분당 510만 달러, 분당 4억 8,900만 요청. 2025년 블랙프라이데이를 받아낸 Shopify는 12년간 써오던 Redis 기반 재고 예약 시스템을 버리고 MySQL로 돌아왔다. SKIP LOCKED라는 1990년대 키워드 하나가 어떻게 21세기 이커머스의 가장 어려운 문제를 풀어냈는지, 그리고 그 뒤에 숨은 4개의 함정과 1,000개의 비밀을 해부한다.
코어닷투데이2026-05-3169분
들어가며: 분당 510만 달러의 무게
$5.1M2025 블랙프라이데이 최대 매출분당, Shopify 플랫폼
489M최대 요청 처리량분당, BFCM 2025
14.8TDB 쿼리BFCM 기간 총합
14%미국 이커머스 점유율Shopify 플랫폼 기준
2025년 11월 29일, 블랙프라이데이. 미국 동부 오후 7시 30분. Shopify 본사 토론토 사무실의 상황실 모니터에는 1분에 510만 달러가 결제되고 있었다. 한국 돈으로 약 70억 원이 60초마다 처리되는 속도다.
이 순간에 미국에서 일어나는 모든 온라인 결제의 14%가 같은 Ruby on Rails 모놀리스를 통과했다. 그 안에서 가장 무거운 책임을 진 시스템은 — 의외로 — 가격도, 결제도, 배송도 아닌 "재고 예약(Inventory Reservation)" 이었다.
"이 마지막 한 켤레의 운동화가 누구의 것인가." 동시에 결제 버튼을 누른 수천 명 중 단 한 명만 정답을 받는다. 그리고 그 정답은 0.05초 안에 나와야 한다.
이 문제는 컴퓨터가 처음 데이터베이스를 가지게 된 순간부터 존재했다. 1976년, IBM 산호세 연구소의 짐 그레이(Jim Gray)는 "Notes on Database Operating Systems" 라는 88페이지 짜리 글을 썼다. 여기서 그는 2-Phase Locking(2단계 잠금) 을 정식화한다.
핵심 아이디어:
1단계 · 잠금 획득 단계 (Growing)
트랜잭션은 필요한 자원의 잠금을 차례차례 가져온다. 한 번 가져온 잠금은 절대 놓지 않는다.
2단계 · 잠금 해제 단계 (Shrinking)
모든 작업이 끝나면, 한꺼번에 모든 잠금을 놓는다. 한 번 놓은 후에는 새 잠금을 절대 가져오지 않는다.
결과 · 직렬화 가능성
동시에 실행되어도, 마치 한 줄로 차례차례 실행된 것과 동일한 결과를 보장한다.
그레이의 통찰은 우아하지만 비싸다. 트랜잭션 A가 1번 행에 잠금을 걸면, 다른 모든 트랜잭션은 A가 끝날 때까지 기다려야 한다. 1초에 1만 명이 같은 행을 잡으러 오면, 9,999명이 줄을 선다.
이 문제는 1970년대에는 풀 가치가 없었다. 그때 데이터베이스는 한 회사의 내부 시스템이었고, 1초에 동시 접속 100명이면 호황이었다. 하지만 2025년 블랙프라이데이에는 1초에 30만 명이 같은 결제 페이지를 두드린다.
1.3 1980년대~90년대 — 두 갈래 길
이 병목을 풀기 위해 컴퓨터 과학은 두 갈래로 갈라졌다.
길 A — 낙관적 동시성 제어(Optimistic Concurrency Control, OCC). 1981년, MIT의 H.T. Kung과 John T. Robinson이 제안. "어차피 충돌은 드물다. 일단 자유롭게 하다가, 커밋 시점에 충돌을 검사하고, 충돌이 있으면 재시도." 깔끔하지만 충돌이 잦아지면 재시도 폭주(retry storm)가 일어난다.
길 B — 낙관적 잠금의 우회로(Lock Skipping). 1990년대, Oracle 8i의 내부 구현에 "이미 잠긴 행은 그냥 건너뛰자" 라는 옵션이 등장했다. SKIP LOCKED 이라는 SQL 키워드. 1996년경에 Oracle의 Advanced Queueing(AQ)을 위해 만들어졌지만, 공식 문서에는 11g(2007년)에 와서야 실린다.
이 두 번째 길이 — 30년이 지나 — Shopify의 답이 된다.
