블로그로 돌아가기
Git버전 관리GitHub브랜치DevOps협업CI/CD
Git 완전 정복: 코드 버전 관리가 왜 팀 협업의 핵심인가
final_v2_진짜최종_수정3.pptx 시대를 끝내자. 리누스 토르발스가 2주 만에 만든 Git이 어떻게 현대 소프트웨어 협업의 기반이 되었는지 — 핵심 개념, 내부 구조, 브랜칭 전략, DevOps 연동까지 완전히 풀어본다.
코어닷투데이2026-02-1369분
final_v2_진짜최종_수정3.pptx 시대를 끝내자. 리누스 토르발스가 2주 만에 만든 Git이 어떻게 현대 소프트웨어 협업의 기반이 되었는지 — 핵심 개념, 내부 구조, 브랜칭 전략, DevOps 연동까지 완전히 풀어본다.
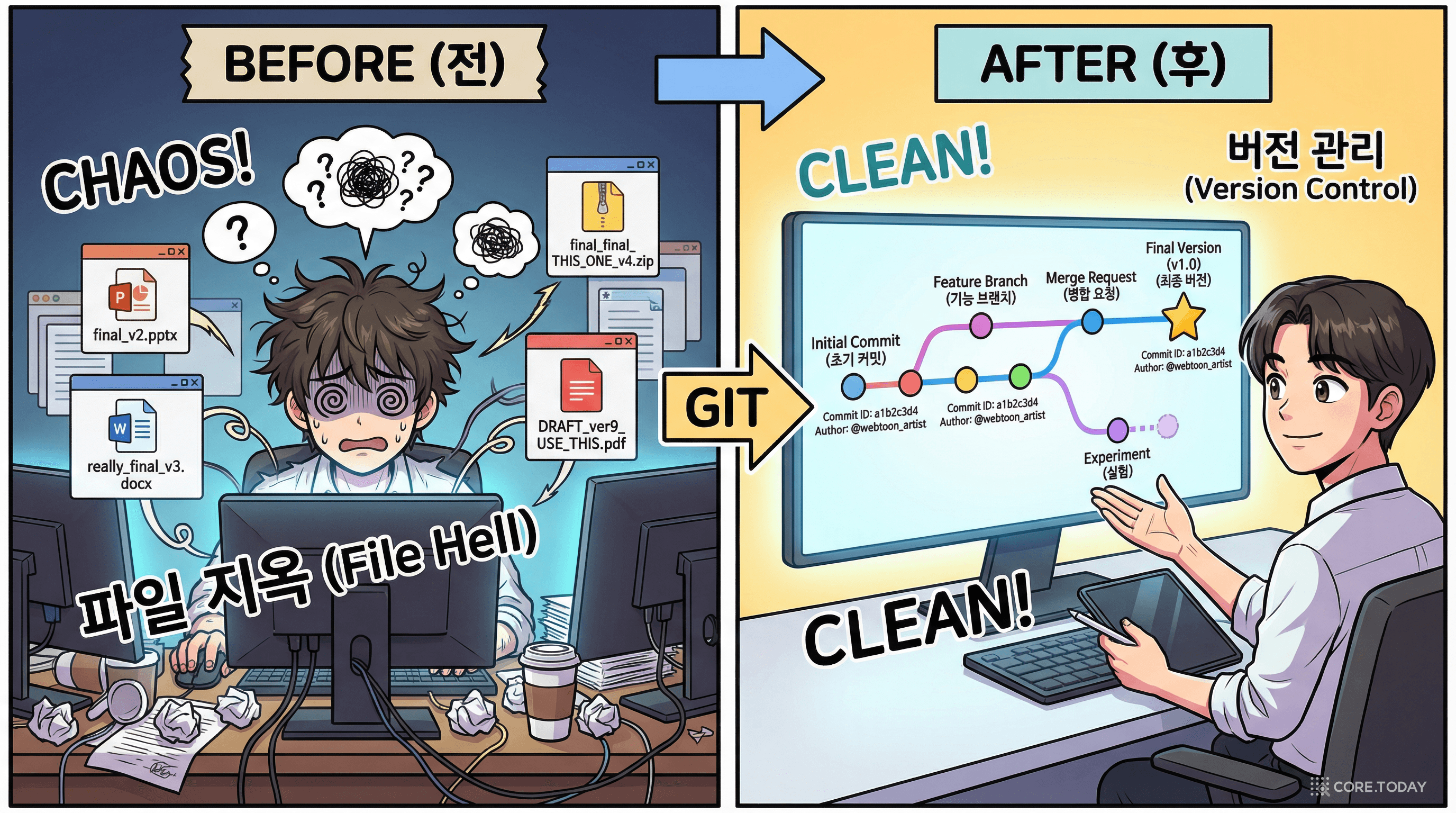
누구나 한 번쯤 이런 파일명을 본 적이 있을 것이다.
