Knowledge Work를 위한 Codex — 코드를 못 짜도 되는 AI (Codex Use Cases 특집 5)
Codex use case의 절반은 코드가 아니다. 코딩 에이전트가 어떻게 비개발자를 돕는가 — 보이지 않는 코드와 편집 가능한 산출물 원칙으로 캐시플로우·DCF·데이터 청소·미팅 브리프·슬라이드 덱을 만드는 법을 비개발자 눈높이로 풀어봅니다. Codex Use Cases 특집 5편.
이게 "코딩 에이전트가 비개발자를 돕는 다리"입니다. 1편에서 본 샌드박스(안전 펜스가 있는 놀이터)가 여기서 데이터 처리장으로 쓰이는 거죠. 이 일은 $로 시작하는 스킬을 통해 불러냅니다 — $spreadsheets(엑셀), $slides(PPT), $documents/$doc(문서), $pdf, $imagegen(이미지).
그리고 이번 편에서 가장 중요한 두 원칙이 있습니다.
1
편집 가능한 산출물 — 죽은 표가 아니라 살아있는 모델
$spreadsheets는 openpyxl로 셀에 계산된 숫자가 아니라 수식 자체를 씁니다 (예: =B5*(1+가정!B2)). 그래서 재무 담당자가 파일을 열어 가정을 계속 바꿔가며 직접 시나리오를 돌릴 수 있습니다. 슬라이드도 $slides가 PptxGenJS로 만들어, 차트가 진짜 편집 가능한 PowerPoint 차트입니다.
