법률 문서, 왜 아직도 PDF인가?
2026년 현재, 우리는 AI에게 코드를 짜달라고 하고, 논문을 요약하라고 하며, 심지어 영화 각본까지 쓰게 합니다. 그런데 정작 우리 삶을 지배하는 법률 문서는 어떨까요?
충격적인 현실: 전 세계 대부분의 법률은 여전히 PDF나 스캔된 이미지, 심지어 종이 문서로만 존재합니다. AI가 법률을 "읽으려면" 먼저 이 비정형 텍스트를 파싱해야 하는데, 법률 특유의 복잡한 참조 구조와 개정 이력을 정확히 파악하기란 거의 불가능합니다.
예를 들어 봅시다. "민법 제750조에 의한 손해배상 청구 시, 같은 법 제763조가 준용하는 제393조 제1항의 통상손해..."
사람도 따라가기 어려운 이 참조의 미로를, 기계는 어떻게 이해해야 할까요?
바로 이 문제를 해결하기 위해 탄생한 것이 Akoma Ntoso(아코마 은토소)입니다. 아프리카 가나의 아칸어로 "연결된 마음(Linked Hearts)"이라는 뜻을 가진 이 XML 표준은, 법률 문서를 기계가 이해할 수 있는 구조화된 데이터로 변환하는 혁명적인 시도입니다.
1. 탄생: 아프리카의 "연결된 마음"에서 시작되다
아프리카 의회의 투명성 위기
2000년대 초반, 아프리카 대륙의 많은 의회들은 심각한 정보 격차에 직면해 있었습니다. 법률 문서가 체계적으로 관리되지 않았고, 시민들은 자국의 법이 무엇인지조차 쉽게 알 수 없었습니다. 의회 간 법률 정보를 교환하는 것도 사실상 불가능했죠.
2004년, UN/DESA(유엔 경제사회국)는 이 문제를 해결하기 위해 "아프리카 의회 정보 시스템 강화(Africa i-Parliaments Action Plan)" 프로젝트를 시작합니다. 목표는 명확했습니다: ICT를 활용해 아프리카 의회의 투명성과 책임성을 높이자.
볼로냐 대학교의 두 교수
이 프로젝트의 기술적 핵심을 설계한 사람은 이탈리아 볼로냐 대학교의 모니카 팔미라니(Monica Palmirani) 교수와 파비오 비탈리(Fabio Vitali) 교수였습니다. CIRSFID(법학사·법철학·법사회학 연구소) 소속이었던 두 교수는 법률 문서의 디지털 표현에 대한 깊은 전문성을 갖고 있었죠.
이름의 의미: Akoma Ntoso는 서아프리카 가나의 아칸어로 "연결된 마음"을 뜻합니다. 동시에 교묘한 역(逆)두문자어(backronym)이기도 합니다: Architecture for Knowledge-Oriented Management of African Normative Texts using Open Standards and Ontologies. 아프리카의 마음을 연결하겠다는 비전과, 기술적 정의를 동시에 담은 이름입니다.
22년의 여정: UN 프로젝트에서 국제 표준으로
2004
UN/DESA 아프리카 i-Parliaments 프로젝트 내에서 탄생
2007
최초의 AKN 기반 법률 편집기 개발 (OpenOffice 기반)
2010
유럽의회, AT4AM 수정안 도구에 AKN 채택 — 유럽 진출
2012
UN에서 OASIS로 이관, LegalDocML 기술위원회 발족
2014
영국, 전체 법률을 AKN으로 변환 — 오픈데이터 1위 달성
2018
Akoma Ntoso v1.0, OASIS 공식 표준으로 채택 (8월 30일)
2022~
스위스·독일·일본 채택, AI와의 결합 본격화
아프리카 의회의 투명성 프로젝트로 시작된 Akoma Ntoso는, 14년간의 실전 검증을 거쳐 2018년 8월 30일 OASIS 국제 표준으로 공식 채택되었습니다. 아프리카의 한 프로젝트에서 시작해 유럽, 미국, 아시아까지 퍼진 것입니다.
