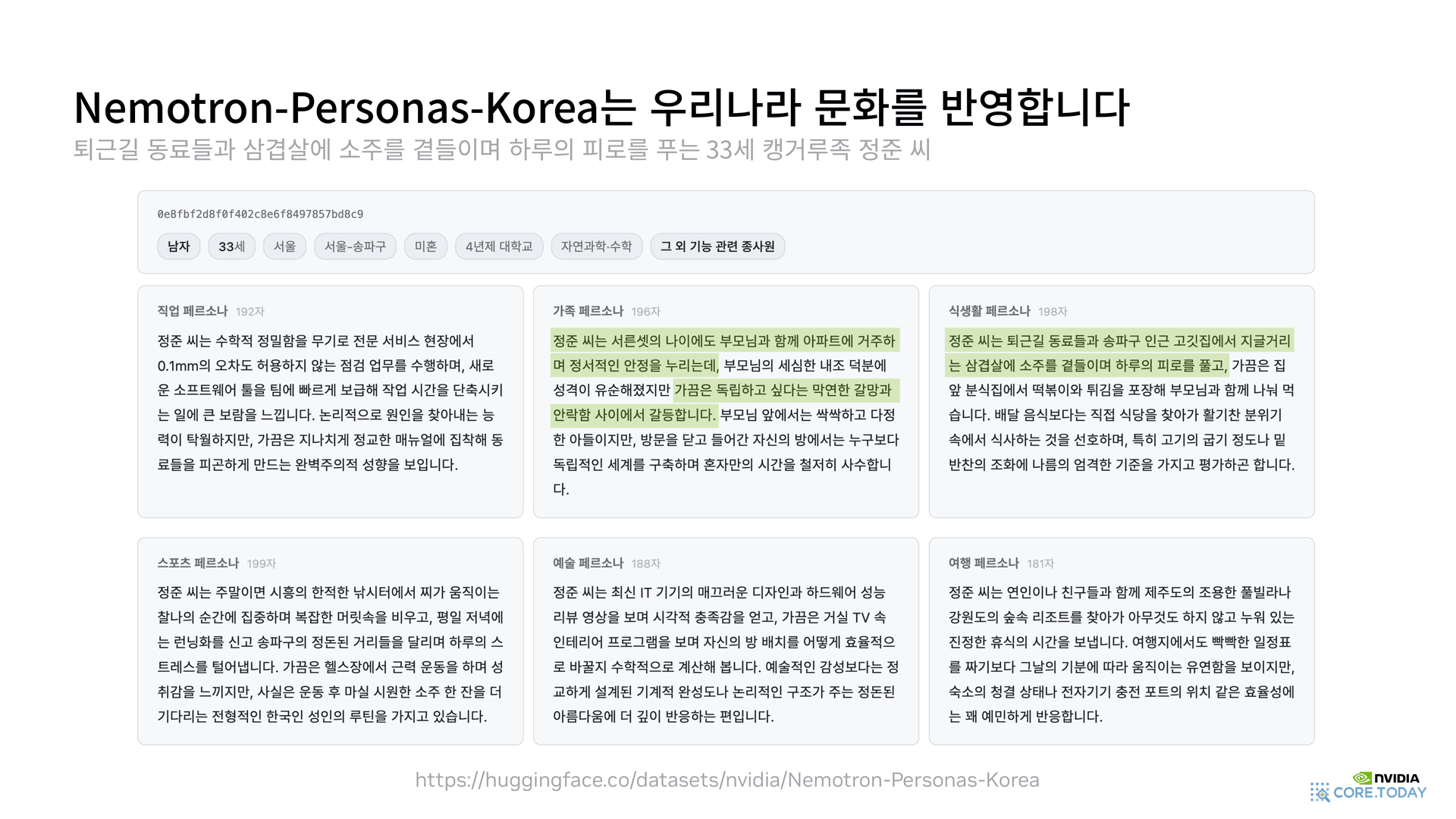
- 직업 페르소나: 수학적 정합성과 기술 전문성의 균형
- 가족 페르소나: 부모와 함께 거주하는 행거루족(캥거루족) 라이프스타일
- 식생활 페르소나: 삼겹살에 소주, 회식과 동료 문화
- 소셜 페르소나: 동료 중심의 강한 유대
- 예술/여행 페르소나: 주말 짧은 여행, 콘서트·전시 취향
- 그 외 기능 관련 종사자 페르소나: 직업 영역 밖의 활동 묘사
같은 한 사람의 데이터지만, 챗봇/에이전트가 어느 시점에서 추론할 것인지에 따라 골라 쓸 수 있게 분리돼 있다. "우리가 알고 있는 우리나라 사람" 의 결을 그대로 옮긴 셈이다.
4-6. 분포가 진짜 한국과 일치하는가 — 4개 차원 비교
PDF 발표에서 제시된 가장 강력한 그림은 LLM-only 합성 vs Nemotron-Personas-Korea의 분포 비교다.
