한 줄로 시작하는 이야기
세계 최고의 AI에게도 치명적인 약점이 하나 있다. 어제를 기억하지 못한다는 것.
당신이 ChatGPT와 두 시간 동안 프로젝트를 논의하고, 취향과 맥락을 알려주고, 함께 결론에 도달해도 — 내일 새 창을 열면 그 AI는 당신을 처음 보는 사람처럼 대한다. 똑똑하지만 매일 아침 기억이 깨끗이 지워지는 '영원한 신입사원' 인 셈이다.

우리는 이 시리즈에서 스킬을 다뤘다. 그런데 스킬이 'AI가 일하는 법'이라면, 그 일을 시간을 가로질러 이어가게 하는 것이 바로 기억이다. 2026년, AI 연구의 가장 뜨거운 전선 중 하나가 에이전트 메모리(agent memory) 인 이유다.
이 글은 AI가 기억하는 법의 과학을 정리한다. 왜 기억이 필요한지(제1장), 기억을 어떻게 나누는지(제2장·인지과학에서 빌려온 4분류), 실제 시스템은 어떻게 만드는지(제3장·MemGPT의 '기억 운영체제'), 얼마나 잘 기억하는지(제4장·벤치마크), 그리고 메모리 연구의 불편한 진실(제5장)과 기억의 보안(제6장)까지 — 원문 논문의 설계도를 그대로 인용하며 풀어낸다.
제1장: 왜 기억인가 — 맥락 창의 한계와 '외부화'
↓
제2장: 네 갈래의 기억 — 인지과학에서 빌려오다
↓
제3장: 기억의 건축양식 — MemGPT의 '기억 운영체제'
↓
제4장: 얼마나 잘 기억하나 — 벤치마크의 숫자들
↓
제5장: 불편한 진실 — 메모리 연구의 함정
↓
제6장: 기억의 보안 — 오염된 기억은 사라지지 않는다
↓
제7장: 통합 그림 — 외부화로 보는 시리즈 전체
제1장: 왜 기억인가 — 맥락 창의 한계와 '외부화'
AI가 어제를 잊는 이유는 단순하다. LLM은 고정된 맥락 창(context window) 안의 정보만 본다. 창이 아무리 커져도(100만 토큰이라 해도) 그 창을 벗어난 과거는 존재하지 않는 것과 같다. 대화가 길어지면 앞부분은 밀려나 사라진다.
이를 넘어서려는 접근이 메모리 증강 생성(Memory-Augmented Generation, MAG) 이다. 《Anatomy of Agentic Memory》(arXiv 2602.19320)의 정의를 빌리면, 에이전트 메모리란 "상호작용을 가로질러 진화하는, 쓰기 가능한 영속 메모리 — 에이전트가 정보를 저장·갱신·재사용하게 하는 것" 이다. 핵심은 '쓰기 가능(writable)' 과 '영속(persistent)'. 단순히 문서를 검색해 오는 RAG를 넘어, AI가 자기 경험을 외부에 기록하고 다듬어 나간다.
큰 그림: '외부화'라는 한 단어
이 흐름을 가장 우아하게 설명하는 논문이 《Externalization in LLM Agents》(arXiv 2604.08224)다. 핵심 주장은 — AI의 발전이 '외부화(externalization)', 즉 "인지 부담을 모델 가중치 내부에서 영속적이고 검사 가능한 외부 구조로 옮기는 것" 으로 설명된다는 것이다. 그리고 이것은 인류 문명의 진화와 똑같은 궤적을 그린다.
