2025년, AI 에이전트 시장은 폭발적으로 성장했다. LangChain, AutoGen, CrewAI, OpenAI Agents SDK — 에이전트를 만드는 프레임워크가 넘쳐났다. 모두가 "에이전트의 시대"를 외쳤다.
하지만 한 가지 불편한 진실이 있었다. 대부분의 에이전트는 훈련되지 않은 채 배포되고 있었다.
무슨 뜻인가? 개발자가 프롬프트를 작성하고, 몇 번 테스트해보고, "이 정도면 되겠지"하고 프로덕션에 올린다. 에이전트가 실패하면? 프롬프트를 손으로 고치고 다시 배포한다. 이것은 마치 교과서만 읽고 시험을 보게 하는 것과 같다. 연습 문제도 안 풀어보고, 모의고사도 안 치르고.
인간이 전문가가 되는 방법을 생각해보자. 의사는 수천 건의 케이스를 경험하며 진단 능력을 기른다. 바리스타는 수백 잔의 커피를 추출하며 최적의 레시피를 찾는다. 경험과 피드백을 통한 학습 — 이것이 핵심이다.
AI 에이전트도 마찬가지여야 한다. 그리고 2025년 8월, Microsoft Research가 이 문제의 해답을 내놓았다.
Agent Lightning — AI 에이전트를 강화학습(RL)으로 훈련시키는 오픈소스 프레임워크.
"Agent Lightning은 ANY AI 에이전트를 강화학습으로 훈련시킬 수 있습니다. 프레임워크에 구애받지 않고, 코드 변경 거의 없이."
— Microsoft Research 논문 (arXiv: 2508.03680)
이 글은 Agent Lightning의 모든 것을 해부한다. 왜 에이전트 훈련이 필요한지부터, 강화학습의 원리, 아키텍처의 세부 구조, 실전 적용 사례, 그리고 2026년 AI 개발의 미래까지.
2024년까지 AI 에이전트의 성능을 올리는 방법은 대부분 프롬프트 엔지니어링이었다. "너는 전문 SQL 분석가야. 사용자의 질문을 정확한 SQL로 변환해"같은 시스템 프롬프트를 정교하게 다듬는 작업이다.
문제는, 이 방법이 천장에 부딪힌다는 것이다.
프롬프트 v1 (기본)
46%
프롬프트 v5 (최적화)
58%
프롬프트 v12 (극한 튜닝)
62%
Agent Lightning RL 훈련 후
74%
위 수치는 Agent Lightning 논문의 Spider(Text-to-SQL) 벤치마크 기준. Qwen2.5-Coder-1.5B 모델 사용.
프롬프트를 아무리 다듬어도 62%에서 정체되던 SQL 에이전트가, 강화학습 훈련 후 74%까지 올라갔다. 12%p의 도약 — 이것은 프롬프트 수십 번 고쳐서는 절대 달성할 수 없는 성능이다.
1.2 왜 강화학습인가?
강화학습(Reinforcement Learning)을 비유로 설명하면 이렇다.
📚
지도학습 (SFT) = 교과서 공부
"이 질문에는 이 답이 정답이야" — 정해진 답을 암기하는 방식. 새로운 유형의 문제에 약하다.
🏋️
강화학습 (RL) = 실전 연습
"직접 풀어보고, 맞으면 보상, 틀리면 감점" — 시행착오를 통해 스스로 전략을 발견하는 방식. 일반화 능력이 뛰어나다.
⚡
Agent Lightning = 체계적 훈련 시스템
에이전트에게 수천 개의 문제를 풀게 하고, 결과에 대한 보상/감점을 주고, 이를 바탕으로 모델 가중치와 프롬프트를 최적화한다.
바둑의 알파고를 떠올려보자. 알파고는 인간의 기보(지도학습)만으로는 세계 챔피언이 될 수 없었다. 자기 자신과 수백만 판을 두며 강화학습을 한 뒤에야 이세돌을 이겼다. AI 에이전트도 마찬가지다.
1.3 에이전트 훈련이 어려운 진짜 이유
그런데 왜 지금까지 에이전트에 강화학습을 적용하지 못했을까? 이유는 세 가지다.
첫째, 프레임워크 파편화. LangChain으로 만든 에이전트와 AutoGen으로 만든 에이전트는 구조가 완전히 다르다. 각각에 맞는 RL 파이프라인을 만들어야 했다.
