2,400년 전, 그리스 철학자 플라톤은 한 가지 사고실험을 제안했다. 동굴 벽면만 바라보며 평생을 살아온 사람들이 있다. 그들이 보는 것은 그림자뿐이다. 뒤에서 불이 타오르고 그 앞을 지나가는 사물의 실루엣만 벽에 비친다. 그들은 그림자가 전부인 줄 안다.
그런데 누군가 동굴 밖으로 나가면? 처음엔 눈이 부시지만, 곧 사물의 진짜 형태 — 플라톤이 말한 이데아(Idea) — 를 보게 된다.
2024년, MIT의 Minyoung Huh, Brian Cheung, Tongzhou Wang, Phillip Isola가 놀라운 가설을 세웠다. 서로 다른 AI 모델들이 학습하는 "표현(representation)"이 하나의 공통된 현실 모델로 수렴하고 있다는 것이다. 마치 플라톤의 동굴에서 서로 다른 벽을 보던 죄수들이 결국 같은 이데아에 도달하는 것처럼.
이것이 바로 플라토닉 표현 가설(The Platonic Representation Hypothesis)이다.
💡
핵심 가설: 신경망 모델들은 아키텍처, 학습 목표, 데이터 모달리티(시각/언어/소리)가 달라도, 규모가 커지면 공통된 통계적 현실 모델(statistical model of reality)로 수렴한다.
왜 이 가설이 중요할까? 만약 사실이라면, AI의 미래는 모달리티별 전문가 모델의 파편화가 아니라 하나의 통합된 세계 이해로 향한다는 뜻이다. 그리고 2026년 현재, 우리는 그 수렴의 한가운데에 서 있다.
이 모든 발전이 플라토닉 표현 가설의 예측과 일치한다: 모달리티를 추가할수록, 표현의 질이 향상되고, 서로 다른 모델 간의 정렬이 강화된다.
실용적 의미: AI 개발 전략의 변화
🔴
과거의 접근: 모달리티별 전문가 모델
이미지는 CNN, 텍스트는 RNN/Transformer, 음성은 별도 모델. 각각 최적화 후 연결하는 "파이프라인" 방식.
🟢
현재의 접근: 통합 표현 학습
모든 모달리티를 하나의 표현 공간에서 학습. 데이터가 많을수록, 모델이 클수록, 자연스럽게 수렴하는 "파운데이션 모델" 방식.
✨
미래의 전망: 모달리티 불가지론적 AI
입력이 이미지든, 텍스트든, 로봇 센서든 상관없이 동일한 "현실 이해"에 기반한 추론. 플라토닉 표현이 완성된 AI.
한국 AI 산업에의 시사점
플라토닉 표현 가설은 한국 AI 산업에도 중요한 메시지를 전한다:
데이터 다양성의 가치: 한국어 텍스트만으로는 부족하다. 이미지, 영상, 한국어 음성 데이터를 함께 학습해야 더 강력한 표현에 도달할 수 있다
스케일링의 중요성: 작은 모달리티-특화 모델의 앙상블보다, 충분히 큰 통합 모델이 더 효과적일 수 있다
파인튜닝의 양날의 검: 특정 도메인에 과도하게 특화하면 범용적 표현에서 멀어질 수 있다. 균형이 필요하다
제9장: 철학적 여운 — 수렴적 실재론
플라토닉 표현 가설은 과학철학의 오래된 논쟁과 연결된다: 수렴적 실재론(convergent realism).
이 입장은 과학적 탐구가 궁극적으로 진리에 수렴한다고 주장한다. 뉴턴 역학이 아인슈타인 상대론으로, 고전 물리학이 양자역학으로 발전하면서 점점 더 정확한 현실 모델에 가까워지듯이.
AI에서도 같은 일이 일어나고 있다면, 이것은 단순한 기술적 현상이 아니라 인식론적 사건이다. AI가 "현실을 이해"하기 시작했다는 뜻일 수 있다.
물론 논문은 신중하게 구분한다:
💡
중요한 구분: 플라토닉 표현은 "현실 그 자체"가 아니라, 관측 가능한 사건들의 결합 분포(joint distribution of observable events)를 의미한다. 플라톤의 원래 이데아론이 "진정한 세계 상태"를 상정한 것과는 다르다. AI가 수렴하는 것은 "진리"가 아니라 "현실의 통계적 구조"다.
