AI 사서 7명이 협업한다 — Google의 Agentic RAG가 '믿을 수 있는 답'을 만드는 법
한 번 검색하고 답하는 RAG는 여러 데이터베이스에 흩어진 질문 앞에서 무너진다. Google이 Gemini Enterprise에 넣은 Agentic RAG는 7명의 전문 에이전트가 '계획 → 검색 → 충분성 검증 → 재검색 → 합성'을 반복해 답을 만든다. 왜 이 구조가 나왔는지 ReAct부터의 역사와 논문, 병원·기업 사례, FRAMES 벤치마크(정확도 34%↑)로 쉽고 자세하게 풀었다.
"존 도 환자가 무릎 수술 후 퇴원할 때 받은 약과 식이제한은 무엇이고, 입원 기간 중 알레르기 반응은 있었나요?"
흔한 RAG(검색 증강 생성) 챗봇은 이렇게 동작한다. 질문을 벡터로 바꿔 한 번 검색하고, 가장 비슷해 보이는 문서 몇 개를 가져와, 그걸 근거로 답을 쓴다. 약 정보와 식이표는 잘 나왔다. 그런데 알레르기 기록은 간호기록의 다른 섹션에 "발진(rash)"이라는 단어로만 적혀 있었고, 첫 검색에는 걸리지 않았다.
문제는 그다음이다. 챗봇은 "모르겠습니다"라고 멈추지 않았다. 검색된 문서에 알레르기 항목이 안 보이자, "입원 중 특별한 알레르기 반응은 없었습니다"라고 자신 있게 답해버렸다. 실제로는 있었는데도.
이것은 가상의 시나리오가 아니다. 우리는 RAG의 숨겨진 약점: '충분한 컨텍스트'가 환각을 결정한다에서, 관련은 있지만 답이 빠진 문서를 받으면 LLM의 환각이 최대 6.5배까지 폭증한다는 Google Research의 ICLR 2025 실험을 다룬 적이 있다. 정보가 아예 없을 때는 솔직히 거부하던 모델이, 어설프게 관련된 문서를 받으면 오히려 더 위험해진다.
핵심 질문은 하나다. "한 번 검색해서 안 나오면, 그냥 답해버려도 되는가?"
