
블로그로 돌아가기
VAE생성 모델잠재 공간변분 추론ELBOVQ-VAE
VAE 완전 정복: 확률의 마법으로 '없던 것'을 만들어내는 AI
점 하나 대신 '구름'을 배우는 AI — Variational Autoencoder가 확률을 무기로 생성 AI의 시대를 연 이야기. 원리부터 신약 설계, Stable Diffusion과의 연결까지.
코어닷투데이2025-11-0338분
점 하나 대신 '구름'을 배우는 AI — Variational Autoencoder가 확률을 무기로 생성 AI의 시대를 연 이야기. 원리부터 신약 설계, Stable Diffusion과의 연결까지.
인간은 한 번도 본 적 없는 것을 상상할 수 있습니다. 고양이를 수천 마리 봤으면, 실제로 존재하지 않는 새로운 고양이의 모습을 머릿속에 그릴 수 있죠. "고양이란 이런 거"라는 추상적 이해가 있기 때문입니다.
AI도 이렇게 할 수 있을까요? 단순히 기존 데이터를 외우는 것이 아니라, 데이터의 본질적 구조를 이해하고, 그 이해를 바탕으로 완전히 새로운 것을 만들어내는 것. 이것이 바로 생성 모델(Generative Model)의 꿈입니다.
2013년, 킹마와 웰링(Diederik P. Kingma & Max Welling)이 발표한 "Auto-Encoding Variational Bayes"는 이 꿈에 수학적으로 우아한 해법을 제시합니다. 그 이름은 VAE(Variational Autoencoder, 변분 오토인코더).
GAN이 "경쟁"으로 생성을 배웠다면, VAE는 "확률"로 생성을 배웁니다.
VAE가 등장하기 전, 생성 모델의 선택지는 제한적이었습니다:
연구자들이 원한 것은 명확했습니다:
