들어가며: 0.09%가 만드는 7시간의 차이
"우리 서비스 가용성 99.9%입니다."
이 말을 들으면 대부분 "거의 완벽하네"라고 생각한다. 하지만 숫자를 펼쳐보면 이야기가 달라진다.
99.9%에서 99.99%로 가는 데는 나인(9) 하나가 추가될 뿐이다. 하지만 허용 다운타임은 8시간 45분에서 52분 33초 로 — 거의 10배 줄어든다. 이 0.09%의 차이가 사용자 이탈, 매출 손실, 브랜드 신뢰도를 좌우한다.
Amazon은 100ms의 지연이 매출 1%를 떨어뜨린다고 밝혔다. 서비스가 살아 있는 것은 기능이 아니라 사업의 전제 조건 이다. 그래서 Google은 2003년, 소프트웨어 엔지니어에게 운영을 맡기면 어떤 일이 벌어질까? 라는 질문에서 SRE를 만들었다.
1. SRE의 탄생: "소프트웨어 엔지니어가 운영을 설계하면"
Ben Treynor Sloss의 실험
2003년, Google의 엔지니어링 VP Ben Treynor Sloss 는 혁명적인 실험을 시작했다. 전통적인 운영(Ops) 팀 대신, 소프트웨어 엔지니어로 구성된 팀 에게 프로덕션 시스템의 운영을 맡긴 것이다.
그의 유명한 정의:
"SRE is what happens when you ask a software engineer to design an operations function."
아이디어는 단순했다: 전통적 운영팀은 문제가 생기면 수동으로 고쳤지만, 소프트웨어 엔지니어라면 이 반복을 코드로 해결할 것이다.
전통적 Ops vs SRE
비교 항목 전통적 Ops SRE 팀 구성 시스템 관리자 중심 소프트웨어 엔지니어 중심 문제 해결 방식 수동 대응 (티켓 기반) 자동화 코드 작성 확장 방식 인원 충원 시스템/도구 개선 장애 대응 "누가 실수했나" "시스템이 왜 허용했나" 성공 기준 장애 0건 에러 버짓 내 운영 변경 속도 느림 (변경 = 위험) 빠름 (자동화된 안전장치)
핵심은 마인드셋의 전환 이다. 전통적 운영은 "변경은 위험하다, 최소화하라"였다면, SRE는 "변경은 불가피하다, 안전하게 빠르게 하라"로 바뀌었다. 2026년 현재, SRE 팀은 Google 검색, Gmail, YouTube 등 모든 핵심 서비스의 신뢰성을 책임진다.
2. SLI, SLO, SLA — 신뢰성을 숫자로 정의하는 법
SRE의 출발점은 "좋은 서비스란 무엇인가?"를 숫자로 정의하는 것 이다. 감각이나 직관이 아니라, 측정 가능한 지표로.
세 가지 약어의 관계
SLI (Service Level Indicator)
↓ 측정값에 목표를 설정하면
SLO (Service Level Objective)
↓ 목표를 계약으로 만들면
SLA (Service Level Agreement)
SLI — 무엇을 측정할 것인가
SLI(Service Level Indicator) 는 서비스 품질을 나타내는 정량적 측정값 이다. "서비스가 좋다/나쁘다"를 판단하는 온도계 같은 것이다.
대표적인 SLI 4가지:
핵심 SLI 4가지
가용성 (Availability)
성공한 요청 수 / 전체 요청 수
지연 시간 (Latency)
요청~응답까지 걸리는 시간 (p50, p99)
에러율 (Error Rate)
5xx 응답 수 / 전체 응답 수
처리량 (Throughput)
초당 처리 가능한 요청 수 (RPS)
SLO — 얼마나 좋아야 하는가
SLO(Service Level Objective) 는 SLI에 목표값 을 설정한 것이다. "가용성 99.95%를 유지하겠다"는 약속이다.
가용성 SLO
월간 가용성 99.95% 이상 유지
→ 월 다운타임 허용: 21분 54초
지연 시간 SLO
p50(중앙값): 200ms 이하
p99(최악 1%): 1,000ms 이하
에러율 SLO
5xx 에러율 0.1% 미만 유지
→ 요청 100만 건당 에러 1,000건 미만
SLO를 설정할 때 흔한 실수: 100%를 목표로 잡는 것 이다. 100%는 달성 불가능할 뿐 아니라, 모든 변경(배포, 업데이트)을 막는 독이 된다. SRE는 의도적으로 100% 미만의 목표를 설정한다 — 이것이 다음에 나올 "에러 버짓"의 출발점이다.