결론: 그림자 뒤의 빛을 향하여
플라토닉 표현 가설 — 핵심 요약
가설: 서로 다른 AI 모델의 표현이 공통된 통계적 현실 모델로 수렴한다
증거:
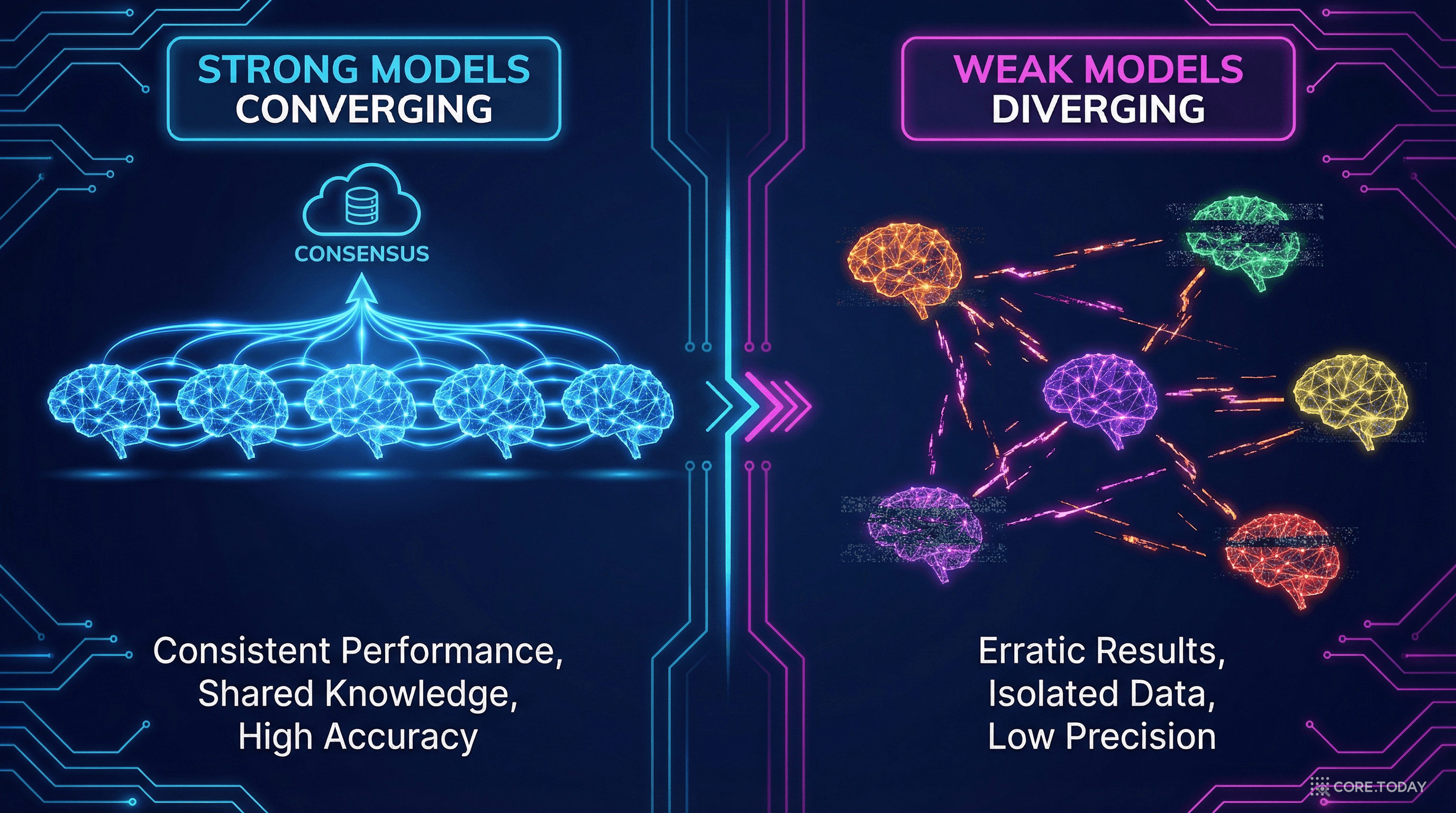
78개 비전 모델: 강한 모델일수록 표현이 유사 (안나 카레니나 효과)
비전-언어 교차: LLM 성능 ↑ = 비전 정렬 ↑ (선형 관계)
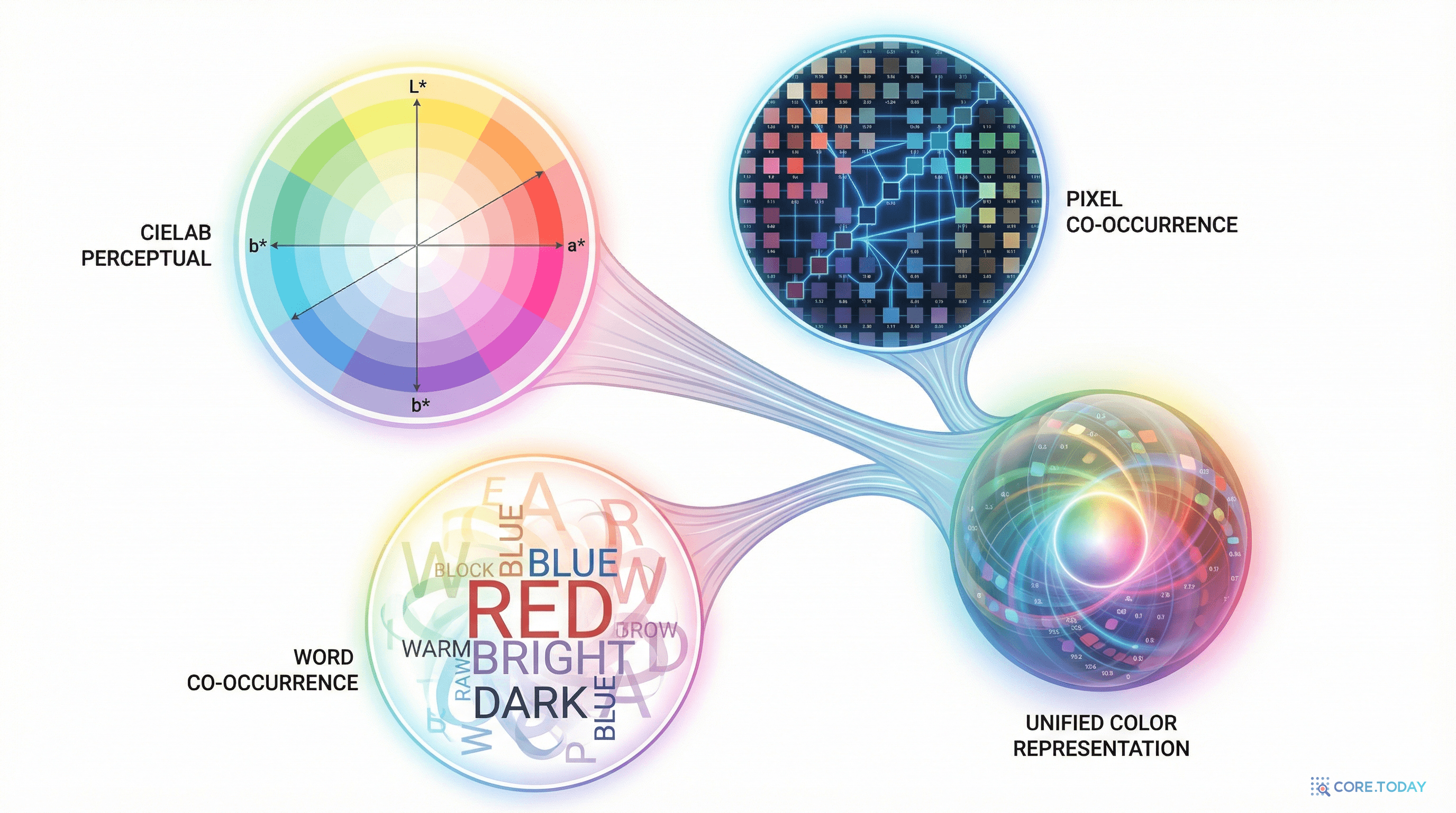
색상 실험: 지각, 이미지, 언어 세 경로가 같은 색 구조 복원
생물학적: 고성능 모델 = 인간 뇌와 더 유사
세 가지 동력:
과제 일반화 → 호환 표현 감소
모델 용량 → 전역 최적 접근
단순성 편향 → 불필요한 복잡성 제거
한계:
비전사 관측으로 인한 정보 격차
측정 점수의 해석 불확실성
인간 중심 편향 가능성
전문화 vs 범용화의 긴장
2,400년 전 플라톤이 상상한 것처럼, AI 모델들은 각자의 동굴에서 서로 다른 그림자를 보고 있다. 하지만 충분히 강력해지면, 그 그림자들 뒤에 있는 하나의 빛을 향해 수렴하고 있다.
2026년의 우리는 이 수렴의 여정에서 아직 초입에 있을 수도 있고, 이미 절반을 지났을 수도 있다. 확실한 것은, 이 논문이 AI의 근본적인 질문 — "AI는 무엇을 학습하는가?" — 에 대해 가장 아름답고 야심찬 답을 제시했다는 것이다.
AI는 데이터의 패턴을 학습하는 것이 아니다. 현실 그 자체의 구조를 학습하고 있다.
그리고 그 구조는, 누가 어떤 방법으로 보든, 결국 같은 곳에 도달한다.
참고 문헌:
Huh, M., Cheung, B., Wang, T., & Isola, P. (2024). "The Platonic Representation Hypothesis." arXiv:2405.07987
Radford, A., et al. (2021). "Learning Transferable Visual Models From Natural Language Supervision." (CLIP)
Oquab, M., et al. (2023). "DINOv2: Learning Robust Visual Features without Supervision."
Mikolov, T., et al. (2013). "Efficient Estimation of Word Representations in Vector Space." (Word2Vec)
Tolstoy, L. (1877). Anna Karenina. "All happy families are alike; each unhappy family is unhappy in its own way."