제2장: 두 가지 실패 모드 — 오버셀과 언더셀
Shopify의 글이 가장 먼저 못박는 정의가 있다. "재고 예약 시스템의 임무는 단 두 가지 실패를 막는 것이다."
오버셀 (Overselling)
언더셀 (Underselling)
창고에 1개 있는데 2명에게 판매
창고에 1개 있는데 "품절"로 표시
결과: 주문 취소, 사과 메일, 고객 지원 비용, 브랜드 신뢰도 하락
결과: 매출 손실, 고객은 경쟁사로 이동
측정 가능 — 환불 건수로 잡힘
측정 거의 불가 — "안 일어난 매출"
SNS에 박제되어 화제가 됨
조용히 사라짐
대부분의 회사는 오버셀을 더 두려워한다. 눈에 보이는 비용이고, 트위터에 박제되기 때문이다. 그래서 시스템 설계자들이 흔히 빠지는 함정이 있다 — "의심스러우면 일단 품절로 표시하자." 그러면 언더셀이 폭증하지만, 아무도 모른다.
Shopify는 둘 다 0으로 만들고 싶었다. 정확히 마지막 한 개까지 팔되, 한 개도 두 번 팔지 않기. 이것이 "매 마지막 한 켤레의 운동화는 정확히 1명의 손에 도달한다" 라는 약속이다.
💡
왜 둘 다 어려운가: 오버셀을 막으려면 동시성을 줄여야 하고(잠금 강하게), 언더셀을 막으려면 동시성을 늘려야 한다(잠금 약하게). 두 목표가 정반대 방향으로 시스템을 잡아당긴다. 이 균형점을 찾는 것이 50년 묵은 문제의 본질이다.
제3장: Shopify의 옛 시스템 — Redis와 MySQL의 위태로운 동거
3.1 12년간 잘 굴러간 두 데이터 저장소
Shopify는 2013년경부터 인벤토리 예약을 Redis에 저장해왔다. 이유는 단순하다:
이걸 해결하려면 두 시스템에 걸친 ACID 트랜잭션이 필요한데, Redis와 MySQL은 서로 다른 시스템이라 그런 보장이 없다. 이론적으로는 분산 트랜잭션(2PC) 이나 Saga 패턴을 써야 하지만, 둘 다 추가 복잡도와 지연을 가져온다.
Shopify는 이 문제를 화해 작업(reconciliation jobs) — 주기적으로 두 시스템을 비교하고 맞추는 배치 — 으로 봉합해왔다. 작동은 했지만, 매번 누가 진실의 원천(source of truth)인지 명확하지 않은 상태였다.
3.3 균열 #2 — 멀티 로케이션의 등장
옛 모델은 "아이템 1개에 가용 수량 1개" 였다. 그런데 2020년대 들어 Shopify 머천트들이 점점 여러 창고를 운영하기 시작했다. 서울 창고 5개, 부산 창고 3개, 인천 풀필먼트 센터 2개. 같은 SKU가 10곳에 흩어져 있다.
이걸 Redis 키 구조로 표현하면 키가 폭증한다. 그리고 "이 고객 주문은 가장 가까운 창고에서 빼내라" 같은 비즈니스 로직을 Redis의 단순 카운터로는 표현하기 어렵다.
3.4 균열 #3 — 운영 부담
Redis 클러스터는 별도 인프라다. 별도 모니터링, 별도 장애 대응, 별도 보안 패치. Shopify의 데이터 인프라 팀은 "MySQL 하나에 모을 수 있다면 모으자" 라는 단순화 압력을 받고 있었다.
세 균열을 모두 보면, "Redis를 빼고 MySQL로 가자" 는 결론은 거의 필연이다. 하지만 그러려면 가장 큰 질문에 답해야 한다 — "MySQL이 분당 510만 달러를 받아낼 수 있는가?"
답은 "그냥은 안 된다. 하지만 한 가지 키워드를 쓰면 된다."
제4장: 작은 키워드, 큰 변화 — SKIP LOCKED의 30년 역사
4.1 1996년: Oracle 8i의 비밀 옵션
SKIP LOCKED는 본래 데이터베이스의 비공개 무기였다. Oracle 8i가 Advanced Queueing(AQ) — Oracle 안에서 메시지 큐를 구현하는 기능 — 을 만들면서 이 키워드를 내부적으로 추가했다. 큐에서는 "이 메시지는 이미 누가 처리하고 있다 → 다음 메시지를 보자" 라는 로직이 필수다.
