100억 개의 보이지 않는 낙인, 그리고 그것을 깨뜨린 200장의 검은 이미지
2026년 3월, 한 개발자가 GitHub에 올린 저장소 하나가 AI 업계를 발칵 뒤집었습니다.
"Google이 Gemini가 생성한 모든 이미지에 보이지 않는 워터마크를 심었다. 100억 개가 넘는 콘텐츠에. 한 백수 개발자가 검은 이미지 200장과 수학만으로 그걸 풀어버렸다."
이 저장소의 이름은 reverse-SynthID. Google DeepMind가 자랑하던 AI 워터마킹 시스템 SynthID를 역설계(reverse engineering)하여, 워터마크를 탐지하고, 분석하고, 제거하는 방법을 공개한 것입니다.
이 사건은 단순한 해킹 이야기가 아닙니다. AI가 만든 콘텐츠를 어떻게 구분할 것인가, 딥페이크 시대에 진짜와 가짜를 어떻게 가려낼 것인가라는 근본적인 질문을 던집니다. EU AI Act가 2026년 8월 발효를 앞둔 지금, 이 이야기는 그 어느 때보다 중요합니다.

디지털 워터마크의 70년 역사 — 바이닐 레코드에서 AI까지
AI 워터마킹을 이해하려면, 먼저 "디지털 워터마크"라는 개념이 어디서 시작됐는지 알아야 합니다.
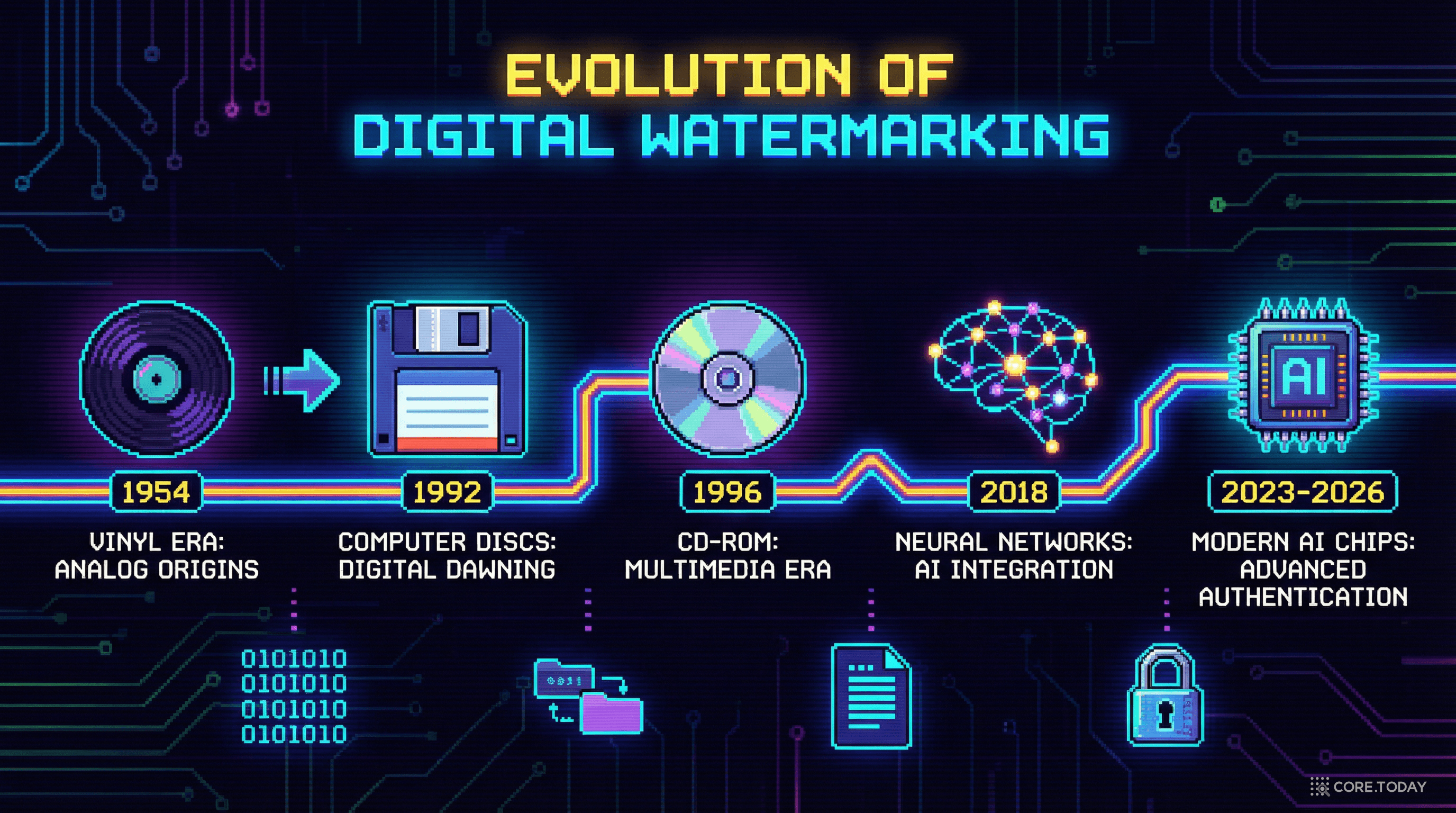
1954
최초의 오디오 워터마크
Emil Hembrooke가 바이닐 레코드에 인간이 들을 수 없는 1Hz 주파수로 모스 부호를 삽입하는 특허를 출원합니다. 저작권 분쟁에서 레코드의 원본 소유자를 증명하기 위한 것이었습니다. 이것이 디지털 워터마크의 시초입니다.