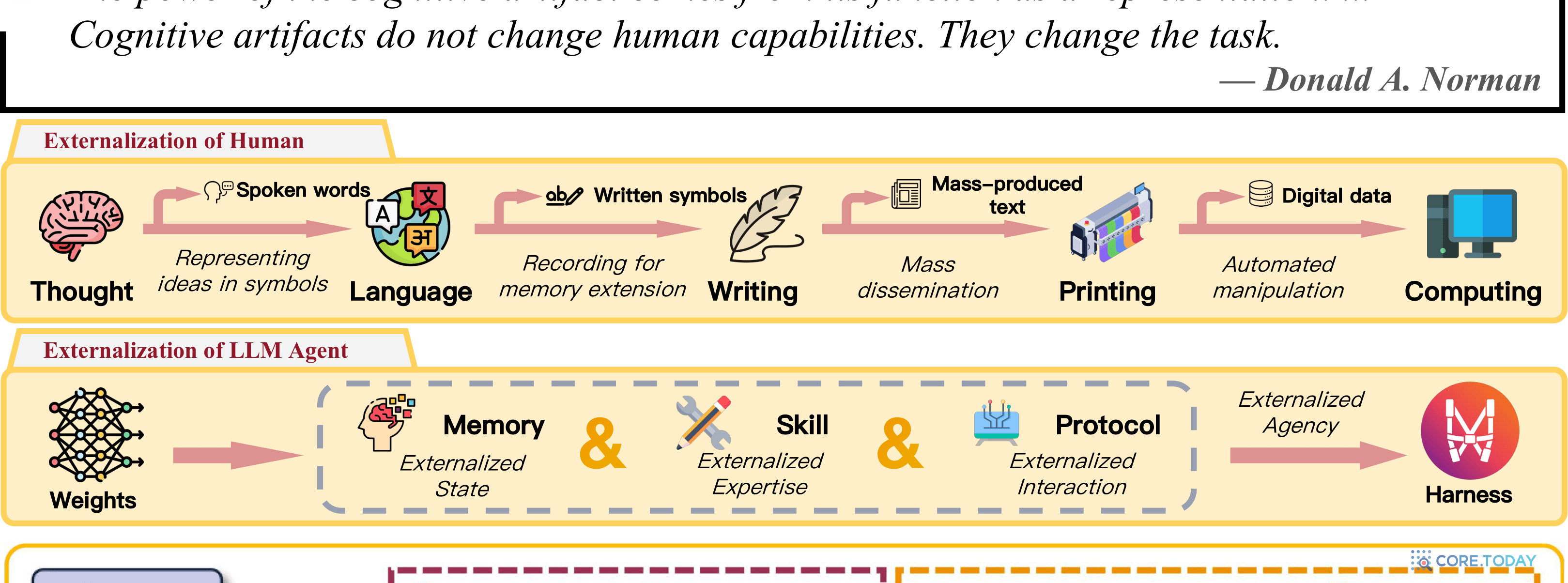
▲ 원문 Fig. 1: Externalization in LLM Agents (arXiv:2604.08224)
인간은 생각을 언어로, 언어를 문자로, 문자를 인쇄로, 다시 컴퓨팅으로 외부화하며 문명을 쌓았다. LLM 에이전트도 똑같이 능력을 가중치(weights)에서 → 기억·스킬·프로토콜로 → 나아가 하네스(harness)로 외부화한다. 인지과학자 도널드 노먼의 말처럼 — "인지적 인공물은 인간의 능력을 바꾸지 않는다. 과업 자체를 바꾼다."
이 프레임에서 기억과 스킬의 차이가 또렷해진다.
기억 vs 스킬 — 무엇을 외부화하는가
Memory · 기억
시간을 가로지른 '상태'
무슨 일이 있었나. '재생성'을 '재인(recognition)'으로 바꾼다 — 과거를 다시 만들지 않고 꺼내 본다
Skill · 스킬
'절차적 전문성'
어떻게 하나. '즉흥'을 '조합'으로 바꾼다 — 매번 짜내지 않고 검증된 부품을 끼운다
논문의 한 문장이 둘의 관계를 정확히 못박는다. "기억은 과거 실행의 증거를 저장하고, 스킬은 그 증거를 재사용 가능한 지침으로 추상화한다." 즉 기억이 쌓이면 스킬이 되고(증류), 스킬이 실행되면 다시 기억을 남긴다.
제2장: 네 갈래의 기억 — 인지과학에서 빌려오다
AI 메모리 연구는 바퀴를 새로 발명하지 않았다. 수십 년 인지심리학이 정리한 인간 기억의 분류를 그대로 빌려왔다. 2026년 학계가 수렴한 분류는 네 갈래다.

