"텍스트 한 줄로 그림을 그린다고요?"
2022년 여름, 세상이 뒤집어졌습니다.
"우주에서 말을 타는 우주비행사를 유화 스타일로" — 이 한 문장을 입력하면, AI가 몇 초 만에 실제로 그럴듯한 그림을 만들어냈습니다. DALL-E 2, Midjourney, Stable Diffusion이 연달아 공개되면서, "AI가 그림을 그린다"는 것이 더 이상 SF가 아닌 현실이 되었습니다.
이 모든 서비스의 심장에 같은 기술이 뛰고 있습니다: 디퓨전 모델(Diffusion Model).
이 글은 GAN, 오토인코더, VAE를 다뤘던 생성 모델 시리즈의 완결편입니다. 앞선 모델들의 한계를 디퓨전이 어떻게 극복했는지, 그리고 왜 2025년 현재 AI 이미지·영상 생성의 절대 강자가 되었는지를 풀어봅니다.
1. 디퓨전의 탄생: 열역학에서 온 영감
물리학에서 빌려온 아이디어
"디퓨전(Diffusion)"은 원래 물리학 용어입니다. 잉크 한 방울을 물에 떨어뜨리면, 잉크 분자가 서서히 퍼져나가 결국 균일한 색이 됩니다. 이것이 확산(diffusion)입니다.
잉크 한 방울
(구조가 있는 상태)
→
점점 퍼짐
(구조가 흐려짐)
→
완전히 퍼짐
(균일 = 노이즈)
2015년, 솔-딕스타인 등(Sohl-Dickstein et al., "Deep Unsupervised Learning using Nonequilibrium Thermodynamics")은 이 물리 현상을 뒤집어서 생각합니다:
"잉크가 퍼지는 과정(정방향)은 쉽다. 그렇다면 퍼진 잉크를 다시 모으는 과정(역방향)을 학습시킬 수 있지 않을까?"