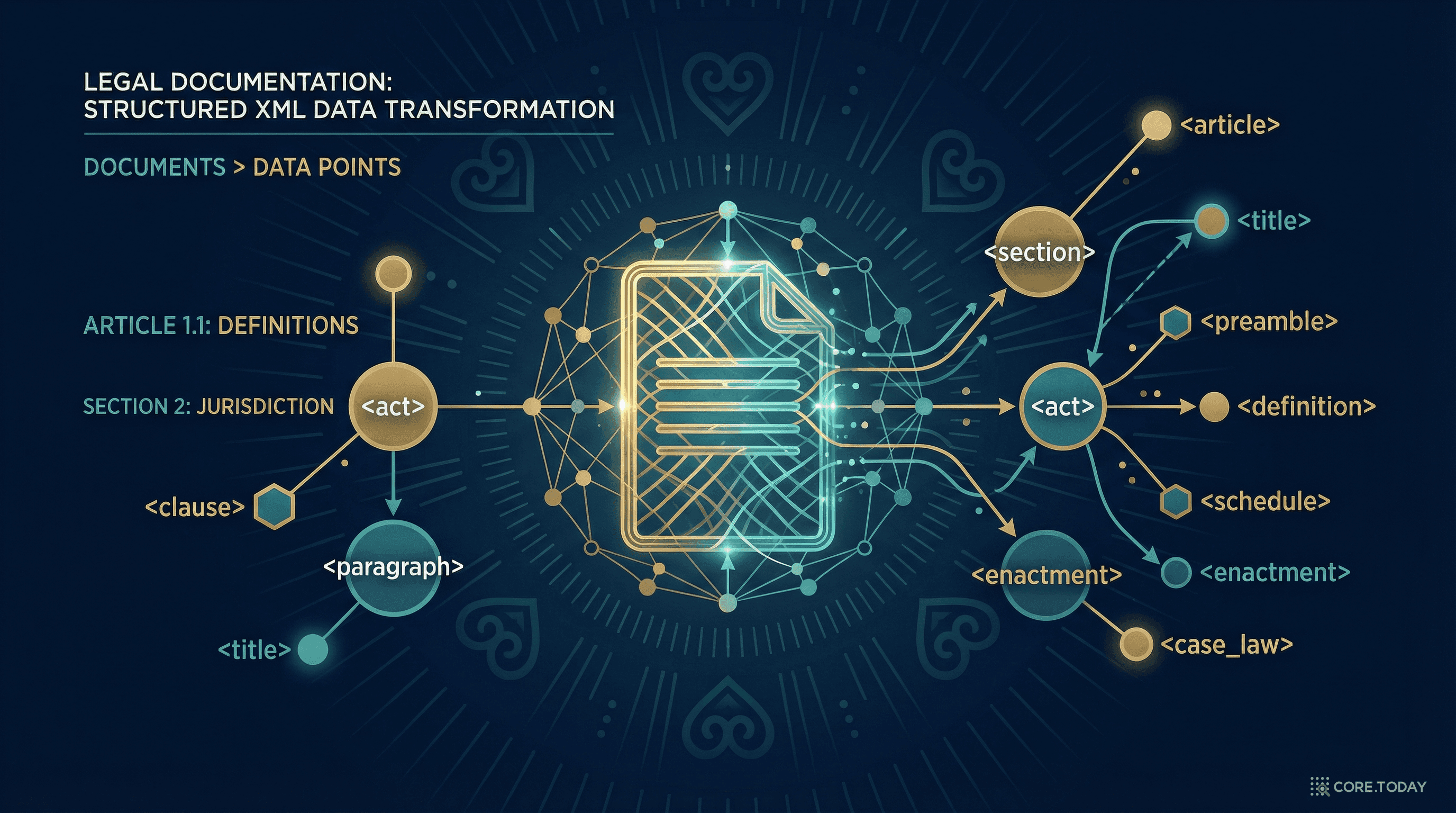
2. 핵심 아이디어: "법률을 데이터로"
법률 문서의 3중 분리 원칙
Akoma Ntoso의 가장 근본적인 설계 철학은 3중 분리(Three-layer Separation)입니다:
📝 콘텐츠(Content)
입법자가 작성한 원본 텍스트 — 법의 권위 있는 내용 그 자체
🏗️ 구조(Structure)
편(Part), 장(Chapter), 조(Article), 항(Paragraph) 등의 계층적 조직
🏷️ 메타데이터(Metadata)
제정일, 개정 이력, 관련 기관, 분류 — 비권위적 편집 정보
이 분리가 왜 중요할까요? PDF 파일 하나에 모든 것이 뒤섞여 있으면, 기계는 "제1조"라는 글자가 법률의 구조인지, 본문 내용인지, 아니면 다른 법률에 대한 참조인지 구분할 수 없습니다. 3중 분리를 통해 각 층위가 독립적으로 처리 가능해집니다.