1992
"디지털 워터마크" 용어 탄생
Andrew Tirkel과 Charles Osborne이 학술 논문에서 처음으로 "digital watermark"라는 용어를 사용합니다. 이듬해, 이미지에 스펙트럼 확산(spread spectrum) 기법으로 워터마크를 삽입/추출하는 데 성공합니다.
1995
Cox의 스펙트럼 확산 워터마킹
Cox, Kilian, Leighton, Shamoon이 지각적으로 중요한 변환 영역 계수에 워터마크를 삽입하는 기법을 제안합니다. JPEG 압축과 신호 처리에도 살아남는 강인한(robust) 워터마크의 시작입니다. 이 논문은 현대 워터마킹의 초석이 됩니다.
1996
최초의 상용 워터마킹
Digimarc가 Adobe Photoshop 플러그인으로 최초의 상용 이미지 워터마킹 제품을 출시합니다. 사진작가와 미디어 회사들이 저작권 보호에 사용하기 시작합니다.
2018
딥러닝 워터마킹의 시작 — HiDDeN
Zhu 등이 ECCV에서 발표한 HiDDeN은 인코더-디코더-적대자(encoder-decoder-adversary) 구조로, 최초의 엔드투엔드 딥러닝 워터마킹 프레임워크입니다. 워터마크의 삽입과 추출을 하나의 신경망으로 학습합니다.
2020
StegaStamp — 인쇄해도 살아남는 워터마크
Tancik 등이 CVPR에서 발표한 StegaStamp는 이미지를 인쇄한 후 다시 촬영해도 워터마크가 살아남는 놀라운 강인성을 보여줍니다. BCH 오류 정정 코드를 활용한 56비트 페이로드를 구현합니다.
2023.8
Google SynthID 출시
Google DeepMind가 Imagen 이미지 생성 모델에 SynthID를 탑재하여 출시합니다. 이후 Gemini(텍스트), Lyria(오디오), Veo(비디오)로 확장되며, 2026년까지 100억 개 이상의 콘텐츠에 워터마크를 삽입합니다.
2023
Meta Stable Signature & Tree-Ring
Meta는 디퓨전 모델의 디코더를 파인튜닝하여 생성 시점에 워터마크를 삽입하는 Stable Signature를 발표합니다. 같은 해, Tree-Ring Watermarks는 초기 노이즈 벡터의 푸리에 공간에 패턴을 삽입하는 혁신적 접근을 선보입니다.
2024.10
SynthID-Text, Nature에 게재
Google DeepMind의 텍스트 워터마킹 기술이 Nature에 발표됩니다. 토너먼트 샘플링(tournament sampling)이라는 기법으로 LLM 텍스트에 감지 불가능한 워터마크를 삽입합니다. Hugging Face를 통해 오픈소스화됩니다.
2026.3
reverse-SynthID 공개
aloshdenny라는 개발자가 SynthID 이미지 워터마크를 역설계하는 코드를 GitHub에 공개합니다. 200장의 레퍼런스 이미지와 FFT 분석만으로 워터마크의 캐리어 주파수를 특정하고, 90% 정확도의 탐지기를 구축하며, 이미지 품질을 유지하면서 워터마크를 제거하는 데 성공합니다.
70년에 걸친 이 역사에서 하나의 패턴이 보입니다: 보호 기술이 등장하면, 그것을 무력화하는 기술이 반드시 뒤따른다는 것. 디지털 워터마크의 역사는 곧 "창과 방패"의 역사입니다.
SynthID란 무엇인가 — Google DeepMind의 야심작
핵심 개념: 보이지 않는 서명
SynthID의 핵심 아이디어는 단순합니다: AI가 콘텐츠를 생성하는 순간, 인간이 감지할 수 없는 디지털 서명을 콘텐츠 자체에 새긴다.
이것은 사진의 메타데이터(EXIF)에 태그를 붙이는 것과는 완전히 다릅니다. 메타데이터는 스크린샷을 찍거나 파일을 변환하면 사라지지만, SynthID 워터마크는 이미지의 픽셀 자체에 스며들어 있어서 크롭, 리사이즈, JPEG 압축, 필터 적용 후에도 살아남습니다.
비유하자면 이렇습니다:
📋
메타데이터 = 이름표
옷에 붙은 이름표처럼, 떼어내면 끝입니다. 스크린샷 한 번이면 사라집니다.
🧬
워터마크 = DNA
세포 하나하나에 새겨진 유전 정보처럼, 이미지의 모든 픽셀에 분산되어 있어 잘라내거나 압축해도 남아있습니다.
🔬
SynthID = 홀로그래픽 DNA
이미지 전체에 홀로그램처럼 분산된 신호. 일부분만 잘라내도 전체 정보를 담고 있습니다.
