들어가며: "그냥 Postgres 쓰세요"
2026년, 세계에서 가장 많은 사용자가 동시에 접속하는 AI 서비스 — ChatGPT. 주간 활성 사용자 8억 명, 초당 수백만 건의 쿼리, 99.999%의 가용성. 이 모든 것을 지탱하는 데이터베이스가 뭔지 아시나요?
PostgreSQL. 그것도 단 하나의 프라이머리 인스턴스로.
MongoDB도 아니고, Cassandra도 아니고, 자체 개발한 분산 데이터베이스도 아닙니다. 1986년 UC 버클리의 한 교수 연구실에서 시작된 오픈소스 관계형 데이터베이스가, 40년이 지난 지금 AI 시대의 심장을 뛰게 하고 있습니다.
OpenAI는 2025년 7월 공식 블로그에 "Scaling PostgreSQL to power 800 million ChatGPT users"라는 글을 발표하며 그 비밀을 공개했습니다. 이 글은 그 내용을 깊이 파고들되, 왜 이런 결정을 내렸는지, 핵심 개념은 무엇인지, 그리고 2026년 현재 이것이 의미하는 바가 무엇인지를 풀어보겠습니다.
1장. PostgreSQL: 40년의 여정
교수님의 실험에서 시작된 혁명
1986년, UC 버클리의 마이클 스톤브레이커(Michael Stonebraker) 교수는 기존 데이터베이스의 한계에 좌절하고 있었습니다. 그가 이전에 만든 Ingres는 상업적으로 성공했지만, 확장성에 구조적 문제가 있었죠.
그래서 그는 완전히 새로운 프로젝트를 시작합니다. 이름은 POSTGRES — "Post-Ingres", 즉 "Ingres 이후"라는 뜻입니다.
스톤브레이커 교수의 핵심 철학은 하나였습니다: "확장 가능한(extensible) 데이터베이스." 사용자가 새로운 데이터 타입, 연산자, 인덱스 방식을 직접 추가할 수 있어야 한다는 것이었죠.
1986
UC 버클리에서 POSTGRES 프로젝트 시작. 마이클 스톤브레이커 교수 주도
1989
Version 1 출시. 외부 사용자에게 처음 공개
1994
Andrew Yu와 Jolly Chen이 SQL 인터프리터 추가 → Postgres95
1996
이름을 PostgreSQL로 변경. 오픈소스 커뮤니티 본격 성장
2012
PostgreSQL 9.2에서 캐스케이딩 리플리케이션 도입
2025
OpenAI, 8억 사용자를 단일 프라이머리로 서빙. "Just use Postgres" 밈 현실화
왜 40년이 지나도 PostgreSQL인가?
2026년 현재, Stack Overflow 개발자 설문조사에서 PostgreSQL은 가장 사랑받는 데이터베이스 1위를 6년 연속 차지하고 있습니다. 그 이유는 스톤브레이커 교수의 원래 철학 — 확장성 — 이 오늘날 빛을 발하고 있기 때문입니다.
- pgvector — 벡터 검색을 위한 확장 (AI 임베딩 저장)
- PostGIS — 지리공간 데이터 처리
- pg_stat_statements — 쿼리 성능 모니터링
- Citus — 수평 샤딩을 위한 분산 확장
별도의 벡터 DB, 별도의 지리공간 DB, 별도의 분석 DB 대신 PostgreSQL 하나에 확장을 꽂아 쓰는 것. 이것이 OpenAI가 PostgreSQL을 선택한 근본적인 이유입니다.
2장. OpenAI의 결단: "샤딩하지 않겠다"
보통은 이렇게 합니다
사용자가 폭증하면 대부분의 기업은 이런 순서를 따릅니다:
1단계
수직 확장 — 서버 사양을 올린다 (CPU, RAM, SSD)
2단계
읽기 복제 — Read Replica를 추가해서 읽기 부하를 분산
3단계
샤딩 — 데이터를 쪼개서 여러 서버에 분산 저장
4단계
분산 DB 전환 — CockroachDB, Spanner 등으로 마이그레이션
OpenAI는 2단계에서 멈췄습니다. 그리고 그 2단계를 극한까지 최적화하는 방향을 택했죠.
