
블로그로 돌아가기
체화 지능로보틱스VLA 모델텐센트파운데이션 모델
HY-Embodied-0.5: AI가 드디어 '몸'을 갖다 — 체화 지능 파운데이션 모델의 새 시대
텐센트가 공개한 HY-Embodied-0.5는 2B 파라미터로 7B급 성능을 달성하며 로봇 AI의 새 기준을 세웠습니다. 1966년 Shakey부터 2026년 체화 지능까지, AI가 물리 세계를 이해하는 여정을 쉽고 자세하게 살펴봅니다.
코어닷투데이2026-04-1345분
텐센트가 공개한 HY-Embodied-0.5는 2B 파라미터로 7B급 성능을 달성하며 로봇 AI의 새 기준을 세웠습니다. 1966년 Shakey부터 2026년 체화 지능까지, AI가 물리 세계를 이해하는 여정을 쉽고 자세하게 살펴봅니다.
ChatGPT에게 "커피 한 잔 타 줘"라고 말하면 어떻게 될까요? 레시피를 알려주겠죠. 하지만 실제로 컵을 집고, 물을 붓고, 설탕을 넣는 일은 하지 못합니다. 아무리 똑똑한 AI라도 물리적인 몸이 없으면 현실 세계에서는 무력합니다.
이것이 바로 체화 지능(Embodied Intelligence)의 핵심 문제입니다. "AI가 텍스트만 잘 이해하면 되는 거 아닌가?"라고 생각할 수 있지만, 현실은 훨씬 복잡합니다. 컵의 무게를 가늠하고, 미끄러지지 않게 힘을 조절하고, 선반까지의 3D 경로를 계산하는 것 — 이 모든 것이 "몸을 가진 지능"이 해야 할 일입니다.
2026년 4월, 텐센트 Robotics X 팀이 발표한 HY-Embodied-0.5는 이 문제에 대한 가장 최신의 답변입니다. 22개 벤치마크에서 최고 성능을 기록하면서도, 겨우 2B(20억) 파라미터로 7B급 모델을 능가하는 놀라운 효율성을 보여줬습니다.
이 글에서는 체화 지능이 왜 필요한지, 어떤 역사를 거쳐 여기까지 왔는지, 그리고 HY-Embodied-0.5가 어떻게 게임 체인저가 되었는지를 처음부터 자세히 풀어보겠습니다.

체화 지능은 AI가 물리적 몸체(로봇)를 통해 현실 세계를 인지하고, 추론하고, 행동하는 능력을 말합니다. 단순히 "로봇 + AI"가 아닙니다. 핵심은 감각-인지-행동의 통합적 루프입니다.
이 세 가지가 실시간으로 맞물려야 합니다. 눈은 환경을 보고, 뇌는 전략을 세우고, 손은 실행합니다. 하나라도 빠지면 로봇은 벽에 부딪히거나 컵을 떨어뜨립니다.
ChatGPT나 GPT-4 같은 대규모 언어모델(LLM)은 텍스트 세계의 천재입니다. 하지만 이들에게는 치명적인 한계가 있습니다:
| 능력 | LLM (텍스트 AI) | 체화 AI (로봇 AI) |
|---|---|---|
| "컵이 뭔지 아는가?" | ✅ 개념적으로 안다 | ✅ 보고, 무게를 느끼고, 잡을 수 있다 |
| "컵을 잡아라" | ❌ 물리적 실행 불가 | ✅ 그리퍼 각도·힘 조절 가능 |
| "테이블 아래에 뭐가 있지?" | ❌ 3D 공간 인식 불가 | ✅ 카메라 각도 바꿔서 확인 |
| "이 물건 깨지기 쉬운가?" | 🔺 텍스트로 추론만 가능 | ✅ 힘 센서로 실시간 판단 |
HY-Embodied-0.5 논문은 이 간극을 "LLM 에이전트와 물리 에이전트 사이의 다리"라고 표현합니다. 바로 이 다리를 놓기 위해 체화 파운데이션 모델이 필요한 것입니다.
