엔지니어를 위한 Codex — 이해·검토·이전의 기술 (Codex Use Cases 특집 2)
엔지니어의 하루는 새 코드 작성이 아니라 이해·검토·개선·이전이다. Codex가 거대 코드베이스 파악, PR 리뷰, 리팩토링, 마이그레이션, CLI 자가제작, 보안 감사, 스코어 기반 반복을 어떻게 돕는지 실제 프롬프트와 사례로 풀어봅니다. Codex Use Cases 특집 2편.
지난 1편에서 우리는 Codex가 "코드 자동완성기"에서 "디지털 작업 에이전트"로 진화한 역사와 아키텍처를 살펴봤습니다. 이제 가장 본진인 개발 현장으로 들어갑니다.
여기서 솔직해질 필요가 있습니다. 시니어 엔지니어의 하루를 떠올려 보세요. 텅 빈 파일에 멋진 새 기능을 처음부터 짜는 시간이 얼마나 될까요? 현실은 대부분 이렇습니다.
처음 보는 20만 줄짜리 코드베이스에서 "이 결제는 도대체 어디서 처리되지?"를 찾는 일
남이 올린 PR을 읽으며 "이거 회귀 버그 생기는 거 아냐?"를 걱정하는 일
5년 묵은 모듈에서 죽은 코드를 걷어내고 현대적 패턴으로 바꾸는 일
레거시 프레임워크를 신규 스택으로 조심조심 옮기는 일
새벽에 뜬 보안 권고를 보며 "우리 이거 영향받나?"를 조사하는 일
Codex의 use case 카탈로그에서 엔지니어링 항목들이 정확히 이 지점들을 겨냥합니다. 화려한 "AI가 앱을 5분 만에 만들어줌"이 아니라, 재미없지만 시간을 가장 많이 잡아먹는 일을 대신합니다. 이 글은 그 8가지를 엔지니어의 작업 흐름 순서대로 따라갑니다.
1. 먼저 어휘 정리 — Codex 엔지니어링의 3종 도구
본문에 들어가기 전, 2편 내내 반복해서 등장할 세 가지 개념을 먼저 짚겠습니다. 이 셋만 알면 나머지가 술술 읽힙니다.
개념
정체
비유
AGENTS.md
저장소에 두는 지침 파일. 코드 스타일·테스트법·금지사항·리뷰 규칙을 적어둠
신입에게 주는 온보딩 문서
ExecPlan
여러 세션에 걸친 작업의 장기 계획 문서. 종착 상태와 각 단계 검증을 기록
장기 프로젝트의 공사 설계도 + 작업일지
Skills ($이름)
재사용 가능한 절차. $cli-creator, $skill-creator, $openai-docs 등
반복 업무용 매크로 / 표준작업서
특히 AGENTS.md가 핵심입니다. Codex는 수정하려는 파일에 가장 가까운 AGENTS.md를 적용합니다. 즉 디렉터리마다 다른 규칙을 둘 수 있습니다 — /payments 폴더엔 "PII를 로그에 남기지 마라", /auth 폴더엔 "모든 라우트에 인증 미들웨어를 감싸라" 같은 식으로요. 사람 팀원에게 "이 동네에선 이렇게 일해" 하고 알려주는 것과 똑같습니다.
이제 엔지니어의 하루를 따라가 봅시다.
