Flow Matching확산 모델Rectified FlowODE최적 수송FLUXStable Diffusion 3생성 AI
Flow Matching 완전정복: 확산 모델 이후의 생성 AI 패러다임
DALL-E, Midjourney를 만든 확산 모델은 왜 느렸나? Meta AI의 Flow Matching은 '구불구불한 길' 대신 '직선 경로'로 노이즈를 이미지로 바꾼다. FLUX, SD3, Movie Gen, Voicebox — 2026년 최강 생성 모델들의 공통 비밀을 해부한다.
코어닷투데이2025-12-3028분
들어가며: 왜 AI 그림은 느렸을까?
2022년, Stable Diffusion이 세상을 바꿨다. 텍스트 한 줄로 그림을 만들어내는 마법. 하지만 사용해 본 사람이라면 알 것이다 — 느리다. 고해상도 이미지 한 장에 20~50 스텝, 고급 GPU에서도 수십 초. 왜?
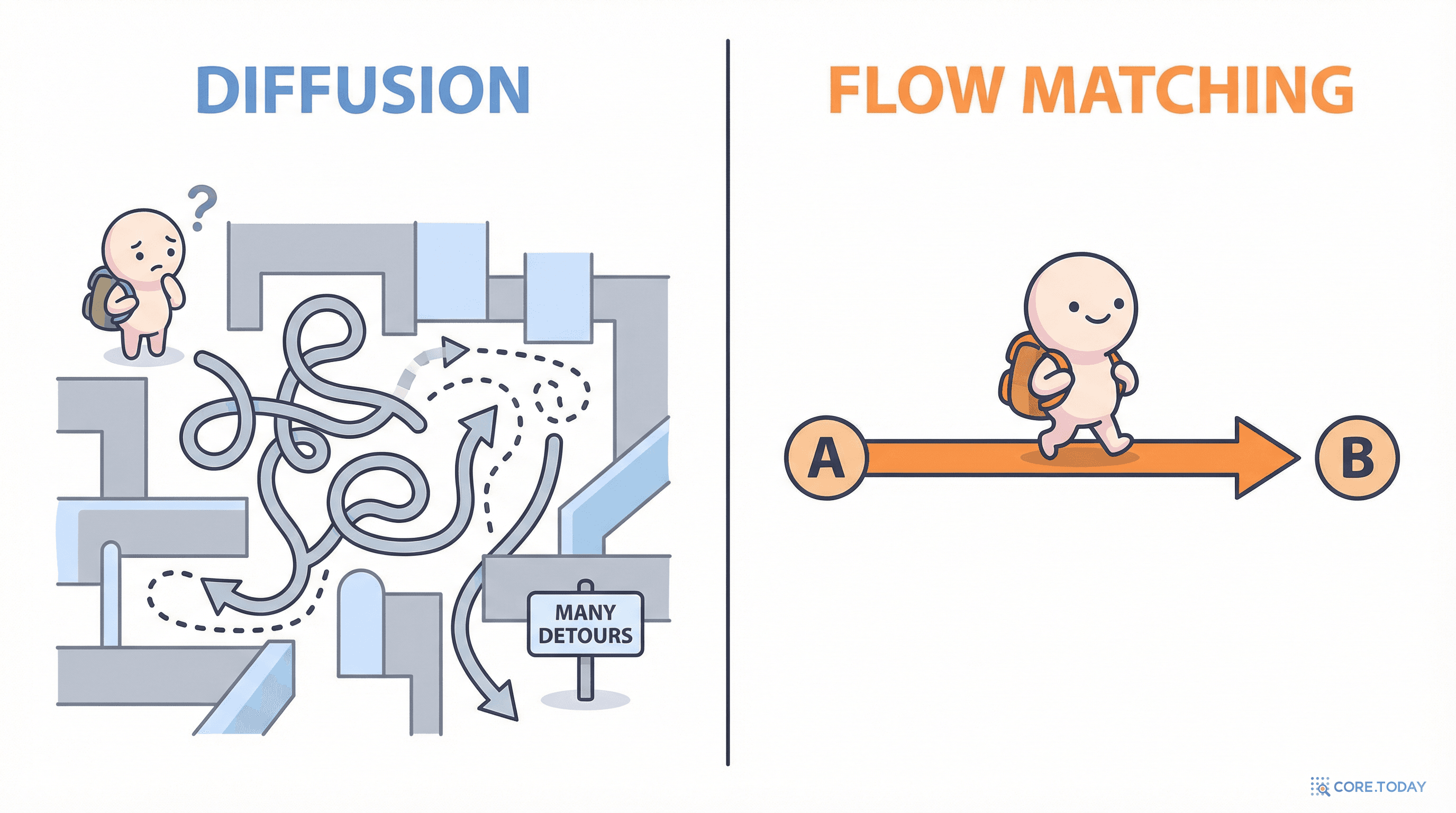
답은 그 이름에 있다. 확산(Diffusion). 확산 모델은 이미지를 만들 때, 마치 향수가 방 안에 퍼지듯 노이즈를 점진적으로 제거한다. 향수가 퍼지는 과정이 구불구불하고 비효율적이듯, 확산 모델의 경로도 그렇다. 노이즈 제거의 대부분이 마지막 몇 스텝에 몰려 있고, 나머지 스텝은 거의 아무 일도 하지 않는다.