2026년 5월, Google Research와 Google Cloud는 이 질문에 대한 본격적인 제품화 답안을 내놓았다. 이름은 Agentic RAG. 한 명의 검색기가 한 번에 답하던 구조를, 7명의 전문 에이전트가 협업하는 팀으로 바꾼 것이다. 이 글은 왜 이런 구조가 필요했는지를 역사와 논문에서부터 따라가, 7명의 에이전트가 각각 무엇을 하는지, 그리고 2026년 엔터프라이즈 AI에서 이 기술이 어떤 자리를 차지하는지까지 차근차근 풀어낸다.
기존 RAG의 근본 가정은 단순하다. "질문 하나 → 검색 한 번 → 답 하나." 위키피디아 한 문단이면 답이 나오는 질문에는 이 구조가 완벽하게 작동한다.
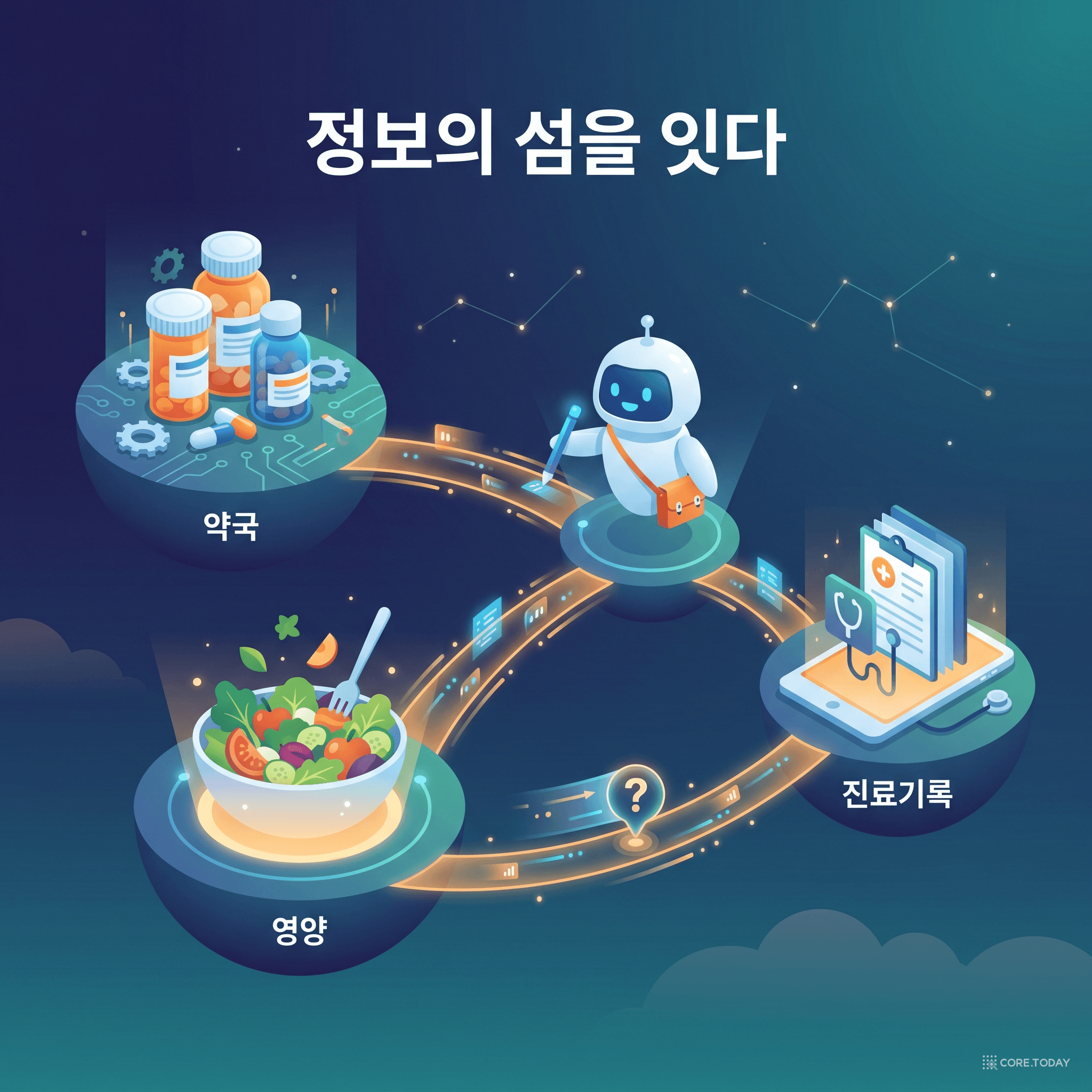
하지만 현실의 기업 질문은 그렇게 친절하지 않다. 답이 여러 개의 분리된 데이터 더미("정보의 섬")에 흩어져 있다.
"한 번의 검색"이 풀 수 없는 질문들
멀티홉(multi-hop)
"프로젝트 X에 쓰인 서버의 사양은?"
→ ① 먼저 X의 서버 ID를 찾고
→ ② 그 ID로 다른 DB에서 사양을 또 찾아야 함
멀티소스(multi-source)
"퇴원 약 + 식이제한 + 알레르기?"
→ 약국 DB · 영양 DB · 진료기록 DB
→ 세 섬에 답이 나뉘어 있음
비교·집계
"가장 길었던 시즌 피날레 2개, 길이 차이는?"
→ 여러 문서에서 사실을 모아
→ 추려서 계산까지 해야 함
한 번만 검색하는 RAG는 이런 질문에서 두 가지 방식으로 실패한다. 부분만 답하거나(약·식이만 답하고 알레르기는 빠뜨림), 빠진 조각을 그럴듯하게 지어낸다(환각). 그리고 앞서 봤듯이, 둘 중 더 위험한 건 후자다.
여기서 결정적인 깨달음이 등장한다. 사람이라면 이럴 때 어떻게 하는가?
도서관에서 리포트를 쓰는 연구자를 떠올려 보자. 책 한 권에서 답이 안 나오면, 그는 답을 지어내지 않는다. "아, 알레르기 부분이 비었네. 간호기록 쪽을 더 찾아봐야겠다"고 판단하고, 다시 검색하러 간다. 검색 → 확인 → 부족하면 재검색. 이 반복 루프가 사람이 신뢰할 수 있는 답을 만드는 방식이다.
