들어가며: 5백만 달러짜리 지진
2025년 1월 20일, 중국 항저우의 AI 스타트업 DeepSeek이 하나의 논문을 공개했다. 제목: "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning." 제목만 보면 평범한 기술 논문이었다. 강화학습으로 언어 모델의 추론 능력을 향상시켰다는 이야기.

일주일 뒤인 1월 27일 월요일, 미국 증시가 열리자마자 NVIDIA 주가가 17% 폭락했다. 하루 만에 시가총액 5,890억 달러(약 860조 원)가 증발했다. 미국 증시 역사상 단일 기업의 하루 최대 시가총액 손실 기록이었다. Broadcom 17.4%, ASML 6.8%, AMD 6.4% — 반도체 섹터 전체가 피를 흘렸다. S&P 500에서 관련 종목만으로 하루에 1조 달러가 사라졌다.
왜? 중국의 작은 스타트업이 발표한 논문 하나가, 실리콘밸리가 수년간 쌓아올린 서사를 뒤흔들었기 때문이다. 그 서사는 이랬다: "최고 수준의 AI를 만들려면 수십억 달러의 투자, 수만 장의 최첨단 GPU, 수천 명의 연구자가 필요하다." 이 서사 위에 NVIDIA의 주가가 올라가 있었고, Microsoft, Google, Meta의 대규모 데이터센터 투자 계획이 정당화되고 있었다.
DeepSeek-R1이 보여준 현실은 달랐다. OpenAI o1에 필적하는 추론 능력을, 훈련 비용 560만 달러로 달성했다. OpenAI가 GPT-4 학습에 쓴 것으로 추정되는 1억 달러 이상과 비교하면 50분의 1도 안 되는 비용이다. 게다가 모델 가중치를 MIT 라이선스로 완전 공개했다. 누구나 다운로드해서 쓸 수 있다.
하지만 비용 효율성보다 더 놀라운 발견이 논문 안에 숨어 있었다. DeepSeek이 R1-Zero라고 이름 붙인 실험에서, 인간이 만든 예시 데이터(SFT) 없이 순수 강화학습만으로 학습한 모델이 스스로 "잠깐, 다시 생각해보자"라고 말하며 자기 검증을 하는 행동을 보인 것이다. 아무도 그렇게 하라고 가르치지 않았는데 — 보상 신호만으로 이 행동이 창발(emergence)했다.
Marc Andreessen은 이를 두고 이렇게 말했다:
"DeepSeek R1은 내가 본 가장 놀라운, 가장 인상적인 돌파구 중 하나다 — 그것도 오픈소스로서 세계에 대한 심오한 선물이다."
이 글에서는 DeepSeek-R1 논문이 어떤 문제를 풀려 했는지(제1장), R1-Zero에서 무슨 일이 일어났는지(제2장), R1이 어떻게 야생의 추론을 길들였는지(제3장), 이 논문이 산업에 미친 충격(제4장), 그리고 2026년 현재 이 논문을 어떻게 읽어야 하는지(제5장)를 풀어본다.
제1장: AI의 추론 문제 — 왜 "생각하는 AI"가 필요했는가 (2022–2024)
"다음 토큰 예측"의 근본 한계
LLM(대규모 언어 모델)의 학습 목표는 본질적으로 단순하다. "이 문맥 다음에 올 토큰이 뭘까?" GPT-3, GPT-4, Claude, Gemini — 이름이 어떻든 핵심 학습 목표는 같다. 주어진 텍스트의 다음 토큰을 예측하는 것. 이 단순한 목표로 놀라운 일이 벌어졌다. 번역, 요약, 코딩, 시 쓰기, 심지어 법률 자문까지. 하지만 이 능력에는 근본적 한계가 있었다.
다음 토큰 예측은 본질적으로 패턴 매칭이다. "파리는 프랑스의 __"에서 "수도"를 예측하는 것은 추론이 아니라 기억이다. 학습 데이터에서 이 패턴을 수천 번 봤기 때문에 맞추는 것이다. 문제는, 진짜 추론이 필요한 상황에서 드러난다.
수학 올림피아드 문제를 보자. "1부터 100까지의 양의 정수 중에서 3의 배수이면서 5의 배수가 아닌 수의 합을 구하라." 이 문제를 풀려면 여러 단계의 논리적 사고가 필요하다. 3의 배수를 구하고, 15의 배수를 제외하고, 나머지를 더해야 한다. 단순히 "다음에 올 그럴듯한 숫자"를 예측하는 것으로는 정확한 답에 도달할 수 없다.
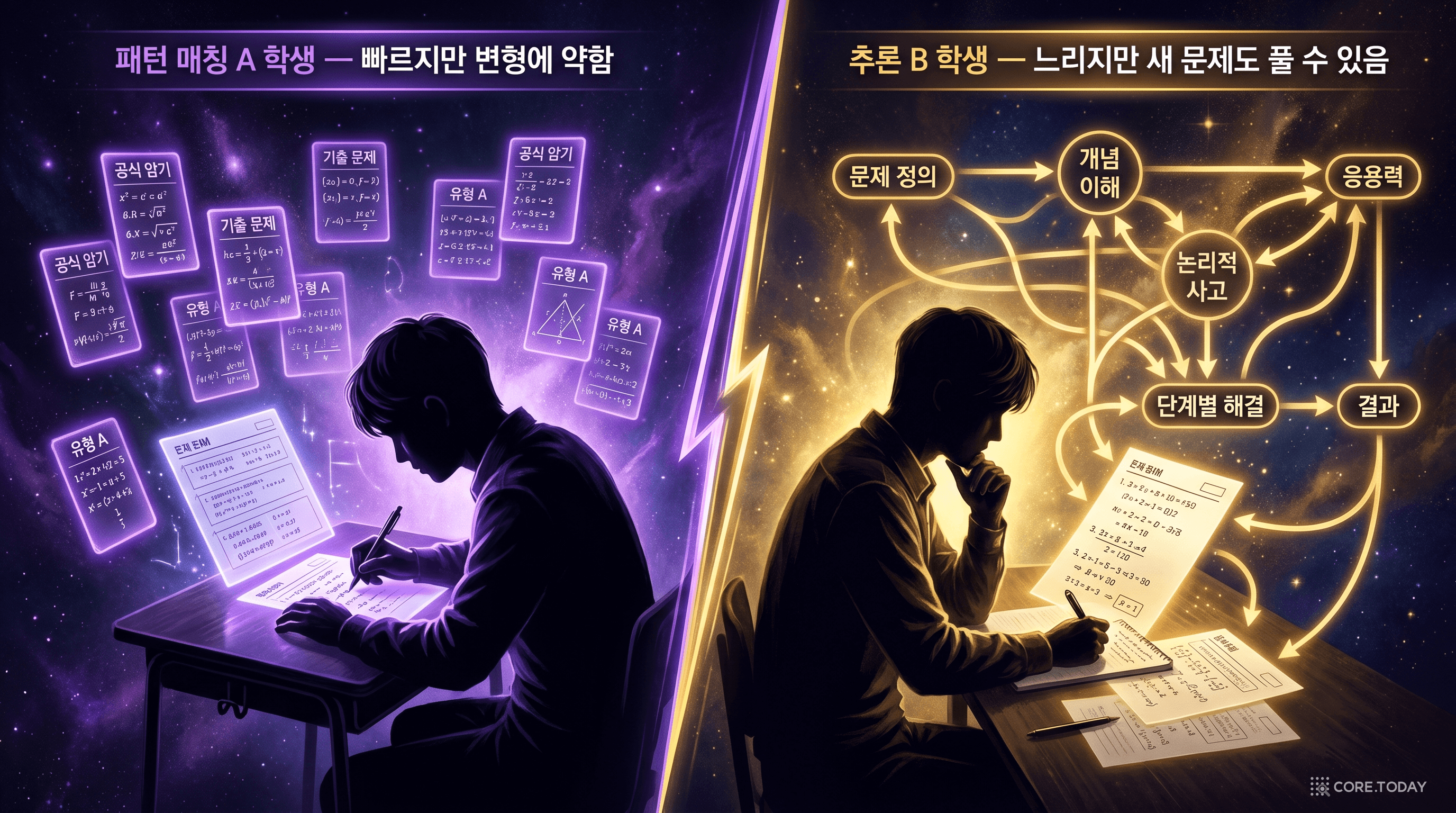
비유하자면 이렇다. 수학 시험에서 두 종류의 학생이 있다. A 학생은 비슷한 문제의 답을 많이 외워서 빠르게 적는다. 익숙한 유형이면 정답률이 높지만, 조금만 변형되면 틀린다. B 학생은 느리지만 풀이 과정을 하나하나 적어가며 푼다. 중간에 실수하면 돌아가서 확인한다. 처음 보는 유형도 풀 수 있다.