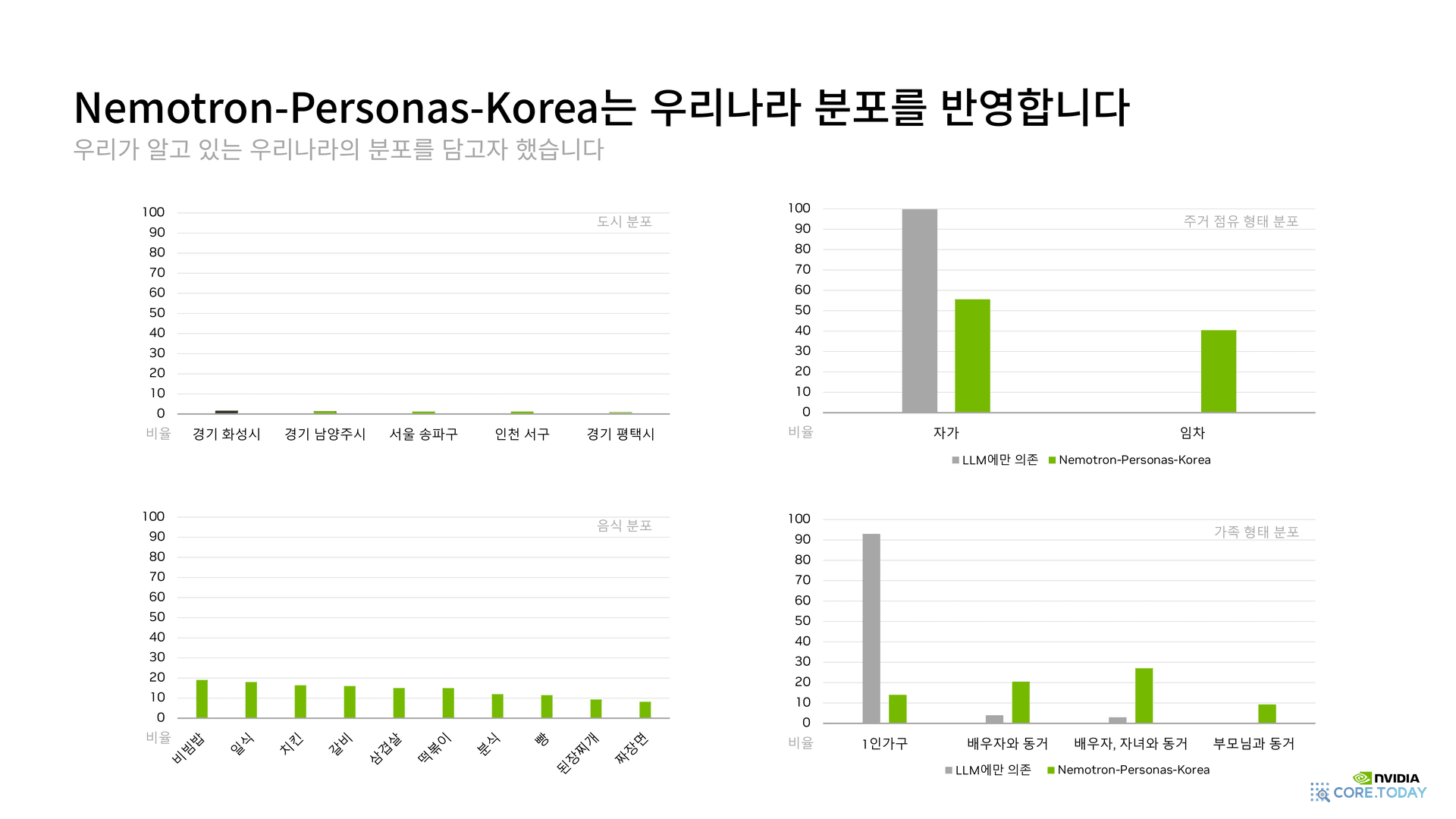
- 도시 분포: LLM-only는 순천·창원에 몰리지만, Nemotron은 252개 시군구 전반에 균등 분포 (경기 화성시·남양주시, 서울 송파구, 인천 서구, 경기 평택시 등 실제 인구 비율 그대로).
- 주거 점유: LLM-only는 자가 100%였지만, Nemotron은 자가 ≈ 60% / 임차 ≈ 40%로 한국 통계와 정합.
- 음식 분포: LLM-only는 샐러드 40%, Nemotron은 비빔밥·일식·치킨·갈비·삼겹살·떡볶이·분식·빵·된장찌개·짜장면 — 실제 식품소비행태조사 분포에 가까움.
- 가족 형태: LLM-only는 1인 가구 90%였지만, Nemotron은 1인 ≈ 12%, 부부 ≈ 23%, 부부+자녀 동거 ≈ 28%, 부모님과 동거 ≈ 11%로 다양하게 분포.
같은 도구(LLM)로 만들었지만, 앞에 PGM이 들어오느냐 마느냐로 결과가 완전히 달라진다.
