들어가며: "나는 Ubuntu를 실행하고 있다"는 착각
터미널에 이 명령어를 입력한다.
hljs language-bash
docker run -it ubuntu bash
프롬프트가 뜬다. apt update도 된다. cat /etc/os-release를 치면 "Ubuntu 22.04"라고 대답한다. 모든 것이 Ubuntu처럼 보인다.
하지만 이것은 Ubuntu가 아니다.
더 정확히 말하면, 당신이 실행하고 있는 것은 호스트 머신의 Linux 커널 위에 Ubuntu의 유저랜드 도구들(apt, bash, glibc 등)을 얹은 것이다. Ubuntu 커널? 없다. Ubuntu 부트로더? 없다. Ubuntu 디바이스 드라이버? 역시 없다.
이 글은 이 "착각"을 해부한다. 왜 컨테이너 속 Ubuntu가 진짜 Ubuntu가 아닌지, 베이스 이미지에는 실제로 무엇이 들어있는지, 그리고 이 사실이 왜 중요한지를 역사·원리·실전 사례로 풀어보겠다.

제1장: 운영체제의 해부학 — 커널과 유저랜드
베이스 이미지를 이해하려면 먼저 운영체제(OS)의 구조를 알아야 한다. 많은 사람이 "Ubuntu"나 "Fedora"를 하나의 덩어리로 생각하지만, 사실 모든 Linux 배포판은 크게 두 층으로 나뉜다.
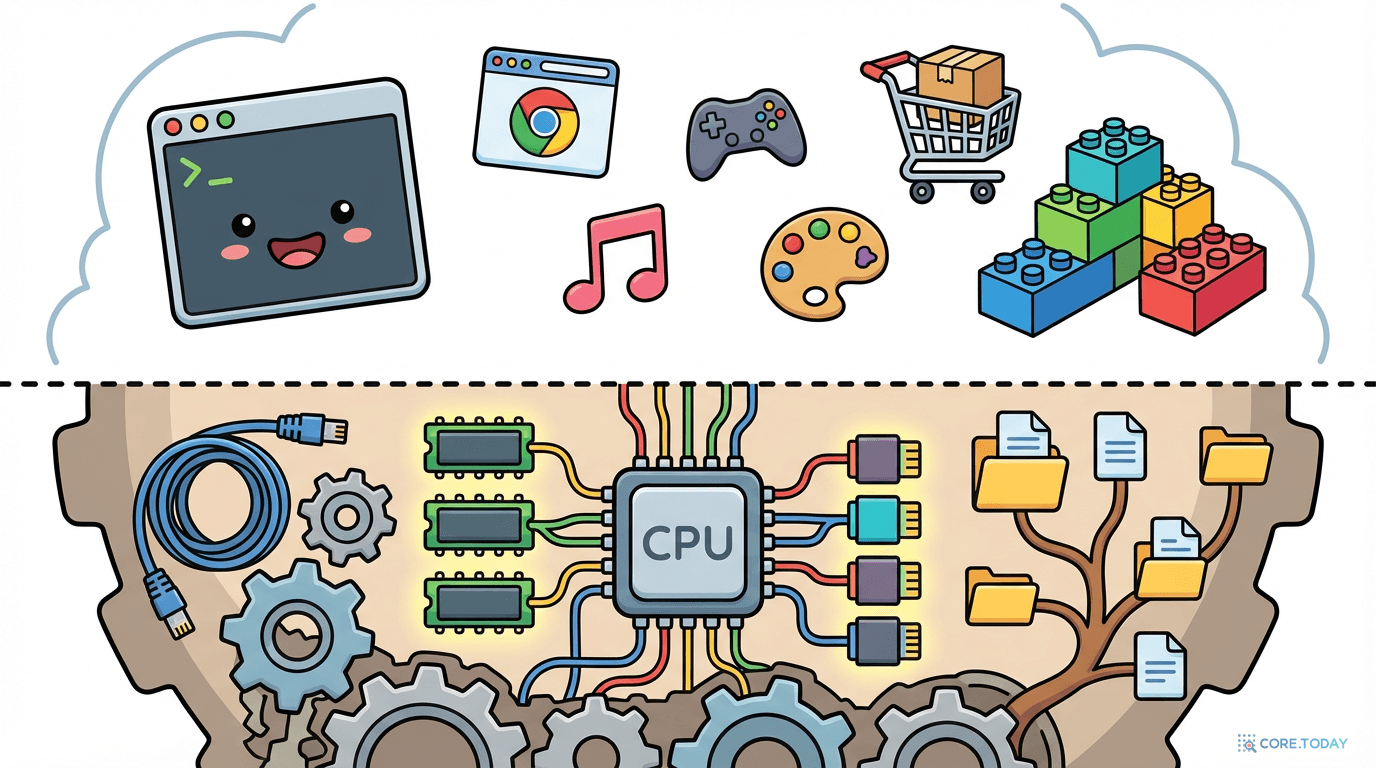
커널(Kernel): 보이지 않는 지휘자
커널은 운영체제의 핵심 엔진이다. 하드웨어와 직접 대화하며, 다음을 담당한다:
- 프로세스 스케줄링 — 어떤 프로그램이 CPU를 얼마나 쓸지 결정
- 메모리 관리 — 각 프로세스에 메모리를 할당하고 보호
- 파일 시스템 — 디스크의 0과 1을 파일과 디렉토리로 변환
- 네트워크 스택 — TCP/IP 통신 처리
- 디바이스 드라이버 — 키보드, 그래픽 카드, 네트워크 카드 제어
- 보안 — 누가 무엇에 접근할 수 있는지 통제
비유하자면, 커널은 건물의 기초·배관·전기 배선이다. 보이지 않지만 모든 것이 이 위에서 돌아간다.
