들어가며: 정답이 하나라는 착각
2026년, AI는 의료 영상을 판독하고, 자율주행차를 제어하고, 금융 사기를 탐지한다. 그런데 여기 불편한 질문이 하나 있다:
"AI가 올바른 답을 냈다면, 그 이유도 올바른 걸까?"
대부분의 사람은 "정답을 맞혔으면 된 거 아닌가?"라고 생각한다. 하지만 현실은 훨씬 복잡하다.
한 AI가 X-ray를 보고 "폐렴"이라 진단했다고 하자. 그런데 같은 정확도를 가진 다른 AI는 완전히 다른 특징을 보고 같은 진단을 내린다. 첫 번째 모델은 폐의 음영 패턴을, 두 번째 모델은 횡격막의 위치를, 세 번째 모델은 "정상 폐가 아님"이라는 소거법을 사용했다.
모두 정답이다. 하지만 모두 다른 이유로.
이것이 바로 라쇼몬 효과(Rashomon Effect)다. 그리고 2025년 11월, 코넬 대학교 연구진이 이 현상을 체계적으로 탐구하고 활용하는 획기적인 프레임워크를 발표했다:
"Many Ways to be Right: Rashomon Sets for Concept-Based Neural Networks"
이 글에서는 이 논문이 왜 중요한지, 어떤 문제를 해결하는지, 그리고 2026년 AI 시대에 어떤 의미를 갖는지를 깊이 파헤쳐 본다.
1. 라쇼몬: 영화에서 시작된 철학적 질문

1.1 구로사와 아키라의 걸작 (1950)
라쇼몬(羅生門)은 1950년 구로사와 아키라 감독의 영화다. 줄거리는 단순하다: 숲속에서 한 사무라이가 살해당한다. 목격자 4명이 법정에서 증언한다.
문제는 4명의 증언이 모두 다르다는 것이다.
| 증언자 | 주장 | 동기 |
|---|
| 도적 | "내가 정정당당히 싸워 이겼다" | 자신의 용맹을 과시 |
| 아내 | "실신 중에 일어난 비극" | 자신의 무고함을 증명 |
| 사무라이 (영매 통해) | "명예를 지키기 위해 자결" | 무사도의 자존심 |
| 나무꾼 | "추잡한 싸움이었다" | 유일한 목격자의 시선 |
같은 사건, 네 가지 진실. 누가 거짓말을 하는 걸까? 아니면, 모두가 자신의 관점에서 '진실'을 말하고 있는 걸까?
이 영화는 "객관적 진실이란 존재하는가"라는 철학적 질문을 던졌고, 이후 사회과학, 법학, 심리학에서 라쇼몬 효과라는 용어로 널리 쓰이게 되었다.
1.2 레오 브레이먼: "통계학의 두 문화" (2001)
2001년, 버클리 대학의 통계학자 레오 브레이먼(Leo Breiman)이 역사적인 논문 "Statistical Modeling: The Two Cultures"를 발표한다. 랜덤 포레스트의 발명자이기도 한 브레이먼은 여기서 머신러닝에 라쇼몬 셋(Rashomon Set)이라는 개념을 도입했다.
"보통 성능이 거의 같은 많은 다른 설명 모델이 존재한다. 이 모델들의 집합을 라쇼몬 셋이라 부른다."
— Leo Breiman, 2001
핵심 통찰은 이것이다: 데이터가 하나의 '최적' 모델을 결정하는 것이 아니라, 거의 같은 성능을 내는 수많은 모델이 존재한다. 우리가 훈련으로 얻는 모델은 그 중 하나에 불과하다.