제5장: 어떻게 만들어졌는가 — PGM + LLM 컴파운드 시스템
5-1. 두 단계 파이프라인
① 실제 통계 (KOSIS·대법원·NHIS·KREI·NAVER Cloud)
↓
② 확률 그래픽 모델 (PGM)
인구·지리·교육·혼인 의존성 인코딩
↓
③ 속성 표본추출
레코드 1건당 12개 인구·지리 필드 생성
↓
④ LLM 확장 (Gemma-2-9B-it / 4-31B-it 계열)
속성을 입력으로 7종 페르소나 자연어 생성
↓
⑤ 검증 단계
Pydantic 구조 검증 + 일관성 체크
↓
⑥ 최종 데이터셋
1M 레코드 × 26 필드, CC BY 4.0 공개
5-2. 세계 최대 규모의 PGM — 42 노드 × 75 엣지 × 10⁴⁶가지 경우의 수
발표자료에서 가장 인상적인 한 장면은 확률 그래프 모델 자체의 규모였다.

- 노드(node): 42개 — 각 노드는 인구·지리·교육·결혼·가구·산업·직업 등 한국 사회를 기술하는 변수에 대응한다.
- 엣지(edge): 75개 — 변수들 사이의 통계적 의존성을 표현한다. 예) 연령 → 결혼 상태 → 가구 형태, 시도 → 산업 분포, 학력 → 직업.
- 경우의 수: 10⁴⁶가지 — 모든 노드의 조합을 곱한 것. 이 숫자가 가지는 의미는 단순하다. 사람 수보다 훨씬 많은 가능 인물의 좌표 공간을 만들어 두고, 그 안에서 실제 한국 통계의 분포에 정합한 표본만 뽑는다는 뜻이다.
PGM이 없는 LLM-only 합성은 결국 모델이 외운 빈도 높은 패턴(유자 농민, 요양보호사)으로 수렴한다. PGM은 그 수렴을 42개 변수의 조건부 분포 위에서 강제로 흩뜨린다. 그래서 분포가 깨지지 않는다.
김현우 박사: "세계 최대 규모의 페르소나 확률 그래프 모형 구축. 그래야 한국 사회의 실제 분포를 그대로 옮겨 담을 수 있습니다."
5-3. 62개의 통계 자료 — 한국 사회를 통째로 입력
KOSIS·대법원·NHIS·KREI·NAVER Cloud의 다섯 출처가 줄기지만, 실제로는 그 밑으로 총 62개의 통계 자료가 PGM에 흘러들어 갔다. 이름·나이·성별·지역·혼인·주거·학력·전공분야·경제활동·산업군·직업군·소득·산업군별 직업군 조합·BMI·여행·여가생활·선호 식당 종류·배달 및 외식 빈도까지 — 우리나라 사회를 거의 '통째로' 입력한 셈이다.
한국적 정합성을 만든 5대 출처 (그 아래 62개 통계 자료)
KOSIS (통계청)
인구·산업·직업·여행·여가 분포
대법원
1940년 이후 이름 전수 데이터
NHIS (건강보험공단)
2024 건강검진·BMI
KREI (농경연)
2024 식품소비행태조사
NAVER Cloud
설계 단계 도메인 자문 + 시드 데이터
5-4. 21만 개의 이름 — 1940년부터의 시간 축
이름 데이터는 가장 미묘한 영역이다. 일반 LLM은 학습에 들어간 이름을 외우다 보니 "82세 김하율 씨"나 "21세 김순자 씨" 같은, 시대 감각에 어긋나는 이름을 자연스럽게 만들어 낸다. 하율은 2010년대 이후 유행한 이름이고, 순자는 1950~60년대 이름이기 때문이다.

NVIDIA가 대법원에서 가져온 데이터는 다르다.
- 우리나라에서 공개된 일반적인 이름 데이터셋은 2008년 이후로만 한정됐다 — 부모가 출생 신고할 때 사용 가능한 한자·한글 이름의 행정 기준이 그때 마련됐기 때문.
- Nemotron-Personas-Korea는 1940년부터의 우리나라 이름 전수 데이터를 기반으로 한 최초의 공개 데이터셋이다.
- 한국에는 약 9만 5천 개의 이름이 있고 (성씨 제외), 가장 흔한 이름은 김영숙·김정숙. 데이터셋에는 약 21만여 개의 이름(성씨 포함)이 들어 있다.
- 결과: 80대 페르소나의 이름과 20대 페르소나의 이름이 서로 다른 시대 감각을 갖는다. 이게 한국 사용자에게는 즉시 느껴지는 자연스러움이다.
시대상을 반영한 보다 사실적인 이름 — 그것이 페르소나가 데이터로 작동하는 이유 중 하나다.
5-5. NeMo Data Designer — 컴파운드 AI 시스템
이 모든 파이프라인은 NVIDIA NeMo Data Designer 라는 컴파운드 AI 시스템 안에서 돌아간다.