Oracle은 이걸 8i, 9i, 10g 시절 내내 문서화하지 않은 채 운영했다. 일부 DBA들이 EXPLAIN을 뜯어보다 발견해서 비공식적으로 썼다. 11g(2007년 발표)에 와서야 공식 문서에 등재된다.
4.2 2016년: PostgreSQL이 표준화하다
2016년 1월 7일, PostgreSQL 9.5가 발표된다. 핵심 신기능 중 하나가 SELECT ... FOR UPDATE SKIP LOCKED. 갑자기 모든 PG 사용자가 "DB로 직접 작업 큐를 만들 수 있는" 세상에 떨어졌다. Sidekiq 대신 PostgreSQL, RabbitMQ 대신 PostgreSQL.
4.3 2018년: MySQL 8.0의 추격
2018년 4월, MySQL 8.0이 GA. PostgreSQL과 같은 SKIP LOCKED 키워드가 들어온다. 이로써 세 메이저 RDB(Oracle, PostgreSQL, MySQL)가 모두 같은 무기를 갖춘다.
4.4 2023년: 37signals가 길을 보여주다
2023년 12월, Basecamp/HEY를 만드는 37signals가 Solid Queue를 오픈소스로 공개한다. "우리는 하루 1,800만 개의 백그라운드 작업 중 3분의 1을 DB 기반 큐로 돌린다. Redis는 필요 없다." — DHH가 X에 자랑한 그 시스템이다.
Solid Queue의 핵심은 UPDATE ... SKIP LOCKED 한 줄. 데이터베이스가 "이 작업은 이미 누가 가져갔으니, 다음 거 가져가세요" 라고 자연스럽게 분산해준다. Shopify의 엔지니어들이 이 글을 읽고 "이 패턴, 우리 재고 예약에도 쓸 수 있겠는데?" 라고 떠올린 순간이 — 추측이지만 — 이 마이그레이션의 출발점이다.
-- 일반 SELECT (대기): 잠긴 행이 있으면 풀릴 때까지 기다린다SELECT*FROM inventory_units WHERE item_id =42FORUPDATE;
-- SKIP LOCKED (건너뛰기): 잠긴 행은 무시하고 다음 행을 가져온다SELECT*FROM inventory_units WHERE item_id =42FORUPDATESKIP LOCKED LIMIT 1;
비유하자면 "공중화장실" 이다. 일반 SELECT는 "한 칸에 줄을 서서 기다리는 사람", SKIP LOCKED는 "문 닫힌 칸은 패스하고 다음 칸 시도하는 사람". 후자가 훨씬 빨리 자기 자리를 찾는다.
🔑
SKIP LOCKED의 본질: 정합성을 희생하지 않고 동시성을 높인다. 잠긴 행을 "없는 것처럼" 다루지만, 한 번에 한 트랜잭션만 그 행을 갖는다는 ACID 보장은 그대로다. 이게 30년 전 만들어진 키워드가 2026년 분당 510만 달러 트랜잭션을 받아내는 이유다.