왜 샤딩을 하지 않았을까?
답은 놀라울 정도로 현실적입니다:
"샤딩을 구현하려면 이 데이터베이스를 사용하는 수백 개의 애플리케이션을 수정해야 합니다. 안전하고 포괄적인 마이그레이션은 몇 달, 심지어 몇 년이 걸릴 수 있습니다."
ChatGPT가 하루가 다르게 성장하는 상황에서, 수백 개의 마이크로서비스를 동시에 수정하는 대규모 마이그레이션을 감행하는 것은 움직이는 비행기의 엔진을 교체하는 것과 같습니다.
대신 OpenAI는 더 실용적인 질문을 던졌습니다:
🔍
관찰
ChatGPT 워크로드의 대부분은 읽기(Read)다. 사용자는 대화를 불러오고, 설정을 확인하고, 기록을 조회한다.
💡
핵심 판단
읽기는 복제본(Replica)으로 무한히 확장 가능하다. 문제는 쓰기(Write)에만 존재한다.
✅
전략
프라이머리의 쓰기 부하를 최소화하고, 읽기는 50개의 리플리카로 분산한다. 샤딩이 필요한 워크로드만 별도 시스템으로 분리.
3장. 아키텍처 해부: 단일 프라이머리의 생존 전략
OpenAI의 PostgreSQL 아키텍처를 한눈에 보면 이렇습니다:
OpenAI PostgreSQL 아키텍처
Primary DB
Azure PostgreSQL
모든 쓰기 처리
Hot Standby
HA 페일오버용
실시간 동기화
Cascading Relay
중간 릴레이
WAL 중계
읽기 리플리카
~50대
지역 분산 배포
PgBouncer
K8s Pod
커넥션 풀링
Cosmos DB
Azure
쓰기 집약 워크로드
이 구조가 어떻게 초당 수백만 쿼리를 처리할 수 있는지, 3가지 핵심 전략으로 분해해 보겠습니다.
전략 1: 프라이머리의 짐을 덜어라
프라이머리 DB는 모든 쓰기를 처리하는 유일한 노드입니다. 이 노드가 과부하에 걸리면 전체 시스템이 멈춥니다. OpenAI는 세 가지 방법으로 프라이머리를 보호했습니다:
읽기 트래픽 완전 분리 — 읽기 쿼리는 전부 50개 리플리카로 라우팅합니다. 쓰기 트랜잭션 내에서 발생하는 읽기만 프라이머리를 사용합니다.
게으른 쓰기(Lazy Writes) — 모든 쓰기를 즉시 처리하는 대신, 긴급하지 않은 쓰기는 트래픽이 낮은 시간대로 지연시킵니다. 이것은 마치 세탁물을 바로 개지 않고 바구니에 모아뒀다가 한 번에 정리하는 것과 같습니다.
샤딩 가능한 워크로드 분리 — 독립적으로 분산 가능한 쓰기 워크로드(예: 로그, 이벤트 추적)는 Azure Cosmos DB로 이전했습니다. PostgreSQL에는 관계형 일관성이 필요한 핵심 데이터만 남깁니다.
전략 2: 쿼리와 커넥션을 최적화하라
데이터베이스 성능의 80%는 쿼리 품질에 달려 있습니다.
12개 테이블 JOIN의 교훈
OpenAI 엔지니어들은 어느 날 프라이머리 DB의 CPU가 치솟는 것을 발견했습니다. 원인을 추적하니 12개 테이블을 동시에 JOIN하는 단일 쿼리가 범인이었죠.