보고서_최종.docx보고서_최종_수정.docx보고서_최종_수정_진짜최종.docx보고서_최종_수정_진짜최종_v2_팀장님피드백반영.docx웃기지만, 이것이 버전 관리(Version Control)가 없던 시절의 현실이었다. 파일명에 날짜를 넣고, 폴더를 복사하고, 누가 마지막으로 수정했는지 카카오톡으로 물어보는 — 그야말로 원시적인 방법이다.
개인 문서도 이 정도인데, 소프트웨어 코드는 어떨까? 수십만 줄의 코드를, 수십 명의 개발자가, 동시에 수정한다. 파일명으로 버전을 관리하는 것은 불가능하다. 누가 언제 무엇을 왜 바꿨는지 추적할 수 없고, 두 사람이 같은 파일을 동시에 고치면 누군가의 작업은 사라진다.
이 문제를 해결하기 위해 버전 관리 시스템(Version Control System, VCS)이 탄생했다. 그리고 2026년 현재, 전 세계 개발자의 93% 이상이 사용하는 VCS가 바로 Git이다.
이 글에서는 Git이 왜 만들어졌는지, 어떻게 작동하는지, 그리고 현대 팀 협업에서 왜 필수인지를 처음부터 끝까지 풀어본다.
Git 이전에도 버전 관리 도구는 있었다. 1972년의 SCCS, 1982년의 RCS, 1990년의 CVS, 2000년의 Subversion(SVN) — 모두 "중앙 서버에 코드를 보관하고, 개발자가 하나씩 꺼내 쓰는" 모델이었다.
이 중앙집중식(Centralized) 모델의 치명적 문제는 명확했다. 서버가 다운되면 아무도 작업할 수 없고, 네트워크가 없으면 히스토리를 볼 수 없다. 오프라인에서는 커밋조차 불가능하다.
Linux 커널은 세계 최대의 오픈소스 프로젝트다. 수천 명의 개발자가 동시에 코드를 기여한다. 2002년부터 Linux 커널 팀은 BitKeeper라는 상용 분산 버전 관리 시스템을 무료로 사용하고 있었다. BitKeeper의 개발사 BitMover가 오픈소스 커뮤니티에 무료 라이선스를 제공한 것이다.
그런데 2005년 4월, 이 관계가 깨졌다. Linux 커널 개발자 Andrew Tridgell이 BitKeeper의 프로토콜을 리버스 엔지니어링한 것이 발단이었다. BitMover는 무료 라이선스를 즉시 철회했다.
리누스 토르발스(Linus Torvalds)는 분노했다. 기존의 오픈소스 버전 관리 시스템(CVS, SVN)은 Linux 커널의 규모를 감당할 수 없었다. 그래서 그는 직접 만들기로 결심한다.
2005년 4월 3일에 개발을 시작해, 4월 7일에 Git은 자기 자신의 소스 코드를 관리할 수 있게 되었다. 4월 18일에는 Linux 커널 브랜치를 합칠 수 있었고, 4월 29일에는 초당 6.7개의 패치를 Linux 커널에 적용하는 성능 목표를 달성했다.
불과 2주 만에, 역사상 가장 중요한 개발 도구가 탄생한 것이다.
Git을 처음 접하면 용어가 쏟아진다. 하지만 핵심 개념은 다섯 가지다.
프로젝트의 모든 파일과 그 변경 이력을 담는 공간. 프로젝트 폴더 안에 .git이라는 숨김 디렉토리가 생기면, 그 폴더는 Git 저장소다.
핵심: Git은 분산형이므로, 로컬 저장소만으로도 완전한 버전 관리가 가능하다. 원격 저장소는 팀 협업과 백업을 위한 것이다.
프로젝트의 스냅샷. 특정 시점의 파일 상태를 저장하는 행위이자 그 결과물이다. 게임의 "세이브 포인트"와 같다.
각 커밋에는 다음 정보가 포함된다:
커밋 히스토리의 독립적인 작업 흐름. 나무의 "가지"처럼, 메인 줄기에서 갈라져 나와 독립적으로 작업한 뒤, 다시 합칠 수 있다.