이 비평형 열역학에서 영감을 받은 아이디어가 디퓨전 모델의 기원입니다. 하지만 2015년 논문은 이론적 가능성을 보여준 수준이었고, 실용적인 성능은 아직 먼 이야기였습니다.
DDPM: 진짜 혁명의 시작 (2020)
5년 뒤, 호 등(Ho, Jain & Abbeel)이 "Denoising Diffusion Probabilistic Models"(NeurIPS 2020)을 발표합니다. 줄여서 DDPM.
이 논문이 보여준 것: 디퓨전 모델이 GAN에 필적하는 이미지 품질을 달성할 수 있다.
DDPM은 아이디어를 놀랍도록 단순하게 만들었습니다:
"이미지에 노이즈를 조금씩 더하는 과정을 뒤집어서, 노이즈에서 이미지를 복원하는 법을 학습한다."
이게 전부입니다. 정말로.
2. 작동 원리: 파괴하고, 되살리다
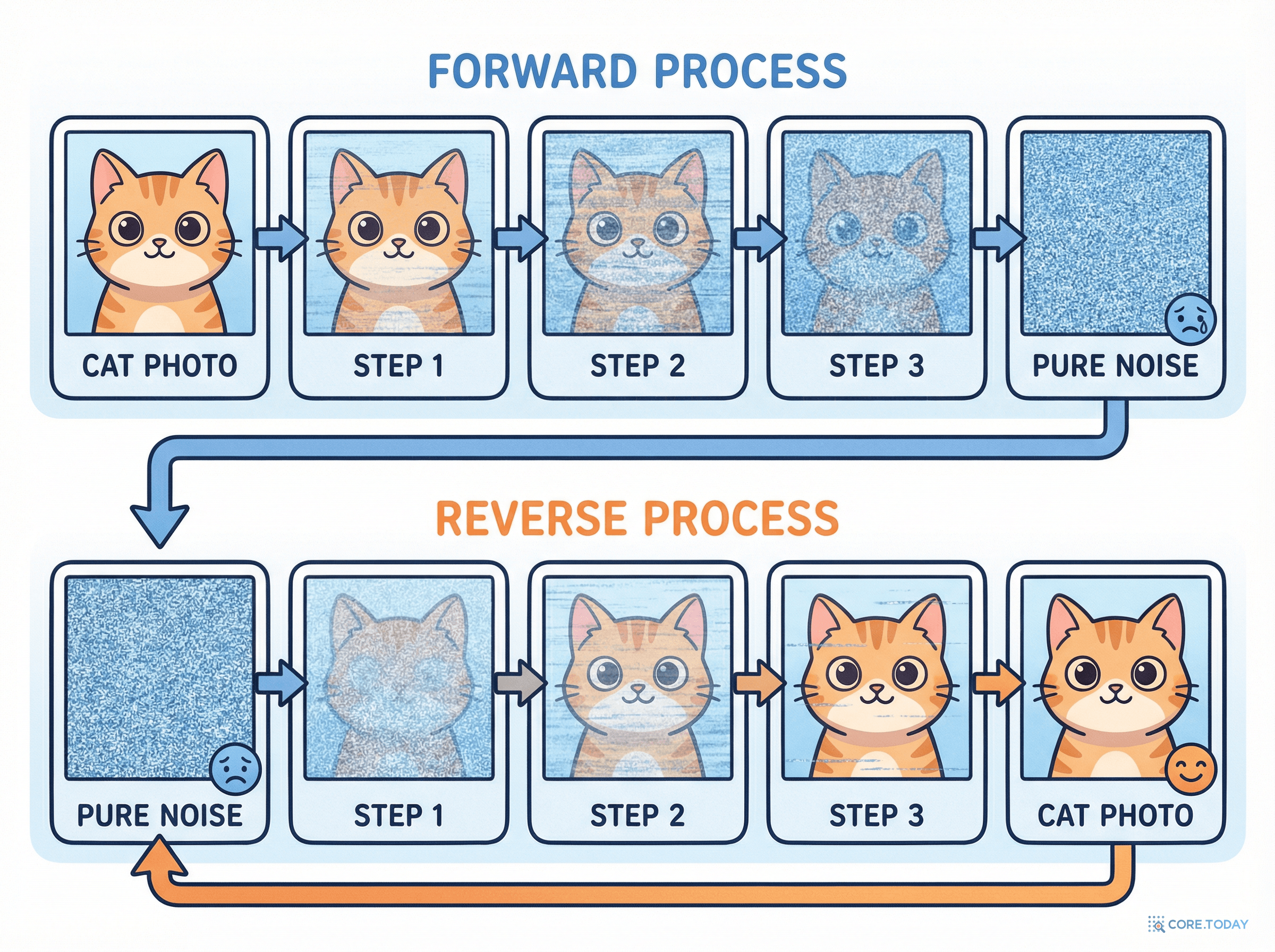
정방향 과정: 이미지를 천천히 파괴하기
고양이 사진 하나를 가져옵니다. 여기에 아주 작은 가우시안 노이즈를 추가합니다. 한 번, 두 번, 세 번... 이것을 T번(보통 1,000번) 반복합니다.
t = 0
선명한 고양이 사진 🐱
t = 250
약간 흐릿한 고양이... 아직 알아볼 수 있음
t = 500
뿌옇고 형체가 흐려짐... 고양이인 것 같기도?
t = 750
거의 노이즈... 뭔지 모르겠음
t = 1000
완전한 가우시안 노이즈 (백색 소음) 📺
수학적으로:
q(xₜ | xₜ₋₁) = N(xₜ; √(1-βₜ) · xₜ₋₁, βₜ · I)
각 단계에서 이전 이미지에 살짝 노이즈를 섞는 것입니다. βₜ는 각 단계의 노이즈 양을 결정하는 스케줄입니다.
핵심: 이 과정은 학습이 필요 없습니다. 그냥 노이즈를 더하는 것뿐이니까요. 수학 공식으로 정확히 계산할 수 있습니다.