기존 LLM은 A 학생이었다. DeepSeek-R1이 만들려 했던 것은 B 학생이다.
Chain-of-Thought: "단계별로 생각해보자"의 발견 (2022)
2022년 1월, Google Brain의 Jason Wei 등이 발표한 "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"는 LLM 연구의 전환점이었다. 핵심 발견은 놀라울 정도로 단순했다.
프롬프트에 "Let's think step by step"(단계별로 생각해보자)이라는 한 줄을 추가하는 것만으로, 수학 문제 정확도가 급등한 것이다. GSM8K(초등학교 수학 문제) 벤치마크에서 PaLM 540B 모델의 정답률이 표준 프롬프팅으로 17.9%에서, Chain-of-Thought(CoT) 프롬프팅으로 56.9%로 뛰었다. 3배가 넘는 향상이다.
왜 이런 일이 일어났을까? LLM은 한 번에 하나의 토큰을 생성한다. 중간 추론 단계를 텍스트로 풀어쓰게 하면, 각 토큰을 생성할 때 이전 추론 과정이 컨텍스트에 포함된다. 모델이 "자기가 쓴 풀이 과정"을 보면서 다음 단계를 결정할 수 있게 되는 것이다. 일종의 외부 작업 기억(external working memory)이다.
하지만 CoT에는 치명적 한계가 있었다. 프롬프트 트릭이라는 것이다. 모델 자체의 능력이 변한 것이 아니라, 입력 형식을 바꿔서 잠재된 능력을 끌어낸 것에 불과했다. 프롬프트를 빼면 원래대로 돌아간다. 모델이 스스로 언제 깊이 생각해야 할지, 어떤 전략으로 접근해야 할지 판단하는 것은 아니었다.
OpenAI o1: 최초의 "추론 모델" (2024.9)
2024년 9월, OpenAI가 o1을 발표했다. 공식 이름은 "OpenAI o1-preview." 이것이 세계 최초의 본격적 추론 모델(reasoning model)이었다.
o1은 기존 LLM과 근본적으로 달랐다. 사용자의 질문을 받으면, 답을 바로 생성하는 것이 아니라 먼저 길고 상세한 내부 사고 과정(chain of thought)을 거쳤다. 수학 문제라면 여러 접근법을 시도하고, 막히면 다른 방향을 탐색하고, 중간 결과를 검증한 뒤에야 최종 답을 내놓았다. 이 과정에서 수백, 때로는 수천 개의 토큰을 "생각"에 사용했다.
결과는 충격적이었다. AIME 2024(미국 수학 올림피아드 예선)에서 o1은 83.3%를 달성했다. GPT-4o의 13.4%와 비교하면 6배 이상의 격차다. 국제 과학 올림피아드(GPQA Diamond)에서는 인간 전문가(PhD 수준)를 넘어섰다.
이것은 단순한 성능 향상이 아니었다. 패러다임의 전환이었다.
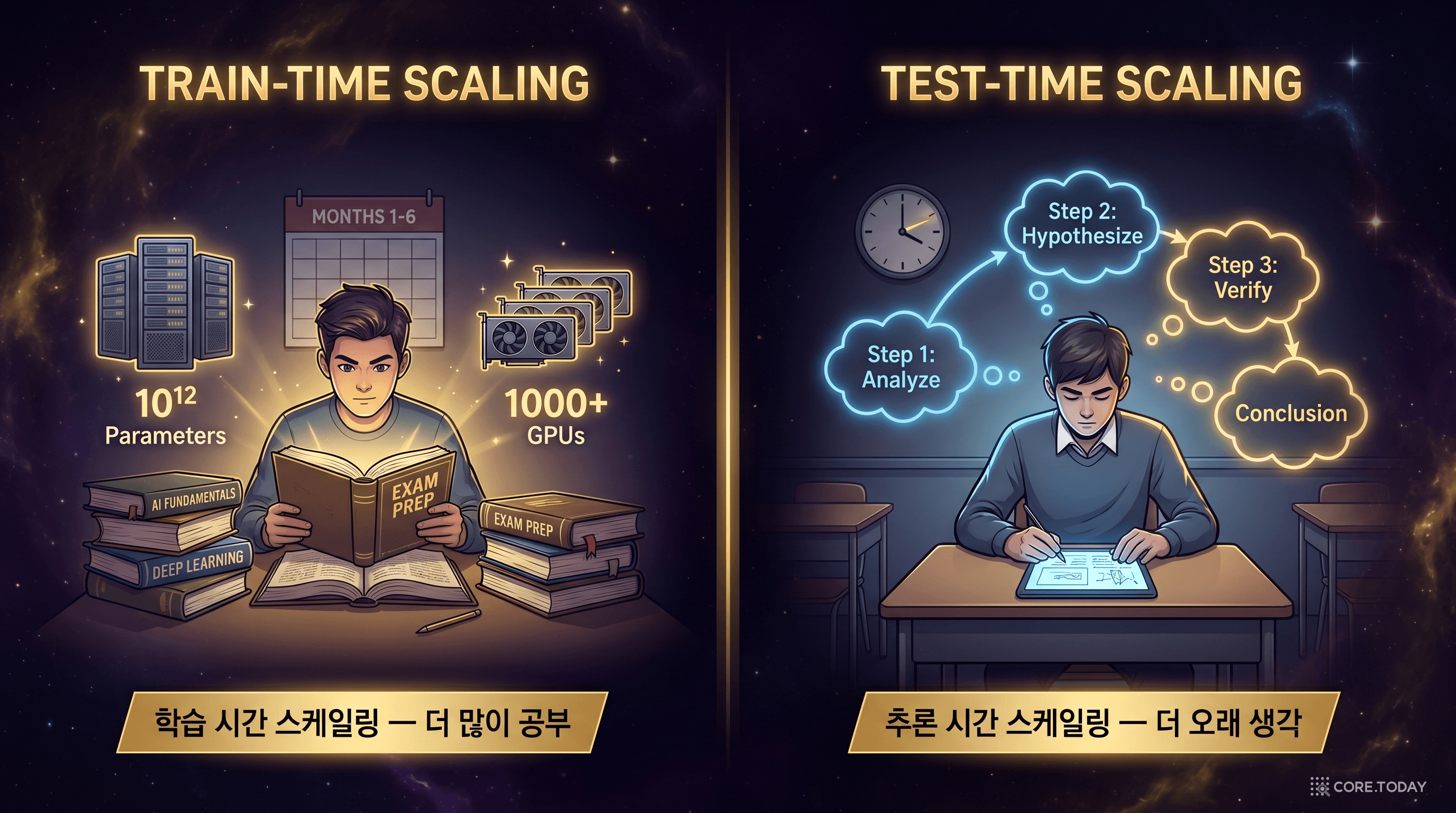
기존 AI 성능 향상의 공식은 "학습 시간 스케일링(train-time scaling)"이었다. 더 많은 데이터, 더 많은 GPU, 더 오래 학습하면 더 좋은 모델이 나온다. o1이 보여준 것은 다른 공식이었다 — "추론 시간 스케일링(test-time scaling)". 학습을 더 많이 하는 대신, 추론할 때 더 오래 생각하게 하면 성능이 올라간다.