유저랜드(Userland): 눈에 보이는 모든 것
유저랜드는 커널 위에서 실행되는 사용자 공간의 모든 프로그램과 라이브러리다:
- 셸 —
bash, sh, zsh
- 핵심 유틸리티 —
ls, cat, grep, chmod
- 패키지 매니저 —
apt(Ubuntu/Debian), dnf(Fedora), apk(Alpine)
- C 표준 라이브러리 —
glibc(대부분의 배포판) 또는 musl(Alpine)
- 설정 파일 —
/etc/passwd, /etc/apt/sources.list 등
비유하자면, 유저랜드는 건물의 인테리어·가구·가전제품이다. 같은 기초(커널) 위에 IKEA 스타일(Ubuntu)을 얹을 수도 있고, 미니멀 스타일(Alpine)을 얹을 수도 있다.
🏠
핵심 비유
Ubuntu, Debian, Fedora, Alpine은 모두 같은 Linux 커널 위에 다른 인테리어(유저랜드)를 올린 것이다. 마치 같은 아파트 골조에 다른 인테리어를 한 집들처럼.
📦
Docker 베이스 이미지의 정체
Docker 베이스 이미지는 이 인테리어(유저랜드)만 패키징한 것이다. 커널(골조)은 호스트 머신에서 빌려 쓴다.
시스템 콜: 두 세계를 잇는 다리
유저랜드 프로그램이 커널의 기능을 사용하려면 시스템 콜(syscall)을 거쳐야 한다. open(), read(), write(), fork(), exec() 같은 함수들이다.
예를 들어 컨테이너 안에서 ls /home을 실행하면:
1
유저랜드: ls 바이너리가 실행됨 (컨테이너의 /bin/ls)
2
syscall: ls가 getdents64() 시스템 콜을 호출
3
호스트 커널: 호스트의 Linux 커널이 이 syscall을 처리 (컨테이너의 커널이 아님!)
4
결과 반환: 커널이 디렉토리 목록을 돌려줌 → ls가 화면에 출력
핵심: 컨테이너 안에서 어떤 명령을 실행하든, 시스템 콜은 항상 호스트 커널로 간다. "Ubuntu 컨테이너"든 "Alpine 컨테이너"든 상관없다.
제2장: 베이스 이미지에는 실제로 뭐가 들어있나?
이제 docker pull ubuntu를 했을 때 실제로 다운로드되는 것이 무엇인지 해부해 보자.
들어있는 것 ✅
필수 바이너리
/bin/bash, /bin/ls
/usr/bin/apt, /usr/bin/dpkg
공유 라이브러리
glibc (libc.so.6)
pthread, math 라이브러리
설정 파일
/etc/apt/sources.list
/etc/passwd, /etc/group
DNS 설정
패키지 데이터베이스
dpkg/apt 메타데이터
설치된 패키지 목록
들어있지 않은 것 ❌
이것이 핵심이다. 베이스 이미지에는 다음이 절대 포함되지 않는다:
- Linux 커널 — 호스트에서 공유
- 부트로더 (GRUB 등) — 컨테이너는 "부팅"하지 않음
- 디바이스 드라이버 — 하드웨어 접근은 호스트 커널의 몫
- 커널 모듈 (.ko 파일) — 호스트에 설치된 것을 사용
- initramfs — 부팅 초기화 과정이 없음
베이스 이미지는 "파일 시스템 스냅샷"이다. 운영체제가 아니다. 특정 배포판의 유저랜드 파일들을 tar로 묶어놓은 것에 불과하다.
직접 확인해 보기
hljs language-bash
docker run ubuntu du -sh / 2>/dev/null
78MB vs 4GB — 차이가 나는 이유가 바로 커널과 시스템 서비스의 부재다.
제3장: 커널 공유의 마법 — 하나의 커널, 수백 개의 컨테이너
Docker의 가장 강력한 특성은 모든 컨테이너가 호스트의 단일 커널을 공유한다는 것이다.
증거: 모든 "배포판"이 같은 커널을 보고한다
hljs language-bash
uname -r
docker run ubuntu uname -r
docker run alpine uname -r
docker run fedora uname -r
Ubuntu, Alpine, Fedora 컨테이너 모두 동일한 커널 버전을 보고한다. 세 "배포판"이 같은 커널 위에서 돌아가고 있다는 결정적 증거다.
