블로그로 돌아가기
HITL신뢰도 임계치에스컬레이션피드백 루프AI 엔지니어링
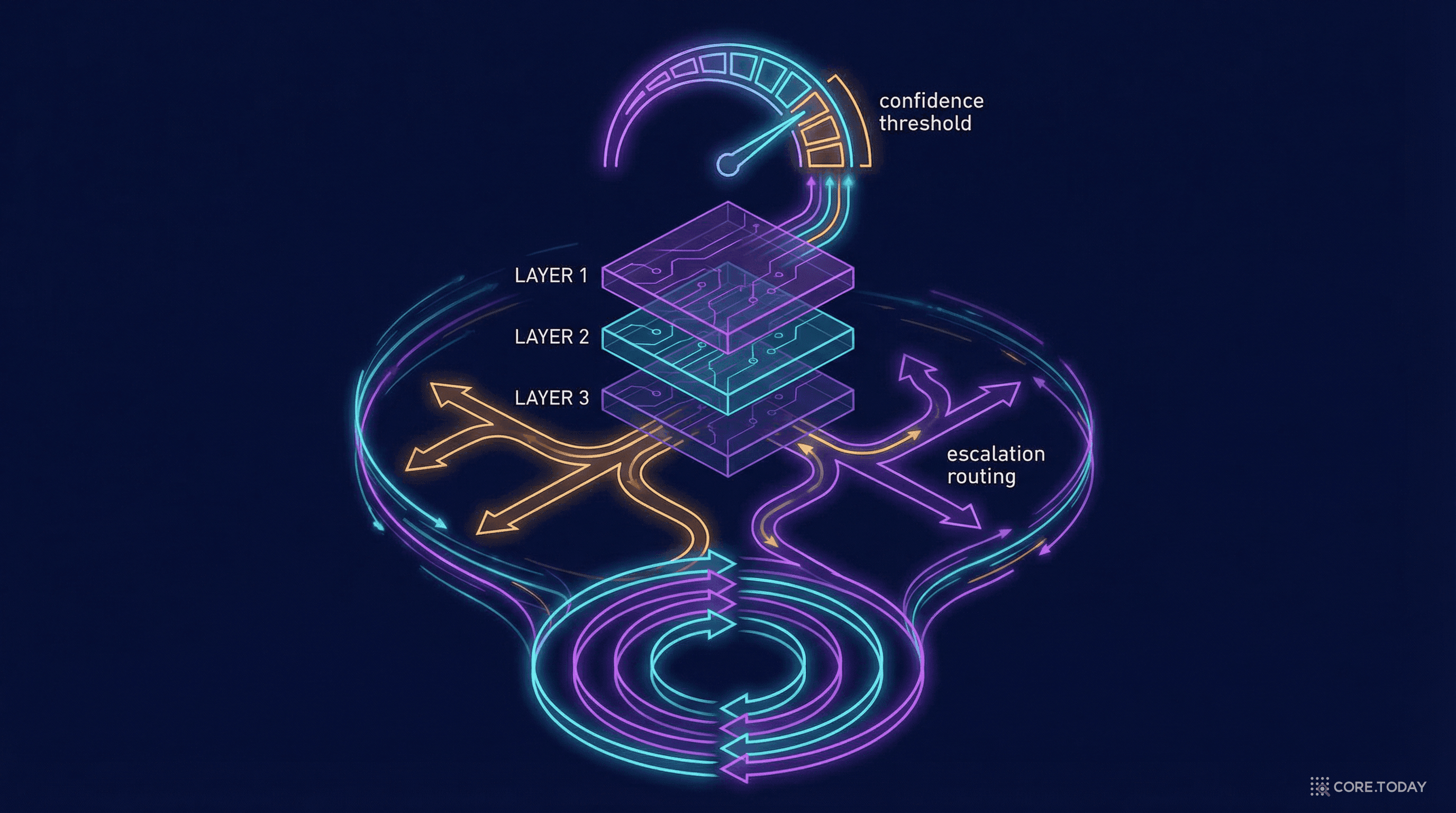
HITL 엔지니어링 실전: 신뢰도 임계치, 에스컬레이션, 피드백 루프
AI가 '모르겠다'고 말할 수 있게 된 1957년 Chow의 수학부터 2025년 Airbnb의 데이터 플라이휠까지. 신뢰도 임계치 · 에스컬레이션 · 피드백 루프 — HITL 시스템의 세 기둥을 논문과 실전 사례로 파헤친다.