2
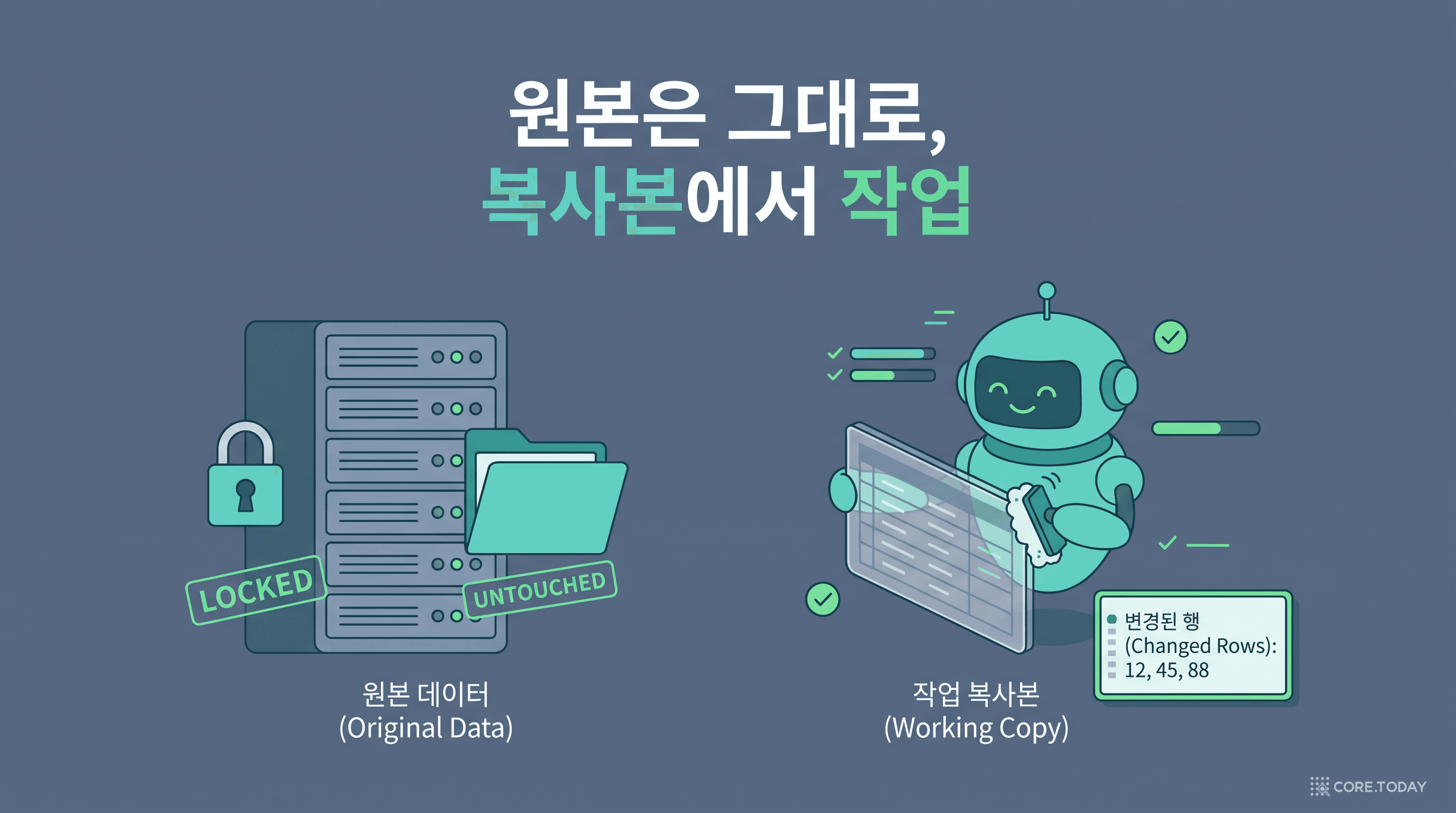
원본은 절대 건드리지 않는다
데이터 작업은 항상 복사본에서. 원본 파일은 그대로 두고, 행 ID를 보존하며, 바꾼·지운·불확실한 행을 적은 데이터 품질 노트를 따로 남깁니다.
무엇을 시키면 무엇을 받는지, 아래에서 직접 눌러보세요.
이 두 원칙(편집 가능 + 원본 보존)을 머리에 넣고, 각 직군의 작업으로 들어갑니다.
2. 파이낸스 ① — 캐시플로우 예측, 가정 하나가 만드는 차이
재무에서 가장 조마조마한 질문. "우리 자금, 언제 가장 위험해지지?"Forecast Cash Flow는 이걸 편집 가능한 13주 롤링 예측으로 답합니다.
기초 현금, 예상 수금, 급여, 거래처 결제 조건, 안전 현금 임계값을 주면 Codex가 워크북을 짭니다.
캐시플로우 — 프롬프트
요청
"$spreadsheets로 첨부 파일들로부터 편집 가능한 캐시플로우 예측 워크북을 만들어줘."
"유동성 바닥점, 최저 기말 잔액, 안전 임계값 위반을 표시하는 요약 뷰를 포함할 것."