🎬
영화 라쇼몬
같은 사건을 4명이 다르게 기억한다
📊
브레이먼의 라쇼몬 셋
같은 데이터를 수많은 모델이 다르게 설명한다
🧠
Rashomon CBM (2025)
같은 이미지를 신경망들이 다른 '개념'으로 이해한다
2. 왜 이것이 문제인가: "맞으면 됐지"의 위험성
2.1 의료 AI: 생사를 가르는 추론 경로
2020년, Google Health는 유방암 검진 AI를 발표하며 방사선 전문의보다 높은 정확도를 보인다고 주장했다. 하지만 후속 연구들은 충격적인 사실을 밝혀냈다:
- 일부 모델은 종양의 실제 특성 대신 스캐너의 기종이나 병원 라벨을 학습했다
- 같은 정확도를 보이는 모델들이 완전히 다른 영역에 주목하고 있었다
- 훈련 데이터의 병원이 바뀌면 성능이 급락하는 모델이 존재했다
정확도만 보면 구분할 수 없다. 모델이 왜 그 답을 냈는지 알아야 진짜로 신뢰할 수 있다.
2.2 형사 사법: 같은 점수, 다른 근거
미국에서 사용되는 재범 예측 AI COMPAS는 큰 논란을 불러일으켰다. 같은 위험 점수를 산출하더라도:
- 어떤 모델은 범죄 이력에 가중치를 둔다
- 어떤 모델은 거주 지역에 가중치를 둔다
- 어떤 모델은 나이와 고용 상태에 가중치를 둔다
피고인 입장에서 "내가 왜 고위험으로 분류되었는지"는 생사가 걸린 문제다. 모든 모델이 같은 점수를 내더라도, 어떤 근거로 그 판단을 내렸는지가 공정성의 핵심이다.
2.3 자율주행: 같은 '멈춤' 판단, 다른 이유
자율주행차가 갑자기 멈춰 선다. 이유는?
모델 A
"보행자를 감지했다"
✅ 올바른 추론
모델 B
"도로 위 그림자를 감지했다"
⚠️ 취약한 추론
모델 C
"속도가 특정 임계값을 넘었다"
❌ 잘못된 추론
세 모델 모두 "멈춤"이라는 같은 결정을 내렸고, 이번에는 결과적으로 옳았다. 하지만 모델 B와 C는 다음번에 치명적 실수를 할 수 있다. 정확도만으로는 이 차이를 발견할 수 없다.
2.4 Google의 "미명세(Underspecification)" 문제 (2020)
2020년, Google 연구진(D'Amour et al.)은 대규모 실험을 통해 이 문제를 체계적으로 증명했다. 논문 제목은 직설적이다: "Underspecification Presents Challenges for Credibility in Modern Machine Learning"
핵심 발견:
같은 훈련 데이터, 같은 아키텍처, 같은 하이퍼파라미터로 훈련해도 — 랜덤 시드만 다르면 완전히 다른 모델이 나온다. 그리고 이들은 배포 환경에서 극적으로 다르게 행동한다.
이것이 바로 라쇼몬 셋이 단순한 학술적 호기심이 아닌, 실제 AI 안전 문제인 이유다.
3. 기존 해석 방법의 한계: 왜 새로운 접근이 필요한가
AI를 이해하려는 시도는 오래되었다. 하지만 기존 방법들에는 근본적인 한계가 있다.
| 접근법 | 방식 | 한계 | 비유 |
|---|
| LIME (2016) | 입력을 조금씩 바꿔가며 출력 변화 관찰 | 국소적 설명만 가능, 전체 모델 이해 불가 | 환자 한 명의 증상만 분석 |
| SHAP (2017) | 각 특성의 기여도를 게임 이론으로 계산 | 입력→출력 관계만 설명, 내부 메커니즘은 미지 | 각 재료가 맛에 얼마나 기여했는지는 알지만, 요리법은 모름 |
| 어텐션 시각화 | 모델이 어디를 '봤는지' 히트맵 표시 | "어디를 봤는지"는 알지만 "왜 봤는지"는 모름 | CCTV로 범인 동선은 파악했지만 동기는 모름 |
| 개념 병목 모델 (CBM) | 인간이 이해 가능한 개념을 중간 표현으로 사용 | 하나의 모델만 학습 — 다른 추론 경로를 볼 수 없음 | 한 의사의 진단 과정만 볼 수 있음 |
기존 방법들의 공통 문제: 모두 하나의 모델, 하나의 설명만 제공한다. 라쇼몬 셋의 관점에서 보면, 이것은 수백 가지 가능한 추론 경로 중 딱 하나만 들여다보는 것이다.