비유하자면: "시험에서 더 잘하려면?" — 이전 답은 "더 많이 공부해라(학습 시간 스케일링)"였다. o1의 답은 "시험 시간에 더 오래 생각해라(추론 시간 스케일링)"였다. 두 전략 모두 유효하지만, 후자는 학습 비용을 극적으로 줄일 수 있는 가능성을 열었다.
하지만 o1에는 결정적 문제가 있었다. 폐쇄 모델이라는 것이다. OpenAI는 o1을 어떻게 훈련했는지 공개하지 않았다. 내부 사고 과정도 사용자에게 보여주지 않았다. 학술 커뮤니티와 오픈소스 생태계는 o1이 무엇을 할 수 있는지는 알았지만, 어떻게 그것을 달성했는지는 알 수 없었다.
패턴 매칭
(기존 LLM)
→
CoT 프롬프팅
(Wei et al., 2022)
→
RL 기반 추론 학습
(o1 → R1)
o1의 등장은 AI 커뮤니티에 하나의 질문을 던졌다: "이것을 오픈소스로 재현할 수 있을까?" 2025년 1월, DeepSeek이 그 답을 내놓았다.
제2장: R1-Zero — 감독 없이 추론을 배우다
대담한 실험: "SFT를 건너뛰면 어떻게 될까?"
모든 현대 LLM의 포스트트레이닝은 SFT(Supervised Fine-Tuning)로 시작한다. 인간 전문가가 "이 질문에는 이렇게 답해"라는 시범 데이터를 만들고, 모델이 이를 모방하도록 학습시키는 것이다. InstructGPT 이래로 이것은 거의 의심 없이 받아들여진 표준 절차였다.
DeepSeek은 이 상식에 정면으로 도전했다. "SFT 없이, 사전학습된 기초 모델에 바로 강화학습을 적용하면 어떻게 될까?" 이 질문에 대한 실험이 DeepSeek-R1-Zero다. 인간이 만든 추론 예시 단 하나 없이, 순수하게 보상 신호만으로 모델이 추론을 학습할 수 있는지 시험한 것이다.
베이스 모델: DeepSeek-V3
R1-Zero의 출발점은 DeepSeek-V3-Base다. 이 모델 자체가 상당한 기술적 성취물이다.
- 671B(6,710억) 파라미터 규모의 MoE(Mixture of Experts) 아키텍처
- 각 토큰 처리 시 37B 파라미터만 활성화 — 전체의 약 5.5%
- 14.8T(14.8조) 토큰으로 사전학습
- Multi-Head Latent Attention(MLA)과 DeepSeekMoE 아키텍처 — 메모리와 연산 효율 극대화
- FP8 혼합 정밀도 학습으로 GPU 메모리 추가 절감
- 학습 비용: 약 $5.58M (H800 GPU 2,048장, 약 2개월)
MoE 아키텍처를 비유하자면 이렇다. 대형 종합병원에 671명의 전문의가 있다. 환자가 오면 모든 의사가 동시에 진료하는 것이 아니라, 증상에 맞는 37명의 전문의만 선택적으로 투입된다. 전체 전문성은 유지하면서, 한 번에 투입되는 인력은 최소화하는 것이다.
GRPO: 가치 함수 없는 강화학습
R1-Zero의 핵심 학습 알고리즘은 GRPO(Group Relative Policy Optimization)다. DeepSeek이 2024년 DeepSeekMath 논문에서 처음 도입한 이 알고리즘은, 기존 강화학습의 가장 비싼 부분을 제거한다.
기존 PPO(Proximal Policy Optimization)의 구조를 먼저 보자.