체화 지능은 하루아침에 나온 개념이 아닙니다. 60년에 걸친 도전과 실패, 그리고 혁신의 역사가 있습니다.
1966년, Shakey — 스탠포드 연구소(SRI)에서 태어난 세계 최초의 이동형 지능 로봇입니다. 카메라와 범프 센서를 장착하고, 거대한 원격 컴퓨터의 도움을 받아 스스로 방을 돌아다니고 물건을 밀 수 있었습니다. 지금 보면 우스울 정도로 느리고 서툴렀지만, "기계가 환경을 인식하고 행동을 계획할 수 있다"는 것을 처음 증명한 역사적 순간이었습니다.
1973년, WABOT-1 — 일본 와세다대학이 만든 최초의 인간형 로봇. 두 발로 걷고, 두 손으로 물체를 집었습니다. "사람처럼 생긴 로봇"이라는 꿈의 시작점입니다.
1989년, ALVINN — 신경망 하나로 미국 동서 횡단에 성공한 자율주행 시스템. 카메라 입력을 신경망이 직접 핸들 조작으로 변환하는 엔드투엔드(end-to-end) 접근법의 원조입니다. 이 아이디어는 35년 뒤 VLA 모델에서 부활합니다.
1991년, 로드니 브룩스의 혁명 — MIT의 브룩스 교수가 "Intelligence Without Representation(표현 없는 지능)"이라는 논문을 발표합니다. "로봇에게 세상의 내부 모델을 만들어줄 필요 없다. 환경과 직접 상호작용하면 지능이 자연스럽게 출현한다." 이 급진적 주장은 이후 체화 지능 연구의 철학적 기반이 됩니다.
2016년 AlphaGo의 충격 이후, 딥러닝의 파도가 로보틱스 분야를 덮었습니다. 연구자들은 시뮬레이션 환경에서 로봇을 수백만 번 훈련시키는 방법을 개발했습니다. OpenAI의 루빅스 큐브 로봇 손, DeepMind의 축구하는 로봇 등이 이 시기에 등장합니다.
하지만 한계가 뚜렷했습니다. 시뮬레이션과 현실의 차이(sim-to-real gap)가 컸고, 한 가지 작업을 학습한 로봇이 조금만 다른 상황에서 완전히 무력해지는 문제가 있었습니다. "컵을 잡는 법을 배운 로봇이 약간 다른 모양의 컵은 못 잡는" 웃지 못할 상황이 벌어진 것입니다.
전환점은 2022년, Google의 PaLM-E와 SayCan이었습니다. 대규모 언어모델을 로봇에 연결한다는 발상이 모든 것을 바꿨습니다. "주방에서 음료수를 가져와"라는 자연어 명령을 이해하고, 가능한 행동들을 순서대로 계획하고, 실행하는 로봇이 처음 등장한 것입니다.
2023년, RT-2 — Google DeepMind가 웹 데이터로 사전학습한 비전-언어 모델을 로봇 액션으로 직접 변환하는 VLA(Vision-Language-Action) 모델을 발표합니다. 인터넷에서 배운 지식이 로봇의 손끝까지 전달된다는 혁명적 개념입니다.
2024년, OpenVLA와 π0 — Stanford의 OpenVLA는 7B 파라미터 오픈소스 VLA로, 22개 기관에서 수집한 100만 에피소드 데이터로 훈련되었습니다. Physical Intelligence의 π0는 확산 정책(diffusion policy)으로 50Hz의 고빈도 연속 제어를 구현하며 새로운 지평을 열었습니다.
2025년 — Google의 Gemini Robotics와 Figure AI의 Helix가 상용 휴머노이드 로봇에 VLA를 탑재하기 시작합니다. 공장과 가정에 실제로 배치되는 시대가 열렸습니다.
그리고 2026년 4월, 텐센트가 HY-Embodied-0.5를 발표합니다.
HY-Embodied를 이해하려면 먼저 VLA(Vision-Language-Action) 모델을 알아야 합니다.