4. 개념 병목 모델(CBM)이란 무엇인가
이 논문의 핵심인 Rashomon CBM을 이해하려면, 먼저 개념 병목 모델(Concept Bottleneck Model)이 무엇인지 알아야 한다.
4.1 기본 아이디어: "인간의 언어로 생각하는 AI"
2020년, 스탠포드의 Koh et al.이 발표한 CBM은 혁신적인 아이디어였다:
모델이 최종 예측을 내리기 전에, 반드시 '인간이 이해할 수 있는 개념'을 거치게 하자.
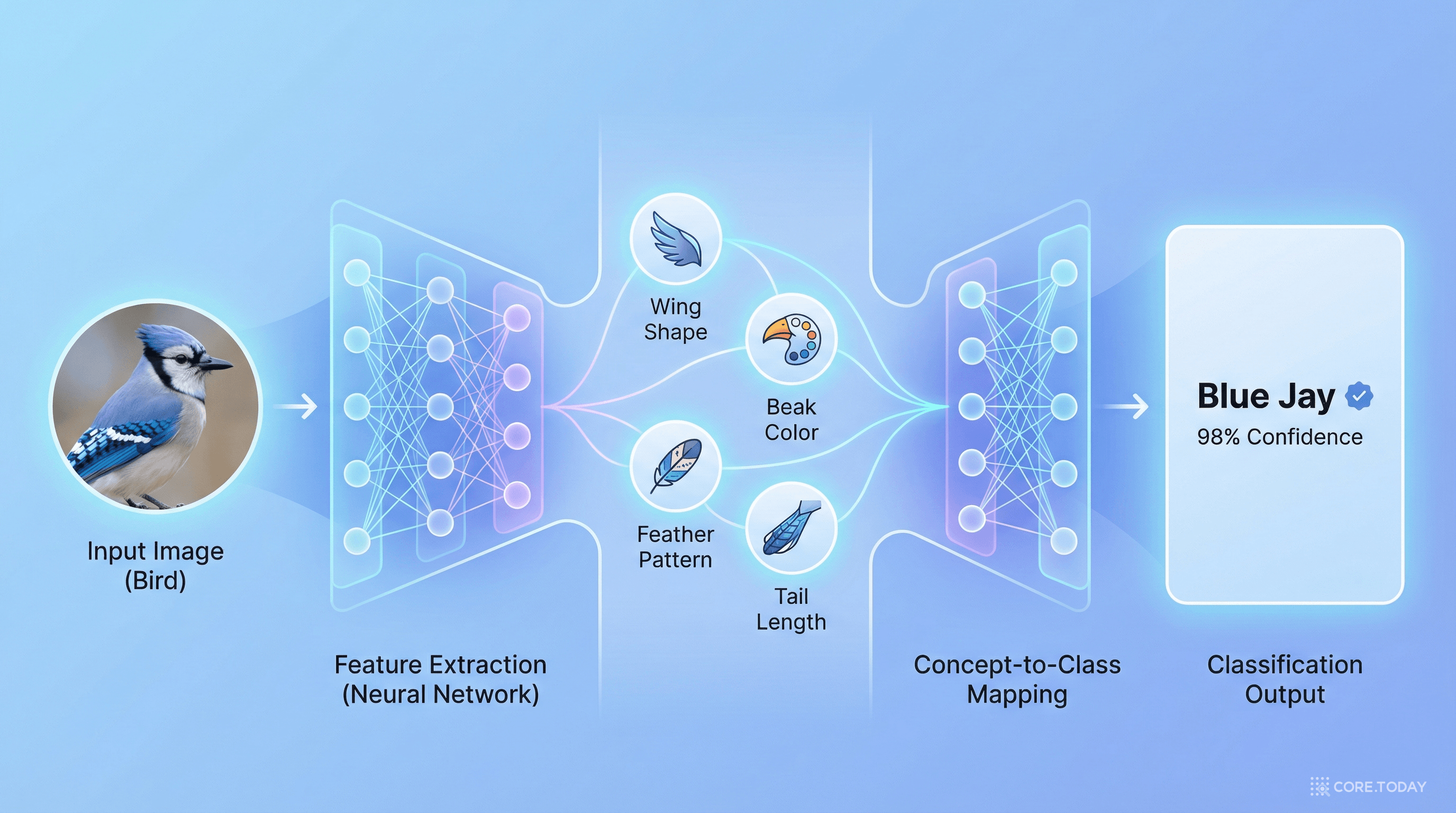
일반적인 신경망은 이미지 픽셀에서 곧바로 "이 새는 호반새(Kingfisher)다"라고 예측한다. 중간 과정은 수백만 개의 숫자로 이루어진 블랙박스다.
CBM은 다르다:
🖼️ 입력 이미지
→
🏷️ 개념 예측
"부리: 길고 뾰족함"
"날개: 파란색"
"크기: 작음"
→
🐦 분류 결과
"호반새"
중간의 "개념 병목"이 핵심이다. 모델은 먼저 인간이 이해할 수 있는 속성들(부리 모양, 날개 색상, 체형 등)을 예측하고, 이 개념들을 기반으로 최종 분류를 수행한다.
4.2 CBM의 장점
- 투명성: "왜 호반새라고 판단했는가?" → "긴 부리(0.95), 파란 날개(0.88), 작은 체구(0.72)를 근거로"
- 개입 가능성: 전문가가 개념 예측을 수정할 수 있다. "사실 이 부리는 짧다"로 수정하면 결과가 바뀐다.