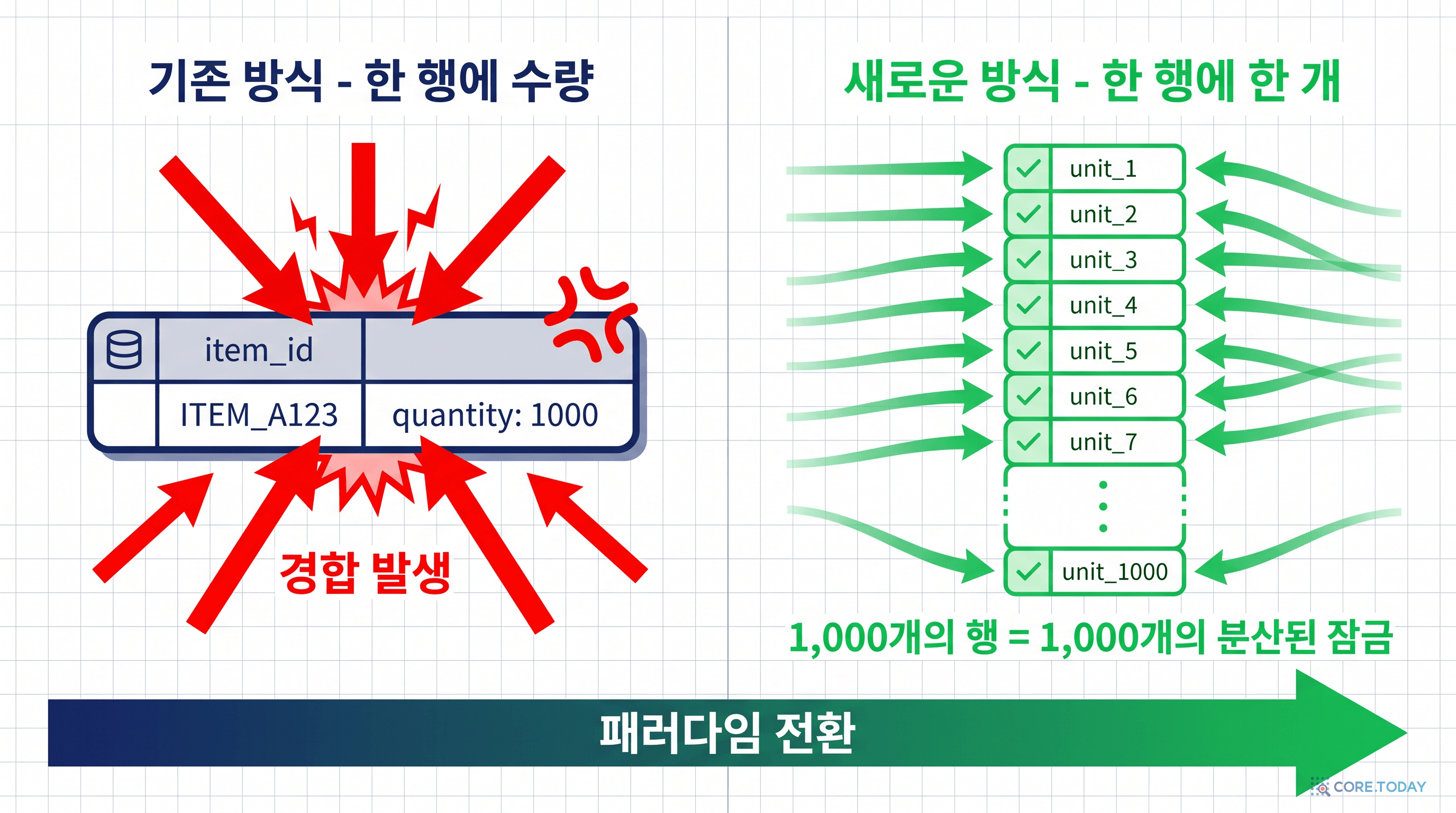
제5장: 패러다임 전환 — 한 행에 한 개
이 키워드를 쥐고도, 옛 데이터 모델 그대로 쓰면 의미가 없다. "item_id=42의 수량은 100" 이라는 한 줄짜리 행을 두면, 모든 결제가 이 한 행을 잠그러 달려든다. SKIP LOCKED가 건너뛸 다른 행이 없으니, 모두가 줄을 선다.
Shopify의 엔지니어 Emilie Noel과 동료들은 데이터 모델 자체를 뒤집었다.
5.1 옛 모델 vs 새 모델
옛 모델 — 한 행에 수량
새 모델 — 한 행에 한 개
item_id=42, qty=100
unit_id=1..100, item_id=42
아이템당 1행
아이템당 N행 (재고 수만큼)
모든 결제가 같은 행을 잠근다
결제가 서로 다른 행을 잠근다
SKIP LOCKED 무용지물
SKIP LOCKED가 빛난다
스토리지 절약
스토리지 100배
옛 모델에서는 운동화 100켤레가 데이터베이스 행 1개로 표현됐다. 새 모델에서는 100개의 행이 된다 — unit_001, unit_002, ..., unit_100.
예약 쿼리는 이렇게 바뀐다:
hljs language-sql
SELECT id
FROM inventory_units
WHERE item_id =42AND location_id =7AND reserved =falseFORUPDATESKIP LOCKED
LIMIT 1;
이 한 줄이 무엇을 하는가:
SQL 한 줄의 내부
의도
"item 42, location 7에서 예약되지 않은 unit 1개를 잠근다"
행위
MySQL 옵티마이저가 인덱스를 스캔하며 가용한 unit을 찾는다. 잠긴 unit은 패스한다.