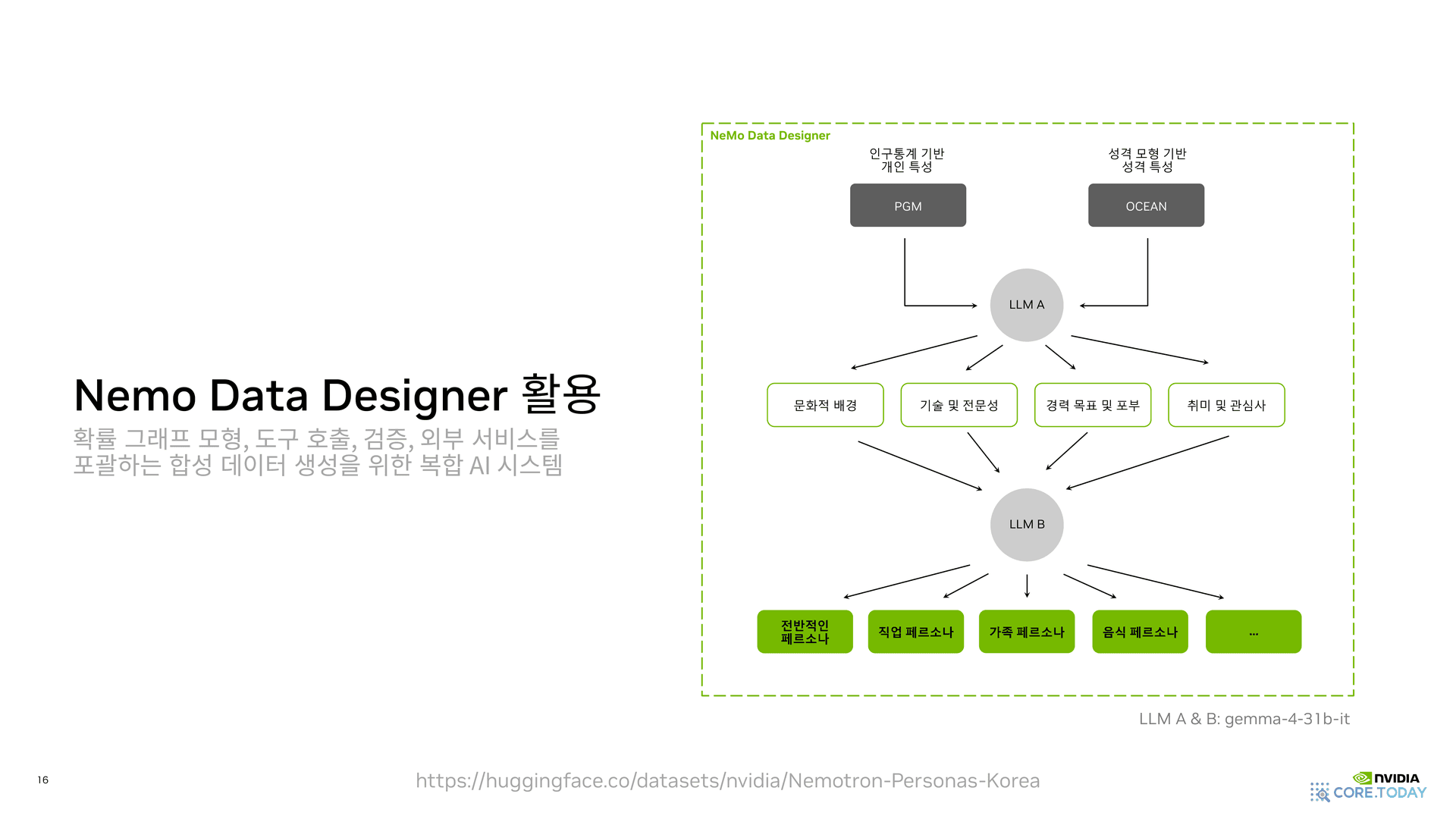
구조를 풀어 보면 4개 모듈로 구성된다.
- PGM (인구통계 기반 개인 특성): 앞서 본 42-node × 75-edge 확률 그래프. 인구·지리·교육·혼인·가구·직업의 조건부 분포에서 표본을 뽑는다.
- OCEAN (성격 모형 기반 성격 특성): 심리학의 5요인 성격 모형(Big Five — Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism). 페르소나에 일관된 성격 결을 부여한다.
- LLM A: PGM과 OCEAN의 출력을 받아 문화적 배경, 기술 및 전문성, 경력 목표 및 포부, 취미 및 관심사를 자연어로 확장한다.
- LLM B: LLM A의 출력을 다시 묶어 전반적인 페르소나, 직업 페르소나, 가족 페르소나, 음식 페르소나 등 7가지 시점별 페르소나를 합성한다.
LLM A·B 모두 gemma-4-31b-it 을 사용한다. 즉, 핵심 성능은 PGM의 분포 정합성에서 나오고, LLM은 그 위에 자연스러운 자연어를 입히는 역할을 분담한다.
hljs language-bash
pip install data-designer
오픈소스로 공개된 도구라, 같은 파이프라인으로 회사 도메인에 특화된 페르소나 데이터셋을 만들 수 있다. 6개월 만에 GitHub 스타가 1.5K를 넘으며 빠르게 채택되고 있다.
5-6. 분포가 진짜처럼 보이는 이유
이 데이터셋에서 가장 인상적인 부분은 분포의 디테일이다.
