비정형 텍스트에서 구조화된 지식을 자동으로 추출하는 OneKE 시스템을 깊이 분석합니다. 규칙 기반부터 LLM 에이전트까지, 지식 추출 기술의 30년 역사와 함께 Schema·Extraction·Reflection 세 에이전트의 협력 메커니즘을 사례와 인터랙티브 데모로 쉽게 이해할 수 있습니다.
코어닷투데이2026-01-3139분
프롤로그: 세상의 지식은 정리되지 않은 채 흩어져 있다
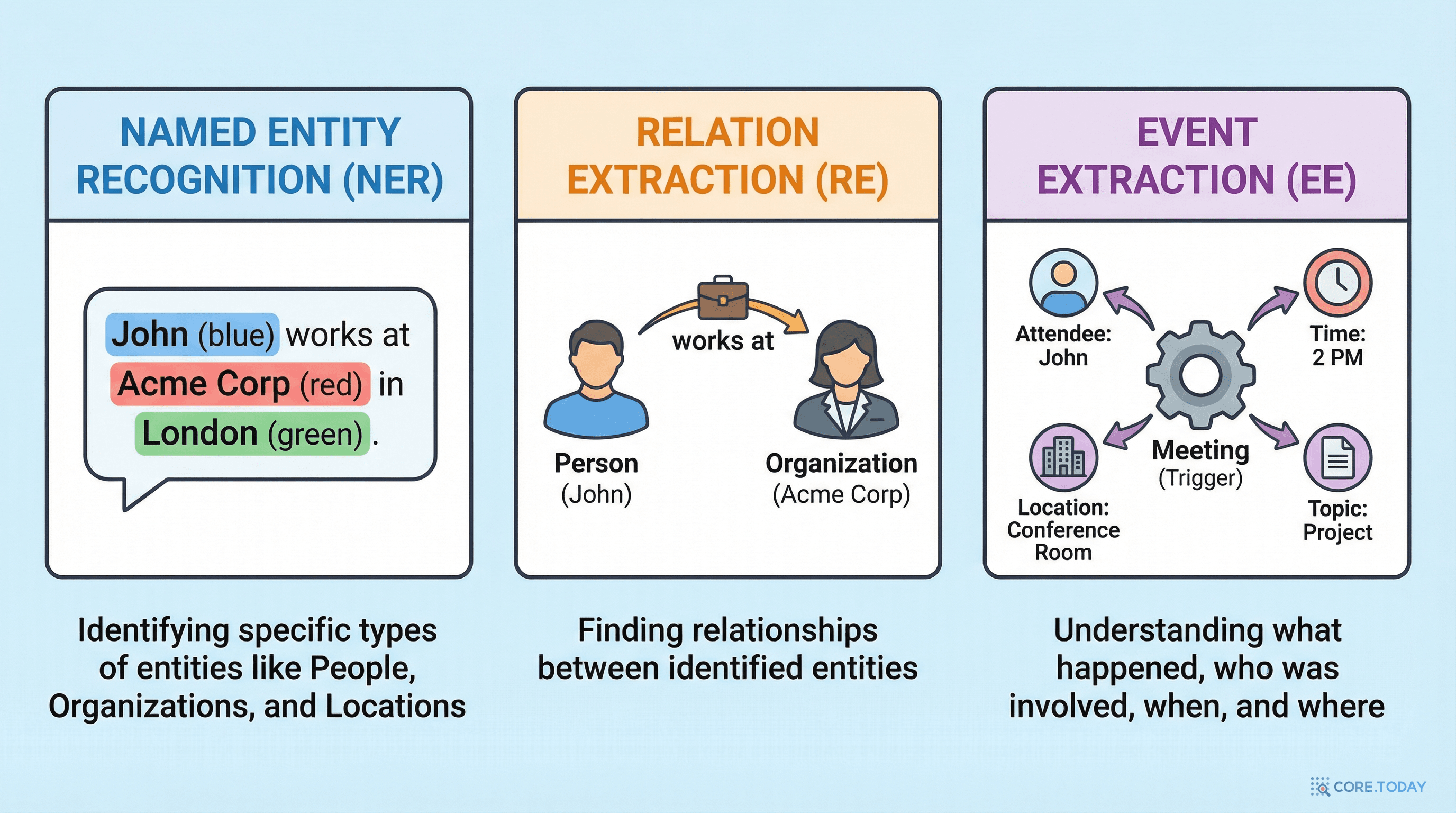
당신이 신약 개발 연구자라고 상상해 보자. 매일 쏟아지는 수천 편의 논문에서 "어떤 단백질이 어떤 질병과 관련되어 있고, 어떤 약물이 어떤 부작용을 일으키는지"를 파악해야 한다. 모든 정보가 자연어 텍스트 속에 묻혀 있다.
