블로그로 돌아가기
RotatE지식 그래프 임베딩복소 벡터 공간링크 예측TransEComplEx관계 패턴
RotatE: 복소수의 회전으로 지식 그래프를 이해하다
세상의 모든 관계를 '회전'으로 설명할 수 있다면? 2019년 ICLR에서 발표된 RotatE는 복소수 공간에서의 회전이라는 우아한 아이디어로, 지식 그래프 임베딩의 판도를 바꿨다. 수학의 아름다움과 AI의 실용성이 만나는 이 논문을 완전 해부한다.
코어닷투데이2026-04-0744분
세상의 모든 관계를 '회전'으로 설명할 수 있다면? 2019년 ICLR에서 발표된 RotatE는 복소수 공간에서의 회전이라는 우아한 아이디어로, 지식 그래프 임베딩의 판도를 바꿨다. 수학의 아름다움과 AI의 실용성이 만나는 이 논문을 완전 해부한다.
구글에 "고양이"를 검색하면, 오른쪽에 정보 패널이 뜬다. "포유류", "수명: 12~18년", "학명: Felis catus". 구글은 이 정보를 어디서 가져올까?
답은 지식 그래프(Knowledge Graph) 다. 2012년 구글이 "Things, not strings"이라는 슬로건으로 발표한 이 시스템은, 세상의 사실을 (주어, 관계, 목적어) 형태의 트리플(triple)로 저장한다:
Freebase에 19억 개, Wikidata에 100억 개 이상의 트리플이 저장되어 있다. 하지만 문제가 있다. 이 그래프에는 빈 곳이 너무 많다. 알려진 사실만 기록되어 있을 뿐, 추론 가능한 사실의 대부분이 빠져 있다. "(아인슈타인, nationality, 독일)"이 없더라도, "(아인슈타인, born_in, 울름)"과 "(울름, located_in, 독일)"로부터 추론할 수 있어야 한다.
이 빠진 링크를 예측하는 것이 지식 그래프의 핵심 과제이고, 이를 위해 등장한 기술이 바로 지식 그래프 임베딩(Knowledge Graph Embedding, KGE) 이다.
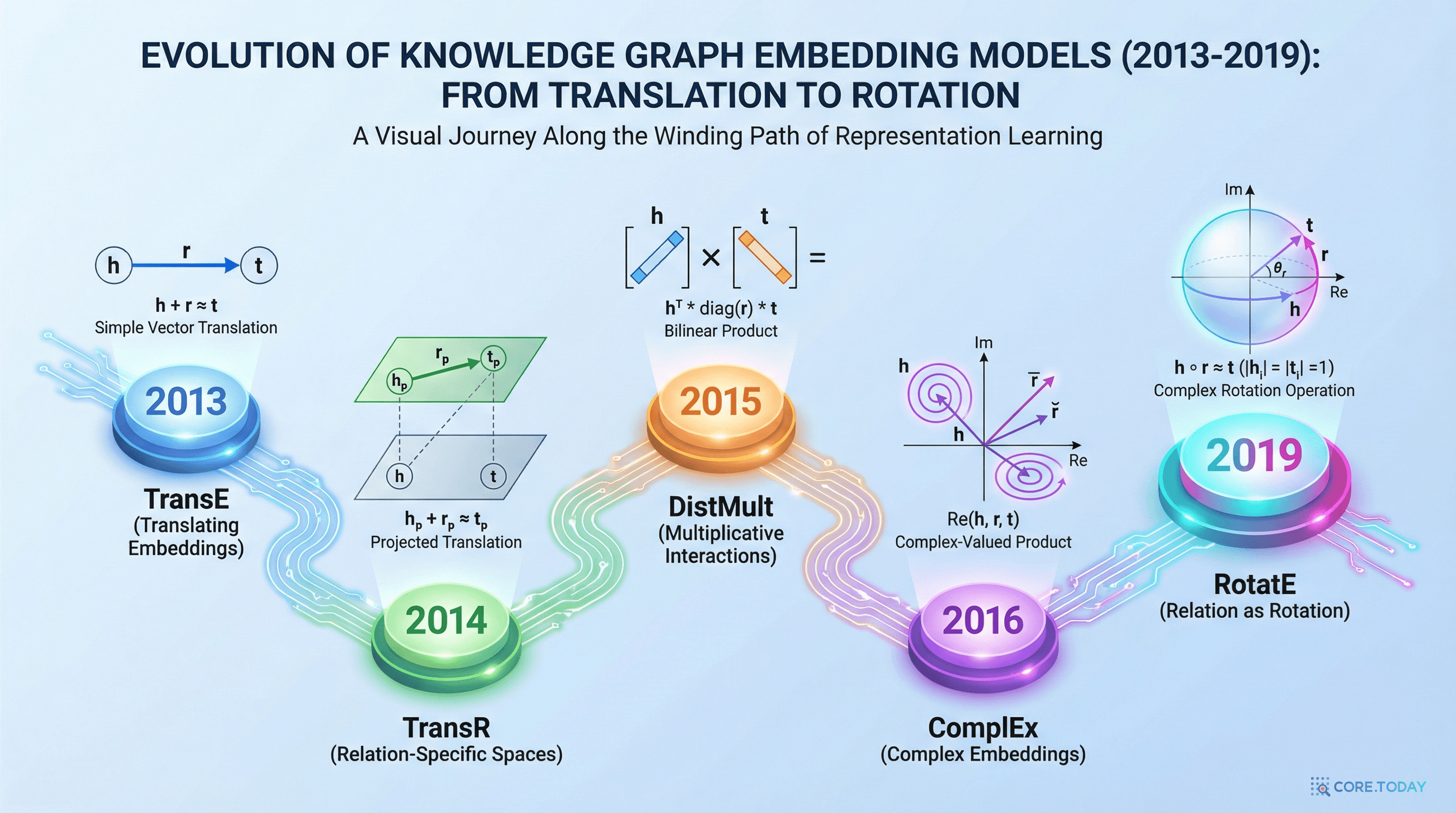
그리고 2019년, ICLR에서 발표된 RotatE는 오일러 공식이라는 수학의 보석을 활용하여, 기존 모델들이 각각 일부만 다룰 수 있었던 관계 패턴 — 대칭, 반대칭, 역관계, 합성 — 을 단 하나의 연산(회전) 으로 모두 모델링하는 데 성공했다.
