Giveme5W1H — AI가 뉴스를 읽는 법: 육하원칙으로 해체하는 기사 분석의 모든 것
기자가 기사를 쓸 때 반드시 답하는 육하원칙(누가, 무엇을, 언제, 어디서, 왜, 어떻게) — 이걸 AI가 자동으로 추출할 수 있을까? 2019년 독일 콘스탄츠 대학 연구팀이 만든 Giveme5W1H 시스템의 원리부터 2026년 LLM 시대의 의미까지, 뉴스 이벤트 추출의 세계를 완전 해부한다.
코어닷투데이2026-04-1375분
들어가며: 뉴스 한 편을 읽을 때, 우리 뇌는 무엇을 하는가
아침에 스마트폰을 열면 수십 개의 뉴스가 쏟아진다. 우리는 무의식적으로 각 기사에서 핵심 정보를 추출한다:
"아, 미국 대통령이(누가) 관세를 인상했구나(무엇을), 어제(언제) 워싱턴에서(어디서) 무역 적자 때문에(왜) 행정명령을 통해서(어떻게)."
이 과정은 너무 자연스러워서 의식하지 못하지만, 사실 인간의 뇌는 매 기사마다 여섯 가지 질문에 답하고 있다. 저널리즘에서는 이것을 육하원칙(5W1H) — Who, What, When, Where, Why, How — 이라고 부른다.
그런데 하루에 생산되는 뉴스가 수십만 건이라면 어떨까? 인간이 일일이 읽을 수 없다. 그래서 연구자들은 오래전부터 물었다:
"컴퓨터가 뉴스 기사를 읽고, 육하원칙에 자동으로 답할 수 있을까?"
2019년, 독일 콘스탄츠(Konstanz) 대학의 Felix Hamborg 연구팀이 이 질문에 대한 최초의 범용적이고 오픈소스인 답을 내놓았다. 그 이름은 Giveme5W1H.
이 글에서는 논문 "Giveme5W1H: A Universal System for Extracting Main Events from News Articles"를 중심으로, 왜 이런 시스템이 필요한지, 어떻게 작동하는지, 그리고 2026년 LLM 시대에 이 기술이 어떤 의미를 갖는지를 자세히, 쉽고, 재밌게 풀어본다.
제1장: 육하원칙의 기원 — 2,000년 전 로마에서 시작된 질문법
고대 수사학에서 탄생한 프레임워크
육하원칙의 역사는 놀라울 정도로 오래됐다. 기원전 1세기, 로마의 수사학자 헤르마고라스(Hermagoras of Temnos)는 연설을 구성할 때 반드시 답해야 할 질문들을 정리했다:
Quis, quid, quando, ubi, cur, quem ad modum, quibus adminiculis
(누가, 무엇을, 언제, 어디서, 왜, 어떻게, 무엇으로)
이 일곱 가지 질문은 중세를 거치며 저널리즘의 핵심 원칙으로 자리 잡았다. 19세기 미국 신문 산업이 폭발적으로 성장하면서, "좋은 기사의 첫 문단(리드)은 반드시 5W1H에 답해야 한다"는 것이 기자 교육의 기본이 되었다.
역피라미드 구조: 가장 중요한 것을 먼저
뉴스 기사는 역피라미드(Inverted Pyramid) 구조를 따른다. 가장 중요한 정보가 기사의 맨 위(헤드라인과 리드 문단)에 오고, 아래로 갈수록 부가 정보와 배경이 나온다. 이 구조가 중요한 이유는:
📰
역피라미드가 왜 존재하는가?
원래 전신(telegraph) 시대에 통신이 끊길 수 있었기 때문에, 가장 중요한 정보를 먼저 보냈다. 또한 신문 편집자가 지면이 부족하면 기사 뒤쪽을 잘라냈기 때문에, 핵심 정보가 앞에 있어야 했다.
💡
AI 추출에 주는 힌트
역피라미드 구조 덕분에, 기사 앞부분에 나오는 정보일수록 주요 이벤트를 설명할 가능성이 높다. Giveme5W1H는 이 저널리즘 원칙을 직접 스코어링 알고리즘에 반영한다.
이렇게 2,000년 넘게 이어진 프레임워크가 이제 기계가 뉴스를 이해하는 언어가 되려 하고 있다.