Agentic RAG의 아이디어는 정확히 이것이다. RAG를 한 번의 함수 호출이 아니라, AI 에이전트가 도는 루프로 바꾼다. 그런데 이 발상은 갑자기 튀어나온 게 아니다. 지난 5년간 차곡차곡 쌓여온 흐름의 가장 최근 한 걸음이다.
2. 역사 — ReAct에서 Agentic RAG까지의 5년
2020: RAG의 탄생, 그리고 그 벽
2020년 Meta AI의 Patrick Lewis 등이 RAG를 처음 제안했다(Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks). LLM이 모든 걸 외우는 대신 필요할 때 외부 문서를 검색해 참고하게 하자는 것. 지식 단절·환각·출처 부재를 한 번에 푸는 듯 보였고, LangChain·LlamaIndex와 함께 순식간에 산업 표준이 됐다.
하지만 이 초기 RAG는 구조적으로 "한 번 검색하고 끝(single-shot)"이었다. 검색이 빗나가면 그대로 빗나간 답이 나왔다. 그래서 연구자들은 RAG에 '생각하고 다시 행동하는' 능력을 붙이기 시작한다.
리플렉션 토큰으로 "검색이 필요한가? 이 문서가 쓸모 있나? 답이 근거에 맞나?"를 스스로 평가
2024 · CRAG (Yan et al.)
교정형(Corrective) RAG
경량 검색 평가기가 문서 품질을 채점 → 나쁘면 웹 검색 등으로 교정
2024 · Adaptive-RAG (Jeong et al.)
적응형 라우팅
질문 난이도를 판별해 쉬우면 한 번, 어려우면 멀티스텝으로 경로를 바꿈
2025 · Agentic RAG (서베이 정립)
다중 에이전트 협업
위 능력들을 역할별 전문 에이전트로 분업화. 계획·검색·검증·합성을 나눠 맡김
흐름을 한 문장으로 요약하면 이렇다. 검색은 점점 "한 번 하는 일"에서 "판단하며 반복하는 일"로 바뀌어 왔다. ReAct가 루프의 골격을 세웠고, FLARE·Self-RAG·CRAG·Adaptive-RAG가 각각 "언제 검색할지, 문서가 쓸모 있는지, 답이 근거에 맞는지"를 다듬었다. 2025년 Agentic RAG 서베이는 이 조각들을 에이전트 수·제어 구조·자율성·지식 표현으로 분류하며 하나의 패러다임으로 묶었다.
더 큰 그림으로 보면, 이는 우리가 루프 엔지니어링에서 다룬 흐름과 정확히 같다. "에이전트에게 프롬프트하지 말고, 에이전트를 미는 루프를 설계하라." Agentic RAG는 그 철학을 검색이라는 한 분야에 적용한 결과물이다.
그리고 2026년, Google은 이 패러다임을 연구 논문이 아니라 Gemini Enterprise라는 실제 제품에 넣었다. 여기서부터가 이 글의 본론이다.
대부분의 RAG 시스템은 검색이 끝나면 곧바로 답을 쓰기 시작한다. 검색된 게 충분한지 아닌지는 묻지 않는다. 그래서 "관련은 있지만 답은 빠진" 문서를 받으면 그대로 환각으로 직행한다.
Sufficient Context Agent는 이 사이에 검문소를 하나 세운다. 답을 쓰기 직전에, 컨베이어 벨트를 멈추고 묻는다.
"성실한 독자가 지금 모은 이 자료만으로 질문 전체에 답할 수 있는가?"
답이 "예"면 통과("충분/Sufficient"). "아니오"면 멈추고, 무엇이 빠졌는지 구체적으로 지목한 뒤 재검색을 지시한다. 어설픈 답을 만드는 대신, 빈칸을 정확히 가리키는 것이다.
이 검사관은 세 가지 일을 한다.
1
검색된 조각 평가
RAG Agent가 DB에서 끌어온 실제 텍스트 청크를 들여다보고, 질문에 필요한 정보가 그 안에 실제로 들어 있는지 확인한다. "관련성"이 아니라 "충분성"을 본다.
2
중간 초안 검토
모델이 작성하려는 중간 답변이 근거에 충분히 뿌리내렸는지(grounded) 평가한다. 근거 없이 떠 있는 문장을 잡아낸다.
3
갭 식별 → 재검색 트리거
빠진 조각을 구체적으로 지목하는 피드백을 생성한다. 그 피드백이 새로운 검색을 부른다. "불충분합니다"로 끝내지 않고, "알레르기 부분이 빠졌으니 다시 찾자"로 이어진다.