왜 이게 혁명적인가: VM과의 비교
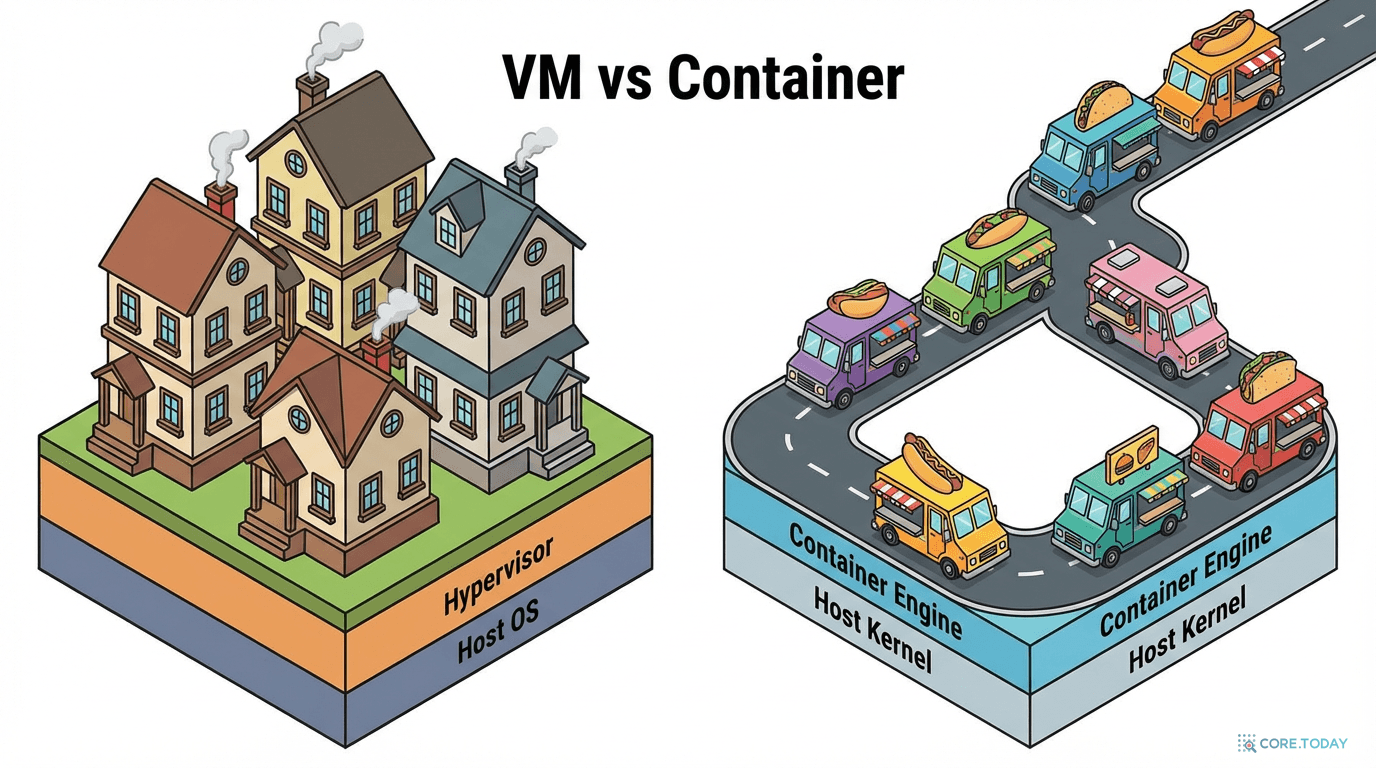
이 구조가 가상 머신(VM)과 근본적으로 다른 점을 비교해 보자.
| 항목 | VM (가상 머신) | 컨테이너 |
|---|
| 커널 | VM마다 자체 커널 보유 | 모든 컨테이너가 호스트 커널 공유 |
| 부팅 시간 | 수십 초 ~ 수 분 | 밀리초 |
| 메모리 오버헤드 | VM당 512MB~4GB | 컨테이너당 1~10MB |
| 격리 수준 | 하드웨어 수준 (하이퍼바이저) | 프로세스 수준 (namespace) |
| 성능 영향 | ~5~10% 오버헤드 | 네이티브에 가까움 |
| 디스크 사용 | GB 단위 이미지 | MB 단위 이미지 |
🏗️
비유로 이해하기
VM은 독립 주택이다. 각 집마다 자체 기초(커널), 배관, 전기 시스템을 갖추고 있다. 안전하지만 비용이 크다.
컨테이너는 공유 오피스다. 건물의 기초·배관·전기(커널)는 공유하고, 각 입주사는 자기 사무실(유저랜드)만 꾸민다. 가볍고 빠르다.