SLA — 어기면 얼마를 물어줄 것인가
SLA(Service Level Agreement) 는 SLO를 비즈니스 계약 으로 만든 것이다. SLO를 지키지 못하면 고객에게 크레딧, 환불, 위약금 등을 제공한다.
구분 SLO SLA 대상 내부 엔지니어링 팀 외부 고객 강제력 기술적 목표 법적/계약적 구속력 수준 더 엄격 (여유분 확보) SLO보다 약간 느슨 예시 가용성 99.95% 가용성 99.9% (미달 시 10% 크레딧)
3. 에러 버짓: "실패해도 괜찮다, 예산 안에서만"
가장 혁신적인 아이디어
SRE에서 가장 반직관적이면서 가장 혁신적인 개념이 에러 버짓(Error Budget) 이다.
에러 버짓의 공식은 단순하다:
에러 버짓 = 1 − SLO \text{에러 버짓} = 1 - \text{SLO} 에러 버짓 = 1 − SLO
SLO가 99.95%라면, 에러 버짓은 0.05% 이다. 월간 요청 1억 건 기준으로 50,000건의 에러가 허용 된다는 뜻이다.
에러 버짓이 작동하는 방식
1
버짓 충분 (여유 상태)
에러 버짓이 70% 이상 남아있다. 적극적으로 새 기능을 배포 한다. 빠른 실험, 대담한 변경이 가능하다. 이 상태에서는 개발팀이 속도를 내는 것이 올바른 선택이다.
2
버짓 소진 중 (주의 상태)
에러 버짓이 30~70% 남아있다. 배포 속도를 조절 하고, 리스크가 큰 변경은 카나리 배포로 제한한다. SRE 팀이 개발팀과 협의해서 우선순위를 조정한다.
3
버짓 소진 (동결 상태)
에러 버짓이 바닥났다. 기능 배포를 중단 하고, 신뢰성 개선 작업에만 집중한다. 이것은 벌이 아니라, 시스템이 "지금은 안정화가 우선"이라고 알려주는 신호이다.
에러 버짓의 진짜 힘: 개발팀("빨리 배포")과 운영팀("건드리지 마라")의 갈등을 데이터로 해결 한다. "에러 버짓이 남아있는가?"라는 객관적 질문으로 바꾸는 것이다.
월간 에러 버짓 소진 상태 예시 (SLO 99.95%)
4. 토일(Toil) 줄이기: 반복 작업을 자동화하라
토일이란 무엇인가
SRE에서 토일(Toil) 은 단순 반복적이고, 자동화 가능하며, 서비스 성장에 비례해서 늘어나는 운영 작업을 말한다.
토일(Toil)의 6가지 특성
수동적
사람이 직접 해야 함
반복적
같은 작업을 계속 반복
자동화 가능
기계가 대신할 수 있음
전술적
즉각 대응형, 전략 없음
가치 없음
서비스를 개선하지 않음
선형 증가
트래픽에 비례해 늘어남
예를 들어, "수동 서버 증설"은 토일이고, "자동 스케일링 시스템 구축"은 엔지니어링 워크이다.
Google의 50% 규칙
Google SRE의 핵심 원칙: SRE 엔지니어의 업무 시간 중 토일은 최대 50%로 제한한다. 나머지 50% 이상은 반드시 엔지니어링 프로젝트 — 즉 자동화, 도구 개발, 시스템 설계 — 에 투자해야 한다.
토일이 50%를 넘으면 자동화 프로젝트를 시작하거나 인원을 충원해야 한다. 토일을 줄이는 것은 게으른 것이 아니라, 시스템이 인간 없이도 스스로 회복하도록 만드는 엔지니어링 이다.
5. 모니터링: 메트릭, 로그, 트레이스 — 관측 가능성의 세 기둥
장애가 발생했을 때 가장 먼저 나오는 질문: "지금 무슨 일이 벌어지고 있는가?"
이 질문에 답하려면 시스템이 관측 가능(observable) 해야 한다. SRE에서는 이를 옵저버빌리티(Observability) 라 부르며, 세 가지 기둥으로 구성된다.
세 가지 기둥
옵저버빌리티의 3가지 기둥
메트릭 (Metrics)
무엇이 발생했는가
숫자로 된 시계열 데이터. CPU, 메모리, 에러율 등
로그 (Logs)
왜 발생했는가
개별 이벤트의 상세 기록. 에러 메시지, 스택 트레이스
트레이스 (Traces)
어디서 발생했는가
요청의 전체 여정을 추적. 서비스 간 호출 경로
각 기둥이 답하는 질문
상황 : 사용자가 "결제가 안 돼요"라고 신고했다.