역방향 과정: 노이즈에서 이미지를 복원하기
진짜 마법은 여기서 일어납니다. 신경망이 "이전 단계는 어땠을까?"를 학습합니다.
t = 1000
완전한 노이즈에서 시작 📺
t = 750
신경망: "이 노이즈 패턴을 보니... 뭔가 둥근 형체가 있었을 것 같아" → 노이즈 살짝 제거
t = 500
신경망: "이 형체를 보니... 동물 같은데? 귀가 있었을 것 같아" → 노이즈 더 제거
t = 250
신경망: "고양이네! 털 색은 이랬을 것 같아" → 디테일 복원
t = 0
선명한 고양이 사진 복원! 🐱
비유: 모래에 묻힌 조각상을 발굴하는 고고학자입니다. 한 번에 모래를 확 걷어내는 게 아니라, 조심스럽게 한 층씩 제거하며 형태를 드러냅니다. 각 단계에서 "여기는 더 파도 될 것 같고, 여기는 조심해야 할 것 같은데..."를 판단하는 것이 바로 신경망의 역할입니다.
실제로 학습하는 것: 노이즈 예측
DDPM의 가장 우아한 부분 — 신경망이 직접 "깨끗한 이미지"를 예측하는 것이 아니라, "이 단계에서 추가된 노이즈가 무엇인지"를 예측합니다.
hljs language-python
for images in dataloader:
t = torch.randint(0, T, (batch_size,))
noise = torch.randn_like(images)
noisy_images = add_noise(images, noise, t)
predicted_noise = model(noisy_images, t)
loss = MSE(noise, predicted_noise)
loss.backward()
6줄의 핵심 로직. GAN의 복잡한 적대적 학습, VAE의 ELBO 최적화에 비하면 놀라울 정도로 단순합니다.
🔍 왜 노이즈를 예측하는 게 이미지를 예측하는 것보다 나은가요? (눌러서 펼치기)
직관적으로: 노이즈를 예측하는 것이 더 안정적입니다.
이미지 자체를 예측하면, 모델은 전체 픽셀의 값을 맞춰야 합니다. 하지만 노이즈를 예측하면, "원래 이미지에서 무엇이 변했는지"만 맞추면 됩니다 — 이것은 잔차(residual)를 학습하는 것이고, 딥러닝에서 잔차 학습이 더 효과적이라는 것은 ResNet(2015)에서 이미 증명된 사실입니다.
수학적으로도, 노이즈 예측이 ELBO(증거 하한)를 최대화하는 것과 동치임이 호(Ho et al.)의 논문에서 증명됩니다.
3. U-Net: 디퓨전의 눈과 손
디퓨전 모델에서 노이즈를 예측하는 신경망으로 U-Net 아키텍처가 사용됩니다. 원래 의료 이미지 분할을 위해 론네버거 등(Ronneberger et al., 2015)이 만든 이 구조가 디퓨전의 핵심이 된 이유가 있습니다:
인코더 (다운샘플링):
64×64 → 32×32 → 16×16 → 8×8
이미지를 점점 작게 만들며 "뭐가 있는지" 파악
병목:
8×8에서 전체적인 맥락 이해
디코더 (업샘플링):
8×8 → 16×16 → 32×32 → 64×64
다시 키우면서 "어디에 뭐가 있는지" 복원
스킵 연결 (U 모양의 핵심):
인코더의 각 층이 디코더의 대응 층에 직접 연결
→ 전체적 구조 + 세밀한 디테일 모두 활용
U-Net에 시간 임베딩(t)을 함께 주입하여, "지금 몇 번째 단계인지"에 따라 다르게 동작합니다. 초기 단계(t가 큰)에서는 전체적 형태를, 후기 단계(t가 작은)에서는 세밀한 디테일을 다룹니다.
4. 조건부 생성: "우주에서 말 타는 우주비행사"

기본 디퓨전은 랜덤 이미지를 생성합니다. 하지만 우리가 원하는 건 원하는 이미지죠. "고양이" 또는 "우주에서 말을 타는 우주비행사"처럼요.
CLIP: 텍스트와 이미지를 연결하는 다리
래드포드 등(Radford et al., "Learning Transferable Visual Models From Natural Language Supervision", 2021)의 CLIP(Contrastive Language-Image Pre-training)은 텍스트와 이미지를 같은 벡터 공간에 매핑합니다.
"고양이가 모자를 쓰고 있다"
(텍스트)
→
CLIP
같은 벡터 공간에 매핑
←
고양이+모자 사진
(이미지)
의미적으로 일치하는 텍스트-이미지 쌍은 벡터 공간에서 가까이, 일치하지 않는 쌍은 멀리 배치됩니다. 이 연결 고리가 "텍스트로 이미지를 생성하는" 조건부 디퓨전의 핵심입니다.