둘째, 훈련-실행 결합(Coupling). 기존 RL 프레임워크는 에이전트의 실행 환경과 훈련 루프가 단단히 묶여 있었다. 에이전트가 외부 API를 호출하거나, 파일을 생성하거나, 데이터베이스를 조회하는 복잡한 작업을 할 때 — 이 모든 것을 RL 훈련 루프 안에서 처리해야 했다.
셋째, 크레딧 할당(Credit Assignment). 에이전트가 10단계를 거쳐 작업을 완료했을 때, "어느 단계가 성공에 기여했고 어느 단계가 실패를 유발했는가?"를 판별하는 것이 극도로 어렵다.
Agent Lightning은 이 세 가지 문제를 모두 해결한다.
제2장: Agent Lightning의 핵심 철학
2.1 "ZERO CODE CHANGE (거의)"
Agent Lightning의 가장 파괴적인 특징은 기존 에이전트 코드를 거의 수정하지 않아도 된다는 것이다.
기존 LangChain 에이전트에 Agent Lightning을 적용하는 데 필요한 코드 변경은 딱 두 줄이다:
hljs language-python
# 기존 에이전트 코드 (변경 없음)from langchain.agents import create_react_agent
agent = create_react_agent(llm, tools, prompt)
# Agent Lightning 추가 — 이것뿐!import agentlightning as agl
agl.emit_reward(score=0.85) # 결과에 대한 보상 신호
이것이 가능한 이유는 Agent Lightning이 자동 계측(Auto-Instrumentation) 기술을 사용하기 때문이다. 에이전트가 LLM을 호출할 때, 도구를 사용할 때 — 이 모든 것을 투명하게 추적(trace)한다. 개발자가 명시적으로 로깅 코드를 넣을 필요가 없다.
2.2 프레임워크 불가지론(Framework-Agnostic)
Agent Lightning은 특정 에이전트 프레임워크에 종속되지 않는다.
프레임워크
지원 방식
변경량
LangChain / LangGraph
자동 계측
~2줄
AutoGen
자동 계측
~2줄
CrewAI
자동 계측
~2줄
OpenAI Agents SDK
자동 계측
~2줄
커스텀 에이전트
emit_xxx() 헬퍼
~5줄
TypeScript 에이전트
LLM Proxy 경유
엔드포인트 URL만 변경
핵심은 경량 헬퍼 함수 agl.emit_xxx()와 자동 추적(Tracer)의 조합이다. 에이전트가 어떤 프레임워크로 만들어졌든, Agent Lightning은 LLM 호출을 자동으로 포착하고, 개발자는 보상 신호만 보내면 된다.
전통적인 RL 시스템에서는 에이전트 실행과 모델 훈련이 같은 프로세스 안에서 돌아간다. 하지만 AI 에이전트는 외부 세계와 상호작용한다 — API를 호출하고, 웹을 검색하고, 데이터베이스를 조회한다. 이런 I/O 집약적 작업을 GPU 훈련 루프 안에 넣으면 GPU가 I/O를 기다리며 놀게 된다.
Agent Lightning은 이 문제를 훈련과 실행을 완전히 분리하여 해결한다. 이것이 논문이 "Training-Agent Disaggregation Architecture"라고 부르는 핵심 설계다.
제3장: 아키텍처 완전 해부
3.1 세 기둥: Algorithm, Runner, LightningStore
Agent Lightning의 아키텍처는 세 가지 핵심 컴포넌트로 구성된다. 이것을 이해하면 전체 시스템의 동작 원리를 파악할 수 있다.
Agent Lightning 아키텍처 — 세 기둥
🧠 Algorithm
"두뇌" — 어떤 작업을 할지 결정하고, 결과를 학습하고, 모델/프롬프트를 업데이트한다
⚡ LightningStore
"중앙 데이터베이스" — 작업 큐, 결과 저장소, 리소스 허브. Algorithm과 Runner를 연결하는 유일한 통로
LightningStore = 주문 시스템(POS). 주방과 홀을 연결하는 유일한 통신 채널이다.
Runner = 웨이터+요리사. 주문을 받아 음식을 만들고, 결과를 주문 시스템에 기록한다.
주방장이 직접 서빙할 필요 없고, 웨이터가 레시피를 개발할 필요도 없다. 관심사의 완전한 분리.