제2장: 왜 자동 5W1H 추출이 필요한가? — 실제 사례로 보는 문제
사례 1: 뉴스 클러스터링
2016년 11월, 아프가니스탄 마자르이샤리프에서 탈레반이 독일 영사관을 공격했다. 이 사건 하나를 두고 수십 개 언론사가 각자의 기사를 쏟아냈다. Reuters, AP, BBC, Al Jazeera, 현지 언론까지.
뉴스 집계 서비스(Google News, Naver News 등)는 이 기사들을 같은 사건에 대한 기사로 묶어야 한다. 어떻게? 각 기사에서 누가(탈레반), 무엇을(공격), 언제(2016-11-10), 어디서(마자르이샤리프)를 추출해서 비교하면 된다.
사례 2: 미디어 편향 분석
같은 사건이라도 언론사마다 다르게 프레이밍한다:
질문
A 언론사
B 언론사
Who
"무장 세력"
"탈레반 테러리스트"
What
"건물 손상"
"치명적 자살 폭탄 공격"
Why
"지역 불안정"
"서방 세력에 대한 보복"
5W1H 추출을 자동화하면, 같은 사건에 대해 언론사마다 어떻게 다르게 표현하는지 대규모로 분석할 수 있다. Hamborg 연구팀이 바로 이런 미디어 편향(media bias) 연구를 위해 이 시스템을 만들었다.
사례 3: 재난 대응
지진, 홍수, 테러 등 재난 발생 시 실시간으로 쏟아지는 뉴스에서 "어디서, 언제, 어떤 규모로" 발생했는지 자동 추출하면, 구호 기관이 더 빠르게 대응할 수 있다.
제3장: 기존 방법들의 한계 — 왜 "범용적 시스템"이 없었는가
Giveme5W1H 논문이 지적한 기존 연구의 세 가지 한계를 정리하면 이렇다:
한계 1
암묵적(implicit) 이벤트 감지만 수행 — 토픽 모델링 등으로 "이 기사는 경제 관련"이라고 분류하지만, 구체적으로 "누가 무엇을 했다"는 추출하지 못했다.
한계 2
특정 도메인에만 특화 — 예: 재난 뉴스에서 "사상자 수"만 추출하는 시스템. 스포츠나 정치 뉴스에는 쓸 수 없다.
한계 3
비공개 또는 재현 불가능 — 논문에서 높은 성능을 보고했지만, 코드를 공개하지 않거나 방법론 설명이 불충분해서 재현이 불가능했다.