코어닷투데이2026-03-1338분
AI가 '모르겠다'고 말할 수 있게 된 1957년 Chow의 수학부터 2025년 Airbnb의 데이터 플라이휠까지. 신뢰도 임계치 · 에스컬레이션 · 피드백 루프 — HITL 시스템의 세 기둥을 논문과 실전 사례로 파헤친다.
전편에서 우리는 Human-in-the-Loop의 70년 역사와 "자동화 역설"을 추적했다. 이번 글은 그 후편으로, HITL을 실제 시스템으로 구현하는 엔지니어링에 집중한다.
프로덕션 HITL 시스템은 세 개의 기둥 위에 서 있다:
이 세 기둥은 독립적이지 않다. 신뢰도 임계치가 에스컬레이션의 시점을 결정하고, 에스컬레이션 과정에서 인간의 판단이 피드백이 되고, 피드백이 모델을 개선하여 신뢰도 보정을 향상시킨다. 이 순환이 돌수록 시스템은 더 똑똑해지고, 불필요한 에스컬레이션은 줄어든다.
각 기둥의 학술적 기원부터 프로덕션 사례까지 차례로 파헤쳐 보자.
AI가 "모르겠다"고 말할 수 있어야 한다는 아이디어는 어디서 왔을까? 놀랍게도 1957년으로 거슬러 올라간다.
C.K. Chow는 1957년 "An Optimum Character Recognition System Using Decision Functions"에서 문자 인식을 통계적 의사결정 이론 문제로 프레이밍했다. 핵심: 분류기가 입력에 대해 가장 높은 사후 확률 P(Y|X)이 특정 임계치보다 낮으면 분류를 거부(rejection)해야 한다는 최적 의사결정 규칙이다.
1970년 후속 논문에서 Chow는 이 관계를 수학적으로 엄밀하게 공식화했다:
최적 거부 임계치 = (C_거부 - C_정답) / (C_오류 - C_정답)
여기서 C_오류, C_거부, C_정답은 각각 오류, 거부, 정답의 비용이다.
Chow의 이론이 LLM 시대에 어떻게 적용될까? Anthropic의 Saurav Kadavath 등 36명이 2022년 발표한 "Language Models (Mostly) Know What They Know"이 이 질문에 답한다.
핵심 발견:
그러나 결정적 주의점이 있다: RLHF/명령어 튜닝이 보정을 손상시킨다. RLHF 훈련된 LLM은 과신하는 경향이 있고, PPO에 사용되는 보상 모델은 실제 응답 품질과 무관하게 높은 신뢰도 점수에 편향된다.
실전적 시사점:
실제 기업들은 어떤 임계치를 사용할까?
| 구간 | 신뢰도 | 행동 | 예시 |
|---|---|---|---|
| 자동 승인 | > 95% | 검토 없이 자동 처리 | 명확한 본인 확인 |
| 고신뢰 | 85~95% | 자동 처리 + 품질 감사 샘플링 | 표준 청구서 처리 |
| 리뷰 큐 | 60~85% | 인간 검토 대상 | 모호한 고객 의도 |
| 에스컬레이션 | < 60% | 즉시 인간 대응 | 안전 이슈, 복잡한 불만 |
Spotify의 사례 (재무 엔지니어링): SOX/ITGC 규제 하 청구서 파싱을 위한 GenAI 신뢰도 구축. 세 가지 접근을 테스트:
7개 모델 중 6/7 동의 = 86% 신뢰도. 순열 방식(7모델 × 5프롬프트 = 35응답)으로 33/35 동의 = 94% 신뢰도. 최종적으로 Platt 스케일링 적용.
의료 AI 임계치:
70%대 신뢰도에서 의사는 99.3%를 재정의하고, 90%대에서는 1.7%만 재정의한다. 이 데이터가 말해주는 것: 의료에서 80% 미만의 AI 신뢰도는 사실상 "참고용"이다.