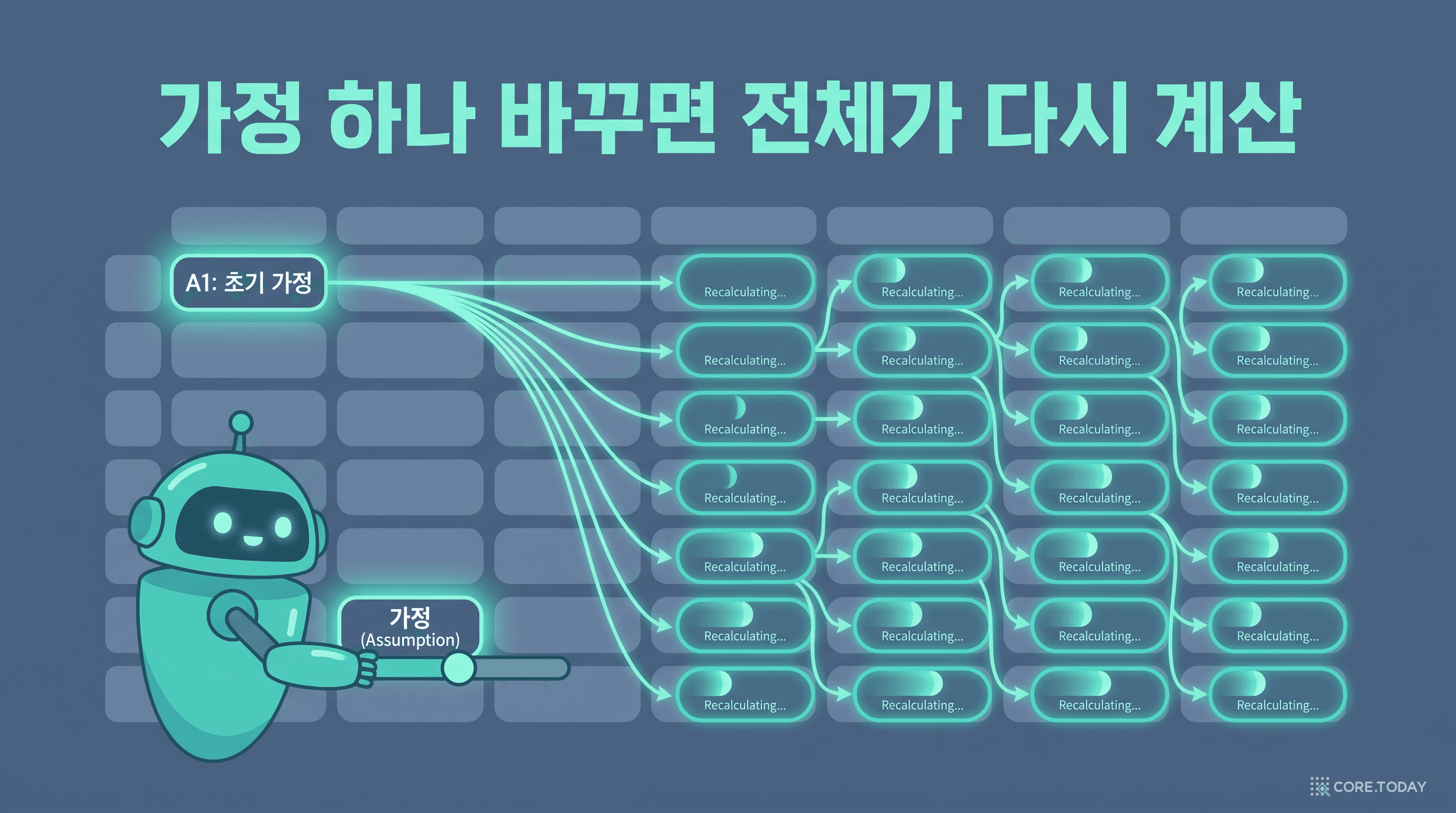
핵심은 "살아있는 수식"입니다. 수금이 며칠 늦어진다는 가정 하나를 바꾸면, 그 효과가 13주 전체에 도미노처럼 번집니다. 아래에서 직접 슬라이더를 움직여 보세요 — 자금 바닥이 어떻게 깊어지고, 어느 순간 임계값을 깨는지 보입니다.
여기서 결정적 차이가 드러납니다. Codex가 던져주는 건 어제 숫자가 박힌 죽은 표가 아닙니다. 모든 칸이 수식으로 연결된 살아있는 모델이라, 재무 담당자가 파일을 받아 자기 손으로 시나리오를 계속 돌릴 수 있습니다. 회의 들어가기 전에 검토 가능한, 수식으로 연결된 예측 — 그게 산출물입니다.
3. 파이낸스 ② — DCF 밸류에이션 & 예산 대비 실적
같은 "편집 가능 + 가정 투명" 원칙이 더 무거운 모델에도 적용됩니다.