모든 것은 2013년, Antoine Bordes 등이 NeurIPS에서 발표한 TransE에서 시작되었다. 아이디어는 놀라울 정도로 단순하다:
머리 엔티티(h)에 관계 벡터(r)를 더하면 꼬리 엔티티(t)에 가까워져야 한다.
"서울"이라는 벡터에 "capital_of"라는 벡터를 더하면 "대한민국" 벡터 근처에 도달하는 것이다. 수직선 위에서 평행이동(translation) 하는 것과 같다.
TransE는 단순하면서도 강력했다. 하지만 치명적인 약점이 있었다:
Bishan Yang 등이 제안한 DistMult는 다른 접근을 택했다. 관계를 대각 행렬로 표현하고, 머리-관계-꼬리의 삼중 상호작용을 점수로 사용한다:
이 함수는 h와 t를 바꿔도 값이 같다 — 즉 대칭 관계를 자연스럽게 모델링한다. 하지만 바로 그 때문에 반대칭 관계를 표현할 수 없다. "(사람, father_of, 아이)"와 "(아이, father_of, 사람)"을 구분하지 못하는 것이다.
Théo Trouillon 등이 발표한 ComplEx는 획기적인 아이디어를 가져왔다. 임베딩을 실수가 아닌 복소수 공간으로 확장한 것이다:
여기서 는 t의 켤레복소수다. 복소수의 켤레를 취하면 허수부의 부호가 바뀌므로, h와 t를 교환할 때 값이 달라질 수 있다. 이로써 대칭/반대칭/역관계를 모두 모델링할 수 있게 되었다.
하지만 ComplEx에도 한계가 있었다: 합성(composition) 패턴을 추론할 수 없었다.
| 모델 | 대칭 | 반대칭 | 역관계 | 합성 |
|---|---|---|---|---|
| TransE (2013) | 불가 | 가능 | 가능 | 가능 |
| DistMult (2015) | 가능 | 불가 | 불가 | 불가 |
| ComplEx (2016) | 가능 | 가능 | 가능 | 불가 |
| RotatE (2019) | 가능 | 가능 | 가능 | 가능 |
어떤 기존 모델도 네 가지 패턴을 모두 다루지 못했다. 이것이 RotatE가 등장한 이유다.
