AI 에이전트는 어떻게 '계획'을 세우는가
여러분이 집을 리모델링한다고 상상해 보세요. 건축가 한 명에게만 맡기면, 그 사람의 스타일과 경험에 맞춰 하나의 설계안이 나옵니다. 하지만 세 명의 건축가에게 독립적으로 설계를 맡기고, 네 번째 전문가가 세 안의 장점을 골라 최종안을 만든다면 어떨까요?
이것이 바로 Ultraplan의 핵심 아이디어입니다.
2026년 Anthropic이 Claude Code v2.1.91에서 공개한 Ultraplan은 "AI 코딩 에이전트가 코드를 작성하기 전에 어떻게 계획을 세워야 하는가"라는 근본적인 질문에 대한 대답입니다. 단순히 LLM에게 "계획을 세워줘"라고 하는 것이 아니라, 멀티 에이전트 아키텍처를 통해 인간 수준의 숙의 과정을 시뮬레이션합니다.
"좋은 계획은 좋은 코드보다 중요하다. 계획 없는 코딩은 나침반 없는 항해와 같다."
왜 '계획'이 중요한가 — 실패에서 배우는 역사
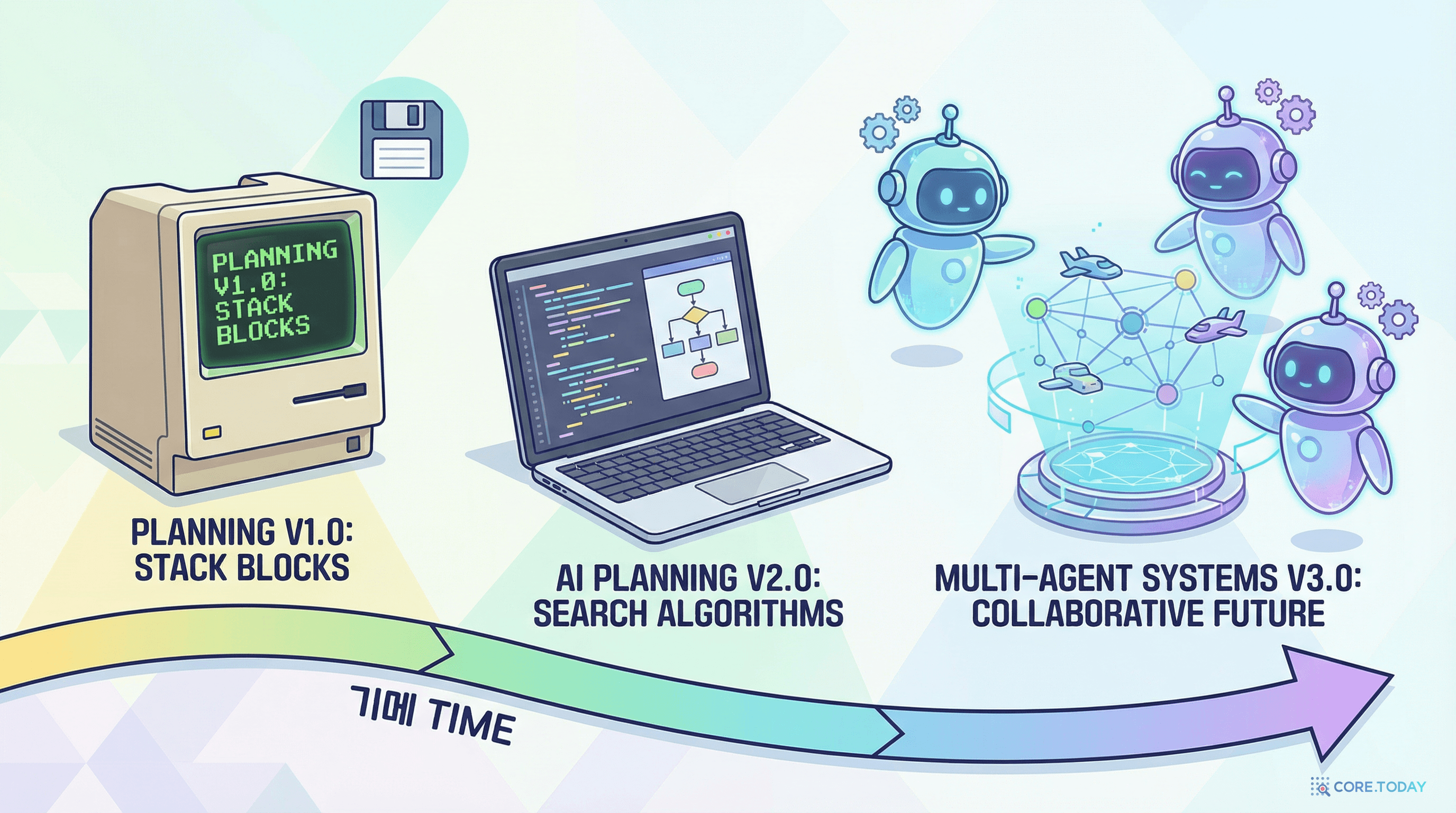
코딩 AI의 진화
AI가 코드를 작성하는 역사는 생각보다 깁니다. 하지만 "계획을 세우고 코드를 작성하는" 능력은 최근에야 등장했습니다.