3.2 데이터 흐름: 작업은 어떻게 순환하는가
Step 1
Algorithm이 작업 생성 — 데이터셋에서 문제를 꺼내 Rollout(작업 단위)을 만들어 LightningStore 큐에 넣는다
Step 2
Runner가 작업 수령 — 큐에서 Rollout을 꺼내고, 현재 리소스(모델 가중치, 프롬프트 템플릿)를 가져온다
Step 3
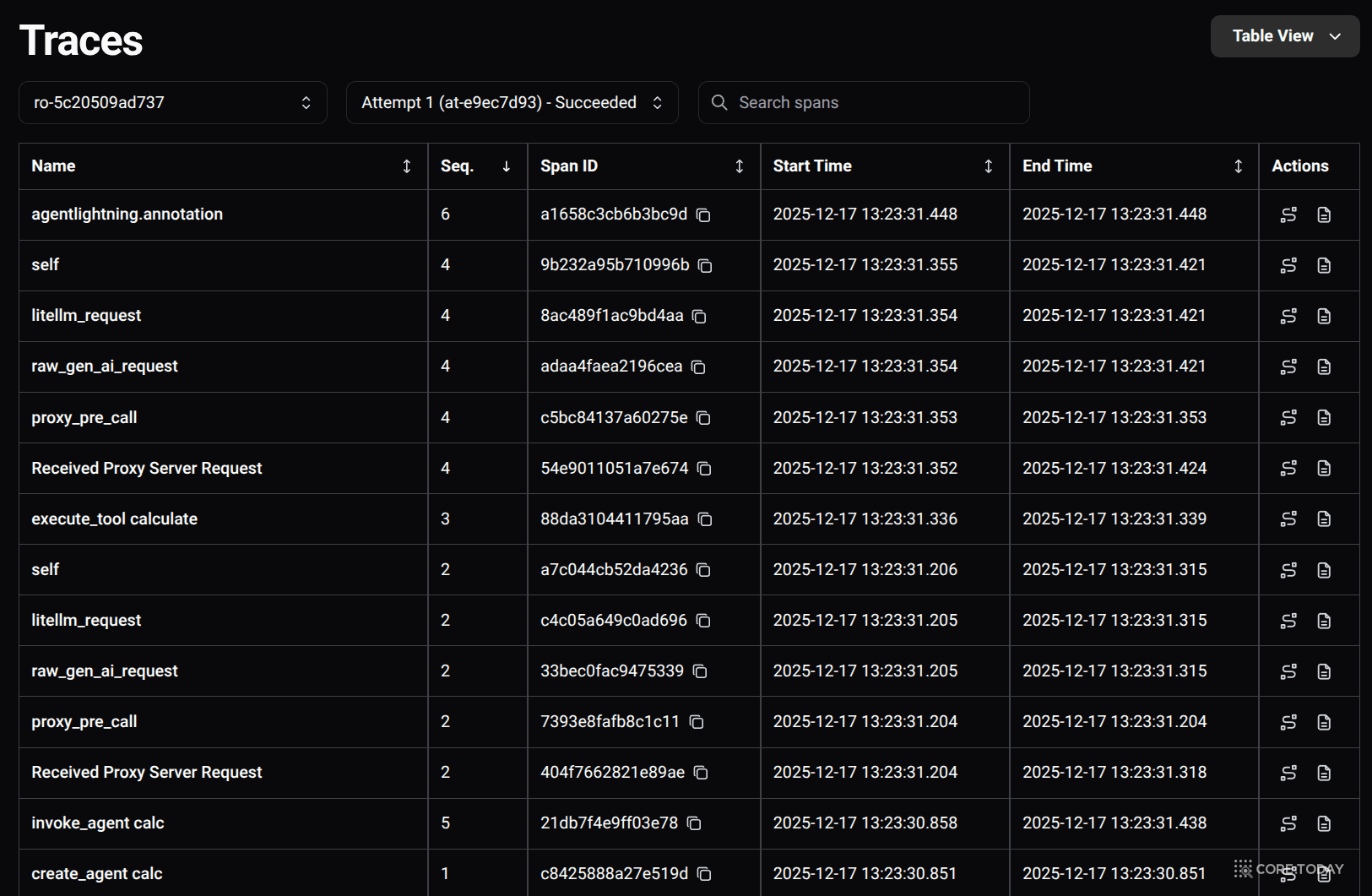
에이전트 실행 — Runner가 에이전트를 실행하고, Tracer가 모든 LLM 호출과 도구 사용을 Span으로 기록한다
Step 4
보상 신호 발생 — 에이전트 실행 결과에 대한 점수(reward)가 매겨진다. 자동 검증 또는 수동 평가
Step 5
결과 저장 — 모든 Span과 보상이 LightningStore에 스트리밍된다
Step 6
Algorithm이 학습 — 새로운 데이터를 가져와 RL 알고리즘으로 모델 가중치를 업데이트하거나, 프롬프트를 다시 작성한다. 그리고 Step 1로 돌아간다
이 사이클이 수백~수천 번 반복되면서 에이전트의 성능이 지속적으로 향상된다.