만약 노이즈에서 이미지로 가는 직선 경로가 있다면? 구불구불 돌아갈 필요 없이, 최단 거리로 한 번에 도달할 수 있다면?
이것이 Flow Matching의 핵심 아이디어다.
2022년 말, 세 그룹의 연구자들이 거의 동시에 같은 통찰에 도달했다:
Meta AI (FAIR): Yaron Lipman 등 — "Flow Matching for Generative Modeling" (ICLR 2023)
UT Austin: Xingchao Liu 등 — "Rectified Flow" (ICLR 2023 Spotlight)
NYU: Michael Albergo 등 — "Stochastic Interpolants" (ICLR 2023)
그로부터 3년, 2026년 현재 — FLUX, Stable Diffusion 3, Meta Movie Gen, Voicebox, HunyuanVideo, Wan 2.1 — 세계 최강의 생성 모델들은 모두 Flow Matching을 사용한다.
이 글에서는 Flow Matching이 왜 필요했고, 어떻게 작동하며, 왜 확산 모델을 대체하고 있는지를 처음부터 끝까지 설명한다.
확산 모델의 역방향 경로를 시각화하면, 대부분의 스텝에서 거의 변화가 없다. 노이즈 제거가 마지막 몇 스텝에 집중된다. 앞의 수십 스텝은 "고민만 하고 움직이지 않는" 시간이다.
비유하자면:
서울에서 부산까지 가는데, 확산 모델은 고속도로를 타지 않고 전국의 국도를 돌아다닌다. 마지막에야 "아, 부산이 저기구나" 하고 방향을 잡는다. 20~50번의 방향 전환(스텝)이 필요하다.
Flow Matching은 서울에서 부산까지 직선 고속도로를 탄다. 1~4번의 방향 확인만으로 도착한다.
수학적 차이
관점
확산 모델 (DDPM)
Flow Matching
수학적 도구
SDE (확률적 미분방정식)
ODE (상미분방정식)
예측 대상
노이즈 (ϵ-prediction)
속도장 (velocity field)
경로 형태
곡선 (마지막에 급변)
직선 (선형 보간)
필요 스텝 수
20~1000
1~50 (증류 시 1~4)
이론적 기반
스코어 매칭, 랑주뱅 동역학
연속 방정식, 최적 수송 이론
일반성
특정 노이즈 스케줄에 종속
확산 경로를 특수한 경우로 포함
마지막 행이 결정적이다 — 확산 모델은 Flow Matching의 특수한 경우다. Flow Matching은 확산을 포함하면서, 그보다 더 효율적인 경로(직선 경로)를 사용할 수 있는 일반적 프레임워크다.
제3장: Flow Matching의 핵심 — 놀랍도록 단순한 아이디어
직관: "노이즈에서 이미지로 가는 직선을 배워라"
Flow Matching의 핵심을 한 문장으로:
시간 t=0의 노이즈에서 시간 t=1의 이미지까지, 각 시점에서 데이터가 어느 방향으로 얼마나 빠르게 움직여야 하는지(속도장, velocity field)를 학습한다.
2단계 레시피
Meta의 "Flow Matching Guide and Code" (2024)에 따르면, Flow Matching은 정확히 두 단계로 작동한다:
Step 1: 확률 경로(Probability Path) 설계. 소스 분포(가우시안 노이즈, t=0)에서 타겟 분포(실제 데이터, t=1)로 가는 연속적인 확률 경로 pt(x)를 정의한다.
가장 단순한 선택: 선형 보간.xt=(1−t)⋅x0+t⋅x1
여기서 x0은 노이즈, x1은 데이터 샘플.
Step 2: 속도장 학습. 신경망 vθ(x,t)를 학습하여, 각 시점 t에서 데이터 x가 어느 방향으로 이동해야 하는지 예측한다.