관찰
동시에 들어온 다른 트랜잭션도 같은 일을 한다. 두 트랜잭션이 절대 같은 unit을 잠그지 않는다.
100명이 동시에 결제 버튼을 누르면, 100명이 각자 다른 unit을 잡고 나간다. 줄 서는 사람 0명, 충돌 0건, 오버셀 0건. 마지막 100번째 사람이 마지막 unit을 가져간 직후의 101번째 사람만 "재고 부족" 페이지를 본다.
이게 다음 문제다. 운동화는 100개일 수 있지만, "검은색 무지 티셔츠 M 사이즈" 같은 상품은 10만 개일 수 있다. 10만 행을 만들면 SKIP LOCKED 스캔이 느려진다. "가용한 행 1개 찾기" 위해 수만 개의 잠긴 행을 건너뛰어야 한다.
Shopify의 답은 Bounded Pool(제한된 풀) 이다.
제6장: 1,000개의 비밀 — Bounded Pool
6.1 왜 1,000인가
Shopify는 "한 (item × location) 조합당 최대 1,000개의 예약 행만 유지하자" 라는 규칙을 정했다. 운동화가 50,000켤레여도 테이블에는 1,000개의 빈 슬롯만 있다. 1,000개가 다 채워지면(=다 예약되면), 그때 다음 1,000개를 인벤토리 원장에서 가져와 채워 넣는다(Replenishment).
이 숫자가 1,000인 이유:
왜 1,000인가 — Shopify의 계산
관찰된 피크플래시 세일 시 1초에 수백~수천 건 예약
여유 마진피크 × 약 2~3배의 헤드룸
테이블 비대화 회피1,000개면 인덱스 스캔이 여전히 빠르다
1,000이라는 숫자는 마법이 아니다. "피크 시 초당 예약율 × 보충 사이의 시간 × 안전 계수" 정도로 결정된 엔지니어링 판단이다. 다른 회사라면 100일 수도, 10,000일 수도 있다.
플래시 세일 시작 후 5초 안에 1,000개 풀이 비었다고 하자. 그 순간 다음 1,000명이 동시에 예약 시도를 한다. "모두가 동시에 풀을 채우려 하면 어떻게 되나?" — 이게 분산 시스템의 고전 문제 Thundering Herd(천둥 떼)다.
Shopify의 해법은 우아하다:
1. 첫 번째 미스
풀이 비어있음을 발견한 트랜잭션이 인라인 보충(Inline Replenishment)을 시작한다. 인벤토리 원장에 잠금을 건다.
2. 후속 트랜잭션의 운명
동시에 들어온 다른 트랜잭션들은 잠금에 막혀 대기한다. 각자 풀을 채우려 경쟁하지 않는다.
3. 보충 완료
첫 트랜잭션이 1,000개를 채우고 잠금을 푼다. 대기하던 모두가 깨어나 정상 예약을 진행한다.
4. 사용자 경험
그 순간의 예약은 살짝 느릴 수 있지만 (보충 + 대기 시간), 실패하지 않는다. 진짜 재고가 0일 때만 품절 페이지를 본다.
이 패턴은 캐시 분야에서는 Singleflight(또는 Request Coalescing)으로 잘 알려져 있다. 1990년대 facebook이 memcache의 thundering herd를 막을 때 처음 정형화한 방법이고, Go의 singleflight 패키지로 표준화되었다. Shopify는 같은 패턴을 SQL로 구현한 것이다.
⚡
Singleflight in SQL: 단 한 명의 트랜잭션만 보충 작업을 한다. 나머지는 그 결과를 기다린다. 시스템 전체로 보면 보충 작업이 1번만 일어나고, 모두에게 가용 재고가 나타난다.
제7장: 4개의 숨겨진 함정
여기까지 들으면 "SKIP LOCKED + 1 row per unit + bounded pool, 끝!" 처럼 들린다. 실제로는 Shopify 엔지니어들이 수개월간 풀어낸 4개의 미묘한 함정이 있었다. 이 부분이 이 글의 진짜 기술적 알맹이다.
