들어가며: 도서관에서 책등이 사라진다면
상상해 보자. 거대한 도서관에 들어섰는데, 모든 책의 표지와 책등이 사라져 있다. 책은 수만 권이 있지만, 어떤 책이 세법 해설인지, 어떤 책이 요리 레시피인지 알 수 없다. 페이지를 펼치면 내용은 있지만, "이 페이지가 어떤 책의 몇 번째 장인지"는 아무도 모른다.

바로 이것이 전통적인 RAG(Retrieval-Augmented Generation)가 처한 상황이다.
AI가 똑똑해지려면 배경 지식이 필요하다. 고객 지원 챗봇은 회사의 서비스 매뉴얼을, 법률 AI는 수만 건의 판례를, 기업용 AI는 내부 보고서를 알아야 한다. RAG는 이 방대한 지식을 작은 조각(청크)으로 나눈 뒤, 사용자 질문에 맞는 조각을 찾아 AI에게 건네주는 기술이다.
문제는, 잘게 쪼개는 순간 맥락이 사라진다는 것이다.
2024년 9월, Anthropic이 이 문제를 정면으로 해결한 기술을 발표했다 — Contextual Retrieval. 검색 실패율을 최대 67%까지 줄이는 이 기법이 어떻게 작동하는지, 왜 이런 개념이 나올 수밖에 없었는지, 1957년부터 시작되는 정보 검색의 역사와 함께 완전 해부한다.
제1장: 검색은 어떻게 시작되었는가 — TF-IDF에서 BM25까지
Contextual Retrieval을 이해하려면, 먼저 "컴퓨터가 문서를 어떻게 검색하는가"의 역사를 알아야 한다.
1957년 — 시작: 단어를 세는 것부터
IBM의 한스 페터 룬(Hans Peter Luhn)이 1957년에 제안한 아이디어는 놀라울 정도로 단순했다:
"문서에 특정 단어가 자주 나타나면, 그 문서는 그 단어와 관련 있을 것이다."
이것이 TF(Term Frequency) — 단어 빈도의 개념이다. "강화학습"이라는 단어가 10번 나오는 문서는, 1번 나오는 문서보다 강화학습에 대한 문서일 가능성이 높다.
1972년 — IDF의 등장: 흔한 단어는 쓸모없다
15년 뒤, 케임브리지 대학의 카렌 스파르크 존스(Karen Spärck Jones)가 결정적인 통찰을 더했다:
"모든 문서에 나타나는 단어는 검색에 쓸모가 없다."
"그리고", "하지만", "이다" 같은 단어는 거의 모든 문서에 나타난다. 이런 흔한 단어는 검색 가치가 낮다. 반대로, "양자컴퓨팅"처럼 소수의 문서에만 나타나는 단어는 가치가 높다. 이것이 IDF(Inverse Document Frequency) — 역문서 빈도다.
TF와 IDF를 곱한 것이 바로 TF-IDF다. 정보 검색의 기초가 되는 이 공식은 50년 넘게 살아남았다.
1994년 — BM25: 검색의 표준이 탄생하다
TF-IDF에는 치명적인 약점이 있었다. 단어가 100번 나오는 문서가 1번 나오는 문서보다 정말 100배 더 관련 있을까? 상식적으로 아니다. 일정 횟수를 넘어가면 "이 문서는 이 주제에 대한 것이다"라는 확신은 크게 변하지 않는다.
1994년, 런던 시립대학의 스티븐 로버트슨(Stephen Robertson) 과 동료들이 BM25(Best Matching 25)를 발표한다. "25"는 이들이 시도한 25번째 랭킹 함수라는 뜻이다 — 그만큼 오랜 시행착오의 결과였다.
🔑
BM25의 핵심 개선
① 포화(Saturation) — 단어 빈도가 높아질수록 점수 증가가 둔화된다. 100번 나와도 10번과 큰 차이 없다.
② 문서 길이 정규화 — 긴 문서가 단순히 더 많은 단어를 포함한다고 높은 점수를 받지 않는다.
③ 튜닝 가능한 파라미터 — k1(포화 속도)과 b(길이 정규화 강도)를 데이터에 맞게 조절할 수 있다.
BM25는 30년이 지난 2026년 현재도 Elasticsearch, OpenSearch, Solr 등 모든 주요 검색 엔진에서 사용된다. 딥러닝 시대에도 살아남은 이유는 간단하다 — 정확한 키워드 매칭에서는 여전히 최고이기 때문이다.
제2장: RAG의 탄생 — "AI에게 책을 읽게 하자"
2020년 — 검색 + 생성의 결합
시간을 2020년으로 건너뛰자. GPT-3가 발표되고 대형 언어 모델(LLM)의 시대가 열렸다. 하지만 LLM에는 치명적인 한계가 있었다:
- 학습 데이터가 과거에 멈춰 있다 — 어제 발표된 뉴스를 모른다
- 환각(Hallucination) — 모르는 것도 아는 척한다
- 기업 내부 지식에 접근 불가 — 회사의 비공개 문서를 학습하지 못했다
2020년 5월, Facebook AI Research(현 Meta AI)의 패트릭 루이스(Patrick Lewis) 등이 획기적인 논문을 발표한다:
"Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (NeurIPS 2020)
핵심 아이디어: 질문을 받으면 관련 문서를 먼저 검색하고, 그 문서를 읽고 나서 답변을 생성한다. 마치 시험 문제를 받았을 때, 교과서에서 관련 부분을 먼저 찾아보고 답을 쓰는 것과 같다.