두 브랜치의 변경사항을 하나로 합치는 작업. Git의 머지는 매우 영리해서, 두 사람이 다른 파일을 수정했다면 자동으로 합친다. 같은 파일의 같은 줄을 수정했을 때만 "충돌(conflict)"이 발생하며, 이때는 사람이 직접 해결해야 한다.
현재 작업 중인 커밋을 가리키는 포인터. "지금 내가 어디에 있는지"를 알려준다. 보통 HEAD는 현재 브랜치의 최신 커밋을 가리킨다.
Git이 왜 빠르고 안전한지 이해하려면, 내부 구조를 살짝 들여다볼 필요가 있다. 복잡하지 않다 — Git의 핵심은 놀라울 정도로 단순한 데이터 구조 위에 세워져 있다.
Git 저장소의 .git/objects/ 디렉토리 안에는 네 가지 종류의 객체만 존재한다.
Git의 모든 객체는 SHA-1 해시로 이름이 붙는다. 40자리의 16진수 문자열이다.
한 글자만 바꿔도 해시가 완전히 달라진다. 이것이 Git의 데이터 무결성 보장 원리다. 파일이 전송 중에 손상되거나, 누군가 몰래 히스토리를 변경하면, 해시값이 달라지므로 즉시 감지할 수 있다.
각 커밋은 부모 커밋의 해시를 포함한다. 이것이 커밋들을 연결 리스트(Linked List)처럼 연결한다. 최신 커밋에서 부모를 따라가면 프로젝트의 전체 역사를 거슬러 올라갈 수 있다.
그리고 부모의 해시가 자식 커밋에 포함되기 때문에, 과거 커밋을 조작하면 그 이후의 모든 해시가 연쇄적으로 변한다. 블록체인과 같은 원리다. Git은 2005년에 이미 이 구조를 사용하고 있었다.
이론은 충분하다. 실제로 Git을 어떻게 사용하는지 보자.
Git은 파일을 세 가지 영역으로 관리한다. 이것을 이해하는 것이 Git 사용의 핵심이다.
스테이징 영역이 Git의 독특한 설계다. 다른 VCS는 변경된 파일을 전부 커밋하지만, Git은 원하는 변경사항만 골라서 커밋할 수 있다. 예를 들어 5개의 파일을 수정했지만, 그 중 3개만 하나의 논리적 변경에 해당한다면, 3개만 스테이징하고 커밋하면 된다.
이 여섯 가지 명령어만 알아도 Git의 기본은 끝이다. init으로 시작하고, add로 고르고, commit으로 저장하고, push로 공유하고, pull로 받아온다.
Git의 진정한 힘은 브랜치(Branch)에 있다. SVN에서 브랜치를 만드는 것은 전체 프로젝트를 복사하는 것이나 마찬가지여서 무겁고 느렸다. Git에서는 브랜치가 단지 40바이트짜리 포인터 하나를 만드는 것이다. 즉시 생성되고, 메모리도 거의 쓰지 않는다.
가장 기본적인 전략. 새로운 기능을 만들 때마다 main에서 브랜치를 만들고, 기능이 완성되면 다시 main으로 합친다.
# 새 기능 브랜치 생성
git checkout -b feature/login-page
# ... 작업 후 커밋 ...
git add .
git commit -m "로그인 페이지 UI 구현"
# main으로 돌아가서 합치기
git checkout main
git merge feature/login-page
이것만으로도 소규모 팀에서는 충분하다. 하지만 팀이 커지면 더 구조화된 전략이 필요하다.
| 항목 | Git Flow | GitHub Flow | Trunk-Based |
|---|---|---|---|
| 브랜치 수 | 5종 (main, develop, feature, release, hotfix) | 2종 (main + feature) | 1종 (main만, 아주 짧은 feature) |
| 복잡도 | 높음 | 낮음 | 매우 낮음 |
| 배포 빈도 | 주 1~2회 (릴리즈 주기) | 일 수회 | 일 수십 회 (지속적 배포) |
| 적합한 팀 | 명확한 릴리즈 주기가 필요한 대규모 팀 | 대부분의 웹 서비스 팀 | CI/CD가 성숙한 고성과 팀 |
| 대표 사용자 | 모바일 앱, 패키지 SW | GitHub, Shopify | Google, Meta, Netflix |
| 머지 충돌 빈도 | 높음 (장기 브랜치) | 보통 | 매우 낮음 |
Git Flow는 Vincent Driessen이 2010년에 제안한 모델로, main, develop, feature/*, release/*, hotfix/* 다섯 종류의 브랜치를 사용한다. 릴리즈 버전 관리가 명확하지만, 현대적인 웹 서비스에는 지나치게 복잡하다.