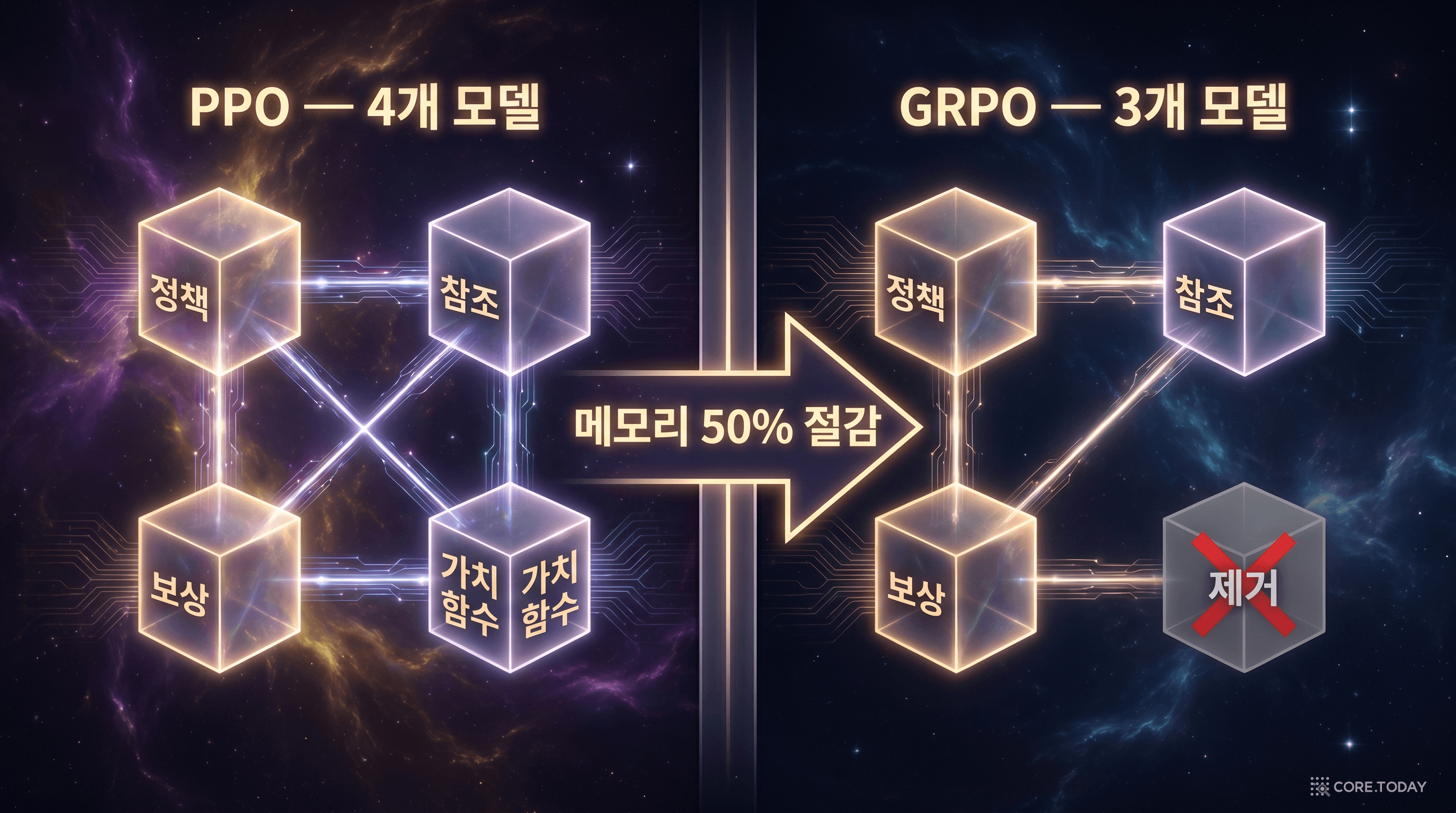
PPO vs GRPO — 구조 비교
PPO (4개 모델)
정책 모델 + 참조 모델 + 보상 모델 + 가치 함수(Critic)
GRPO (3개 모델)
정책 모델 + 참조 모델 + 보상 모델 (가치 함수 제거!)
PPO에서 가치 함수(critic model)는 "이 상태에서 앞으로 얼마나 보상을 받을 수 있을지" 예측하는 모델이다. 이 예측값을 기준선(baseline)으로 사용하여, 실제 보상이 기대보다 높았는지 낮았는지를 판단한다. 문제는 이 가치 함수 모델이 정책 모델과 같은 크기여야 한다는 것이다. 671B 모델의 PPO 학습이라면, 가치 함수만으로 추가 671B 파라미터 분의 메모리가 필요하다. 실질적으로 GPU 메모리 요구량이 거의 2배가 되는 셈이다.
GRPO는 이 가치 함수를 완전히 제거한다. 대신, 다음과 같은 방식으로 기준선을 계산한다:
- 하나의 프롬프트(문제)에 대해 G개의 답변을 동시에 샘플링한다 (논문에서 G는 보통 64)
- 각 답변에 보상 점수 ri를 매긴다
- 그룹 내 평균과 표준편차를 구하여 상대적 advantage를 계산한다:
Ai=std(r1,…,rG)ri−mean(r1,…,rG)
비유하자면 이렇다. 교사가 학생 10명에게 같은 수학 문제를 풀게 한다. 별도의 채점 기준표를 만드는 대신, 10명의 점수를 비교한다. 평균보다 잘한 학생은 칭찬(positive advantage)하고, 평균보다 못한 학생은 개선하라(negative advantage)고 한다. 외부 기준이 아니라, 그룹 내 상대 비교로 "잘했다/못했다"를 판단하는 것이다. 별도의 "예상 점수 계산기"(가치 함수)가 필요 없다.
이 설계의 실질적 이점은 명확하다. 메모리 약 50% 절감, 그에 따른 학습 속도 향상, 하이퍼파라미터 간소화. 671B 규모의 모델에 RL을 적용하는 것을 실현 가능하게 만든 핵심 기술이다.

보상 설계: 극단적 단순함
R1-Zero의 보상 설계는 놀라울 정도로 단순하다. 두 종류의 보상만 사용했다.
1. 정확도 보상(Accuracy Reward). 수학 문제의 정답을 맞혔는가? 맞으면 보상, 틀리면 패널티. 그것뿐이다. LeetCode 같은 코딩 문제에서는 테스트 케이스 통과 여부로 판정했다. 인간 피드백 없음. 학습된 보상 모델 없음. 답이 맞는지 틀린지만 확인한다.
2. 형식 보상(Format Reward). 모델의 출력이 지정된 형식(추론 과정을 <think>...</think> 태그 안에, 최종 답을 그 밖에 쓰는 것)을 따르는지 확인한다. 형식에 맞으면 소량의 보상을 준다.
이것이 전부다. "이렇게 추론해라", "이런 전략을 써라", "막히면 다시 생각해라" 같은 지시는 일절 없다. 오직 "맞았냐 틀렸냐"만 알려준다.
R1-Zero의 놀라운 결과
R1-Zero의 성능 진화를 보자. 학습이 진행되면서 AIME 2024(미국 수학 올림피아드 예선, 30문제) 성능이 어떻게 변했는가:
R1-Zero AIME 2024 정답률 — 학습 진행에 따른 변화
RL 완료 (consensus@64)
86.7%
15.6%에서 71.0%로 — 4.5배 이상의 향상이다. consensus@64(64개 답변을 생성해서 다수결로 답을 선택하는 방식)에서는 86.7%를 달성했다. 이것은 OpenAI o1-0912의 79.2%를 넘어서는 수치다.
SFT 없이, 인간이 만든 추론 예시 없이, 순수 RL만으로. 이 결과만으로도 충분히 놀랍다. 하지만 정말 놀라운 것은 숫자가 아니었다.
"아하!" 순간: 아무도 가르치지 않은 행동
DeepSeek 연구팀은 R1-Zero의 학습 중간 체크포인트들을 분석했다. 그러다 예상치 못한 행동을 발견했다. 모델이 어려운 문제에서 막혔을 때, 스스로 멈추고 다른 접근법을 시도하는 모습을 보인 것이다.
논문에서 인용한 R1-Zero의 실제 출력:
"Wait, wait. Let me reconsider. ... Hmm, I think I need to approach this differently..."
("잠깐, 잠깐. 다시 생각해보자. ... 음, 다른 방식으로 접근해야 할 것 같다...")
이것이 왜 놀라운가? 아무도 모델에게 "막히면 다시 생각하라"고 가르치지 않았기 때문이다. SFT 데이터에 "잠깐, 다시 생각해보자"라는 예시가 포함되어 있지 않았다. 보상 함수에 "자기 검증을 하면 추가 보상"이라는 규칙도 없었다. 모델은 오직 "정답이면 보상, 오답이면 패널티"라는 신호만 받았다.