- 연령 피라미드: 50–64세에 봉우리(약 9%), 70대 이후 여성 비중이 남성의 1.52배(80–89세) — 한국 인구 구조 그대로의 "역항아리" 모양.
- 결혼 상태 변화: 19~24세 95% 미혼 → 30대 55%→31% → 35–50대 60–78% 기혼 → 80세 이상 66%가 사별 → 50대 후반~60대 초반 이혼율 12%로 정점("황혼이혼").
- 교육 격차: 20–34세는 75%가 대학 이상, 80세 이상은 36%가 무학·37%가 초등.
- 가구 형태: 1인 가구가 20대와 75세 이후에 동시에 봉우리. 한부모는 모자(母子) 가구가 부자(父子) 가구의 약 2.5배.
- 이름: 김(21.5%) · 이(14.7%) · 박(8.5%) · 정(4.8%) · 최(4.7%) — 5대 성씨가 54%. 가장 흔한 풀네임은 "김영숙"(실제 통계와 일치).
이 모든 비율이 LLM이 적당히 만든 게 아니라, PGM이 실제 통계로부터 표본을 뽑은 결과다. 그래서 한국 사회 시뮬레이터로서 의미가 있다.
제6장: 사례로 이해하기 — 페르소나가 있을 때와 없을 때
6-1. 사례 1. 보건소 예방접종 상담 챗봇
질문: "독감 예방접종은 언제 맞아야 하나요?"
| 관점 | 페르소나 없음 (범용 모델) | 한국 보건직 페르소나 그라운딩 |
|---|
| 언어 톤 | 영어 직역체 / 어색한 반말 혼용 | 자연스러운 존댓말, 의료 전문 어휘 |
| 추천 기관 | "local clinic을 방문하세요" | "가까운 보건소에서 어르신 무료접종 가능합니다" |
| 정책 인용 | CDC 가이드 | 국가예방접종지원사업(NIP), 65세 이상 무료 안내 |
| 시기 안내 | "가을철" | "매년 9~10월부터 보건소 예약, 11월 본격 접종" |
| 대상자 구분 | 일반론 | 임산부·어르신·소아 분류, 광주광역시 자치구별 보건소 안내 |
6-2. 사례 2. 은행 대출 모델의 공정성 감사
금융업의 가장 큰 공포는 "우리 신용평가 모델이 50대 자영업자나 70대 농촌 거주자에게 차별적인가?" 하는 점이다. 실제 고객 데이터를 그대로 테스트셋으로 쓰면 PIPA 위반 위험이 있다.
🚨
문제
실제 고객의 대출 신청 기록은 가명처리해도 재식별 위험이 남는다. 그렇다고 임의로 합성하면 한국 자영업자 분포(예: 50대 후반 음식·숙박 자영업 비중)가 빠진다.
🛠️
해결
Nemotron-Personas-Korea에서 occupation·age·province 조건으로 1만 건을 추출하고, 각 페르소나에 대해 모델 점수를 받아 분포 차이를 분석한다. PII가 없으므로 사내 누구나 분석 가능.
✅
결과
"60대 이상·비수도권·자영업" 군에서 점수가 평균 7점 낮게 나오는 패턴이 잡힌다 → 피처 엔지니어링·모델 재학습으로 보정 → 외부 감사 보고서에 합성 페르소나 데이터셋 ID와 분포 명시.
6-3. 사례 3. 게임 NPC 다양화 — Krafton의 Raon
Krafton은 자체 파운데이션 모델 Raon을 만들면서 NeMo Curator/Megatron-LM과 함께 페르소나 데이터셋을 활용하고 있다(NVIDIA Nemotron Developer Days Seoul 2026). 게임에서 페르소나가 갖는 의미는 단순한 학습 데이터 이상이다.
Step 1
캐릭터 슬롯 정의 (예: 시장 상인, 의뢰인, 길드 마스터)
Step 2
Nemotron-Personas-Korea에서 직업·연령대 조건으로 페르소나 표본 추출
Step 3
각 NPC에 대화 톤·관심사·가족 배경을 자동 시딩 → 한국 사회를 배경으로 한 게임에서 NPC가 "강원도 산골 출신 50대 어머니" 같은 결을 갖게 됨
Step 4
동일 NPC가 서로 다른 플레이어와 대화하면서도 일관된 정체성 유지
6-4. 사례 4. SK텔레콤 A.X K1 — 519B MoE의 다양성 강화
SKT는 519B 파라미터 MoE 모델 A.X K1의 후속 학습에 Nemotron 계열 데이터와 Megatron-LM/NeMo Curator를 사용한다. 페르소나 데이터의 역할은 분명하다.