| 기억 유형 | 담는 것 | AI에서의 예 |
|---|
작업 기억
Working | 지금 이 순간의 맥락 | 현재 대화·로드된 파일·직전 도구 결과 (= 맥락 창) |
일화 기억
Episodic | 무슨 일이 언제 있었나 | 세션 로그·의사결정 기록·과거 디버깅 흔적 |
의미 기억
Semantic | 요약된 사실·지식 | 사용자 프로필·정리된 선호·도메인 지식 |
절차 기억
Procedural | 일을 하는 방법 | 재사용 스킬·실행 전략 → 승격되면 '스킬'이 된다 |
여기서 우리 시리즈가 한 점으로 모인다. 절차 기억이 명시적인 재사용 지침으로 '승격(promote)'되는 순간, 그것은 더 이상 메모리가 아니라 '스킬'이 된다. 즉 지난 글의 스킬은 사실 메모리의 한 갈래가 독립한 것이었다. 기억과 스킬은 한 몸에서 갈라진 형제다.
네 가지가 함께 '추론 스택'을 이룬다. 절차 기억이 '어떻게'를, 의미 기억이 '정책이 무엇인지'를, 일화 기억이 '무슨 일이 있었는지'를, 작업 기억이 '지금의 추론'을 담당한다.
제3장: 기억의 건축양식 — MemGPT의 '기억 운영체제'
그렇다면 실제 메모리 시스템은 어떻게 만들까? 《Anatomy of Agentic Memory》는 현존 시스템을 네 가지 구조로 분류한다. 원문의 분류 대지도를 그대로 가져온다.
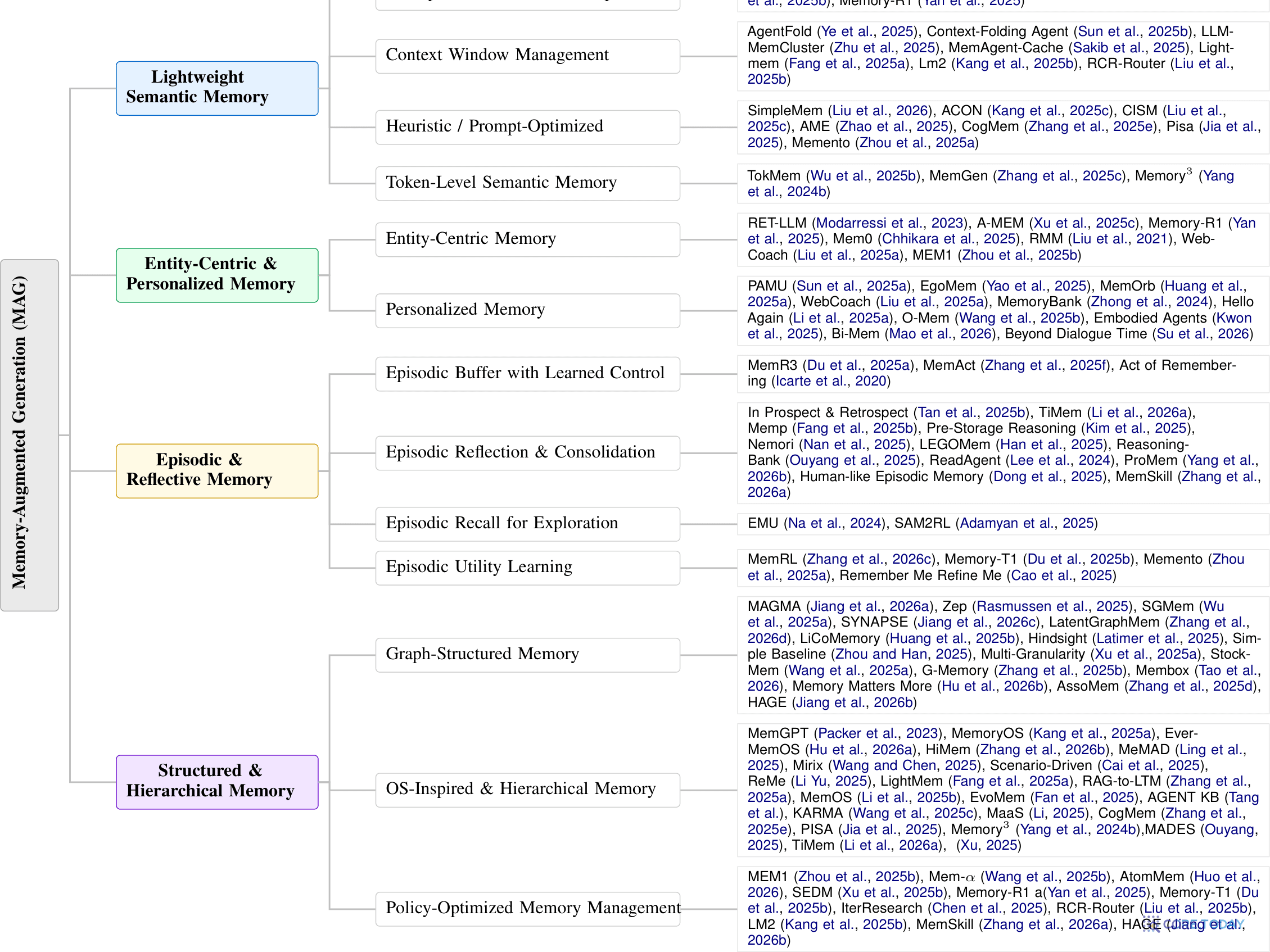
▲ 원문 Fig. 1: Taxonomy of Memory-Augmented Generation systems (arXiv:2602.19320)
메모리 시스템의 4가지 건축양식
① 경량 의미 메모리
텍스트 조각을 벡터로 임베딩해 top-k로 검색. 가볍지만 정밀한 상태 추적엔 약함
② 엔티티 중심·개인화
사용자·과제 단위로 구조화된 레코드. 영속 프로필로 일관된 개인화 (A-MEM 등)
③ 일화·반성 메모리