해결의 실마리는 "누가 연결을 잡고 있는가" 를 측정하는 새 관측 도구였다. 두 단계로 구성된다:
🔍
문제: 연결을 잡고 있는 주체가 누군지 모름
기존 메트릭은 "이 쿼리가 얼마 걸렸나"만 본다. "이 비즈니스 흐름이 연결을 얼마나 오래 잡고 있나"는 측정되지 않는다.
🏷️
해법 1: 애플리케이션 레이어 태깅
모든 SQL에 SQL 주석으로 비즈니스 프로세스 태그를 단다. /* conn_tag:checkout_completion */ SELECT ...
📊
해법 2: ProxySQL 레이어 집계
ProxySQL이 태그를 파싱하고 "비즈니스 프로세스별 연결 점유 시간"을 메트릭으로 export한다.
💡
결과: 진짜 범인이 보였다
재고 예약은 진범이 아니었다. 결제 경로의 다른 코드들이 트랜잭션을 길게 잡고 있었다. 이전에는 한계에 닿지 않아 보이지 않던 부분.
8.3 회수된 자원
태깅 결과를 분석하니 결제 경로에서 다음을 제거할 수 있었다:
결제 경로 정리 효과 (Shopify)
primary DB 읽기 제거
−50%
primary DB 트랜잭션 제거
−33%
피크 시 writer CPU
< 50%
피크 시 reader CPU
< 16%
거기에 더해, 수년 전 보수적으로 설정해두었던 InnoDB 스레드 동시성 설정을 다시 봤다. 하드웨어와 워크로드가 바뀐 지금은 더 높일 수 있는 헤드룸이 있었다. 천장이 사라졌다.
8.4 진짜 교훈
이 챕터의 핵심 — Shopify가 글에서 가장 강조한 부분 — 은 다음 문장이다:
⚠️
"재고 예약은 결제, 장바구니 업데이트, 주문 생성과 같은 DB를 공유한다. 연결을 다 쓰거나 잠금을 너무 오래 들고 있는 시스템은, 의존하는 다른 모든 시스템도 위험하게 만든다."
목표는 "재고 예약을 빠르게 만들기" 가 아니었다. "재고 예약이 다른 시스템에게 좋은 이웃이 되기" 였다. 진짜 기준은 처리량이 아니라 데이터베이스 건강을 유지하면서 그 처리량을 내는 것.
이건 분산 시스템 운영의 가장 깊은 교훈 중 하나다. "가장 빠른 시스템" 이 아니라 "공유 자원을 가장 적게 점유하는 시스템" 이 운영적으로 이긴다.
제9장: Shadow Mode — 무중단 이전 전략
분당 510만 달러를 받는 시스템의 핵심을 갈아치우는데, "오늘 밤 점검합니다" 라는 메일을 보낼 수는 없다. Shopify가 쓴 전략은 Shadow Mode(섀도우 모드) — 두 시스템을 동시에 굴리며 점진 전환.
Phase 1 · 이중 쓰기 (Dual Write)
모든 예약을 Redis와 MySQL 둘 다에 쓴다. Redis는 여전히 진실의 원천(source of truth). MySQL은 그림자.
Phase 2 · 비교 검증
프로덕션 트래픽 위에서 MySQL이 같은 비즈니스 결과를 내는지, 성능 요구사항을 충족하는지 확인.
Phase 3 · 진실의 전환
검증이 끝나면 진실의 원천을 MySQL로 바꾼다. 이때까지 진행 중인 Redis 예약은 그대로 살려둔다(새 예약이 새 시스템으로만 가도록).
Phase 4 · 점진적 롤아웃
파드별로(pod-by-pod) 전환. 작은 머천트 파드부터 시작, 가장 큰 트래픽의 머천트로 확장.
Phase 5 · 킬 스위치 보유
언제든 Redis로 즉시 복귀 가능한 토글을 유지. 결국 사용하지 않았지만, 있어야 안전하게 전진할 수 있다.
핵심 통찰: "인플라이트 예약"이 없었기에 가능한 전환이었다. 예약은 짧은 보유(short hold)다 — 결제가 성공하거나 만료되면 사라진다. 그래서 어느 시점에 "오늘부터 새 예약은 MySQL로" 라고 선언해도 기존 Redis 예약은 자연 소멸한다.
이 전략은 "진행 중인 상태가 짧은 시스템" 에서 통한다. 만약 "6개월짜리 구독 상태" 같은 걸 마이그레이션한다면 훨씬 복잡한 dual-read + 점진적 데이터 복사가 필요하다.