XML로 표현하면 이렇습니다
법률 조항 하나가 Akoma Ntoso XML에서 어떻게 표현되는지 봅시다:
hljs language-xml
<akomaNtoso xmlns="http://docs.oasis-open.org/legaldocml/ns/akn/3.0">
<act name="civil-code">
<meta>
<identification source="#source">
<FRBRWork>
<FRBRthis value="/akn/kr/act/민법/1958-02-22/법률제471호"/>
<FRBRdate date="1958-02-22" name="enactment"/>
<FRBRauthor href="#국회"/>
</FRBRWork>
</identification>
</meta>
<body>
<article eId="art_750">
<num>제750조</num>
<heading>불법행위의 내용</heading>
<content>
<p>고의 또는 과실로 인한 위법행위로 타인에게
손해를 가한 자는 그 손해를 배상할 책임이 있다.</p>
</content>
</article>
</body>
</act>
</akomaNtoso>
<article>, <num>, <heading>, <content> — 각 요소가 의미적으로 명확하게 구분됩니다. 기계는 이제 "제750조"가 조문 번호이고, "불법행위의 내용"이 해당 조의 제목이며, 그 아래가 본문 내용이라는 것을 정확히 이해할 수 있습니다.
3. 문서 유형: 법률만이 아니다
Akoma Ntoso가 강력한 이유 중 하나는 다양한 법률 문서 유형을 모두 포괄한다는 점입니다. 단순히 법률(Act)만 다루는 게 아닙니다.
| 카테고리 | 문서 유형 | 설명 | 실제 예시 |
|---|
| 계층형 | <act>, <bill> | 법률·법안 (편→장→절→조 구조) | 민법, 형법, 국회 계류 법안 |
| 회의록 | <debate> | 의회 토론·회의 기록 | 국회 본회의 회의록, UN 총회 기록 |
| 판결문 | <judgment> | 법원 판결·결정문 | 대법원 판례, 헌법재판소 결정 |
| 수정안 | <amendment> | 법률 개정 지시 사항 | "제3조 제1항 중 '5년'을 '3년'으로" |
| 모음집 | <officialGazette> | 관보, 문서 컬렉션 | 대한민국 관보, EU 공식 저널 |
| 일반 | <doc>, <statement> | 성명, 보고서, 결의안 | UN 결의안, 정부 성명서 |
왜 회의록과 판결문까지? 법은 진공 속에서 만들어지지 않습니다. 법안이 발의되고(<bill>), 토론되고(<debate>), 수정되고(<amendment>), 제정되고(<act>), 해석되는(<judgment>) 전체 생애주기를 추적해야 법의 의미를 완전히 이해할 수 있습니다. Akoma Ntoso는 이 전체 과정을 하나의 표준으로 아우릅니다.
4. FRBR 모델: 같은 법, 다른 버전
한국의 민법은 1958년에 제정된 이후 수십 차례 개정되었습니다. 2020년의 민법과 2025년의 민법은 "같은 법"이면서도 "다른 법"입니다. 이 복잡한 관계를 어떻게 표현할까요?
Akoma Ntoso는 도서관학의 FRBR(Functional Requirements for Bibliographic Records) 모델을 차용합니다:
Work (작품)
"대한민국 민법"이라는 추상적 개념 그 자체
↓ 하나의 Work → 여러 Expression
Expression (표현)
특정 시점의 특정 언어 버전. "2025년 개정 후 한국어 민법"
↓ 하나의 Expression → 여러 Manifestation
Manifestation (구현)
물리적 형태. XML 파일, PDF, 인쇄본
↓ 하나의 Manifestation → 여러 Item
Item (아이템)
특정 서버의 특정 파일. 법제처서버/민법_2025.xml
이 4단계 모델 덕분에 "2020년 3월 시점의 민법 제750조는 어떤 내용이었나?"라는 시간 여행 질문에도 정확하게 답할 수 있습니다. 각 개정 버전이 별도의 Expression으로 관리되기 때문이죠.