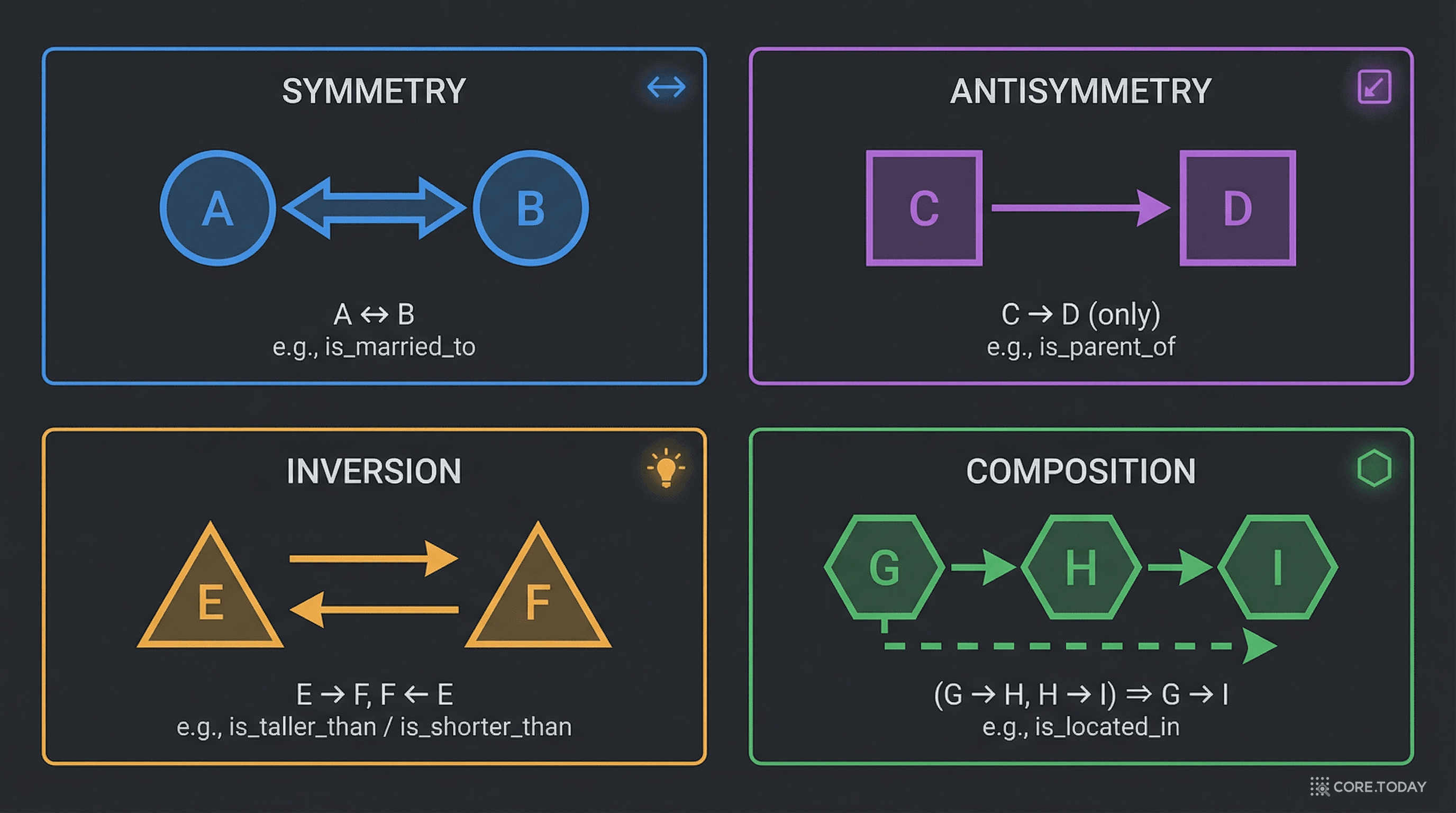
본격적으로 RotatE를 이해하기 전에, 네 가지 관계 패턴이 무엇이고 왜 중요한지 실제 사례로 살펴보자.
r(x, y) ⇒ r(y, x)
"결혼", "형제자매", "roommate" 같은 관계. A가 B와 결혼했으면, B도 A와 결혼한 것이다.
WordNet에서는 similar_to 관계가 대표적인 대칭 관계다.
r(x, y) ⇒ ¬r(y, x)
"father_of", "부분_of", "수도_of" 같은 관계. 서울이 대한민국의 수도이지, 대한민국이 서울의 수도가 아니다.
Freebase의 filiation(친자 관계)이 대표적이다.
r₂(x, y) ⇒ r₁(y, x)
"hypernym"과 "hyponym" 의 관계. "개는 동물의 하위어(hyponym)"이면 "동물은 개의 상위어(hypernym)"이다. 서로 다른 두 관계가 방향만 반대인 것.
FB15k 데이터셋의 테스트 트리플 중 81% 가 역관계를 통해 추론 가능하다.
r₂(x, y) ∧ r₃(y, z) ⇒ r₁(x, z)
가장 복잡하지만 가장 강력한 패턴. "엄마의 남편은 아버지"처럼 두 관계를 조합해 새로운 관계를 추론하는 것.