Model DCF Valuation은 3년 재무제표·가정 시트·모델링 노트를 받아 명시적 드라이버(매출 성장률, 마진, capex, 운전자본) → 무차입 잉여현금흐름 → WACC → 잔존가치 → 기업가치 → 자기자본가치로 이어지는 다탭 워크북을 만듭니다. 여기서 못 박는 규칙이 인상적입니다.
"가정이 빠졌으면, 수식 안에 숨기지 말고 가정 탭에 라벨 붙은 placeholder를 둘 것."
가정을 지어내지도(no fabricated inputs), 수식 속에 감추지도(no black box) 않습니다. 사람이 모든 가정을 보고 따질 수 있게 하는 거죠.
Review Budget vs. Actuals도 비슷합니다. 예산안 + 실적 추출(GL) + 마감 노트를 받아 변동(금액·%)을 수식으로 계산하고, 유리/불리(favorable/unfavorable)를 판정합니다. 그리고 중요한 분리를 합니다.
노트로 설명되는 변동
사람이 답해야 할 미해결 질문
"마케팅비 +12% — 3월 캠페인 집행(노트 근거)"
"출장비 +40% — 근거 노트 없음, 확인 필요"
근거가 있으니 그대로 보고
임의로 추측하지 않고 질문으로 남김
그리고 원본 탭은 감사 추적(audit trail)을 위해 그대로 보존하고, 계산 탭을 따로 추가합니다. 2편 엔지니어 편에서 본 "증거로 닫는다"가 재무에선 "근거 있는 것과 추측을 분리한다"로 나타나는 셈입니다.
4. 데이터 작업 — 청소하고, 묻고, 리포트로
이제 모든 직군이 부딪히는 일, 지저분한 데이터입니다. 세 use case가 한 흐름을 이룹니다.
Clean and Prepare Messy Data — 날짜 형식이 뒤섞이고, 통화에 원·콤마가 붙고, 중복과 요약행이 끼어든 CSV를 던집니다.
데이터 청소 — 프롬프트
요청
"@매출-export.csv를 정리해줘. 정리된 CSV를 새로 쓰되 원본은 그대로 둘 것."
"날짜는 한 형식으로 통일하고, 바꾼·지운·자신 없이 둔 행을 적은 데이터 품질 노트를 함께 줘."
Query Tabular Data — 정리됐으면 평범한 말로 묻습니다. "지난 분기에 가장 많이 변한 고객 세그먼트는?" Codex는 분석 전에 컬럼부터 검사하고, 샌드박스에서 분석한 뒤, HTML 차트를 만들어 브라우저에 띄웁니다. 같은 스레드에서 "지역별로 다시 쪼개줘" 같은 후속도 가능하죠.
Analyze Datasets and Ship Reports — 더 무거운 루프입니다. 가져오기 → 정리 → 변환·모델링 → 전달. AGENTS.md에 규칙(폴더, Python 컨벤션, 출력 표준)을 적어두면, Codex가 조인 전에 키의 유일성·널·매칭률을 점검하고, 분석 후 Matplotlib/Seaborn 차트와 함께 .docx·.pdf·메모를 발행합니다. 여기서도 철칙은 하나.
"결측치나 조인 키를 지어내지 말 것." 모르면 모른다고 표시합니다. 이게 데이터 작업에서 신뢰의 핵심입니다.
Prepare Meeting Briefs는 회의명·날짜·승인된 소스를 받아, 먼저 도달 가능한 소스를 인벤토리합니다 — @google-calendar, @google-drive, @slack, @gmail. 그런 뒤 목적, 참석자 맥락, 출처가 뒷받침하는 사실, 예상 의제, 미해결 질문, 그리고 결정/담당/기한/리스크를 적을 노트 템플릿까지 초안을 냅니다. 검증 안 된 주장은 "소스 갭" 섹션에 격리하고요.