- 디버깅: 어떤 개념이 잘못 예측되었는지 쉽게 확인할 수 있다.
4.3 CBM의 한계: "하나의 진실"만 보여준다
그런데 여기서 문제가 발생한다. CBM을 한 번 훈련하면 단 하나의 개념-예측 경로만 얻는다.
호반새를 분류하는 데 "긴 부리 + 파란 날개"를 사용하는 CBM을 얻었다면, "작은 체구 + 물가 서식"을 사용하는 동등하게 정확한 다른 CBM은 영원히 발견하지 못한다.
이것은 마치 라쇼몬 영화에서 도적의 증언만 듣고 판결을 내리는 것과 같다.
5. 논문의 핵심: Rashomon CBM
이제 이 논문의 주인공, Rashomon CBM을 만나보자.
5.1 핵심 아이디어: "모든 증인의 진술을 듣자"
Rashomon CBM의 목표는 명확하다:
같은 정확도를 유지하면서, 서로 다른 개념을 사용하는 여러 CBM을 동시에 학습한다.
이를 통해 연구자는 단일 모델이 아닌, 라쇼몬 슬라이스(Rashomon Slice)라 불리는 다양한 모델들의 집합을 얻는다.
❌
기존 CBM
하나의 모델, 하나의 설명 → "이 새는 부리가 길어서 호반새다"
🔄
랜덤 초기화 방식
여러 번 훈련하면 다른 모델이 나올 수도 있지만... 비용이 5~10배, 다양성 보장 없음
✅
Rashomon CBM
한 번의 훈련으로 10~25개의 다양한 모델 확보. 메모리 92% 절감, 파라미터 98.7% 절감
5.2 기술적 구조: 어떻게 가능한가?