특히, 당시(2019년) 최고 성능을 보인 Yaman et al. (2009)의 시스템은 4W 정밀도 P4W=0.89를 달성했지만, 10년이 넘은 비공개 시스템이었고, 평가 방법도 달라 직접 비교가 어려웠다.
논문의 저자들은 이 세 가지 한계를 동시에 해결하려 했다:
범용성
뉴스 카테고리에 무관하게 작동
명시적 추출
구체적 문구를 추출
오픈소스
GitHub에 완전 공개
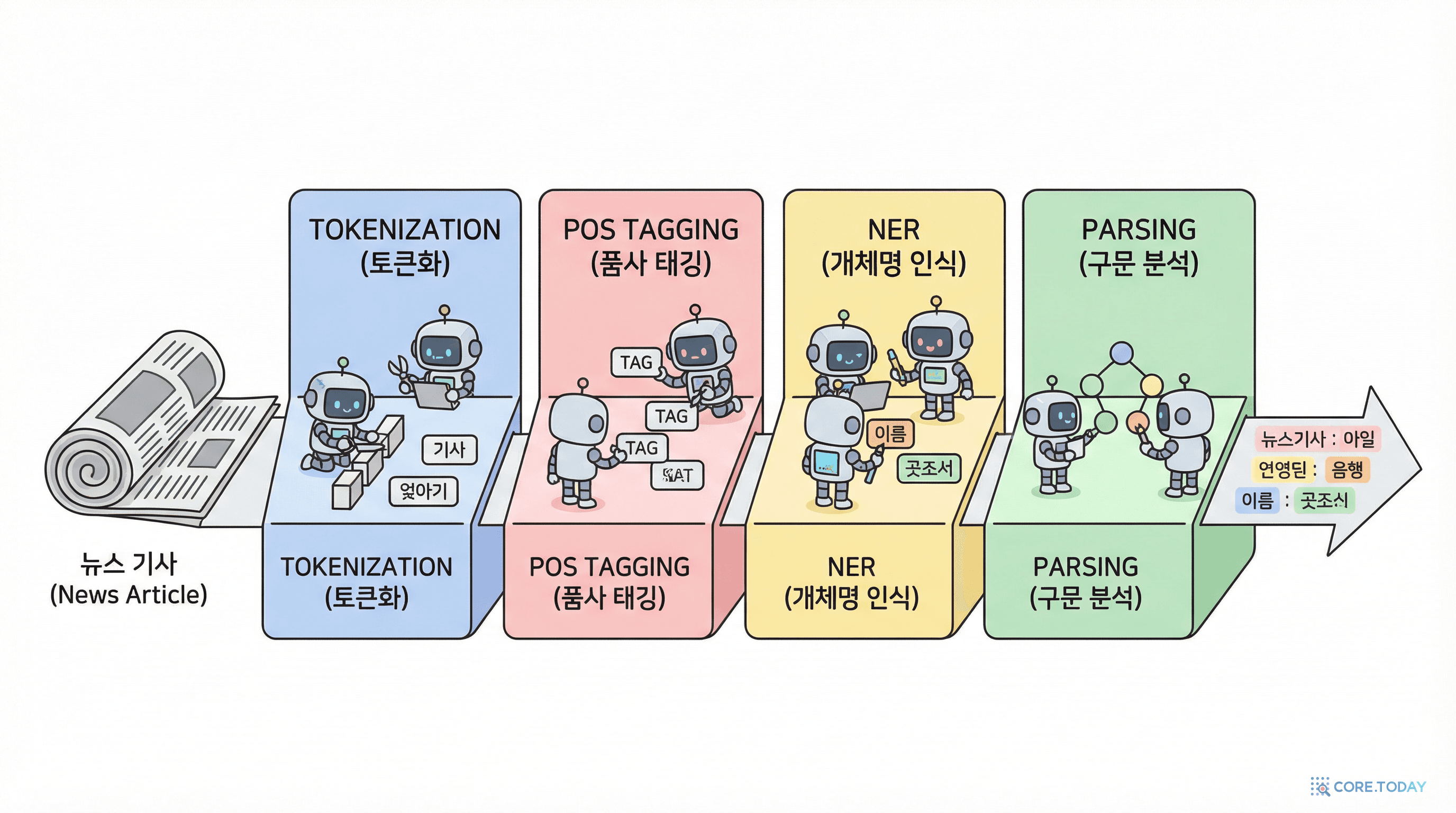
제4장: Giveme5W1H의 작동 원리 — 3단계 파이프라인
Giveme5W1H 시스템은 세 단계로 뉴스 기사를 분석한다. 마치 숙련된 편집자가 기사를 읽는 과정을 기계적으로 모방한 것이다.
Phase 1 전처리 Preprocessing
→
Phase 2 문구 추출 Phrase Extraction
→
Phase 3 후보 점수화 Candidate Scoring
Phase 1: 전처리 — 기사를 "이해 가능한 형태"로 분해
원시 텍스트가 들어오면, Stanford CoreNLP를 사용해 다음 작업을 순차적으로 수행한다. 마치 작은 로봇 팀이 각자의 역할을 맡아 텍스트를 분석하는 것과 같다:
전처리 파이프라인
문장 분리
Sentence Splitting
토큰화
Tokenization
품사 태깅
POS Tagging
구문 분석
Full Parsing
개체명 인식
NER (7-class)
상호참조 해결
Coreference Resolution
여기서 특히 중요한 것이 상호참조 해결(Coreference Resolution)이다. 예를 들어:
상호참조 해결 예시
원문
"바이든 대통령이 새로운 관세를 발표했다. 그는 이것이 미국 산업을 보호할 것이라고 말했다."
해결 후
"바이든 대통령이 새로운 관세를 발표했다. 바이든 대통령은 이것이 미국 산업을 보호할 것이라고 말했다."
"그는"이 "바이든 대통령"을 가리킨다는 것을 컴퓨터가 이해해야 Who 질문에 정확히 답할 수 있다.