2021
GitHub Copilot 등장
자동완성 수준의 코드 제안. 한 줄, 한 함수 단위. "다음 토큰 예측"의 시대.
2023
GPT-4 + 에이전트 프레임워크
AutoGPT, LangChain 등장. AI가 여러 단계를 순차적으로 실행하기 시작. 하지만 장기 계획은 여전히 불안정.
2024
Claude Code, Cursor, Devin 등장
AI가 파일을 직접 수정하고, 테스트를 실행하고, 커밋하는 시대. 하지만 복잡한 태스크에서 "계획 없이 돌진"하는 문제 발생.
2025
Plan Mode의 도입
Claude Code에 로컬 플랜 모드 추가. 에이전트가 구현 전에 계획을 세우도록 강제. 하지만 단일 에이전트의 한계 존재.
2026
Ultraplan 출시
멀티 에이전트 클라우드 플래닝. 3 탐색자 + 1 비평자 아키텍처로 앵커링 바이어스 해결.
"계획 없는 AI"의 재앙적 사례들
왜 AI에게 계획이 필요한지, 실제 사례를 통해 살펴보겠습니다.
⚠️
사례 1: 데이터베이스 마이그레이션의 비극
한 개발팀이 AI 코딩 에이전트에게 "PostgreSQL에서 MongoDB로 마이그레이션해줘"라고 요청했습니다. 에이전트는 즉시 코드를 수정하기 시작했고, 관계형 스키마를 그대로 문서 구조로 변환했습니다. 결과는? 수백 개의 중첩 조인이 필요한 쿼리가 $lookup 지옥이 되어 성능이 100배 저하되었습니다. 계획 단계에서 스키마 재설계를 먼저 논의했다면 막을 수 있는 참사였습니다.
⚠️
사례 2: 인증 시스템 "개선"의 역습
AI에게 "보안을 강화해달라"고 하자, 모든 API 엔드포인트에 이중 인증을 추가했습니다. 웹훅 콜백, 내부 서비스 간 호출, 헬스체크까지 전부. 서비스 전체가 멈췄습니다. 시스템 아키텍처를 먼저 분석하고, 어디에 인증이 필요한지 계획을 세웠어야 합니다.
이런 사례들은 하나의 공통점을 가지고 있습니다: AI가 코드를 잘 작성하는 것과 올바른 코드를 작성하는 것은 완전히 다른 문제라는 점입니다.
앵커링 바이어스 — AI도 편견에 빠진다
인간의 인지 편향, AI에게도 적용된다
심리학에서 앵커링 효과(Anchoring Effect)란 처음 접한 정보에 과도하게 의존하는 인지 편향을 말합니다. 1974년 Tversky와 Kahneman이 발표한 기념비적 논문 "Judgment under Uncertainty: Heuristics and Biases"에서 처음 체계적으로 연구되었습니다.
AI 언어 모델도 이와 유사한 문제를 겪습니다. LLM은 토큰을 순차적으로 생성하기 때문에, 초반에 선택한 방향이 이후 전체 출력에 영향을 미칩니다. 이것을 AI의 앵커링 바이어스라고 합니다.
🔴
문제: 단일 에이전트의 앵커링
LLM이 "React로 프론트엔드를 만들겠습니다"라고 시작하면, 이후 모든 결정이 React 중심으로 편향됩니다. Vue나 Svelte가 더 나은 선택일 수 있어도, 초기 앵커에서 벗어나지 못합니다.
🟡
해결: 독립 컨텍스트 윈도우
3개의 에이전트가 완전히 분리된 컨텍스트에서 동일한 문제를 풀면, 각자 다른 앵커를 형성합니다. 이것이 진정한 접근법의 다양성을 만듭니다.