SynthID의 작동 방식: 모달리티별 분석
SynthID는 텍스트, 이미지, 오디오, 비디오 — 네 가지 모달리티 모두에 적용됩니다.
| 모달리티 | 삽입 방식 | 탐지 방식 | 강인성 |
|---|
| 이미지 | 이중 신경망(임베더+디텍터) 공동 학습. 픽셀값을 미세하게 수정하여 주파수 영역에 워터마크 삽입 | 디텍터 네트워크가 워터마크 신호를 읽어 상관계수 계산 | JPEG 압축, 크롭, 리사이즈, 필터, 노이즈에 강인 |
| 텍스트 | 토너먼트 샘플링: 이전 H개 토큰에서 시드 생성 → 후보 토큰 대결 → g-value 높은 토큰 선택 | 같은 키로 토너먼트 재현, 관측된 토큰이 일관되게 시드 토너먼트와 일치하면 워터마크 | 번역이나 완전한 재작성에는 약화 |
| 오디오 | 파형을 스펙트로그램으로 변환 후 스펙트럼 성분에 비가청 워터마크 삽입 | 스펙트로그램에서 워터마크 패턴 매칭 | MP3 압축, 노이즈, 속도 변경에 강인 |
| 비디오 | 각 프레임 픽셀에 개별적으로 이미지 워터마크 삽입 | 프레임별 워터마크 검출 후 종합 판단 | 손실 인코딩, 프레임 추출에 강인 |
이미지 워터마킹의 기술적 핵심
SynthID 이미지 워터마킹은 이중 신경망 아키텍처를 사용합니다:
AI 이미지 생성
→
임베더 네트워크
→
워터마크된 이미지
의심 이미지
→
디텍터 네트워크
→
상관계수 (0~1)
→
임계값 0.179와 비교
학습 과정에서 두 네트워크는 동시에 훈련됩니다:
- 임베더는 이미지 품질을 최대한 유지하면서 워터마크를 삽입하도록 학습
- 디텍터는 다양한 공격(압축, 노이즈, 크롭 등)을 거친 후에도 워터마크를 읽어내도록 학습
- 적대적 노이즈 레이어가 중간에 삽입되어 실세계 변환을 시뮬레이션
핵심은 워터마크가 주파수 영역(frequency domain)에 삽입된다는 것입니다. 이것이 무슨 뜻인지 이해하려면, 주파수 영역이 무엇인지부터 알아야 합니다.
주파수 영역 101 — 이미지의 숨겨진 세계
왜 주파수인가?
우리가 보는 이미지는 공간 영역(spatial domain)에 있습니다. 각 픽셀이 특정 위치(x, y)에 특정 밝기값을 가지는 형태죠. 그런데 같은 이미지를 완전히 다른 방식으로 표현할 수 있습니다: 바로 주파수 영역(frequency domain)입니다.

쉽게 비유하면:
- 공간 영역 = 악보의 가사 (어느 위치에 어떤 음이 있는지)
- 주파수 영역 = 악보의 조성과 화성 (어떤 주파수의 음들이 얼마나 강한지)
이미지에서:
- 저주파(Low Frequency) = 이미지의 전체적인 밝기, 배경의 점진적 변화 (파란 하늘이 서서히 밝아지는 것)
- 고주파(High Frequency) = 날카로운 가장자리, 갑작스러운 변화 (건물 윤곽선, 텍스트 가장자리)
- 중간 주파수(Mid Frequency) = 텍스처, 패턴, 세부 구조
핵심 변환: FFT, DCT, DWT
이미지를 공간 영역에서 주파수 영역으로 바꾸는 수학적 도구들이 있습니다:
| 변환 | 풀네임 | 핵심 원리 | 주요 용도 | 워터마킹 특성 |
|---|
| FFT | Fast Fourier Transform | 이미지를 사인/코사인 파의 합으로 분해 | 전체 주파수 스펙트럼 분석 | 기하학적 변환(회전, 크기조절)에 강인 |
| DCT | Discrete Cosine Transform | 8x8 블록을 코사인 파의 합으로 표현 | JPEG 압축의 핵심 | 압축에 가장 강인, JPEG 자체가 DCT 기반 |
| DWT | Discrete Wavelet Transform | 다중 해상도로 분해 (LL, LH, HL, HH 서브밴드) | 의료영상, 보안 문서 | 공간+주파수 정보 동시 보존, 가장 높은 보안성 |
워터마크는 왜 중간 주파수에 숨는가?
핵심 원리: 워터마크를 숨기기에 가장 좋은 곳은 중간 주파수 대역입니다.
- 저주파에 넣으면? → 이미지의 전체적인 톤이 바뀌어 눈에 보입니다
- 고주파에 넣으면? → JPEG 압축 시 가장 먼저 제거됩니다
- 중간 주파수에 넣으면? → 눈에 안 보이면서도 압축에 살아남습니다
이것이 Cox의 1995년 논문 이후 30년간 변하지 않는 워터마킹의 황금률입니다.
