
블로그로 돌아가기
경사하강법옵티마이저AdamSGD딥러닝 최적화
경사하강법의 모든 것: 공이 골짜기를 찾아가는 180년의 여정
1847년 코시가 '가장 가파른 내리막으로 걸어라'고 제안한 이래, 경사하강법은 모멘텀을 얻고, 적응적 학습률을 갖추고, AI가 스스로 발견하는 단계까지 진화했다. 손실 지형 위를 굴러가는 공의 180년 여정을 추적한다.
코어닷투데이2025-06-1024분
1847년 코시가 '가장 가파른 내리막으로 걸어라'고 제안한 이래, 경사하강법은 모멘텀을 얻고, 적응적 학습률을 갖추고, AI가 스스로 발견하는 단계까지 진화했다. 손실 지형 위를 굴러가는 공의 180년 여정을 추적한다.

안개가 자욱한 산에서 눈을 감고 있다고 상상해 보자. 목표는 가장 낮은 골짜기를 찾는 것이다. 지도도, GPS도 없다. 할 수 있는 것은 딱 하나 — 발밑의 경사를 느끼고, 가장 가파른 내리막 방향으로 한 걸음 내딛는 것.
이것이 경사하강법(Gradient Descent) 의 전부다. 180년 전에 만들어진 이 단순한 아이디어가, 오늘날 GPT, DALL-E, AlphaFold 등 모든 딥러닝 모델을 학습시키는 핵심 엔진이다.
단순해 보이지만, 이 길에는 함정이 가득하다. 얕은 웅덩이에 빠져 진짜 골짜기를 놓치고(지역 최솟값), 평평한 고원에서 길을 잃고(안장점), 너무 큰 걸음으로 골짜기를 뛰어넘기도 한다(발산). 180년간의 혁신은 이 함정들을 하나씩 극복해 온 과정이다.
오귀스탱루이 코시(Augustin-Louis Cauchy) 는 1847년 10월 18일, 프랑스 학술원에 "Méthode générale pour la résolution des systèmes d'équations simultanées"를 발표했다.
코시의 동기는 천문학이었다. 행성 궤도를 계산하려면 6개의 미지수를 가진 연립방정식을 풀어야 했는데, 직접 풀기엔 너무 복잡했다. 그의 제안: 변수를 편미분의 양의 배수만큼 빼면서 반복적으로 갱신하라.
x_{t+1} = x_t - α · ∇f(x_t)
이것이 최급강하법(method of steepest descent) — 경사하강법의 최초 공식화다.
61년 뒤인 1908년, 자크 아다마르(Jacques Hadamard) 가 탄성판 평형 문제에서 독립적으로 경사 기반 방법을 개발했다.
함수 f(x)의 기울기 ∇f(x)는 f가 가장 빠르게 증가하는 방향을 가리킨다. 우리는 f를 최소화하고 싶으므로, 기울기의 반대 방향으로 이동한다. 학습률 α는 한 걸음의 크기를 결정한다.
1951년, 허버트 로빈스(Herbert Robbins) 와 서턴 먼로(Sutton Monro) 가 The Annals of Mathematical Statistics에 "A Stochastic Approximation Method"을 발표했다. 이것이 확률적 경사하강법(SGD) 의 이론적 기초다.
| 배치 경사하강법 | 확률적 경사하강법 (SGD) |
|---|---|
| 전체 데이터의 기울기를 계산 후 한 걸음 | 하나의 샘플(또는 미니배치)로 기울기 추정 후 한 걸음 |
| 정확하지만 느림 | 부정확하지만 빠름 |
| 결정론적 경로 | 노이즈가 포함된 확률적 경로 |
직관에 반하지만, SGD의 노이즈는 축복이다:
로빈스-먼로 조건이 수렴을 보장한다: 학습률 α_t의 합은 무한(어디든 도달 가능), α_t²의 합은 유한(노이즈 감쇠).