이것이 RAG(Retrieval-Augmented Generation)의 탄생이다.
2022–2023년: RAG의 황금기
ChatGPT의 등장(2022년 11월) 이후, RAG는 폭발적으로 성장했다. 모든 기업이 "우리 데이터로 AI를 만들고 싶다"고 외쳤고, RAG는 그 핵심 기술이었다.
- LangChain(2022.10)과 LlamaIndex(2022.11) — RAG 프레임워크의 양대 산맥
- Self-RAG(Asai et al., 2023) — AI가 스스로 "검색할지 말지"를 판단
- RAPTOR(2023) — 문서를 계층적으로 요약하여 검색
하지만 이 화려한 성장 뒤에는, RAG의 구조적 한계가 서서히 드러나고 있었다.
제3장: 전통 RAG의 치명적 약점 — "맥락의 실종"
전통 RAG는 이렇게 작동한다
전통적인 RAG 파이프라인은 6단계로 구성된다:
Step 1
지식 베이스를 수백 토큰 단위의 청크로 분할
Step 2
각 청크의 TF-IDF/BM25 인덱스와 시맨틱 임베딩 생성
Step 3
사용자 쿼리에 대해 BM25로 키워드 매칭 검색
Step 4
동시에 임베딩으로 의미 유사도 검색
Step 5
두 결과를 Rank Fusion으로 합산 및 중복 제거
Step 6
상위 K개 청크를 프롬프트에 추가하여 최종 답변 생성
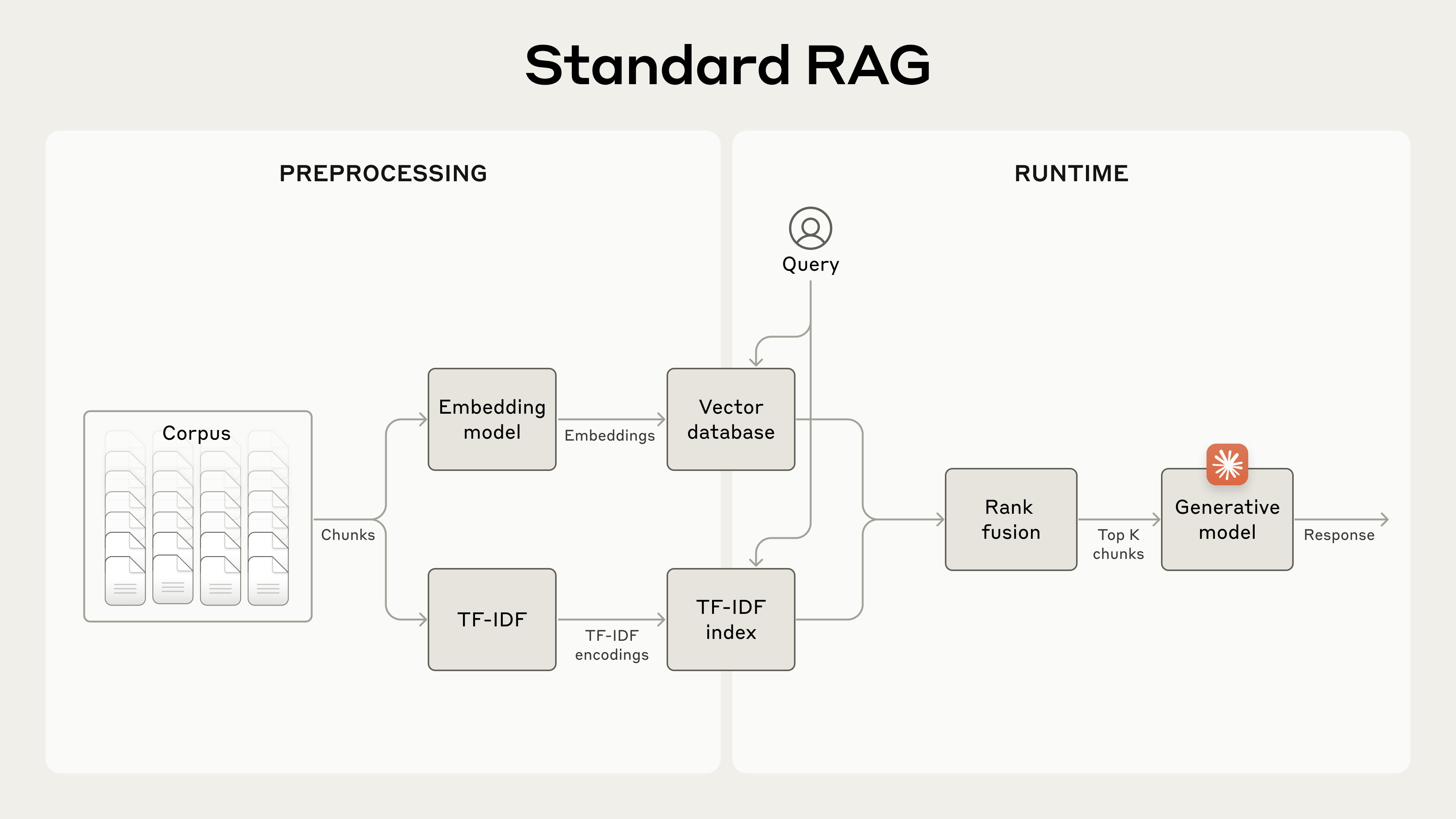
겉보기에는 완벽해 보이는 이 파이프라인에, 구조적 결함이 숨어 있다.