스펙트럼 확산: 워터마크의 생존 전략
SynthID의 이미지 워터마크는 스펙트럼 확산(spread spectrum) 기법을 사용합니다. 이것은 군사 통신에서 가져온 개념입니다:
- 워터마크 신호를 하나의 주파수에 집중시키지 않고, 여러 주파수 대역에 분산시킵니다
- 마치 비밀 메시지를 한 곳에 숨기는 대신 건물 곳곳에 나눠 숨기는 것과 같습니다
- 한두 개의 주파수 대역이 손상되더라도 나머지에서 복원할 수 있습니다
그리고 여기서 핵심적인 특성이 하나 있습니다: 위상 인코딩(phase encoding). SynthID는 특정 캐리어 주파수의 진폭(amplitude)뿐 아니라 위상(phase)에도 정보를 심습니다. 이 위상 패턴은 같은 모델에서 생성된 모든 이미지에서 99.5% 이상의 일관성을 보입니다.
바로 이 일관성이 역설계의 실마리가 됩니다.
역공학의 서막 — 200장의 검은 이미지로 10억의 비밀을 풀다
발견의 시작
2026년 3월, 스스로를 "백수 엔지니어"라고 소개한 개발자 aloshdenny는 기발한 아이디어를 떠올립니다:
"순수한 검은색(RGB 0,0,0) 이미지에서는 모든 픽셀값이 0이다. 그런데 Gemini로 검은 이미지를 생성하면... FFT에서 0이 아닌 값들이 나타난다. 그 0이 아닌 값들이 바로 워터마크다."

이것은 눈부시게 단순한 통찰입니다. 순수한 검은 이미지를 FFT로 변환하면, 이론적으로 모든 주파수 성분이 0이어야 합니다. 하지만 AI가 생성한 검은 이미지에는 워터마크 신호만 남아있습니다. 마치 빈 방에서 도청기를 찾는 것처럼요.
실험 과정
1단계
Gemini로 순수 검은(0,0,0)과 순수 흰(255,255,255) 이미지 각 200장 생성
2단계
각 이미지에 2D FFT(고속 푸리에 변환) 적용, RGB 채널별로 분리 분석
3단계
123,268개 이미지 쌍에서 FFT 결과의 진폭과 위상을 평균화
4단계
특정 주파수 위치(캐리어 주파수)에서 일관된 위상 패턴 발견 — 99.99% 교차 이미지 일관성
5단계
발견된 캐리어 주파수 좌표: (±14, ±14), (±126, ±14), (±98, ±14), (±128, ±128), (±210, ±14), (±238, ±14)
해상도 의존성의 발견
역설계에서 발견된 또 하나의 핵심 사실: 워터마크의 캐리어 주파수 위치는 이미지 해상도에 따라 달라집니다.
| 이미지 해상도 | 캐리어 주파수 예시 위치 | 의미 |
|---|
| 1024 x 1024 | (9, 9) | 기본 해상도의 캐리어 위치 |
| 1536 x 2816 | (768, 704) | 같은 논리적 캐리어가 완전히 다른 주파수 빈에 위치 |
이것은 중요한 발견입니다. 하나의 해상도에서 추출한 워터마크 패턴으로는 다른 해상도의 이미지에서 워터마크를 제거할 수 없습니다. 해상도별로 별도의 코드북(codebook)이 필요하다는 뜻입니다.
채널별 워터마크 강도
워터마크는 RGB 채널에 균등하게 분포하지 않습니다:
녹색 채널에 워터마크가 가장 강하게 삽입됩니다. 이것은 인간의 시각 시스템이 녹색에 가장 민감하면서도, 그만큼 많은 정보를 담을 수 있기 때문으로 추정됩니다. 워터마크 제거 시에도 녹색 채널에 더 강한 필터링이 필요합니다.
세 세대의 우회 — V1에서 V3까지의 진화
reverse-SynthID 프로젝트는 세 가지 버전의 워터마크 우회(bypass) 방법을 개발했습니다. 각 버전은 이전의 실패에서 교훈을 얻어 발전했습니다.
V1: JPEG 압축 — "가장 쉬운 방법은 통하지 않았다"
첫 번째 시도는 가장 직관적이었습니다: JPEG 압축을 걸어서 워터마크를 날려버리자.
JPEG은 원래 고주파 성분을 제거하는 손실 압축입니다. 워터마크도 주파수 영역에 있으니, 강한 압축을 걸면 함께 사라지지 않을까?
결과: 실패. SynthID의 스펙트럼 확산 설계가 JPEG 압축에 충분히 강인했습니다. Quality 50으로 압축해도 워터마크의 상관계수가 0.85로, 탐지 임계값(0.179)을 훨씬 상회했습니다.
V2: 다단계 변환 — "더 많은 공격, 그러나 부족했다"
두 번째 시도는 여러 가지 공격을 조합했습니다:
입력
→
미세 아핀 변환
±0.3° 회전, ±0.5% 스케일
→
크롭 & 리사이즈
→
원근 왜곡
노이즈 주입
→
디노이즈
→
색상 채널 교란
→
출력
결과: 탐지 신뢰도가 1.0에서 ~0.4로 떨어졌지만, 여전히 0.179 임계값을 넘겼습니다. 무차별적인 공격은 워터마크를 약화시키지만, 이미지 품질도 심하게 훼손합니다 (PSNR 34dB). 워터마크를 없애기 전에 이미지가 먼저 못쓰게 됩니다.
V3: 스펙트럼 코드북 — "외과 수술처럼 정밀하게"
세 번째이자 결정적인 접근은 패러다임 자체를 바꿨습니다. 무차별적으로 공격하는 대신, 워터마크만 정밀하게 제거하는 것입니다.