시간 축으로 에피소드를 조직·압축. 학습된 정책으로 삽입·보존·삭제 (TiMem 등)
④ 구조화·계층 메모리
그래프·다층 구조. MemGPT의 'LLM 주도 메모리 페이징'이 대표 (Zep·MemoryOS)
MemGPT: LLM을 운영체제처럼
이 중 가장 영향력 있는 아이디어가 MemGPT(현 Letta)다. 발상은 컴퓨터 운영체제(OS)에서 빌려왔다. LLM의 맥락 창을 컴퓨터의 RAM처럼 다루는 것.

맥락 창 = RAM
지금 당장 필요한 활성 기억만 올려둔다 (작고 빠르지만 용량 제한)
외부 저장소 = 디스크
최근 대화(recall)와 장기 사실(archival)을 외부에 보관 (느리지만 무제한)
페이징(paging)
에이전트가 메모리 도구로 필요한 기억을 RAM↔디스크로 직접 넘긴다 — 스스로 무엇을 기억하고 잊을지 결정
컴퓨터가 한정된 RAM으로 거대한 프로그램을 돌리듯, MemGPT는 한정된 맥락 창으로 사실상 무한한 기억을 다룬다. Mem0(엔티티 링킹 통합), Zep(시간 지식그래프 Graphiti), Cognee 등 2026년의 주요 시스템들이 이 계보 위에서 저마다의 방식으로 경쟁하고 있다 — 논문의 표현처럼 "아직 단일 승자는 없다."
제4장: 얼마나 잘 기억하나 — 벤치마크의 숫자들
메모리 시스템의 성능은 LoCoMo 같은 벤치마크로 잰다. LoCoMo는 최대 35세션·300턴에 걸친 긴 대화에서 단일홉·멀티홉·시간추론·개방형 질문 1,540개로 '진짜 기억하는지'를 시험한다.
대표 주자 Mem0의 2026년 성적이 메모리의 가치를 잘 보여준다 — 풀컨텍스트(맥락 창에 전부 욱여넣기) 대비 토큰을 4분의 1로 줄이면서 더 높은 점수를 낸다.
※ 적을수록 효율적. Mem0는 약 4배 적은 토큰으로 LoCoMo 92.5점, LongMemEval 94.4점 달성 (전 버전 대비 시간추론 +29.6, 멀티홉 +23.1).
