블로그로 돌아가기
팩트체킹주장 추출ClaimifyLLM 환각사실 검증ACL 2025
AI가 말한 건 사실일까? — 주장 추출과 팩트체킹의 최전선
LLM이 쏟아내는 긴 답변 속에서 '진짜 사실'만 골라내려면? ACL 2025 최우수 논문이 제시한 주장 추출 평가 프레임워크와 Claimify 시스템을 쉽고 재미있게 파헤칩니다.
코어닷투데이2026-04-0244분
LLM이 쏟아내는 긴 답변 속에서 '진짜 사실'만 골라내려면? ACL 2025 최우수 논문이 제시한 주장 추출 평가 프레임워크와 Claimify 시스템을 쉽고 재미있게 파헤칩니다.
2023년 6월, 뉴욕의 변호사 Steven Schwartz가 법원에 준비서면을 제출했다. 인용한 판례 6건 — Varghese v. China Southern Airlines 등 — 은 모두 ChatGPT가 만들어낸 가짜였다. 실존하는 저자 이름, 실존하는 법원명, 그리고 실존하는 학술지를 교묘하게 조합해 탄생한 '유령 판례'였다.
벌금 $5,000. 하지만 진짜 비용은 따로 있었다 — "AI가 말한 건 과연 사실인가?"라는 질문이 세상에 던져진 것이다.
2026년 현재, ChatGPT·Copilot·Gemini 같은 LLM이 하루에 만들어내는 텍스트는 수십억 단어에 달한다. 뉴스 요약, 보고서 작성, 학술 검색, 법률 자문 — AI가 생성한 장문의 응답을 그대로 믿어도 될까?
이 글에서는 ACL 2025에 발표된 Microsoft Research 논문 "Towards Effective Extraction and Evaluation of Factual Claims"를 중심으로, AI 텍스트를 팩트체킹하는 최신 기법을 깊이 있게 탐구한다.
LLM의 본질은 다음 토큰 예측이다. "대한민국의 수도는" 뒤에 "서울"이 올 확률이 높다는 패턴을 학습했을 뿐, 이것이 사실인지 판단하는 능력은 없다.
문제는 학습 데이터에 없는 질문이 들어왔을 때다. 모델은 "모르겠습니다"라고 답하는 대신, 가장 그럴듯한 패턴을 자신감 있게 생성한다. 이것이 환각(hallucination)이다.
Xu et al. (2024)의 증명: 범용 LLM에서 환각은 구조적으로 불가피하다 — 완벽한 데이터가 있어도, 통계적·계산적 한계 때문에 대형 언어 모델은 항상 그럴듯하지만 거짓인 출력을 생성할 수 있다.
짧은 응답은 그나마 검증이 쉽다. 하지만 LLM이 1,000단어짜리 보고서를 생성하면? 사실, 의견, 추론, 배경지식이 뒤섞인 긴 문단에서 어디가 맞고 어디가 틀린지 한눈에 판별하기란 사실상 불가능하다.
AI 팩트체킹은 하루아침에 등장한 것이 아니다. 그 뿌리는 인터넷 시대의 허위정보 대응까지 거슬러 올라간다.
기본 아이디어는 간단하다:
그런데 여기서 중요한 질문이 생긴다: "주장을 잘 쪼갰는지"는 어떻게 판단할까?
잘못 쪼개면 팩트체킹 전체가 무너진다. 원문의 의미를 왜곡하거나, 중요한 사실을 빠뜨리거나, 맥락 없이 독립적으로 이해 불가능한 주장을 만들면 — 아무리 좋은 검증 시스템이 있어도 쓰레기가 들어가면 쓰레기가 나온다(Garbage In, Garbage Out).
바로 이 문제를 해결한 것이 이 논문의 핵심 기여다.
논문은 주장 추출의 품질을 평가하는 세 가지 핵심 기준을 제안한다.
추출된 주장은 원문에 의해 논리적으로 뒷받침되어야 한다. 원문이 사실이라면, 거기서 추출한 주장도 반드시 사실이어야 한다는 뜻이다.
이전 연구들은 이 기준을 faithfulness, coherence, correctness 등 다양한 이름으로 불렀지만, 핵심은 같다 — 추출된 주장이 원문을 왜곡하면 안 된다.
추출된 주장들은 원문의 검증 가능한 정보를 빠짐없이 포착하되, 검증 불가능한 정보는 포함하지 않아야 한다.