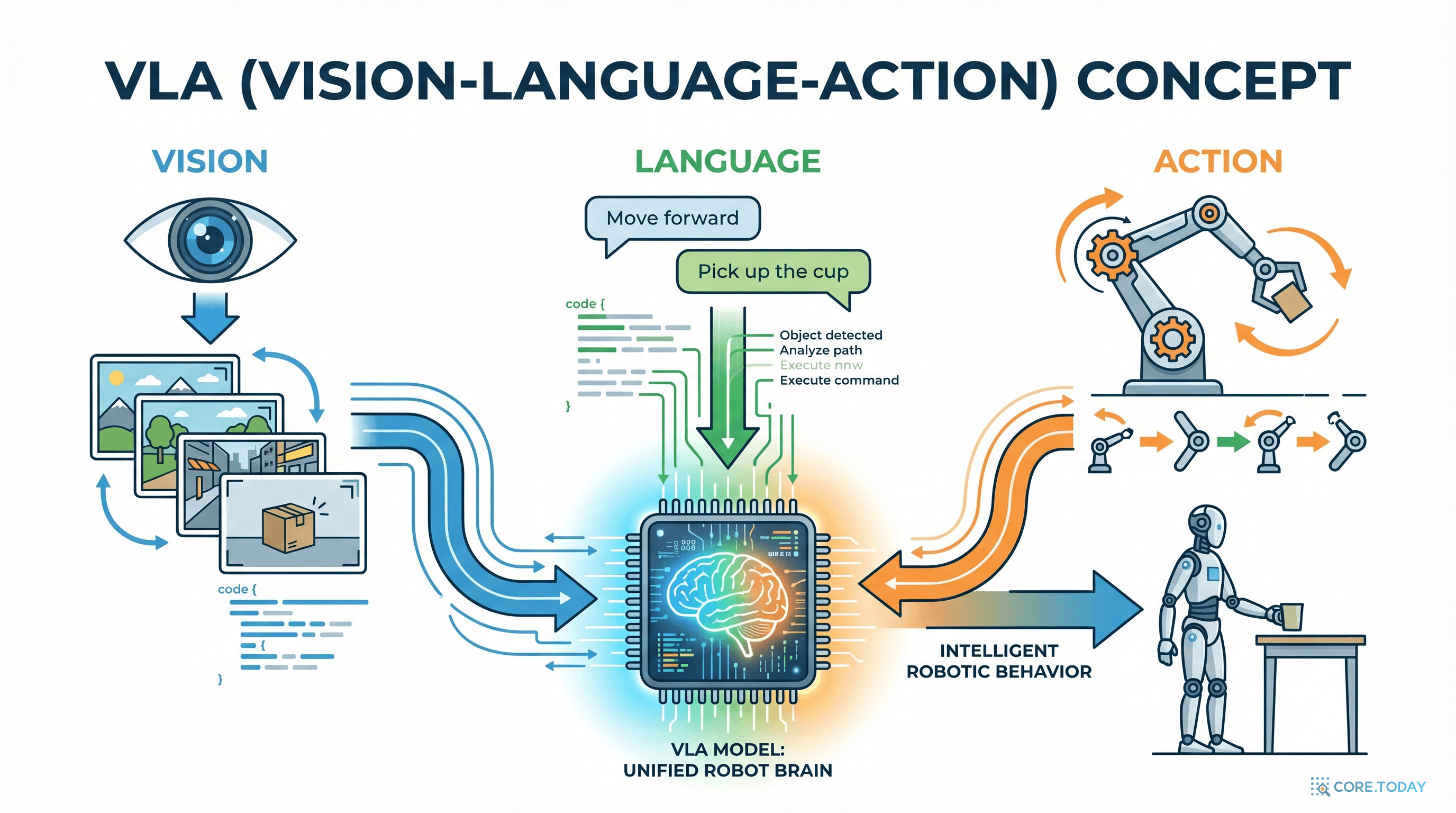
VLA 모델은 이름 그대로 세 가지를 통합합니다:
쉽게 비유하면 이렇습니다. 기존 AI가 "눈을 감고 전화 통화만 하는 상담원"이었다면, VLA 모델은 "눈으로 보고, 말을 듣고, 직접 손으로 행동하는 현장 기술자"입니다.