그런데 모델은 학습하는 과정에서, "한 번에 답을 내놓는 것보다 중간에 멈추고 검증하는 것이 정답률을 높인다"는 사실을 스스로 발견한 것이다. 이 행동이 더 높은 보상으로 이어졌기 때문에, 강화학습의 자연스러운 최적화 과정에서 이 전략이 강화되었다.

DeepSeek 논문은 이것을 모델의 "아하! 순간(aha moment)"이라고 불렀다. 학습이 진행되면서 모델의 응답 길이가 점점 길어진 것도 관찰되었다. 모델이 더 많은 토큰을 "생각"에 할애하게 된 것이다 — 아무도 "길게 생각하라"고 지시하지 않았는데. 보상 최적화의 결과로, 더 많이 생각하는 전략이 자연적으로 선택된 것이다.
💡
창발(Emergence)이란: 시스템의 개별 구성 요소에는 없는 행동이 시스템 전체 수준에서 나타나는 현상이다. 개미 한 마리는 단순한 규칙만 따르지만, 개미 군집 전체는 복잡한 구조물을 짓고 농사까지 짓는다. R1-Zero에서 관찰된 자기 검증 행동은 — 보상 규칙에 명시되지 않았음에도 학습 과정에서 나타났다는 점에서 — 이러한 창발의 한 사례로 해석된다.
R1-Zero의 한계: 야생의 추론
하지만 R1-Zero는 완벽하지 않았다. 인간의 지도 없이 야생에서 자란 추론 능력에는 세 가지 심각한 문제가 있었다.
1. 언어 혼합(Language Mixing). 한 문장 안에서 영어와 중국어가 섞이는 현상이 빈번했다. "Let's calculate 이 문제의 답은..." 같은 식이다. 기초 모델이 다국어 데이터로 학습되었기 때문에, RL 과정에서 언어 경계가 무너진 것이다.
2. 가독성 부족. 추론 과정이 사람이 읽기 어려운 형태로 나왔다. 논리적 단계가 뒤섞이고, 같은 내용을 다른 표현으로 반복하고, 구조화되지 않은 흐름이 이어졌다. "정답을 맞히는 능력"은 있지만, "읽기 쉽게 설명하는 능력"은 학습되지 않은 것이다 — 당연하다, 보상 함수에 가독성 기준이 없었으니까.
3. 반복 루프. 같은 추론 단계를 끝없이 반복하는 현상이 관찰됐다. 모델이 "더 많이 생각하면 보상이 올라간다"는 것을 학습했지만, "언제 멈춰야 하는지"는 학습하지 못한 것이다.
R1-Zero는 야생에서 자란 천재 같았다. 놀라운 능력이 있지만, 말이 통하지 않고, 예의가 없고, 장황하다. DeepSeek의 다음 과제는 이 야생의 추론 능력을 길들이는 것이었다.
제3장: DeepSeek-R1 — 야생의 추론을 길들이다
4단계 파이프라인: 야생과 문명의 조합
R1-Zero의 실험이 증명한 것은 명확했다: 순수 RL만으로도 추론 능력은 창발한다. 하지만 실용적인 AI 모델을 만들려면 가독성, 언어 일관성, 범용성도 필요하다. DeepSeek-R1은 이 문제를 4단계 파이프라인으로 해결했다.

1. Cold-Start SFT
→
2. 추론 특화 RL
↓
3. 거부 샘플링 + SFT
→
4. 범용 RL
Stage 1: Cold-Start SFT — 문명의 씨앗
R1-Zero의 가장 큰 문제는 출력의 가독성이었다. 이를 해결하기 위해, DeepSeek은 먼저 수천 개의 장문 Chain-of-Thought 예시를 수집했다. 이 데이터에는 명확한 형식이 있었다: <think> 태그 안에 추론 과정을 단계별로 서술하고, 태그 밖에 최종 답변을 제시하는 구조.
이 Cold-Start SFT 데이터로 V3-Base를 미세조정하여, RL의 출발점을 만들었다. R1-Zero가 빈 들판에서 시작한 것과 달리, R1의 RL은 이미 "읽기 쉬운 추론 형식"을 아는 모델에서 시작한 것이다. 비유하자면, 야생에서 자란 아이에게 글자를 가르친 뒤 학교에 보내는 것이다. 학교에서 배울 내용(수학, 과학)은 같지만, 글을 읽고 쓸 줄 아는 상태로 시작하면 학습 효율이 전혀 다르다.
Stage 2: 추론 특화 RL — 깊은 사고의 학습
Cold-Start SFT 모델 위에 GRPO 강화학습을 적용했다. R1-Zero와 같은 알고리즘이지만, 보상 설계에 핵심 차이가 있었다.
R1-Zero는 정확도 보상과 형식 보상만 사용했다. R1의 2단계 RL에서는 여기에 언어 일관성 보상을 추가했다. 응답에서 영어와 중국어가 섞이면 패널티를 주는 규칙이다. 이 단순한 추가만으로 R1-Zero의 가장 큰 문제 중 하나였던 언어 혼합이 극적으로 감소했다.
학습 대상 과제도 명확했다: 수학 문제, 코딩 과제, 논리 퍼즐 — 정답이 객관적으로 검증 가능한 과제에 집중했다. 에세이 쓰기나 대화 같은 "정답이 없는" 과제는 이 단계에서 다루지 않았다.
Stage 3: 거부 샘플링 + SFT — 최고의 답만 골라 다시 배우기
2단계에서 RL로 학습된 모델은 이제 상당히 강력한 추론 능력을 가지고 있다. 하지만 이 모델의 출력은 여전히 RL 특유의 거칠음이 남아 있다. 3단계에서 DeepSeek은 독창적인 전략을 사용했다.
2단계 RL 모델에게 대량의 문제를 풀게 하고, 정답인 답변만 수집한다. 이것이 거부 샘플링(Rejection Sampling)이다. 하나의 문제에 여러 답변을 생성하게 하고, 틀린 답변은 "거부"하고 맞은 답변만 "수락"한다. 이렇게 약 60만 개의 고품질 추론 샘플을 확보했다.
여기에 비추론 과제(일반 대화, 글쓰기, 번역 등)의 데이터 약 20만 개를 추가했다. 이 비추론 데이터는 DeepSeek-V3의 파이프라인에서 가져온 것이다.
총 80만 개의 데이터로 V3-Base 모델을 처음부터 다시 SFT했다. 왜 2단계 RL 모델을 계속 학습하지 않고, 기초 모델로 돌아가서 다시 시작할까? RL 학습 과정에서 모델 분포가 변형되면서 생기는 분포 이동(distribution drift) 문제를 리셋하기 위해서다. 깨끗한 기초 모델 위에, 가장 좋은 추론 데이터만 올리는 것이다.
Stage 4: 범용 RL — 마지막 다듬기
3단계에서 만든 SFT 모델에 2차 RL을 적용한다. 이번에는 두 종류의 과제를 모두 다룬다.