메트릭
"에러율이 5%를 넘었다" — 대시보드의 그래프가 빨간색으로 변하고, 알림이 온다. 문제가 발생했다는 사실 을 안다.
로그
"결제 게이트웨이 타임아웃, 30초 초과" — 에러 로그를 열어 구체적인 에러 메시지를 확인한다. 왜 에러가 나는지 안다.
트레이스
"주문 서비스 → 결제 서비스 → PG사 API에서 병목" — 요청이 어디서 멈췄는지 전체 경로를 추적한다. 어디서 문제가 생겼는지 안다.
대표적 도구 조합: 메트릭 은 Prometheus + Grafana(오픈소스) 또는 Datadog(SaaS), 로그 는 ELK Stack 또는 Splunk, 트레이스 는 Jaeger 또는 Datadog APM. 올인원이 필요하면 Datadog이 대세이다.
알림 피로를 피하는 법
모니터링에서 가장 흔한 실수는 알림 피로(Alert Fatigue) 이다. Google SRE의 원칙: 긴급하고, 행동 가능하고, 중복 없는 알림만 보낸다. "CPU 90% 초과" 같은 원인 기반이 아니라, "에러율이 SLO를 위협" 같은 결과 기반 알림 을 사용한다.
6. 인시던트 관리: 온콜, 인시던트 커맨더, 블레임리스 포스트모텀
온콜 (On-Call)
서비스는 24시간 돌아간다. 새벽 3시에 장애가 나면 누군가는 대응해야 한다. 이것이 온콜(On-Call) 제도이다.
SRE 팀원들은 1~2주 간격으로 온콜 로테이션 을 돈다. 알림을 5분 내에 확인하고, 필요하면 에스컬레이션한다. Google의 규칙: 교대 근무당 페이지(알림) 최대 2건 . 그 이상이면 시스템에 구조적 문제가 있다는 뜻이다.
인시던트 대응 프로세스
대규모 장애가 발생하면 인시던트 관리 프로세스 가 작동한다. 핵심은 역할 분담:
IC
인시던트 커맨더 — 전체 상황을 총괄. 의사결정, 우선순위 판단, 커뮤니케이션 관리
OL
운영 리드 — 실제 기술적 대응 수행. 로그 분석, 롤백, 핫픽스 배포
COMMS
커뮤니케이션 리드 — 경영진, 고객, 다른 팀에 상황 공유. 상태 페이지 업데이트
SME