핵심은 SpectralCodebook(스펙트럼 코드북): 다수의 레퍼런스 이미지에서 추출한 워터마크 지문(fingerprint)의 모음입니다.
코드북 구축
검은/흰 이미지 200장의 FFT를 채널별로 평균화하여 각 주파수 빈의 워터마크 진폭·위상 프로파일 추출
해상도 매칭
대상 이미지의 해상도에 맞는 코드북 프로파일 자동 선택
채널별 FFT
대상 이미지를 RGB 채널별로 2D FFT 수행
외과적 제거
각 캐리어 주파수 빈에서 코드북의 진폭 패턴을 감산 (이미지 콘텐츠 에너지의 30% 상한)
위상 교란
캐리어 주파수의 위상 성분을 워터마크 방향으로 제거
역변환
역 FFT로 공간 영역으로 복원 → 워터마크 없는 이미지 출력
비유하자면, V1과 V2가 "문서에서 잉크를 지우려고 종이를 통째로 물에 담근 것"이라면, V3는 "특수 용액으로 잉크만 정확하게 녹여낸 것"입니다.
핵심 메트릭 완전 가이드 — PSNR, SSIM, 그리고 나머지
워터마크 제거의 성과를 평가하는 네 가지 핵심 지표가 있습니다. 하나씩 쉽게 풀어보겠습니다.
1. PSNR (Peak Signal-to-Noise Ratio) — "원본과 얼마나 같은가?"
PSNR은 원본 이미지와 처리된 이미지 사이의 차이를 데시벨(dB) 단위로 측정합니다.
PSNR=10⋅log10(MSEMAX2)
여기서 MAX는 최대 픽셀값(보통 255), MSE는 평균 제곱 오차입니다.
직관적으로:
V3의 43.5dB는 인간의 눈으로는 원본과 구분할 수 없는 수준입니다. 이것이 V3가 "성공적"이라고 평가받는 핵심 이유입니다: 워터마크를 제거하면서도 이미지 품질은 유지했다.
2. SSIM (Structural Similarity Index Measure) — "구조적으로 얼마나 비슷한가?"
PSNR이 픽셀 단위의 수치적 차이를 측정한다면, SSIM은 인간의 시각 체계가 실제로 인지하는 유사도를 측정합니다.
SSIM은 세 가지 요소를 종합합니다:
휘도 (Luminance)
전반적인 밝기의 유사도
대비 (Contrast)
명암 차이의 유사도
구조 (Structure)
패턴과 텍스처의 유사도
- SSIM = 1.000: 완벽히 동일
- SSIM = 0.997 (V3): 거의 완벽 — 전문가도 구분 불가
- SSIM = 0.950: 주의 깊게 보면 미세한 차이 감지
- SSIM = 0.900: 차이가 눈에 보임
PSNR보다 SSIM이 더 중요한 이유가 있습니다. PSNR은 단순히 픽셀값의 수치적 차이만 보지만, SSIM은 인간이 실제로 "달라 보인다"고 느끼는 구조적 변화를 포착합니다. 예를 들어, 이미지 전체의 밝기를 1만큼 올리면 PSNR은 크게 떨어지지만 SSIM은 거의 변하지 않습니다.
3. Carrier Energy Drop — "워터마크 신호가 얼마나 약해졌는가?"
이것은 캐리어 주파수에서의 워터마크 신호 에너지가 얼마나 감소했는지 측정합니다.
캐리어 주파수란? SynthID가 워터마크 정보를 심어놓은 특정 주파수 위치들입니다. 라디오 방송에서 특정 주파수에 신호를 실어보내는 것과 같은 원리입니다. 106.1MHz가 KBS 라디오의 캐리어 주파수인 것처럼, SynthID도 (±14, ±14), (±126, ±14) 등의 주파수 좌표를 사용합니다.
- V1: 캐리어 에너지 12% 감소 → 워터마크가 거의 손상 안 됨
- V2: 캐리어 에너지 45% 감소 → 상당히 약해졌지만 탐지 가능
- V3: 캐리어 에너지 75.8% 감소 → 워터마크 신호의 3/4이 제거됨
4. Phase Coherence Drop — "위상 패턴이 얼마나 깨졌는가?"
이것이 아마도 가장 결정적인 지표입니다. SynthID는 위상 인코딩을 사용하므로, 위상 일관성(phase coherence)의 파괴가 곧 워터마크 탐지 불가능을 의미합니다.
위상 일관성이란: SynthID가 삽입한 캐리어 주파수들의 위상 패턴이 얼마나 일관되게 유지되는지를 나타냅니다. 원본 워터마크에서는 이 값이 거의 1.0(완벽한 일관성)인데, 이 값이 떨어지면 탐지기가 워터마크를 인식하지 못합니다.
- V1: 위상 일관성 8% 감소 → 거의 영향 없음
- V2: 위상 일관성 52% 감소 → 절반 정도 교란
- V3: 위상 일관성 91.4% 감소 → 상위 5개 캐리어의 위상 패턴이 사실상 파괴됨
탐지 임계값: 0.179
SynthID 탐지기는 이미지의 노이즈와 워터마크 코드북 사이의 상관계수(correlation coefficient)를 계산합니다. 이 값이 0.179를 넘으면 "SynthID 워터마크 있음"으로 판정합니다.