- 추론 과제(수학, 코드): R1-Zero/2단계와 같은 규칙 기반 보상 (정답 여부 확인)
- 일반 과제(대화, 글쓰기): 선호 보상 모델(Reward Model) 기반 보상
이 2차 RL이 최종 모델에 범용성을 부여한다. 수학과 코딩에서의 추론 능력을 유지하면서, 일반적인 대화에서도 유용하고 안전한 응답을 하도록 정렬하는 것이다.
DeepSeek-R1 벤치마크: o1과의 정면 대결
완성된 DeepSeek-R1의 성능을 OpenAI o1-1217(2024년 12월 출시된 o1 정식 버전)과 비교하자.
DeepSeek-R1 vs OpenAI o1-1217 — 주요 벤치마크
결과를 요약하면:
- AIME 2024: R1 79.8% vs o1 79.2% — R1 승리
- MATH-500: R1 97.3% vs o1 96.4% — R1 승리
- Codeforces: R1 2029 Elo vs o1 2061 Elo — 거의 동등
- SWE-bench Verified: R1 49.2% vs o1 48.9% — R1 승리
- GPQA Diamond: R1 71.5% vs o1 75.7% — o1 승리
수학과 코딩에서 o1과 동등하거나 약간 앞서고, 과학(GPQA)에서는 약간 뒤진다. 전체적으로 OpenAI o1에 필적하는 성능이다.
훈련 비용: 5백만 달러의 충격
이 성능을 달성하는 데 든 비용은 얼마였을까?
- V3 베이스 모델 사전학습: $5.58M (H800 GPU 2,048장 x ~2개월)
- R1 RL 학습: $294K (추정)
- 총 약 $5.6M
OpenAI GPT-4의 학습 비용은 공식적으로 공개되지 않았지만, $100M 이상으로 추정된다. o1의 학습 비용도 비공개다. DeepSeek-R1이 약 20분의 1의 비용으로 동등한 추론 성능을 달성한 것이다.
물론 이 비교에는 뉘앙스가 있다. $5.6M에는 연구 과정에서의 실험 비용, 실패한 시도들의 비용, 인건비 등은 포함되어 있지 않다. 하지만 최종 학습 실행의 직접 컴퓨팅 비용만으로 비교해도, 그 격차는 충분히 충격적이다.
증류: 추론 능력의 민주화
DeepSeek-R1의 또 다른 혁신은 증류(Distillation)다. 671B 파라미터의 거대한 R1 모델이 생성한 추론 데이터를 사용하여, 훨씬 작은 모델들도 추론 능력을 갖추게 한 것이다.
DeepSeek은 6개의 증류 모델을 오픈소스로 공개했다: Qwen 계열의 1.5B, 7B, 14B, 32B와 Llama 계열의 8B, 70B.
결과는 놀라웠다:
- R1-Distill-Qwen-32B가 OpenAI o1-mini를 추월 (AIME: 72.6% vs 63.6%)
- R1-Distill-Qwen-7B (AIME 55.5%)가 QwQ-32B-Preview (50.0%)를 추월 — 4.5배 작은 모델이 큰 모델을 이겼다
- 심지어 1.5B 모델(R1-Distill-Qwen-1.5B)도 AIME에서 28.9%를 달성 — GPT-4o(13.4%)의 2배 이상
이것이 의미하는 바는 크다. 스마트폰이나 엣지 디바이스에서 돌아갈 수 있는 소형 모델에도 본격적인 추론 능력을 부여할 수 있다는 것이다.

오픈소스: MIT 라이선스의 힘
DeepSeek-R1과 6개 증류 모델은 모두 MIT 라이선스로 공개되었다. 상업적 사용에 제한이 없다. 발표 한 달 만에 HuggingFace에서 700개 이상의 파생 모델이 생겨났고, 500만 건 이상의 다운로드가 발생했다. 오픈소스 AI 역사상 가장 빠른 확산 속도 중 하나다.
이것이 NVIDIA 주가를 폭락시킨 핵심이다. "최첨단 AI는 수십억 달러와 수만 장의 최신 GPU가 필요하다"는 서사가 무너지면, NVIDIA의 프리미엄 GPU에 대한 수요 전망도 흔들린다. R1은 "GPU 2,048장으로 2개월이면 충분하다"는 것을 보여줬고, 증류 모델들은 "추론 시에는 작은 모델로도 된다"는 것을 보여줬다.

제4장: DeepSeek-R1이 바꾼 것들
산업 충격: "수십억 달러" 서사의 균열
R1이 AI 산업에 미친 충격은 단순한 벤치마크 경쟁을 넘어선다. AI 개발의 경제학에 대한 근본적 질문을 던졌기 때문이다.
NVIDIA 시가총액 $589B 증발은 상징적 사건이었다. 시장은 이렇게 읽었다: "최첨단 AI를 만드는 데 H100/H200 수만 장이 필요하지 않을 수 있다면, NVIDIA의 매출 성장 전망이 흔들린다." 물론 이것은 과잉 반응이었다 — NVIDIA 주가는 이후 상당 부분 회복되었고, AI 인프라 수요는 여전히 강력하다. 하지만 "효율적 AI 개발"이라는 가능성이 시장의 레이더에 올라온 것은 돌이킬 수 없었다.
R1 발표 전 — AI 산업의 상식
최첨단 모델 = 수십억 달러 투자
추론 모델 = OpenAI만 가능 (폐쇄)
모델 크기 = 성능의 핵심 변수
오픈소스 모델 = 프론티어에 2세대 뒤처짐
GPU 수 = AI 능력의 대리 지표
R1 발표 후 — 새로운 현실
$5.6M로 프론티어급 모델 가능
추론 모델 = 오픈소스로 재현 가능
학습 효율 = 새로운 핵심 변수
오픈소스 모델 = 프론티어와 동등
알고리즘 혁신 = GPU 수보다 중요할 수 있음
"추론 모델" 경쟁의 촉발
R1 발표 이후, 모든 주요 AI 연구소가 추론 모델 경쟁에 뛰어들었다. R1이 "이것이 가능하다"를 증명하자, "우리도 해야 한다"가 된 것이다.
OpenAI o3/o4-mini (2025.4). R1 발표 3개월 후, OpenAI는 o3와 경량 버전 o4-mini를 발표했다. o3는 o1 대비 추론 능력을 대폭 강화했고, o4-mini는 비용 효율에 초점을 맞췄다. R1의 가격 경쟁력에 대한 직접적 대응이었다.
Anthropic Claude 3.7 Sonnet (2025.2). Anthropic은 독자적 접근법을 택했다. Claude 3.7 Sonnet은 최초의 "하이브리드 추론 모델"이다. 사용자가 확장 사고(extended thinking)를 켜고 끌 수 있다. 간단한 질문에는 즉답하고, 복잡한 문제에는 깊이 생각하는 — 두 모드를 하나의 모델에서 전환할 수 있게 한 것이다. "모든 질문에 20초씩 생각하는 것은 비효율적"이라는 현실적 문제에 대한 해법이었다.
Google Gemini 2.5 Pro (2025.3). Google은 Gemini 2.5 Pro에 "사고(thinking)" 기능을 내장했다. 수학, 과학, 코딩 영역에서 새로운 SOTA를 달성했다. 특히 100만 토큰의 긴 컨텍스트 윈도우와 추론 능력의 결합은 다른 추론 모델들이 아직 따라잡지 못한 강점이었다.