- 복잡한 데이터(이미지, 음성)의 확률 분포를 학습하고
- 그 분포에서 새로운 샘플을 빠르게 뽑아낼 수 있으며
- 수학적으로 탄탄한 프레임워크
킹마와 웰링은 세 가지를 모두 만족하는 모델을 만들어냅니다.
기존 오토인코더의 문제를 다시 짚어봅시다:
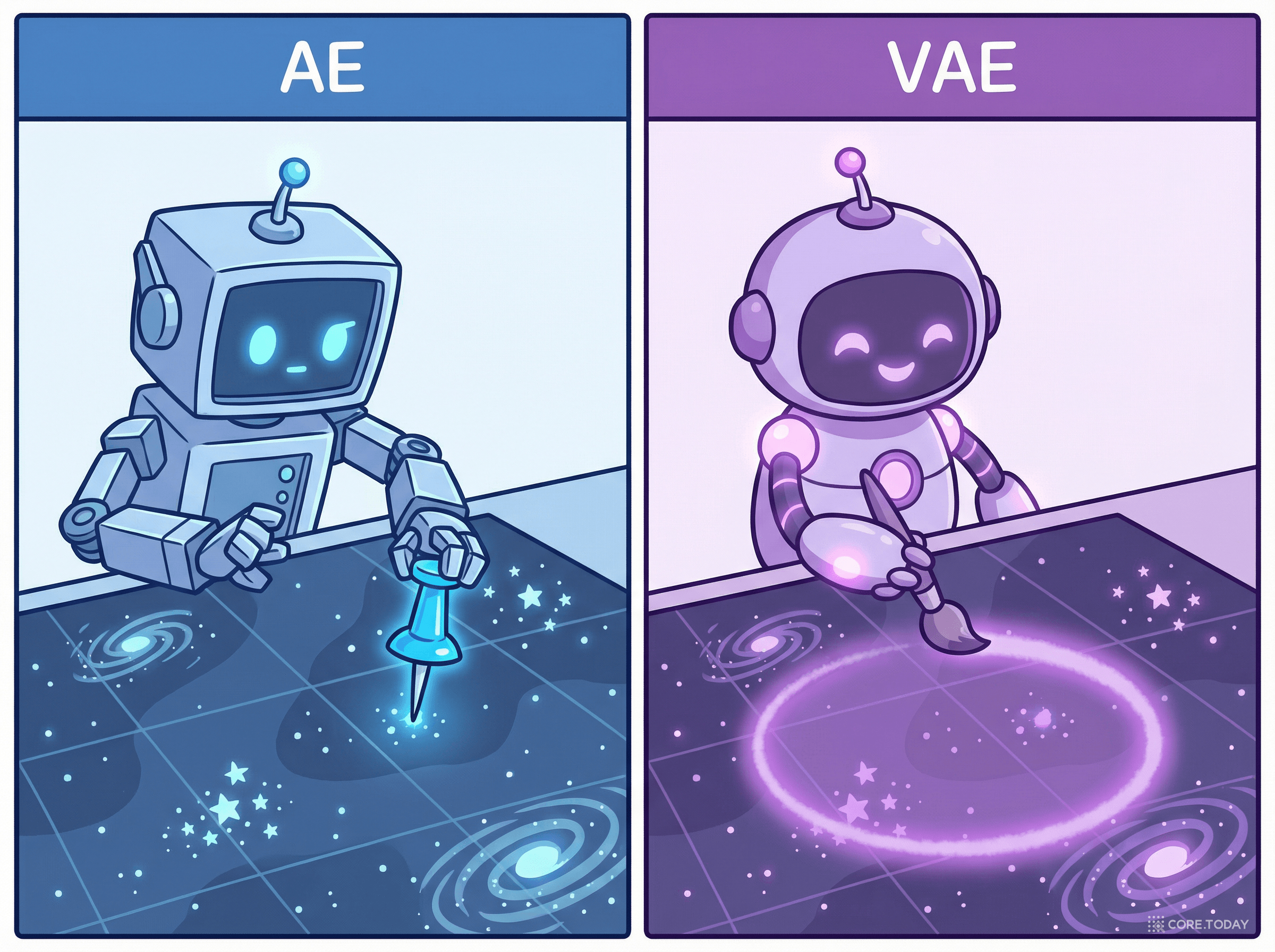
이 "점 → 구름" 전환이 VAE의 핵심 아이디어입니다. 수학적으로 말하면, 인코더가 결정론적 함수가 아니라 확률 분포를 매개변수화하는 것입니다.
VAE의 수학은 변분 추론(Variational Inference)이라는 통계학의 도구에 기반합니다. 어렵게 들리지만, 핵심 직관은 단순합니다.
궁극적으로 원하는 것: 데이터의 확률 분포 p(x)를 알고 싶습니다. "고양이 이미지의 확률 분포"를 알면, 거기서 샘플링해서 새 고양이를 만들 수 있으니까요.
문제는 p(x)를 직접 계산하려면 잠재 변수 z에 대한 적분이 필요한데, 이 적분이 계산 불가능(intractable)합니다:
p(x) = ∫ p(x|z) · p(z) dz
해석:
• p(z): 잠재 변수의 사전 분포 (보통 표준 정규분포)
• p(x|z): 잠재 변수 z가 주어졌을 때 데이터 x가 나올 확률 (디코더)
• 이 적분은 모든 가능한 z에 대해 합산하는 것 → 차원이 높으면 사실상 계산 불가능
직접 계산할 수 없으니, 우리가 다룰 수 있는 단순한 분포 q(z|x)로 진짜 사후 분포 p(z|x)를 근사합니다.
인코더 qφ(z|x)는 입력 x를 받아 가우시안 분포의 평균(μ)과 분산(σ²)을 출력합니다. 이것이 바로 VAE의 인코더가 "점 대신 구름을 출력한다"는 의미입니다.