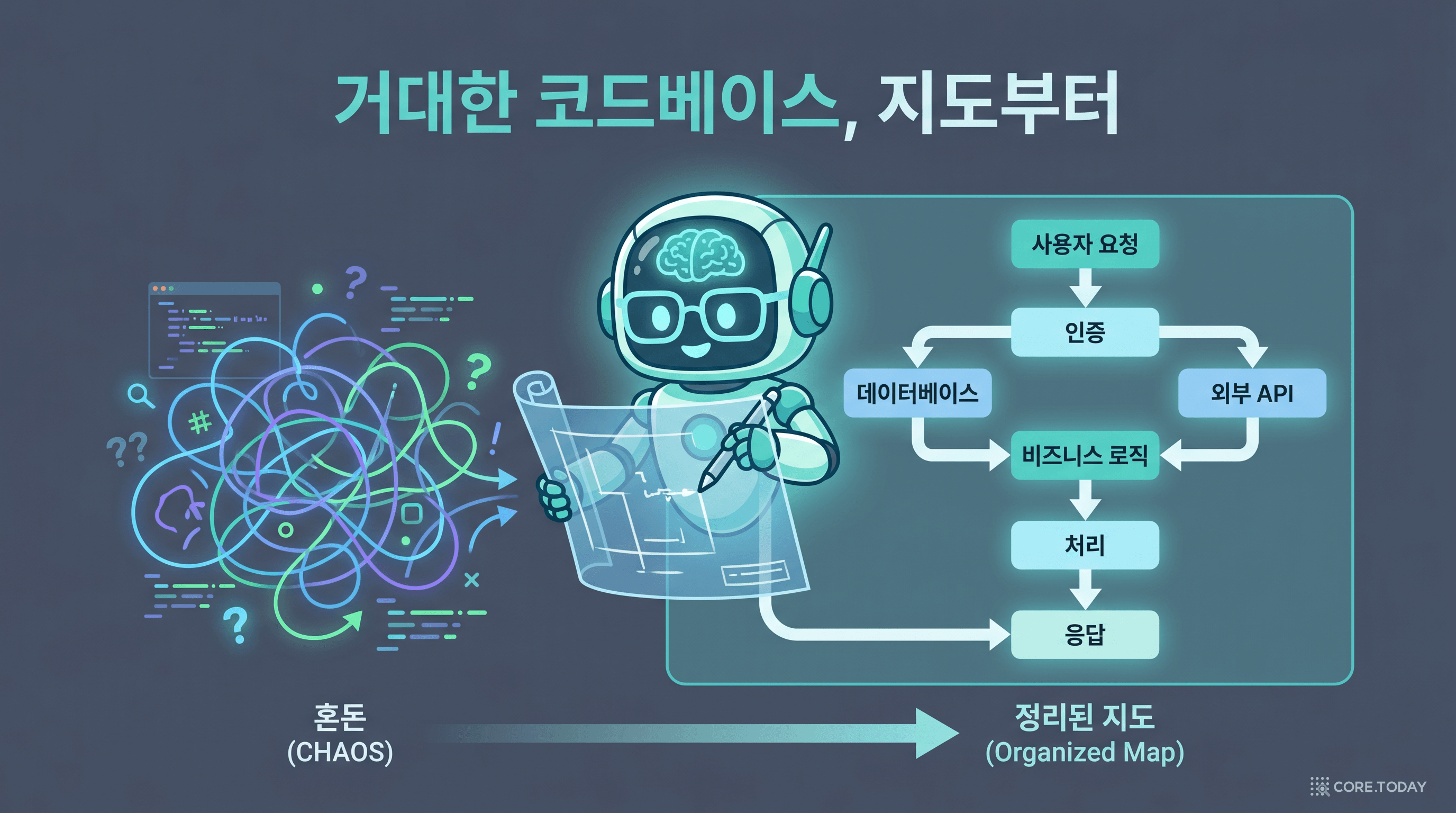
2. 이해 — 거대한 코드베이스, 지도부터 그린다
새 프로젝트에 투입된 첫 주를 떠올려 보세요. 코드는 방대하고, 문서는 낡았고, 원작자는 퇴사했습니다. 어디서부터 읽어야 할지 막막합니다. 잘못 건드리면 아키텍처를 깨뜨리기 십상이죠.
Codex의 Understand Large Codebases는 "파일 목록"이 아니라 구조의 지도를 그려줍니다. 실제 문서가 권장하는 시작 프롬프트는 이렇습니다.
코드베이스 온보딩 — 시작 프롬프트
요청
"<시스템 영역>에서 요청이 어떻게 흐르는지 설명해줘. 포함할 것:
- 어느 모듈이 무엇을 담당하는지
- 데이터가 어디서 검증되는지
- 변경 전에 주의할 가장 큰 함정들"
예를 들어 처음 보는 커머스 서비스에서 "체크아웃 요청이 들어와서 결제가 끝날 때까지 전 과정을 추적해줘"라고 하면, Codex는 샌드박스 읽기 전용 모드로 코드를 훑으며 이런 답을 만듭니다.