주제 전문가 — 해당 시스템을 가장 잘 아는 사람. 필요 시 호출되어 기술 지원
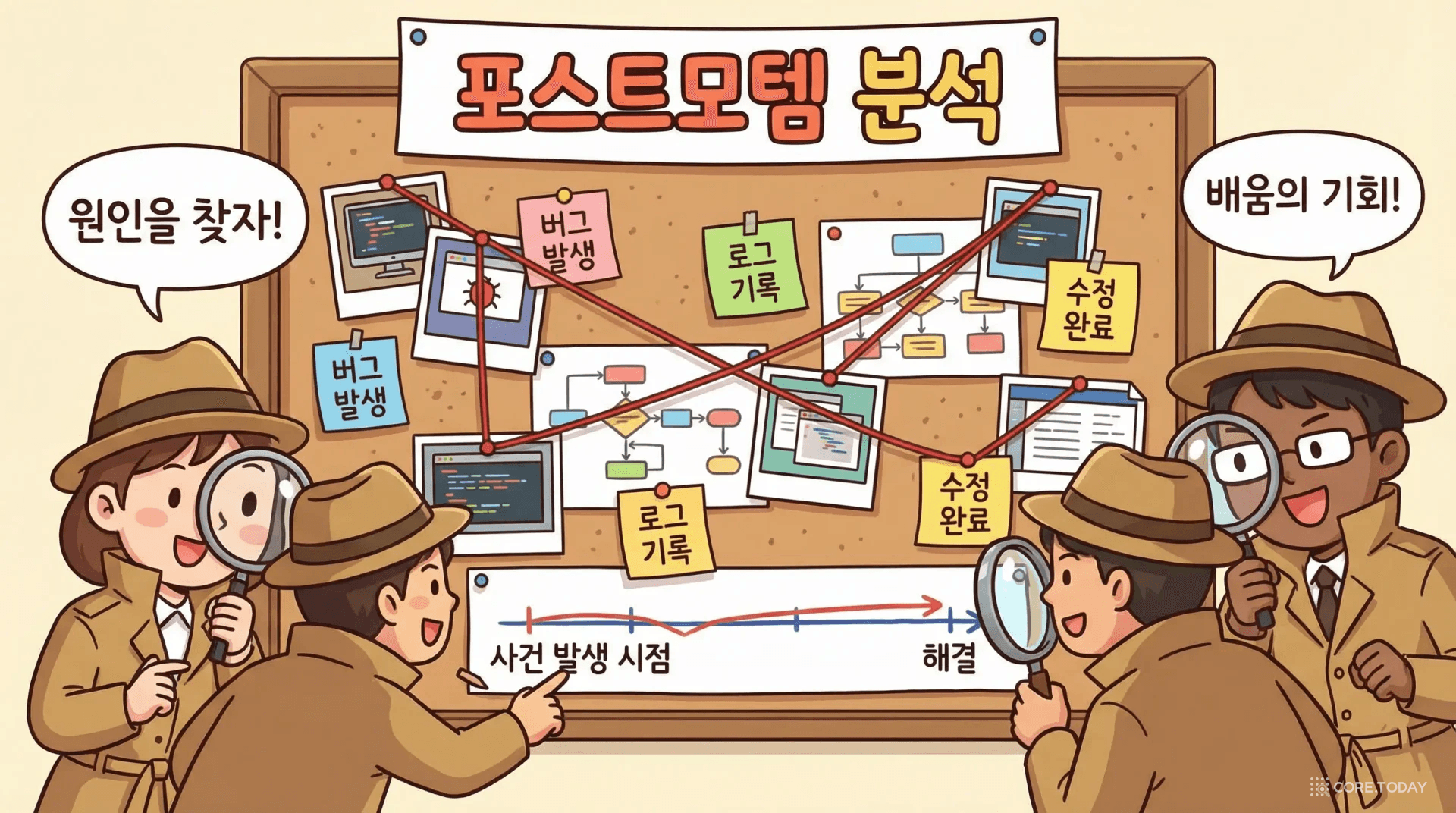
블레임리스 포스트모텀 (Blameless Postmortem)
장애가 복구된 후에는 포스트모텀(사후 분석) 을 작성한다. SRE에서 포스트모텀의 핵심 원칙은 블레임리스(Blameless) — 사람을 탓하지 않는 것이다.
"김 대리가 실수로 프로덕션 DB를 날렸다" ← 나쁜 포스트모텀
"프로덕션 DB 삭제 명령이 확인 절차 없이 실행 가능했다" ← 좋은 포스트모텀
Q
왜 블레임리스인가?
사람을 탓하면 두 가지 나쁜 일이 벌어진다. 첫째, 실수를 숨기게 된다 . 장애를 보고하면 벌을 받으니, 작은 장애는 쉬쉬하고 넘어가게 된다. 둘째, 근본 원인을 놓치게 된다 . 진짜 문제는 그 실수를 허용한 시스템인데, 사람을 탓하면 시스템은 그대로 남는다.
A
좋은 포스트모텀의 구조
1) 타임라인 : 장애 발생부터 복구까지 분 단위 기록 → 2) 근본 원인 : 기술적 원인 분석 (5 Whys 기법 활용) → 3) 영향 범위 : 영향받은 사용자 수, 매출 손실 → 4) 액션 아이템 : 재발 방지를 위한 구체적 조치 + 담당자 + 기한
!
핵심 효과
같은 장애가 두 번 발생하지 않는다 . 포스트모텀의 액션 아이템은 반드시 추적되고, 실행되고, 검증된다. Google에서는 포스트모텀 작성이 문화이며, 매주 "포스트모텀 리뷰" 미팅에서 전체 SRE 팀이 함께 학습한다.
7. 카오스 엔지니어링: 일부러 고장 내서 더 강해지는 법
Netflix의 카오스 몽키
2010년, Netflix가 AWS로 이전하면서 카오스 몽키(Chaos Monkey) 를 만들었다. 이름 그대로, 프로덕션 환경에서 무작위로 서버를 꺼버리는 프로그램이다.
논리는 명확하다: 통제된 환경에서 미리 경험하는 것이 새벽 3시에 당하는 것보다 낫다.
카오스 엔지니어링의 원칙
1단계
정상 상태를 정의 한다. "이 시스템이 정상이면 p99 지연이 200ms 이하이고 에러율이 0.1% 미만이다."