정규화(Canonicalization): 같은 것을 같은 형태로
전처리 후, 추출된 개체(entity)를 표준 형태(canonical form)로 변환한다. 논문에서는 세 가지 정규화를 수행한다:
유형
도구
변환 예시
시간
SUTime → TIMEX3
"어제 오후 1시" → 2016-11-10T13:00
장소
Nominatim (OpenStreetMap)
"Mazar-i-Sharif" → 36.7°N, 67.1°E
인물/조직
AIDA → YAGO 지식그래프
"트럼프" → YAGO:Donald_Trump
이 정규화가 왜 중요한가? "yesterday", "last night", "the previous day"는 모두 같은 날짜를 가리킬 수 있다. 정규화를 통해 다른 표현이지만 같은 의미인 것들을 통일한다.
Phase 2: 문구 추출 — 4개의 독립적 추출 체인
Phase 2에서는 네 개의 독립적인 추출기가 각각 후보 문구를 추출한다:
4개 추출 체인
행위 추출기
Action Extractor
Who + What
환경 추출기
Environment Extractor
When + Where
원인 추출기
Cause Extractor
Why
방법 추출기
Method Extractor
How
각 추출기가 어떻게 작동하는지 하나씩 살펴보자.
행위 추출기 (Action Extractor): Who + What
핵심 아이디어: 각 문장의 주어(Subject)가 Who 후보, 술어(Predicate)가 What 후보다.
구문 분석 트리(parse tree)에서 다음 규칙을 적용한다:
Who 추출 규칙
규칙 1
문장의 최상위 NP(명사구)를 찾되, 오른쪽 형제가 VP(동사구)인 것만 선택
규칙 2
하위에 VP를 포함하는 NP는 제거 (너무 긴 문구 방지)
결과
"The Taliban" → Who 후보로 추출
What 추출은 VP에서 수행하되, VP가 너무 길면 자식 NP 이후를 잘라낸다. 단, VP가 3개 이하의 토큰이면서 전치사구(PP)가 뒤따르면 잘라내지 않는다 — 정보가 너무 적어지는 것을 방지하기 위해서다.
이해를 돕기 위해 실제 예시를 보자:
실제 추출 예시 — 탈레반 영사관 공격 기사
원문 문장
"The Talibanattacked the German consulate in Mazar-i-Sharif, Afghanistan, on November 10, 2016."
추출 결과
■Who: The Taliban ■What: attacked the German consulate ■Where: Mazar-i-Sharif (→ 36.7°N, 67.1°E) ■When: November 10, 2016 (→ TIMEX3)
원인 추출기 (Cause Extractor): Why
"왜" 질문은 가장 어려운 추출 대상이다. Giveme5W1H는 세 가지 인과관계 지표를 찾는다:
유형 1
인과 접속사 — "because", "due to", "as a result of" 등. 접속사 뒤의 절이 Why 후보가 된다. 가장 신뢰도가 높다.
유형 2
인과 부사 — "therefore", "hence", "thus" 등. 부사 앞의 절이 원인이 된다.
"The attack was carried out because of growing tensions in the region."
여기서 "because of" 다음에 오는 "growing tensions in the region"이 Why 후보가 된다.
방법 추출기 (Method Extractor): How
How 추출은 두 가지 전략을 사용한다:
접속 구문 분석 — "after", "by" 같은 접속사 뒤의 절을 추출 (최대 10토큰으로 제한)
형용사/부사 추출 — 행위를 수식하는 형용사나 부사를 추출 (폴백 전략)
Phase 3: 후보 점수화 — 누가 "정답"인가
Phase 2에서 추출된 후보는 보통 여러 개다. 기사에서 "the Taliban"이 Who로 추출될 수도 있고, "Afghan security forces"가 추출될 수도 있다. 어떤 후보가 주요 이벤트를 가장 잘 설명하는가?
Giveme5W1H는 각 질문별로 가중치가 다른 점수화 함수를 사용한다:
sq,c=∑iwq,i⋅sq,i(c)
여기서 sq,c는 질문 q에 대한 후보 c의 점수, wq,i는 i번째 점수화 인자의 가중치다.