HTTP 핸들러 POST /checkout — 입력 검증은 여기서
↓
CartService — 비즈니스 로직(재고·할인 계산)
↓
PaymentGateway 어댑터 — 외부 호출 · 재시도 로직(함정!)
↓
OrderRepository — 영속화 + 결제 후 비동기 이메일 잡(놓치기 쉬움)
이어서 "비즈니스 로직을 가진 모듈은 전송/UI 계층과 어떻게 분리돼 있어?", "이 흐름을 바꾸면 같이 깨질 수 있는 백그라운드 잡은 뭐야?" 같은 후속 질문을 던지면 됩니다. 핵심은 편집을 시작하기 전에 읽어야 할 파일 목록과 함정을 미리 받는다는 것. 온보딩에 쓰던 며칠이 한 번의 대화로 줄어듭니다.
사람 멘토에게 "이 동네 구조 좀 설명해줘"라고 묻는 것과 같습니다. 다만 이 멘토는 24시간 깨어 있고, 20만 줄을 몇 분 만에 읽습니다.
3. 검토 — PR에 @codex를 부르면 벌어지는 일
코드를 이해했으니 이제 남의 코드를 검토할 차례입니다. PR 리뷰는 팀의 품질을 지키는 마지막 보루지만, 동시에 가장 미뤄지는 일이기도 합니다. Codex의 Review GitHub Pull Requests는 사람 리뷰 앞단에 자동 검토 한 겹을 더합니다.
작동 방식은 단순합니다. 저장소 설정에서 Code review를 켜면(원하면 모든 새 PR을 자동 검토하게도 가능), PR에서 이렇게 부릅니다.
@codex 리뷰 플로우GitHub
호출@codex review 또는 범위 지정: @codex review for security regressions, missing tests, and risky behavior changes
반응Codex가 👀 이모지로 접수 표시 → 클라우드 샌드박스에서 PR을 분석
결과일반 GitHub 리뷰 형식으로 코멘트 게시. 고치라고 하면: @codex fix the P1 issue → 클라우드 태스크가 PR을 업데이트
여기서 중요한 설계 철학이 있습니다. Codex는 시시콜콜 다 지적하지 않습니다. P0/P1급(심각/중요) 문제에 집중합니다 — 보안 회귀, 빠진 테스트, 위험한 동작 변경, 의존성·인증 변경 같은 것들. 사소한 스타일 잔소리로 리뷰를 도배하지 않죠. "노이즈를 줄여야 사람이 진짜 문제를 본다"는 것입니다.
그리고 앞서 배운 AGENTS.md가 여기서 빛납니다. 리뷰 규칙을 저장소에 박아둘 수 있습니다.
AGENTS.md — 리뷰 가이드라인 예시
## Review guidelines
- PII(개인정보)를 로그에 남기지 말 것
- 인증 미들웨어가 모든 라우트를 감싸는지 검증할 것
그러면 Codex의 리뷰가 우리 팀 규칙에 맞춰집니다. 새 라우트에 인증이 빠졌다면? 사람이 보기 전에 Codex가 먼저 잡습니다.
터미널파를 위한 짝도 있습니다. CLI 세션에서 /review 슬래시 명령으로 아직 커밋 안 한 변경(staged·unstaged·untracked)을 읽기 전용으로 검토할 수 있고, 이를 프리커밋 훅으로 걸어 치명적 문제가 있으면 커밋을 막도록 할 수도 있습니다. PR을 올리기도 전에 자가 검열이 되는 셈입니다.
4. 개선 — 리팩토링은 "작은 패스"의 예술
코드는 시간이 지나면 썩습니다. 죽은 코드, 안 쓰는 기능 플래그, 옛 호환 레이어, 비대해진 모듈, 복붙된 경로… Refactor Your Codebase는 이걸 전면 재작성 없이 정리합니다.
비결은 작고 리뷰 가능한 패스로 쪼개는 것입니다. 먼저 지도부터 그립니다.
