블로그로 돌아가기
양자화QuantizationGPTQAWQGGUFINT4LLM 최적화
양자화(Quantization) 완전 해부: 70B 모델을 내 노트북에서 돌리는 마법의 원리
280GB짜리 AI 모델을 35GB로 줄이면서 성능은 97%를 유지한다. 어떻게? FP32에서 INT4까지, BinaryConnect에서 BitNet까지 — 양자화의 역사, 원리, 실전 기법, 그리고 안전성 문제까지 총정리.
코어닷투데이2025-10-2024분
280GB짜리 AI 모델을 35GB로 줄이면서 성능은 97%를 유지한다. 어떻게? FP32에서 INT4까지, BinaryConnect에서 BitNet까지 — 양자화의 역사, 원리, 실전 기법, 그리고 안전성 문제까지 총정리.
Llama 2 70B 모델의 원본 크기: 약 280GB (FP32). 이것을 실행하려면 수백만 원짜리 GPU 여러 장이 필요하다.
같은 모델을 INT4로 양자화하면: 약 35GB. RTX 4090(24GB) 하나에 부분적으로 올릴 수 있다. 성능 저하는 1~3%.
이것이 양자화(Quantization)의 마법이다 — 모델의 숫자 정밀도를 낮춰 크기를 줄이면서, 실용적 성능은 거의 유지하는 기법.
2025년 현재, 양자화 없이는 AI를 실용적으로 사용할 수 없다. ChatGPT부터 스마트폰 AI까지, 모든 곳에 양자화가 적용되어 있다.

디지털 카메라로 사진을 찍으면 RAW 파일은 수십 MB다. 이것을 JPEG로 변환하면 수 MB로 줄어든다. 색상 정보의 정밀도를 약간 낮추지만, 눈으로 보기에는 거의 차이가 없다.

양자화도 같다. AI 모델의 가중치(weight)는 기본적으로 32비트 부동소수점(FP32)으로 저장된다. 이것을 8비트 정수(INT8) 또는 4비트 정수(INT4)로 변환하면:
양자화의 핵심 공식은 단순하다:
대칭 양자화 (AbsMax):
스케일: s = max(|x|) / (2^(b-1) - 1)
양자화: x_q = round(x / s)
역양자화: x̂ = x_q × s
예: 가중치 값 0.73을 INT8(-127~127)로 양자화하면:
이 정도 오차는 신경망의 성능에 거의 영향을 주지 않는다.
Rastegari 등이 발표한 XNOR-Net은 급진적이었다. 가중치와 활성화를 모두 {-1, +1}로 이진화하면, 행렬 곱셈을 XNOR 비트 연산으로 대체할 수 있다.
결과: 합성곱 연산 58배 가속, 메모리 32배 절감. 하지만 정확도가 크게 떨어졌고, 실용적이기보다는 "이것이 가능하다"를 증명한 논문이었다.
Tim Dettmers 등이 NeurIPS 2022에서 발표한 LLM.int8()은 LLM 양자화의 전환점이었다.
핵심 발견: 67억 파라미터 이상의 대형 모델에서, 특정 은닉 차원의 활성화 값이 나머지보다 ~100배 큰 "아웃라이어(이상치)"가 나타난다. 전체 값의 0.1%에 불과하지만, 이 아웃라이어를 무시하면:
해법: 혼합 정밀도 분해 — 99.9%의 값은 INT8로, 아웃라이어(크기 ≥ 6)는 FP16으로 처리. 이것이 bitsandbytes 라이브러리의 기원이다.
Frantar 등의 GPTQ는 LLM을 최초로 4비트로 압축하면서도 성능을 유지한 기법이다. 역 헤시안 정보를 사용해, 한 가중치의 양자화 오차를 나머지 가중치에 재분배한다. 이것이 오늘날 HuggingFace에서 가장 많이 보는 양자화 모델의 기반이다.