손실 함수는 놀랍도록 단순하다:
L=E[∥vθ(xt,t)−(x1−x0)∥2]
"현재 위치에서의 예측 속도"와 "실제 속도(= 데이터 - 노이즈)"의 차이를 최소화하라. 이것이 전부다.
조건부 Flow Matching (CFM): 핵심 트릭
이론적으로 "모든 데이터 포인트에 대한 평균 속도장"을 직접 계산하는 것은 불가능하다 (비다루기, intractable). 하지만 조건부 Flow Matching(CFM)이 이 문제를 해결한다.
핵심 정리: 개별 데이터 포인트에 조건화된 속도장(conditional vector field)을 학습하는 것은, 전체 속도장(marginal vector field)을 학습하는 것과 수학적으로 동일한 그래디언트를 준다.
따라서 학습 시에는 데이터 포인트 하나, 노이즈 하나를 뽑아서 선형 보간하고, 그 속도를 예측하기만 하면 된다. 확산 모델의 ϵ-prediction과 비슷한 수준의 단순함이지만, 더 효율적인 경로를 학습한다.
왜 직선이 최적인가 — 최적 수송(Optimal Transport)
Flow Matching이 직선 경로를 사용하는 것은 우연이 아니다. 수학적으로 이것은 최적 수송 이론과 연결된다.
1780년대, 프랑스 수학자 가스파르 몽주(Gaspard Monge)는 이런 문제를 제시했다: "흙더미를 구덩이에 옮길 때, 가장 적은 비용으로 옮기는 방법은?" 이것이 최적 수송 문제다.
2000년대, Benamou와 Brenier는 이 문제의 동적 형식화를 제시했다: 확률 분포를 연속적으로 이동시킬 때, 운동 에너지를 최소화하는 경로는 무엇인가? 답은 직선(측지선, geodesic)이다.
Flow Matching의 직선 보간 xt=(1−t)x0+tx1은 정확히 이 최적 수송의 해에 해당한다. 노이즈와 데이터 사이의 가장 에너지 효율적인 경로다.
왜 직선이 좋은가 — 3가지 이유
1. 이산화 오차 제로: 완벽한 직선은 오일러 스텝 1번으로 정확히 풀린다. 구불구불한 경로는 많은 스텝이 필요.
2. 경로가 교차하지 않음: OT 경로는 서로 교차하지 않아, 학습 분산이 낮고 수렴이 빠르다.
3. 학습 신호가 단순: 속도가 상수(x1−x0)이므로, 신경망의 회귀 타겟이 단순하다.
제4장: 실전 — Flow Matching이 만든 모델들
FLUX.1: 2024년 이미지 생성의 왕
FLUX.1은 Black Forest Labs가 2024년 8월 출시한 120억 파라미터 이미지 생성 모델이다. 개발팀은 Stable Diffusion의 원 저자들(Robin Rombach, Andreas Blattmann, Patrick Esser)이 독립하여 설립한 회사다.
FLUX.1의 핵심 아키텍처는 Rectified Flow Transformer — Flow Matching의 직선 경로와 트랜스포머를 결합한 것이다.
세 가지 변형:
FLUX.1 [pro]: 플래그십. 텍스트-이미지 ELO 1060점, 리더보드 1위
FLUX.1 [dev]: 가이던스 증류 버전. 연구/비상업 용도
FLUX.1 [schnell]: 속도 최적화. 1~4 스텝으로 2048px 이미지 생성. A100에서 약 10초
FLUX.1은 Midjourney, DALL-E 3, Stable Diffusion 3, SDXL을 모두 능가하는 성능을 보인다.
Stable Diffusion 3: Rectified Flow의 대중화
2024년 3월, Stability AI의 Esser 등이 발표한 SD3 논문 "Scaling Rectified Flow Transformers for High-Resolution Image Synthesis"(ICML 2024)는 Flow Matching을 대중에게 알린 결정적 논문이다.
핵심 기여:
MMDiT (Multimodal Diffusion Transformer): 텍스트와 이미지에 별도 가중치를 사용하되 양방향 정보 교환. 텍스트 이해력, 타이포그래피 품질 향상
노이즈 샘플링 개선: Rectified Flow의 노이즈를 지각적으로 중요한 스케일로 편향시켜 학습 효율 향상
예측 가능한 스케일링: 검증 손실이 낮을수록 생성 품질이 향상되는 예측 가능한 관계 확인
Meta Movie Gen: 300억 파라미터 비디오 생성
2024년 10월, Meta가 공개한 Movie Gen은 300억 파라미터의 Flow Matching 기반 비디오 생성 모델이다.