ORM(Object-Relational Mapping)이 자동으로 생성한 이 쿼리는, 사람이 직접 작성했다면 절대 쓰지 않았을 비효율적인 구문이었습니다. OpenAI의 대응:
- 복잡한 JOIN을 애플리케이션 레이어로 분해 — DB에서 한 번에 처리하는 대신, 여러 개의 단순 쿼리로 나누어 앱 서버에서 조합
- ORM이 생성하는 SQL을 수동 검토 — 자동 생성을 믿지 않고 실제 실행 계획 확인
- 타임아웃 강제 적용 —
idle_in_transaction_session_timeout으로 오래 열려 있는 트랜잭션 자동 종료
PgBouncer: 커넥션의 교통정리

PostgreSQL은 새로운 클라이언트가 연결할 때마다 프로세스를 하나 생성(fork)합니다. 이것은 안정적이지만 무겁습니다. 수천 개의 마이크로서비스가 동시에 연결하면? 서버 메모리가 빠르게 소진됩니다.
PgBouncer는 이 문제를 해결하는 경량 프록시입니다:
😱
PgBouncer 없이
클라이언트 5,000개 → PostgreSQL 프로세스 5,000개 → 커넥션 수립 시간 50ms
🎯
PgBouncer 적용 후
클라이언트 5,000개 → PgBouncer → PostgreSQL 프로세스 수백 개 → 커넥션 수립 시간 5ms
⚡
결과
커넥션 오버헤드 10배 감소. Kubernetes에서 리플리카마다 여러 PgBouncer 파드를 동일 리전에 배치하여 네트워크 레이턴시까지 최소화.
비유하자면, PgBouncer는 인기 맛집의 웨이팅 관리 시스템입니다. 손님 1,000명이 동시에 문을 열고 들어오면 주방이 마비되지만, 프론트에서 "지금 자리 나면 바로 안내해 드릴게요"라고 관리하면 주방은 안정적으로 돌아갑니다.
전략 3: 연쇄 장애를 막아라
분산 시스템에서 가장 무서운 것은 한 곳의 장애가 전체를 무너뜨리는 연쇄 반응입니다.
캐시 미스 폭풍 (Cache Stampede)
10만 명이 동시에 같은 데이터를 요청했는데, 캐시에 없다고 가정해 봅시다. 10만 개의 요청이 동시에 DB를 때립니다. 이것을 캐시 미스 폭풍(Cache Stampede)이라 부릅니다.
OpenAI의 해결책: 캐시 락(Cache Lock) 메커니즘
10만 요청 → 캐시 미스 → 1개만 DB 조회 락 획득
→ 나머지 99,999개는 대기
→ 1개가 캐시 업데이트
→ 99,999개는 캐시에서 읽기
이 단순한 메커니즘 하나로 DB 부하를 10만 분의 1로 줄일 수 있습니다.
노이지 네이버 격리 (Noisy Neighbor Isolation)
새로운 기능을 출시할 때, 비효율적인 쿼리가 포함되어 있으면 기존 핵심 서비스까지 느려질 수 있습니다. OpenAI는 워크로드를 우선순위별로 분리하여 이 문제를 해결했습니다:
| 구분 | 높은 우선순위 | 낮은 우선순위 |
|---|
| 사용처 | 실시간 대화, 인증 | 분석, 배치 작업 |
| DB 인스턴스 | 전용 리플리카 | 공유 리플리카 |
| 장애 격리 | 독립 운영 | 성능 저하 허용 |
다층 속도 제한 (Multi-Layer Rate Limiting)
OpenAI는 4개 계층에 걸쳐 속도 제한을 적용했습니다:
애플리케이션 레이어
→
커넥션 풀러 (PgBouncer)
→
프록시 레이어
→
쿼리 레이어
한 곳이 뚫려도 다음 계층에서 잡습니다. 이것은 댐 하나가 아니라 여러 겹의 방파제를 쌓는 것과 같습니다.
4장. MVCC — PostgreSQL의 천재적 설계와 그 대가

OpenAI가 PostgreSQL을 운영하면서 가장 많은 고민을 쏟은 부분이 MVCC(Multi-Version Concurrency Control)입니다. 이것은 PostgreSQL의 핵심 동작 원리이자, 동시에 가장 큰 운영 과제입니다.