1986년, 루멜하트, 힌턴, 윌리엄스가 Nature에 역전파를 발표하면서, 경사하강법은 신경망 학습의 핵심 엔진이 되었다. 역전파가 "기울기를 계산하는 방법"이라면, 경사하강법은 "그 기울기로 가중치를 갱신하는 방법"이다.
1998년, 르쿤(LeCun) 등의 "Efficient BackProp"이 실전적 노하우를 집대성했다: 입력 정규화, 가중치 초기화, 학습률 스케줄, 모멘텀. 르쿤은 모멘텀 계수 μ로 학습하는 것이 학습률 1/(1-μ)로 모멘텀 없이 학습하는 것과 동치임을 보였다.
소련 수학자 보리스 폴리악(Boris Polyak) 은 1964년 중구법(heavy ball method) 을 제안했다. 아이디어는 물리학에서 왔다: 공이 언덕을 굴러갈 때, 관성(momentum) 이 있으면 얕은 골짜기를 통과하고, 작은 돌기를 넘어간다.
x_{t+1} = x_t - α · ∇f(x_t) + β · (x_t - x_{t-1})
β 항이 이전 이동의 일부를 현재에 더한다 — 이것이 모멘텀이다.
유리 네스테로프(Yurii Nesterov) 는 1983년 소련 학술원 회보에서 최적 수렴 속도 O(1/k²) 을 달성하는 가속 경사법을 증명했다 — 표준 경사하강법의 O(1/k)와 비교하면 근본적 가속이다.
네스테로프의 핵심 트릭: 폴리악은 현재 위치에서 기울기를 계산하지만, 네스테로프는 모멘텀이 데려갈 예상 위치에서 기울기를 계산한다. 마치 공이 "먼저 앞을 보고" 과도한 이동을 사전에 교정하는 것이다.
어떤 파라미터는 기울기가 항상 크고(자주 업데이트), 어떤 파라미터는 기울기가 거의 0이다(드물게 업데이트). 하나의 학습률로는 둘 다 만족시킬 수 없다.
두치(Duchi), 하잔(Hazan), 싱어(Singer) 가 JMLR 2011에 발표. 핵심: 과거 기울기의 제곱합을 누적해, 자주 큰 기울기를 받은 파라미터의 학습률을 자동으로 줄인다. 희소 데이터(추천 시스템, NLP)에 탁월. 약점: 누적합이 계속 커져 학습률이 결국 0으로 수렴.
제프리 힌턴(Geoffrey Hinton) 이 2012년 Coursera 강의 "Neural Networks for Machine Learning"의 Lecture 6.5에서 제안. 정식 논문으로 출판된 적이 없다 — 아마 역사상 가장 영향력 있는 미출판 알고리즘.
AdaGrad의 누적합 대신 지수이동평균을 사용해 학습률이 0으로 수렴하는 문제를 해결했다.
킹마(Kingma) 와 바(Ba) 가 2014년 12월 arXiv에 올린 "Adam: A Method for Stochastic Optimization"(ICLR 2015)은 이름 그대로 Adaptive Moment Estimation — RMSProp의 적응적 학습률(2차 모멘트)과 모멘텀(1차 모멘트)을 결합하고, 초기 편향 보정까지 추가한 것이다.
로쉴로프(Loshchilov) 와 후터(Hutter) 가 발견한 결정적 오류: L2 정규화와 가중치 감쇠는 SGD에서는 동치이지만, Adam에서는 아니다. Adam에서 L2 정규화는 적응적 학습률에 의해 왜곡되어, 자주 업데이트되는 파라미터에 대한 정규화가 약해진다.
AdamW는 가중치 감쇠를 기울기 기반 업데이트에서 분리(decouple) 하여 이 문제를 해결했다. 현재 거의 모든 LLM 학습의 표준 옵티마이저다.