리팩토링 — 매핑 프롬프트
요청
"이 코드베이스를 분석해서 죽은 코드, 중복 경로, 비대한 모듈, 변경을 느리게 만드는 레거시 패턴을 찾아줘."
그다음 각 패스마다 세 가지를 명시하게 합니다: (a) 현재 동작, (b) 구조 개선점, (c) 최소 검증. 그리고 각 패스 뒤에 기존 테스트를 돌려 동작이 안 바뀌었는지 확인합니다. 공개 API는 건드리지 않습니다. 프레임워크 교체나 의존성 변경처럼 큰 건은 별도 작업으로 미룹니다.
1
문제 — 큰 리팩토링 PR은 리뷰가 불가능하다
2,000줄짜리 "정리 PR"은 아무도 제대로 리뷰 못 한다. 회귀 버그가 숨어도 못 찾는다.
2
해결 — 작은 패스 + 패스마다 테스트
한 번에 한 가지 구조 개선만. 여러 모듈·여러 세션에 걸치면 ExecPlan에 종착 상태와 진행을 기록해 길을 잃지 않는다.
3
결과 — 리뷰 부담↓, 회귀 조기 발견
각 패스가 작아 리뷰가 쉽고, 문제가 생겨도 그 패스만 되돌리면 된다.
5. 이전 ① — 마이그레이션은 "체크포인트"로 건넌다
리팩토링보다 무서운 게 마이그레이션입니다. 레거시 프레임워크를 신규 스택으로 옮기는 일은 "큰맘 먹고 한 방에 다시 짜기"의 유혹이 큽니다. 그리고 그 한 방은 거의 항상 지옥으로 끝나죠. Code Migrations의 철학은 정반대입니다 — 작은 체크포인트로 나눠 건넌다.
아래 인터랙티브로 그 리듬을 직접 따라가 보세요. 레거시 Express 모놀리스를 모던 스택으로 옮기는 과정입니다.
핵심은 parity proof(동등성 증명)입니다. 각 체크포인트가 끝날 때마다 "옛것과 새것이 같게 동작하는가"를 가장 작은 방법으로 증명합니다 — 타입체크, 계약 테스트, 스모크 테스트, 또는 레거시와 응답을 나란히 비교. 그리고 사람이 diff와 남은 리스크를 리뷰합니다. 실패하면? 전체가 아니라 그 체크포인트만 롤백합니다. 폭발 반경(blast radius)이 작아지는 거죠. 옛 코드와 새 코드가 잠시 공존하도록 호환 레이어(adapter)를 두는 것도 이 때문입니다.
6. 이전 ② — "모델 이름만 바꾸면 끝"이 아니다
마이그레이션의 특수한 사례가 하나 있습니다. AI 앱을 쓴다면 모델 자체를 업그레이드해야 할 때가 옵니다. Upgrade Your API Integration이 이걸 다룹니다. 그리고 여기엔 엔지니어가 자주 데이는 함정이 있습니다.
"모델 이름만 gpt-4o → 최신 모델로 바꾸면 되겠지?" — 아닙니다.
새 모델은 API 형태(예: 어시스턴트 메시지에 새 파라미터 추가)도, 잘 먹는 프롬프트도 달라집니다. 이름만 바꾸면 조용한 회귀가 생깁니다 — 에러는 안 나는데 품질이 슬그머니 떨어지는 거죠. 가장 무서운 종류입니다.
Codex는 $openai-docs 스킬로 최신 모델·프롬프트 가이드를 참고하며 업그레이드합니다.
API 통합 업그레이드 — 프롬프트
요청
"$openai-docs를 써서 이 OpenAI 통합을 최신 권장 모델과 API 기능으로 업그레이드해줘. 특히 이 모델에 맞는 최신 모델·프롬프트 가이드를 찾아봐."
그리고 결정적인 한 걸음 — evals(평가)로 회귀를 잡습니다. 업그레이드 전후의 출력을 같은 평가 세트로 채점해 품질이 떨어지지 않았는지 확인하는 것이죠. 프롬프트·도구·응답 형태가 바뀌는 지점은 사람 리뷰로 표시합니다.