- 같은 질문 "주택담보대출 한도가 얼마인가요?"에 대해
- 20대 신혼부부 / 40대 자영업자 / 60대 은퇴 직전 가장의 시점에서 모두 자연스러운 답을 학습
- → 결과: 콜센터, 매장, 모바일 앱 등 멀티 채널에서 답변 일관성 + 사용자 경험 향상
6-5. 사례 5. LG AI Research K-EXAONE — 산업 코파일럿
LG AI Research는 K-EXAONE 계열을 enterprise·industrial AI 모델로 키우는 중이다. 콜 어시스턴트, 사내 코파일럿, 엔지니어링 설계 지원 등에 NeMo와 Megatron-LM을 사용한다. 페르소나가 들어가는 지점:
- "화학 공정 엔지니어 페르소나" + "기계 설비 보전 기술자 페르소나"가 가상의 동료처럼 코파일럿을 학습시킴
- 한국 산업 현장의 호칭(과장님·반장님), 안전 매뉴얼 어법, 보고서 양식 → 모델이 자연스럽게 체득
6-6. 사례 6. NAVER HyperCLOVA X / Motif Technologies
NAVER Cloud는 Nemotron-Personas-Korea 설계 단계부터 시드 데이터와 도메인 자문으로 참여했다. HyperCLOVA X 차세대 버전은 Nemotron 3 Nano 아키텍처와 자체 데이터를 결합하여 내부 검증 중이며, 강화학습 단계에 있다. Motif Technologies는 한국 정부 주권 AI 컨소시엄의 일원으로 LLM/VLM/VLA 멀티모달 모델을 만들면서 NeMo Curator + Nemotron 데이터를 사용한다.
6-7. 사례 7. NVIDIA Nemotron Nano Japanese — Nejumi 리더보드 1위
페르소나 데이터셋이 실제 모델 성능에 얼마나 기여하는지 보여 주는 가장 명확한 증거는 옆 나라에서 나왔다.

- NVIDIA는 같은 페르소나 + 도구(tool set) 조합으로 데이터를 합성하고 학습시킨 결과, Nemotron-Nano-9B-v2-Japanese 가 Nejumi 리더보드(일본어 LLM 종합 평가 벤치마크) 1위를 기록했다.
- 비슷한 방법론은 Nemotron Nano v3 와 Super v3 에도 도입됐다.
- 부수 효과: 모델 안전성도 함께 향상. Sensitive-safety-category-refusals (SSCR) 데이터셋의 시드로 페르소나가 활용되며, SSCR은
nemotron-safety-blend에 포함된다.
같은 방법론을 한국어 모델에도 적용하면, A.X K1·K-EXAONE·HyperCLOVA X·Solar 등이 자국어 벤치마크에서 의미 있는 점수 향상을 거둘 수 있다는 가설이 생긴다. 이미 LG·SKT·NAVER는 이 방향으로 움직이고 있다.
6-8. 사례 8. 헬스케어 — 청소년 정신건강 챗봇
또 하나 흥미로운 사례. 청소년 정신건강 챗봇을 만들 때, 실제 환자 대화 데이터로 학습하는 건 사실상 불가능하다(개인정보·의료법). 페르소나 그라운딩은 다음과 같이 작동한다.
hljs language-python
personas = ds.filter(lambda p: p["age"] >= 19 and "교육" in p["occupation"])
for p in personas.select(range(500)):
prompt = build_counseling_prompt(p)
dialogues += generate_dialogue(prompt, scenario="중학생 시험 스트레스")
이렇게 합성된 대화로 미세조정하면, 챗봇은 한국 학교 환경(중간고사·기말고사·학원·수능), 한국식 가족 호칭(엄마·아빠·할머니), 지역별 학원가 표현을 자연스럽게 다루게 된다.
제7장: 2026 소버린 AI의 그림에서 페르소나의 자리
7-1. 한국의 7,350억 달러 그림
한국 정부의 독자 AI 파운데이션 모델 프로젝트(K-AI / Sovereign AI Foundation Model)는 2025년 시작되어 2026년 6월~12월에 단계별 평가가 진행된다. 5개 컨소시엄에서 LG AI Research·SK Telecom·Upstage가 본선에 진출했고, Motif Technologies가 추가 합류했다. 컨소시엄에는 KAIST, 서울대, 42dot, Rebellions, Liner, SelectStar, Krafton 등이 결합되어 있다.
목표는 분명하다.
- 외산 사전학습 가중치 의존 없이 밑바닥부터(한국 데이터로) 학습
- 데이터 주권 — 한국 데이터가 한국 안에 머물러야 함
- 국산 AI 반도체 활용 (Rebellions 등)
- 2026년 시행 AI 기본법 대응
7-2. 페르소나가 왜 이 그림에 들어맞나
소버린 AI 4대 축에서 페르소나의 위치
컴퓨팅
DGX Spark, Rebellions, 데이터센터
데이터 ⭐
자국어 말뭉치 + 합성 페르소나 + 도메인 데이터
모델
EXAONE, A.X K1, HyperCLOVA X, Solar, Raon
인력
컨소시엄·연구소·스타트업 생태계
핵심은 데이터다. 자국어 말뭉치만으로는 분포가 한쪽으로 기운다. 한국 인터넷의 콘텐츠 생산자 분포는 실제 한국 인구 분포와 다르다 — 청년·수도권·고학력자가 과대 대표된다. 70대 농촌 가구의 시점은 인터넷에 거의 남아 있지 않다.