각 질문별로 어떤 인자를 사용하는지 보자:
Who 점수화: "누가" 가장 중요한 인물인가
위치 (앞에 나올수록)
w = 0.46
개체명 여부
w = 0.31
빈도 (자주 언급될수록)
w = 0.23
위치(Position): 역피라미드 원칙 — 기사 앞부분에 등장할수록 높은 점수
개체명(NE): "the Taliban"처럼 고유명사이면 가산점 — 뉴스에서 주요 행위자는 대부분 고유명사
빈도(Frequency): 기사 전체에서 자주 언급될수록 주요 행위자일 가능성이 높음
When 점수화: "언제"가 사건 시점인가
When은 네 가지 인자를 사용한다. 특히 흥미로운 것은 기사 발행일과의 근접성(closeness) 인자다:
발행일 근접성
w = 0.40
위치 (앞에 나올수록)
w = 0.24
짧은 지속시간
w = 0.20
빈도
w = 0.16
발행일 근접성은 뉴스의 본질을 반영한다 — 뉴스는 최근에 일어난 일을 보도한다. "1990년대 냉전 시대"보다 "어제 오후"가 기사의 주요 이벤트 시점일 가능성이 훨씬 높다.
짧은 지속시간 인자는 "어제"(하루)가 "지난 10년간"보다 높은 점수를 받도록 한다. 이벤트는 특정 시점에 일어나기 때문이다.
Where 점수화: 얼마나 구체적인 장소인가
위치 (앞에 나올수록)
w = 0.37
빈도
w = 0.30
지리적 포함관계
w = 0.30
구체성
w = 0.03
지리적 포함관계(containment)가 흥미롭다. "마자르이샤리프"가 "아프가니스탄" 안에 포함되므로, 더 구체적인 "마자르이샤리프"가 높은 점수를 받는다. 구체성은 해당 장소의 면적으로 계산한다 — 225m²(작은 부지) ~ 530,000km²(국가 평균 면적) 범위에서 로그 정규화한다.
Why & How: 왜 가장 어렵고, 어떻게 점수화하는가
인자
Why 가중치
How 가중치
위치
0.56
0.23
인과/방법 유형 신뢰도
0.44
0.63
빈도
-
0.14
Why에서는 인과관계 유형의 신뢰도가 중요하다:
접속사 "because" → 신뢰도 1.0 (거의 확실히 원인)
부사 "therefore" → 신뢰도 0.62
인과 동사 "trigger" → 신뢰도 0.06 (거짓 양성 많음)
How에서는 방법 유형 신뢰도가 가장 높은 가중치(0.63)를 받는다.
결합 점수화 (Combined Scoring)
마지막으로, 서로 다른 질문의 후보들 사이의 관계를 활용한다. "방법(how)"은 "행위(what)"와 같은 문장에 있을 가능성이 높다는 가정 하에:
방법 후보 c와 행위 후보 a 사이의 문장 거리가 멀수록 점수를 감점한다. "어떻게 했는지"는 "무엇을 했는지"와 가까이 언급되기 마련이라는 직관을 수학적으로 표현한 것이다.
제5장: 성능 평가 — 숫자로 보는 Giveme5W1H
평가 방법
BBC 뉴스 데이터셋에서 120개 기사를 5개 카테고리(비즈니스, 엔터테인먼트, 정치, 스포츠, 기술)에서 추출하고, 3명의 평가자가 각 기사에서 추출된 5W1H 문구의 관련성을 3점 척도로 평가했다:
1.0 — 완전히 관련 있고 정확함
0.5 — 부분적으로 관련 있거나 정보 누락
0.0 — 관련 없음
전체 결과
0.82
4W 평균 정밀도
Who + What + When + Where
0.73
전체 6Q 평균 정밀도
5W1H 전체
질문별 상세 성능
Who (누가)
0.77 Good
When (언제)
0.77 Good
Where (어디서)
0.68 Fair
What (무엇을)
0.57 Fair
How (어떻게)
0.42 Challenging
Why (왜)
0.28 Difficult
카테고리별 상세 성능
카테고리
Who
What
When
Where
Why
How
비즈니스
0.85
0.69
0.89
0.83
0.42
0.21
엔터테인먼트
0.89
0.70
0.93
0.79
0.29
0.40
정치
0.85
0.42
0.63
0.49
0.17
0.58
스포츠
0.47
0.38
0.58
0.45
0.13
0.53
기술
0.80
0.67
0.81
0.86
0.41
0.40
성능 패턴 분석
📊
엔터테인먼트가 가장 높은 이유
엔터테인먼트 기사는 보통 하나의 명확한 이벤트(시상식, 앨범 출시 등)를 다루고, 주요 행위자가 명확하다. When 정밀도 0.93은 전체 최고 수치다.