V3만이 유일하게 0.179 아래로 내려가는 데 성공했습니다. 이것이 바로 V3가 "SynthID를 뚫었다"고 말할 수 있는 이유입니다.
아키텍처 심층 분석 — SpectralCodebook의 내부
SpectralCodebook: 워터마크의 DNA 지도
V3의 핵심 혁신인 SpectralCodebook의 구축 과정을 좀 더 자세히 살펴보겠습니다.
hljs language-python
class SpectralCodebook:
def build(self, reference_images: list):
profiles = {}
for resolution in unique_resolutions(reference_images):
imgs = filter_by_resolution(reference_images, resolution)
avg_magnitude = {ch: np.zeros(resolution) for ch in ['R','G','B']}
avg_phase = {ch: np.zeros(resolution) for ch in ['R','G','B']}
for img in imgs:
for ch in ['R', 'G', 'B']:
fft = np.fft.fft2(img[ch])
avg_magnitude[ch] += np.abs(fft)
avg_phase[ch] += np.angle(fft)
for ch in ['R', 'G', 'B']:
avg_magnitude[ch] /= len(imgs)
avg_phase[ch] /= len(imgs)
carriers = find_peak_frequencies(avg_magnitude)
profiles[resolution] = {
'magnitude': avg_magnitude,
'phase': avg_phase,
'carriers': carriers
}
return profiles
왜 평균화가 작동하는가? 순수 검은/흰 이미지의 FFT에서:
- 이미지 콘텐츠 신호 = 0 (검은색이니까)
- 워터마크 신호 ≠ 0 (AI가 삽입했으니까)
따라서 FFT 결과의 0이 아닌 모든 값은 순수한 워터마크 신호입니다. 200장을 평균화하면 노이즈는 상쇄되고 워터마크 패턴만 선명하게 남습니다.
워터마크 제거 파이프라인
hljs language-python
def remove_watermark(image, codebook):
resolution = image.shape[:2]
profile = codebook[resolution]
channel_weights = {'R': 0.85, 'G': 1.0, 'B': 0.70}
result = np.zeros_like(image)
for ch_idx, ch_name in enumerate(['R', 'G', 'B']):
fft = np.fft.fft2(image[:, :, ch_idx])
for carrier in profile['carriers']:
fx, fy = carrier
max_removal = 0.3 * np.abs(fft[fx, fy])
removal = min(
profile['magnitude'][ch_name][fx, fy] * channel_weights[ch_name],
max_removal
)
fft[fx, fy] -= removal * np.exp(1j * profile['phase'][ch_name][fx, fy])
result[:, :, ch_idx] = np.real(np.fft.ifft2(fft))
return np.clip(result, 0, 255).astype(np.uint8)
핵심 설계 결정 두 가지:
-
30% 에너지 상한: 캐리어 주파수의 에너지를 무한정 제거하지 않습니다. 해당 빈의 이미지 콘텐츠 에너지의 30%까지만 제거하여, 이미지 품질 저하를 최소화합니다.
-
채널별 가중치: 녹색 채널(1.0)에 가장 강하게, 청색 채널(0.70)에 가장 약하게 필터링합니다. 이는 SynthID가 채널별로 다른 강도로 워터마크를 삽입하기 때문입니다.
논쟁과 반응 — 커뮤니티는 어떻게 봤는가
HackerNews의 냉정한 평가
이 프로젝트가 HackerNews에 올라왔을 때, 커뮤니티의 반응은 흥미로웠습니다:
refulgentis (회의론):
"전후 비교 이미지가 어디에도 없다. 비가시적 수정을 핵심 주장으로 하는 프로젝트에서 이건 심각한 결함이다."
doctorpangloss (핵심 지적):
"이 도구는 자체 탐지기로 제거 성능을 테스트한다. Google의 SynthID 앱에 대해서는 테스트하지 않았다. 자기 시험을 자기가 채점하는 셈이다."
coppsilgold (흥미로운 추론):
"Google이 아마 두 종류의 워터마크를 유지할 것이다 — 온라인 오라클로 공개한 허술한 것 하나, 그리고 숨겨둔 예비 워터마크 하나."
akersten (근본적 회의):
"본질적으로 퍼지 신호에 의존하는 것이며, 사람들이 이것에 의존해서는 안 된다."
X(Twitter)에서의 바이럴
Nav Toor의 포스트가 바이럴되었습니다:
"Google이 Gemini가 생성한 모든 이미지에 보이지 않는 워터마크를 심었다. 100억 개가 넘는 콘텐츠에 마크를 남겼다. 한 백수 엔지니어가 그걸 풀어버렸다. 검은 이미지 200장과 수학으로."
중요한 비판: "자체 탐지기" 문제
HackerNews의 doctorpangloss가 짚은 점은 핵심적입니다. reverse-SynthID는 자체 구축한 탐지기로 우회 성능을 측정했습니다. Google의 실제 SynthID 탐지기가 동일한 결과를 보일지는 확인되지 않았습니다.
Google이 "이중 워터마크" 전략(공개용 + 비공개 예비)을 사용할 가능성도 있습니다. 마치 건물의 보안 카메라가 보이는 것과 숨겨진 것 두 종류가 있는 것처럼요.