하지만 진짜 장기 기억은 여전히 어렵다. 1,000만 토큰 규모의 BEAM 벤치마크에서는 한계가 드러난다.
※ 규모가 10배 커지자 점수가 약 25% 하락 — '시간적 추상화'는 아직 미해결 과제.
제5장: 불편한 진실 — 메모리 연구의 함정
여기까지면 "메모리는 풀린 문제"처럼 들린다. 그러나 《Anatomy of Agentic Memory》의 진짜 기여는 이 분야의 불편한 진실 네 가지를 실측으로 폭로한 데 있다.
진실 ① 벤치마크가 사실은 기억을 필요로 하지 않는다
논문은 '맥락 포화 격차(Context Saturation Gap, Δ)' — 메모리 시스템과 '그냥 전부 맥락에 넣기'의 성능 차 — 를 제안한다. Δ가 0에 가까우면 그 벤치마크는 메모리 없이도 풀린다. 충격적이게도 HotpotQA·MemBench 등 다수 벤치마크가 '높은 포화 위험'으로, 긴 맥락 LLM이 외부 메모리 없이 풀 수 있었다. "우리가 메모리를 평가한다고 믿었던 시험이, 사실은 맥락 창 크기를 재고 있었다."
진실 ② 채점 자가 틀렸다 (어휘 vs 의미)
전통적 F1 점수는 단어 겹침을 본다. 그런데 메모리 시스템이 옳지만 다른 표현으로 답하면 F1이 부당하게 깎인다. 실제로 AMem은 F1 0.116(5위) 인데 의미 기반 채점에선 0.480(4위) 이었다 — 맞는 답을 어휘 착시로 떨어뜨린 것이다.
진실 ③ '조용한 실패(Silent Failure)'
복잡한 그래프·일화 메모리는 약한 백본 모델 위에서 소리 없이 무너진다. 메모리 쓰기 작업의 형식 오류율을 보자.
※ 메모리 쓰기 형식 오류율. 약한 모델 + 복잡한 구조 = 기억이 조용히 손상된다. 겉으론 멀쩡히 대화하면서.
진실 ④ '에이전시 세금(Agency Tax)'
똑똑한 메모리는 공짜가 아니다. 구조가 복잡할수록 지연과 비용이 폭증한다. 가장 극단적인 MemoryOS는 한 번 답하는 데 32초가 걸렸다.
※ 게다가 AMem은 메모리 구축에만 15시간, Nemori는 700만 토큰을 썼다 — 눈에 안 보이는 '지능세'.
메시지는 분명하다. "더 똑똑한 메모리"가 항상 정답은 아니다. 정확도·지연·비용·안정성 사이에서 균형을 찾아야 하고, 무엇보다 — 당신의 과제에 정말 외부 메모리가 필요한지부터 의심하라.
제6장: 기억의 보안 — 오염된 기억은 사라지지 않는다
지난 보안 글에서 우리는 '오염된 스킬'을 다뤘다. 그런데 기억은 더 무섭다. 한 번 심긴 거짓 기억은 미래의 모든 세션에서 되살아나기 때문이다.
《Toward Mnemonic Sovereignty》(arXiv 2604.16548)는 이를 '기억 주권(mnemonic sovereignty)' 문제로 정의한다. "에이전트가 자기 과거를 통제하는가, 아니면 그 과거가 몰래 다시 쓰일 수 있는가?" 논문은 메모리 공격이 일회성 프롬프트 인젝션과 근본적으로 다른 세 가지 성질을 갖는다고 경고한다.
∞
지속성(Persistence)
초기 대화에 심은 독성 기억이 몇 주 뒤, 수십 개의 무관한 작업에서 반복적으로 되살아난다
~
상태성(Statefulness)
미묘한 편향이 누적되며 에이전트의 행동이 서서히 변질된다 — 한순간의 사고가 아니라 점진적 표류
⇉
전파성(Propagation)
공유 메모리를 통해 사용자·에이전트 경계를 넘어 오염이 옆으로·위로 번진다
공격은 기억의 6단계 생애주기(쓰기→저장→검색→실행→공유→망각) 전반에서 일어난다. 쓰기 단계의 주입, 저장 단계의 '압축으로 증폭되는 독성', 검색 단계의 RAG 오염, 실행 단계의 제어 흐름 탈취(검색된 기억이 사용자 의도를 덮어씀)까지. 실제로 한 연구(Nasr et al.)는 산업계 방어를 90% 넘는 성공률로 우회했다.