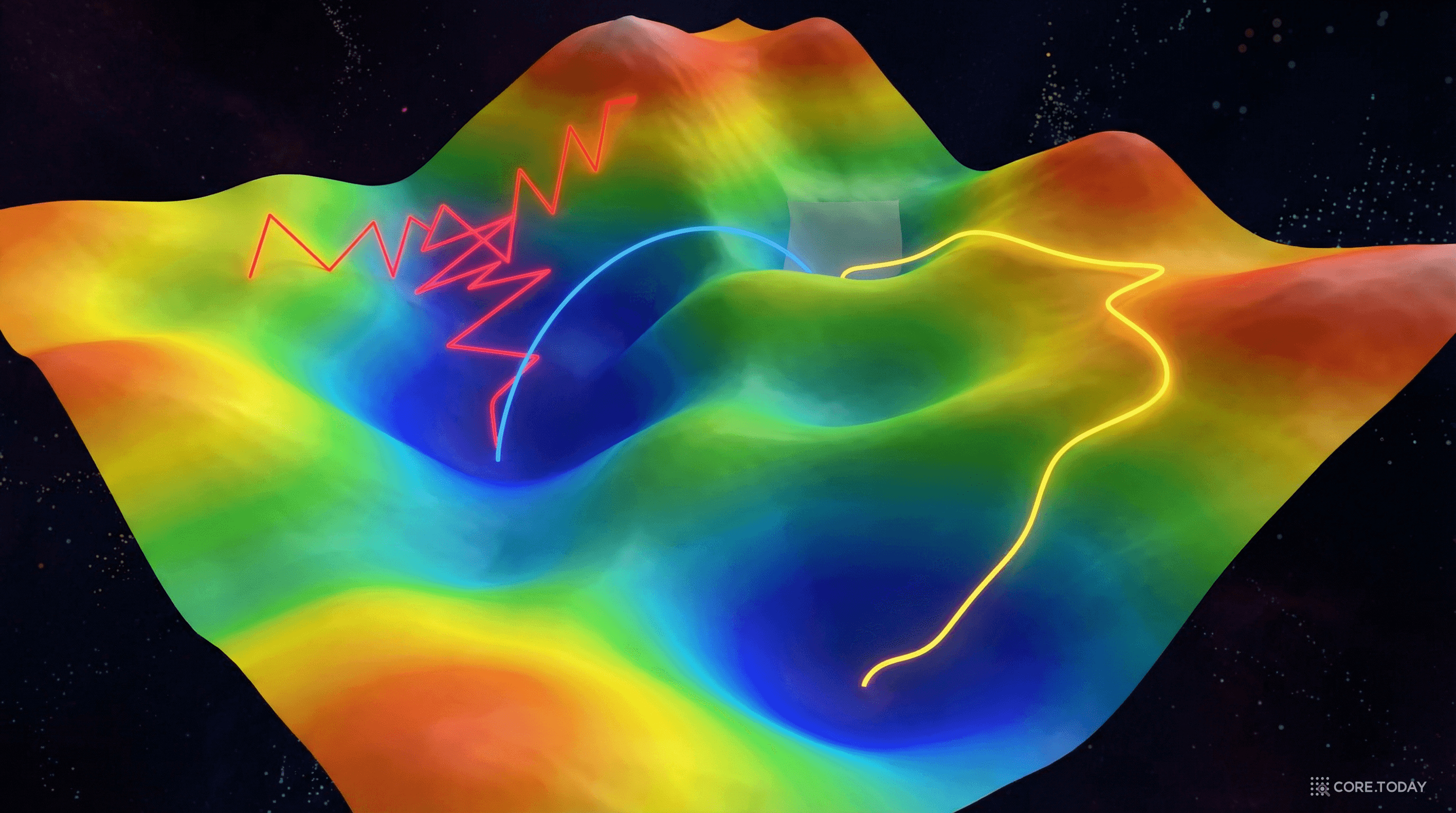
고차원 공간에서는 지역 최솟값보다 안장점(saddle point) 이 훨씬 더 큰 문제다. 도팡(Dauphin) 등이 NeurIPS 2014에서 증명한 것: 차원이 높아질수록 안장점과 지역 최솟값의 비율이 지수적으로 증가한다. 안장점은 어떤 방향으로는 내리막이지만, 다른 방향으로는 오르막인 지점이다 — 기울기가 0이라 경사하강법이 멈춰 버린다.