이 근사를 최적화하면 유명한 ELBO(Evidence Lower Bound)가 나옵니다:
ELBO = 𝔼q(z|x)[log p(x|z)] - KL(q(z|x) ‖ p(z))
첫 번째 항: 복원 손실 (Reconstruction Loss)
"z에서 x를 얼마나 잘 복원하는가?"
→ 디코더가 잘 작동하도록 밀어줌
→ 이 항만 있으면 기본 오토인코더와 같음
두 번째 항: KL 발산 (KL Divergence)
"인코더가 출력하는 분포가 표준 정규분포에 얼마나 가까운가?"
→ 잠재 공간을 매끄럽고 연속적으로 만들어줌
→ 이 항이 있기에 생성이 가능해짐
쉽게 비유하면: 시소의 양쪽입니다.
VAE는 이 두 힘의 균형을 찾는 것입니다. 이 균형이 바로 "잘 복원하면서도 자연스러운 생성이 가능한" 모델을 만듭니다.
VAE 학습에는 한 가지 기술적 장벽이 있습니다. 인코더가 분포를 출력하고, 거기서 랜덤 샘플링을 해야 하는데, 랜덤 연산은 미분이 불가능합니다. 역전파가 안 되면 학습도 안 됩니다.
킹마의 해법 — 리파라미터화 트릭(Reparameterization Trick):
# 리파라미터화 트릭 구현
def reparameterize(mu, log_var):
std = torch.exp(0.5 * log_var) # σ = exp(½ log σ²)
eps = torch.randn_like(std) # ε ~ N(0,1) (외부 랜덤)
z = mu + eps * std # z = μ + ε × σ
return z # μ, σ에 대해 미분 가능!
이 트릭은 단순해 보이지만, 이것 없이는 VAE가 존재할 수 없습니다. 킹마 논문의 핵심 기여 중 하나입니다.
변분 추론(Variational Inference) 자체는 VAE보다 훨씬 오래된 방법입니다. 1990년대에 조던(Michael I. Jordan), 비숍(Christopher Bishop) 등이 베이지안 통계에서 계산 불가능한 사후 분포를 근사하기 위해 발전시켰습니다.
핵심 아이디어는 "어려운 분포를 쉬운 분포로 근사하고, 그 차이를 KL 발산으로 최소화"하는 것입니다.
킹마의 천재성은 이 고전적인 통계학 도구를 딥러닝과 결합한 것입니다. 인코더 신경망이 변분 분포의 파라미터를 출력하게 하면서, 대규모 데이터에서도 확장 가능한(scalable) 변분 추론을 실현했습니다.
같은 시기에 레젠데 등(Rezende, Mohamed & Wierstra)도 거의 동일한 아이디어를 독립적으로 발표합니다 — "Stochastic Backpropagation and Approximate Inference in Deep Generative Models"(ICML, 2014). 두 논문 모두 "신경망 + 변분 추론 + 리파라미터화 트릭"의 조합이라는 점에서 놀라운 동시 발견입니다.
VAE의 잠재 공간은 기본 오토인코더와 질적으로 다릅니다. KL 발산 정규화 덕분에 구조적이고 연속적입니다.
VAE의 잠재 공간에서는 두 점 사이를 부드럽게 이동하면, 의미 있는 중간 형태가 생성됩니다:
얼굴 생성 VAE의 잠재 공간:
웃는 여자 → 약간 웃는 여자 → 무표정 여자 → 무표정 남자 → 웃는 남자
잠재 공간의 한 점에서 다른 점으로 직선으로 이동하면,
표정, 성별, 나이가 부드럽게 변환됩니다.
기본 오토인코더에서는 중간 지점이 무의미한 노이즈가 되는 것과 대조적!
잘 학습된 VAE의 잠재 공간에서는 각 차원이 의미 있는 특징에 대응하는 경향이 있습니다:
* 실제로는 이렇게 깔끔하게 분리되지 않을 수 있습니다. Beta-VAE가 이 문제를 해결합니다 (후술).
z₁만 변경하면 얼굴 각도만 바뀌고 나머지는 유지됩니다. 이것을 분리된 표현 학습(Disentangled Representation Learning)이라 하며, VAE 연구의 핵심 주제입니다.