Classifier-Free Guidance: 방향을 더 강하게
호와 살리만스(Ho & Salimans, 2022)의 Classifier-Free Guidance(CFG)는 생성 품질을 극적으로 향상시킨 기법입니다:
CFG = 1.0: 프롬프트를 약하게 반영 → 다양하지만 관련 없는 이미지도 나옴
CFG = 7.0: 적당한 균형 → 대부분의 서비스 기본값
CFG = 15.0: 프롬프트를 강하게 반영 → 정확하지만 과포화/부자연스러움
CFG = 30.0+: 극단적 반영 → 인위적, 색이 넘침
Stable Diffusion, DALL-E, Midjourney 모두 이 파라미터를 사용합니다.
원리는 간단합니다: 조건부 예측과 무조건부 예측의 차이를 증폭합니다. "프롬프트가 있을 때와 없을 때의 차이"가 클수록, 프롬프트를 더 강하게 따르는 이미지가 생성됩니다.
5. 디퓨전의 진화: DALL-E에서 Sora까지
Latent Diffusion / Stable Diffusion (2022)
롬바흐 등(Rombach et al.)의 혁신은 단순하지만 결정적이었습니다: 이미지 공간이 아니라 잠재 공간에서 디퓨전을 수행한다.
!
문제
512×512 이미지에서 직접 디퓨전 → GPU 메모리와 시간이 막대함
→
해결
VAE로 512×512 → 64×64 잠재 공간에 압축 (64배 작아짐!)
이 작은 잠재 공간에서 디퓨전 수행 → 계산 비용 대폭 절감
✓
결과
소비자급 GPU(RTX 3090)에서도 고품질 이미지 생성 가능!
→ Stable Diffusion 오픈소스 공개 → 대중화 폭발
이것이 바로 이전 글들(오토인코더, VAE)에서 다룬 기술이 여기서 합류하는 지점입니다:
VAE 인코더
(이미지 → 잠재 표현)
→
U-Net 디퓨전
(잠재 공간에서
노이즈 추가/제거)
→
VAE 디코더
(잠재 표현 → 이미지)
+ CLIP 텍스트 인코더 (프롬프트 → 벡터) + Classifier-Free Guidance
주요 서비스 타임라인
Stable Diffusion (2022.08)
DiT: U-Net에서 트랜스포머로 (2023~)
페블 등(Peebles & Xie, "Scalable Diffusion Models with Transformers", 2023)의 DiT(Diffusion Transformer)는 디퓨전의 백본을 U-Net에서 트랜스포머로 교체합니다. 트랜스포머의 스케일링 법칙이 디퓨전에도 적용됨을 보여줬고, Sora를 포함한 최신 모델들의 기반이 됩니다.
Sora: 이미지를 넘어 영상으로 (2024)
OpenAI의 Sora는 디퓨전 모델을 영상 생성으로 확장합니다. "도쿄 거리를 걷는 여성" 같은 프롬프트로 60초 길이의 사실적인 영상을 생성합니다.
핵심: Sora는 영상을 시공간 패치(spacetime patch)로 분할하여 DiT로 처리합니다. 개별 프레임이 아니라 시간을 포함한 3D 구조를 학습하므로, 프레임 간 일관성이 자연스럽게 보장됩니다.
6. 왜 디퓨전이 GAN을 이겼나
이전 글에서 GAN의 한계를 다뤘습니다. 디퓨전이 그 한계를 어떻게 극복했는지 정리합니다.
모드 붕괴
하나의 이미지만 반복 생성
없음
확률 과정이므로 매번 다른 결과
학습 불안정
생성자-판별자 균형 붕괴
안정적
단순 노이즈 예측, 균형 불필요
텍스트 조건 생성 어려움
조건부 GAN은 복잡하고 불안정
자연스러움
CLIP + CFG로 텍스트 조건 우아하게 통합
스케일링 한계
모델/데이터 키워도 개선 불확실
스케일링 법칙 적용
더 큰 모델 = 더 좋은 결과 (DiT)
남은 약점: 속도
디퓨전의 유일한 명확한 약점은 생성 속도입니다. GAN이 한 번의 순전파로 이미지를 생성하는 반면, 디퓨전은 수십~수백 번의 반복이 필요합니다.