IRI 명명 규칙: 법률의 GPS 좌표
모든 법률 문서에 전 세계적으로 유일한 주소를 부여하는 것이 IRI(Internationalized Resource Identifier) 명명 규칙입니다:
Work IRI (어떤 법률인가?)
/akn/{관할권}/{문서유형}/{하위유형}/{기관}/{날짜}/{번호}
Expression IRI (어떤 버전·언어인가?)
{Work IRI}/{언어}@{버전날짜}
Manifestation IRI (어떤 형식인가?)
{Expression IRI}/{파일명}.{형식}
예를 들어, 대한민국 민법의 IRI는 이렇게 구성될 수 있습니다:
Work: /akn/kr/act/민법/1958-02-22/법률제471호
Expression (2025년 한국어): /akn/kr/act/민법/.../kor@2025-01-15
Manifestation (XML): /akn/kr/act/민법/.../kor@2025-01-15/main.xml
→ 어떤 나라의, 어떤 종류의, 어떤 버전의, 어떤 형식의 문서인지 IRI만 보면 알 수 있습니다.
5. 메타데이터: 법률의 DNA
Akoma Ntoso의 <meta> 블록은 법률 문서의 DNA와 같습니다. 무려 11개 영역에 걸쳐 문서의 모든 맥락 정보를 기록합니다:
🔍 식별(Identification)
문서 IRI, 날짜, 저작자
📰 공포(Publication)
관보 정보, 공식 지위
🏷️ 분류(Classification)
키워드, 법률 분류 체계
🔄 생애주기(Lifecycle)
제정→개정→폐지의 이벤트 기록
⚙️ 워크플로(Workflow)
발의→위원회→본회의 입법 절차
🔬 분석(Analysis)
능동적·수동적 수정 관계, 적용 조건
⏱️ 시간 데이터(Temporal)
시행일, 효력 기간, 경과 규정
🔗 참조(References)
외부 자료, 관련 문서, 온톨로지 매핑
📝 주석(Notes)
편집 주석, 각주, 해설
Top Level Classes: 법률 세계의 온톨로지
메타데이터 참조를 위해 14개의 Top Level Classes(TLC)가 정의되어 있습니다:
| TLC | 의미 | 예시 |
|---|
TLCPerson | 개인 | 법안 발의 의원, 판사 |
TLCOrganization | 조직 | 국회, 대법원, 법제처 |
TLCConcept | 추상 개념 | "과실", "선의의 제3자" |
TLCEvent | 사건 | 제정, 개정, 공포 |
TLCLocation | 장소 | 관할 지역, 법원 소재지 |
TLCRole | 역할 | 의장, 위원장, 재판장 |
TLCTerm | 용어 | 법률 용어의 정의 |
TLCProcess | 절차 | 입법 절차, 재판 절차 |
TLCObject | 물리적 대상 | 증거물, 문서 |
TLCReference | 외부 참조 | 온톨로지 매핑, 외부 DB 연결 |
각 TLC는 고유 식별자(@eId), 온톨로지 IRI(@href), 표시 레이블(@showAs)을 가집니다. 이를 통해 "이 법률을 발의한 사람은 누구인가?", "이 판결에서 참조된 법률은 무엇인가?"와 같은 질문에 기계적으로 답할 수 있게 됩니다.