최대 16초 고해상도 비디오 생성
10억 이미지-텍스트 쌍 + 1억 비디오-텍스트 쌍으로 학습
4가지 능력: 비디오 생성, 개인화 비디오, 정밀 비디오 편집, 오디오 생성
Flow Matching의 장점: 제로 터미널 SNR(signal-to-noise ratio)이 내재적으로 보장되어, 추가 조정 없이 안정적인 비디오 출력
Meta Voicebox: 음성 생성의 혁명
2023년 6월 발표된 Voicebox는 Flow Matching의 첫 대규모 음성 적용 사례다 (NeurIPS 2023).
비자기회귀(non-autoregressive) Flow Matching 모델
5만 시간 이상의 음성 데이터로 학습
6개 언어 지원
Microsoft의 VALL-E 대비: 인식 오류율 1.9% vs 5.9%, 음성 유사도 0.681 vs 0.580, 속도 최대 20배 빠름
HunyuanVideo & Wan 2.1: 오픈소스 비디오 생성
텐센트 HunyuanVideo (2024~2025): 130억 파라미터, Flow Matching 기반 최대 오픈소스 비디오 생성 모델. 15억 비디오 + 100억 이미지로 학습.
알리바바 Wan 2.1 (2025년 2월): 140억 파라미터 Flow Matching 모델. VBench 리더보드 1위 (86.22%) — OpenAI Sora (84.28%), Luma (83.61%)를 능가.
flow_matching PyTorch 라이브러리: 연속/이산 FM 구현 및 예제 (github.com/facebookresearch/flow_matching)
"Flow Matching Guide and Code" (2024년 12월): 분야의 참조 문서 역할. 수학적 기초부터 PyTorch 구현까지 자기 완결적 리뷰
핵심 논문들: 원본 Flow Matching, Voicebox, Movie Gen, Discrete FM
산업 채택 현황
Flow Matching 기반 주요 모델 (2023~2026)
이미지: FLUX.1, SD3120억 파라미터. 1~4 스텝 생성
비디오: Movie Gen, Wan 2.1140~300억. VBench 1위
음성: VoiceboxVALL-E 대비 20배 빠름
텍스트: Discrete FM비자기회귀 최고 성능
단백질: SE(3)-FMICLR 2024. 분자 설계
마치며: 직선의 힘
수학자 몽주가 1780년대에 물었다: "흙을 옮기는 가장 효율적인 경로는?" 답은 직선이었다.
240년 뒤, AI 연구자들이 물었다: "노이즈를 이미지로 바꾸는 가장 효율적인 경로는?" 답은 역시 직선이었다.
확산 모델은 "어떤 경로든 결국 목적지에 도달한다"는 것을 보여주었다. Flow Matching은 "최적의 경로가 존재하고, 그것을 직접 학습할 수 있다"는 것을 보여주었다. 그 차이가 50 스텝과 4 스텝의 차이, 수십 초와 수 초의 차이, 그리고 2022년과 2026년의 차이를 만들었다.
FLUX가 1초에 이미지를 그리고, Movie Gen이 16초 비디오를 만들고, Voicebox가 20배 빠르게 말하고, Wan 2.1이 VBench 1위를 차지한 것 — 이 모든 것의 수학적 기반에는 "직선이 가장 빠르다"는 단순하고도 깊은 통찰이 있다.
때로는 가장 단순한 답이 가장 강력하다.
참고 문헌
Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., & Le, M. (2023). Flow Matching for Generative Modeling. ICLR 2023. arXiv:2210.02747.
Liu, X., Gong, C., & Liu, Q. (2023). Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. ICLR 2023 Spotlight. arXiv:2209.03003.
Albergo, M. S., Boffi, N. M., & Vanden-Eijnden, E. (2023). Stochastic Interpolants: A Unifying Framework for Flows and Diffusions. arXiv:2303.08797.
Esser, P., et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. ICML 2024. arXiv:2403.03206.
Meta AI. (2024). Flow Matching Guide and Code. arXiv:2412.06264.
Gat, I., et al. (2024). Discrete Flow Matching. NeurIPS 2024 Spotlight. arXiv:2407.15595.
Polyak, A., et al. (2024). Movie Gen: A Cast of Media Foundation Models. Meta AI. arXiv:2410.13720.
Le, M., et al. (2023). Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale. NeurIPS 2023. arXiv:2306.15687.
Chen, R. T. Q., et al. (2018). Neural Ordinary Differential Equations. NeurIPS 2018 Best Paper. arXiv:1806.07366.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239.