🟢
결과: 비평 에이전트의 객관적 평가
비평 에이전트는 어떤 탐색자의 결과에도 "투자"하지 않았기 때문에, 순수하게 요구사항 대비 장단점을 평가할 수 있습니다.
관련 연구: 왜 다수의 에이전트가 효과적인가
이 접근법은 여러 학술 연구에서 그 효과가 검증되었습니다:
| 연구/논문 | 핵심 발견 | Ultraplan과의 연관성 |
|---|
| Self-Consistency (Wang et al., 2022) | 동일 프롬프트에 대해 여러 추론 경로를 샘플링하고 다수결로 답을 선택하면 정확도가 크게 향상 | 3 탐색자의 독립 탐색이 이 원리를 에이전트 수준으로 확장 |
| Tree of Thoughts (Yao et al., 2023) | 탐색 트리를 구성하여 여러 "생각 경로"를 평가하고, 가장 유망한 경로를 선택 | 각 탐색자가 하나의 "사고 분기"를 전담하고 비평자가 평가 |
| LLM Debate (Du et al., 2023) | 여러 LLM이 각자의 답을 제시하고 토론하면 사실적 정확성과 추론이 개선됨 | 비평 에이전트가 "토론 중재자" 역할을 하면서 최선을 합성 |
| Mixture-of-Agents (Wang et al., 2024) | 여러 LLM의 출력을 다른 LLM이 종합하면 개별 모델을 초월하는 성능 달성 | Ultraplan의 아키텍처가 이 패턴의 실전 구현체 |

Ultraplan의 핵심 아키텍처: 3 탐색자 + 1 비평자
이제 Ultraplan이 실제로 어떻게 작동하는지 깊이 살펴보겠습니다.
전체 구조
Ultraplan 멀티 에이전트 아키텍처
탐색자 A
Explorer Agent
독립 컨텍스트 | 성능 중심 접근
탐색자 B
Explorer Agent
독립 컨텍스트 | 안정성 중심 접근
탐색자 C
Explorer Agent
독립 컨텍스트 | 혁신적 접근
비평 에이전트 (Critic)
Synthesis Agent
3개 결과 평가 → 요소 결합 → 최종 플랜 합성
Phase 1: 병렬 탐색 (Three Explorers)
세 명의 탐색 에이전트는 완전히 동일한 태스크를 받지만, 각자 독립된 컨텍스트 윈도우에서 작업합니다. 서로의 존재를 모르고, 서로의 작업을 볼 수 없습니다.
이것이 왜 중요할까요?
독립성
각 에이전트는 완전히 분리된 메모리와 컨텍스트를 가집니다. 한 에이전트의 초기 결정이 다른 에이전트에 영향을 줄 수 없습니다.
다양성
같은 문제라도 LLM의 확률적 샘플링 덕분에 각 에이전트가 다른 출발점에서 시작합니다. 이것이 진정한 접근법의 다양성을 만듭니다.
병렬성
세 에이전트가 동시에 실행됩니다. 벽시계 기준 단일 에이전트 대비 약 1.5배의 시간에 3배의 탐색 결과를 얻습니다.

Phase 2: 비평과 합성 (One Critic)
비평 에이전트는 세 탐색자의 결과를 동시에 받습니다. 이 에이전트의 역할은:
분석
각 탐색자의 접근법이 원래 요구사항을 얼마나 충족하는지 검증합니다.
비교
각 접근법의 트레이드오프를 분석합니다. 성능 vs 안정성 vs 혁신성.
결합
각 탐색자의 최선의 요소를 골라 하나의 우월한 플랜으로 합성합니다.
검증
합성된 플랜이 각 탐색자가 놓친 실패 모드를 커버하는지 최종 확인합니다.
비평 에이전트가 특별한 이유: 이 에이전트는 어떤 탐색자의 결과에도 감정적 투자(sunk cost)가 없습니다. 자신이 작성한 것이 아니기 때문에, 순수하게 품질 기준으로만 평가할 수 있습니다. 이것이 인간 팀의 "코드 리뷰"와 유사한 구조적 이점입니다.