Meta의 "패닉 모드". R1이 오픈소스 진영에서 튀어나오자, Meta는 더 큰 압박을 받았다. Mark Zuckerberg가 2025년 AI 자본 투자를 $65-72B로 대폭 확대한다고 발표했다. Llama 4는 예정보다 조기에 출시되었다. "오픈소스 AI의 리더"를 자처해온 Meta가, 중국 스타트업에 오픈소스 추론 모델의 주도권을 빼앗길 수 없다는 위기감이 작용했다.
오픈소스 추론 모델 생태계의 폭발
R1의 가장 큰 유산은 벤치마크 기록이 아니라, 오픈소스 추론 모델 생태계의 폭발이다.
Open-R1 (HuggingFace). R1의 학습 파이프라인을 완전히 재현하려는 오픈소스 프로젝트다. 모델 가중치뿐 아니라 학습 코드, 데이터 파이프라인, 보상 함수 설계까지 투명하게 공개하는 것을 목표로 한다. R1 논문이 "무엇을" 했는지 알려줬다면, Open-R1은 "어떻게" 재현하는지를 보여주려는 프로젝트다.
Sky-T1 (UC 버클리). 대학 연구실에서 단 $450의 비용으로 o1-mini급 추론 모델을 학습한 프로젝트다. R1의 GRPO와 유사한 접근법을 사용하되, 더 작은 모델과 더 적은 데이터로 달성했다. "추론 모델 학습이 대형 연구소의 전유물이 아니다"를 상징적으로 보여준 사례다.
Nature 게재 (2025.9). R1은 오픈소스 LLM 최초로 Nature에 독립 피어리뷰를 거쳐 게재되었다. 이것은 단순한 학술적 인정을 넘어, 오픈소스 AI 연구의 과학적 엄격성이 최고 수준의 학술지 기준을 통과할 수 있음을 증명한 이정표다.
RLVR의 부상: 검증 가능한 보상의 시대
R1이 촉발한 가장 중요한 기술적 트렌드는 RLVR(Reinforcement Learning from Verifiable Rewards)의 부상이다.
기존 RLHF는 인간이 "어떤 답이 더 좋다"고 판단한 선호 데이터로 보상 모델을 학습했다. DPO는 보상 모델을 정책 모델에 흡수했다. R1의 GRPO+RLVR은 완전히 다른 접근을 취한다: 자동 검증기(verifier)로 보상을 계산한다.
- 수학 문제: 답이 맞는지 확인 — 검증 가능
- 코드 문제: 테스트 케이스를 통과하는지 확인 — 검증 가능
- 형식 논리: 결론이 전제에서 유효하게 도출되는지 확인 — 검증 가능
이런 "정답이 있는" 과제에서는 인간의 주관적 판단보다 자동 검증이 더 정확하고, 더 빠르고, 더 저렴하다. RLVR은 R1 이후 빠르게 표준으로 자리잡았고, 수학과 코드를 넘어 의학(진단 정확도), 과학(실험 설계), 법률(판례 적용) 등 "검증 가능한 정답"이 존재하는 모든 영역으로 확장 중이다.
💡
RLHF → DPO → RLVR — 보상 신호의 진화: RLHF는 인간이 만든 선호 데이터로 보상 모델을 학습했다 (비싸고 주관적). DPO는 보상 모델을 제거하고 선호 데이터로 직접 학습했다 (간결하지만 여전히 인간 의존). RLVR은 인간을 아예 빼고 자동 검증으로 보상을 계산한다 (저렴하고 객관적, 단 검증 가능한 과제에 한정). 각 단계가 보상 신호에서 인간의 개입을 줄이는 방향으로 진화했다.
제5장: 2026년 관점 — DeepSeek-R1을 어떻게 읽을 것인가
검증된 것들
2026년 3월 현재, R1이 남긴 과학적, 산업적 발견 중 확실하게 검증된 것들이 있다.
첫째, RL만으로 추론 능력이 창발할 수 있다. R1-Zero의 실험은 이것을 명확하게 보여주었다. SFT 없이, 인간이 만든 추론 예시 없이, 보상 신호만으로 모델이 자기 검증, 문제 재접근, 단계적 추론 같은 고차원 행동을 학습했다. 이것은 DeepSeek-R1 논문의 가장 중요한 과학적 기여다. "LLM 안에 추론 능력의 씨앗이 있고, RL이 그것을 깨운다"는 것을 실증한 것이다.
둘째, 추론 모델은 "더 오래 생각하면 더 잘한다." Test-time compute scaling — 추론 시간에 더 많은 연산을 투입하면 성능이 올라간다 — 은 이제 확립된 패턴이다. R1뿐 아니라 o1, o3, Claude 3.7 Sonnet, Gemini 2.5 Pro 모두 이 패턴을 보여준다. 이것은 AI 성능 향상의 새로운 축이다. 학습 시간 스케일링(더 많이 학습)과 추론 시간 스케일링(더 많이 생각) — 두 축이 모두 유효하다는 것이 확인되었다.
셋째, 오픈소스 + 효율적 학습으로 거대 랩의 독점을 깨뜨릴 수 있다. R1은 $5.6M으로 o1에 필적하는 성능을 달성했고, MIT 라이선스로 공개했다. Sky-T1은 $450로 o1-mini급 모델을 만들었다. "최첨단 AI = 대형 연구소만 가능"이라는 공식은 더 이상 유효하지 않다.
넷째, 증류로 작은 모델에도 추론 능력을 전이할 수 있다. 7B 모델이 32B 모델을 이기고, 32B 모델이 o1-mini를 이기는 결과는, 추론 능력이 모델 크기에 비례하지 않음을 보여준다. 큰 모델의 추론 패턴을 작은 모델로 압축해서 전달할 수 있다는 것은, 추론 AI의 실용적 배포를 크게 앞당기는 발견이다.
뉘앙스: 아직 열려 있는 질문들
하지만 R1을 둘러싼 모든 것이 명확한 것은 아니다. 1년이 지난 2026년에도 논쟁이 계속되는 지점들이 있다.
"아하 순간"은 진짜 창발인가? 2025년 상반기, Sea AI Lab(싱가포르)의 연구팀이 흥미로운 발견을 보고했다. RL을 적용하기 전의 기초 모델에도, 낮은 빈도이긴 하지만 자기 성찰(self-reflection) 패턴이 이미 존재한다는 것이다. 즉, RL이 완전히 새로운 능력을 만들어낸 것이 아니라, 기초 모델에 잠재되어 있던 패턴을 강화하고 빈도를 높인 것일 수 있다.
이것은 "창발"의 정의에 대한 철학적 질문으로 이어진다. 개미 한 마리도 간헐적으로 복잡한 행동을 보일 수 있지만, 그것이 군집 수준에서 체계적으로 나타날 때 우리는 "창발"이라고 부른다. R1-Zero의 자기 검증 행동이 "완전히 새로운 것"인지 "잠재된 것의 체계화"인지는 — 둘 다 인상적이긴 하지만 — 과학적으로 다른 주장이다.