MVCC란 무엇인가?
한 가지 비유로 설명해 보겠습니다.
도서관에 인기 책 한 권이 있습니다. 10명이 동시에 읽고 싶어 하고, 1명이 내용을 수정하고 싶어 합니다.
전통적 방식 (락 기반): 수정하는 사람이 끝날 때까지 10명 모두 기다려야 합니다. ❌
MVCC 방식: 수정하는 사람은 새 버전의 책을 만듭니다. 10명은 이전 버전을 그대로 읽습니다. 수정이 끝나면 새 버전이 "최신"이 됩니다. ✅
핵심 원칙은 이것입니다: "읽는 사람은 쓰는 사람을 절대 차단하지 않고, 쓰는 사람은 읽는 사람을 절대 차단하지 않는다."
이것이 8억 명의 사용자가 동시에 ChatGPT를 사용할 수 있는 이유입니다. 대화 기록을 불러오는 읽기 작업이, 새 메시지를 저장하는 쓰기 작업과 서로 충돌하지 않습니다.
그런데... Dead Tuple 문제
MVCC에는 대가가 있습니다. 업데이트할 때 기존 행을 수정하지 않고 새 행을 만든다는 것은, 이전 버전의 행이 계속 쌓인다는 뜻입니다. 이 사용하지 않는 이전 버전을 Dead Tuple(죽은 튜플)이라고 합니다.
1. 원본 상태
Row #42: {name: "ChatGPT", users: 500000000} ← LIVE
2. UPDATE 실행 후
Row #42: {name: "ChatGPT", users: 500000000} ← DEAD (이전 버전)
Row #43: {name: "ChatGPT", users: 800000000} ← LIVE (새 버전)
3. 문제
Dead Tuple이 쌓이면 → 테이블 비대화(Bloat) → 디스크 낭비 + 쿼리 느려짐
Autovacuum: PostgreSQL의 청소부
PostgreSQL은 이 Dead Tuple을 정리하기 위해 VACUUM이라는 프로세스를 백그라운드에서 자동 실행합니다. 이것이 Autovacuum입니다.
문제는, 8억 명의 사용자가 끊임없이 쓰기를 하면 Dead Tuple이 청소 속도보다 빠르게 쌓인다는 것입니다. 특히 오래 열려 있는 트랜잭션이 Autovacuum을 차단하면 상황은 더 악화됩니다.
OpenAI가 취한 조치:
idle_in_transaction_session_timeout 설정으로 유휴 트랜잭션 자동 종료- 모든 쿼리에 타임아웃 강제 적용 (장시간 실행 방지)
- 백필(대량 데이터 투입) 작업의 속도를 의도적으로 제한 — 한 주가 걸리더라도 프로덕션 안정성 우선
- 불필요한 쓰기 제거 — 변경이 없는 UPDATE 방지
5장. 리플리케이션: 50개의 분신술
WAL — 데이터베이스의 블랙박스
PostgreSQL의 리플리케이션을 이해하려면 먼저 WAL(Write-Ahead Log)을 알아야 합니다.
비행기에 블랙박스가 있듯이, PostgreSQL에는 모든 변경 사항을 기록하는 로그가 있습니다. 데이터를 실제로 수정하기 전에 먼저 이 로그에 기록합니다. 그래서 "Write-Ahead Log" — 미리 쓰는 기록장이라는 이름이 붙었죠.
이 WAL을 리플리카에 전송하면? 리플리카가 같은 순서대로 변경을 적용하면서 프라이머리의 정확한 복사본이 됩니다.
50개의 리플리카, 하나의 프라이머리
OpenAI는 약 50개의 읽기 리플리카를 여러 지리적 리전에 분산 배치했습니다. 한국의 사용자가 ChatGPT에 접속하면, 가장 가까운 아시아 리전의 리플리카에서 데이터를 읽습니다.