모델을 완전히 학습한 후에 양자화를 적용한다. 재학습 불필요.
| 비교 항목 | PTQ | QAT |
|---|---|---|
| 재학습 필요? | 아니오 | 예 (전체 학습 주기) |
| 컴퓨트 비용 | 낮음 | 높음 |
| 정확도 (8비트) | 우수 | 우수 |
| 정확도 (4비트 이하) | 떨어짐 | 우수 |
| 최적 용도 | 빠른 배포, 큰 모델 | 극한 압축, 안전 중요 모델 |
2025년 표준: 대부분의 실무에서 PTQ(GPTQ/AWQ)로 충분하다. QAT는 4비트 이하 극한 압축이나 안전성이 중요한 경우에 사용한다.

| 기법 | 연도 | 비트 | 캘리브레이션 | 학습? | 최적 용도 |
|---|---|---|---|---|---|
| GPTQ | 2022 | 4비트 | 필요 | 아니오 | GPU 추론 (HuggingFace 생태계) |
| AWQ | 2023 | 4비트 | 최소 | 아니오 | 빠른 GPU 추론 (vLLM, 최고 속도) |
| SmoothQuant | 2023 | 8비트 (W+A) | 필요 | 아니오 | 가중치+활성화 동시 양자화 |
| bitsandbytes | 2022-23 | 4/8비트 | 불필요 | 예 (QLoRA) | 파인튜닝 |
| GGUF | 2023+ | 2~8비트 | 불필요 | 아니오 | CPU/로컬 추론 (Ollama) |
Lin 등의 AWQ는 핵심 통찰이 명쾌하다: 모든 가중치가 동등하게 중요한 것이 아니다. 활성화(activation) 크기를 관찰하면, 전체의 약 1%만이 "중요한(salient)" 채널이다.
이 1%를 보호하면 나머지 99%를 공격적으로 양자화해도 성능이 유지된다. Marlin 커널과 결합하면 A100에서 741 tok/s — 현존 최고 속도.
GGUF는 양자화 알고리즘이 아니라 파일 포맷이다. llama.cpp와 Ollama가 사용한다.
| 레벨 | 비트/가중치 | 크기 (7B 기준) | 품질 | 추천 |
|---|---|---|---|---|
| Q8_0 | 7.17 | ~7.2 GB | FP16과 거의 동일 | 메모리 여유 시 |
| Q6_K | 6.57 | ~5.5 GB | 매우 좋음 | 고품질 필요 |
| Q4_K_M | 4.83 | ~3.8 GB | 좋음 (92% 유지) | 대부분의 사용자 추천 |
| Q4_K_S | 4.57 | ~3.6 GB | 좋음 | 메모리 제한 시 |
| IQ3_S | 3.52 | ~2.8 GB | 보통 | 극한 압축 |
| IQ2_XS | 2.43 | ~2.1 GB | 낮음 | 실험용 |
황금 규칙: GPU에 완전히 올릴 수 있는 가장 큰 양자화 레벨을 선택하라. Q4_K_S가 여유 있게 들어가면, 더 작은 모델 대신 더 큰 모델의 Q4_K_M을 선택하는 것이 낫다.
