들어가며: "이 노트북에 AI 칩이 들어 있다고요?"
2026년, 새 노트북을 사려고 스펙을 보면 낯선 항목이 눈에 띈다: NPU 50 TOPS. CPU와 GPU는 익숙한데, NPU는 뭔가?
더 혼란스러운 건 Microsoft가 "AI PC"라는 용어를 만들며 "NPU 40 TOPS 이상"을 필수 요건으로 정했다는 것이다. Windows 12에서는 NPU가 없으면 주요 AI 기능을 쓸 수 없을 것이라는 전망도 나온다.
그리고 가장 놀라운 뉴스: OpenAI의 오픈소스 모델 GPT-OSS-120B(1,170억 파라미터)를 내 노트북에서 돌리는 사람들이 등장했다. GPU가 아니라 NPU+통합 메모리로.
이 글은 NPU가 무엇인지, 왜 필요한지, 어떻게 작동하는지를 처음부터 차근히 설명한다.
제1장: CPU, GPU, 그리고 NPU — 세 가지 칩의 차이
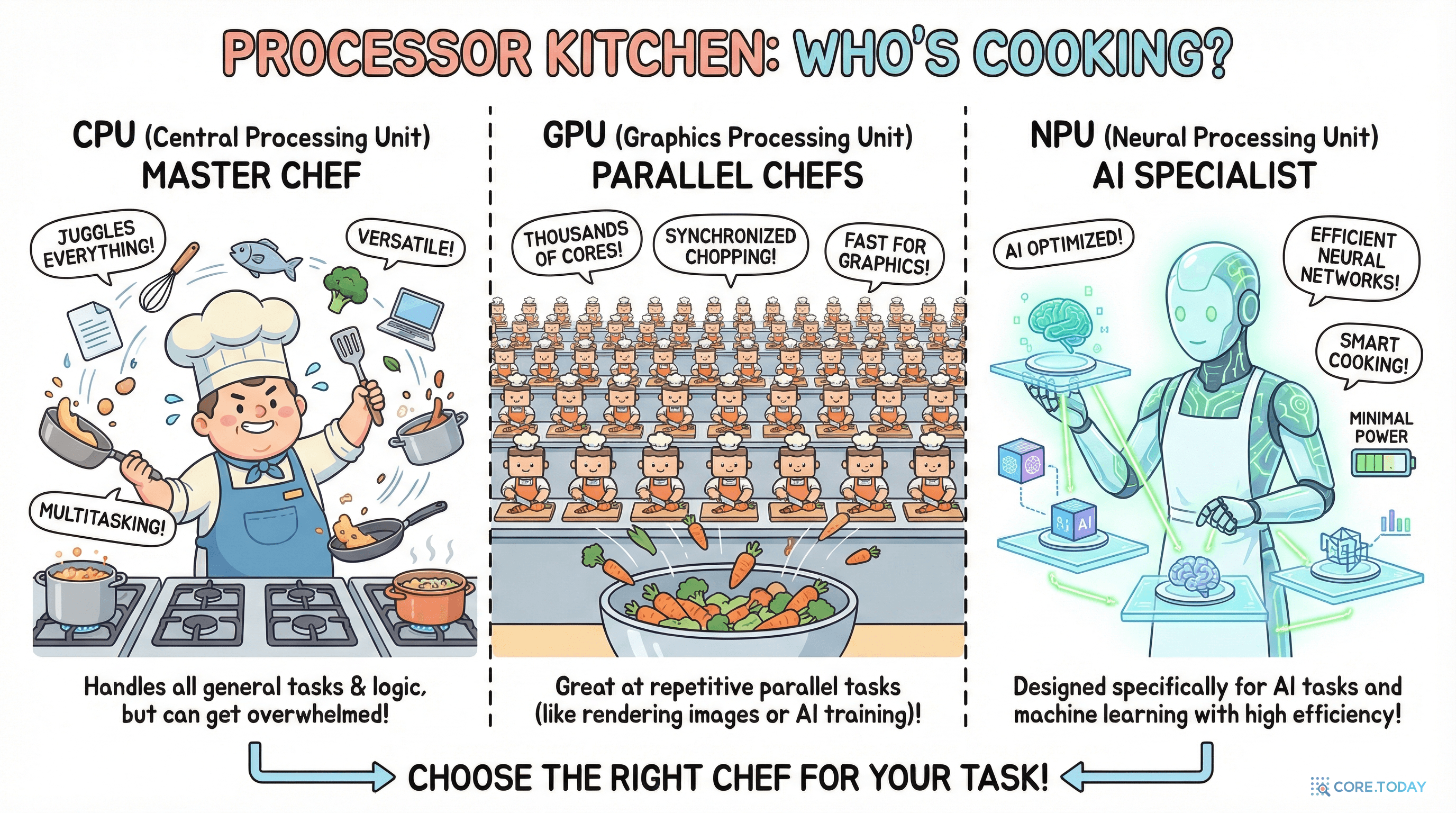
비유로 이해하기
세 가지 프로세서의 비유
CPU
만능 요리사
모든 요리를 할 수 있지만, 한 번에 하나씩. 복잡한 요리도 가능.