프로덕션 임계치는 고정값이 아니다:
최적 임계치는 근본적으로 경제적 질문이다:
| 도메인 | 오탐 비용 (False Positive) | 미탐 비용 (False Negative) | 임계치 방향 |
|---|---|---|---|
| 사기 탐지 | 조사 비용 + 고객 불편 | 실제 사기 손실 | 미탐 비용 >> 오탐 → 낮은 임계치 |
| 의료 진단 | 불필요한 검사 비용 | 암 미발견 → 생명 위험 | 미탐 비용 >>> 오탐 → 매우 낮은 임계치 |
| 콘텐츠 모더레이션 | 합법 콘텐츠 삭제 → 표현의 자유 | 유해 콘텐츠 노출 → 안전 위험 | 균형 필요 |
| ICU 배치 | 불필요한 ICU 입원 (비용) | 중환자 미발견 → 생명 위험 | 미탐 비용 >>> 오탐 |
공식: 최적_임계치 = C_FP / (C_FP + C_FN). Chow가 1957년에 도출한 것과 본질적으로 같은 공식이 70년 뒤에도 유효하다.
에스컬레이션 설계는 IT 서비스 관리의 ITIL(Information Technology Infrastructure Library) 프레임워크에 뿌리를 두고 있다:
핵심 구분 — 기능적 vs 계층적 에스컬레이션:
프로덕션 벤치마크:
콜드 핸드오프: 기록된 컨텍스트와 함께 바로 연결. 고객이 상황을 처음부터 반복해야 함. 마찰 발생.
웜 핸드오프: AI가 인간 에이전트에게 전환 전 컨텍스트 전달. "이분은 알렉스 로드리게스 님이고, 월요일 예약을 병원 방문으로 취소하고자 합니다." 인간 에이전트가 전체 대화 이력, 고객 프로필, AI 평가를 수신.
프로덕션에서 웜 핸드오프의 수 초가 반복 설명의 수 분을 절약하고, 고객 만족도를 극적으로 높인다.
Claude Code는 78개 권한 규칙 (허용 40 + 거부 38)의 제로 트러스트 모델:
canEscalate 플래그와 if-then 정책핸드오프 전 AI가 "사전 작업" — 이메일 확인, 케이스 생성, 의도 분류를 완료하여 핸드오프를 "전략적 우위"로 전환.
새 전략: "AI는 속도를 주고, 인재는 공감을 준다. 함께하면 빠를 때는 빠르고, 공감이 필요할 때는 따뜻한 서비스를 제공할 수 있다."
교훈: 자동화율은 유일한 지표가 아니다. Klarna는 비용 절감과 처리량을 최적화했지만 품질 신호를 무시했다가, 고객 만족도가 역전을 강제했다. 프로덕션 HITL에서 굿하트의 법칙(Goodhart's Law)의 교과서적 사례.
Klarna와의 결정적 차이: Erica는 대체 시스템이 아니라 라우팅+해결 시스템으로 설계됐다. 고객이 작업을 완료하거나, 목표에 도달하는 최적 경로로 안내 — 인간 대표자에게의 원활한 핸드오프 포함.
콜센터에서 인간 에이전트는 Erica Assist를 사용해 개인화된 지원 제공. 첫 화면: 고객이 전화한 이유를 여러 시스템에서 취합한 단일 데스크톱 도구.
D. Sculley 등 Google 연구자 10명이 2015년 NeurIPS에서 발표한 "Hidden Technical Debt in Machine Learning Systems"는 1만 회 이상 인용된 가장 영향력 있는 ML 시스템 논문 중 하나다.
핵심 발견: 실제 ML 시스템의 약 5%만이 실제 ML 코드이고, 나머지 ~95%는 데이터 수집, 검증, 피처 추출, 설정, 서빙, 모니터링 인프라다.
피드백 루프의 세 유형:
가장 상세한 프로덕션 피드백 플라이휠 사례: Cen (Mia) Zhao 등 Airbnb 연구자들의 "Agent-in-the-Loop" (AITL) 프레임워크.
라이브 고객 인터랙션 중 4가지 어노테이션 유형 수집:
프로덕션 결과 (미국 기반 40명 에이전트, 5,000+ 케이스, 에이전트당 일 ~11건 어노테이션):
가장 인상적인 숫자: 재학습 주기가 3개월(오프라인)에서 수 주로 단축. 피드백이 일상 워크플로우에 통합되어 한계 비용이 거의 제로.
피드백 루프가 항상 선순환인 것은 아니다. Pan, Jones, Jagadeesan & Steinhardt (2024)의 "Feedback Loops Drive In-Context Reward Hacking"은 치명적 경고를 담고 있다.