여기서 논문이 제안하는 혁신적인 개념이 바로 요소 수준 커버리지(element-level coverage)다.
기존 방식인 문장 수준 커버리지는 "이 문장에 사실적 주장이 포함되어 있는가?"만 묻는다. 하지만 이것만으로는 부족하다.
문장 수준에서는 A와 B 모두 "이 문장에 사실적 주장이 있다"고 정확하게 판별했으므로 동등한 점수를 받는다. 하지만 실제로는 B가 훨씬 낫다!
논문은 문장을 개별 요소(element)로 분해한다:
| 요소 | 검증 가능? | 방법 A | 방법 B |
|---|---|---|---|
| 미국 국기는 상징적이다 | ❌ 의견 | 명시적 포함 (FP) | 미포함 (TN) ✅ |
| 별이 50개 있다 | ✅ 사실 | 미포함 (FN) | 명시적 포함 (TP) ✅ |
| 줄무늬가 13개 있다 | ✅ 사실 | 미포함 (FN) | 명시적 포함 (TP) ✅ |
방법 A: 검증 불가능한 의견("상징적이다")을 포함하고, 핵심 숫자(50개, 13개)를 놓침 — FP 1개, FN 2개 방법 B: 검증 가능한 사실만 정확히 추출 — TP 2개, TN 1개
이것이 요소 수준 커버리지의 핵심이다. 같은 문장에서도 무엇을 골라냈는가에 따라 품질이 완전히 달라진다.
추출된 주장은 원래 맥락 없이도 독립적으로 이해되어야 한다. 그리고 원래 맥락에서 가졌던 의미를 그대로 유지해야 한다.
이것이 왜 중요한지, 논문의 가장 인상적인 예시를 보자:
핵심 맥락("전기차에 대한", "팟캐스트에서")을 생략했기 때문에 팩트체킹 시스템이 엉뚱한 증거를 가져와 잘못된 판정을 내린 것이다.
기존 연구들은 "이 주장이 충분히 탈맥락화되었는가?"를 사람이 주관적으로 판단했다. 논문은 이를 결과 기반(outcome-based)으로 바꾼다:
판정이 일치하면 빠진 맥락이 결과에 영향을 미치지 않으므로 OK. 판정이 다르면 맥락이 부족하다는 뜻이므로 탈맥락화 실패다.
이 접근법의 혁신은 "충분한 맥락"이라는 주관적 판단을 "팩트체킹 결과가 바뀌는가"라는 객관적 판단으로 대체했다는 점이다.