페르소나 데이터셋은 그 빈자리를 통계적으로 채워 주는 합성 보충재다. 그리고 NVIDIA가 CC BY 4.0으로 공개했기 때문에 KAIST 연구실부터 카카오까지, 누구나 같은 베이스라인 위에서 모델을 만들 수 있다.
7-3. PIPA, AI 기본법, 그리고 합성데이터
한국 개인정보보호위원회(PIPC)는 2024년 12월과 2025년 7월에 걸쳐 개인정보 처리 통합 안내서와 생성형 AI 개발·활용을 위한 개인정보 처리 안내서를 발간했다. 핵심 메시지:
- 가명정보·익명정보·합성데이터(synthetic data) 의 활용 영역을 명시적으로 인정
- 합성 시점에 원본의 식별 가능 영역을 사전 삭제할 것
- 유용성과 안전성의 트레이드오프를 사용 목적에 맞춰 설계할 것
Nemotron-Personas-Korea가 이 가이드라인의 표준 후보가 될 수 있는 이유:
PIPA 합성데이터 요건과 Nemotron-Personas-Korea의 정렬
PII 미포함
UUID 외 식별자 없음
통계적 정합
PGM이 KOSIS 분포에 묶음
사용 목적 명시
학습·평가·레드팀·테스트
상업·비상업 가능
CC BY 4.0
7-4. 한국이 이 데이터셋을 받았다는 것의 의미
NVIDIA가 USA → Japan → India → Singapore → Korea → Brazil → France 순서로 페르소나 시리즈를 풀고 있는 흐름을 보면, 단순한 데이터셋 출시가 아니라 NVIDIA의 소버린 AI 생태계 전략의 한 축이다. 한국이 받았다는 것은:
- NVIDIA가 한국을 글로벌 5대 AI 거점으로 인정한다는 시그널
- NeMo Curator + Megatron-LM + DGX Spark + Personas-Korea의 풀스택 한국 진출
- 한국 기업들이 자체 모델로 글로벌 시장에 진출할 때 쓸 수 있는 표준 페르소나 베이스라인 확보
제8장: 실전 가이드 — 우리 팀이 오늘 시작하려면
8-1. 30초 시작
hljs language-python
from datasets import load_dataset
ds = load_dataset("nvidia/Nemotron-Personas-Korea")
print(ds["train"].column_names)
print(ds["train"][0])
8-2. 도메인별 필터링 패턴
hljs language-python
health = ds["train"].filter(
lambda x: any(k in (x["occupation"] or "")
for k in ["보건", "간호", "의료", "약사"])
)
elder_self = ds["train"].filter(
lambda x: x["age"] >= 60
and x["province"] not in {"서울", "경기", "인천"}
and "자영" in (x["occupation"] or "")
)
8-3. 시스템 프롬프트로 그라운딩하는 정석 패턴
hljs language-python
def to_system_prompt(p):
return f"""당신은 한국의 도메인 전문 AI 에이전트입니다.
[배경 페르소나]
- 지역: {p['province']} {p['district']}
- 연령/성별: {p['age']}세 {p['sex']}
- 직업: {p['occupation']}
- 학력: {p['education_level']}
- 가구 형태: {p['family_type']}
[전문성]
{p['skills_and_expertise']}
[행동 지침]
- 한국어 존댓말로 응답
- 한국 공공·민간 서비스 체계를 우선 인용
- 사용자가 어르신이면 천천히, 짧게, 구체 예시 포함
"""
8-4. 4가지 활용 모드
학습 데이터
페르소나 × 시나리오 조합으로 명령어/대화/문서 합성 → SFT·DPO에 투입
평가·레드팀
같은 질문을 1만 페르소나에 돌려 응답 다양성·안정성 측정
에이전트 그라운딩
시스템 프롬프트에 페르소나 주입 → 톤·맥락 일관 유지
규제 감사
금융·헬스 모델에 합성 페르소나로 분포 차이 시뮬레이션 → 공정성 보고서 첨부
8-5. NeMo Data Designer로 직접 확장
NVIDIA는 데이터셋 생성에 사용한 NeMo Data Designer 를 오픈소스로 공개한다(GitHub: NVIDIA-NeMo/DataDesigner). PGM 정의 + LLM 호출 + Pydantic 검증 + Jinja 템플릿이 통합된 컴파운드 시스템.
같은 도구로 회사 도메인에 특화된 페르소나 변형을 만들 수 있다. 예시:
- 자사 콜센터용 —
province × occupation × 보험 가입상태 조합
- 게임용 —
age × hobbies_and_interests × 지역 방언
- 의료용 —
age × NHIS 만성질환 여부 × 가구 형태
제9장: 한계와 주의점 — 이건 만능이 아니다
9-1. 데이터셋 자체의 한계 (NVIDIA 공식 명시)
1. 독립 가정(Independence Assumption): PGM이 변수 간 상호작용을 모두 모델링하지 않는다. 예) "성별 × 전공 분야"의 한국 특유 패턴은 부분적으로만 잡힘.