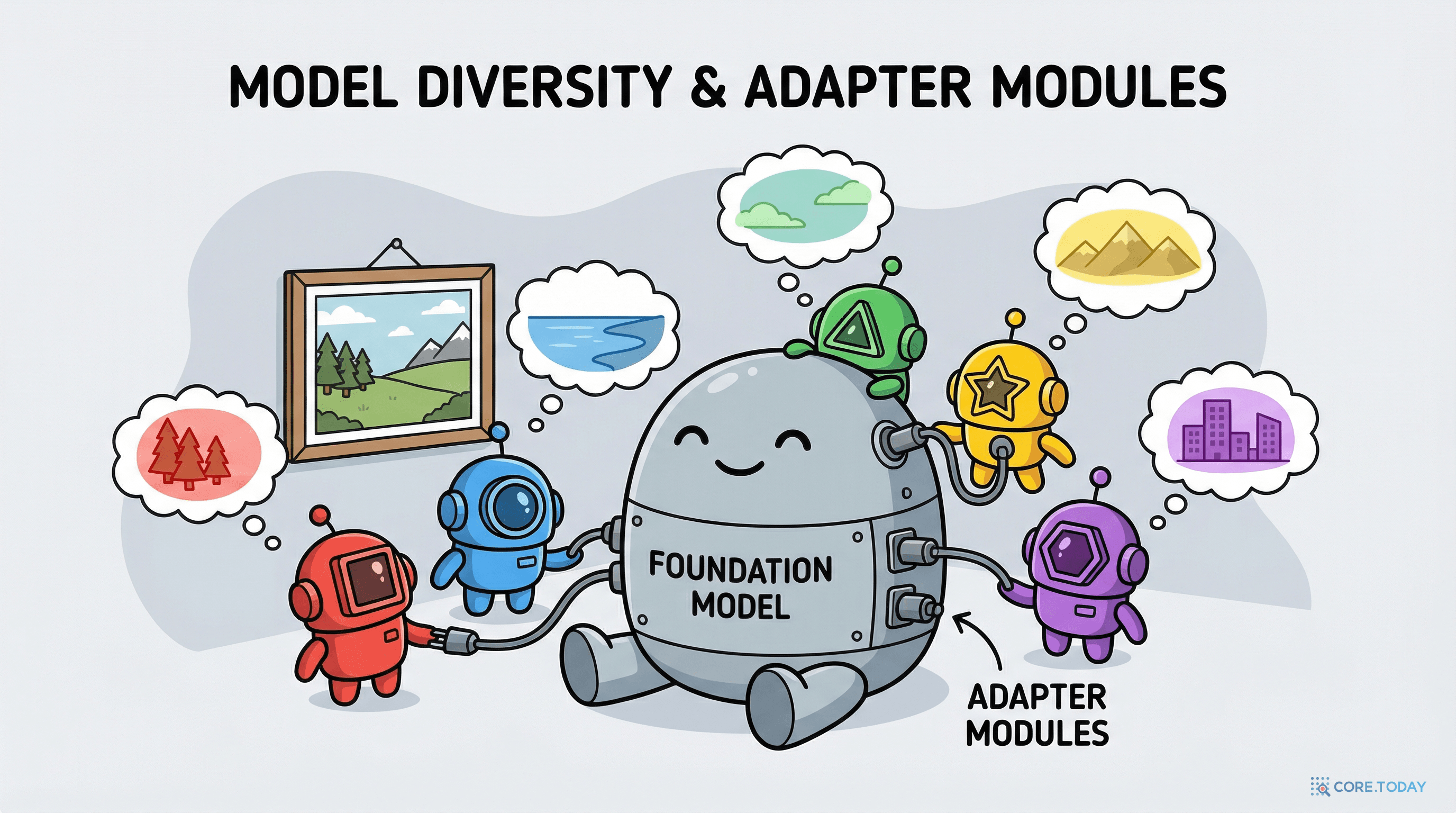
공유 백본 + 독립 어댑터
핵심 아이디어는 놀라울 정도로 우아하다:
- 사전훈련된 백본(ViT, ResNet 등)은 고정한다 — 이미 충분히 좋은 시각적 표현을 학습했으므로
- 각 모델마다 경량 어댑터(LoRA) 모듈만 독립적으로 학습한다
- 다양성 정규화 손실이 모델들을 서로 다른 방향으로 밀어낸다
수식으로 표현하면:
Ltotal=maxmLpr(m)+λ(maxmLc(m)−Mα∑mLdiv(m))
이 수식에서 중요한 것은 세 가지다:
max 연산
모든 모델 중 가장 성능이 나쁜 것을 기준으로 최적화한다. → 어떤 모델도 뒤처지지 않게 보장
개념 손실 (λ)
각 모델이 인간이 이해 가능한 개념을 정확히 예측하도록 한다. → 해석가능성 유지
다양성 손실 (α)
모델 간 개념 예측의 코사인 유사도를 낮추도록 한다. → 서로 다른 추론 경로 유도
LoRA 어댑터의 역할
각 모델 m은 ViT의 셀프 어텐션 레이어에 독립적인 LoRA 모듈을 삽입한다:
W+ΔW=W+UmVm
여기서 Um∈Rdout×r, Vm∈Rr×din이며, rank r=8로 매우 작다. 이 덕분에 10개 모델을 동시에 학습해도 추가 파라미터는 전체의 1.3%에 불과하다.
모델-축 체크포인팅
10개 모델을 동시에 학습하면 메모리 문제가 심각해진다. 논문은 모델-축 그래디언트 체크포인팅이라는 기법을 제안한다: 한 번에 하나의 모델만 활성화 메모리를 유지하고, 나머지는 필요할 때 재계산한다. 이를 통해 10개 모델의 메모리 사용량이 단일 모델 수준으로 유지된다.
6. 실험 결과: 정말 작동하는가?
6.1 호랑이를 분류하는 5가지 방법