수렴과 발산의 시그널
탐색 결과에서 중요한 패턴이 나타납니다:
| 탐색자들이 수렴할 때 | 탐색자들이 발산할 때 |
|---|
| 세 에이전트가 비슷한 결론에 도달 | 세 에이전트가 완전히 다른 접근법 제시 |
| → 높은 신뢰도 시그널 | → 비평 에이전트의 합성이 더 가치있음 |
| 해당 접근법이 객관적으로 우월할 가능성 높음 | 문제 공간이 넓어서 최적해가 비자명함 |
| 비평 에이전트가 세부사항 통합에 집중 | 비평 에이전트가 전략적 선택에 집중 |
실전 체험: Ultraplan 시뮬레이터
아래 시뮬레이터에서 Ultraplan의 멀티 에이전트 프로세스를 직접 체험해 보세요. "시뮬레이션 시작" 버튼을 누르면 3개의 탐색 에이전트가 동시에 작업을 시작하고, 완료 후 비평 에이전트가 결과를 합성합니다.
Ultraplan 사용법 — 터미널에서 클라우드까지
시작하기
Ultraplan을 사용하는 방법은 세 가지입니다:
Ultraplan 실행 방법
/ultraplan 명령
CLI Command
/ultraplan + 프롬프트로 직접 실행
키워드 포함
Auto-detect
프롬프트에 "ultraplan" 단어를 포함
로컬 플랜에서 전환
Upgrade Path
로컬 플랜 승인 시 "Ultraplan으로 개선" 선택
hljs language-bash
/ultraplan 인증 서비스를 세션에서 JWT로 마이그레이션
ultraplan을 사용해서 결제 모듈을 마이크로서비스로 분리해줘
워크플로우
Ultraplan의 전체 워크플로우를 단계별로 살펴보겠습니다:
1. CLI에서 실행
터미널에서 /ultraplan + 태스크 입력
↓
2. 클라우드 탐색
3 탐색자가 코드베이스 분석 & 독립 플랜 생성
↓
3. 비평 & 합성
비평 에이전트가 3개 결과 평가·합성
↓
4. 브라우저에서 리뷰
인라인 댓글, 이모지 반응, 반복 수정
↓
5A. 웹에서 실행 → PR 생성
또는
5B. 터미널로 전송 → 로컬 실행
터미널 상태 표시
Ultraplan이 실행되는 동안 터미널에 다음과 같은 상태가 표시됩니다:
◇ ultraplan — 코드베이스 분석 & 플랜 초안 작성 중
◇ ultraplan needs your input — 확인 질문이 있음, 세션 링크 확인
◆ ultraplan ready — 플랜 완성! 브라우저에서 리뷰 가능

브라우저에서의 리뷰 경험
Ultraplan의 가장 혁신적인 부분 중 하나는 브라우저 기반 리뷰 인터페이스입니다. 터미널에서 텍스트로 계획을 리뷰하는 것과는 차원이 다른 경험을 제공합니다.
인라인 코멘트
플랜의 특정 부분을 하이라이트하고 직접 코멘트를 달 수 있습니다. "Phase 2에서 Redis 대신 Memcached를 쓰면 어떨까?"처럼 구체적인 피드백이 가능합니다. 전체 플랜에 대해 "다시 해줘"라고 말하는 것보다 훨씬 정밀한 조율이 가능합니다.
이모지 반응
각 섹션에 이모지로 빠르게 의사를 표현할 수 있습니다. 👍 은 승인, 🤔 은 재고 필요, ❌ 은 반대. 이 반응들이 Claude에게 어디를 수정해야 하는지 신호를 줍니다.
반복 수정
리뷰 → 수정 → 리뷰를 원하는 만큼 반복할 수 있습니다. 계획이 완벽해질 때까지 다듬을 수 있습니다. 이것은 마치 인간 아키텍트와 함께 설계 리뷰를 하는 것과 같습니다.
실행 경로 선택
최종 승인 후 두 가지 선택이 있습니다:
| 웹에서 실행 | 터미널로 전송 |
|---|
| "Approve Claude's plan and start coding" 선택 | "Approve plan and teleport back to terminal" 선택 |
| 클라우드에서 구현 → 자동 PR 생성 | 터미널에서 3가지 옵션 (현재 세션, 새 세션, 취소) |
| 로컬 환경 의존성 없이 작업 가능 | 로컬 도구, 환경변수 활용 가능 |
| 팀 리뷰에 최적 | 개인 개발 워크플로우에 최적 |
성능: 로컬 플랜 대비 4배 빠르다
Ultraplan의 성능 향상은 인상적입니다.