캐스케이딩 리플리케이션: 프라이머리의 부담을 줄이다
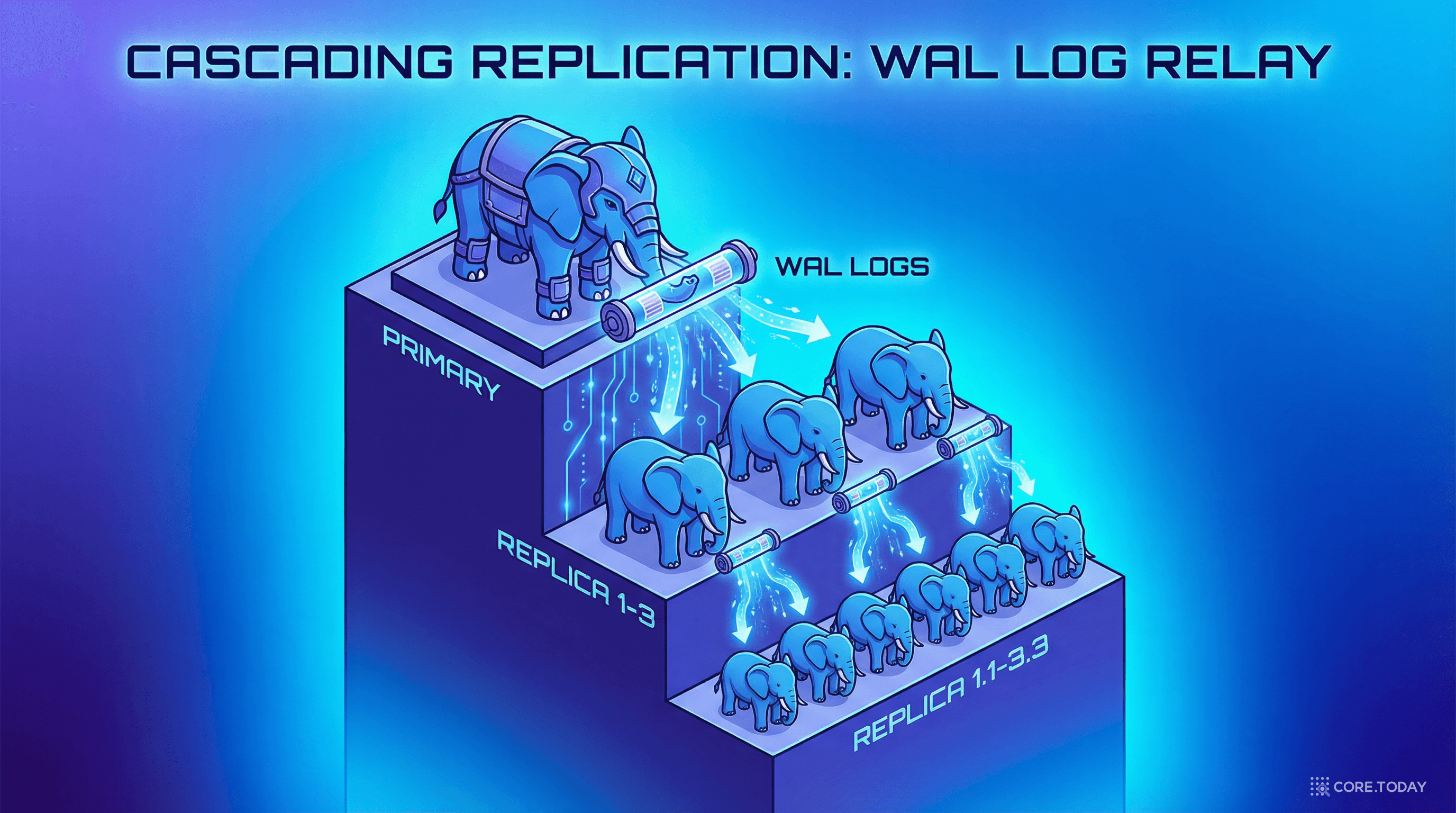
50개의 리플리카가 모두 프라이머리에서 직접 WAL을 받으면? 프라이머리의 네트워크 대역폭이 병목이 됩니다.