실제 용량 차이
16GB RAM 서버에서 현실적으로 운영 가능한 수:
같은 서버에서 VM은 3~5개인데, 경량 컨테이너는 100개까지 돌릴 수 있다. 커널을 공유하기 때문이다.
제4장: 격리의 역사 — chroot에서 Docker까지
컨테이너가 커널을 공유하면서도 서로 격리될 수 있는 이유는 뭘까? 그 답은 47년에 걸친 격리 기술의 발전사에 있다.
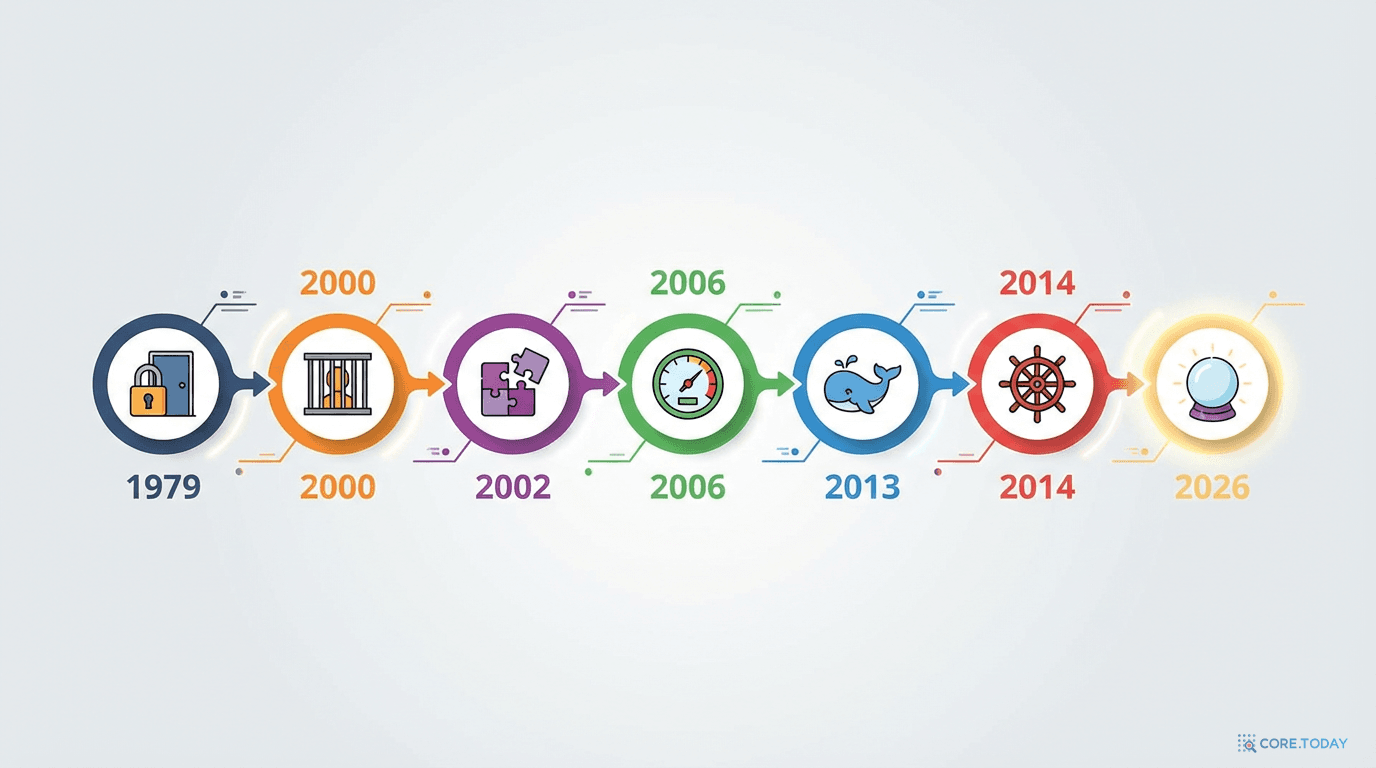
1979년: chroot — 모든 것의 시작
Unix V7 개발 중 도입된 chroot(change root) 시스템 콜. 프로세스가 보는 루트 디렉토리를 바꿔 파일 시스템을 격리했다. 원래는 보안이 아니라 빌드 환경 격리를 위해 만들어졌다 — 4.2BSD를 깨끗한 환경에서 빌드하기 위한 것이었다.
하지만 파일 시스템만 격리했을 뿐, 프로세스·네트워크·사용자는 여전히 공유됐다. root 사용자라면 chroot jail을 쉽게 탈출할 수도 있었다. 그래도 "프로세스에게 제한된 세계를 보여준다"는 아이디어 자체는 이후 모든 컨테이너 기술의 씨앗이 된다.
2000년: FreeBSD Jails — 진정한 격리의 시작
Poul-Henning Kamp와 Robert Watson이 FreeBSD 4.0에 Jails를 도입했다. USENIX 2000 논문 "Jails: Confining the omnipotent root"에서 발표된 이 기술은 파일 시스템뿐 아니라 프로세스, 네트워크, 사용자까지 격리하는 최초의 OS 수준 가상화였다. 핵심 원칙: root 권한을 가진 사용자조차 jail 밖을 볼 수 없어야 한다.