2. 성별만 있고 젠더 정체성은 없음: 한국 공공통계가 생물학적 성만 제공하는 한계의 직접 반영.
3. 19세 이상 성인만: 청소년·아동 시나리오에 직접 사용 불가.
4. 2024년 통계 기준: 최근 인구·가구 변화의 빠른 흐름은 시차가 있음.
5. 직업 분류는 광범위: 매우 세분화된 직군(예: 특정 의료 서브스페셜티)은 별도 보강 필요.
6. 이름 우연 일치: 실존 인물과 이름이 우연히 겹칠 수 있음 — 100% 가상.
9-2. 사용자 측의 안티패턴
- "페르소나만 넣으면 모델이 알아서 한국적이 된다" — 아니다. 시스템 프롬프트 설계와 평가셋이 함께 가야 한다.
- "페르소나 데이터로만 학습한다" — 다양성은 좋아지지만 사실 정확도는 별도의 코퍼스가 필요하다.
- "개인 데이터의 대체재" — 페르소나는 가설 검증·평가·다양성 확보용이다. 실제 사용자 행동 로그를 대체할 수는 없다.
9-3. 거버넌스 체크리스트
SYSTEM
합성 데이터를 어떤 모델 학습/평가에 어떤 비율로 썼는지 모델 카드에 명시한다 (PIPC 안내서 권고).
CONTEXT
페르소나 데이터셋 ID, 추출 쿼리, 결합한 다른 데이터 소스를 데이터 시트에 기록한다.
CHECK
실제 사용자 분포와의 차이를 KPI로 추적한다. 합성-실제 분포 격차가 커지면 페르소나 비중을 조정한다.
제10장: 더 큰 그림 — 페르소나는 어디로 가는가
10-1. 페르소나 × 시간 × 도메인
NVIDIA는 USA 시리즈 블로그에서 다음 확장 방향을 명시했다.
- 국제 분포(이미 진행 중) — Korea, Japan, India, Singapore, Brazil, France
- 도메인 변형 —
finance_persona, healthcare_persona 등
- 시간 차원 — 한 페르소나의 시계열적 변화(취직 → 결혼 → 은퇴)
특히 시간 차원은 한국에서 의미가 크다. 30대 직장인 → 40대 자영업자 → 60대 은퇴자로 같은 인물이 이동하는 시계열을 만들면 장기 고객 여정 시뮬레이션, 연금 모델, 건강 예측 모델에 그대로 쓸 수 있다.
10-2. 페르소나는 "AI 사회의 인구 통계"가 된다
조금 멀리서 보면 한 가지 흐름이 보인다. AI 모델은 점점 "사람을 흉내 내는 시스템"이 아니라 "다양한 사람들의 시점을 다루는 시스템"으로 이동한다. 그리고 그 다양성을 통계적으로 기술하는 표준이 합성 페르소나다.
미국 센서스가 사회 통계의 표준 좌표였듯, 앞으로 5년 안에 국가별 페르소나 데이터셋이 AI 모델 평가의 기본 좌표가 될 가능성이 높다. "우리 모델은 Nemotron-Personas-Korea의 1만 표본에서 응답 다양성 0.84, 공정성 격차 ±3% 이내" 같은 카드 명세가 표준이 될 것이다.
10-3. 한국 입장에서의 두 가지 과제
- 데이터셋의 한국화 심화 — NVIDIA가 만든 베이스라인 위에 KAIST·서울대·민간 연구소가 한국 사회의 미세한 결(지역 방언, 세대 갈등, 직군별 호칭)을 보태야 한다. NeMo Data Designer가 오픈소스이기에 가능하다.
- 페르소나 거버넌스의 표준화 — PIPC의 가이드라인을 산업별 적용 표준으로 구체화. 금융·의료·공공 각 분야가 합성 페르소나 사용 보고 양식을 공유하면, 합성 데이터에 대한 사회적 신뢰가 빠르게 형성된다.
마치며: 700만 명의 가상 한국인이 던지는 질문
전기태 씨는 데이터셋 안의 한 줄이지만, 그 한 줄을 통해 우리는 AI 모델이 무엇을 알고 무엇을 모르는지를 점검할 수 있게 됐다. 모델이 광주 서구의 70대 하역 노동자에게 적절한 톤으로 보건소를 안내하지 못한다면, 그건 우리 사회가 만들고 있는 AI에 누가 빠져 있는지 가르쳐 주는 신호다.
소버린 AI는 GPU와 모델만으로 완성되지 않는다. 누구의 시점에서 학습하고 평가할 것인가 — 그 질문에 답하는 통계적 인구 좌표가 필요하다. Nemotron-Personas-Korea는 그 좌표를 처음 그어 준 데이터셋이고, 한국 AI 생태계는 이 위에서 다음 단계를 그릴 수 있게 됐다.
이 글의 한 줄 결론: 모델은 데이터를 닮고, 데이터는 사회를 닮는다. 700만 명의 가상 한국인이 그 사회의 좌표를 다시 그리고 있다.
참고 자료