제10장: 2026년 — 새것이 옛것이 되는 시대
10.1 모든 회사가 따라할 흐름
Shopify의 결정은 진공에서 나오지 않았다. 2023년 37signals의 Solid Queue, 2024년 GitHub의 "우리는 Kafka 대신 MySQL 쓴다" 공개, 2025년 Stripe의 "PG 트랜잭션으로 결제 큐 운영" 사례가 쌓이고 있다. 업계가 한 방향으로 정렬되는 중이다:
2010s
"Specialized Polyglot Persistence" 시대
큐는 Redis, 검색은 Elasticsearch, 캐시는 Memcached, RDB는 OLTP만. 각 워크로드에 특화된 저장소를 따로 운영.
PG 14, MySQL 8.0이 SKIP LOCKED + 파티셔닝 + 컬럼 압축 같은 기능을 제공. "RDB가 모든 걸 다 할 수 있다"는 자신감.
2023~26
"Modular Monolith + Single DB" 르네상스
37signals Solid 시리즈, Shopify의 회귀, DHH의 "Once" 운동. 운영 단순성이 다시 미덕이 되는 시대.
10.2 AI 시대의 함의
2026년의 관점에서 이 사례는 한 가지를 더 말해준다. AI 에이전트들이 빠르게 코드를 생성하는 시대, 시스템 복잡도 자체가 비용이 된다. "내가 만든 시스템을 6개월 후의 내가, 또는 AI 에이전트가, 이해할 수 있는가" 라는 질문이 중요해졌다.
Shopify의 새 시스템에는 다음이 없다:
별도 Redis 클러스터 → 모니터링 1개 줄어듦
분산 트랜잭션 화해 작업 → 배치 잡 1개 줄어듦
"두 시스템 사이의 일관성" 문제 → 멘탈 모델 1개 줄어듦
대신 1개의 MySQL과 그 안의 명확한 ACID 트랜잭션이 있다. "마지막 신발이 누구의 것인가" 가 단 하나의 시스템에서, 단 하나의 트랜잭션 안에서 결정된다.
이게 AI 코딩 에이전트가 가장 잘 이해할 수 있는 시스템이기도 하다. 메모리 모델이 단순하고, 장애 시나리오가 폐쇄적이고, 새 기능 추가가 "테이블 컬럼 추가 + 새 인덱스" 만큼 단순하다.
🤖
2026년의 아이러니: AI가 코드를 점점 더 많이 짤수록, 사람과 AI 모두 다루기 쉬운 단순한 시스템의 가치가 올라간다. Shopify의 사례는 "가장 단순한 답이 가장 빠른 답이기도 하다"는 옛 격언의 부활이다.
10.3 한국 시장의 의미
한국 이커머스도 같은 문제를 가지고 있다. 무신사, 쿠팡, 네이버 스마트스토어 모두 "한정판 드롭", "라이브 커머스 카운트다운", "신상품 출시 동시 결제" 같은 시나리오를 다룬다. 신발 드롭 한 번에 분당 수십만 트랜잭션이 몰린다.
대부분의 한국 이커머스 시스템은 여전히 "Redis 카운터 + 비동기 MySQL 반영" 패턴을 쓴다. Shopify의 사례는 "하나의 RDB로 충분하다" 라는 새로운 답을 제시한다. 운영 복잡도가 낮아지고, 일관성 문제가 사라지고, "마지막 1켤레가 누구의 것인가" 가 명확해진다.
특히 한국처럼 모바일 트래픽이 폭발적인 환경에서 — "앱과 웹과 카카오 알림이 동시에 한 상품을 노리는" 시나리오에서 — 단일 RDB의 ACID 보장은 강력한 답이다.
제11장: 시스템 아키텍처 깊게 보기
11.1 전체 흐름도
세 가지 컴포넌트와 그들의 관계:
Shopify Inventory Reservation — New Architecture
Checkout Service예약 요청 발신
Reservation ServiceRuby on RailsSKIP LOCKED + UNION ALL
기억해야 할 것: 새 시스템에서 읽기는 일반 격리 수준, 재고 예약 트랜잭션만 READ COMMITTED. 트랜잭션마다 격리 수준을 바꾸는 패턴은 Rails 같은 프레임워크에서는 일반적이지 않아서, 프레임워크 코드를 수정해야 했다.