이것이 바로 그 논문의 제품화다
눈치챈 독자도 있을 것이다. 이 "충분성(sufficiency)"이라는 개념은 우리가 충분한 컨텍스트 글에서 자세히 다룬 Google Research의 ICLR 2025 논문"Sufficient Context: A New Lens on Retrieval Augmented Generation Systems"의 핵심 아이디어다.
그 논문의 가장 실전적인 강점은 이것이었다. 정답을 몰라도 "이 컨텍스트가 답하기에 충분한지"를 판별할 수 있다. 실제 프로덕션에서는 사용자가 무슨 질문을 할지 미리 알 수 없으니 정답 라벨도 없다. 그런데도 충분성은 판단 가능하다. Gemini를 활용한 Autorater는 93% 이상의 정확도로 인간의 충분/불충분 판단과 일치했다.
즉, Agentic RAG의 Sufficient Context Agent는 논문 속 Autorater가 에이전트 루프 안으로 들어와, "검색을 멈출지 계속할지" 결정하는 센서가 된 것이다. 연구(2025)가 제품(2026)이 되는 순간을, 우리는 두 글에 걸쳐 따라가고 있는 셈이다.
이 차이가 결과를 가른다. 다른 멀티에이전트 RAG가 부분 정보로 답하거나 "정보 부족"으로 끝내는 두 갈래뿐이라면, Google의 시스템은 제3의 길을 연다. 완전하고 근거 있는 답을 내거나, 빠진 것을 정확히 겨냥해 한 번 더 검색하거나.
5. 직접 돌려보는 5단계 파이프라인 + 병원 사례
전체 흐름은 5개의 국면으로 정리된다.
1. 오케스트레이션Root Agent가 요청을 파싱하고 하위 에이전트에 위임. Query Rewriter가 복합 질문을 검색 가능한 조각으로 분해.
2. 검색지정된 소스들에서 표준 RAG 검색을 수행. Search Fanout이 질의를 여러 소스로 동시 배포.
3. 충분성 검증모은 정보가 질문의 모든 요소를 충족하는지 Sufficient Context Agent가 판정.
4. 반복(Iteration)갭이 발견되면, 빠진 부분을 겨냥한 정교한 추가 질의로 다시 검색.
5. 합성완전성을 마지막으로 확인한 뒤, Synthesis Agent가 근거 기반 답변을 생성.
말로만 보면 추상적이다. 아래 시뮬레이터에서 맨 앞의 병원 퇴원 질문이 이 7개 에이전트를 거쳐 '충분한 답'이 되기까지를 직접 단계별로 넘겨보자. 특히 5번 스텝(충분성 검증)에서 알레르기 칸이 비는 순간과, 6번에서 시스템이 답을 멈추고 재검색으로 되돌아가는 장면을 눈여겨보라.
재검색'알레르기'로만 찾지 말고 의무기록 용어로: "발진(rashes)" · "이상반응(adverse events)"로 재질의 → 놓쳤던 파일에서 발견.
재검증세 영역 모두 충족 → "충분" 판정.
합성검증된 근거만으로, 출처가 추적되는 완전한 답변 생성.
맨 앞 시나리오와 비교해 보자. 같은 질문, 같은 데이터. 차이는 단 하나 — "답하기 전에 충분한지 묻는 검문소"가 있느냐다. 그 한 칸이 "알레르기는 없었습니다"라는 위험한 거짓말을, "발진 반응이 기록되어 있습니다"라는 정확한 답으로 바꾼다.
6. Cross-Corpus Retrieval — 흩어진 데이터베이스를 잇다
지금까지의 이야기에는 숨은 전제가 하나 있었다. "여러 소스를 검색한다"는 것. 그런데 기업의 데이터는 한 통에 담겨 있지 않다. 인사 DB, 재무 DB, 제품 위키, 고객지원 로그 — 서로 다른 시스템에 따로 산다. 바로 그 정보의 섬들이다.
Agentic RAG의 Planner Agent는 이 섬들 사이에서 라우팅(routing)을 한다. "이 질문의 이 부분은 재무 DB로, 저 부분은 제품 위키로." 이 기능이 Gemini Enterprise Agent Platform에 Cross-Corpus Retrieval(교차 코퍼스 검색)이라는 이름으로 들어갔고, 현재 퍼블릭 프리뷰로 제공된다.