하지만 기존 VLA 모델에는 심각한 문제들이 있었습니다:
HY-Embodied-0.5는 이 세 가지 문제를 모두 해결하기 위해 설계되었습니다.
텐센트 Robotics X 팀이 2026년 4월에 공개한 HY-Embodied-0.5는 두 가지 모델로 구성됩니다:
| 특성 | MoT-2B (경량) | MoE-A32B (대형) |
|---|---|---|
| 총 파라미터 | 4B (활성화: 2.2B) | 32B 활성화 |
| 타겟 환경 | 엣지 디바이스 (로봇 탑재) | 클라우드/서버 |
| 추론 속도 | 2B 모델급 빠른 속도 | 고성능 GPU 필요 |
| 벤치마크 성능 | 22개 중 16개 1위 | Gemini 3.0 Pro 능가 |
| 핵심 용도 | 실시간 로봇 제어 | 복잡한 추론, 교사 모델 |
핵심 통찰: 32B 모델이 "교사", 2B 모델이 "학생"입니다. 교사가 배운 지식을 학생에게 효율적으로 전달(증류)하여, 작은 모델로도 놀라운 성능을 끌어냅니다.
HY-Embodied가 기존 모델과 차별화되는 점을 세 가지로 정리할 수 있습니다.
각각을 자세히 살펴보겠습니다.
MoT는 HY-Embodied의 심장입니다. Meta 연구팀이 2024년에 처음 제안한 아키텍처를 체화 지능에 맞게 개량한 것입니다.
일반적인 멀티모달 모델은 시각 토큰과 텍스트 토큰을 같은 파라미터로 처리합니다. 이미지를 본 직후에 텍스트를 생성하면, 시각 정보가 텍스트 생성을 방해하거나 그 반대 현상이 일어납니다. 마치 하나의 뇌로 동시에 그림을 그리면서 소설을 쓰는 것과 같습니다.
MoT는 이 문제를 우아하게 해결합니다. 모달리티별 전용 파라미터를 분리하되, 어텐션은 전체적으로 공유합니다.
비유하자면: 시각 전문가와 언어 전문가가 따로 일하되, 회의실(글로벌 어텐션)에서 정보를 교환하는 구조입니다. 각 전문가는 자기 분야에 최적화된 도구를 쓰지만, 중요한 결정은 함께 내립니다.
특히 주목할 점은 시각 토큰에는 양방향 어텐션, 텍스트 토큰에는 단방향(인과적) 어텐션을 사용한다는 것입니다.
이 비대칭 설계 덕분에 시각 인식 능력은 올라가면서도 언어 생성 능력은 유지됩니다.
HY-Embodied만의 독특한 기법입니다. 이미지나 영상 프레임 뒤에 학습 가능한 잠재 토큰을 추가합니다. 이 토큰들은 교사 ViT의 글로벌 피처로 지도학습을 받으며, 시각과 텍스트 사이의 다리 역할을 합니다.
쉽게 말하면: 이미지를 본 뒤 "잠깐, 이 장면에서 정말 중요한 것만 요약해볼게"라고 하는 시각적 메모 패드입니다.
로봇의 "눈"에 해당하는 비전 인코더도 새롭게 설계되었습니다.
핵심 특징:
HY-Embodied의 학습 과정은 4단계로 나뉩니다. 각 단계를 인간의 교육 과정에 비유하면 이해하기 쉽습니다.
강화학습 단계에서 사용하는 GRPO(Group Relative Policy Optimization)는 특히 흥미롭습니다. 16개의 응답을 한 그룹으로 생성하고, 그 안에서 상대적으로 우수한 응답에 높은 보상을 줍니다.