쪼개는 순간, 맥락이 죽는다
실제 사례로 이해해 보자.
원본 문서: ACME Corp 2023년 Q2 SEC 공시 보고서 (전체 50페이지)
이 문서를 수백 토큰 단위로 잘게 쪼개면, 17번째 청크가 이런 내용이 된다:
전분기 대비 매출이 3% 성장했다. 아태 지역에서의 성장이 두드러졌으며, 클라우드 서비스 부문이 전체 성장을 견인했다.
이제 사용자가 질문한다: "ACME Corp의 2023년 Q2 매출 성장률은?"
이 청크에는 "3% 성장"이라는 정답이 있다. 하지만 문제는:
- "ACME Corp"라는 회사 이름이 없다
- "2023년 Q2"라는 시점 정보가 없다
- "SEC 공시"라는 문서 유형도 없다
임베딩 검색은 "매출 성장"이라는 의미는 잡겠지만, 수천 개의 유사한 매출 관련 청크 중에서 이 청크가 정확히 ACME Corp Q2에 대한 것인지 구분하지 못한다. BM25도 "ACME"라는 키워드가 없으니 매칭에 실패한다.
이것이 바로 Contextual Retrieval이 해결하려는 핵심 문제다 — 청크가 원본 문서의 맥락을 잃어버리는 것.
"Lost in the Middle" — 찾아도 제대로 못 쓴다
2023년 스탠포드의 넬슨 류(Nelson F. Liu) 등은 또 다른 충격적인 발견을 한다:
LLM은 긴 컨텍스트의 가운데에 있는 정보를 놓친다.
관련 문서가 프롬프트의 처음이나 끝에 있으면 잘 찾지만, 중간에 묻혀 있으면 성능이 급격히 떨어진다. 이른바 "Lost in the Middle" 문제다.
🚨
전통 RAG의 이중고
① 검색 단계: 맥락 부족으로 관련 청크를 못 찾음
② 생성 단계: 너무 많은 청크를 넣으면 핵심 정보가 중간에 묻혀 무시됨
💡
해결 방향
① 검색을 더 정밀하게 — 맥락을 복원하여 정확한 청크를 찾고
② 리랭킹으로 필터링 — 정말 관련 있는 소수의 청크만 최종 프롬프트에 전달
제4장: Contextual Retrieval — Anthropic의 해법
핵심 아이디어: "청크에 이름표를 달아 주자"
2024년 9월 19일, Anthropic이 Contextual Retrieval을 발표했다. 아이디어는 놀라울 정도로 직관적이다:
각 청크를 임베딩하기 전에, LLM이 그 청크가 원본 문서에서 어떤 맥락인지 설명하는 짧은 텍스트를 앞에 붙여 준다.
앞서 본 ACME Corp 사례를 다시 보자:
[컨텍스트] 이 청크는 ACME Corp의 2023년 Q2 SEC 공시 보고서에서 발췌한 것이다. 전분기(Q1 2023) 매출은 3억 1,400만 달러였다. 해당 섹션은 지역별 매출 성장 분석에 관한 것이다.
전분기 대비 매출이 3% 성장했다. 아태 지역에서의 성장이 두드러졌으며, 클라우드 서비스 부문이 전체 성장을 견인했다.
이제 "ACME Corp", "Q2 2023", "SEC 공시", "3억 1,400만 달러"라는 핵심 맥락이 청크에 포함되어 있다. BM25는 "ACME"를 매칭할 수 있고, 임베딩은 "ACME Corp Q2 매출 성장"이라는 정확한 의미를 인코딩한다.

컨텍스트는 어떻게 생성하는가
Anthropic은 Claude 모델을 사용해 각 청크의 컨텍스트를 자동 생성한다. 프롬프트 구조는 이렇다:
<document>
{{전체_문서}}
</document>
이 문서의 특정 청크를 검색 개선을 위해 맥락화하려 합니다.
<chunk>
{{청크_내용}}
</chunk>
이 청크를 전체 문서 맥락에서 설명하는 짧고 간결한 컨텍스트를 작성하세요.
컨텍스트만 답변하세요.