| 형식 | 비트 | 용도 | 특징 |
|---|---|---|---|
| FP32 | 32 | 연구, 기준선 | 최고 정밀도. 실무에서는 거의 사용 안 함 |
| BF16 | 16 | 학습의 표준 | FP32와 같은 범위, 낮은 정밀도. 2024~ 학습 기본값 |
| FP8 | 8 | H100+ 프로덕션 추론 | E4M3(정밀도↑)/E5M2(범위↑) 두 변형. 2024~ GPU 표준 |
| INT8 | 8 | 프로덕션 추론 | 정수 연산. 가장 오래된 프로덕션 양자화 |
| NF4 | 4 | QLoRA 파인튜닝 | 정규 분포에 최적화된 비균일 양자화. bitsandbytes 전용 |
| INT4 | 4 | 로컬 추론의 핵심 | GPTQ, AWQ, GGUF에서 사용. 8배 절감, 1~3% 성능 저하 |
| MXFP4 | 4 | 차세대 하드웨어 | OCP 표준. 32개 원소가 스케일 공유. AMD/NVIDIA 지원 |
| 1.58비트 | 1.58 | 연구/실험 | {-1, 0, +1} 삼진법. 곱셈→덧셈. BitNet b1.58 |
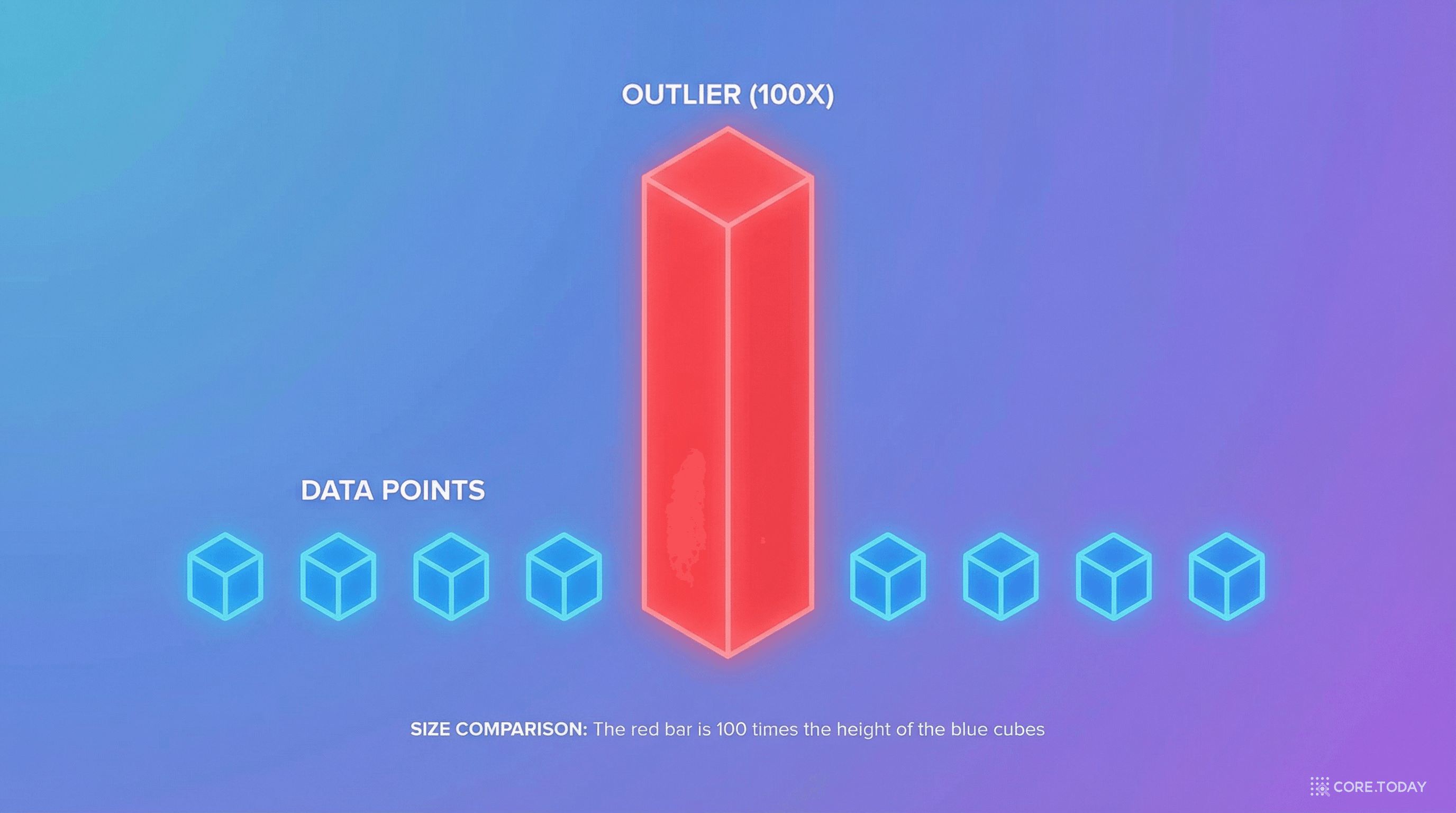
6.7B+ 모델에서 나타나는 이상치 특징(outlier features)은 양자화의 가장 큰 적이다.