보상 설계도 과제에 따라 다릅니다:
위치 찾기(Grounding): IoU(교집합/합집합)와 거리 메트릭으로 "얼마나 정확히 찾았나" 평가
수치 추정(Regression): 오차에 따라 부드럽게 감소하는 보상. 가까울수록 높은 점수
궤적 계획(Trajectory): DTW(동적 시간 왜곡)와 프레셰 거리로 "경로가 얼마나 비슷한가" 평가
추론(Textual): LLM 판사가 개방형 추론의 논리성과 정확성을 채점
또 하나의 기술적 디테일: 일반적인 PPO는 클리핑 범위를 대칭적으로 [0.8, 1.2]로 설정하지만, HY-Embodied는 [0.8, 1.35]로 비대칭 설정합니다. 상한을 넓혀서 좋은 행동을 더 적극적으로 학습하도록 한 것입니다. 이것이 멀티모달 학습의 안정성을 크게 개선했다고 합니다.
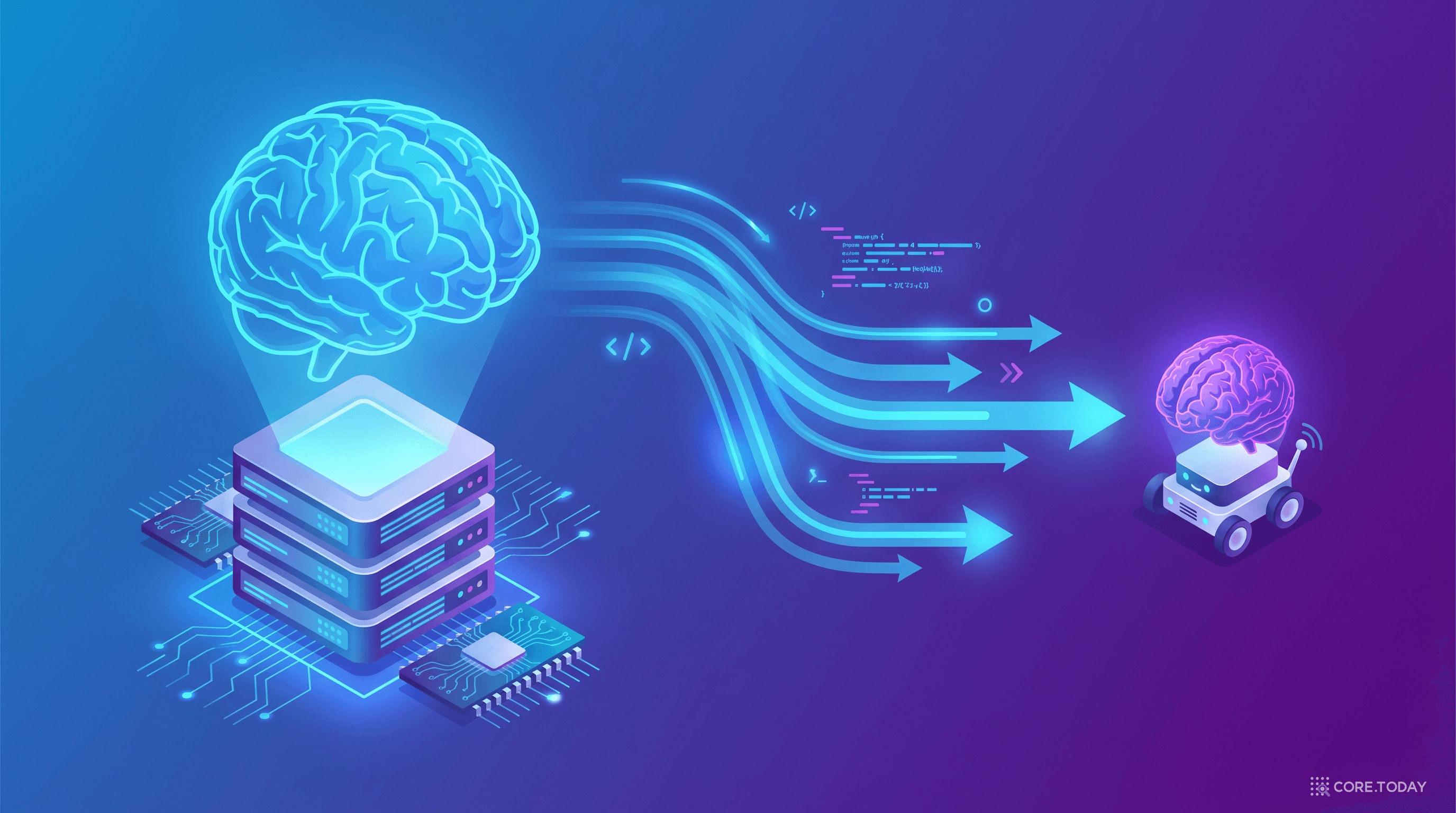
일반적인 지식 증류는 교사 모델의 출력을 학생 모델이 모방합니다. 하지만 HY-Embodied의 온-폴리시 증류는 한 단계 더 나아갑니다.