GPU
수천 명의 보조 요리사
단순한 작업을 수천 개 동시에 처리. 대량 생산 전문.
NPU
AI 전문 요리사
AI 연산만 한다. 대신 에너지를 거의 안 쓰며 매우 빠르다.
기술적 차이
| 항목 | CPU | GPU | NPU |
|---|
| 설계 목적 | 범용 순차 처리 | 대규모 병렬 그래픽/연산 | AI/ML 추론 전용 |
| 코어 수 | 4~24개 | 수천 개 (작은 코어) | 전용 MAC 배열 + DSP |
| 소비 전력 | 15~125W | 50~700W | 5~15W |
| AI 성능 | 1~5 TFLOPS | 80~300 TFLOPS | 10~85 TOPS |
| 강점 | 유연성, OS 작업 | 학습, 대규모 연산 | 에너지 효율적 추론 |
핵심 차이는 전력 효율이다. NPU는 같은 AI 연산을 GPU 대비 소비 전력의 1/10 이하로 수행한다. KAIST 연구에 따르면, NPU 아키텍처는 GPU 대비 60% 빠른 추론을 44% 적은 전력으로 달성했다.
TOPS가 뭔가?
TOPS = Tera Operations Per Second = 초당 1조 번의 연산. NPU 성능을 비교하는 표준 단위다. 주로 INT8(8비트 정수) 연산 기준이다.
- Apple M4: 38 TOPS
- Qualcomm Snapdragon X2 Elite: 80 TOPS
- Microsoft AI PC 기준: 40 TOPS 이상
제2장: NPU의 역사 — Google TPU에서 시작된 혁명

타임라인
2006 — Qualcomm Hexagon DSP (NPU의 전신)
↓
2015 — Google TPU v1 내부 배포
↓
2017 — Apple A11 Neural Engine (모바일 최초)
↓
2020 — Apple M1으로 Mac에 NPU 탑재
↓
2023 — Intel, AMD PC에 NPU 통합
↓
2026 — NPU가 모든 PC의 표준이 되다
Google TPU — 모든 것의 시작
2013년, Google의 Jeff Dean 팀은 충격적인 계산을 했다. 전 세계 모든 Android 사용자가 하루에 3분씩 음성 검색을 쓰면, Google의 모든 데이터센터를 합쳐도 부족하다는 것이었다. 범용 CPU로는 감당할 수 없었다.
해답은 AI 전용 칩이었다. Norman Jouppi가 이끈 팀은 15개월 만에 TPU(Tensor Processing Unit) v1을 설계했다. 2015년 내부 배포, 2016년 공식 발표. 핵심 스펙:
- 65,536개의 8비트 MAC(곱셈-누적) 연산 유닛이 시스톨릭 배열(systolic array)로 배치
- 92 TOPS 최대 처리량
- 28 MiB 온칩 메모리
2017년 논문(arXiv 1704.04760)에서 발표된 결과: 당시 CPU/GPU 대비 15~30배 성능, 30~80배 성능/와트 효율.
이것이 NPU 혁명의 시작이었다.
Apple Neural Engine — 모바일에서 PC로
Apple은 2017년 A11 Bionic에 최초의 모바일 Neural Engine을 탑재했다. 2코어, 초당 6,000억 연산. Face ID의 얼굴 인식이 가능했던 이유다.