전체 활성화의 0.1%에 불과하지만, 나머지보다 ~100배 큰 값이 특정 은닉 차원에 나타난다. 이 값을 포함해 균일 양자화하면, 나머지 99.9%의 값이 극히 좁은 범위에 압축되어 정보가 대량 손실된다.
해결책: SmoothQuant(활성화 스무딩), LLM.int8()(혼합 정밀도), AWQ(중요 채널 보호) 등이 각자의 방식으로 아웃라이어를 다룬다.
가장 심각한 문제:
양자화가 RLHF 안전 가드레일을 침묵 속에 무력화할 수 있다.
연구 결과:
퍼플렉시티는 "배포 준비 상태의 불충분하고 종종 오해를 부르는 대리 지표"라는 것이 연구자들의 경고다.
시사점: 안전이 중요한 모델은 양자화 후 반드시 안전성 재평가를 거쳐야 한다.
Microsoft Research의 Ma 등이 2024년에 발표한 BitNet b1.58은 파격적이다: 가중치가 오직 {-1, 0, +1} 세 값만 가진다. log₂(3) = 1.58비트.
곱셈이 덧셈과 뺄셈으로 대체된다. 부동소수점 곱셈 유닛이 필요 없다.
| 비교 항목 | BitNet b1.58 (3B) | LLaMA FP16 (3B) |
|---|---|---|
| 퍼플렉시티 | 9.91 | 10.04 |
| 메모리 | 2.22 GB | 7.89 GB |
| 지연 시간 | 1.87ms | 5.07ms |
| 에너지 (행렬곱) | 71.4배 절감 | 기준 |
놀라운 점: 1.58비트 모델이 FP16보다 퍼플렉시티가 더 낮다(더 좋다). 0의 추가가 "특징 필터링" 효과를 주기 때문이다.
BitNet b1.58의 연구에서 발견된 패턴:
bitnet.cpp로 100B BitNet 모델을 CPU에서 인간 읽기 속도(5~7 tok/s)로 실행할 수 있다.
| 시나리오 | 추천 기법 | 이유 |
|---|---|---|
| 프로덕션 GPU 서버 (vLLM) | AWQ | Marlin 커널로 최고 속도 (741 tok/s) |
| 프로덕션 GPU 서버 (HF) | GPTQ | 가장 큰 사전 양자화 모델 라이브러리 |
| 가중치+활성화 8비트 | SmoothQuant | 하드웨어 가속 W8A8 |
| Ollama/로컬 PC | GGUF Q4_K_M | CPU에서도 작동, 에너지 효율 최고 |
| 적은 GPU로 파인튜닝 | bitsandbytes (QLoRA) | 48GB GPU 하나로 65B 파인튜닝 |
| 극한 압축 (연구) | QuIP# / QTIP | 2~3비트 SOTA |
BF16으로 학습하고, INT4로 배포한다.
이것이 산업계가 수렴한 결론이다.
양자화는 AI를 실용적으로 만든 기술이다.
데이터센터에서만 돌아가던 수백 GB 모델을 노트북에서 돌리게 만들었고, 수백만 원짜리 GPU가 필요하던 추론을 스마트폰에서 가능하게 만들었으며, 월 수만 달러의 클라우드 비용을 수백 달러로 줄였다.
2015년 BinaryConnect에서 시작된 여정은, 2025년 BitNet b1.58에서 곱셈 없는 신경망까지 도달했다. 이것은 끝이 아니라 시작이다 — NVFP4, 1비트 하드웨어, 온디바이스 양자화가 다음 챕터를 열고 있다.
# 이 한 줄이 280GB를 35GB로 바꾼다
model = AutoModelForCausalLM.from_pretrained("model_name", load_in_4bit=True)