여기 중요한 기술 선택이 있습니다. Codex는 슬라이드를 만들 때 python-pptx가 아니라 PptxGenJS(자바스크립트)를 씁니다. 왜일까요?
python-pptx (지양)
PptxGenJS (사용)
이미지처럼 굳은 결과가 되기 쉬움
텍스트가 편집 가능한 텍스트 객체로
읽기·검사 용도로만 권장
차트가 네이티브 PowerPoint 차트(막대·선·파이)로
즉, 받은 사람이 PowerPoint에서 숫자를 고치고 차트를 다시 그릴 수 있습니다. 작업 방식도 꼼꼼합니다 — 기존 브랜드 템플릿을 주면 비율·기하를 맞추고, 텍스트·차트를 PptxGenJS로 편집하고, 일러스트는 $imagegen으로 생성한 뒤, 각 슬라이드를 PNG로 렌더해 넘침·폰트·정렬을 자가검증합니다. 그리고 .pptx와 함께 "무엇이 바뀌었는지" 노트를 줍니다. 매주·매달 반복되는 정기 보고에 특히 강하죠. (이 "렌더해서 자가검증"은 3편 비주얼 루프, 4편 시뮬레이터 루프와 같은 가족입니다.)
한 운영 담당자의 월요일 아침
지금까지의 use case도 따로 노는 게 아니라 한 스레드로 이어집니다. 매주 월요일 주간 실적 보고를 만드는 운영 담당자를 상상해 봅시다.
9:00
영업팀이 보낸 지저분한 주간 매출 CSV(날짜 뒤섞임, 중복, 요약행)를 던진다 → Codex가 복사본에 정리하고 데이터 품질 노트를 남긴다. 원본은 그대로.
9:10
"지난주 대비 가장 많이 변한 고객 세그먼트는?" → 컬럼을 먼저 검사한 뒤 분석, HTML 차트로 한눈에. "지역별로 다시 쪼개줘" 후속도 같은 스레드에서.
9:25
예산 대비 실적을 $spreadsheets로 갱신 — 변동을 수식으로 계산하고, 근거 있는 변동과 확인 필요 항목을 분리.
9:40
그 결과를 $slides로 브랜드 템플릿에 맞춘 편집 가능한 덱으로. 임원이 PowerPoint에서 숫자를 직접 만질 수 있는 상태로 공유.
40분. 그동안 담당자가 한 일은 파일을 던지고, 질문하고, 결과를 검토한 것뿐입니다. 청소·분석·계산·작도는 코드가 무대 뒤에서 처리하고, 앞에는 바로 고칠 수 있는 결과물만 쌓였습니다. 이게 비개발자에게 "코딩 에이전트"가 실제로 의미하는 바입니다.
7. 새 개념 학습 — 병렬 서브에이전트로
마지막은 모든 직군에 해당하는 일, 빠르게 배우기. Learn a New Concept는 빽빽한 논문·자료를 명료한 학습 리포트로 바꿉니다.
흥미로운 건 방식입니다. Codex가 병렬 서브에이전트를 띄웁니다 (1편에서 본 서브에이전트가 여기 쓰입니다).
코드를 짜는 4편의 작업이든, 코드를 모르는 이번 편의 작업이든, Codex의 본질은 같습니다 — 사람은 가정·맥락·판단을 제공하고, Codex는 그걸 실행 가능한 산출물로 바꾼다. 다만 여기선 코드가 무대 뒤로 완전히 숨고, 사람 앞엔 바로 쓰고 계속 고칠 수 있는 결과물만 남습니다.
재무 담당자가 수식을 직접 검증하고, 기획자가 PRD의 인용을 따라가 확인하고, 운영팀이 데이터 품질 노트를 읽는 것 — 이 판단의 몫은 여전히 사람에게 있습니다. Codex는 코드라는 장벽을 치워줄 뿐, 책임까지 가져가진 않습니다.
9. 다음 편 예고 — 시리즈의 마지막
코드를 못 짜는 사람도 Codex로 캐시플로우를 모델링하고, 데이터를 정리하고, PRD와 덱을 만드는 법을 봤습니다. 핵심은 보이지 않는 코드 + 편집 가능한 산출물이었습니다.