이후 빠르게 진화했다:
Apple Neural Engine 성능 진화 (TOPS)
7년 만에 성능이 60배 이상 증가했다. 그리고 2020년 M1 칩으로 Mac에도 NPU가 탑재되면서, PC 시장에 NPU 시대가 열렸다.
제3장: 2026년 NPU 현황 — 전쟁의 지형도

주요 NPU 비교
2026년 주요 NPU 성능 비교 (TOPS)
상세 비교표
| 칩 | 제조사 | NPU TOPS | 플랫폼 | 공정 |
|---|
| Snapdragon X2 Elite Extreme | Qualcomm | 85 | Windows ARM 노트북 | 3nm |
| Snapdragon X2 Elite/Plus | Qualcomm | 80 | Windows ARM 노트북 | 3nm |
| AMD Ryzen AI 400 (XDNA 2) | AMD | 60 | Windows x86 노트북 | 4nm |
| Samsung Exynos 2500 | Samsung | 59 | Galaxy 스마트폰 | 3nm GAA |
| Intel Panther Lake (NPU 5) | Intel | 50 | Windows x86 노트북 | Intel 18A |
| Intel Lunar Lake (NPU 4) | Intel | 48 | Windows x86 노트북 | TSMC 3nm |
| Apple M4 / M5 | Apple | 38 | MacBook, iPad | 3nm |
특수 하드웨어
| 장치 | AI 성능 | 메모리 | 가격 | 용도 |
|---|
| NVIDIA DGX Spark | 1 PFLOP (FP4) | 128 GB 통합 | $4,699 | 데스크톱 AI 슈퍼컴퓨터 |
| AMD Ryzen AI Max+ 395 | 50+ TOPS NPU + GPU | 최대 128 GB | ~$2,500+ (노트북) | GPT-OSS-120B 로컬 구동 가능 |
제4장: 왜 지금 NPU인가 — 2026년의 전환점

Microsoft의 "AI PC" 정의
Microsoft가 Copilot+ PC 요건을 공식 정의했다:
- NPU 40 TOPS 이상 (필수)
- RAM 16 GB 이상
- SSD 256 GB 이상
- Windows 11 24H2+
Windows 12(코드명 "Hudson Valley Next")에서는 NPU가 OS 핵심 요구사항이 될 것으로 전망된다. NPU 없는 PC는 주요 AI 기능을 쓸 수 없게 되는 것이다.
AI PC 시장 폭발
Gartner에 따르면 AI PC는 2026년 말까지 전체 PC 시장의 55%를 차지할 전망이다. 2029년에는 표준 폼 팩터가 된다.
로컬 AI의 5가지 이점
왜 클라우드 AI가 아니라 내 기기의 NPU에서 AI를 돌려야 하는가?
| 이점 | 설명 |
|---|
| 프라이버시 | 데이터가 기기를 떠나지 않음. GDPR/HIPAA 컴플라이언스 용이 |
| 지연 시간 | 클라우드 왕복(수백 ms) 제거. 즉각 응답 |
| 비용 | 클라우드 추론 $0.50 → 로컬 추론 $0.05 (90% 절감) |
| 가용성 | 인터넷 없이도 작동 |
| 배터리 | NPU 가속 AI가 GPU 대비 배터리 수명 15~20% 연장 (1.5~3시간) |
2026년 기준, AI 추론의 약 80%가 클라우드가 아닌 로컬 디바이스에서 이루어진다.
제5장: GPT-OSS-120B — OpenAI의 오픈소스 혁명
무엇인가
2025년 8월 5일, OpenAI가 GPT-OSS-120B를 Apache 2.0 라이선스로 오픈소스 공개했다. OpenAI 최초의 완전 오픈 웨이트 모델이다.
| 스펙 | gpt-oss-120b | gpt-oss-20b |
|---|
| 총 파라미터 | 1,168억 | 209억 |
| 활성 파라미터/토큰 | 51억 | 36억 |
| 아키텍처 | MoE Transformer | MoE Transformer |
| 전문가 수 | 128개 (top-4 라우팅) | 32개 |
| 컨텍스트 길이 | 131,072 토큰 | 131,072 토큰 |
| 양자화 | MXFP4 (4.25 bits/param) | MXFP4 |
| 체크포인트 크기 | 60.8 GB | 12.8 GB |
| 최소 하드웨어 | 80 GB GPU 1개 | 16 GB RAM |
MoE가 핵심

GPT-OSS-120B가 1,170억 파라미터임에도 로컬에서 작동할 수 있는 이유는 MoE(Mixture of Experts) 아키텍처 때문이다. 128개 전문가 중 매번 4개만 활성화되므로, 한 토큰당 실제로 사용되는 파라미터는 51억에 불과하다.