3.3 핵심 용어 사전
Agent Lightning을 이해하려면 다섯 가지 핵심 개념을 알아야 한다.
용어
비유
설명
Resource
도구 세트
훈련/최적화 대상. 모델 가중치, 프롬프트 템플릿 등
Rollout
시험 한 회차
에이전트가 하나의 문제를 처음부터 끝까지 수행하는 단위
Attempt
시험 재응시
하나의 Rollout에 대한 개별 실행 (재시도 지원)
Span
시험 풀이 과정 한 단계
Rollout 중 개별 작업 단위 — LLM 호출, 도구 실행, 보상 등. OpenTelemetry 표준 준수
Reward
채점 결과
Rollout 품질을 판단하는 수치 점수. RL의 핵심 신호
이들의 관계를 정리하면:
Dataset = [Rollout1, Rollout2, ..., RolloutN] (문제지)
└── Rollout = 하나의 문제
└── Attempt = 한 번의 풀이 시도
└── [Span1, Span2, ..., SpanM] (풀이 과정 각 단계)
└── Reward (채점 결과)
3.4 실행 번들: 두 세계의 분리
Agent Lightning의 가장 중요한 설계 결정은 시스템을 두 개의 독립적인 번들로 나누는 것이다.
LLM Proxy는 Agent Lightning에서 가장 영리한 컴포넌트 중 하나다. LiteLLM 위에 구축된 이 프록시는:
🔌
통합 엔드포인트
다양한 LLM 백엔드(OpenAI, Anthropic, vLLM, Azure)를 하나의 OpenAI 호환 API로 통합한다
🔄
동적 모델 교체
에이전트 코드를 변경하지 않고도 모델을 실시간으로 교체할 수 있다. 훈련 도중 새 가중치로 원활히 전환
🔑
토큰 ID 캡처
RL 훈련에 필수적인 토큰 ID를 자동으로 캡처한다. vLLM v0.10.2+와 협업하여 구현
특히 동적 모델 교체 기능이 중요하다. RL 훈련에서 모델 가중치는 계속 업데이트된다. 에이전트가 모델을 호출할 때, LLM Proxy가 자동으로 가장 최신 가중치를 사용하도록 라우팅해준다. 에이전트 코드는 한 줄도 바뀌지 않는다.
4.4 토큰 ID 문제 — RL 훈련의 숨겨진 난관
강화학습에서 토큰 ID가 왜 중요한가? RL 알고리즘(특히 PPO, GRPO)은 모델이 생성한 각 토큰의 확률을 알아야 한다. 이를 위해 정확한 토큰 ID가 필요하다.
문제는, LLM API가 보통 텍스트만 반환하고 토큰 ID는 반환하지 않는다는 것이다. 텍스트를 다시 토크나이즈(retokenize)하면 되지 않을까?
❌ 재토크나이징의 함정
원본 생성: [15043, 382, 1234, 98] ← 모델이 실제 생성한 토큰
재토크나이징: [15043, 38, 2123, 4, 98] ← 텍스트를 다시 분해한 결과
→ 토큰 경계가 다름 → 확률 계산 불일치 → 훈련 불안정
이 문제가 발생하는 이유:
채팅 템플릿 차이 — 각 모델의 특수 토큰 삽입 방식이 다르다
도구 호출 파싱 — JSON 형태의 도구 호출은 토크나이저마다 경계가 다르게 잡힌다
토큰 경계 모호성 — 같은 텍스트도 분해 방법이 여러 가지일 수 있다
Agent Lightning은 이 문제를 vLLM 팀과 협업하여 해결했다. vLLM v0.10.2부터 return_token_ids 파라미터가 추가되어, API 응답에 토큰 ID가 직접 포함된다.