그럼에도 불구하고, 이 연구가 보여준 것은 공개된 신호 처리 기법만으로도 워터마크의 구조를 파악하고 상당 부분 무력화할 수 있다는 사실입니다.
더 큰 그림 — 2026년의 AI 콘텐츠 인증 지형
현재 업계 현황
| 기업 | 접근 방식 | 상태 | 커버리지 |
|---|
| Google | SynthID (독자적) + C2PA | 가장 많이 배포 (100억+ 이미지) | Gemini, Imagen, Veo, Lyria |
| OpenAI | C2PA 메타데이터 | DALL-E, ChatGPT Images, Sora에 적용 | 메타데이터 기반 |
| Meta | Stable Signature + AudioSeal + Video Seal | 오픈소스 (Apache 2.0 / MIT) | 오픈소스 생태계 |
| Adobe | C2PA + Content Authenticity Initiative | 업계 표준화 선도 | 크리에이티브 도구 |
| Anthropic | 워터마킹 미배포, 로드맵에 포함 | R&D 단계 | — |
C2PA vs 워터마킹: 두 가지 철학
AI 콘텐츠 인증에는 크게 두 가지 접근이 존재합니다:
C2PA (메타데이터 기반)
콘텐츠에 암호화 서명된 매니페스트를 첨부합니다. 누가, 언제, 어떤 도구로 만들었는지 기록합니다. "영양성분표" 같은 것입니다.
장점: 표준화, 상세한 출처 추적, 변조 감지
단점: 스크린샷이나 파일 변환으로 쉽게 제거됨
워터마킹 (신호 기반)
콘텐츠 자체에 보이지 않는 신호를 삽입합니다. 파일 형식이 바뀌어도 살아남습니다. "DNA" 같은 것입니다.
장점: 메타데이터 제거에도 생존, 부분 크롭에도 유지
단점: 역설계 가능, 위조 가능, 생성 기업별 독자 방식
Google은 두 가지를 모두 사용합니다 — SynthID 워터마크와 C2PA 메타데이터를 동시에 적용하는 이중 방어 전략입니다.
규제의 그림자: EU AI Act
2026년 8월 시행을 앞둔 EU AI Act 제50조는 AI 생성 콘텐츠에 대해:
- 가시적 라벨: 사용자가 볼 수 있는 AI 생성 표시
- 기계 판독 가능 메타데이터: 자동화 시스템이 감지할 수 있는 출처 정보
- 비가시적 워터마크: 압축과 크롭에도 살아남는 픽셀 수준 마킹
세 가지를 모두 요구하며, 위반 시 전 세계 연간 매출의 3%까지 과징금이 부과됩니다.
하지만 현실은 냉혹합니다. 2025년 연구(arXiv:2503.18156)에 따르면:
38%
기계 판독 워터마크를 적용하는 AI 이미지 생성기
18%
가시적 표시를 제공하는 AI 이미지 생성기
97.5%
EU 외부에서 개발된 분석 대상 시스템
50개 AI 이미지 생성기 중 19개만이 워터마크를, 9개만이 가시적 라벨을 제공합니다. EU 규제의 역외 적용이 실효성을 가질지는 의문입니다.
워터마킹의 근본적 딜레마
비가시성 vs 강인성: 풀리지 않는 삼각형
디지털 워터마킹에는 세 가지 속성이 있으며, 이들은 근본적으로 충돌합니다:
비가시성 (Imperceptibility)
워터마크가 콘텐츠의 품질에 영향을 주지 않아야 한다
강인성 (Robustness)
압축, 크롭, 노이즈 등의 공격에도 살아남아야 한다
용량 (Capacity)
충분한 양의 정보를 담을 수 있어야 한다
비가시성을 높이면 → 워터마크 신호가 약해져서 → 강인성이 떨어진다
강인성을 높이면 → 워터마크 신호를 강하게 만들어야 해서 → 비가시성이 떨어진다
SynthID는 43.5dB PSNR이라는 높은 비가시성과 JPEG/크롭 등에 대한 강인성 사이에서 균형점을 찾으려 했습니다. 그러나 reverse-SynthID는 바로 그 균형점이 안전하지 않다는 것을 보여주었습니다.
더 근본적인 문제: 수학적 한계
2024년 NeurIPS에서 발표된 논문 "Invisible Watermarks are Provably Removable Using Generative AI"는 충격적인 결론을 제시합니다:
정리: 충분히 강력한 생성 AI 모델은 이론적으로 어떤 비가시적 워터마크든 제거할 수 있다. 이것은 특정 구현의 약점이 아니라, 워터마킹이라는 접근 방식 자체의 수학적 한계이다.
직관적으로 이해하면: 생성 AI가 이미지의 분포를 완벽히 학습했다면, 워터마크가 있는 이미지를 입력받아 동일한 내용이지만 워터마크가 없는 이미지를 새로 생성할 수 있습니다. 워터마크가 "비가시적"이라는 것은 원본 이미지와 워터마크 이미지의 분포가 거의 동일하다는 뜻이며, 이는 생성 모델이 워터마크 없는 버전을 복원할 수 있는 조건이 됩니다.