2002~2013년: Linux Namespaces — 점진적 격리 혁명
Linux 커널에 10년에 걸쳐 추가된 네임스페이스들:
| 네임스페이스 | 격리 대상 | 도입 시기 |
|---|
| Mount (mnt) | 파일 시스템 마운트 포인트 | 2002 (Linux 2.4.19) |
| UTS | 호스트네임 | 2006 (Linux 2.6.19) |
| IPC | 프로세스 간 통신 | 2006 (Linux 2.6.19) |
| PID | 프로세스 ID | 2008 (Linux 2.6.24) |
| Network | 네트워크 스택 | 2009 (Linux 2.6.29) |
| User | 사용자/그룹 ID | 2013 (Linux 3.8) |
| Cgroup | cgroup 계층 | 2016 (Linux 4.6) |
| Time | 시스템 시계 | 2020 (Linux 5.6) |
각 네임스페이스는 프로세스에게 "내가 이 시스템의 유일한 사용자"라는 환상을 준다. 이 거대한 작업을 10년 넘게 주도한 것은 커널 개발자 Eric W. Biederman이었다. Mount 네임스페이스의 CLONE_NEWNS라는 플래그 이름이 특이한 이유도 재미있다 — 처음에는 네임스페이스가 이것 하나뿐이라 "NEW NameSpace"로 지었는데, 이후에 6개가 더 추가된 것이다!
2004년: Solaris Zones — 엔터프라이즈의 답
FreeBSD Jails에 자극받아 Sun Microsystems도 Solaris 10에 Zones를 도입했다(Daniel Price, Andrew Tucker의 USENIX LISA 2004 논문). 파일 시스템·프로세스·네트워크 격리뿐 아니라 CPU cap, 메모리 제한, 공정 스케줄링까지 자원 관리를 통합한, 당시 가장 완성도 높은 컨테이너 시스템이었다. "Branded Zones"를 통해 Solaris 위에서 Linux 바이너리를 실행할 수도 있었다.
2006~2008년: cgroups — "얼마나 쓸 수 있는가"
Google의 엔지니어 Rohit Seth과 Paul Menage가 개발한 cgroups(Control Groups). 네임스페이스가 "무엇을 볼 수 있는가"를 통제한다면, cgroups는 "얼마나 쓸 수 있는가"를 통제한다. CPU, 메모리, 디스크 I/O, 네트워크 대역폭에 제한을 건다.
💡
Google 내부 사용: Google은 cgroups를 자사 데이터센터의 컨테이너 시스템인 Borg에서 이미 2004년부터 사용하고 있었다. 2015년 공개된 Borg 논문 "Large-scale cluster management at Google with Borg"은 이후 Kubernetes의 설계에 직접적인 영향을 미쳤다.
2008년: LXC — 최초의 Linux 컨테이너
namespaces + cgroups를 조합해 완전한 컨테이너 환경을 만든 LXC(Linux Containers)가 등장했다. 하지만 설정이 복잡하고, 이미지 공유가 어려웠다.
2013년: Docker — 대중화의 순간
Solomon Hykes가 PyCon 2013에서 Docker를 처음 공개했다. 5분짜리 라이트닝 토크 — "The future of Linux Containers". Hykes는 원래 dotCloud이라는 PaaS 스타트업의 CTO였다. dotCloud 내부에서 사용하던 컨테이너 도구를 오픈소스로 공개한 것이 Docker였고, 반응이 폭발적이어서 회사 자체가 Docker Inc.로 이름을 바꿀 정도였다.
Docker가 한 것은 새로운 격리 기술을 발명한 게 아니었다. 기존 기술(namespaces, cgroups, Union FS)을 누구나 쓸 수 있게 패키징한 것이었다.
1
Dockerfile — 이미지를 코드로 정의 (Infrastructure as Code)
2
Docker Hub — 이미지를 npm처럼 공유 (패키지 레지스트리)
3
docker run — 한 줄로 컨테이너 실행 (극적으로 낮아진 진입 장벽)
4
레이어 시스템 — 이미지 재사용과 증분 빌드 (효율적인 배포)
제5장: 네임스페이스의 환상 — PID 1의 착각
컨테이너가 "독립된 OS처럼 보이는" 마법의 핵심은 네임스페이스다. 가장 이해하기 쉬운 PID 네임스페이스를 살펴보자.
컨테이너 안에서 본 세계
hljs language-bash
$ ps aux
USER PID %CPU %MEM COMMAND
root 1 0.0 0.0 /bin/bash ← "나는 PID 1이다!"
root 15 0.0 0.0 ps aux
컨테이너 안에서 bash는 PID 1이다. Unix/Linux에서 PID 1은 init 프로세스 — 시스템의 최초 프로세스다. bash는 자신이 이 시스템의 "시조"라고 생각한다.