인벤토리
현재 쓰는 모델·엔드포인트·도구 가정을 목록화
최소 경로
최신 지원 경로로 가는 가장 작은 변경안 (불필요한 동작 변경 금지)
프롬프트 갱신
새 모델 가이드에 맞춰 프롬프트 조정, 변경점은 사람 리뷰로
evals
평가 세트로 회귀 확인 → 통과해야 머지
이 "evals 플라이휠"은 다음 섹션에서 더 깊게 나오는 주제입니다.
7. 도구화 — 에이전트가 자기 도구를 만든다
이건 좀 메타한 use case입니다. Create Agent-Friendly CLIs — Codex가 자기 자신이 쓸 도구를 만드는 것입니다.
왜 필요할까요? 에이전트에게 "CI 로그 가져와서 첫 실패 단계 알려줘" 같은 반복 작업을 매번 시키면, 그때그때 다른 방식으로 즉흥 처리하고(일관성 없음), 거대한 로그 전문을 컨텍스트에 욱여넣다 토큰을 낭비합니다. 그래서 표준화된 CLI를 한 번 만들어 두는 겁니다. 그러면 에이전트는 매번 파싱하느라 머리 쓰는 대신, 추론에만 집중합니다.
만드는 법도 스킬로 정형화돼 있습니다.
CLI + 동반 스킬 만들기
요청
"$cli-creator로 쓸 CLI를 만들고, 같은 스레드에서 $skill-creator로 동반 스킬도 만들어줘."
학습 소스: [API 문서 / OpenAPI / 가린 curl 예시 / 로그 폴더…]
첫 기능: "빌드 URL에서 실패한 CI 로그 다운로드, 지원 티켓 검색 후 ID로 하나 읽기"
검증 조건
command -v [cli-name]가 소스 폴더 밖에서도 성공할 것
[cli-name] --help가 주요 명령을 설명할 것
잘 만든 에이전트용 CLI의 설계 원칙은 사람용과 조금 다릅니다.
원칙
이유
페이지 단위 검색 + ID로 정확히 읽기
전문을 통째로 안 받고 필요한 것만 → 컨텍스트 절약
예측 가능한 JSON 출력
에이전트가 안정적으로 파싱
읽기는 안전, 쓰기는 승인 게이트
draft-before-write — 위험한 작업은 사람 확인 후
PATH 설치
어느 폴더에서든 실행 가능
이렇게 한번 $ci-logs 같은 도구와 스킬을 만들어두면, 다음부턴 "이 빌드의 실패 로그 받아서 첫 실패 단계 알려줘"라고만 하면 됩니다. 에이전트가 매주 스스로 재사용하는 거죠.
8. 보안 — "절대 실행하지 마" 모드의 감사
새벽 2시, 의존성 패키지에 치명적 보안 권고가 떴습니다. 악성 postinstall 스크립트가 심겼고, CI에 넓은 배포 토큰이 있다는군요. 패닉이 시작됩니다. Dependency Incident Audits는 이 순간을 위한 use case입니다.
여기서 가장 중요한 건 하지 말아야 할 것입니다. 인시던트 대응 중에 섣불리 패키지를 설치하거나 스크립트를 돌리면 오히려 악성 코드를 실행하게 됩니다. 그래서 이 작업은 철저히 읽기 전용 증거 수집으로 시작합니다.
의존성 감사 — 안전 제약 (반드시 명시)
금지 사항
"내가 명시적으로 승인하기 전에는 패키지 설치·라이프사이클 스크립트 실행·프로젝트 빌드·신뢰할 수 없는 코드 실행·자격증명 회전·파일 정리를 하지 마."
이 제약 위에서 Codex는 공개 권고문을 감사 계획으로 바꿉니다: 영향받는 패키지·버전 범위를 정리하고, 매니페스트·락 파일·CI 워크플로와 권한·postinstall 같은 설치 스크립트·벤더링된 산출물·토큰 노출 경로를 읽기만 하며 점검합니다. 그리고 각 항목을 세 가지 상태로 보고합니다.