비유하면: 학생이 시험을 보고, 선생님이 채점하면서 "여기서 이렇게 생각했어야 했어"라고 과정을 교정해주는 것입니다. 답만 알려주는 것보다 훨씬 풍부한 학습 신호를 제공합니다.
아래 인터랙티브 시뮬레이터로 HY-Embodied가 시각 입력에서 로봇 행동까지 어떻게 처리하는지 직접 체험해 보세요.
이론은 훌륭하지만, 실제 성능은 어떨까요? HY-Embodied-0.5는 22개 벤치마크에서 테스트되었으며, 결과는 놀라웠습니다.
특히 체화 이해(Embodied Understanding)와 공간 추론(Spatial Reasoning)에서의 격차가 압도적입니다. 이는 HY-Embodied가 단순한 범용 비전 모델이 아니라, 로봇에 특화된 능력을 갖추었음을 보여줍니다.
| 벤치마크 | HY MoT-2B | Qwen3-VL-4B | MiMo-7B |
|---|---|---|---|
| CV-Bench (시각 인지) | 89.2% | 81.5% | 85.0% |
| EmbSpatial-Bench (공간) | 82.8% | 68.4% | 74.2% |
| MindCube (3D 추론) | 66.3% | 42.1% | 50.8% |
| Where2Place (배치) | 68.0% | 41.5% | 55.3% |
| RoboBench-MCQ (로봇) | 49.2% | 38.7% | 44.1% |
대형 모델의 성적은 더욱 인상적입니다:
Google의 Gemini 3.0 Pro를 3.4%p 차이로 능가하며, 체화 지능 분야에서 가장 강력한 모델임을 입증했습니다.

벤치마크 점수가 아무리 높아도, 진짜 시험은 실제 로봇입니다. 텐센트 팀은 양팔 로봇 Xtrainer를 사용해 세 가지 과제를 수행했습니다.
비교군의 성적과 차이가 극명합니다:
| 과제 | HY-Embodied | π0 | π0.5 |
|---|---|---|---|
| 정밀 플러그인 조립 | 85% | 45% | 50% |
| 식기 쌓기 | 80% | 50% | 55% |
| 머그컵 걸기 | 75% | 45% | 50% |
특히 머그컵 걸기 과제에서 π0 대비 30%p, π0.5 대비 25%p의 격차는 놀랍습니다. 머그 손잡이를 후크에 정확히 걸기 위해서는 3D 공간에서의 정밀한 방향 제어가 필요한데, 이것이 바로 HY-Embodied의 강화된 공간 추론 능력이 빛을 발하는 순간입니다.
글로벌 서비스 로보틱스 시장은 2024년 471억 달러에서 2029년 987억 달러로 급성장할 전망입니다(CAGR 15.9%). 이 시장의 핵심 동력이 바로 체화 지능입니다.