4.5 LightningStore — 모든 것의 중심
LightningStore는 메시지 큐 + 데이터베이스 + 리소스 레지스트리를 하나로 합친 컴포넌트다.
구현체
백엔드
사용 시나리오
특징
InMemory
Python dict
로컬 개발, CI 테스트
외부 의존성 없음, 가장 빠름
MongoDB
MongoDB
프로덕션, 분산 환경
영속적, 멀티프로세스 안전, 데이터 보존
SQLite
SQLite
(개발 중)
파일 기반, 경량 영속성
Server/Client
HTTP REST
멀티머신 분산 배포
네트워크 넘어 통신, 스케일아웃
4.6 Hooks — 훈련 생명주기에 끼어드는 콜백
Hooks는 훈련 과정의 핵심 시점에 사용자 정의 로직을 삽입할 수 있게 해준다.
hljs language-python
classMyHooks:
defon_rollout_start(self, rollout):
"""Rollout 시작 전 — 환경 초기화, 데이터 준비"""print(f"Starting rollout: {rollout.id}")
defon_trace_start(self, trace):
"""개별 추적 시작 — 타이머 시작"""passdefon_trace_end(self, trace):
"""추적 종료 — 결과 검증, 보상 계산"""
score = evaluate(trace.result)
agl.emit_reward(score)
defon_rollout_end(self, rollout):
"""Rollout 종료 — 정리 작업, 메트릭 보고"""
log_metrics(rollout)
제5장: 훈련 알고리즘 — 에이전트를 어떻게 똑똑하게 만드는가
5.1 VERL + GRPO — 강화학습의 핵심 엔진
Agent Lightning의 기본 RL 알고리즘은 GRPO(Group Relative Policy Optimization)를 사용하는 VERL 프레임워크다.
GRPO를 직관적으로 설명하면:
1. 그룹 생성
같은 문제에 대해 여러 개의 응답을 생성한다 (예: 8개)
2. 상대 평가
8개 응답의 보상을 비교한다. "이 그룹 안에서 상대적으로 좋은 응답"과 "상대적으로 나쁜 응답"을 구분한다
3. 정책 업데이트
좋은 응답의 확률은 높이고, 나쁜 응답의 확률은 낮추도록 모델 가중치를 조정한다
왜 GRPO인가? 기존 PPO(Proximal Policy Optimization)는 가치 함수(value function)라는 별도의 모델이 필요했다. GRPO는 가치 함수 대신 그룹 내 상대 비교를 사용하여 더 단순하고 안정적이다. DeepSeek-R1이 바로 이 GRPO로 훈련되었다.
VERL의 분산 처리 구조:
VERL 분산 훈련 파이프라인
추론 (vLLM)
에이전트가 응답을 생성하는 단계. 여러 GPU에서 병렬 추론
학습 (FSDP)
보상 기반으로 가중치를 업데이트하는 단계. 분산 데이터 병렬 처리
참조 모델
원래 모델의 복사본. KL divergence 제약을 위해 사용
5.2 APO — 프롬프트 자동 최적화
모든 상황에서 모델 가중치를 업데이트할 수 있는 것은 아니다. 클로즈드 소스 모델(GPT-4o, Claude)을 사용하는 경우, 프롬프트만 최적화하는 것이 현실적이다.
APO(Automatic Prompt Optimization)는 텍스트 그래디언트라는 독특한 개념을 사용한다.
1. 평가 (Evaluate)
현재 프롬프트로 Rollout을 실행하고 성능을 측정한다
2. 비평 (Critique)
"텍스트 그래디언트" 생성 — "이 프롬프트의 어떤 부분이 낮은 성능을 유발했는지" 자연어로 분석한다. 예: "도구 사용 순서에 대한 명시적 지시가 부족함"
3. 재작성 (Rewrite)
비평을 반영하여 개선된 프롬프트를 생성한다. 그리고 Step 1로 돌아간다
실전 결과 (Room Selector 벤치마크):
기본 프롬프트
56.9%
APO 1라운드
~65%
APO 2라운드
72.0%
2라운드, 약 10분 만에 27% 성능 향상. 수동으로 프롬프트를 고치며 A/B 테스트를 반복하는 것보다 훨씬 효율적이다.