~1분
Ultraplan 평균 소요 시간
3 탐색자 병렬 + 1 비평자
~4분
로컬 Plan Mode 소요 시간
단일 에이전트 순차 처리
비밀은 병렬 처리에 있습니다. 세 탐색자가 동시에 실행되므로, 벽시계 시간은 단일 에이전트의 약 1.5배에 불과합니다. 하지만 3배의 탐색 결과를 얻고, 비평까지 거칩니다.
계획 없는 직접 구현
~2분 (+ 재작업 리스크)
AI 에이전트 계획 수립의 더 넓은 맥락
Ultraplan은 "AI 에이전트가 어떻게 계획을 세워야 하는가"라는 더 큰 질문의 일부입니다. 이 분야의 핵심 연구들을 살펴보겠습니다.
1. 계층적 태스크 분해 (Hierarchical Task Decomposition)
복잡한 태스크를 작은 하위 태스크로 분해하는 것은 AI 계획의 핵심입니다. STRIPS(1971)부터 시작된 고전적 AI 계획에서부터, 현대의 LLM 기반 에이전트까지 이 원리는 일관됩니다.
Ultraplan의 탐색자들은 각각 이 분해를 독립적으로 수행하며, 서로 다른 분해 전략을 탐색합니다. 한 탐색자는 기능 단위로, 다른 탐색자는 계층 단위로, 세 번째는 리스크 단위로 분해할 수 있습니다.
2. Monte Carlo Tree Search (MCTS)와의 유사성
AlphaGo를 탄생시킨 MCTS는 "탐색(exploration)"과 "활용(exploitation)"의 균형을 맞추는 알고리즘입니다. Ultraplan의 구조와 놀라운 유사성이 있습니다:
| MCTS | Ultraplan |
|---|
| 여러 경로를 동시에 탐색 | 3 탐색자가 독립 경로 탐색 |
| 시뮬레이션으로 각 경로의 가치 평가 | 비평 에이전트가 각 결과의 품질 평가 |
| 역전파로 최적 경로에 자원 집중 | 최선의 요소를 합성하여 최종 플랜 생성 |
| UCB 공식으로 탐색-활용 균형 | 독립 컨텍스트로 자연스러운 다양성 보장 |
3. 집단 지성과 다양성 정리 (Diversity Theorem)
경제학자 Scott Page의 다양성 정리(The Diversity Prediction Theorem)에 따르면:
집단 오차 = 평균 개인 오차 − 예측의 다양성
즉, 다양한 관점의 집단이 뛰어난 개인보다 더 나은 의사결정을 한다는 것입니다. 이 원리가 Ultraplan에 정확히 적용됩니다: 세 탐색자의 다양한 접근법이 비평 에이전트를 통해 개별 탐색자보다 우월한 플랜으로 합성됩니다.
4. Claude Code의 아키텍처적 맥락
Claude Code는 핵심적으로 단일 스레드 마스터 루프를 기반으로 합니다. 이것은 의도적인 설계 결정입니다: "단순한 단일 스레드 마스터 루프와 규율 있는 도구, 계획의 결합이 제어 가능한 자율성을 제공한다."
Ultraplan은 이 철학의 확장입니다. 로컬에서는 단일 스레드로 간결하게, 복잡한 계획이 필요할 때만 클라우드의 멀티 에이전트로 확장합니다. 이것은 "필요할 때만 복잡성을 추가한다"는 소프트웨어 설계의 기본 원칙과 일치합니다.
실전 활용 시나리오
시나리오 1: 대규모 리팩토링
hljs language-bash
/ultraplan 주문 처리 모놀리스를 이벤트 기반 마이크로서비스로 분리.
현재 상태: 모든 비즈니스 로직이 OrderService.java에 집중 (3,200줄).
제약: 무중단 배포 필수, 기존 REST API 호환 유지.
왜 Ultraplan이 적합한가: 이런 태스크에서 단일 에이전트는 하나의 분해 전략에 고착됩니다. Ultraplan의 세 탐색자는 Strangler Fig, Big Bang, 그리고 하이브리드 접근법을 각각 탐색하고, 비평 에이전트가 "무중단" 제약을 가장 잘 충족하는 전략을 합성합니다.
시나리오 2: 기술 스택 전환
hljs language-bash
/ultraplan React 18 프로젝트를 Next.js 16 App Router로 전환.
현재: CRA 기반, Redux, React Router.
목표: SSR/SSG 활용, 페이지 로드 시간 50% 단축.