복합 질문→Planner: 어느 섬으로?→코퍼스 A · B · C · D→충분성 검증→합성
여기서 자연스럽게 떠오르는 의심이 있다. "4개의 서로 다른 DB 중 맞는 걸 고르고 가로지르면, 정확도가 떨어지고 느려지지 않나?" 이게 다음 장의 벤치마크가 답하는 질문이다.
7. 벤치마크 — FRAMES, 정확도 34%↑, 지연은 그대로
Google은 FRAMES(FramesQA)라는 까다로운 데이터셋으로 시스템을 평가했다. 이 벤치마크는 멀티홉 추론을 요구하도록 설계됐다.
824
멀티홉 질문 수
2,676
PDF 문서 수
+34%
표준 RAG 대비 사실성 정확도 향상
대표적인 예시 질문은 이렇다. "2024년 6월 기준 가장 많이 시청된 두 개의 TV 시즌 피날레 중, 어느 쪽이 더 길었고 얼마나 차이 나는가?" — 여러 문서에서 사실을 모아, 추려서, 길이를 계산까지 해야 한다. 전형적인 "한 번 검색으로 안 되는" 질문이다.
핵심 결과 1: 사실성 정확도가 최대 34% 향상
여러 사실성(factuality) 데이터셋에서 Agentic RAG는 표준("바닐라") RAG 대비 최대 34%까지 높은 정확도를 기록했다. 계획·라우팅·충분성 검증을 더한 효과가, 단순히 더 좋은 임베딩을 쓰는 것보다 컸다는 뜻이다.
핵심 결과 2: 섬을 가로질러도 정확도가 거의 안 떨어진다
가장 인상적인 숫자는 여기 있다. 단일 코퍼스에서 검색할 때와, 4개 코퍼스 중 맞는 것을 골라 가로질러 검색할 때의 정확도를 비교했다.
조건
정확도
의미
단일 코퍼스 (Single-corpus)
약 90.8%
답이 어느 DB에 있는지 이미 아는 쉬운 설정
교차 코퍼스 (Cross-corpus)
90.1%
4개 중 맞는 DB를 스스로 골라 가로지른 설정
두 숫자의 차이는 1%포인트 미만이다. 즉, 정답이 어느 데이터베이스에 있는지 미리 알려주지 않고 "알아서 찾아라"고 해도, 정확도가 거의 그대로 유지된다. Planner의 라우팅이 제값을 한다는 증거다. 엔터프라이즈 현실(데이터가 수십 개 시스템에 흩어진 환경)에서 결정적인 성질이다.
핵심 결과 3: 지연(latency)은 3% 이내
"에이전트를 7개나 돌리고 재검색까지 하면 느리지 않나?" 직관적인 우려다. 하지만 단일 코퍼스 설정과 교차 코퍼스 설정의 지연 차이는 3% 이내였다. 검색 fanout이 병렬로 돌고, 재검색은 정말 필요할 때만 트리거되기 때문이다.
✓
정리하면
정확도는 표준 RAG 대비 최대 34% 올리고, 데이터가 흩어져 있어도 정확도 손실은 1%p 미만, 추가 지연은 3% 이내. "더 정확하면 더 느리고 비싸다"는 통념을 비껴간 결과다.
주의 깊게 읽기. 34%는 특정 사실성 데이터셋 기준의 상대적 향상폭이고, 90.x%는 FRAMES 계열 설정에서의 정확도다. 모든 도메인·모든 질문에서 같은 수치가 나오는 건 아니다. 벤치마크는 방향성을 보여줄 뿐, 당신의 데이터에서는 직접 측정해야 한다 — 이건 RAG 평가의 기본이다.
8. 2026년, Agentic RAG의 자리
어디에 쓰이고 있나
2026년 현재, 단순 "한 방 검색" RAG는 데모와 FAQ 봇의 영역으로 밀려나고 있다. 반면 Agentic RAG는 답이 틀리면 책임이 따르는 영역으로 들어가고 있다.