핵심 통찰: 메모리 보안은 '능력'이 아니라 '아키텍처'가 결정한다. 항목별 출처(provenance)와 버전 관리가 없는 시스템은 애초에 감사·롤백·검증된 삭제가 불가능하다. 논문이 정의한 9개 거버넌스 원칙을 전부 충족하는 메모리 아키텍처는 아직 하나도 없다. 우리가 COLLEAGUE.SKILL 글부터 강조해 온 '거버넌스 우선 설계'가 기억에서도 그대로 생존 조건인 것이다.
제7장: 통합 그림 — '외부화'로 보는 시리즈 전체
한 발 물러서 보자. 우리가 네 편에 걸쳐 다룬 것들 — 사람의 전문성(COLLEAGUE.SKILL), 스킬(스킬 중심 에이전트), 그 보안(오염된 스킬), 그리고 오늘의 기억 — 은 사실 하나의 거대한 흐름의 부분들이었다. 바로 외부화다.
| 시대 | 능력이 사는 곳 | 핵심 구성 |
|---|
| ~2022 | 가중치(Weights) | 능력이 모델 안에 학습으로 박제됨 |
| 2023 | 맥락(Context) | 프롬프트·few-shot·RAG로 능력 확장 |
| 2024~2026 | 하네스(Harness) | 메모리 + 스킬 + 프로토콜 + 제어 런타임이 서로 맞물려 작동 |
그리고 이 네 구성요소는 깊이 얽혀 있다. 기억→스킬(경험이 절차로 증류), 스킬→기억(실행이 새 흔적을 남김), 기억↔프로토콜(어떤 경로를 따를지 결정), 스킬↔프로토콜(어떻게 발견·호출되는지). 하네스는 이들의 상충(trade-off) 을 조율한다 — 메모리를 늘리면 스킬에 쓸 맥락 예산이 줄어든다. 고정된 컴퓨팅 예산 안에서 이 균형을 맞추는 것, 그것이 2026년 에이전트 엔지니어링의 본질이다.
아직 남은 6가지 숙제
물론 갈 길은 멀다. Mem0 팀이 꼽은 미해결 과제들이 현실을 보여준다.
2026년 에이전트 메모리의 미해결 과제
시간적 추상화
규모가 10배 커지면 성능 25% 하락 — 진짜 장기 기억은 여전히 난제
기억의 진화
대부분 시스템이 '변화'를 '교체'로 처리 — 사람처럼 기억을 다듬어 발전시키지 못함
기억의 노화(staleness)
한때 맞던 사실이, 상황이 바뀐 뒤에도 '자신 있게 틀린' 답으로 남는다
여기에 개인정보(누가 기억을 들여다보나, 얼마나 보관하나), 익명·멀티기기 환경의 신원 연결까지 — 기술과 거버넌스가 함께 풀어야 할 숙제가 쌓여 있다.
마치며: 기억하는 기계, 그리고 잊을 줄 아는 기계
AI에게 기억을 주는 일은 단순히 '용량을 늘리는' 문제가 아니다. 무엇을 기억하고, 무엇을 잊고, 누구의 기억을 믿을지를 설계하는 일이다. 인간이 모든 것을 기억하지 않기에 지혜로울 수 있듯, 좋은 AI 메모리의 핵심도 결국 '잘 잊는 법' 에 있다.
2026년, AI는 드디어 어제를 기억하기 시작했다. 다음 질문은 더 어렵다 — 그 기억을 어떻게 믿고, 어떻게 다스릴 것인가. 코어닷은 그 답이 '거버넌스를 처음부터 설계에 넣는 것'에 있다고 본다. 기억하는 기계의 시대에, 진짜 경쟁력은 신뢰할 수 있는 기억에서 나온다.
참고 자료 / 출처