논문에서 가장 인상적인 결과 중 하나는 호랑이 분류 사례다. AwA2 데이터셋에서 5개의 Rashomon CBM 모델이 호랑이를 분류하는 과정을 비교했다:
이 인터랙티브 탐색기에서 볼 수 있듯이, 5개 모델 모두 95% 이상의 정확도로 호랑이를 맞힌다. 하지만 사용하는 개념은 극적으로 다르다. 시각적 외형을 보는 모델, 생태학적 특성을 분석하는 모델, 소거법을 사용하는 모델 — 마치 서로 다른 전문가가 각자의 관점에서 진단하는 것과 같다.
6.2 수치로 본 다양성
📊 SHAP 유사도 (CIFAR-10, 낮을수록 다양함) — Rashomon CBM의 0.032는 Dropout CBM의 0.994와 비교해 30배 이상 다양한 추론을 의미한다.
6.3 효율성: 적은 비용으로 더 많은 통찰
| 방법 | 정확도 | SHAP 유사도 ↓ | 메모리 (GB) | 파라미터 (M) |
|---|
| Rashomon CBM | 98.0% | 0.032 | 2.88 | 2.9 |
| 랜덤 초기화 (×10) | 97.8% | 0.766 | 37.09 | 217.2 |
| Dropout CBM | 97.5% | 0.994 | 3.71 | 21.7 |
| x2c (독립 백본) | 97.6% | 0.150 | 37.09 | 217.2 |
Rashomon CBM은 메모리 92% 절감, 파라미터 98.7% 절감을 달성하면서도 가장 높은 다양성을 보인다. 이것이 가능한 이유는 사전훈련된 백본을 공유하고 경량 어댑터만 독립적으로 학습하기 때문이다.
7. 실험실에서 직접 체험하기
아래 인터랙티브 실험실에서 다양성 정규화 강도(α)를 조절하며 정확도와 다양성의 트레이드오프를 직접 탐색하고, 방법론 비교와 레이어별 분석을 확인해보자.