호크라이터와 슈미트후버 (1997) 는 "Flat Minima"에서 평평한 최솟값이 일반화에 유리하다고 주장했다 — MDL/베이지안 관점에서 평평한 영역이 더 단순한 모델에 해당하기 때문이다.
케스카르(Keskar) 등 (ICLR 2017) 은 경험적으로 확인했다:
SGD의 노이즈가 일종의 암묵적 정규화로 작용해, 평평한 최솟값을 선호하게 만드는 것이다.
벨킨(Belkin) 등 (PNAS, 2019) 이 발견한 이중 하강(double descent) 현상은 전통적 편향-분산 트레이드오프를 뒤집었다. 테스트 오차가 U자형으로 올라가다가, 보간 임계점에서 정점을 찍고, 모델이 더 커지면 다시 내려간다. 과대 파라미터화된 모델이 오히려 잘 일반화하는 이유를 설명했다.
"학습률은 딥러닝에서 단일 가장 중요한 하이퍼파라미터다." — 요슈아 벤지오 (2012)
레슬리 스미스(Leslie Smith) 의 학습률 탐색기(LR Finder) 는 실용적 걸작이다: 수백 반복 동안 학습률을 지수적으로 올리며 손실을 관찰하고, 손실이 가장 빠르게 줄어드는 지점(발산 직전)을 최적 학습률로 선택한다. fast.ai 라이브러리로 대중화되었다.
Google Brain의 천(Chen) 등이 NeurIPS 2023에 발표한 Lion(EvoLved Sign Momentum) 은 프로그램 탐색(진화 알고리즘) 으로 옵티마이저 프로그램 공간을 자동 탐색해 발견했다. 모멘텀의 부호(sign)만 사용하여 업데이트하므로 Adam보다 메모리 효율적이다. 확산 모델에서 최대 2.3배 계산 절감, ViT에서 ImageNet 정확도 2% 향상.
스탠퍼드의 리우(Liu) 등이 제안한 Sophia는 대각 헤시안 추정을 10스텝마다 가볍게 계산해 사전 조건화에 사용한다. GPT 모델(125M~1.5B) 학습에서 Adam 대비 2배 속도 — 같은 perplexity를 50% 적은 스텝으로 달성.
켈러 조던(Keller Jordan) 이 NanoGPT 스피드런 기록을 세우며 공개한 Muon(MomentUm Orthogonalized by Newton-Schulz) 은 네스테로프 모멘텀으로 계산한 업데이트를 뉴턴-슐츠 반복으로 직교화한다. AdamW 대비 35% 학습 속도 향상, bfloat16에서 안정적으로 동작, FLOP 오버헤드 1% 미만.
드파지오(Defazio) 등이 NeurIPS 2024에 발표한 Schedule-Free 옵티마이저는 학습률 스케줄을 완전히 제거했다. 스케줄링과 반복 평균화를 새로운 이론으로 통합한다. MLCommons 2024 AlgoPerf 챌린지에서 우승.
1847년 코시는 "가장 가파른 내리막으로 걸어라"고 했다. 그로부터 180년, 우리는 그 걸음에 관성을 주고(폴리악, 1964), 적응적 보폭을 부여하고(Adam, 2014), AI가 스스로 걷는 법을 발견하게 하고(Lion, 2023), 마침내 스케줄마저 제거했다(Schedule-Free, 2024).
하지만 본질은 변하지 않았다. 모든 딥러닝 모델의 학습은 여전히 같은 원리에 기반한다:
기울기를 계산하고, 그 반대 방향으로 한 걸음 내딛는다.
GPT가 다음 단어를 더 정확히 예측할 때, DALL-E가 더 선명한 이미지를 생성할 때, AlphaFold가 단백질 구조를 더 정밀하게 예측할 때 — 그 뒤에서 일어나는 일은 결국 수조 개의 파라미터가 손실 지형의 골짜기를 향해 한 걸음씩 내딛는 것이다.
코시가 행성 궤도를 계산하기 위해 만든 그 단순한 알고리즘이, 180년 뒤 인공지능의 모든 것을 가능하게 했다.