2단계
가설을 세운다. "데이터베이스 레플리카 하나가 죽어도 서비스는 정상 동작할 것이다."
3단계
실험을 실행 한다. 실제로 레플리카를 중단시킨다 — 프로덕션에서!
4단계
결과를 분석 한다. 가설이 맞았나? 페일오버가 정상 작동했나? 예상 못한 부수 효과는?
대표 도구: Netflix의 Chaos Monkey (무작위 인스턴스 종료), Gremlin (GUI 기반 안전한 실험), CNCF의 Litmus (K8s 네이티브), AWS FIS (관리형), Chaos Mesh (네트워크 장애 주입).
단, 준비 없이 시작하면 진짜 장애 가 된다. 모니터링이 먼저 갖춰져야 하고, 롤백 계획이 필수이며, 범위를 좁게(인스턴스 1개부터) 시작해야 한다.
8. SRE vs DevOps vs Platform Engineering: 뭐가 다른가
이 세 가지 용어는 종종 혼동된다. 정리하면:
핵심 차이
비교 항목 DevOps SRE Platform Engineering 본질 문화/철학 직무/역할 제품/플랫폼 핵심 질문 "개발과 운영을 어떻게 합칠까?" "서비스를 어떻게 신뢰성 있게 운영할까?" "개발자가 셀프서비스로 인프라를 쓰게 하려면?" 탄생 2009년 (Patrick Debois) 2003년 (Google) 2020년대 (진화) 초점 CI/CD 파이프라인, 협업 SLO, 에러 버짓, 인시던트 IDP (내부 개발자 플랫폼) 결과물 파이프라인, 자동화 프로세스 SLO 대시보드, 런북, 자동 복구 셀프서비스 포털, 골든 패스 관계 방향성 (Why) 구현체 (How) 플랫폼 (What)
Google이 직접 밝힌 정의: "Class SRE implements interface DevOps." DevOps는 인터페이스(원칙)이고, SRE는 그 구현체(실천)이고, Platform Engineering은 그 결과물의 제품화이다.
세 가지는 상호 배타적이지 않다. DevOps 문화 + SRE 방법론 + Platform Engineering의 개발자 경험이 이상적인 조합이다.
9. 한국 기업의 SRE: 카카오, 네이버, 토스 사례
2022년 카카오 데이터센터 화재 — SRE의 중요성이 증명된 순간
2022년 10월 15일, 카카오의 SK C&C 판교 데이터센터에서 화재가 발생했다. 카카오톡, 카카오맵, 카카오페이, 카카오택시 — 사실상 한국인의 디지털 생활 전체가 동시에 멈췄다.
!
문제: 단일 데이터센터 의존
핵심 서비스가 하나의 데이터센터에 집중되어 있었다. 이중화(redundancy)가 불충분했고, 재해 복구(DR) 계획이 실전에서 검증되지 않았다 . 카오스 엔지니어링의 부재가 드러난 순간이었다.
→
대응: SRE 조직 대규모 확대
카카오는 사고 이후 SRE 전담 조직을 크게 확대 했다. 멀티 리전 인프라 구축, DR 자동화, 정기적 재해 복구 훈련(Game Day)을 도입했다. SRE 채용도 대폭 늘렸다.
O
결과: 한국 IT 업계 전체의 변화
카카오 사태는 한국 IT 업계에 "SRE는 선택이 아닌 필수" 라는 인식을 심어주었다. 과기정통부가 주요 플랫폼 사업자에 재해 복구 체계 강화를 권고했고, 다른 빅테크들도 SRE 투자를 가속화했다.
네이버: 대규모 트래픽 SRE
네이버는 서비스별 세분화된 SLO와 에러 버짓 기반 배포를 운영한다. 특히 자체 개발한 분산 트레이싱 도구 Pinpoint 는 GitHub 13,000+ 스타를 받은 세계적인 오픈소스 APM으로 성장했다.
토스: 금융 서비스의 SRE
토스는 송금 성공률 SLO 99.99% 이상 을 유지한다. 장애 감지부터 에스컬레이션까지 자동화하고, PG사 연동 실패 등 금융 특화 카오스 엔지니어링을 정기 실행한다. 블레임리스 포스트모텀을 전사에 공개하는 문화도 주목할 만하다.
2022년 카카오 사태를 기점으로, SRE는 한국 IT 업계에서 가장 빠르게 성장하는 직군이 되었다. 카카오, 네이버, 토스, 쿠팡, 배달의민족 모두 SRE 채용을 대폭 확대 중이다.