Agentic RAG가 진짜 값을 하는 영역
의료·임상
약·진단·알레르기가 서로 다른 기록에 흩어진 환경. 환각이 곧 사고
법률·컴플라이언스
조문·판례·내부 정책을 가로질러 근거를 모아야 함. 출처 추적 필수
금융·감사
여러 보고서·DB를 비교·집계. "감사 가능한(auditable)" 답이 요구됨
공통점은 셋이다. 데이터가 여러 섬에 흩어져 있고, 답에 책임이 따르며, "출처를 댈 수 있는 근거"가 필수라는 것. Google이 이 시스템의 결과를 "감사 가능하고(auditable), 추적 가능하며(traceable), 근거에 기반한(grounded)"이라고 강조하는 이유가 여기 있다.
실전 설계의 정답은 보통 하나만 고르기가 아니라 난이도에 따라 경로를 가르는 것(Adaptive-RAG의 교훈)이다. 쉬운 질문은 한 번 검색, 어려운 질문만 에이전트 루프로. 이렇게 하면 비용과 정확도를 동시에 잡는다. 기본기는 여전히 실전 RAG 개선 7가지 테크닉과 컨텍스트 엔지니어링이다.
더 큰 그림: 검색이 에이전트 협업의 한 장면이 되다
마지막으로 한 칸 물러서서 보자. Agentic RAG는 에이전트들이 협업해 일을 끝내는 더 큰 흐름의 한 사례다. 같은 패턴이 코딩(루프 엔지니어링), 데이터 분석, 업무 자동화 전반에서 동시에 일어나고 있다. 에이전트들이 서로 표준 프로토콜로 대화하는 A2A 프로토콜이나, 도구를 표준 방식으로 붙이는 MCP가 그 배관이다. Agentic RAG는 그 위에서 "신뢰할 수 있는 검색"이라는 한 모듈을 맡는다.
핵심 정리: 기억해야 할 6가지
1한 번의 검색은 흩어진 질문 앞에서 무너진다. 멀티홉·멀티소스·비교 질문은 답이 여러 '정보의 섬'에 나뉘어 있다.
2해법은 RAG를 루프로 바꾸는 것. ReAct(2022)→Self-RAG→CRAG→Adaptive-RAG로 이어진 5년의 흐름이 Agentic RAG(2025)로 수렴했다.
3Google은 7개의 전문 에이전트로 분업한다. 오케스트레이터·플래너·질의 재작성·검색 fanout·RAG·충분성 검증·합성.
4심장은 충분성 검증 에이전트. 답하기 전에 "이 자료로 충분한가"를 묻고, 부족하면 빈틈을 지목해 재검색한다. ICLR 2025 논문의 제품화다.
5숫자가 통념을 깬다. 사실성 정확도 최대 34%↑, 4개 코퍼스 교차 검색에도 정확도 손실 1%p 미만, 지연 3% 이내.
6고위험·고가치 영역의 표준이 되어간다. 의료·법률·금융처럼 출처와 책임이 따르는 곳. 단순 질문엔 여전히 단순 RAG가 답이다.
마치며: "모르면 다시 찾아본다"는 평범한 지혜
이 기술의 가장 깊은 통찰은 의외로 평범하다. 모르면 답을 지어내지 말고, 다시 찾아본다. 성실한 연구자라면 누구나 하는 일이다.
오랫동안 LLM은 이걸 못 했다. 관련 문서가 눈앞에 있으면 "답할 수 있는 상태"라고 착각하고, 빠진 조각을 그럴듯하게 메웠다. Agentic RAG가 한 일은, 그 충동과 최종 답변 사이에 "잠깐, 이걸로 충분한가?"라고 묻는 한 칸을 끼워 넣은 것이다. 그리고 그 한 칸이, 데모용 챗봇을 병원과 법무팀이 믿고 쓰는 시스템으로 바꾼다.
충분한 컨텍스트 글의 마지막을 다시 빌리면, 소크라테스는 "나는 내가 모른다는 것을 안다"고 했다. 2026년의 Agentic RAG는 여기에 한 줄을 더한다. "모른다는 걸 알았으면, 다시 찾아본다." 그게 신뢰할 수 있는 AI의 다음 한 걸음이다.
Joren et al., Sufficient Context: A New Lens on Retrieval Augmented Generation Systems, ICLR 2025 — arXiv:2411.06037
Singh et al., Agentic Retrieval-Augmented Generation: A Survey — arXiv:2501.09136
Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020), Yao et al. ReAct (2022), Asai et al. Self-RAG (2023), Yan et al. CRAG (2024), Jeong et al. Adaptive-RAG (2024)