8. 깊은 레이어에서 일어나는 일: 다양성의 해부학
8.1 초기 레이어: "모두 같은 것을 본다"
ViT의 12개 트랜스포머 블록을 분석하면 흥미로운 패턴이 나타난다. 초기 레이어(Block 1~3)에서는 모든 모델의 어댑터가 거의 동일한 표현을 학습한다. 이는 에지 검출, 텍스처 인식 같은 저수준 시각 특징이 보편적이기 때문이다.
8.2 깊은 레이어: "여기서 갈라진다"
Block 8 이후부터 모델 간 유사도가 급격히 떨어진다. Block 12에서는 고유벡터 유사도가 18%까지 하락한다. 이것은 고수준 개념 추론이 일어나는 지점이며, 바로 여기서 "줄무늬를 볼 것인가, 발톱을 볼 것인가"의 결정이 이루어진다.
Block 1~3 (초기 레이어)
유사도 88~95% — 에지, 텍스처, 색상 등 보편적 특징
→ 모든 모델이 같은 기초를 공유
Block 4~7 (중간 레이어)
유사도 55~83% — 부분적 패턴, 형태 조합
→ 서서히 분화 시작
Block 8~12 (깊은 레이어)
유사도 18~42% — 고수준 개념, 추상적 추론
→ 각 모델이 독자적 추론 경로 형성
이 발견은 인간의 인지 과정과도 놀라운 유사성을 보인다. 우리 모두 같은 눈으로 빛을 감지하지만(저수준), 그 시각 정보를 해석하는 방식(고수준)은 사람마다 다르다. 미술가는 색채를, 건축가는 구조를, 생물학자는 생태를 '본다'.
9. 2026년, 왜 지금 이 연구가 중요한가
9.1 EU AI Act의 본격 시행
2026년, EU AI 법(AI Act)의 핵심 조항이 본격 시행되기 시작했다. 고위험 AI 시스템에 대해 다음을 요구한다:
- 투명성 의무: AI 시스템이 어떻게 결정을 내리는지 설명할 수 있어야 한다
- 감사 가능성: 독립적 감사자가 AI의 행동을 검증할 수 있어야 한다
- 편향 평가: AI가 특정 집단에 불리한 결정을 내리지 않는지 평가해야 한다
Rashomon CBM은 이 세 가지 요구를 동시에 충족하는 도구를 제공한다:
투명성
각 모델이 어떤 개념을 사용하는지 명시적으로 확인 가능
감사 가능성
10개 이상의 대안적 추론 경로를 비교하여 취약점 식별
편향 평가
특정 개념(인종, 성별 등)에 과도하게 의존하는 모델을 발견하고 배제
9.2 의료 AI 인증의 새로운 기준
FDA는 의료 AI 소프트웨어에 대해 점점 더 엄격한 해석가능성 기준을 적용하고 있다. Rashomon CBM은 의료 영역에서 특히 강력하다:
- 세컨드 오피니언의 자동화: 5개 모델이 같은 진단을 내리되 서로 다른 근거를 제시하면, 의사는 더 풍부한 정보를 바탕으로 판단할 수 있다
- 오진 탐지: 모든 모델이 같은 답을 내는데 이유가 모두 다르다면 → 높은 신뢰도. 하지만 하나의 모델만 다른 답을 낸다면 → 추가 검토 필요
- 도메인 전문가 매칭: 피부과 전문의는 시각적 특징 중심 모델을, 병리학자는 조직 구조 중심 모델을 선호할 수 있다
9.3 AI 안전과 정렬(Alignment)
AI 정렬(Alignment) 연구에서도 Rashomon CBM은 중요한 도구가 된다. AI가 "올바른 이유로 올바른 답을 내는지" 확인하려면, 하나의 모델만 검사해서는 부족하다.