OpenAI는 Azure PostgreSQL 팀과 협력하여 캐스케이딩 리플리케이션을 도입했습니다:
Primary
WAL →
중간 리플리카 A
WAL →
리플리카 1~15
_
→
중간 리플리카 B
WAL →
리플리카 16~30
_
→
중간 리플리카 C
WAL →
리플리카 31~50
프라이머리는 3개의 중간 리플리카에만 WAL을 전송하고, 중간 리플리카가 나머지에게 릴레이합니다. 이 구조 덕분에 50대를 넘어 100대 이상으로의 확장도 가능해졌습니다.
이것은 전화 연락망과 같습니다. 회장이 100명에게 직접 전화하는 대신, 3명의 부회장에게 전화하고, 부회장이 각각 30명에게 전달하는 것이죠.
6장. 스키마 변경의 공포: 프로덕션 DB에서 ALTER TABLE 하기
관계형 데이터베이스에서 가장 위험한 작업 중 하나가 스키마 변경입니다. 테이블에 컬럼을 추가하거나, 인덱스를 생성하는 것처럼 단순해 보이는 작업이 8억 사용자를 멈추게 할 수 있습니다.
왜 위험한가?
PostgreSQL에서 일부 ALTER TABLE 작업은 테이블 전체를 다시 쓰기(rewrite)합니다. 수억 건의 행이 있는 테이블을 다시 쓰는 동안, 해당 테이블에 대한 모든 쿼리가 차단됩니다.
OpenAI의 스키마 변경 규칙
OpenAI는 프로덕션 PostgreSQL에 대해 매우 엄격한 규칙을 세웠습니다:
| 허용 ✅ | 금지 ❌ |
|---|
| 특정 컬럼 추가/삭제 (경량 변경) | 전체 테이블 rewrite가 필요한 변경 |
| CONCURRENTLY 인덱스 생성 | 일반 CREATE INDEX (테이블 락) |
| 5초 타임아웃 내 DDL | 5초 초과 스키마 변경 |
| 기존 테이블에 행 추가 (속도 제한) | 새 테이블 생성 (→ Cosmos DB로) |
핵심 원칙: 프로덕션 PostgreSQL에 새 테이블을 만들지 않는다. 새로운 워크로드는 Cosmos DB 같은 별도 시스템에 배치합니다.
7장. 실전 사고 보고서: ChatGPT ImageGen 대란
12개월 동안 단 한 번의 SEV-0(최고 심각도) 사고가 발생했습니다. 그리고 그 원인은 기술적 결함이 아니라 폭발적 성공이었습니다.
사건 경위
2025년, ChatGPT에 이미지 생성 기능이 추가되자 1주일 만에 1억 명의 신규 가입이 쏟아졌습니다. 쓰기 트래픽이 순식간에 10배 이상 급증했습니다.
발단
ImageGen 출시 → 바이럴 확산 → 1주일에 1억 명 가입
위기
쓰기 트래픽 10배 급증 → 프라이머리 과부하 → WAL 생성 폭증
연쇄
WALSender 스핀루프 버그 → 높은 CPU에서 리플리카 동기화 실패 → 리플리케이션 지연 증가
복구
아키텍처의 복원력(redundancy)으로 서비스 유지. 이후 근본 원인 수정
이 사건은 중요한 교훈을 남겼습니다: 성공이 가장 큰 장애의 원인이 될 수 있다는 것. 그리고 이에 대비하는 유일한 방법은 여유 용량(headroom)을 항상 확보해 두는 것입니다.