GitHub Flow는 이를 극단적으로 단순화한 것이다. main 브랜치 하나와, 거기서 파생한 feature 브랜치만 사용한다. 기능이 완성되면 Pull Request를 열고, 코드 리뷰를 거쳐 main에 합친다. 대부분의 팀에게 가장 적합한 전략이다.
Trunk-Based Development는 더 극단적이다. 모든 개발자가 하루에도 여러 번 main(trunk)에 직접 통합한다. Feature 브랜치를 만들더라도 하루 이내에 합친다. Google, Meta 같은 기업이 사용하며, 강력한 CI/CD와 Feature Flag가 전제 조건이다.
브랜치를 합치는 방법은 두 가지다. Merge와 Rebase. 이 둘의 차이를 이해하는 것은 Git 중급자로 가는 관문이다.
git checkout main
git merge feature/login
Merge는 두 브랜치의 역사를 합치는 "병합 커밋(merge commit)"을 만든다. 두 줄기의 역사가 만나는 지점이 기록된다.
장점: 실제 작업 흐름이 그대로 보존된다. 누가 언제 어떤 브랜치에서 작업했는지 명확하다.
단점: 많은 브랜치가 합쳐지면 히스토리가 복잡해진다. git log --graph로 보면 지하철 노선도처럼 얽힌다.
git checkout feature/login
git rebase main
Rebase는 브랜치의 시작점을 main의 최신 커밋으로 "다시 배치(re-base)"한다. 마치 main의 최신 상태에서 처음부터 작업한 것처럼 히스토리가 직선이 된다.
장점: 히스토리가 깔끔한 직선이다. 읽기 쉽다.
단점: 이미 공유된 커밋을 rebase하면 다른 사람의 작업이 꼬인다.
Git 자체는 분산형 도구다. GitHub, GitLab, Bitbucket은 Git 위에 협업 기능을 얹은 플랫폼이다. 그 중 가장 중요한 것이 Pull Request(PR) — GitLab에서는 Merge Request(MR)이라 부른다.
"내 브랜치의 변경사항을 main에 합쳐 주세요"라고 요청하는 것이다. PR에는 다음이 포함된다:
PR 기반 코드 리뷰는 단순한 버그 찾기가 아니다. 팀의 지식 공유 메커니즘이다.
Google은 모든 코드 변경에 최소 1명의 리뷰를 의무화한다. Microsoft의 연구에 따르면, 코드 리뷰를 도입한 팀의 결함 밀도가 평균 30% 감소했다.
모든 파일을 Git으로 추적하면 안 된다. 비밀키, 빌드 산출물, 의존성 폴더, OS 임시 파일 등은 저장소에 들어가면 안 된다.
.gitignore 파일에 패턴을 적으면 Git이 해당 파일을 무시한다.
.env 파일(API 키, 데이터베이스 비밀번호 등)을 Git에 커밋하는 것은 보안 사고의 시작이다. GitHub에 공개 저장소로 올린 .env 파일은 수 분 내에 자동 스캔 봇에 의해 발견된다. AWS 키가 유출되어 수천만 원의 클라우드 비용이 청구된 사례는 매년 발생한다.Git Hooks는 커밋, 푸시 등 Git 이벤트가 발생할 때 자동으로 실행되는 스크립트다. .git/hooks/ 디렉토리에 위치한다.
| Hook | 실행 시점 | 활용 예시 |
|---|---|---|
pre-commit | 커밋 직전 | 코드 포맷팅 (prettier), 린트 검사 (eslint) |
commit-msg | 커밋 메시지 작성 후 | 커밋 메시지 형식 검증 (Conventional Commits) |
pre-push | push 직전 | 테스트 실행, 빌드 검증 |
post-merge | merge 완료 후 | 의존성 자동 설치 (npm install) |
실무에서는 Husky + lint-staged 조합을 많이 쓴다. 커밋할 때마다 변경된 파일만 자동으로 포맷팅하고 린트를 돌린다. 잘못된 코드가 저장소에 들어가는 것을 원천적으로 막는다.
Git은 단순한 버전 관리 도구를 넘어, 현대 DevOps 파이프라인의 핵심 트리거다.
개발자가 git push를 하는 순간, GitHub Actions, GitLab CI, Jenkins 같은 CI/CD 도구가 이를 감지하고 자동화 파이프라인을 실행한다. 빌드, 테스트, 배포가 사람의 개입 없이 진행된다.