세 탐색자의 가능한 접근:
- 탐색자 A: 점진적 마이그레이션 (pages → app router 단계적 전환)
- 탐색자 B: 클린 리라이트 (새 프로젝트에서 기존 컴포넌트 재활용)
- 탐색자 C: 병렬 운영 (Turborepo로 두 앱을 공존시키며 전환)
시나리오 3: 보안 강화
hljs language-bash
/ultraplan OWASP Top 10 대응을 위한 인증/인가 시스템 강화.
현재: 커스텀 세션 기반 인증, RBAC 없음.
데이터: 고객 PII 포함, 의료 데이터 규정(HIPAA) 준수 필요.
왜 여러 관점이 필수적인가: 보안은 단일 관점으로는 충분하지 않습니다. 한 탐색자는 인증 흐름에, 다른 탐색자는 데이터 암호화에, 세 번째는 감사 추적에 집중할 수 있습니다. 비평 에이전트가 이를 통합하여 빈틈없는 보안 플랜을 만듭니다.
제약사항과 고려사항
Ultraplan이 만능은 아닙니다. 사용 전에 알아두어야 할 점들이 있습니다:
💡
요구사항
• Claude Code v2.1.91 이상
• Claude Code on the web 계정
• GitHub 리포지토리 연동
• Amazon Bedrock, Google Vertex AI, Microsoft Foundry에서는 사용 불가 (Anthropic 클라우드 인프라에서만 실행)
💡
언제 로컬 Plan Mode가 더 나은가
• 단순한 버그 수정이나 작은 기능 추가
• 네트워크 연결이 불안정한 환경
• 비공개 코드베이스의 클라우드 전송이 우려되는 경우
• 빠른 피드백 루프가 필요한 프로토타이핑
미래 전망: AI 계획 수립의 진화
Ultraplan은 시작에 불과합니다. AI 코딩 에이전트의 계획 수립은 앞으로 더 진화할 것입니다.
전문화된 탐색자
현재 세 탐색자는 범용적이지만, 미래에는 각 탐색자가 특정 도메인에 특화될 수 있습니다. "보안 전문 탐색자", "성능 전문 탐색자", "접근성 전문 탐색자" 등이 프로젝트의 특성에 맞게 자동 배정될 수 있습니다.
인간-AI 공동 탐색
현재는 AI만 탐색을 수행하지만, 인간 개발자가 네 번째 "탐색자"로 참여할 수 있는 가능성도 있습니다. AI의 세 가지 제안과 인간의 한 가지 제안을 비평 에이전트가 함께 평가하는 하이브리드 모델입니다.
지속적 학습과 프로젝트 기억
Ultraplan이 과거 플랜의 성공/실패를 학습하여, 특정 코드베이스에 맞는 최적의 계획 전략을 점점 더 잘 선택하게 되는 미래를 상상할 수 있습니다.
핵심 정리
3+1
에이전트 아키텍처
3 탐색자 + 1 비평자
Ultraplan의 핵심 메시지는 명확합니다: AI 코딩의 미래는 "더 좋은 코드를 작성하는 것"이 아니라 "더 좋은 계획을 세우는 것"에 달려 있습니다. 그리고 더 좋은 계획은 다양한 관점, 독립적 탐색, 그리고 객관적 비평에서 나옵니다.
소프트웨어 개발에서 가장 비싼 실수는 코딩 실수가 아니라 설계 실수입니다. Ultraplan은 AI가 이 "설계의 실수"를 줄이기 위해 인간이 수천 년에 걸쳐 발전시켜 온 의사결정 원리 — 다양성, 독립성, 집단 지성 — 을 체계적으로 적용한 첫 번째 사례입니다.
참고 자료:
- Plan in the cloud with ultraplan — Claude Code 공식 문서
- Tversky, A. & Kahneman, D. (1974). "Judgment under Uncertainty: Heuristics and Biases." Science, 185(4157), 1124-1131.
- Wang, X. et al. (2022). "Self-Consistency Improves Chain of Thought Reasoning in Language Models." arXiv:2203.11171
- Yao, S. et al. (2023). "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." arXiv:2305.10601
- Du, Y. et al. (2023). "Improving Factuality and Reasoning in Language Models through Multiagent Debate." arXiv:2305.14325
- Wang, J. et al. (2024). "Mixture-of-Agents Enhances Large Language Model Capabilities." arXiv:2406.04692
- Page, S. (2007). The Difference: How the Power of Diversity Creates Better Groups, Firms, Schools, and Societies. Princeton University Press.