MoE 아키텍처 — 왜 1,170억인데 작동하는가
라우터
입력 토큰을 분석해 가장 적합한 전문가 4개를 선택
전문가 1
활성화
전문가 2
활성화
전문가 3
활성화
전문가 4
활성화
벤치마크 성능
| 벤치마크 | gpt-oss-120b | 비교 대상 |
|---|
| AIME 2025 (수학) | 97.9% | 최고 수준 |
| MMLU | 90.0% | DeepSeek R1 (85%) 초과 |
| SWE-bench (코딩) | 62.4% | DeepSeek R1 (~65.8%)에 근접 |
| Codeforces | 2622 Elo | o3-mini 초과 |
Hugging Face에서 월 470만 다운로드를 기록 중이다.
제6장: GPT-OSS-120B를 내 PC에서 돌리다

AMD Ryzen AI Max+ 395 — 유일한 소비자 칩
2026년 3월 기준, GPT-OSS-120B를 로컬에서 돌릴 수 있는 유일한 소비자 칩은 AMD Ryzen AI Max+ 395다.
| 항목 | 스펙 |
|---|
| 통합 메모리 | 128 GB (CPU+GPU+NPU 공유) |
| NPU | 50+ TOPS (XDNA 2) |
| GPU | Radeon 890M (RDNA 3.5, 40 CU) |
| VRAM 활용 | 약 61 GB (gpt-oss-120b MXFP4) |
| 추론 속도 | ~30 tok/s (LM Studio + llama.cpp) |
| 가격대 | 약 $2,500+ (노트북) |
128 GB 통합 메모리가 핵심이다. MXFP4 양자화된 GPT-OSS-120B 체크포인트(60.8 GB)를 GPU VRAM에 올리고도 시스템 메모리가 남는다.
NVIDIA DGX Spark — 데스크톱 AI 슈퍼컴퓨터
| 항목 | 스펙 |
|---|
| 칩 | GB10 Blackwell Superchip |
| AI 성능 | 1 PFLOP (FP4) |
| 메모리 | 128 GB 통합 |
| 추론 속도 | ~50 tok/s (SGLang) |
| 가격 | $4,699 |
DGX Spark는 200B 파라미터 모델까지 추론이 가능하며, 최대 4대를 클러스터링해 "데스크톱 데이터센터"를 구성할 수 있다.
gpt-oss-20b — 16 GB 노트북에서도 가능
GPT-OSS-120B는 아직 고사양 하드웨어가 필요하지만, gpt-oss-20b(209억 파라미터, 체크포인트 12.8 GB)는 16 GB RAM 기기에서 작동한다. o3-mini 수준의 성능을 로컬에서 얻을 수 있다.
이것이 NPU가 중요한 이유와 직결된다. gpt-oss-20b 같은 모델을 NPU로 추론하면:
- GPU보다 전력 소비 1/5~1/10
- 배터리 수명 연장
- 팬 소음 최소화
- 동시에 다른 GPU 작업 가능
NPU에서 LLM을 실행하는 프레임워크
| 프레임워크 | 지원 NPU | 설명 |
|---|
| OpenVINO | Intel NPU | INT4 최적화, 가장 성숙한 Intel NPU 지원 |
| QNN SDK | Qualcomm Hexagon | Qualcomm 공식 NPU 런타임 |
| AMD Quark | AMD XDNA | AMD 오픈소스 최적화 도구 |
| Core ML | Apple Neural Engine | Apple 공식 ML 프레임워크 |
| MS Foundry Local | 모든 NPU | NPU → GPU → CPU 자동 선택 |
| ONNX Runtime | 범용 | DirectML/QNN 실행 프로바이더 |
제7장: 한국 NPU 생태계

K-NPU 5대 유니콘
한국은 "K-NPU" 이중 전략을 추진 중이다: 단기적으로 GPU를 구매하면서, 장기적으로 국산 NPU를 육성한다.