호스트에서 본 진실
hljs language-bash
$ ps aux | grep bash
root 45678 0.0 0.0 /bin/bash ← 실제로는 PID 45678
같은 프로세스가 호스트에서는 PID 45678이다. 커널이 PID 네임스페이스를 통해 숫자를 "번역"해주는 것이다.

이것은 PID에만 적용되는 게 아니다. 네트워크, 파일 시스템, 호스트네임, 사용자 ID까지 — 컨테이너의 모든 "독립성"은 네임스페이스가 만들어낸 정교한 환상이다.
PID namespace
컨테이너 안: PID 1 → 호스트: PID 45678
Network namespace
컨테이너 안: eth0 (172.17.0.2) → 호스트: veth8a3b... (브릿지)
Mount namespace
컨테이너 안: / (OverlayFS) → 호스트: /var/lib/docker/overlay2/...
제6장: 베이스 이미지 선택 가이드
베이스 이미지가 유저랜드 도구의 집합이라는 것을 이해했으니, 이제 어떤 유저랜드를 선택할 것인가의 문제가 된다.
scratch: 완전한 빈 캔버스 (0MB)
hljs language-dockerfile
FROM scratch
COPY myapp /myapp
ENTRYPOINT ["/myapp"]
문자 그대로 아무것도 없다. 셸도 없고, C 라이브러리도 없다. Go나 Rust로 정적 컴파일한 바이너리만 넣을 수 있다. 공격 표면이 0이므로 보안은 최고.
실제 사례: Google의 distroless 이미지의 기반. 2024년 기준 Docker Hub에서 가장 많이 pull되는 이미지 중 gcr.io/distroless/static이 상위권.
Alpine: 작지만 함정이 있다 (7MB)
hljs language-dockerfile
FROM alpine:3.19
RUN apk add --no-cache python3
7MB라는 놀라운 크기. 하지만 musl libc를 사용한다는 점이 핵심적인 차이다.
⚠️
glibc vs musl — 실제 사고 사례
2019년, 한 핀테크 스타트업이 Debian에서 Alpine으로 마이그레이션 후 프로덕션 장애를 겪었다. 원인: Python의 locale 모듈이 musl에서 다르게 동작하여 통화 포맷팅이 깨진 것. 금융 보고서의 숫자가 틀리게 표시됐다.
🔑
교훈
C 라이브러리의 차이(glibc vs musl)는 "같은 Linux"에서도 미묘한 호환성 문제를 일으킬 수 있다. 베이스 이미지 선택이 단순한 크기 문제가 아닌 이유.
🌐
또 다른 함정: Kubernetes DNS
musl의 DNS 리졸버는 /etc/nsswitch.conf를 지원하지 않고, UDP 크기 제한을 넘는 DNS 응답의 TCP 폴백도 과거 버전에서 미지원이었다. Kubernetes의 search domain이 길어지면 Alpine 컨테이너에서 DNS 조회가 실패하는 문제가 실제 운영 환경에서 빈번히 보고됐다. 기본 스레드 스택 크기도 glibc의 8MB 대비 musl은 128KB로, 깊은 재귀를 쓰는 앱이 segfault를 일으키기도 한다.
실전 팁: Go 서비스는 Alpine이 최적이다(Go는 기본적으로 정적 링킹). Python/Node.js/Java는 glibc 기반 이미지(Debian Slim, Distroless)가 안전하다.
Distroless: 보안 팀이 좋아하는 선택 (~20MB)
Google이 만든 distroless 이미지는 셸과 패키지 매니저를 완전히 제거했다. glibc는 포함되어 있어 대부분의 바이너리와 호환된다.
hljs language-dockerfile
FROM gcr.io/distroless/base-debian12
COPY --from=builder /app /app
ENTRYPOINT ["/app"]
장점: 공격자가 컨테이너에 침입해도 셸이 없어 추가 공격이 극히 어렵다.
단점: 셸이 없으므로 docker exec -it <container> sh로 디버깅이 불가능하다.
Debian Slim vs Ubuntu: 사실상 형제 (~78~80MB)
Ubuntu는 Debian을 기반으로 한다. 둘 다 glibc와 apt를 사용한다. 크기도 비슷하다. 차이는 주로:
- 패키지 버전: Ubuntu가 약간 더 최신
- 기본 설정: Ubuntu에 adduser 등 편의 도구가 더 있음
- 지원 주기: Ubuntu LTS는 5년, Debian Stable은 ~3년
프로덕션에서 Ubuntu vs Debian Slim 논쟁은 vi vs emacs 논쟁만큼 오래됐다. 정답은 없고, 팀의 익숙함이 가장 큰 결정 요인이다.
제7장: 이것이 왜 중요한가 — 실전 사례
"커널을 공유한다"는 사실이 이론적 지식에 그치지 않는 이유를 실전 사례로 보자.