라쇼몬 슬라이스를 분석하면:
- 강건한 추론: 대부분의 모델이 같은 개념을 사용한다면, 그 추론은 데이터에 깊이 뿌리박혀 있다
- 취약한 추론: 모델마다 완전히 다른 개념을 사용한다면, 그 예측은 우연에 의존할 수 있다
- 위험한 추론: 특정 모델이 편향적이거나 비윤리적 개념을 사용한다면, 해당 추론 경로를 명시적으로 차단할 수 있다
10. 라쇼몬을 넘어: 미래 방향
10.1 개념 계층 구조
현재 Rashomon CBM은 "평평한" 개념 공간을 사용한다. 미래에는 계층적 개념(예: "날카로운 발톱" → "포식자 형태" → "육식 동물")을 도입하면 더 풍부한 다양성을 탐구할 수 있다.
10.2 희소성 정규화
일부 모델은 소수의 핵심 개념만 사용하고, 일부는 많은 개념을 골고루 사용할 수 있다. 희소성 정규화를 추가하면 "단순한 설명"과 "복잡한 설명" 사이의 트레이드오프도 탐구할 수 있다.
10.3 인터랙티브 대시보드
비전문가도 라쇼몬 슬라이스를 탐색할 수 있는 인터랙티브 시각화 도구가 필요하다. 의사, 판사, 정책 입안자가 직접 모델의 추론 경로를 비교하고 선택할 수 있어야 한다.
10.4 다중 모달리티로의 확장
현재 논문은 이미지 분류에 집중하지만, 텍스트, 음성, 시계열 데이터에도 같은 원리가 적용될 수 있다. "AI가 이 텍스트를 부정적이라 판단한 10가지 다른 이유"를 보는 것도 가능해질 것이다.
11. 핵심 개념 정리
라쇼몬 효과
같은 현상에 대해 동등하게 타당한 여러 설명이 존재하는 현상
라쇼몬 셋
동일한 데이터에서 비슷한 성능을 내는 모델들의 집합
CBM
인간이 이해 가능한 개념을 중간 표현으로 사용하는 모델
LoRA 어댑터
사전훈련 모델에 소량의 파라미터만 추가하는 효율적 학습법
Rashomon CBM
공유 백본 + 독립 어댑터 + 다양성 정규화로
효율적으로 라쇼몬 슬라이스를 구성하는 프레임워크
마치며: 정답이 하나가 아닌 세계에서
구로사와 아키라의 라쇼몬은 "진실은 하나가 아니다"라는 메시지를 던졌다. 75년이 지난 2026년, AI 연구는 같은 깨달음에 도달했다.
하나의 AI 모델만 보는 것은 한쪽 눈을 감고 세상을 보는 것과 같다.
Rashomon CBM이 보여주는 미래는 이것이다:
- AI의 결정만 신뢰하는 것이 아니라, 추론 과정을 검증하는 시대
- 하나의 설명이 아닌, 여러 관점의 설명을 비교하는 시대
- AI가 "무엇을 아는가"뿐 아니라 "무엇을 모를 수 있는가"를 이해하는 시대
메모리 2.88GB, 파라미터 290만 개로 — 라쇼몬의 문을 여는 데 필요한 비용은 놀라울 정도로 작다.
중요한 것은 모든 모델에게 증언할 기회를 주는 것이다.
참고 문헌
- Feng, S., Zhang, C., Xi, M., Hsu, E., Semenova, L., & Zhong, C. (2025). Many Ways to be Right: Rashomon Sets for Concept-Based Neural Networks. arXiv:2511.19636
- Breiman, L. (2001). Statistical Modeling: The Two Cultures. Statistical Science, 16(3), 199-231.
- Koh, P. W., Nguyen, T., Tang, Y. S., Mussmann, S., Pierson, E., Kim, B., & Liang, P. (2020). Concept Bottleneck Models. ICML 2020.
- D'Amour, A., Heller, K., Moldovan, D., et al. (2020). Underspecification Presents Challenges for Credibility in Modern Machine Learning. arXiv:2011.03395
- Hu, E. J., Shen, Y., Wallis, P., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022.