"BRCA1 유전자의 변이는 유방암 위험을 최대 72%까지 증가시키며, 최근 연구에서 PARP 억제제인 올라파립이 이 변이를 가진 환자에게 효과적임이 밝혀졌다."
이 한 문장 안에는 유전자(BRCA1), 질병(유방암), 약물(올라파립), 관계(변이→위험 증가, 약물→효과), 이벤트(연구 발표)가 모두 들어 있다. 사람이 이걸 하나하나 읽고 정리하려면 얼마나 걸릴까?
전 세계에서 매일 생산되는 비정형 데이터는 약 2.5엑사바이트(250경 바이트)에 달한다. 이메일, 뉴스, 논문, SNS, 보고서... 이 거대한 텍스트의 바다에서 의미 있는 지식을 건져 올리는 것 — 이것이 바로 지식 추출(Knowledge Extraction)이다.
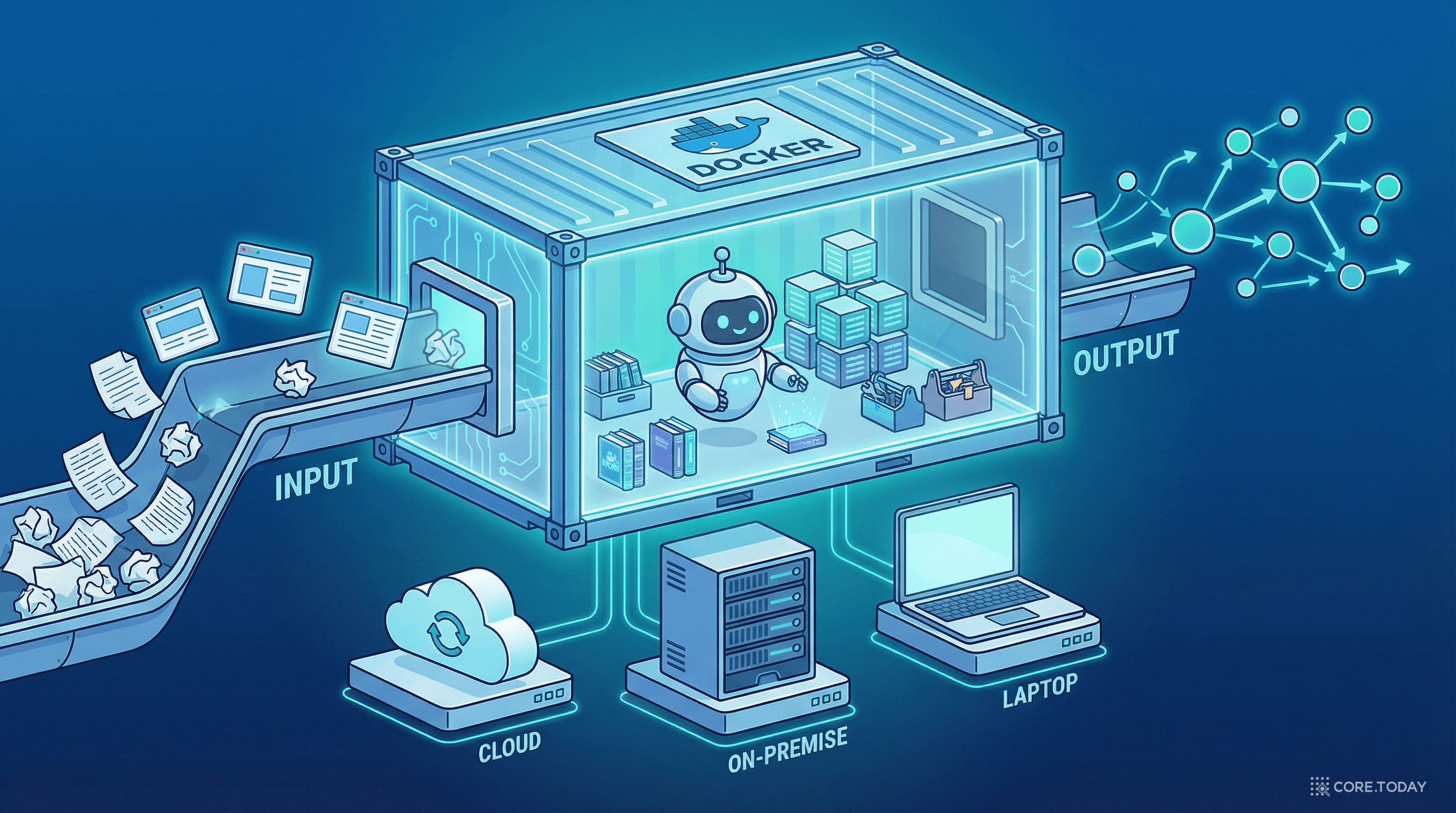
OneKE의 이름에서 눈에 띄는 단어가 있다: Dockerized. 왜 Docker가 중요한가?
재현성 문제
AI 연구의 고질적인 문제 중 하나가 재현성(reproducibility)이다. "논문에서는 된다고 했는데 내 환경에서는 안 된다"는 경험, AI 개발자라면 누구나 있을 것이다.
OneKE는 시스템 전체를 Docker 컨테이너로 패키징하여 이 문제를 해결한다:
hljs language-bash
# OneKE를 단 두 줄로 실행
docker pull zjunlp/oneke:v4
docker run --gpus all -v ./OneKE:/app/OneKE -it oneke:v4 /bin/bash
Python 버전, CUDA 버전, 라이브러리 의존성 — 이 모든 것이 컨테이너 안에 고정되어 있어 어떤 환경에서든 동일하게 작동한다.