RLVR은 "더 빠르게" 만들 뿐, "더 똑똑하게" 만들지 않을 수 있다. 일부 연구자들은 RLVR이 모델의 추론 능력 자체를 향상시키는 것이 아니라, 이미 가지고 있는 능력을 더 효율적으로 사용하게 만드는 것일 수 있다고 주장한다. 사전학습에서 배운 지식의 범위 안에서 정확도를 높이는 것이지, 사전학습에서 보지 못한 완전히 새로운 종류의 추론을 만들어내는 것은 아닐 수 있다는 것이다.
검증 가능한 과제 vs 열린 질문. RLVR은 수학과 코딩에서 놀라운 성과를 보여주었다. 하지만 이 과제들은 정답이 명확하게 존재하는 영역이다. "좋은 에세이란 무엇인가?", "윤리적 딜레마에서 올바른 선택은?", "이 비즈니스 전략이 성공할까?" 같은 열린 질문에서 RLVR은 적용하기 어렵다. 정답이 없으면 검증도 할 수 없기 때문이다.
실제 훈련 비용의 뉘앙스. $5.6M이라는 수치는 최종 학습 실행의 직접 컴퓨팅 비용만 포함한다. 여기에 포함되지 않은 것들: 아키텍처 탐색 실험, 실패한 학습 시도, 하이퍼파라미터 튜닝, 연구 인력 인건비, 인프라 구축 비용 등. 실제 총 연구 비용은 $5.6M의 수배에서 수십 배에 달할 수 있다. $5.6M은 "이미 최적의 방법을 아는 상태에서 한 번 실행하는 비용"이지, "이 방법을 발견하는 데 든 비용"은 아니다.
DeepSeek-R1-0528: 5개월 후의 업데이트
2025년 5월, DeepSeek은 R1의 업데이트 버전인 R1-0528을 공개했다. 같은 아키텍처와 접근법을 기반으로 학습 과정을 개선한 버전이다.
DeepSeek-R1 → R1-0528 성능 향상
LiveCodeBench (0528)
73.3%
GPQA Diamond (0528)
81.0%
LiveCodeBench 65.9%에서 73.3%로, SWE-bench 49.2%에서 57.6%로, GPQA Diamond 71.5%에서 81.0%로. 특히 GPQA Diamond의 향상이 눈에 띈다 — 원래 R1이 o1에 뒤졌던 영역(71.5% vs 75.7%)에서, 0528이 o1을 넘어선 것이다(81.0%).
이 업데이트가 보여주는 것은 R1 파이프라인에 아직 최적화 여지가 많이 남아 있다는 것이다. 아키텍처를 바꾸지 않고 학습 과정의 세부 조정만으로 이 정도의 향상이 가능하다면, 앞으로의 개선 공간도 상당하다.
LLM 포스트트레이닝의 미래: 3단계 표준
R1 이후, LLM의 포스트트레이닝은 3단계 구조로 표준화되는 추세다.
2026년 LLM 포스트트레이닝 — 3단계 표준
Stage 1: SFT
지시 따르기 — "이렇게 대화해"
Stage 2: 선호 최적화
정렬 — DPO / SimPO / ORPO
Stage 3: 추론 RL
추론 능력 — GRPO / DAPO / RLVR
- Stage 1: SFT — 사전학습된 모델에게 지시를 따르는 방법을 가르친다. InstructGPT 이래의 표준.
- Stage 2: 선호 최적화 — DPO, SimPO, ORPO 등으로 인간의 선호에 정렬한다. 이전 글에서 다룬 DPO가 이 단계의 핵심이다.
- Stage 3: 추론 RL — GRPO, DAPO 등으로 추론 능력을 강화한다. R1이 이 단계의 가능성을 열었다.
이 3단계 구조에서 GRPO/DAPO 계열이 PPO를 빠르게 대체하고 있다. 가치 함수를 제거한 GRPO의 효율성이 대규모 모델 학습에서 결정적 이점을 제공하기 때문이다. ByteDance의 DAPO는 GRPO를 더 개선하여, 클리핑 전략을 상한/하한 독립적으로 조절하고 동적 샘플링으로 학습 효율을 높였다. R1-Zero 대비 50% 적은 학습 스텝으로 동등 이상의 성능을 달성했다.
이 논문이 남긴 가장 깊은 질문
DeepSeek-R1 논문은 기술적 성취를 넘어, AI 연구의 근본적 질문을 다시 수면 위로 끌어올렸다.
"AI의 추론은 진짜 추론인가, 아니면 정교한 패턴 매칭인가?"
R1-Zero가 "잠깐, 다시 생각해보자"라고 말하는 것은, 모델이 정말로 "생각"을 하는 것인가? 아니면 학습 데이터에서 "잠깐, 다시 생각해보자 → 정답 확률 증가"라는 패턴을 학습한 것에 불과한가?
이 질문에 대한 답은 아직 없다. 어쩌면 이 질문 자체가 잘못된 이분법일 수도 있다. 인간의 추론도, 결국 뇌의 신경망에서 일어나는 패턴 매칭이 아닌가? "진짜 추론"과 "정교한 패턴 매칭"의 경계가 어디인지는, 인공지능뿐 아니라 인지과학에서도 여전히 열려 있는 질문이다.
마치며: "잠깐, 다시 생각해보자"
2025년 1월의 어느 서버에서, 671B 파라미터의 신경망이 수학 문제와 씨름하고 있었다. 아무도 "막히면 다시 생각하라"고 가르치지 않았다. 보상 함수에는 오직 "맞으면 +1, 틀리면 -1"만 있었다.
그런데 모델이 멈췄다. 그리고 말했다.
"Wait, wait. Let me reconsider."
이 순간이 진짜 추론의 시작인지, 패턴의 정교한 재현인지는 아직 모른다. 하지만 확실한 것이 있다.
DeepSeek-R1은 추론 AI의 "Attention Is All You Need"가 되었다. 2017년 Transformer 논문이 아키텍처 혁명을 열었듯이, R1 논문은 추론 학습 혁명을 열었다. 이 논문 이후, 모든 주요 AI 연구소가 추론 모델을 만들기 시작했고, 오픈소스 커뮤니티에서 수백 개의 파생 프로젝트가 생겨났고, "test-time compute scaling"이 새로운 연구 분야로 자리잡았다.
지금의 AI 시대를 만든 논문을 꼽으라면, 네 편이 떠오른다:
- Attention Is All You Need (2017) — 아키텍처의 혁명. Transformer.
- Textbooks Are All You Need (2023) — 데이터 패러다임의 혁명. "양보다 질."
- Direct Preference Optimization (2023) — 정렬의 혁명. "보상 모델이 필요 없다."
- DeepSeek-R1 (2025) — 추론의 혁명. "RL만으로 추론이 창발한다."
아키텍처, 데이터, 정렬, 추론 — 이 네 가지 축이 2026년 현재의 AI를 만들었다. 그리고 DeepSeek-R1은 그 마지막 축을 놓은 논문이다.

다음 글에서는 이 추론 혁명이 실제 AI 에이전트와 도구 사용에 어떻게 적용되고 있는지를 다룬다.