6. 전 세계 채택 현황: 지도 위의 Akoma Ntoso
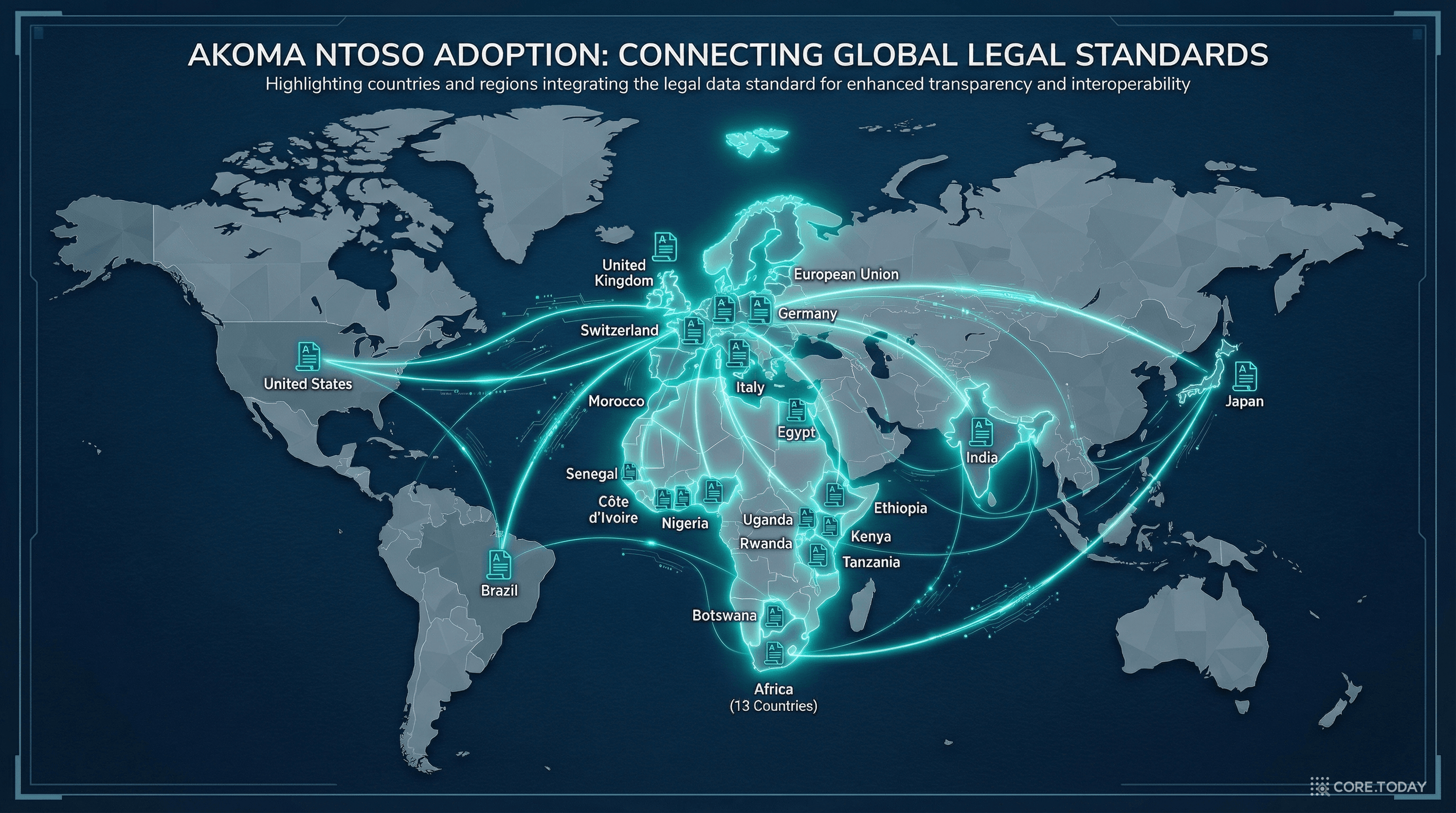
유럽: 가장 적극적인 채택
🇬🇧
영국 — 전체 법률 AKN 변환
2014년, UK National Archives는 모든 법률을 Akoma Ntoso 형식으로 변환했습니다. 결과? 글로벌 오픈데이터 인덱스에서 법률 분야 순위가 4위에서 1위로 급상승. legislation.gov.uk에서 모든 법률의 AKN XML을 API로 제공합니다 (URL 뒤에 /data.akn만 붙이면 됩니다).
🇪🇺
EU — 입법 전 과정에 도입
AT4AM(수정안 작성 도구), LEOS(입법 편집 소프트웨어), AKN4EU(EU 맞춤 프로필 v4.1) 등을 통해 EU 기관 전체에서 법안 작성→토론→수정→공포까지 AKN 기반으로 운영합니다.
🇨🇭
스위스 — 2022년부터 전면 제공
2022년 5월 30일부터 모든 새 공포 문서를 AKN 호환 XML로 다운로드 가능하게 했습니다.
미국: USLM — AKN의 미국 버전
미국은 Akoma Ntoso를 그대로 쓰지 않고, AKN에서 파생된 USLM(United States Legislative Markup)을 개발했습니다. 2013년 미국 의회도서관은 AKN 관련 코딩 챌린지에 $15,000의 상금을 내걸기도 했죠. USLM은 AKN의 "2세대 XML 스키마"로, 미국 법체계에 맞게 확장한 파생 표준입니다.