생성되는 컨텍스트는 50~100 토큰 정도 — 한두 문장으로 충분하다. 이 짧은 문장이 검색 정확도를 극적으로 바꾼다.
두 가지 핵심 기법
Contextual Retrieval은 사실 두 가지 하위 기법의 결합이다:
Contextual Embeddings
컨텍스트를 청크 앞에 붙인 후
시맨틱 임베딩 생성
→ 의미 기반 검색 개선
Contextual BM25
컨텍스트를 청크 앞에 붙인 후
BM25 인덱스 생성
→ 키워드 기반 검색 개선
하이브리드 검색
두 검색 결과를 Rank Fusion으로
합산 → 최종 상위 K개 선정
왜 둘 다 필요한가?

- 임베딩 검색: "매출이 늘었다"와 "수익이 성장했다"처럼 의미가 같은 다른 표현을 잡아낸다
- BM25 검색: "TS-999", "ACME Corp"처럼 정확한 키워드를 잡아낸다
두 방식은 상호 보완적이다. 임베딩이 놓치는 정확한 용어를 BM25가 잡고, BM25가 놓치는 의미적 유사성을 임베딩이 잡는다. Contextual Retrieval은 두 방식 모두에 맥락 정보를 주입하여 양쪽의 정확도를 동시에 끌어올린다.
제5장: 직접 체험해 보자 — 맥락의 힘
말로 설명하는 것보다 직접 보는 것이 낫다. 아래 인터랙티브 데모에서 컨텍스트 추가 전후의 차이를 체험해 보자:

비용은 얼마나 드는가?
"모든 청크에 대해 LLM을 호출하면 비용이 엄청나지 않을까?" — 합리적인 질문이다.
Anthropic은 프롬프트 캐싱(Prompt Caching)으로 이 문제를 해결한다. 같은 문서의 여러 청크를 처리할 때, 문서 전체를 매번 다시 읽지 않고 캐시된 토큰을 재사용한다.
Contextual Retrieval 비용 분석 (100만 문서 토큰 기준)
프롬프트 캐싱을 적용하면 비용이 약 92% 절감된다. 100만 토큰(약 2,500페이지 분량) 처리에 약 1달러 — 일회성 전처리 비용으로 매우 합리적이다.