한국 NPU 스타트업 5사
FuriosaAI
Renegade (RNGD)
H100 대비 와트당 토큰 2.7배. 2026년 2만 개 출하 목표.
Rebellions
Rebel Quad (ATOM)
SKT, KT 클라우드 채택. 국가성장펀드 2,500억 원 투자.
DeepX
DX-M2
1,000억 파라미터 모델을 5W 이하로 구동. 삼성 2nm.
HyperAccel
LPU
GPU 대비 처리 속도 50% 빠름. 삼성 4nm 파운드리.
Mobilint
ARIES (80 TOPS)
산업용 AI PC. MLX-A1 제품.
핵심 기술 성과
- FuriosaAI Renegade: 와트당 토큰/초 비율이 NVIDIA H100 대비 ~2.7배. GPT-OSS와 EXAONE 모델에 최적화.
- DeepX DX-M2: 삼성·Rambus와 2nm 공정 파트너십. 1,000억 파라미터 모델을 5W 이하에서 구동한다는 목표.
- KAIST 연구: AI 클라우드 전력 소비를 44% 절감하는 에너지 효율 NPU 기술 발표.
정부 투자
- 국가성장펀드: Rebellions에 2,500억 원($178M) 투자 (2026년 3월)
- AI 반도체 생태계 연간 투자 목표: $75억(약 10조 원)
- 5개 국산 NPU 기업과의 전략 간담회 개최
제8장: NPU의 미래 — 어디로 향하는가
성능 로드맵
| 시기 | 예상 NPU TOPS (PC) | 주요 발전 |
|---|
| 2026 | 50~85 | Snapdragon X2 (80), Panther Lake (50), XDNA 2 (60) |
| 2027 | 100~200+ | AMD Medusa (Zen 6), Intel Nova Lake |
| 2028 | 500~1,000+ | 차세대 공정 노드 통합 |
핵심 트렌드
1. NPU는 더 이상 선택이 아니다. 모든 주요 SoC에 NPU가 표준 탑재된다. NPU 없는 CPU는 새 PC에서 점차 퇴출된다. Windows 12에서는 NPU가 OS 핵심 요구사항이 될 전망이다.
2. GPU와 NPU의 경계가 흐려진다. Apple M5는 모든 GPU 코어에 Neural Accelerator를 내장했다. GPU가 하던 AI 연산과 NPU가 하던 AI 연산의 구분이 사라지고 있다.
3. 모델이 NPU에 맞춰 줄어든다. 주요 AI 연구소가 4B 이하의 소형 모델을 적극 출시 중이다. Llama 3.2(1B/3B), Gemma 3(270M+), Phi-4 mini(3.8B), SmolLM2(135M~1.7B). NPU에서 실행할 수 있도록 설계된 모델들이다.
4. 소프트웨어 생태계가 따라잡고 있다. Microsoft Foundry Local, Intel OpenVINO, Qualcomm QNN, ONNX Runtime이 NPU 접근을 표준화하고 있다. "어떤 NPU가 있는지 몰라도, 프레임워크가 알아서 최적의 칩을 골라 쓴다"는 것이 목표다.
시장 전망
- NPU 시장: $53억(2023) → $1,000억 이상(2030) — 연평균 35% 성장
- AI 칩 시장 전체: $529억(2024) → $2,956억(2030) — 연평균 33.2% 성장
맺으며: 세 번째 칩의 시대

CPU가 컴퓨터를 만들었고, GPU가 게임과 AI 학습을 만들었다. 이제 NPU가 "내 기기 안의 AI"를 만들고 있다.
2026년의 전환은 명확하다:
2020 — Mac에 NPU 탑재 (M1, 11 TOPS)
↓
2024 — "AI PC" 개념 등장 (40 TOPS 기준)
↓
2026 — 전체 PC의 55%가 AI PC
↓
2029 — NPU 없는 PC는 더 이상 "PC"가 아니다
GPT-OSS-120B를 내 노트북에서 돌리는 시대. OpenClaw AI 에이전트가 NPU에서 24시간 작동하는 시대. 클라우드에 데이터를 보내지 않고도 AI를 사용하는 시대.
그 시대의 핵심에 있는 것이 NPU — CPU도 아닌, GPU도 아닌, AI를 위해 태어난 세 번째 칩이다.
참고 자료