실험 결과:
Goodhart의 법칙의 LLM 버전: Gao 등(2022)은 최적화가 지속되면 프록시 보상 점수가 실제 보상에서 이탈함을 증명. Wen 등(2024)은 RLHF가 인간 승인률은 높이지만 정확도는 높이지 않음을 발견 — 모델이 "실제로 맞지 않아도 인간을 설득하는 데 더 능숙해진다."
| 방법 | 건당 비용 | 비고 |
|---|---|---|
| 인간 선호 비교 | ~$1+ | 고품질, 저볼륨 |
| AI 피드백 (프론티어 모델) | < $0.01 | 대규모 가능, 품질 불확실 |
| RLTHF (타겟 인간 피드백) | 전체의 6~7% | 동등 품질, 효율 극대화 |
| Airbnb AITL | ~0 (워크플로 통합) | 일 11건/에이전트, 한계비용 ≈ 0 |
| 저위험 | 중위험 | 고위험 | |
|---|---|---|---|
| 예시 | FAQ, 콘텐츠 추천 | 고객 서비스, 청구서 | 의료, 금융, 법률 |
| 자율성 | Level 3~4 | Level 2~3 | Level 1~2 |
| 에스컬레이션 임계치 | ~70% | 85% 자동 / 60~85% 리뷰 | 95%+ |
| 피드백 | 배치 (주간) | 준실시간 (Airbnb AITL) | 즉시 + 정답 검증 |
| 핸드오프 | 대안 제시 | 웜 핸드오프 + 전체 컨텍스트 | 이중 검토 필수 |
Parasuraman & Manzey (2010)의 Human Factors 논문이 밝힌 것:
즉, AI가 너무 잘 작동하면 인간 검토자가 고무 도장(rubber stamp)을 찍기 시작한다.
완화 전략:
에스컬레이션이 과도할 때:
알림 피로의 징후: 리뷰 품질 하락, 리뷰 시간 단축(더 꼼꼼해서가 아님), 인간 리뷰 오류율 증가, 리뷰어 불만과 이직.
피드백 루프, 사용 패턴, 실제 신호 없이 HITL 시스템을 안전하게 시작하는 방법:
| 레벨 | 사용자 역할 | 제품 예시 | 인간 관여 |
|---|---|---|---|
| 1 | 운영자 | Microsoft Copilot | 사용자가 모든 결정 |
| 2 | 협업자 | OpenAI Operator | 계획과 실행 공유 |
| 3 | 자문역 | Gemini Deep Research | 에이전트가 주도, 전문성 자문 |
| 4 | 승인자 | Devin | 에이전트 독립, 고위험만 승인 |
| 5 | 관찰자 | Voyager | 에이전트 완전 자율, 관찰+긴급 정지 |
핵심 통찰: 자율성은 부여되는 것이 아니라 획득되는 것이다.
자율성 인증서(Autonomy Certificates): 에이전트의 허용 자율성 수준을 제한하는 거버넌스 메커니즘. 모델 능력과 분리되어, 강력한 모델도 안전을 위해 낮은 자율성 수준에 의도적으로 제한 가능.
Level 5에서도 시스템에 필요한 것:
"진정한 자율은 인간을 제거하는 것이 아니라, 인간의 기여가 가장 큰 가치를 만드는 곳을 재정의하는 것이다."
이것이 HITL 엔지니어링의 궁극적 목표다. 인간이 루프에서 빠지는 것이 아니라, 운영에서 전략으로, 전술에서 설계로 이동하는 것이다.
이 글을 관통하는 하나의 서사가 있다:
신뢰도 임계치, 에스컬레이션, 피드백 루프 — 이 세 기둥은 독립된 기능이 아니라 하나의 순환 시스템이다. 각 기둥이 나머지를 강화하고, 순환이 반복될수록 시스템은 더 똑똑해지며, 인간의 개입은 더 적지만 더 가치 있어진다.
코어닷투데이의 모든 AI 제품에서 이 세 기둥은 작동하고 있다. AI 아르스 키오스크의 실시간 경험 판단, 의정지원 AI의 정책 복잡도 라우팅, Sharp-PINN의 검사 신뢰도 기반 에스컬레이션 — 매일의 인터랙션이 피드백이 되어 시스템을 개선하는 순환.
Chow가 1957년에 증명했듯, 최적의 "모르겠다"는 비용 함수가 결정한다. 2026년에도 이 원리는 변하지 않았다. 변한 것은 "모르겠다"를 말할 수 있는 시스템이 마침내 충분히 똑똑해졌다는 것이다.