⚽
스포츠가 가장 낮은 이유
스포츠 기사는 과거 경기 기록, 선수 이력 등 배경 정보가 많아 주요 이벤트와 부수적 정보를 구별하기 어렵다. Who 정밀도 0.47은 전체 최저 수치다.
❓
Why가 전체적으로 낮은 이유
많은 기사가 원인을 명시적으로 서술하지 않는다. "왜 그런 일이 일어났는가"는 기사 전반에 암시될 뿐, "because..."로 시작하는 깔끔한 문장이 드물다.
제6장: 논문의 핵심 설계도 — 시스템 아키텍처 도해
논문의 Figure 2에 제시된 시스템 아키텍처를 재구성하면 다음과 같다:
Raw Article Python / REST API
↓
Phase 1: Preprocessing
↓
Phase 1 상세
CoreNLP
문장분리 · 토큰화 · POS · 구문분석 · NER · 상호참조
SUTime
시간 → TIMEX3
Nominatim
장소 → 좌표
AIDA
개체 → YAGO
↓
Phase 2: Phrase Extraction
↓
Phase 2 상세
Action
Who · What
Environment
When · Where
Cause
Why
Method
How
↓
Phase 3: Candidate Scoring
↓
Phase 3 상세
개별 점수화
질문별 가중치 합산
결합 점수화
질문 간 교차 참조
5W1H Output
정규화된 구조화 결과
제7장: 파라미터 학습 — "최적의 가중치"는 어떻게 찾았나
데이터셋 구축
논문 저자들은 자체 어노테이션 데이터셋을 구축했다:
100
어노테이션된 기사 수
13
미국·영국 주요 언론사
5
뉴스 카테고리
3
어노테이터 수
어노테이션 품질 관리
3명의 대학원생(IT 전공, 22-32세)이 독립적으로 각 기사의 5W1H 문구를 어노테이션했다. 평가자 간 일치도(inter-rater reliability)는 κCR=0.81로, "거의 완전한 일치(almost perfect agreement)"에 해당한다.
불일치가 있을 경우 다음 규칙으로 조합했다:
어노테이션 조합 규칙
3명 일치
의미적으로 동일하면, 가장 간결한 문구를 선택
2명 일치
2명이 일치하는 문구 채택
전원 불일치
3개 모두 유효한 답으로 포함 (의미적으로 다르지만 각각 타당한 경우)
최적화 과정
60/40 비율로 학습/테스트 세트를 나누고, 텍스트 후보(Who, What, Why, How)에는 Word Mover's Distance(WMD) — 두 문구의 의미적 유사도를 측정하는 최신 기법 — 를, When에는 초 단위 차이를, Where에는 미터 단위 거리를 오차 함수로 사용했다.
5,000개의 최적 파라미터 구성 중 통계적으로 유의미한 차이가 없는 것들은 걸러내고, 최종적으로 각 질문별 최적 가중치를 선정했다.
제8장: 실전 예시 — 실제 뉴스 기사에 적용해 보기
논문에서 사용된 예시 기사를 통해 시스템의 작동을 직관적으로 살펴보자.
예시 기사: 아프가니스탄 독일 영사관 공격 (AFP, 2016)
HEADLINE
Taliban attack on German consulate in Afghan city kills at least six
LEAD
A powerful Taliban car bomb targeting the German consulate in the northern Afghan city of Mazar-i-Sharifon Friday night killed at least six people and wounded more than 100.
Giveme5W1H의 추출 결과:
질문
추출된 문구
정규화 결과
Who
The Taliban
YAGO: Taliban
What
attacked the German consulate
—
When
on Friday night
2016-11-10 (TIMEX3)
Where
Mazar-i-Sharif
36.7°N, 67.1°E
Why
growing insurgency against the government
—
How
with a powerful car bomb
—
이 여섯 개의 답만으로도, 기사를 읽지 않고도 무슨 일이 일어났는지 파악할 수 있다. 이것이 5W1H 추출의 핵심 가치다.