참고: 지식 베이스가 20만 토큰(~500페이지) 이하라면, Contextual Retrieval 대신 프롬프트 캐싱을 활용해 전체 문서를 그대로 프롬프트에 포함하는 것이 더 효율적이다. 레이턴시 2배 이상 감소, 비용 최대 90% 절감.
제6장: 리랭킹 — 최종 정밀 타격
왜 리랭킹이 필요한가
Contextual Retrieval로 검색 정확도가 크게 올라갔지만, 여전히 가짜 양성(false positive)이 포함될 수 있다. 초기 검색에서 150개 후보를 뽑았을 때, 이 중에는 "관련 있어 보이지만 실제로는 별로"인 것들이 섞여 있다.
여기서 리랭킹(Reranking) 모델이 등장한다.

리랭킹의 원리: Bi-encoder vs. Cross-encoder
검색에 쓰이는 모델은 크게 두 종류다:
| 구분 | Bi-encoder (1단계 검색) | Cross-encoder (2단계 리랭킹) |
|---|
| 작동 방식 | 쿼리와 문서를 각각 독립적으로 임베딩 | 쿼리와 문서를 함께 하나의 입력으로 처리 |
| 비유 | 이력서로 서류 심사 (빠르지만 대략적) | 면접으로 심층 평가 (느리지만 정확) |
| 속도 | 매우 빠름 — 벡터 미리 계산 가능 | 느림 — 매번 전체 모델 실행 |
| 정확도 | 준수 — 대략적 유사도 | 높음 — 토큰 수준 상호작용 |
| 적용 범위 | 전체 코퍼스 (수백만 건) | 상위 50~150개 후보만 |
리랭킹 파이프라인
Step 1
하이브리드 검색(Contextual Embedding + Contextual BM25)으로 상위 150개 후보 추출
Step 2
리랭킹 모델(Cohere Reranker 등)이 쿼리와 각 청크를 함께 분석
Step 3
관련성 점수를 기반으로 상위 20개를 재정렬
Step 4
정제된 20개 청크만 LLM에 전달하여 최종 답변 생성
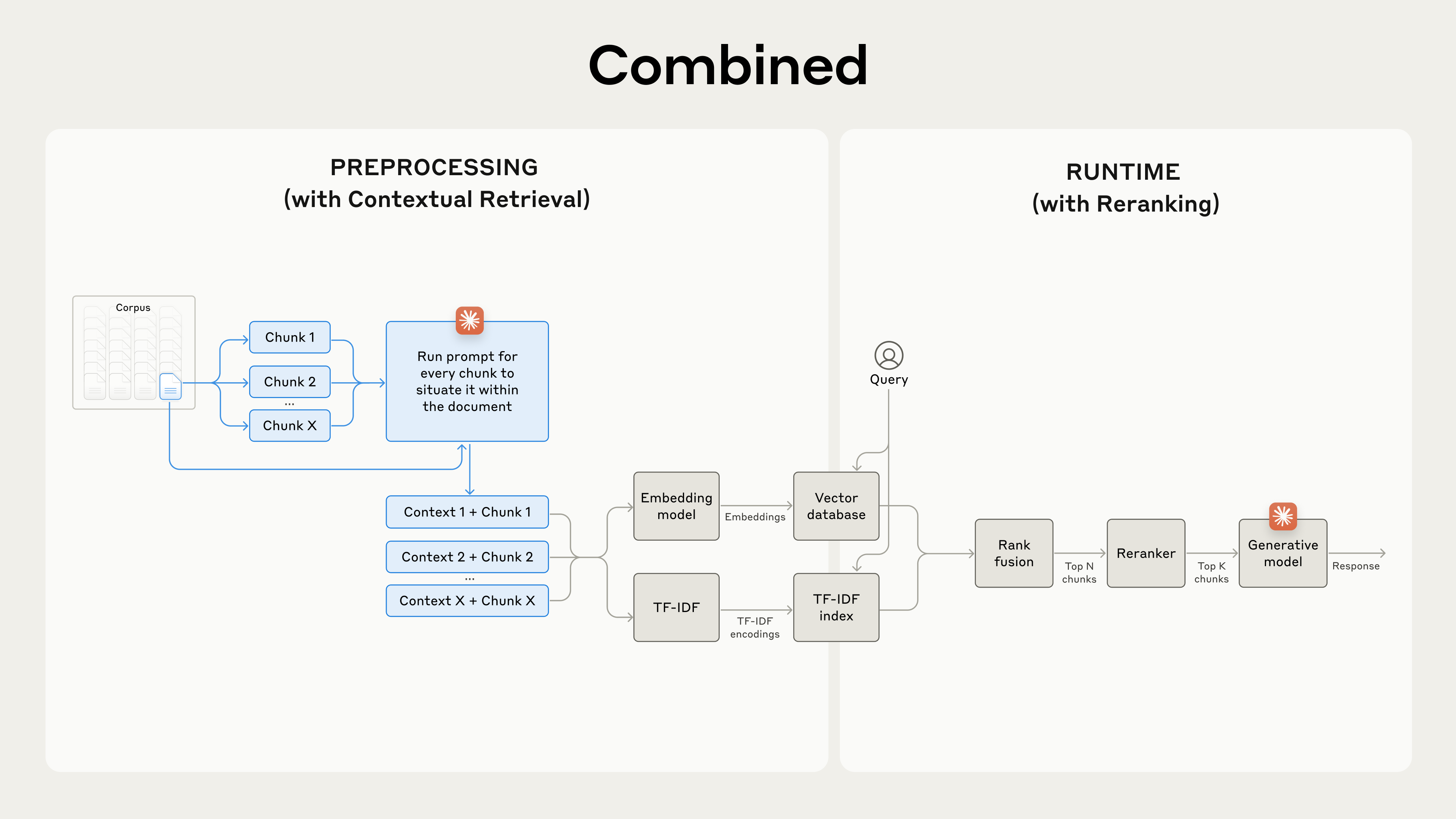
리랭킹은 약간의 레이턴시를 추가하지만, 불필요한 청크를 걸러내서 오히려 최종 응답의 품질과 비용 효율성을 높인다.