아프리카: 시작점이자 성장 중인 생태계
Laws.Africa의 Legislation Commons: 보츠와나, 가나, 케냐, 레소토, 말라위, 모리셔스, 나미비아, 나이지리아, 남아공, 탄자니아, 우간다, 잠비아, 짐바브웨 등 13개국의 법률을 AKN XML로 큐레이션하고 있습니다. 특히 케냐는 아프리카에서 유일하게 AKN XML로 법률을 통합·공포까지 하는 나라입니다.
아시아: 새로운 지평
| 국가 | 현황 | 주목할 점 |
|---|
| 인도 🇮🇳 | Nyaaya 프로젝트로 인도법을 AKN XML 변환 | Schematise — LLM 기반 AKN 자동 변환기 개발 |
| 일본 🇯🇵 | JLS→AKN 변환 파이프라인 연구 (2026) | 다국어 임베딩 + FAISS로 법률 간 유사 조항 매칭 |
| 브라질 🇧🇷 | LexML Brasil — AKN 호환 스키마 (2008~) | 포르투갈어 법률 용어 매핑 완료 |
7. 310개의 요소, 69개의 속성: 구조 해부
Akoma Ntoso v3.0은 약 310개의 XML 요소와 69개의 속성을 정의하며, 34개 모듈로 조직됩니다. 이 중 핵심 모듈 하나만 필수이고 나머지는 선택적으로 사용합니다.
6가지 콘텐츠 패턴
모든 요소는 6가지 콘텐츠 패턴 중 하나에 속합니다:
Marker
위치 표시자 — 빈 요소로 특정 지점을 마킹 (예: 각주 참조점)
Inline
텍스트 내 인라인 요소 — 강조, 참조, 날짜 등 (예: <ref>, <date>)
Block
블록 레벨 요소 — 문단, 목록, 표 (예: <p>, <blockList>)
Subflow
문서 내 하위 흐름 — 각주, 인용 (예: <authorialNote>)
Hier. Container
계층적 컨테이너 — 편, 장, 절, 조 (예: <part>, <article>)
Container
범용 컨테이너 — 서문, 부칙 등 (예: <preamble>, <conclusions>)
수정 관계 추적: 법률의 혈통 추적
법률에서 가장 복잡한 부분 중 하나가 수정(Amendment) 관계입니다. "A법 제3조를 B법이 개정한다"와 같은 관계를 AKN의 <analysis> 섹션에서 명시적으로 추적합니다:
hljs language-xml
<analysis>
<activeModifications>
<textualMod type="substitution">
<source href="#art_5"/>
<destination href="/akn/kr/act/민법/...#art_750"/>
<old href="#old_text"/>
<new href="#new_text"/>
</textualMod>
</activeModifications>
</analysis>
능동적 수정(Active): "이 법이 다른 법을 바꾼다"
수동적 수정(Passive): "이 법이 다른 법에 의해 바뀌었다"
이 양방향 추적 덕분에 "민법 제750조는 어떤 법률들에 의해 몇 번 개정되었는가?"라는 질문에 즉각 답할 수 있습니다.
8. 실전 사례: Akoma Ntoso가 빛나는 순간들
사례 1: EU의 입법 혁신 — LEOS

유럽연합의 LEOS(Legislation Editing Open Software)는 Akoma Ntoso의 가장 야심찬 구현체입니다:
❌
문제: EU 입법의 복잡성
27개 회원국, 24개 공식 언어, 수천 명의 관련 인력이 참여하는 EU 입법 과정은 극도로 복잡합니다. 문서 버전 관리, 수정안 추적, 다국어 동기화가 악몽이었죠.
✅
해결: AKN XML 기반 웹 편집기
LEOS는 AKN v3 XML을 기반으로 공동 편집, 버전 관리, 댓글, 제안 기능을 제공합니다. 템플릿 기반으로 구조적 제약을 강제하여 형식 오류를 원천 차단합니다.
🎯
결과: AI 통합으로 입법 시간 80% 단축
2024-2025년 연구에서 AI + LEOS 하이브리드 시스템이 초안 작성 시간을 최대 80% 절감하고, 복잡한 법안의 통합 성공률 60% 이상을 달성했습니다.
