블로그로 돌아가기

#스케일링 법칙
4개의 포스트
인사이트AI 정책다리오 아모데이
2026.06.18지수곡선 위의 정책: 다리오 아모데이는 왜 '나무수염'을 깨우려 하는가
2026년 6월, Anthropic CEO 다리오 아모데이가 '지수곡선 위의 정책'이라는 에세이를 발표했다. AI는 빛의 속도로 달리는데 정책은 거목(나무수염)의 속도로 움직인다는 이 글은, 발표 이틀 뒤 미국 정부가 바로 그 글이 말한 권한을 Anthropic 자신에게 휘두르면서 더 큰 화제가 됐다. '지수곡선'이 대체 무엇인지(스케일링 법칙과 트랜스포머)부터 그가 제안한 5대 정책까지, 2026년 가장 뜨거운 AI 정책 문서를 쉽고 자세하게 풀어본다.
코어닷투데이41분
기술보편 근사 정리UAT
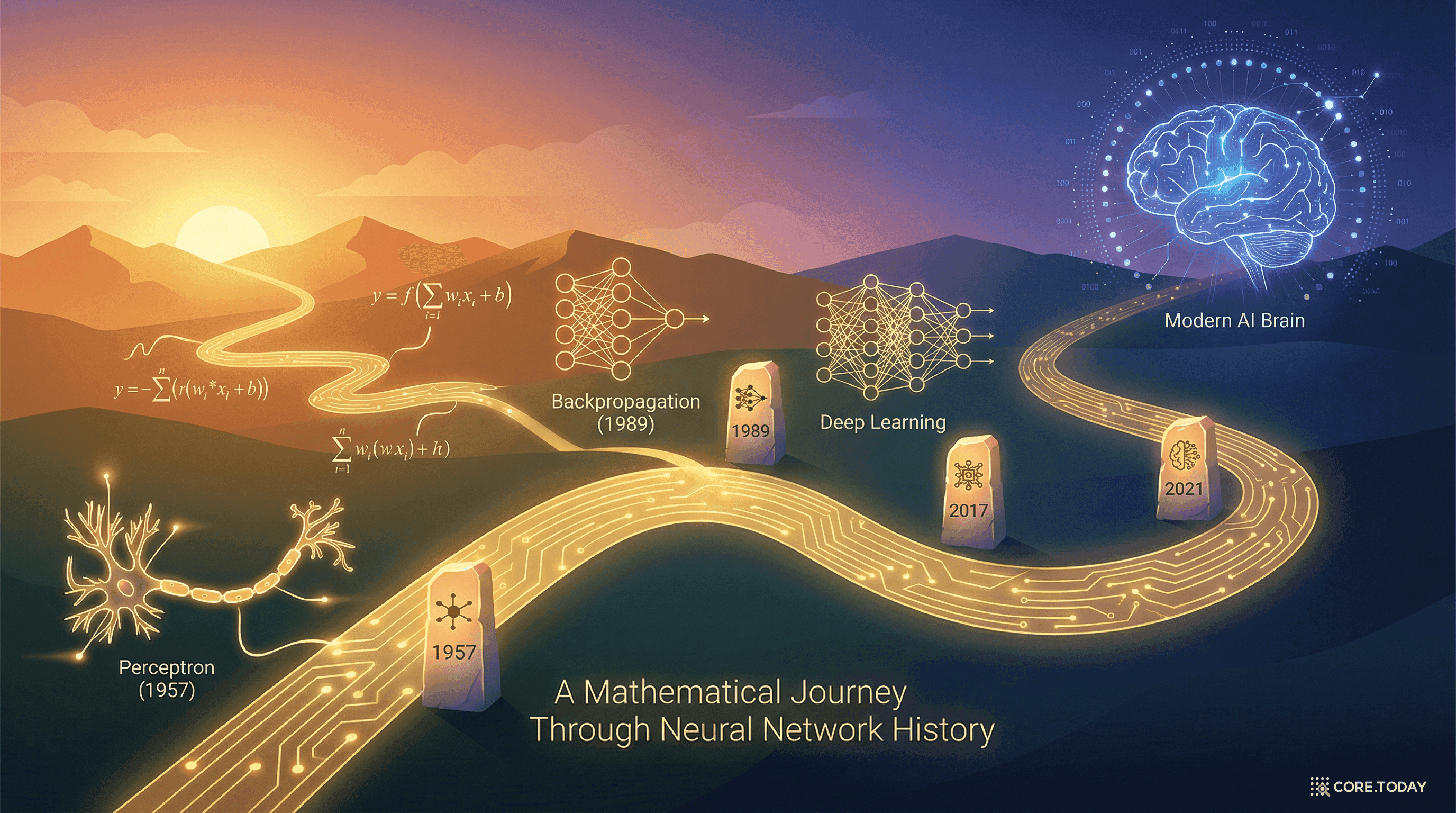
2026.04.04UAT에서 LoRA까지: 신경망이 세상을 배우는 수학적 여정
1989년, 한 수학 정리가 증명했다 — 뉴런이 충분하면 어떤 함수든 흉내 낼 수 있다. 이 '보편 근사 정리'에서 출발하여, 깊이의 혁명, Transformer, 스케일링 법칙을 거쳐 LoRA까지 — 신경망이 세상의 모든 것을 배우는 수학적 여정을 따라간다.
코어닷투데이49분
기술BLT토크나이저
2026.01.19Byte Latent Transformer: 토큰을 버리고 바이트로 돌아간 AI의 반란
GPT부터 Llama까지, 모든 LLM은 '토크나이저'라는 전처리 단계에 의존한다. Meta AI의 BLT는 이 관행을 뒤집었다 — 바이트를 직접 처리하되, 엔트로피 기반으로 '어려운 곳에 더 많은 연산'을 동적 할당하여 80억 스케일에서 Llama 3에 필적하는 성능을 달성했다.
코어닷투데이31분
인사이트스케일링 법칙Chinchilla
2025.10.20친칠라 스케일링 법칙: '더 크게'가 정답이 아니었다 — AI 훈련 패러다임을 뒤집은 논문
GPT-3는 '과소 훈련'된 모델이었다? 2022년 DeepMind의 친칠라 논문이 밝힌 '모델 크기 vs 데이터 양'의 최적 비율, 그리고 업계가 이를 넘어선 이유까지 — AI 스케일링의 역사를 총정리합니다.
코어닷투데이33분