또는 지리적 관계에서: neighborOf(c₁, c₂) ∧ locatedIn(c₂, r) ⇒ locatedIn(c₁, r)
RotatE의 영감은 300년 전의 수학에서 왔다. 오일러 공식(Euler's formula):
이 공식이 말하는 것은 놀랍도록 직관적이다: 복소수 는 복소 평면에서 단위원 위의 점이며, 이것을 곱하는 것은 라디안만큼 회전시키는 것과 같다.
핵심 통찰: 크기가 1인 복소수를 곱하면 회전만 일어난다. 방향은 바뀌지만 크기는 보존된다.
RotatE의 핵심 아이디어는 한 문장으로 요약된다:
지식 그래프의 각 관계를 복소 벡터 공간에서의 회전으로 정의한다.
수식으로:
여기서:
각 차원에서 독립적으로:
이것은 복소 평면에서 를 라디안만큼 회전시켜 에 도달하는 것이다.
거리 함수(스코어 함수)는:
TransE가 "이동(translation)"이라면, RotatE는 "회전(rotation)"이다.
| 모델 | 연산 | 공간 | 직관 |
|---|---|---|---|
| TransE | h + r ≈ t | 실수 공간 R^k | 수직선 위 평행이동 |
| RotatE | h ∘ r ≈ t, |r|=1 | 복소 공간 C^k | 복소 평면 위 회전 |
이제 가장 흥미로운 부분이다. 왜 "회전"이라는 단순한 연산이 네 가지 패턴을 모두 해결하는가?
관계 r이 대칭이려면 이면서 여야 한다.
, 즉
이것이 성립하려면 각 에서 , 즉 또는 .
이면 대칭 관계! 특히 (180도 회전)은 두 번 적용하면 원래 위치로 돌아온다.
TransE에서는 대칭이면 r = 0이 되어 h = t가 강제되지만, RotatE에서는 이라는 자유로운 임베딩이 가능하다. 서로 다른 대칭 관계를 서로 다른 벡터로 표현할 수 있다.
복소 평면에서 (180도 회전):
r이 반대칭이려면 .
이고 인 모든 회전이 반대칭이다. 예를 들어 90도 회전: h를 90도 돌려 t에 도달했는데, t에서 다시 90도 돌리면 h가 아닌 다른 위치에 가게 된다.
두 관계 과 가 역관계이려면:
RotatE에서 이것은 (켤레복소수)일 때 성립한다.
, 즉 반대 방향으로 같은 각도만큼 회전.
hypernym이 30도 회전이라면, hyponym은 -30도(= 330도) 회전이다. 직관적으로 완벽하다!
(관계의 합성)이라면:
즉 — 각도가 더해진다!
30도 회전 후 45도 회전 = 75도 회전. 이것이 바로 관계 합성이다.
이것이 RotatE의 아름다움이다. 복소 평면에서의 회전이라는 단순한 연산 하나로, 네 가지 관계 패턴이 자연스럽게 해결된다.
아래 인터랙티브 도구로 복소 평면에서의 회전과 관계 패턴 모델링을 직접 실험해 볼 수 있다:
RotatE의 또 다른 기여는 자기 적대적 네거티브 샘플링(Self-Adversarial Negative Sampling) 이라는 학습 기법이다.
지식 그래프에는 "참인 트리플"만 있다. "(아인슈타인, born_in, 울름)" 같은 사실만 저장되어 있지, "(아인슈타인, born_in, 파리)"가 거짓이라는 정보는 없다. 학습하려면 거짓 트리플(negative sample) 을 만들어야 한다.
기존 방법은 균일(uniform) 샘플링 — 머리나 꼬리 엔티티를 무작위로 바꿔 거짓 트리플을 만든다:
문제는 이렇게 만든 거짓 트리플 대부분이 너무 뻔한 거짓이라는 것이다. "(아인슈타인, born_in, 피자)"는 모델이 쉽게 구별한다. 학습에 도움이 안 된다.
RotatE의 해법은 현재 모델의 상태를 이용하여, 그럴듯한 거짓 트리플에 더 높은 가중치를 부여하는 것이다:
여기서 는 온도(temperature) 파라미터다. 현재 모델이 "그럴듯하다"고 판단하는 거짓 트리플일수록 높은 확률을 받는다.