원조 VAE는 시작일 뿐입니다. 각각의 한계를 해결하며 강력한 변형들이 탄생합니다.
히긴스 등(Higgins et al., "beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework", 2017)의 아이디어는 놀랍도록 간단합니다:
KL 발산 항에 가중치 β를 곱한다.
ELBO = 복원 손실 - β × KL 발산
β > 1로 설정하면 KL 발산의 압력이 강해져서, 잠재 공간의 각 차원이 독립적인 의미를 갖도록 강제됩니다. "얼굴 각도", "표정", "피부색" 같은 특징이 깔끔하게 분리되는 것이죠.
대신 β를 높이면 복원 품질이 떨어집니다 (더 흐릿해짐). β가 낮으면 선명하지만 특징이 엉켜 있습니다. 최적의 β를 찾는 것이 핵심입니다.
솔(Sohn et al.)의 CVAE는 생성 과정에 조건(condition)을 추가합니다.
"웃는 얼굴을 생성해줘" → z를 랜덤으로 뽑되, 조건 c="웃음"을 함께 주면, 다양하지만 모두 웃고 있는 얼굴이 생성됩니다.
반 덴 오르드 등(van den Oord et al., "Neural Discrete Representation Learning", 2017)의 VQ-VAE(Vector Quantized VAE)는 패러다임을 바꿉니다.
기존 VAE의 잠재 공간은 연속적(아무 실수 값이나 가능)이지만, VQ-VAE는 잠재 공간을 이산적(discrete)으로 만듭니다. 미리 정해진 코드북(codebook)의 벡터 중 가장 가까운 것을 선택합니다.
코드북 = 미리 정의된 벡터 사전
코드 1: [0.2, 0.8, -0.1] → "눈" 패턴
코드 2: [0.9, 0.1, 0.5] → "입" 패턴
코드 3: [-0.3, 0.7, 0.2] → "배경" 패턴
...
코드 512: [0.4, -0.6, 0.8] → "머리카락" 패턴
인코더 출력을 가장 가까운 코드에 "양자화(quantize)"합니다.
마치 포토샵에서 256색으로 줄이는 것처럼!
VQ-VAE가 중요한 이유: 이 아이디어가 발전하여 VQ-VAE-2(2019)가 되고, 이것이 DALL-E 1(2021)의 핵심 구성요소가 됩니다. OpenAI의 첫 번째 텍스트→이미지 모델은 VAE의 직계 후손인 것입니다!
라르센 등(Larsen et al.)은 VAE와 GAN을 결합합니다. VAE의 디코더를 GAN의 생성자로 사용하고, GAN의 판별자가 "복원이 진짜 같은가?"를 추가로 판단합니다.
결과: VAE의 구조적 잠재 공간 + GAN의 선명한 이미지. VAE 특유의 뿌옇함이 크게 개선됩니다.

VAE의 가장 임팩트 있는 응용 중 하나입니다.
고메스-봄바렐리 등(Gómez-Bombarelli et al., "Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules", ACS Central Science, 2018)은 약물 분자의 SMILES 문자열(분자의 텍스트 표현)을 VAE로 학습합니다.
핵심: 잠재 공간이 연속적이기 때문에, 기존 분자의 "근처"를 탐색하면 비슷하지만 새로운 분자를 발견할 수 있습니다. 이산적인 분자 공간에서는 불가능한 접근법입니다.
이 연구는 이후 Insilico Medicine, Atomwise 같은 AI 신약 스타트업의 핵심 기술로 발전합니다. 2020년 이후 코로나 치료제 후보 물질 탐색에도 VAE 기반 분자 생성이 활용되었습니다.