제9장: 한계와 미래 — 논문이 스스로 인정한 약점
"What" 추출의 딜레마
What의 정밀도(0.57)가 Who(0.77)보다 낮은 이유는 두 가지다:
1
저널리스틱 훅(Journalistic Hook)
기자들은 독자의 관심을 끌기 위해 헤드라인에 전체 내용을 담지 않는 경우가 많다. "충격적인 발표가 시장을 뒤흔들었다" — What이 뭔지 알려면 본문을 읽어야 한다.
2
긴 VP 절단의 역효과
"widespread corruption in the finance industry has cost $XX billion" 같은 문장에서, VP를 잘라내면 핵심 정보인 금액이 사라진다.
암묵적 When과 Where
일부 기사는 시간이나 장소를 명시적으로 언급하지 않는다:
"Apple이 새로운 iPhone을 발표했다" — 어디서? (Apple 본사 = Cupertino)
"올해의 칸 영화제에서..." — 정확한 날짜는?
논문 저자들은 YAGO 지식그래프를 활용해 "Apple → Cupertino", "칸 영화제 → 5월"과 같은 암묵적 정보를 추론하는 방법을 향후 연구 과제로 제시했다.
Why와 How: 가장 인간적인 질문
"왜"와 "어떻게"는 본질적으로 추론(reasoning)을 요구하는 질문이다. 기사에서 "because"라고 명시하는 경우는 드물고, 여러 문단에 걸쳐 원인이 암시되는 경우가 대부분이다. 2019년 기준으로 이런 심층적 이해는 규칙 기반 NLP의 한계를 넘어서는 것이었다.
제10장: 2026년, LLM 시대에서 Giveme5W1H의 의미
규칙 기반에서 LLM으로: 무엇이 바뀌었나
2019년에 Giveme5W1H가 구문 분석 트리와 규칙으로 고군분투했던 일을 2026년의 LLM은 자연스럽게 수행한다:
차원
Giveme5W1H (2019)
LLM 기반 (2026)
Why 추출
접속사/동사 매칭 (0.28)
문맥 추론 가능
How 추출
접속 구문 + 부사 (0.42)
의미 이해 기반
다국어
영어 전용
100+ 언어
추론 속도
CoreNLP 기반 빠른 처리
API 호출 비용
정규화
TIMEX3, 좌표, YAGO
별도 구현 필요
해석 가능성
규칙이 명확히 정의됨
블랙박스
하지만 Giveme5W1H가 여전히 중요한 이유
1
프레임워크로서의 가치
5W1H라는 구조화된 추출 프레임워크는 LLM 프롬프트 설계에도 그대로 적용된다. "이 기사의 5W1H를 추출해줘"라는 프롬프트는 Giveme5W1H가 정립한 개념에 기반한다.
2
정규화 파이프라인의 중요성
LLM이 "어제"라고 추출해도, 이걸 2026-04-12로 변환하는 건 별도의 정규화 시스템이 필요하다. Giveme5W1H의 SUTime/Nominatim/AIDA 파이프라인은 여전히 유효한 설계다.
3
벤치마크와 평가 체계
논문이 정립한 120개 기사 × 3명 평가자 × 3점 척도 평가 방법론은 새로운 5W1H 추출 시스템(LLM 포함)의 성능을 측정하는 기준선이 된다.
4
비용과 규모의 현실
하루 수십만 건의 뉴스를 LLM으로 처리하면 비용이 천문학적이다. 규칙 기반 시스템은 비용 제로에 가까운 대규모 처리가 가능하다.
하이브리드 접근법: 최선의 조합
2026년의 최신 트렌드는 규칙 기반 + LLM 하이브리드다:
뉴스 기사 수십만 건/일
→
규칙 기반 1차 추출 Giveme5W1H 스타일
→
신뢰도 낮은 건만 필터링
→
LLM 2차 정제 GPT-4o / Claude
1차로 규칙 기반 시스템이 빠르고 저렴하게 처리하고, 신뢰도가 낮은 결과(특히 Why, How)만 LLM에 넘겨 정제하는 방식이다. 비용은 90% 절약하면서 품질은 최대화하는 전략이다.