최종 손실 함수:
TransE에 self-adversarial 기법만 적용해도 MRR이 .242에서 .298로 23% 향상되었다. 이 기법은 RotatE뿐 아니라 다른 KGE 모델에도 범용적으로 적용 가능하다.
| 데이터셋 | 엔티티 수 | 관계 수 | 학습 트리플 | 핵심 패턴 |
|---|---|---|---|---|
| FB15k | 14,951 | 1,345 | 483,142 | 대칭/반대칭, 역관계 |
| WN18 | 40,943 | 18 | 141,442 | 대칭/반대칭, 역관계 |
| FB15k-237 | 14,541 | 237 | 272,115 | 대칭/반대칭, 합성 |
| WN18RR | 40,943 | 11 | 86,835 | 대칭/반대칭, 합성 |
FB15k-237과 WN18RR은 역관계 트리플을 제거한 "어려운" 버전이다. 여기서 핵심 패턴은 합성이 된다.
WN18에서의 Hits@10 (높을수록 좋음)
역관계 없이 합성 패턴이 핵심인 어려운 데이터셋에서 RotatE의 강점이 빛난다:
핵심 관찰:
Countries 데이터셋은 합성 패턴 추론 능력을 직접 테스트하도록 설계된 벤치마크다:
| Task | DistMult | ComplEx | ConvE | RotatE |
|---|---|---|---|---|
| S1 (단순 합성) | 1.00 | 0.97 | 1.00 | 1.00 |
| S2 (중간 합성) | 0.72 | 0.57 | 0.99 | 1.00 |
| S3 (복잡 합성) | 0.52 | 0.43 | 0.86 | 0.95 |
AUC-PR 점수. S3는 가장 긴 합성 체인을 요구하는 가장 어려운 태스크.
S3에서 ComplEx의 0.43 대비 RotatE의 0.95 — 압도적인 차이. 회전의 합성이 곧 각도의 덧셈이라는 수학적 성질이 빛을 발하는 순간이다.
논문의 가장 인상적인 부분 중 하나는 학습된 관계 임베딩의 위상 분포(phase histogram) 분석이다.
WN18에서 학습한 500차원 RotatE의 similar_to 관계 임베딩 위상 를 히스토그램으로 그리면, 값이 0과 π에 집중되어 있다. 즉 또는 .
은 정확히 대칭 조건 의 해다. 모델이 이론적 예측대로 학습한 것이다.
hypernym과 hyponym의 위상을 원소별로 더하면, 그 합이 0 또는 2π에 집중된다:
이것은 (켤레복소수), 즉 역관계의 이론적 조건과 정확히 일치한다.
FB15k-237에서 학습한 1000차원 RotatE를 분석한 결과:
또는
각도의 덧셈이 실제로 관찰된다. 이론이 실험으로 완벽하게 검증된 것이다.
RotatE의 "회전" 아이디어는 수많은 후속 모델에 영감을 주었다:
2026년 현재, 지식 그래프 임베딩은 LLM(대규모 언어 모델) 시대에 새로운 역할을 맡고 있다:
GraphRAG — 지식 그래프 + RAG
전통적 RAG(Retrieval-Augmented Generation)는 텍스트 청크를 검색하지만, GraphRAG는 지식 그래프를 활용하여 다중 홉 추론이 필요한 질문에 답한다. LinkedIn은 GraphRAG로 티켓 해결 시간을 40시간에서 15시간으로 63% 단축했다.
환각(Hallucination) 감소
FalkorDB는 지식 그래프 기반 RAG로 전통 RAG 대비 환각을 90% 감소시켰다. KGE가 학습한 엔티티/관계 임베딩이 LLM의 출력을 사실에 기반하여 검증하는 데 사용된다.
산업별 응용
약물-질병-유전자 관계 예측, 신약 후보 발굴
사용자-아이템-속성 다중 관계 모델링
거래-계좌-IP 간 비정상 패턴 추론
화합물-특성-구조 관계의 빠른 예측
TH-RotatE: 철도 장비 고장 패턴 추론
엔티티 연결, 질의 확장, 의미 검색
RotatE가 우리에게 보여준 것은, 때로는 올바른 수학적 프레임워크를 선택하는 것만으로 복잡한 문제가 우아하게 풀릴 수 있다는 것이다.
오일러가 300년 전에 발견한 라는 공식이, 2019년에 지식 그래프의 관계 패턴을 모델링하는 열쇠가 되었다. 그리고 2026년, 이 아이디어는 LLM과 결합하여 AI의 신뢰성과 추론 능력을 한 단계 끌어올리고 있다.
수학의 아름다움이 실용으로 이어지는 순간 — 이것이 RotatE의 진정한 가치다.
RELATED