사례 2: 영국 legislation.gov.uk
영국의 사례는 "왜 구조화된 법률 데이터가 중요한가?"를 가장 극적으로 보여줍니다:
단 1년 만에, 전체 법률을 AKN으로 변환한 것만으로 글로벌 오픈데이터 법률 분야 1위를 차지했습니다. 지금도 legislation.gov.uk에서 아무 법률 페이지 URL 뒤에 /data.akn을 붙이면 AKN XML을 바로 받을 수 있습니다.
사례 3: Laws.Africa — 아프리카 법률의 디지털 해방
아프리카 13개국의 법률을 AKN XML로 체계화하는 Laws.Africa 프로젝트는, Akoma Ntoso의 원래 비전인 "아프리카 의회의 투명성"을 가장 충실히 실현하고 있습니다.
케냐에서는 AKN XML로 법률을 온라인 공포할 뿐 아니라, 같은 XML에서 인쇄용 관보까지 자동 생성합니다. 하나의 소스, 다양한 출력 — 이것이 3중 분리 원칙의 실질적 위력입니다.
9. 2026년, AI가 법률 XML을 만났을 때
여기서부터가 진짜 흥미로운 이야기입니다. 2026년 현재, LLM과 RAG가 폭발적으로 성장하는 시대에 Akoma Ntoso는 완전히 새로운 가치를 발휘하고 있습니다.
RAG + 구조화된 법률 = 정확한 법률 AI
일반적인 RAG(Retrieval-Augmented Generation)는 텍스트를 임의의 청크로 나누어 벡터 DB에 저장합니다. 하지만 법률 문서에서 이런 접근은 치명적입니다:
| 비교 항목 | 비정형 텍스트 RAG | AKN 구조화 RAG |
|---|
| 청킹 방식 | 글자 수 기반 임의 분할 | 조·항·호 단위 의미적 분할 |
| 참조 추적 | 불가능 — "제763조가 준용하는 제393조" 해석 불가 | 명시적 <ref> 링크로 자동 추적 |
| 시간 여행 | 불가능 — 어느 시점의 버전인지 불명확 | FRBR Expression으로 정확한 시점 검색 |
| 개정 영향 분석 | 불가능 | <analysis> 섹션으로 수정 그래프 탐색 |
| 결과 신뢰성 | 확률적 — 환각(hallucination) 위험 | 결정론적 — 출처 조항까지 추적 가능 |
SAT-Graph RAG: FRBR + 지식 그래프의 위력
2025년 발표된 SAT-Graph RAG 논문은 이 차이를 극적으로 보여줍니다. 브라질 연방헌법(1988년 제정, 100회 이상 개정)을 대상으로:
❌
일반 RAG의 실패
"2010년 시점의 제5조 내용은?"이라는 질문에 일반 RAG는 시대착오적(anachronistic) 결과를 반환 — 현재 버전의 조항을 2010년의 답이라고 제시했습니다.
✅
SAT-Graph RAG의 해결
FRBR의 Expression 개념을 그래프의 1급 노드로 승격시켜, 시간축을 따라 버전 체인을 탐색합니다. 결정론적으로 정확한 시점의 조항을 검색합니다.
자동 입법 초안 작성
EU 연구에서 검증된 AI + AKN 하이브리드 입법 지원:
입력
의원이 자연어로 입법 의도를 기술: "개인정보 보호를 강화하고 싶다"
검색
AI가 기존 AKN DB에서 유사 법률·조항을 의미적으로 검색
분석
관련 조항의 수정 이력, 판례, 해외 입법례를 자동 분석
초안
AKN XML 형식으로 법률 초안을 자동 생성 (구조·메타데이터 포함)
검증
기존 법률과의 충돌, 용어 일관성, 체계적 정합성을 자동 검사
결과: 초안 작성 시간 최대 80% 절감, 법안 통합 성공률 60% 이상
법률 간 크로스 매칭: 일본의 사례
2026년 발표된 일본 연구(arXiv:2603.15094)는 일본 법률표준(JLS) XML을 Akoma Ntoso로 변환한 후, 다국어 임베딩 + FAISS 검색 + Cross-Encoder 재순위 매기기를 통해 서로 다른 국가의 유사한 법률 조항을 자동 매칭하는 파이프라인을 구축했습니다.