세 가지 실행 모드
Quick 모드
Standard 모드
Customized 모드
긴 텍스트 빠르게 처리
높은 정확도 추출
에이전트별 세부 설정
Schema Agent만 사용
3개 에이전트 모두 사용
사용자가 각 에이전트 구성
속도 우선
정확도 우선
유연성 우선
지원하는 LLM
OneKE는 특정 LLM에 종속되지 않는다:
API 기반: GPT-4o-mini, o3-mini, DeepSeek-chat, DeepSeek-reasoner
로컬 모델: LLaMA, Qwen, ChatGLM, MiniCPM (vLLM 가속 지원)
모델을 교체해도 시스템을 재설계할 필요가 없다. YAML 설정 파일 하나만 바꾸면 된다.
제7장: 실험 결과 — 각 에이전트의 기여도
OneKE 팀은 두 가지 벤치마크에서 시스템을 평가했다:
CrossNER: 크로스 도메인 개체명 인식 (AI, 문학, 음악, 정치, 과학 5개 도메인)
NYT-11-HRL: 뉴욕타임즈 기사 기반 관계 추출
핵심 발견: 모든 에이전트가 기여한다
기본 LLM (Few-shot 없음)
기준선
+ Schema Agent
+8%
+ Case Retrieval
+20%
+ Reflection Agent
+28%
특히 Case Retrieval(사례 검색)이 가장 큰 성능 향상을 가져왔다. 유사한 과거 사례를 Few-shot으로 제공하는 것만으로도 추출 정확도가 크게 올라간 것이다. 그리고 Reflection Agent의 오류 수정이 추가되면서 최종 성능이 한 단계 더 올라갔다.