논문은 위 평가 프레임워크에서 최고 성능을 보이는 새로운 주장 추출 시스템 Claimify를 소개한다.
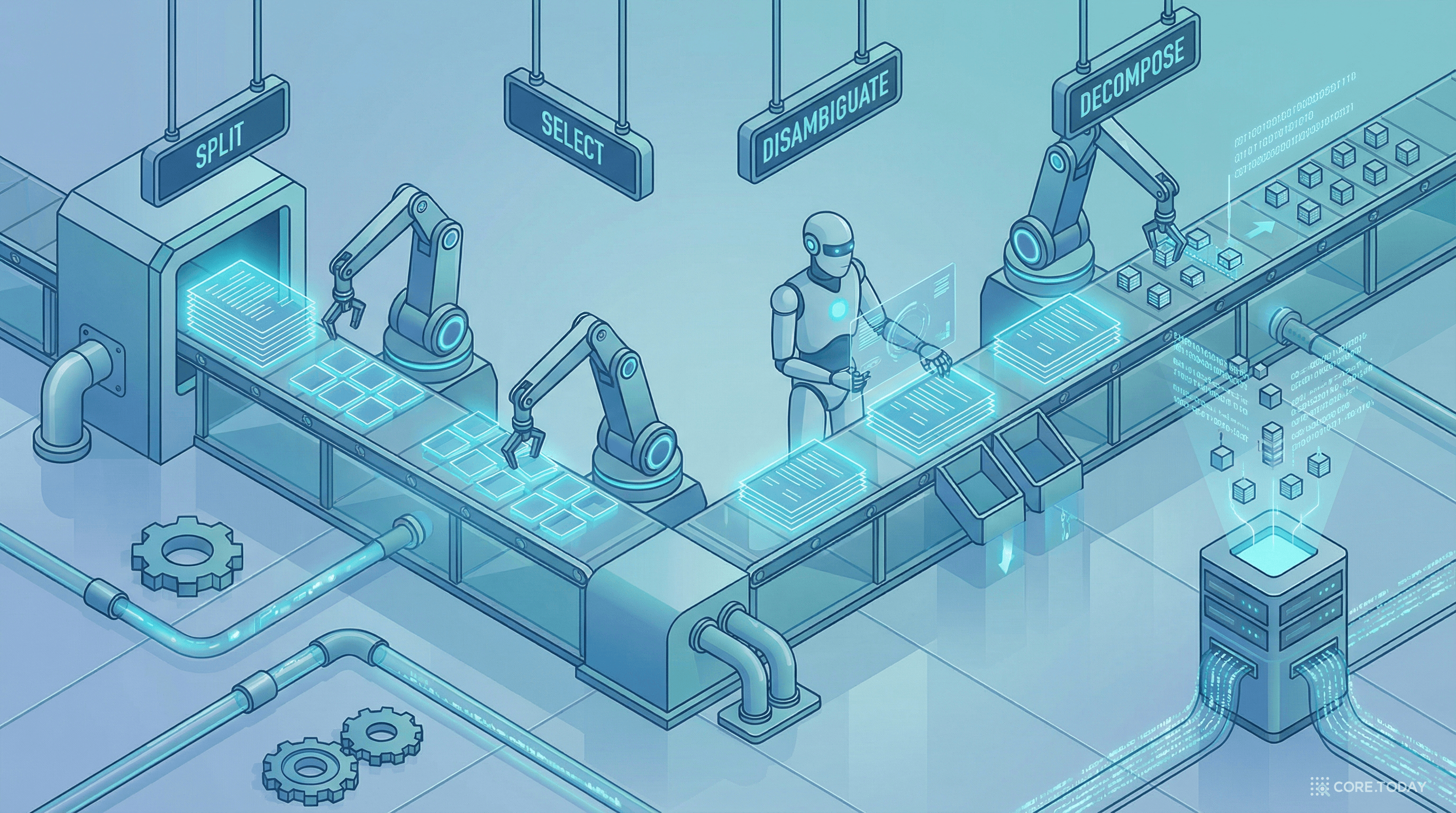
Claimify는 질문-응답 쌍을 입력받아 4단계를 거쳐 검증 가능한 사실적 주장들을 추출한다.
응답을 문장 단위로 분리하고, 각 문장에 앞뒤 문장 맥락을 부여한다.
LLM이 각 문장을 분석하여 검증 가능한 사실적 내용이 있는지 판별한다. 세 가지 옵션 중 하나를 선택한다:
예를 들어 "AI 기술의 발전은 놀라운데, 한국의 AI 특허 출원 건수는 2024년에 1만 건을 넘었다"라는 문장에서:
이 단계가 Claimify를 기존 모든 방법과 구별짓는 핵심이다. 기존 방법들은 모호성을 무시하거나, 항상 해결 가능하다고 가정했다. Claimify는 두 가지 유형의 모호성을 명시적으로 처리한다:
단어나 구가 무엇을 가리키는지 불분명한 경우다.
문법 구조 때문에 여러 해석이 가능한 경우다.
Claimify는 맥락(질문 + 앞뒤 문장)을 활용해 모호성을 해소한다. 만약 맥락으로도 해소할 수 없다면, "해소 불가"로 표시하고 해당 문장을 제외한다. 이것이 핵심이다 — 해석이 불분명한 문장을 억지로 쪼개면 원문의 의미를 왜곡할 수 있기 때문이다.
모호성이 해소된 문장을 독립적으로 검증 가능한 원자적 주장으로 분해한다.
대괄호 표기법은 "markup-and-mask" 방식이라 불린다. 맥락에서 추론한 정보를 명시적으로 표시하여, 이 부분의 신뢰도가 낮을 수 있음을 알려준다. 이는 기존 방법들에서는 찾아볼 수 없는 투명성이다.
아래 시뮬레이터에서 Claimify의 4단계 파이프라인을 직접 체험해 보자. 예시 문장을 선택하면 각 단계별로 어떻게 주장이 추출되는지 시각적으로 확인할 수 있다.
논문은 BingCheck 데이터셋을 사용했다. Microsoft Copilot(구 Bing Chat)이 생성한 396개의 응답으로 구성되며, 다양한 주제와 질문 유형을 포함한다. 6,490개 문장에 대해 3명의 주석자가 사실적 주장 포함 여부를 레이블링했다.