GitOps는 2017년 Weaveworks가 제안한 개념으로, 인프라 설정을 Git 저장소에 선언적으로 정의하고, Git의 변경사항이 곧 인프라에 반영되는 방식이다.
git revert로 이전 상태로 즉시 복구할 수 있다.Terraform, Pulumi, AWS CDK 같은 IaC 도구의 코드도 Git으로 관리한다. 서버 100대의 설정이 Git 저장소 하나에 정의되어 있고, 변경 이력이 모두 추적된다. "2주 전에 누가 방화벽 규칙을 바꿨지?" 같은 질문에 git log로 즉시 답할 수 있다.
커밋 메시지는 미래의 나와 동료에게 보내는 편지다. "수정", "업데이트", "fix" 같은 메시지는 3개월 후에 아무 의미가 없다.
Conventional Commits 형식을 추천한다:
| 패턴 | 나쁜 예 | 좋은 예 |
|---|---|---|
| 빈도 | 하루 종일 작업 후 한 번에 커밋 | 논리적 단위마다 (30분~2시간 간격) |
| 크기 | 50개 파일, 2000줄 변경 | 3~10개 파일, 100~300줄 변경 |
| 범위 | "로그인 기능 + 메인 페이지 UI + DB 스키마 변경" | "로그인 폼 UI 구현" (단일 목적) |
| 메시지 | "작업 완료" / "수정" | "feat(auth): 이메일 유효성 검증 로직 추가" |
작은 커밋은 리뷰하기 쉽고, 문제가 생겼을 때 원인을 찾기 쉽고, 되돌리기도 쉽다.
Git을 쓰다 보면 반드시 실수한다. 당황하지 말자. Git은 거의 모든 것을 복구할 수 있다.
| 상황 | 해결 명령어 | 설명 |
|---|---|---|
| 커밋 메시지를 잘못 적었다 | git commit --amend | 마지막 커밋의 메시지를 수정 (아직 push하지 않은 경우) |
| 파일을 빼먹고 커밋했다 | git add 파일 && git commit --amend | 마지막 커밋에 파일 추가 |
| 커밋을 취소하고 싶다 (변경사항은 유지) | git reset --soft HEAD~1 | 커밋만 취소, 변경사항은 스테이징 상태로 남음 |
| 작업 중인 변경을 임시 저장하고 싶다 | git stash | 변경사항을 숨겨두고 나중에 git stash pop으로 복원 |
| 이미 push한 커밋을 되돌리고 싶다 | git revert HEAD | 변경을 취소하는 "새로운 커밋"을 만든다 (히스토리 보존) |
| 모든 것이 엉망이다 | git reflog | Git이 기억하는 모든 HEAD 이동 기록. 여기서 원하는 시점을 찾아 복구 |
git reset --hard로 작업을 날렸다고? git reflog를 실행하면 Git이 최근 30일간의 모든 HEAD 이동 기록을 보여준다. 거기서 되돌리고 싶은 시점의 해시를 찾아 git reset --hard <해시>하면 복구할 수 있다. 커밋만 했다면, Git에서 데이터를 영구적으로 잃는 것은 거의 불가능하다.2005년에 탄생한 Git은 20년이 지난 지금도 꾸준히 발전하고 있다.
최근의 주목할 변화들:
DX(Digital Transformation)를 추진하려면, 코드든 인프라 설정이든 문서든 — 모든 변경은 추적 가능해야 한다. Git은 그 추적 가능성의 기반이다.
이 글의 시작은 보고서_최종_수정_진짜최종_v2.docx였다. 파일명으로 버전을 관리하던 시대는 끝났다.
Git이 가르쳐주는 것은 단순한 도구 사용법이 아니다. "모든 변경에는 이유가 있어야 하고, 그 이유는 기록되어야 한다"는 원칙이다.
이것이 Git이 만들어낸 현대 협업의 문법이다.
리누스 토르발스가 2주 만에 급하게 만든 도구가, 20년이 지난 지금 전 세계 1억 명 이상의 개발자가 매일 사용하는 사실상의 표준이 되었다. 그 이유는 간단하다. Git은 "사람은 실수하고, 협업은 어렵다"는 현실을 인정하고, 그 위에서 작동하도록 설계되었기 때문이다.
DX 전문가를 꿈꾸든, 소프트웨어 개발자를 목표로 하든, AI 엔지니어를 지향하든 — Git은 반드시 익혀야 할 첫 번째 도구다. 지금 바로 터미널을 열고 git init을 입력해 보자. 그 한 줄이, 당신의 협업 방식을 근본적으로 바꿀 것이다.