LLaMA vs GPT-4
평가 항목
LLaMA-3-8B
GPT-4-turbo
NER (CrossNER)
Case Retrieval에서 큰 향상
전반적으로 높은 기준 성능
RE (NYT-11-HRL)
Reflection에서 큰 향상
Case Retrieval에서 가장 큰 향상
에이전트 효과
모든 에이전트에서 일관된 향상
이미 높은 성능에서도 추가 향상
흥미로운 점은, 오픈소스 모델(LLaMA-3-8B)도 OneKE의 에이전트 시스템과 결합하면 상용 모델에 근접하는 성능을 보인다는 것이다. 이는 비용에 민감한 기업들에게 중요한 시사점이다.
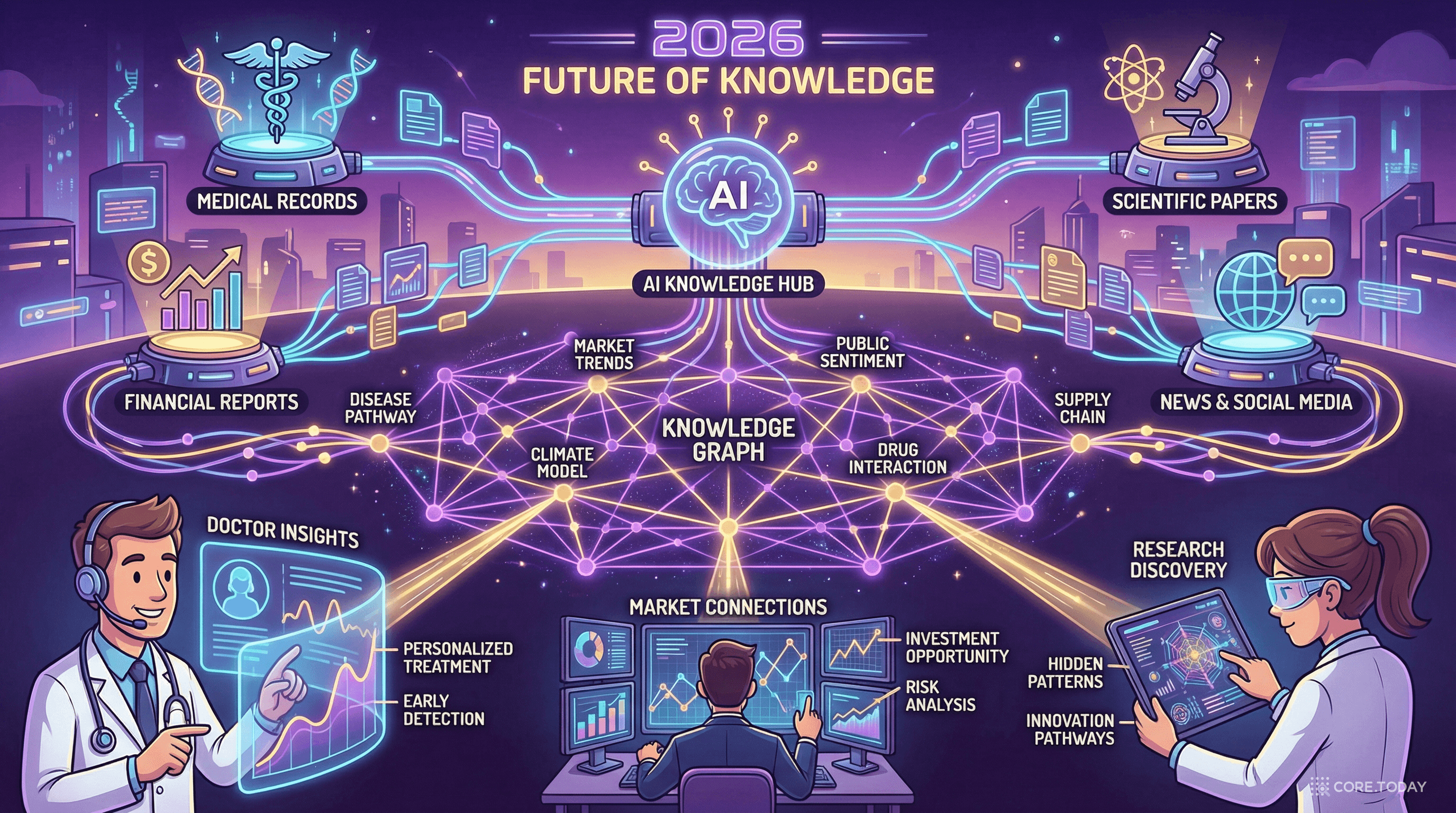
2026년 현재, 지식 추출은 단순한 학술 연구를 넘어 산업 현장의 핵심 기술로 자리잡고 있다:
의료 분야: 환자 기록, 논문, 임상시험 데이터에서 약물-질병-유전자 관계를 자동 추출하여 신약 개발 가속화
금융 분야: 뉴스, 공시, SNS에서 기업 관계, 이벤트(인수합병, 경영진 변동, 규제 변화)를 실시간 추출하여 리스크 관리
법률 분야: 판례, 법률 조항, 계약서에서 법적 관계와 선례를 자동 추출하여 법률 자문 자동화
제조업: 기술 문서, 특허, 매뉴얼에서 부품-공정-불량 관계를 추출하여 품질 관리 자동화
GraphRAG와의 시너지
OneKE 같은 지식 추출 시스템은 GraphRAG(Graph-based Retrieval Augmented Generation)와 결합될 때 진정한 힘을 발휘한다. 지식 추출 → 지식 그래프 구축 → GraphRAG로 질의응답 — 이 파이프라인이 2026년 엔터프라이즈 AI의 핵심 아키텍처가 되고 있다.
비정형 데이터
↓ OneKE (지식 추출)
구조화된 트리플
↓ Neo4j / Neptune
지식 그래프
↓ GraphRAG
정확한 질의응답
OneKE가 남긴 교훈