8장. PostgreSQL이 OpenAI에 보내는 위시리스트
OpenAI는 PostgreSQL을 극한까지 사용하면서, 커뮤니티에 개선을 요청한 기능들이 있습니다. 이것들은 대규모 운영의 고충을 잘 보여줍니다:
| 요청 기능 | 현재 문제 | 기대 효과 |
|---|
| 인덱스 비활성화 | 사용하지 않는 인덱스를 DROP하지 않고 잠시 끄기 불가 | 안전한 인덱스 정리 |
| p95/p99 레이턴시 지표 | pg_stat_statements가 평균 응답 시간만 제공 | 실시간 성능 모니터링 |
| 스키마 변경 이력 | DDL 작업 이력을 시스템 뷰로 추적 불가 | 변경 감사(audit) |
| 지능형 기본 설정 | shared_buffers 기본값이 128MB (1990년대 수준) | 하드웨어 기반 자동 튜닝 |
9장. 2026년, 이것이 의미하는 것
"분산 데이터베이스가 답이다"라는 신화
지난 10년간 기술 업계에서 가장 널리 퍼진 믿음 중 하나는 "대규모 서비스에는 분산 데이터베이스가 필수"라는 것이었습니다. Google의 Spanner, Amazon의 DynamoDB, CockroachDB — 이 도구들은 분명 강력하지만, OpenAI의 사례는 다른 메시지를 전합니다:
대부분의 서비스는 PostgreSQL 하나로 충분하다.
Pigsty 프로젝트의 Vonng은 이렇게 표현합니다: "분산 데이터베이스는 거짓 필요(False Need)"라고. 2017년 중국의 소셜 앱 Tantan에서 수십 개의 PostgreSQL 클러스터로 초당 250만 쿼리를 처리했던 경험을 인용하면서요.
AI 시대에 PostgreSQL이 선택받는 이유
2026년 현재, PostgreSQL은 단순한 관계형 데이터베이스가 아닙니다:
PostgreSQL = 통합 데이터 플랫폼
pgvector
벡터 검색
AI 임베딩
pg_bm25
전문 검색
키워드 검색
PostGIS
지리공간
위치 기반
PostgreSQL Core
관계형 + ACID
40년의 안정성
별도의 벡터 DB(Pinecone, Weaviate)를 운영하는 대신 pgvector 확장 하나로 AI 임베딩 저장과 유사도 검색을 처리할 수 있습니다. 데이터베이스를 여러 개 운영하는 것은 복잡성 = 장애 포인트를 늘리는 것이니까요.
핵심 교훈 정리
1
기술보다 엔지니어링
화려한 새 기술(분산 DB, NewSQL)보다 기존 기술의 깊은 이해와 최적화가 더 큰 성과를 낸다. OpenAI는 PostgreSQL의 MVCC, WAL, 커넥션 모델을 속속들이 이해하고 그에 맞게 운영했다.
2
실용주의가 이긴다
"완벽한 아키텍처"를 위한 대규모 마이그레이션보다, 지금 동작하는 시스템을 점진적으로 개선하는 것이 빠르게 성장하는 서비스에서 더 현명하다.
3
방어적 운영이 핵심
다층 속도 제한, 캐시 락, 워크로드 격리, 타임아웃 강제 — 이런 "장애를 가정하는" 방어적 엔지니어링이 99.999% 가용성을 만든다.
마치며: 코끼리는 느리지 않다
PostgreSQL의 마스코트는 코끼리(Slonik)입니다. 코끼리는 느리다고요? 코끼리의 최고 속도는 시속 40km입니다. 충분히 빠르죠.
OpenAI가 증명한 것은 이겁니다: 올바른 운영 전략과 깊은 이해가 있다면, 40년 된 오픈소스 데이터베이스 하나로도 AI 시대의 가장 큰 서비스를 지탱할 수 있다.
다음에 누군가 "그 정도 규모면 분산 DB 써야 하지 않아?"라고 물으면, 이렇게 답하세요:
"OpenAI한테 물어봐. 걔네 Postgres 하나로 8억 명 서빙해."
참고 자료