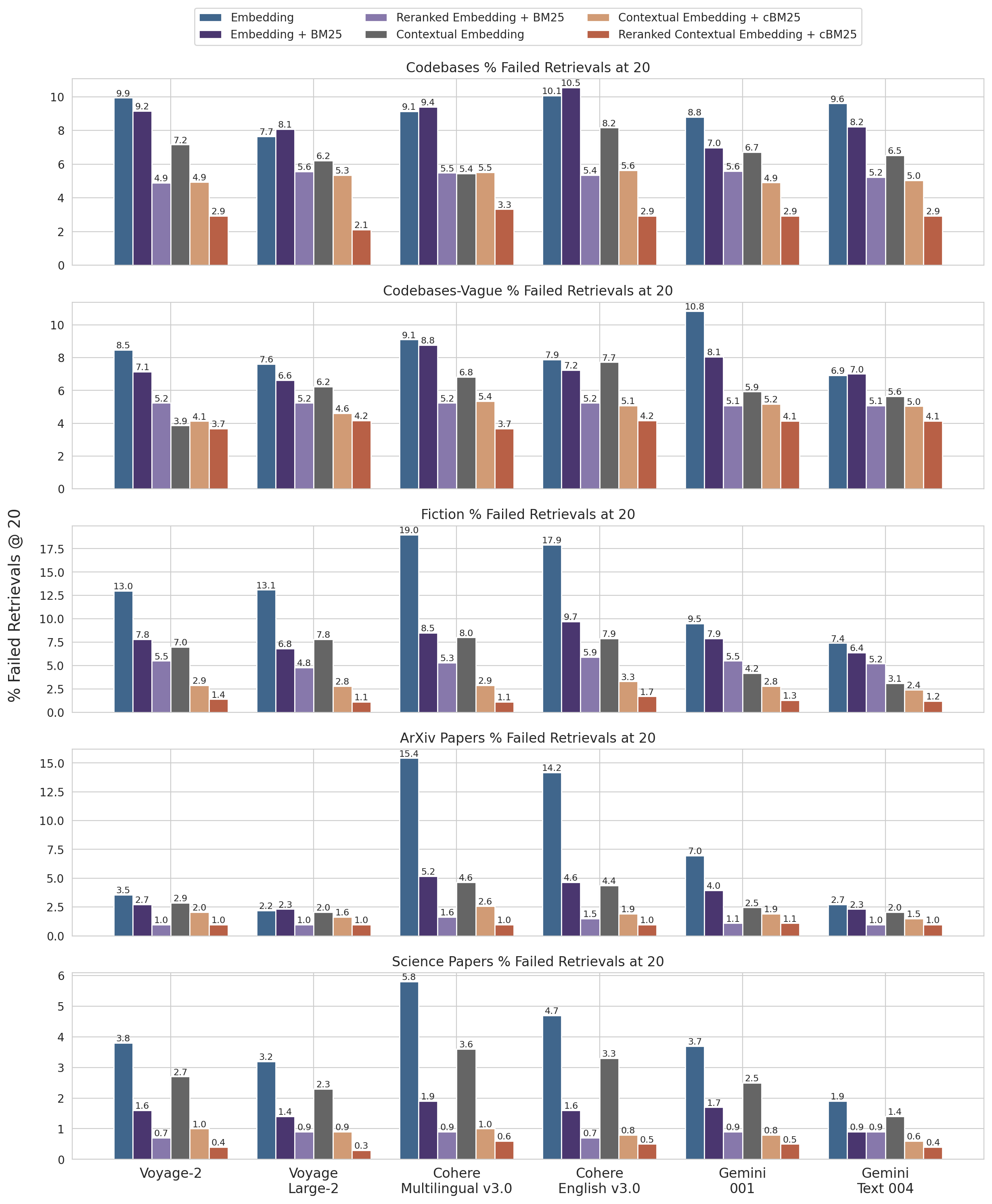
제7장: 벤치마크 — 숫자가 말하는 효과
Anthropic은 코드베이스, 소설, ArXiv 논문, 과학 논문 등 다양한 도메인에서 실험을 진행했다. 평가 지표는 1 - Recall@20 — 상위 20개 청크에 관련 문서가 포함되지 않은 비율(검색 실패율)이다.
아래에서 각 기법의 성능을 직접 비교해 보자:
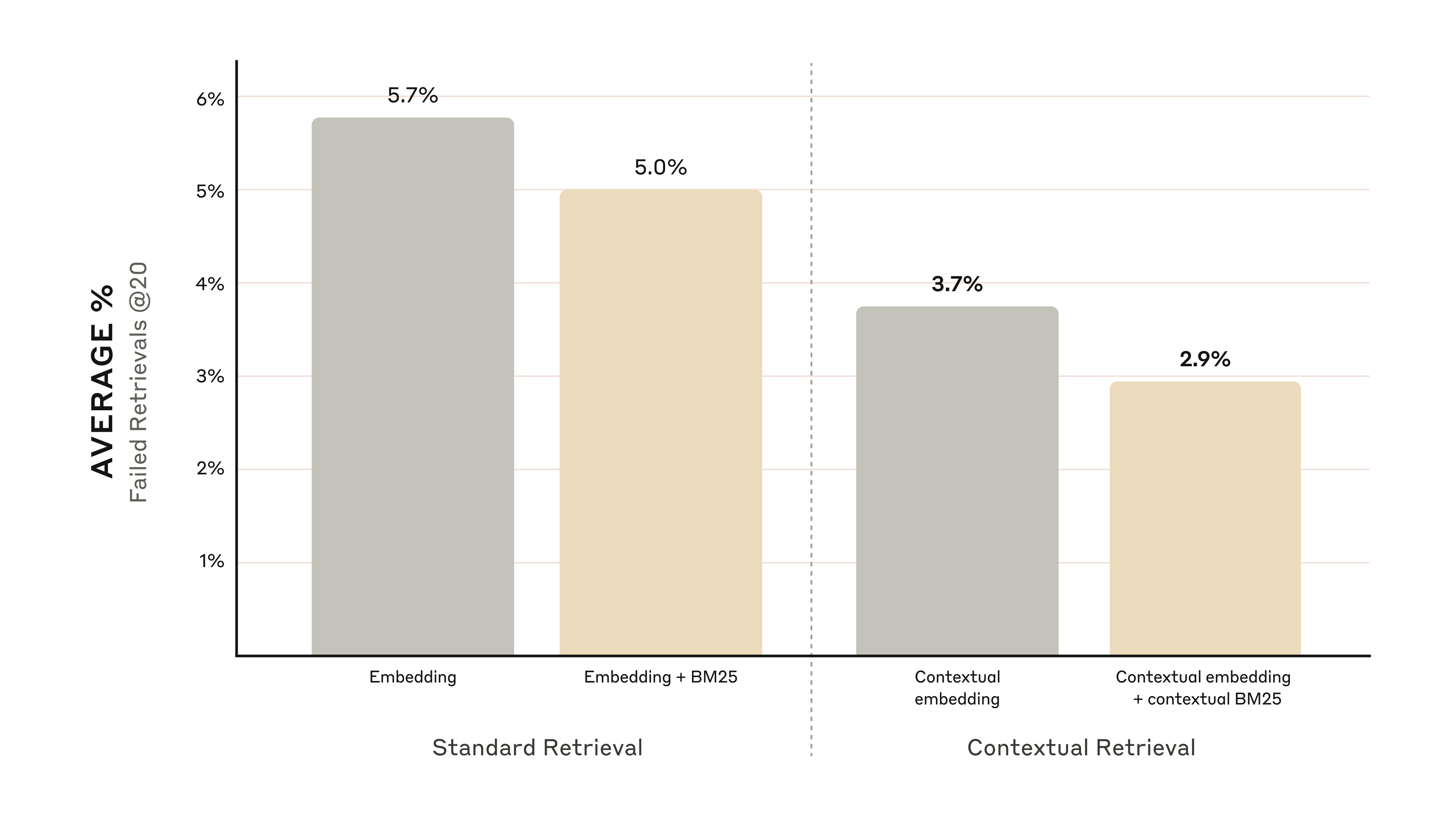
핵심 발견 6가지
기법별 검색 실패율 (Retrieval@20)
+ Contextual Embedding
3.7% -35%
+ Contextual BM25
2.9% -49%
- Embedding + BM25 하이브리드가 Embedding 단독보다 낫다 — 항상
- Voyage와 Gemini 임베딩이 가장 우수한 성능을 보였다
- Top-20이 Top-10, Top-5보다 효과적이다
- 컨텍스트 추가는 모든 임베딩 모델에서 성능을 향상시켰다
- 리랭킹은 항상 이득이다
- 모든 기법은 누적 적용 가능 — 최적 구성은 Contextual Embedding(Voyage/Gemini) + Contextual BM25 + 리랭킹 + Top-20
시도했지만 효과 없었던 것들
Anthropic은 다른 접근법도 시도했으나, 효과가 미미했다:
- 문서 요약을 청크에 추가: 제한적 효과
- 가상 문서 임베딩(HyDE): 낮은 성능
- 요약 기반 인덱싱: 낮은 성능
이들은 "맥락 복원"이라는 핵심을 직접 건드리지 않았기 때문이다. Contextual Retrieval은 각 청크가 원본 문서에서 어디에 위치하는지를 명시적으로 알려주는 것이 핵심이다.
제8장: 구현 시 고려사항
Contextual Retrieval을 실제 시스템에 적용할 때 알아야 할 사항들이다.
1. 청크 경계(Chunk Boundaries)