사례 1: 커널 취약점은 모든 컨테이너에 영향
2024년 3월, CVE-2024-1086 — Linux 커널의 netfilter(nf_tables) 서브시스템에서 로컬 권한 상승 취약점이 발견됐다. 이 취약점으로 컨테이너에서 호스트로 탈출(container escape)이 가능했다.
🚨
위험
호스트에 100개의 컨테이너가 돌아가고 있다면, 커널 취약점 하나로 100개 모두가 위험해진다. VM이라면 각 VM의 커널은 독립적이므로 영향 범위가 제한된다.
✅
대응
호스트 커널 패치가 최우선이다. 컨테이너 이미지를 아무리 업데이트해도 커널 취약점은 해결되지 않는다.
사례 2: 호스트 커널이 컨테이너의 기능을 제한한다
hljs language-bash
docker run my-iouring-app
컨테이너 이미지가 최신 Ubuntu 24.04 기반이더라도, 호스트 커널이 오래됐으면 새로운 커널 기능을 사용할 수 없다. 베이스 이미지의 "배포판 버전"은 커널 버전과 무관하기 때문이다.
사례 3: 커널 ABI 호환성의 축복
반대로 좋은 소식도 있다. Linux는 안정적인 syscall ABI를 유지한다. Linus Torvalds의 유명한 원칙:
"We don't break userspace. Period. If your change breaks a user program, YOUR CHANGE IS BUGGY."
— Linus Torvalds, 2012 LKML
이것은 단순한 구호가 아니다. 2018년, open() 시스템 콜의 경로 해석 변경이 Wine(Windows 호환 레이어)을 깨뜨리자 Torvalds는 즉시 해당 커밋을 되돌렸다. Wine이 "문서화되지 않은 동작"에 의존하고 있었는데도 커널 쪽을 수정한 것이다. 사용자 프로그램이 깨지면, 커널이 잘못한 것이다.
이 원칙 덕분에 Ubuntu 18.04 컨테이너가 커널 6.8 호스트에서도 문제없이 돌아간다. 2018년에 컴파일된 바이너리의 syscall 번호와 의미가 2026년 커널에서도 동일하게 작동한다. write()는 항상 x86_64에서 syscall 번호 1이고, read()는 항상 0이다.
사례 4: OverlayFS와 Copy-on-Write의 효율성
100개의 Ubuntu 기반 컨테이너를 실행해도 Ubuntu 베이스 이미지는 디스크에 한 번만 저장된다. Docker의 레이어 시스템과 OverlayFS의 Copy-on-Write 메커니즘 덕분이다.
베이스 레이어
Ubuntu 22.04 — 78MB, 디스크에 한 번만 저장 (읽기 전용)
앱 레이어
Node.js + 의존성 — 150MB, 이것도 공유 가능
쓰기 레이어
컨테이너별 변경분만 — 보통 수 KB~MB (Copy-on-Write)
100개의 컨테이너 × 78MB가 아니라, 78MB + (100 × 수 KB)만 사용한다. 커널 페이지 캐시도 공유되므로, 동일한 파일을 읽는 100개의 컨테이너가 메모리에 한 번만 캐시한다.
💡
OverlayFS의 비밀: 컨테이너에서 파일을 삭제하면 어떻게 될까? 하위 레이어의 파일은 읽기 전용이라 실제 삭제할 수 없다. 대신 OverlayFS는 상위 레이어에 "whiteout" 파일(major/minor 번호가 0/0인 특수 장치 파일)을 생성해 해당 파일을 숨긴다. 파일은 여전히 하위 레이어에 존재하지만, 합쳐진 뷰에서는 보이지 않게 된다. Docker 이미지의 레이어 차이(diff)에서 .wh. 접두사가 붙은 파일이 바로 이것이다.
제8장: 흔한 오해 바로잡기
지금까지의 내용을 바탕으로, Docker에 대한 가장 흔한 오해들을 정리한다.
| ❌ 오해 | ✅ 진실 |
|---|
| "컨테이너는 가벼운 VM이다" | 컨테이너는 격리된 프로세스다. VM과 근본적으로 다르다 |
| "각 컨테이너마다 자체 커널이 있다" | 모든 컨테이너가 호스트의 단일 커널을 공유한다 |
| "Ubuntu 컨테이너 = Ubuntu 실행" | 호스트 커널 + Ubuntu 유저랜드 도구를 실행하는 것 |
| "베이스 이미지 = 완전한 OS" | 베이스 이미지 = 파일 시스템 스냅샷 (유저랜드만) |
| "컨테이너 100개 = 메모리 100배" | 이미지 레이어 공유 + CoW로 훨씬 적게 사용 |
| "최신 Ubuntu 이미지 = 최신 커널 기능" | 커널 기능은 호스트 커널 버전에 의해 결정됨 |
제9장: 2026년의 컨테이너 — 새로운 지평
베이스 이미지와 커널 공유라는 기본 아키텍처는 2013년 Docker 등장 이후 근본적으로 변하지 않았다. 하지만 2026년 현재, 이 아키텍처의 한계를 보완하는 기술들이 빠르게 발전하고 있다.