VAE는 기본 오토인코더보다 이론적으로 강건한 이상 탐지를 제공합니다:
실전 사례 — 우주항공 부품 검사
NASA와 유럽우주국(ESA)은 위성 부품의 미세 결함 탐지에 VAE를 활용합니다. 정상 부품의 확률 분포를 학습하고, 새 부품이 이 분포에서 벗어나는 정도를 측정합니다. 인간 검사관보다 2-3배 빠른 검사 속도와 동등 이상의 정확도를 달성합니다.
의료, 금융 분야에서는 개인정보 보호 때문에 데이터 공유가 어렵습니다. VAE로 원본 데이터의 통계적 특성은 보존하되 개인을 식별할 수 없는 합성 데이터를 생성할 수 있습니다.
실전 사례 — JP모건의 합성 금융 데이터
JP모건 체이스는 거래 데이터의 패턴을 보존하면서 개인을 식별할 수 없는 합성 데이터를 VAE로 생성하여, 사기 탐지 모델 학습에 활용합니다. 규제 기관에 개인정보 없이 모델의 성능을 검증할 수 있는 방법을 제공합니다.
Google Magenta의 MusicVAE(Roberts et al., 2018)는 멜로디를 잠재 공간에 인코딩합니다. 두 멜로디 사이를 보간하면 자연스러운 중간 멜로디가 생성됩니다. "재즈 멜로디와 클래식 멜로디의 중간"이라는 것이 가능해지는 거죠.
왜 VAE 이미지는 흐릿한가? VAE의 복원 손실(보통 MSE)은 "평균적으로 맞는" 픽셀값을 찾게 합니다. 여러 가능한 복원의 평균은 필연적으로 흐릿합니다 — 마치 여러 사진을 겹쳐놓으면 흐려지는 것처럼. GAN은 판별자의 "이거 흐릿하니까 가짜!" 피드백이 이를 방지합니다.
2025년 가장 많이 쓰이는 이미지 생성 서비스인 Stable Diffusion의 정식 이름은 Latent Diffusion Model(LDM)입니다. 이름에서 알 수 있듯, 잠재(Latent) 공간에서 디퓨전을 수행합니다.
그 잠재 공간을 만드는 것이 바로 VAE입니다.
VAE가 없었다면, 디퓨전 모델은 512×512 해상도에서 직접 작동해야 했고, 이는 GPU 메모리와 학습 시간 면에서 비현실적이었을 것입니다. VAE의 "데이터를 효율적으로 압축하는 능력"이 디퓨전 모델의 대중화를 가능케 한 것입니다.
Stable Diffusion에서 가끔 보이는 "손가락이 이상하게 뭉개진" 현상은, VAE 디코더가 잠재 표현을 복원할 때 미세한 디테일을 놓치기 때문이기도 합니다. 2024년 SDXL에서는 개선된 VAE가 이 문제를 상당 부분 해결했습니다.
2024~2025년 VAE 연구의 전선:
2013년 킹마와 웰링의 논문은 8페이지짜리 짧은 논문이었습니다. 하지만 이 논문이 던진 질문 — "신경망으로 확률적 생성 모델을 어떻게 효율적으로 학습시킬 수 있는가?" — 은 이후 12년간 생성 AI 전체를 관통하는 핵심 질문이 됩니다.
GAN이 "선명함"으로 세상을 놀라게 했다면, VAE는 "구조"로 세상을 바꿨습니다. 데이터를 의미 있는 잠재 공간으로 압축하고, 그 공간에서 자유롭게 탐색할 수 있게 만든 것. 신약을 설계하고, 음악을 보간하고, Stable Diffusion의 심장부에서 이미지를 압축하는 것. 이 모든 것의 시작은 "점 대신 구름을 배우자"는 단순하지만 심오한 아이디어였습니다.
가끔 가장 우아한 해법은, 질문을 살짝 바꾸는 것에서 나옵니다. "이 데이터가 무엇인가?" 대신 "이 데이터가 어떤 분포에서 왔는가?"