왜 이것이 혁명적인가? 전 세계 법률이 Akoma Ntoso라는 하나의 표준으로 표현되면, "한국 개인정보보호법과 EU GDPR에서 동의(Consent)를 정의하는 방식은 어떻게 다른가?"라는 비교법적 질문에 기계가 직접 답할 수 있게 됩니다. 이것은 비교법학의 자동화, 나아가 국제 법률 조화(harmonization)의 첫걸음입니다.
10. 관련 표준 생태계
Akoma Ntoso는 홀로 서 있지 않습니다. 상호 보완적인 표준들의 생태계 속에 있습니다:
LegalDocML (Akoma Ntoso)
법률 문서의 텍스트와 구조 표현
OASIS 표준 (2018)
LegalRuleML
법률의 논리적 규칙 표현
OASIS 표준 (2021)
의무·허가·금지를 기계 실행 가능하게
ELI (유럽 입법 식별자)
법률의 식별과 접근 표준
URI 기반 유럽 법률 식별 체계
AKN IRI와 매핑 가능
CEN MetaLex
법률 XML의 교환 형식
네덜란드 28,000+ 법률을 Linked Open Data로 공개
LEOS
AKN 기반 입법 편집 도구
EU 오픈소스 웹 에디터
EUPL 라이선스
LegalDocML vs LegalRuleML — 무엇이 다른가? LegalDocML(AKN)이 "법률이 뭐라고 쓰여있는가"(텍스트)를 표현한다면, LegalRuleML은 "그 법률이 뭘 말하는가"(규칙)를 표현합니다. 예: AKN으로 "만 18세 미만은 음주를 금한다"라는 텍스트를 구조화하고, LegalRuleML로 IF age < 18 THEN prohibited(drinking)이라는 실행 가능한 규칙을 표현합니다. 이 두 표준이 결합되면 "Rules as Code" — 법률의 자동 실행이 가능해집니다.
11. 한국에의 시사점
현재 한국은 법제처가 자체 시스템으로 법률 정보를 관리하고 있으며, Akoma Ntoso를 공식 채택하지는 않았습니다. 하지만 생각해 볼 점이 있습니다:
🤔
현재: 자체 포맷의 고립
국가법령정보센터의 법률 데이터는 독자적 포맷으로, 국제적 법률 비교나 AI 활용에 구조적 한계가 있습니다. "한국 상법과 일본 회사법의 이사 책임 규정 비교"를 자동화하기 어렵죠.
💡
가능성: AKN 호환으로 열리는 세계
일본의 JLS→AKN 변환 연구처럼, 한국 법률을 AKN 호환 XML로 변환하면 국제 법률 비교, AI 법률 자문, 크로스보더 규제 분석이 가능해집니다. 특히 FTA, 국제통상, 지적재산 분야에서 즉각적 효용이 있을 것입니다.
마무리: 연결된 마음, 연결된 법
Akoma Ntoso는 단순한 XML 스키마가 아닙니다.
그것은 "법률은 모든 시민이 접근할 수 있어야 한다"는 신념의 기술적 구현입니다. 아프리카의 "연결된 마음"에서 시작해, 지금은 AI가 법률을 이해하는 기초 인프라가 되었습니다.
PDF 속에 갇혀 있던 법률이 XML로 해방되고, AI가 그 구조를 타고 지식 그래프를 구축하는 시대. Akoma Ntoso는 그 변혁의 중심에서 조용히, 그러나 확실하게 세상을 바꾸고 있습니다.
법률이 데이터가 되는 순간, 법의 지배(Rule of Law)는 비로소 디지털 시대에 걸맞은 의미를 갖게 됩니다.
참고 자료
- OASIS Akoma Ntoso v1.0 Standard (2018) — oasis-open.org
- Palmirani, M. & Vitali, F. "Akoma Ntoso for Making FAIRer Legislation" (2025, csv,conf,v9)
- SAT-Graph RAG: Ontology-Driven Graph RAG for Legal Norms (2025, arXiv:2505.00039)
- LexDrafter: Terminology Drafting with RAG (2024, arXiv:2403.16295)
- Japan-AKN Bridge: Cross-Jurisdictional Matching (2026, arXiv:2603.15094)
- UK legislation.gov.uk AKN API
- Laws.Africa AKN4Africa Recommendation
- EU LEOS + Hybrid AI Research (2024-2025)