증거 기반 노출 판정
Confirmed
노출 확인 — 파일 근거 + 심각도/blast radius
Needs verification
추가 확인 필요 — 단정 금지
Ruled out
노출 아님 — 근거와 함께 배제
예를 들어 "취약 버전이 우리 락 파일에 있나? CI에 배포 권한이 있나? postinstall이 실제로 도나?"를 아무것도 실행하지 않고 판정합니다. 그다음에야 사람 승인을 받아 remediation PR을 준비하거나 CI 권한을 조이거나 인시던트 노트를 작성합니다. 증거 수집과 조치를 분리하는 것 — 이게 패닉 상황에서 사고를 더 키우지 않는 비결입니다.
9. 막힌 문제 뚫기 — "첫 합격"에서 멈추지 않는 루프
마지막은 가장 흥미로운 use case입니다. Iterate on Difficult Problems — Codex를 점수 기반 개선 루프로 굴리는 것입니다.
어려운 작업(예: 까다로운 UI 컴포넌트 최적화, 성능 튜닝)은 "한 번에 정답"이 안 나옵니다. 그래서 이렇게 시킵니다: AGENTS.md를 읽고 → 채점 스크립트를 찾고 → 기준선을 재고 → 한 번에 하나만 바꾸고 → 다시 채점하고 → 점수와 변경 내용을 기록하고 → 반복. 그리고 전체 점수와 LLM 심판 평균이 둘 다 임계값을 넘을 때까지 멈추지 않습니다.
아래에서 직접 한 번씩 "반복"을 눌러 점수가 오르는 걸 보세요.
여기서 두 종류의 점수를 함께 보는 게 핵심입니다.
점수
재는 것
한계
결정적 점수
정렬 위반·제약 위반 등 기계가 명확히 채점
"규칙은 지켰지만 못생긴" 결과에 갇힐 수 있음
LLM 심판 점수
가독성·심미성·사용성 등 주관적 평가
측정이 흔들릴 수 있음
결정적 지표만 보면 "통과는 했는데 영 별로인" 결과에서 멈추고, LLM 심판만 보면 점수가 들쭉날쭉합니다. 둘을 함께 보면 품질이 "첫 합격"에서 정체되지 않고 계속 올라갑니다. 그리고 긴 세션 동안 점수 로그가 "지금 어디까지 왔는지"를 눈에 보이게 해줍니다. OpenAI가 공개한 "스스로 개선하는 세무 에이전트" 사례도 바로 이 패턴입니다.
10. 관통하는 한 가지 — 사람의 역할이 바뀐다
여덟 가지 use case를 따라왔습니다. 그런데 자세히 보면 같은 부품들이 계속 등장했습니다.
엔지니어링 use case를 떠받치는 공통 기둥
AGENTS.md디렉터리별 지침리뷰 규칙·금지사항·스타일을 코드 곁에
ExecPlan장기 계획리팩토링·마이그레이션의 종착 상태와 진행
Sandbox읽기 전용 / 승인 게이트이해·감사는 안전하게, 쓰기는 확인 후
Evals점수 기반 검증업그레이드·난제의 회귀를 잡는 자
그리고 모든 use case에 공통된 리듬이 있습니다 — Codex가 실행하고, 사람이 방향을 정하고 검증한다. 마이그레이션의 체크포인트 리뷰, PR 리뷰의 P0/P1 확인, 보안 감사의 승인 게이트, eval 루프의 임계값 설정… 전부 "사람의 판단"이 들어가는 지점입니다.
1편에서 봤던 SWE-Lancer·OSWorld의 격차를 떠올려 보세요. AI는 아직 "돈 받는 일"의 절반도 혼자 끝내지 못합니다. 그래서 2026년 엔지니어의 일은 사라지는 게 아니라 한 층 위로 올라갑니다. 한 줄 한 줄 타이핑하는 사람에서, 무엇을 할지 정하고(AGENTS.md·계획) 결과가 옳은지 검증하는(테스트·evals·리뷰) 사람으로요. 키보드를 두드리는 시간은 줄고, 판단하는 시간은 늘어납니다.
11. 다음 편 예고
엔지니어의 하루 — 이해·검토·개선·이전·도구화·보안·난제 돌파 — 를 Codex와 함께 따라가 봤습니다. 화려하진 않지만 시간을 가장 많이 잡아먹던 일들이 한결 가벼워졌습니다.