#GRPO
6개의 포스트

Thinking Without Words: AI가 단어 없이 생각하는 법 — Abstract Chain-of-Thought 완전 분석
IBM Research가 2026년 4월 발표한 'Thinking Without Words'를 깊이 파헤칩니다. 64개의 정체불명 토큰만으로 추론 토큰을 최대 11.6배 줄이고도 동등한 성능을 내는 비밀, 그리고 그 안에서 자연 언어와 똑같이 떠오른 Zipf의 법칙까지 — 'AI가 말 없이 생각한다'는 명제가 현실이 된 순간을 해부합니다.
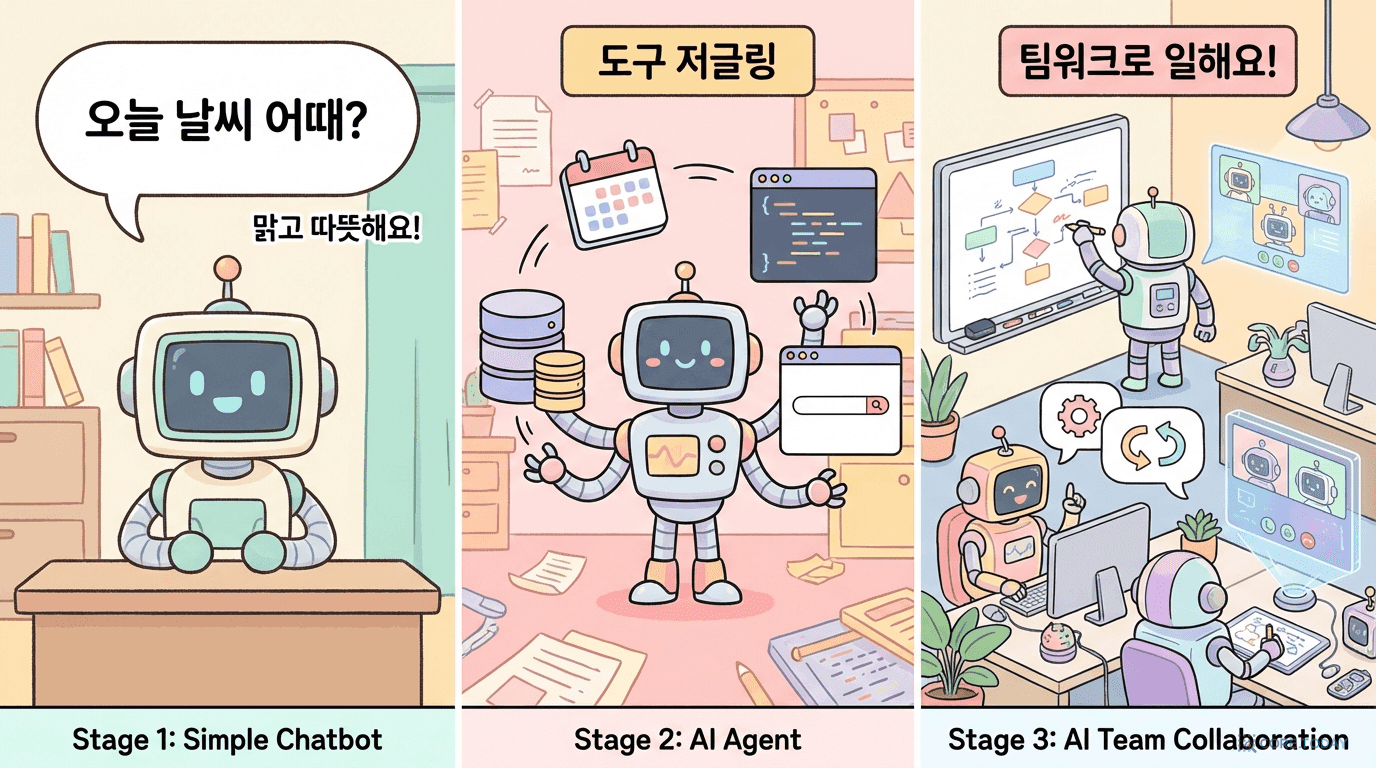
Agent Lightning 완전 가이드 — AI 에이전트를 강화학습으로 훈련시키는 시대가 왔다
Microsoft가 공개한 Agent Lightning은 어떤 AI 에이전트 프레임워크든 강화학습으로 훈련시킬 수 있는 오픈소스 프레임워크다. 왜 에이전트 훈련이 필요한지, 어떤 원리로 작동하는지, 아키텍처의 모든 것을 풍부한 사례와 함께 해부한다.

Vision-R1 특집: AI에게 '눈으로 보고 생각하는 법'을 가르치다 — 과잉사고의 함정부터 점진적 훈련까지
DeepSeek-R1이 텍스트에서 '생각하는 법'을 배웠다면, Vision-R1은 이미지를 보면서 생각하는 법을 배웠다. 하지만 그 과정에서 AI가 '쓸데없이 오래 생각하는' 과잉사고 문제에 빠졌다. ICLR 2026에서 발표된 이 논문이 제시한 점진적 사고 억제 훈련의 원리를, 일러스트와 인터랙티브 요소로 쉽고 깊게 풀어본다.

DAPO 완전 해부: DeepSeek-R1의 비밀을 풀어낸 오픈소스 강화학습의 모든 것
DeepSeek-R1이 강화학습만으로 AI에게 '생각하는 법'을 가르쳤다고 했지만, 핵심 레시피는 비밀이었다. DAPO는 그 비밀을 4가지 기법으로 풀어내고, 절반의 훈련 스텝으로 더 높은 성능을 달성한 뒤 모든 코드를 공개했다. 엔트로피 붕괴부터 동적 샘플링까지, 대규모 RL의 진짜 난관과 해법을 논문 기반으로 풀어본다.

DeepSeek-R1 특집: AI가 스스로 '아하!'를 외친 날 — 강화학습으로 추론 능력을 깨우다
SFT 없이 순수 강화학습만으로 수학 올림피아드 문제를 푸는 AI가 탄생했다. DeepSeek-R1은 OpenAI o1에 필적하는 추론 능력을 5백만 달러로 달성하며, NVIDIA 주가를 17% 폭락시키고, AI 산업의 상식을 뒤흔들었다. 그 안에서 일어난 일을 처음부터 풀어본다.

Nathan Lambert의 RLHF Book 리뷰 — RLHF 전체 지형도를 하나로
ChatGPT를 만든 비밀 무기 RLHF. 그런데 실제로 어떻게 작동하는지 아는 사람은 드물다. AI2의 Nathan Lambert가 쓴 218페이지 무료 교재가 SFT부터 PPO, GRPO, DPO, RLVR, 과최적화, 평가까지 RLHF의 모든 것을 하나로 정리했다. 핵심만 짚어본다.