이건 "우리 시스템은 한 격리 수준만 쓴다" 라는 일반적인 가정에 도전하는 사례다. 마이크로서비스 시대에 우리가 잊고 있던 "트랜잭션 격리는 워크로드별로 다르게 설정할 수 있다" 는 30년 전 RDB의 본래 능력이다.
제12장: 세 가지 교훈
Shopify의 글이 마지막에 정리한 세 교훈을 풀어 본다.
교훈 1 — 옛 결정을 다시 보라
📜
"5년 전 불가능했던 것이 오늘은 가능할 수 있다." MySQL의 SKIP LOCKED는 8.0(2018)에 와서야 들어왔다. 그 이전에는 Redis가 답이었다. 워크로드와 하드웨어가 바뀌었다면 — 그리고 데이터베이스가 새 기능을 추가했다면 — 옛 "룰 오브 썸" 을 다시 점검하라.
특히 "InnoDB 스레드 동시성 한도" 같은 설정은 한 번 정해두면 잊혀지기 쉽다. Shopify는 수년 묵은 보수적 설정을 다시 보고 헤드룸을 발견했다. 옛 설정값에는 옛 가정이 박혀있다.
교훈 2 — 작게 시작하고 관찰하라
🔬
"작은 Ruby 스크립트 + 작은 MySQL이 큰 시스템보다 많이 가르쳐준다." Shopify 팀은 Rails 전체를 쓰지 않고 미니멀한 프로토타입으로 시작했다. MySQL의 잠금 상태를 터미널로 관찰하며 데드락을 재현하고, 격리 수준의 효과를 직접 본 것이 이론적 추론보다 빠르고 정확했다.
이건 "REPL/플레이그라운드 우선" 의 가치다. 대규모 시스템의 미스터리는 자주 미니 재현으로 풀린다. 거대한 모놀리스 안에서 디버깅하는 것보다, 같은 핵심을 가진 50줄짜리 스크립트로 본질을 확인하는 게 빠르다.
교훈 3 — 진짜 적은 "공유 자원"의 건강
🤝
"내 시스템을 빠르게 만들기"보다 "다른 시스템에 좋은 이웃이 되기". 재고 예약이 결제, 카트, 주문 생성과 같은 DB를 공유하는 한, 예약이 연결을 다 잡거나 잠금을 길게 들면 모두가 고통받는다. 진짜 기준은 "내 처리량"이 아니라 "공유 DB의 건강을 유지하면서 내 처리량".
이건 분산 시스템 운영의 가장 깊은 미학이다. 대부분의 마이크로서비스 마이그레이션이 "이 시스템을 떼어내서 빠르게 만들겠다" 라고 시작하지만, 실제 문제는 "공유 자원의 건강" 인 경우가 많다. Shopify는 모놀리스 안에서 — 같은 DB 안에서 — 좋은 이웃이 되는 길을 택했다.
닫으며: 1976년의 짐 그레이가 오늘 보면
이 글의 첫 챕터에서 1976년 짐 그레이의 2단계 잠금 논문을 언급했다. 만약 그가 오늘 Shopify의 시스템을 본다면, 아마 이렇게 말하지 않을까:
"내가 풀려고 했던 문제가 50년 동안 살아남았네. 그리고 우리가 만든 도구들 — 잠금, 격리 수준, ACID, MVCC — 이 여전히 답이라는 사실이 더 놀랍다. 변한 것은 데이터의 양과 트래픽 패턴뿐이지, 근본 문제는 똑같다. 한 자원, 여러 요청, 정확히 한 번."
Shopify의 사례는 "새로운 분산 시스템 패러다임" 이 아니다. "1970년대에 발견한 도구로 2026년 문제를 푸는 우아한 방법" 이다. SKIP LOCKED는 30년 전 키워드, ACID는 50년 전 개념, 모놀리스는 60년 전 아키텍처다.
그 모든 옛것들이 — NVMe SSD와 100Gbps 네트워크와 1TB RAM과 결합되어 — 다시 가장 빠른 답이 되는 시대. 이게 2026년의 작은 아이러니이자, 큰 안도감이다.
"마지막 신발이 누구의 것인가" 라는 질문에 답하기 위해, 우리는 결국 가장 단순한 답으로 돌아왔다. "하나의 데이터베이스 안에서, 하나의 트랜잭션으로, 정확히 한 번."