비교 대상은 5개의 기존 LLM 기반 방법이다:
| 방법 | 특징 | 한계 |
|---|---|---|
| AFaCTA | 프롬프트 앙상블로 분류 | 주장을 추출하지 않고 분류만 |
| Factcheck-GPT | 사실·의견·비주장 분류 | 주장을 추출하지 않고 분류만 |
| VeriScore | 분류+분해+탈맥락화 통합 | 모호성 미처리 |
| DnD | 분해+탈맥락화 통합 | 비사실적 문장 미처리, 모호성 미처리 |
| SAFE | FActScore 분해 + 별도 탈맥락화 | 비사실적 문장 미처리, 모호성 미처리 |
추출된 주장이 원문에 의해 뒷받침되는 비율이다.
Claimify와 VeriScore가 99%로 공동 1위 (통계적 유의차 없음, p=0.145). 나머지 모든 방법은 통계적으로 유의미하게 낮았다 (p<0.001).
문장 수준과 요소 수준 모두에서 Claimify가 최고 정확도를 달성했다.
| 방법 | 문장 정확도 | 문장 Macro F₁ | 요소 정확도 | 요소 Macro F₁ |
|---|---|---|---|---|
| Claimify | 91.8% | 91.2% | 87.9% | 83.7% |
| AFaCTA | 81.6% | 78.7% | — | — |
| VeriScore | 79.0% | 78.9% | 64.7% | 62.5% |
| SAFE | 65.0% | 74.6% | 45.1% | 57.3% |
| DnD | 63.7% | 76.9% | 41.4% | 56.2% |
요소 수준 F₁에서 Claimify(83.7%)가 2위 VeriScore(62.5%)를 21.2%p나 앞섰다. 이는 Claimify가 검증 가능한 내용을 포함하면서 검증 불가능한 내용을 배제하는 능력이 탁월함을 보여준다.
맥락을 충분히 포함하여 팩트체킹 결과를 왜곡하지 않는 비율이다.
특히 주목할 점은 Claimify의 Result 1 비율이 16.3%로 가장 높다는 것이다. Result 1은 주장이 이미 최대로 탈맥락화되어 있어 추가 맥락이 필요 없는 경우다 — 즉 Claimify가 처음부터 충분한 맥락을 포함한 주장을 만들어낸다.
| 변형 | 수반 | 요소 커버리지 | 탈맥락화 |
|---|---|---|---|
| Claimify (전체) | 99.0% | 83.7% | 80.5% |
| Selection 제거 | 98.0% | 54.4% | 81.1% |
| Selection을 탐지기로만 | 97.7% | 74.7% | 80.2% |
| Disambiguation 제거 | 98.3% | 75.9% | 80.9% |
Selection 단계를 제거하면 요소 커버리지가 83.7% → 54.4%로 급락한다. 이는 검증 가능성을 사전에 필터링하는 것이 얼마나 중요한지 보여준다. Disambiguation 단계도 커버리지에 유의미한 기여를 한다(75.9% → 83.7%).
2026년 현재, AI가 생성한 콘텐츠는 우리 일상에 깊이 침투해 있다. 뉴스 요약, 법률 자문, 의료 정보, 학술 연구 — AI 출력물의 사실성 검증은 더 이상 선택이 아니라 필수다.
논문은 솔직하게 현재의 한계도 인정한다:
Steven Schwartz 변호사의 사건으로 돌아가자. 만약 그가 Claimify 같은 시스템을 사용했다면 어떻게 되었을까?
$5,000 벌금도, 경력의 오점도 없었을 것이다.
AI 팩트체킹의 핵심은 결국 '분해'에 있다. 긴 텍스트를 작은 주장으로 쪼개고, 각각을 독립적으로 검증하는 것. 이 논문은 그 '분해'의 품질을 어떻게 측정하고 개선할 수 있는지에 대한 첫 번째 체계적 답을 제시했다.
AI를 100% 신뢰할 수는 없다. 하지만 AI가 말한 것의 어디까지가 사실인지 정확히 알 수 있다면 — 그것만으로도 충분히 강력하다.
"완벽한 AI를 만드는 것보다, AI의 출력을 정확히 검증하는 기술을 만드는 것이 더 현실적이고 더 중요하다."
📄 원문 논문: Dasha Metropolitansky, Jonathan Larson. "Towards Effective Extraction and Evaluation of Factual Claims." Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), pages 6996–7045.
🔗 데이터셋: https://aka.ms/claimify-dataset