제11장: 실무에서의 활용 — 누가 이 기술을 쓰는가
뉴스 집계 서비스
Google News, Naver News, Apple News 등은 5W1H 추출을 통해:
같은 사건에 대한 기사들을 클러스터링
자동 뉴스 요약 생성
중복 기사 탐지 및 제거
미디어 연구
Giveme5W1H의 원래 동기였던 미디어 편향 분석:
같은 사건에 대해 각 언론사가 어떤 행위자(Who)를 강조하는지
어떤 원인(Why)을 선택하는지
어떤 맥락(How)을 제공하는지
지식 그래프 구축
5W1H 추출 결과는 자연스럽게 이벤트 지식 그래프의 노드와 엣지가 된다:
이벤트 지식 그래프
이벤트
공격
Who
탈레반
What
영사관 공격
When
2016-11-10
Where
마자르이샤리프
Why
반정부 봉기
How
자동차 폭탄
이런 구조화된 이벤트 데이터는 EventRAG, GraphRAG 등 최신 검색 증강 생성(RAG) 시스템의 핵심 자원이 된다.
재난 대응 및 위기 관리
실시간 뉴스에서 재난 이벤트를 자동 추출하여:
Where + When → 지도에 실시간 표시
What → 재난 유형 분류
How → 대응 방법 결정 지원
제12장: Word Mover's Distance — 평가에 사용된 핵심 기법
논문의 평가에서 핵심적으로 사용된 Word Mover's Distance(WMD)는 그 자체로 흥미로운 기법이다.
직관적 이해
두 문장의 의미적 거리를 측정하고 싶다고 하자:
문장 A: "Obama speaks to the media"
문장 B: "The president addresses the press"
단어 수준에서 보면 완전히 다른 문장이지만, 의미는 거의 같다. WMD는 Word2Vec 같은 단어 임베딩 공간에서, 한 문장의 단어들을 다른 문장의 단어들로 "이동"시키는 최소 비용을 계산한다.
"Obama"
→ 0.15
"president"
"speaks"
→ 0.12
"addresses"
"media"
→ 0.08
"press"
WMD = 0.15 + 0.12 + 0.08 = 0.35 (의미적으로 가까움)
이 기법을 사용해, Giveme5W1H가 추출한 문구와 사람이 어노테이션한 정답 문구 사이의 의미적 거리를 오차로 사용한 것이다.
마무리: 기계가 뉴스를 "이해"한다는 것
2,000년 전 로마의 수사학에서 시작된 육하원칙(5W1H)이, 2019년에는 컴퓨터 과학의 정보 추출 문제로 재탄생했고, 2026년에는 LLM의 구조화된 출력 프레임워크로 진화하고 있다.
Giveme5W1H 논문의 가장 큰 기여는 단순히 높은 성능의 시스템을 만든 것이 아니다. 그것은:
문제 정의
"뉴스의 핵심 이벤트 추출"을 6개 질문으로 형식화
공개 생태계
최초의 범용 오픈소스 시스템 + 공개 데이터셋
평가 프레임워크
후속 연구가 참조할 수 있는 표준화된 벤치마크
뉴스를 읽는 것은 인간에게 너무나 자연스러운 일이지만, 기계에게 "누가 무엇을 왜 했는지"를 이해시키는 것은 자연어 처리의 핵심 도전 중 하나다. Giveme5W1H는 그 도전에 대한 체계적이고 실용적인 첫 번째 답이었다.
그리고 이제, 이 프레임워크 위에 LLM이라는 강력한 엔진이 올라탄 2026년, "기계가 뉴스를 이해한다"는 말은 더 이상 은유가 아닌 현실이 되어가고 있다.
참고 문헌
Hamborg, F., Breitinger, C., & Gipp, B. (2019). Giveme5W1H: A Universal System for Extracting Main Events from News Articles. Proceedings of INRA 2019, Copenhagen, Denmark. arXiv:1909.02766
Hamborg, F., et al. (2018). Giveme5W: Main Event Retrieval from News Articles by Extraction of the Five Journalistic W Questions.
Kusner, M.J., et al. (2015). From Word Embeddings to Document Distances. (Word Mover's Distance)
Girju, R. (2003). Automatic Detection of Causal Relations for Question Answering.
Chang, A.X. & Manning, C.D. (2012). SUTime: A Library for Recognizing and Normalizing Time Expressions.
Suchanek, F.M., et al. (2007). YAGO: A Core of Semantic Knowledge.