OneKE 논문이 보여준 가장 중요한 인사이트는 이것이다:
LLM 하나로 모든 것을 해결하려 하지 마라. 역할을 나누고, 피드백 루프를 만들어라.
이것은 지식 추출뿐 아니라, LLM 기반 시스템 설계의 일반 원칙이 되고 있다:
1
역할 분리 (Role Separation)
하나의 거대한 프롬프트 대신, 전문화된 에이전트들이 각자의 역할을 수행한다. Schema Agent는 기획만, Extraction Agent는 추출만, Reflection Agent는 검수만 한다
2
경험 축적 (Experience Accumulation)
Case Repository를 통해 시스템이 경험을 축적한다. 성공 사례와 실패 사례가 모두 저장되어, 시간이 지날수록 더 정확해진다
3
자기 반성 (Self-Reflection)
Reflection Agent의 "왜 틀렸는지 분석"은 인간 전문가의 디버깅 과정을 모방한다. 재학습 없이 자기 수정이 가능하다
에필로그: 기계가 세상을 읽는 법
우리는 매일 엄청난 양의 텍스트를 만들어내지만, 그 안의 지식은 대부분 비정형 상태로 잠들어 있다. OneKE는 세 명의 AI 에이전트가 협력하여 이 잠든 지식을 깨우는 시스템이다.
30년 전 사람이 수작업으로 규칙을 만들던 시대에서, 이제 AI 에이전트가 스스로 스키마를 설계하고, 지식을 추출하고, 실수를 반성하며 개선하는 시대가 되었다. 그리고 이 모든 것이 Docker 컨테이너 안에 담겨, 누구나 docker run 한 줄로 실행할 수 있다.
기계가 세상을 읽는 법 — 그것은 더 이상 먼 미래의 이야기가 아니다. 지금, 여기서 일어나고 있다.
참고 자료
Yujie Luo et al., "OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System," WWW 2025 Demonstration, 2024. (arXiv:2412.20005)