2015년에는 Docker, CoreOS, Google, Microsoft 등이 모여 OCI(Open Container Initiative)를 설립해 컨테이너 이미지와 런타임의 표준을 정했다. 덕분에 Docker로 만든 이미지를 Podman, containerd, CRI-O 등 어떤 OCI 호환 런타임에서도 실행할 수 있다. 베이스 이미지의 "호환성"이 특정 벤더에 묶이지 않게 된 것이다.
WebAssembly (Wasm) 컨테이너: 커널도 필요 없다?
Docker의 공동 창업자 Solomon Hykes가 2019년 트윗에서 예언했다:
"If WASM+WASI existed in 2008, we wouldn't have needed to create Docker."
2026년 현재, Wasm 컨테이너는 현실이 됐다. Docker Desktop은 WasmEdge/Spin 런타임을 통해 Wasm 워크로드를 네이티브로 지원한다.
Wasm 컨테이너의 특징:
- Linux 커널에 의존하지 않음 (Windows, macOS에서도 동일하게 실행)
- 베이스 이미지 개념 자체가 불필요
- 시작 시간: 마이크로초 단위
- 바이너리 크기: 수 KB~MB
하지만 아직 범용적이지는 않다. 파일 시스템 접근, 네트워크 소켓, 스레딩 등 시스템 기능이 WASI(WebAssembly System Interface) 표준화 진행 중이다.
Kata Containers: 컨테이너의 편의성 + VM의 격리
"커널을 공유하면 보안이 걱정된다"는 문제를 해결하기 위해, Kata Containers는 각 컨테이너(또는 Pod)를 경량 VM 안에서 실행한다. Docker/Kubernetes API는 그대로 사용하면서, 내부적으로는 microVM(Firecracker 등)이 별도의 커널을 제공한다.
AWS Fargate와 Google Cloud Run이 이 방식을 사용해 멀티테넌트 환경에서 강력한 격리를 제공한다.
eBPF: 커널의 프로그래머블화
eBPF(extended Berkeley Packet Filter)는 커널을 재컴파일하지 않고 커널 기능을 확장할 수 있는 기술이다. 2026년 현재 컨테이너 보안(Falco, Tetragon), 네트워킹(Cilium), 관측성(Pixie) 분야에서 핵심 기술로 자리잡았다.
베이스 이미지 관점에서 eBPF의 의미: 호스트 커널의 기능을 동적으로 확장할 수 있으므로, 컨테이너가 사용할 수 있는 커널 기능의 범위가 호스트 커널 버전에만 의존하지 않게 되고 있다.
Rootless Containers: 권한 최소화
Docker 엔진을 root 권한 없이 실행하는 rootless 모드가 기본화되고 있다. User namespace를 활용해 컨테이너 안의 root가 호스트에서는 일반 사용자로 매핑된다. 커널 공유의 보안 위험을 완화하는 중요한 발전.
마무리: "내가 실행하는 것이 정확히 무엇인지" 아는 것
이 글의 핵심을 한 문장으로 요약하면:
docker run ubuntu는 Ubuntu를 실행하는 게 아니라, 호스트의 Linux 커널 위에 Ubuntu의 유저랜드 도구를 얹는 것이다.
이 사실을 아는 것은 단순한 기술 상식이 아니다. 실전에서 직접적인 영향을 미친다:
- 보안: 커널 취약점은 모든 컨테이너에 영향. 호스트 커널 패치가 최우선.
- 호환성: 베이스 이미지의 배포판 버전이 아니라 호스트 커널 버전이 기능을 결정.
- 성능: 커널 공유 덕분에 컨테이너는 VM보다 훨씬 효율적.
- 디버깅: "컨테이너 안에서 안 되는 것"이 사실 호스트 커널의 제한일 수 있다.
- 이미지 선택: 베이스 이미지 = 유저랜드 선택. 크기, C 라이브러리, 패키지 매니저를 기준으로 판단.
Docker를 만든 Solomon Hykes는 기존 기술(namespaces, cgroups, Union FS)을 누구나 쓸 수 있게 패키징했다. 마찬가지로, 이 글이 "컨테이너의 진짜 구조"를 누구나 이해할 수 있게 패키징하는 역할을 했기를 바란다.
다음에 docker run을 입력할 때, 이제는 정확히 무엇이 일어나고 있는지 알게 될 것이다.
참고 자료:
- Poul-Henning Kamp, Robert Watson. "Jails: Confining the omnipotent root", USENIX, 2000
- Abhishek Verma et al. "Large-scale cluster management at Google with Borg", EuroSys, 2015
- Solomon Hykes, PyCon 2013 Lightning Talk: "The future of Linux Containers"
- Linux man pages: namespaces(7), cgroups(7), unshare(2)
- OCI (Open Container Initiative) Runtime Specification v1.2
- Docker Documentation: "About storage drivers"