이 문제를 해결하기 위한 연구들:
| 기법 | 접근법 | 효과 |
|---|
| DDIM (Song et al., 2020) | 비확률적 샘플링으로 단계 축소 | 1000 → 50 단계 |
| DPM-Solver (Lu et al., 2022) | 고차 ODE 솔버 적용 | 1000 → 10~20 단계 |
| Consistency Models (Song et al., 2023) | 한 번에 깨끗한 이미지 예측 학습 | 1~2 단계! |
| SDXL Turbo / LCM (2023) | 지식 증류 + 적대적 학습 | 1~4 단계 |
2025년 현재, Stable Diffusion은 4단계 만에 고품질 이미지를 생성할 수 있어, 실시간 생성도 가능해졌습니다.
7. 글로벌 논란: AI 이미지와 사회의 충돌

디퓨전 모델의 폭발적 대중화는 전례 없는 사회적 논쟁을 불러왔습니다.
저작권 전쟁
Getty Images vs Stability AI (2023~)
Getty Images는 Stable Diffusion이 자사의 저작권 있는 이미지 수백만 장을 학습 데이터로 무단 사용했다며 소송합니다. 일부 생성 이미지에서 Getty의 워터마크가 흐릿하게 나타나는 것이 증거로 제시됩니다.
뉴욕타임스 vs OpenAI (2023~)
뉴욕타임스는 ChatGPT와 DALL-E의 학습에 자사 기사가 사용되었다고 소송합니다. AI 학습에서의 공정 이용(fair use) 범위가 핵심 쟁점이며, 2025년 현재까지 진행 중입니다.
아티스트의 반발
ArtStation, DeviantArt 등의 플랫폼에서 아티스트들이 대규모 항의를 벌입니다. "내 수십 년의 노력이 담긴 작품이 AI 학습에 동의 없이 사용되었다"는 것이 핵심 주장입니다. Glaze, Nightshade 같은 작품 보호 도구가 등장하기도 합니다.
가짜 이미지의 범람
교황 패딩 사진 (2023.03)
AI로 생성된 "교황 프란치스코가 흰색 패딩을 입은 사진"이 소셜미디어에서 바이럴됩니다. 수백만 명이 진짜라고 믿었고, AI 생성 이미지의 사회적 위험성을 전 세계에 각인시킨 사건입니다.
선거와 딥페이크 (2024)
2024년 미국, 한국, 인도 등의 선거에서 AI로 생성된 후보자 이미지/음성이 유포됩니다. 정치적 맥락에서의 AI 생성 콘텐츠 규제가 시급한 과제로 떠오릅니다.
대응: 규제와 기술적 해법
EU AI Act (2024)
AI 생성물에 라벨링 의무화
C2PA 표준
이미지 출처 메타데이터
Adobe·MS·Intel 주도
워터마킹
Google SynthID 등
보이지 않는 워터마크
8. 생성 모델 시리즈 총정리: VAE → GAN → 디퓨전

이 시리즈에서 다룬 네 가지 생성 모델을 최종 비교합니다.
| 항목 | AE | VAE | GAN | 디퓨전 |
|---|
| 핵심 원리 | 압축→복원 | 확률적 압축→생성 | 생성자 vs 판별자 | 노이즈 추가→제거 |
| 이미지 품질 | 낮음 | 중간 (흐릿) | 높음 | 매우 높음 |
| 생성 다양성 | — | 높음 | 낮음 (모드 붕괴) | 높음 |
| 학습 안정성 | 안정 | 안정 | 불안정 | 매우 안정 |
| 생성 속도 | 빠름 | 빠름 | 빠름 | 느림 (개선 중) |
| 텍스트→이미지 | 불가 | 제한적 | 제한적 | 탁월 |
| 2025 위치 | 디퓨전의 압축기 | 디퓨전의 잠재공간 | 실시간/초해상도 | 절대 주류 |
핵심 인사이트: 이 네 가지는 서로 경쟁하는 게 아니라, 결국 하나로 합쳐졌습니다. 2025년의 Stable Diffusion은 VAE(잠재 공간) + 디퓨전(생성) + 트랜스포머(백본) + CLIP(텍스트 이해)의 합작품입니다. 과거의 아이디어가 버려진 것이 아니라, 더 큰 시스템의 부품이 된 것입니다.