이 논문이 중요한 이유는 단순히 "또 하나의 좋은 모델"이 아니기 때문입니다. 세 가지 패러다임 전환을 보여줍니다:
1. "크면 좋다"에서 "작아도 똑똑하다"로
RT-2(55B), π0(수십B)와 달리, HY-Embodied MoT-2B는 2.2B 활성화 파라미터로 더 큰 모델을 능가합니다. 이는 실시간 로봇 제어를 위해 엣지 디바이스에 직접 탑재할 수 있다는 뜻입니다. 클라우드 지연 없이 밀리초 단위로 반응하는 로봇이 가능해집니다.
2. "범용"에서 "특화"로
GPT-4V를 로봇에 쓰는 것보다, 체화 인지에 특화된 모델을 만드는 것이 더 효과적임을 증명했습니다. 1억 개 이상의 체화·공간 데이터로 훈련한 전문 모델이 범용 대형 모델보다 관련 작업에서 월등히 뛰어납니다.
3. "한 번 학습"에서 "자기진화"로
반복적 강화학습 → RFT 사이클을 통해 모델이 스스로 성능을 개선합니다. 이는 배포 후에도 계속 발전할 수 있는 기반을 제공합니다.
HY-Embodied의 성능 뒤에는 방대한 학습 데이터가 있습니다:
이 데이터에는 단순한 이미지 인식을 넘어서:
등 로봇에게 필수적인 정보들이 포함되어 있습니다.
HY-Embodied-0.5 MoT-2B는 오픈소스로 공개되었습니다.
모델 가중치: Hugging Face tencent/HY-Embodied-0.5 (약 8GB)
추론 코드: GitHub Tencent-Hunyuan/HY-Embodied
요구사항: Python 3.12+, CUDA 12.6, PyTorch 2.8.0, GPU 16GB+ VRAM
계획 중: vLLM 추론, 미세조정 코드, Gradio 온라인 데모
from transformers import AutoModelForImageTextToText, AutoProcessor
import torch
processor = AutoProcessor.from_pretrained("tencent/HY-Embodied-0.5")
model = AutoModelForImageTextToText.from_pretrained(
"tencent/HY-Embodied-0.5",
torch_dtype=torch.bfloat16
).to("cuda").eval()
16GB VRAM GPU가 있다면 누구나 바로 실험해볼 수 있습니다. 이 접근성은 연구 커뮤니티에서의 빠른 후속 연구를 촉진할 것으로 기대됩니다.
HY-Embodied-0.5가 인상적이지만, 아직 완벽하지는 않습니다:
체화 지능의 궁극적 목표는 어떤 환경에서든 자연어 명령만으로 작업을 수행하는 범용 로봇입니다. HY-Embodied-0.5는 그 여정에서 중요한 이정표를 세웠습니다.
1966년 Shakey가 처음 방을 돌아다닌 이후 60년, AI는 드디어 현실 세계를 진짜로 이해하고 조작할 수 있는 단계에 와 있습니다.
HY-Embodied-0.5가 보여준 것은 단순한 기술적 진보가 아닙니다. 효율적인 체화 지능이 가능하다는 것, 그리고 오픈소스로 누구나 접근할 수 있다는 것입니다. 2B 파라미터로 로봇에 직접 탑재할 수 있다는 것은, 비싼 클라우드 인프라 없이도 작은 팀이나 스타트업이 지능형 로봇을 만들 수 있다는 뜻입니다.
ChatGPT가 "AI가 말을 할 수 있다"는 것을 증명했다면, HY-Embodied-0.5 같은 체화 모델은 "AI가 행동할 수 있다"는 것을 증명하고 있습니다. 텍스트 채팅창을 넘어, AI가 물리적 세계에 손을 뻗기 시작한 것입니다.
다음에는 당신의 로봇이 커피를 타줄지도 모릅니다. 그때 그 로봇의 뇌 속에는, 오늘 살펴본 바로 이 기술이 들어 있을 것입니다.
참고 논문: Yu, X., Liu, Z., Wang, Z., et al. (2026). HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents. arXiv:2604.07430
오픈소스: GitHub | Hugging Face