청크의 크기, 경계, 겹침(overlap)은 검색 성능에 큰 영향을 미친다. Anthropic은 수백 토큰 단위를 권장하지만, 문서 유형에 따라 최적값이 다르다.
📏
청킹 전략 팁
구조화된 문서(보고서, 매뉴얼): 섹션 경계를 존중하는 시맨틱 청킹
비구조화 텍스트(소설, 대화록): 고정 크기 + 겹침(50~100 토큰)
코드베이스: 함수/클래스 단위로 분할
2. 임베딩 모델 선택
Gemini Text 004와 Voyage 임베딩이 특히 좋은 성능을 보였다. 중요한 점은, Contextual Retrieval은 어떤 임베딩 모델에서도 성능을 향상시킨다는 것이다 — 다만 모델마다 개선 폭이 다르다.
3. 도메인 특화 프롬프트
범용 프롬프트로도 효과가 좋지만, 도메인 특화 용어 사전을 프롬프트에 포함하면 더 나은 결과를 얻을 수 있다. 예를 들어, 의료 문서라면 "ICD-10 코드", "DRG 분류" 같은 전문 용어를 컨텍스트에 포함하도록 안내한다.
4. 컨텍스트 vs. 원본 구분
최종 LLM에 청크를 전달할 때, 생성된 컨텍스트 부분과 원본 청크 내용을 구분하면 응답 품질이 더 좋아질 수 있다. 컨텍스트는 검색 정확도를 높이기 위한 보조 정보이지, 답변의 직접적 근거가 아니기 때문이다.
제9장: 2026년 현재 — RAG의 진화와 Contextual Retrieval의 위치
RAG는 더 똑똑해지고 있다
Contextual Retrieval 발표 이후 1년 반이 지난 2026년, RAG 생태계는 크게 진화했다:
2020
기본 RAG
검색 + 생성
→
2023
고급 RAG
Self-RAG, RAPTOR
→
2024
Contextual RAG
맥락 복원
→
2025-26
Agentic RAG
에이전트 주도
GraphRAG (Microsoft, 2024): 문서에서 지식 그래프를 구축하고, 커뮤니티 탐지 알고리즘으로 관련 정보를 찾는다. "이 회사의 전체 트렌드는?"처럼 여러 문서를 종합하는 글로벌 질의에 강하다.