9. 2025년 그리고 그 너머
현재 최전선
🖼️ 이미지 → 해결
Stable Diffusion, DALL-E 3, Midjourney v6
→ 사실상 사진 수준의 품질 달성
남은 과제: 손가락, 텍스트 렌더링
🎬 영상 → 급성장
Sora, Runway Gen-3, Kling
→ 60초 고품질 영상 생성 가능
남은 과제: 물리 법칙 일관성
🌐 3D/세계 모델 → 초기
Point-E, Shap-E, 3D 디퓨전
→ 텍스트에서 3D 오브젝트 생성
남은 과제: 품질, 속도, 편집성
디퓨전이 바꾸고 있는 것
- 창작의 민주화 — 전문 일러스트레이터가 아니어도 머릿속 이미지를 시각화할 수 있습니다
- 콘텐츠 제작 비용 혁명 — 스톡 사진, 광고 이미지, 게임 에셋 제작 비용이 급감합니다
- 과학적 발견 — 분자 설계, 단백질 구조, 재료 과학에서 디퓨전 기반 생성이 활용됩니다
- 진실의 위기 — "보는 것을 믿는다"는 전제가 흔들리며, 새로운 미디어 리터러시가 필요합니다
마무리: 노이즈에서 의미를 찾다
2013 — VAE
"확률로 이해하고 생성하자"
흐릿하지만, 잠재 공간이라는 개념을 열었다
2014 — GAN
"경쟁으로 진짜처럼 만들자"
선명하지만, 불안정하고 다양성이 부족했다
2020 — 디퓨전
"파괴를 되돌려 생성하자"
품질, 다양성, 안정성을 모두 잡았다
디퓨전 모델의 핵심 철학은 역설적입니다:
"아름다운 것을 만들려면, 먼저 파괴하는 법을 배워라."
이미지에 노이즈를 더해 완전히 파괴하는 과정을 이해하면, 그 역과정 — 노이즈에서 이미지를 복원하는 것 — 도 가능해집니다. 이 단순하고 우아한 아이디어가 2025년 AI 이미지·영상 생성의 모든 것을 뒤바꿨습니다.
VAE가 잠재 공간을, GAN이 선명함을, 디퓨전이 안정성과 품질을 가져왔고, 결국 이 모든 것이 합쳐져 "텍스트 한 줄로 상상을 시각화하는" 세상을 만들었습니다.
그리고 이 여정은 아직 끝나지 않았습니다. 이미지에서 영상으로, 영상에서 3D로, 3D에서 세계 시뮬레이션으로 — 디퓨전 모델은 계속 진화하고 있습니다.
모래에 묻힌 걸작을 발굴하듯, 한 겹씩 노이즈를 걷어내면 — 거기에 있던 것은 처음부터 아름다웠습니다.
참고 논문 및 자료
- Sohl-Dickstein, J. et al. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. ICML.
- Ronneberger, O. et al. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI.
- Ho, J., Jain, A. & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS.
- Song, J., Meng, C. & Ermon, S. (2020). Denoising Diffusion Implicit Models (DDIM). ICLR.
- Radford, A. et al. (2021). Learning Transferable Visual Models From Natural Language Supervision (CLIP). ICML.
- Dhariwal, P. & Nichol, A. (2021). Diffusion Models Beat GANs on Image Synthesis. NeurIPS.
- Rombach, R. et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR.
- Ho, J. & Salimans, T. (2022). Classifier-Free Diffusion Guidance. NeurIPS Workshop.
- Lu, C. et al. (2022). DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling. NeurIPS.
- Peebles, W. & Xie, S. (2023). Scalable Diffusion Models with Transformers (DiT). ICCV.
- Song, Y. et al. (2023). Consistency Models. ICML.
- Brooks, T. et al. (2024). Video generation models as world simulators (Sora). OpenAI Technical Report.