10. SRE 시작하기: 책, 도구, 커리어 가이드
필독서 3권
SRE 필독서
Site Reliability Engineering
Google SRE Book (2016)
SRE의 바이블. Google의 실제 사례 기반. 무료 온라인 공개
The Site Reliability Workbook
Google (2018)
실전 가이드. SLO 설정법, 모니터링 구축, 인시던트 관리 실습
Building Secure & Reliable Systems
Google (2020)
보안과 신뢰성의 교차점. 보안 SRE 관점
세 권 모두 Google이 무료로 공개 했다. sre.google/books 에서 전문을 읽을 수 있다.
실전 도구 가이드
SRE를 시작하려면 어떤 도구부터 익혀야 할까? 단계별로 정리했다.
입문
Prometheus + Grafana 로 메트릭 수집/시각화를 시작한다. Docker Compose로 로컬에 띄우고, 자신의 서비스 메트릭을 대시보드로 만들어보는 것이 첫 걸음.
기초
PagerDuty 또는 OpsGenie 로 온콜/인시던트 관리를 경험한다. 알림 정책을 설정하고, 에스컬레이션 규칙을 만들어본다. 무료 티어로 시작 가능.
심화
Terraform + Kubernetes 로 인프라를 코드로 관리한다. IaC(Infrastructure as Code)는 SRE의 핵심 스킬이다. 수동 설정 변경 대신 Git으로 인프라를 버전 관리한다.
고급
OpenTelemetry 로 분산 트레이싱을 구축한다. 마이크로서비스 간 요청 추적, 병목 지점 발견. CNCF가 밀고 있는 관측 가능성의 표준이다.
인시던트 관리 도구는 PagerDuty (시장 1위, AI 자동 분류), OpsGenie (Atlassian 통합, $9.45~/월), Grafana OnCall (오픈소스, 무료)이 대표적이다.
SRE 커리어 로드맵
SRE가 되려면 어떤 경로를 밟아야 할까?
소프트웨어 엔지니어 or 시스템 엔지니어
↓ Linux, 네트워크, 코딩 기초
주니어 SRE / DevOps 엔지니어
↓ 모니터링, CI/CD, K8s, IaC 경험
SRE (2~5년차)
↓ SLO 설계, 인시던트 관리, 카오스 엔지니어링
시니어 SRE / SRE 매니저
핵심 역량 : Python/Go 프로그래밍, Linux, AWS/GCP 클라우드, Docker + Kubernetes, Terraform(IaC), Prometheus + Grafana(모니터링), TCP/IP/DNS 네트워크 기초, 그리고 장애 상황의 소통 능력.
마치며: 신뢰성은 기능이 아니라 문화이다
이 글에서 다룬 내용을 한 장으로 정리하면:
SRE 핵심 개념 요약
SLI/SLO/SLA
신뢰성을 숫자로 정의한다
에러 버짓
실패 허용량으로 속도와 안정의 균형
토일 자동화
반복 작업을 코드로 대체
옵저버빌리티
메트릭, 로그, 트레이스
인시던트 관리
온콜, IC, 블레임리스 포스트모텀
카오스 엔지니어링
의도적 장애로 복원력 검증
SRE는 도구의 집합이 아니라, 서비스 신뢰성을 엔지니어링 문제로 접근하는 사고방식 이다. "100%는 불가능하다"를 받아들이는 겸손, 장애에서 배우는 블레임리스 문화, 반복을 참지 않는 자동화 본능, 모든 것을 숫자로 결정하는 원칙.
카카오 사태가 보여주었듯, SRE는 평소에는 보이지 않지만 없으면 모든 것이 멈추는 일 이다. 처음 시작한다면, Google SRE Book을 읽고, Prometheus + Grafana를 로컬에 띄우고, 자신의 서비스에 SLO를 하나 설정해보자. 그것이 첫 걸음이다.
참고 자료
Google SRE Books (무료) — SRE 바이블 3부작Beyer, B. et al., Site Reliability Engineering: How Google Runs Production Systems , O'Reilly (2016)
Google Cloud: SRE Principles — Google Cloud의 SRE 가이드Netflix: Chaos Engineering — Netflix 기술 블로그네이버 Pinpoint (GitHub) — 네이버 오픈소스 APMAtlassian: SRE vs DevOps — SRE와 DevOps 비교PagerDuty Incident Response Guide — 무료 인시던트 대응 가이드