Agentic RAG (2025~): AI 에이전트가 직접 검색 전략을 수립한다. 질문을 분석하고, 어떤 데이터소스를 쿼리할지 결정하고, 검색 결과가 부족하면 쿼리를 재구성하여 다시 검색한다. LangGraph, CrewAI 등의 프레임워크가 이를 지원한다.
Late Chunking (Jina AI, 2024): 청크를 먼저 나누고 임베딩하는 대신, 전체 문서를 먼저 임베딩 모델에 통과시킨 후 청크 수준으로 풀링한다. 크로스-청크 맥락이 자연스럽게 보존된다.
멀티모달 RAG: 텍스트뿐 아니라 이미지, 차트, 표까지 검색 대상으로 확장. ColPali 같은 비전-언어 검색 모델이 등장했다.
Contextual Retrieval의 지속적 영향
Contextual Retrieval은 특정 프레임워크나 도구가 아니라, "청크에 맥락을 복원한다"는 원칙이다. 이 원칙은 2026년의 모든 고급 RAG 시스템에 녹아들어 있다:
- Weaviate, Qdrant, Pinecone 등 벡터 DB들이 "enriched chunking" 또는 "contextual chunking"을 기본 기능으로 지원
- Voyage AI는 2025년 초 Anthropic에 인수되어, 임베딩과 리랭킹이 Claude 생태계에 통합
- 하이브리드 검색(BM25 + 임베딩 + 리랭킹)은 2026년 사실상의 표준 아키텍처
🎯
2026년 프로덕션 RAG 최적 스택
전처리: Contextual Chunking (LLM으로 맥락 생성) + 시맨틱 청크 경계
검색: Contextual Embedding + Contextual BM25 하이브리드
후처리: Cross-encoder 리랭킹 → Top-20 → LLM 생성
고급: Agentic 래퍼로 쿼리 분해 + 반복 검색 + 결과 평가
제10장: 정보 검색 70년의 여정
마지막으로, TF-IDF에서 Contextual Retrieval까지 — 70년에 걸친 정보 검색의 역사를 한눈에 정리하자.
| 연도 | 이정표 | 의의 |
|---|
| 1957 | Luhn — Term Frequency | "단어를 세면 관련 문서를 찾을 수 있다" |
| 1972 | Spärck Jones — IDF | "흔한 단어는 가치가 낮다" |
| 1994 | Robertson — BM25 | 검색 랭킹의 황금 표준 (30년째 현역) |
| 2019 | Nogueira — BERT 리랭킹 | 신경망으로 검색 결과 재정렬 |
| 2020 | Lewis et al. — RAG 탄생 | 검색 + 생성의 결합 |
| 2020 | Khattab — ColBERT | Late-interaction 검색 모델 |
| 2022 | LangChain, LlamaIndex | RAG의 대중화 |
| 2023 | "Lost in the Middle" | LLM의 긴 컨텍스트 활용 한계 발견 |
| 2024 | Contextual Retrieval | 청크에 맥락을 복원하여 검색 실패율 67% 감소 |
| 2024 | GraphRAG | 지식 그래프 + RAG |
| 2025 | Voyage AI → Anthropic 인수 | 임베딩-리랭킹 생태계 통합 |
| 2026 | Agentic RAG | 에이전트가 검색 전략을 주도 |
마치며: 맥락은 모든 것이다
Contextual Retrieval의 교훈은 기술 너머에 있다.
인간의 소통에서도, 맥락 없는 정보는 오해를 낳는다. "3% 성장했다"는 사실 하나도, 누가, 언제, 어떤 상황에서라는 맥락이 있어야 비로소 의미를 갖는다.
AI가 인간의 지식을 제대로 활용하려면, 단순히 정보를 잘게 쪼개서 저장하는 것으로는 부족하다. 쪼개진 정보가 원래 어디서 왔는지, 어떤 맥락에서 의미를 갖는지를 함께 보존해야 한다.
1957년 룬이 "단어를 세자"고 제안한 이래, 70년간 정보 검색은 꾸준히 하나의 방향으로 진화해 왔다 — 더 정확하게, 더 맥락을 살려서, 더 관련 있는 정보를 찾는 것. Contextual Retrieval은 그 여정의 중요한 이정표이며, 2026년의 Agentic RAG 시대에서도 그 핵심 원칙 — "맥락을 되살려라" — 은 여전히 유효하다.
📄 원문: Anthropic Engineering — Contextual Retrieval (2024.09.19)
📚 참고 논문:
- Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (NeurIPS 2020)
- Robertson et al., "Some Simple Effective Approximations to the 2-Poisson Model" (SIGIR 1994)
- Liu et al., "Lost in the Middle: How Language Models Use Long Contexts" (TACL 2024)
- Nogueira & Cho, "Passage Re-ranking with BERT" (2019)