NSF TRAILS 연구소의 연구원은 더 직설적으로 말합니다:
"현재 신뢰할 수 있는 워터마킹은 존재하지 않는다. 우리는 전부 다 깼다. 저 교란 워터마크에 대한 희망은 없다."
그렇다면 대안은?
워터마킹이 완벽하지 않다면, 어떤 대안이 있을까요?
1층: 메타데이터
C2PA — 암호화 서명된 출처 증명. 가장 상세하지만 가장 쉽게 제거됨. "여권" 역할
2층: 워터마크
SynthID 등 — 콘텐츠 자체에 삽입된 신호. 제거 어렵지만 역설계 가능. "DNA" 역할
3층: 포렌식
AI 탐지기 — 콘텐츠의 통계적 패턴으로 AI 생성 여부 판별. 워터마크 없이도 작동. "감식반" 역할
4층: 데이터베이스
핑거프린트 DB — 생성된 모든 콘텐츠의 해시를 중앙 DB에 저장. 원본 대조 가능. "지문 데이터베이스" 역할
미래의 AI 콘텐츠 인증은 이 네 가지 층을 모두 결합하는 다층 방어(defense in depth) 전략으로 나아갈 것입니다. 하나의 층이 뚫려도 나머지가 보완하는 구조입니다.
역공학이 던지는 질문들
reverse-SynthID가 제기하는 질문은 기술적인 것만이 아닙니다.
1. 투명성 vs 보안
SynthID의 워터마크 구조가 역설계 가능했던 이유 중 하나는, 공개 API를 통해 누구나 이미지를 생성하고 분석할 수 있었기 때문입니다. 이것은 보안에 의한 모호성(security through obscurity)의 한계를 보여줍니다.
진정으로 안전한 시스템은 알고리즘이 공개되어도 깨지지 않아야 합니다 — 이것이 Kerckhoffs의 원리입니다. SynthID는 이 원리를 충족하지 못했습니다.
2. 책임 있는 공개
이 연구는 학문적 가치가 있지만, 동시에 악용될 수 있습니다. 딥페이크에서 워터마크를 제거하여 진짜처럼 유포하는 데 사용될 수 있기 때문입니다. 보안 연구의 책임 있는 공개(responsible disclosure) 원칙이 AI 워터마킹에도 적용되어야 할까요?
3. 누구의 문제인가?
AI 콘텐츠 인증이 실패하면 피해를 보는 것은 개인입니다. 선거 기간의 딥페이크, 가짜 뉴스, 사기 — 이 모든 것은 "진짜"와 "가짜"를 구분할 수 없을 때 발생합니다.
앞으로의 전망
단기 (2026~2027)
- EU AI Act 시행으로 워터마킹이 법적 의무화되지만, 기술적 실효성에 대한 논쟁은 계속될 것
- Google은 SynthID를 업데이트하여 역설계에 대한 대응책을 마련할 가능성이 높음
- 다층 방어 전략(C2PA + 워터마크 + AI 탐지 + DB)이 업계 표준으로 자리잡을 것
중기 (2027~2029)
- 국제 표준화: WIPO AIII 등을 통한 글로벌 워터마킹 표준 수립 시도
- 적응형 워터마킹: AI가 콘텐츠별로 최적화된 워터마크를 동적으로 생성하는 기술 발전
- 양자 워터마킹: 양자 컴퓨팅을 활용한 새로운 보안 프리미티브 연구
장기적 관점
AI가 만든 콘텐츠와 인간이 만든 콘텐츠의 구분은 점점 더 어려워질 것입니다. 궁극적으로 중요한 것은 기술적 워터마크가 아니라, 사회적 인프라 — 콘텐츠의 출처를 추적하고 검증하는 제도적 시스템 — 가 될 것입니다.
reverse-SynthID가 보여준 것은 결국 이것입니다: 기술만으로는 진실을 보장할 수 없다. 하지만 그렇다고 기술적 노력이 무의미한 것은 아닙니다. 완벽하지 않더라도, 워터마크는 위조의 비용을 높이고, 탐지의 확률을 올리고, 진실을 지키는 방어선 중 하나로 기능합니다.
100억 개의 워터마크가 200장의 검은 이미지 앞에 무너졌지만, 그 교훈은 다음 방어선을 더 강하게 만들 것입니다.
참고 자료
- Gowal, S. et al. (2025). "SynthID-Image: Image watermarking at internet scale." arXiv:2510.09263.
- Dathathri, S. et al. (2024). "Scalable watermarking for identifying large language model outputs." Nature, 634, 818-823.
- aloshdenny. (2026). "How to Reverse SynthID (legally)." Medium.
- Cox, I. et al. (1995). "Secure Spread Spectrum Watermarking for Multimedia." IEEE Transactions on Image Processing.
- Zhu, J. et al. (2018). "HiDDeN: Hiding Data with Deep Networks." ECCV 2018.
- Wen, Y. et al. (2023). "Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust." NeurIPS 2023.
- Fernandez, P. et al. (2023). "The Stable Signature: Rooting Watermarks in Latent Diffusion Models." ICCV 2023.
- "Invisible Watermarks are Provably Removable Using Generative AI." NeurIPS 2024.
- "Missing the Mark: An Empirical Study of AI Content Labeling Practices." arXiv:2503.18156.
- C2PA Technical Specification 2.3. https://c2pa.org/




